关键词提取任务概述
随着互联网信息的快速增长,文本数据呈现出规模大、更新快、结构复杂等特点。如何从大量文本中快速获取核心信息,成为自然语言处理领域的重要研究内容之一。关键词提取任务正是在这一背景下提出的典型文本处理任务。
1. 关键词提取的定义
关键词提取(Keyword Extraction)是指从一篇或多篇文本中,自动识别并选取能够准确反映文本主题和主要内容的若干词语或短语。这些关键词通常具有较高的信息密度,能够在较短的时间内帮助读者理解文本的核心含义。
与人工标注关键词相比,自动关键词提取方法具有效率高、成本低、可扩展性强等优点,因此在实际应用中具有重要价值。
2. 关键词提取在自然语言处理中的地位
关键词提取属于自然语言处理中的基础任务之一,同时也是许多高级任务的重要前置步骤。例如:
在文本摘要中,关键词可以帮助确定摘要的重点内容;
在文本分类和聚类中,关键词有助于刻画文本特征;
在信息检索和搜索引擎中,关键词用于提高检索的准确性和效率。
可以认为,关键词提取是连接原始文本数据与高层语义分析之间的重要桥梁。
3. 关键词提取的常见应用场景
关键词提取技术已广泛应用于多个实际场景中,主要包括:
文档主题分析
通过提取关键词,快速判断文本的主题或研究方向。
搜索引擎与信息检索
利用关键词对文档进行索引,提高检索效率和相关性。
文本分类与推荐系统
将关键词作为特征,辅助实现内容分类和个性化推荐。
学术文献与新闻分析
自动生成文章关键词,减少人工标注工作量。
4. 关键词提取方法的基本分类
根据是否依赖标注数据,关键词提取方法通常可分为以下两类:
有监督方法:将关键词提取视为分类或序列标注问题,需要大量人工标注数据;
无监督方法:不依赖标注语料,通过统计特征或图结构完成关键词提取。
其中,TF-IDF 方法作为一种经典的无监督关键词提取方法,因其原理简单、实现方便、效果稳定,被广泛用于教学和实际应用中。
TF-IDF 方法的基本思想
在关键词提取任务中,最直观的做法是统计词语在文本中出现的次数,即基于**词频(Term Frequency,TF)**的方法。然而,单纯依赖词频往往难以准确反映词语的重要性,因此提出了 TF-IDF(Term Frequency--Inverse Document Frequency) 方法。
1. 基于词频方法的局限性
词频方法认为,某个词在文本中出现的次数越多,该词就越重要。但在实际文本中,存在大量高频却缺乏区分能力的词语,例如"的""是""我们"等。这类词虽然出现频率很高,却无法体现文本的主题信息。
因此,仅使用词频进行关键词提取,容易导致结果被无意义的高频词干扰,影响关键词的准确性。
2. TF-IDF 的核心思想
TF-IDF 方法在词频的基础上,引入了**逆文档频率(Inverse Document Frequency,IDF)**的概念,其核心思想可以概括为:
一个词在当前文档中出现得越频繁,同时在整个语料库中出现得越少,该词对当前文档的重要性就越高。
该思想兼顾了词语在单篇文档中的重要程度和其在全体文档中的区分能力,有效缓解了单纯使用词频带来的问题。
3. 词频(TF)的定义
词频(Term Frequency,TF)用于衡量某个词在文档中出现的频繁程度,常见的计算方式如下:
TF(t, d) = count(t, d) / |d|
其中:
count(t, d) 表示词语 t 在文档 d 中出现的次数
|d| 表示文档 d 中词语的总数
该形式通过归一化处理,减少文档长度差异对词频计算的影响。
(如果你用 LaTeX,可直接写)
TF(t, d) = \frac{count(t, d)}{|d|}
4. 逆文档频率(IDF)的定义
逆文档频率(Inverse Document Frequency,IDF)用于衡量词语在整个语料库中的普遍程度,其计算公式为:
IDF(t) = log( N / (n_t + 1) )
其中:
N 表示语料库中的文档总数
n_t 表示包含词语 t 的文档数量
分母加 1 用于避免分母为 0 的情况
LaTeX 版本:
IDF(t) = \log \left( \frac{N}{n_t + 1} \right)
- TF-IDF 的计算公式
TF-IDF 通过结合 TF 和 IDF 得到,计算公式如下:
TF-IDF(t, d) = TF(t, d) * IDF(t)
LaTeX 版本:
TF\text{-}IDF(t, d) = TF(t, d) \times IDF(t)
通过计算每个词的 TF-IDF 值,并按权重大小排序,可以选取权重较高的词语作为文本的关键词。
6. TF-IDF 方法的直观理解
从直观角度来看,TF-IDF 方法强调的是**"局部重要性"与"全局稀有性"的结合**。
它不仅关注词语在单篇文档中的表现,还考虑其在整个语料库中的分布情况,因此能够更有效地反映文本的主题特征。
TF-IDF 关键词提取流程
基于 TF-IDF 的关键词提取通常遵循一套相对固定的流程。该流程从原始文本出发,经过预处理、特征计算和结果筛选,最终得到文本的关键词集合。整体过程清晰、可解释性强,适合作为关键词提取任务的入门方法。
1. 构建语料库
在 TF-IDF 方法中,语料库是计算逆文档频率(IDF)的基础。
语料库可以是:
多篇文本组成的文档集合(如新闻、论文、评论)
单篇目标文本与其背景文本集合
语料库的规模和质量会直接影响 IDF 的计算结果,从而影响关键词提取的效果。
2. 文本预处理
为了保证计算结果的准确性,需要对原始文本进行预处理,常见步骤包括:
分词
将连续文本切分为词语序列(中文通常需要分词工具)。
去除停用词
删除"的、是、在"等高频但无实际语义贡献的词语。
文本规范化
如统一大小写、去除标点符号和特殊字符等。
文本预处理的质量在很大程度上决定了最终关键词的合理性。
3. 统计词频(TF)
在完成分词后,对每篇文档中的词语进行统计,计算其词频(TF):
TF(t, d) = count(t, d) / |d|
该步骤用于衡量词语在当前文档中的重要程度,是 TF-IDF 计算的基础。
- 计算逆文档频率(IDF)
在整个语料库范围内,统计每个词语出现于多少篇文档中,并计算其逆文档频率:
IDF(t) = log( N / (n_t + 1) )
该步骤用于降低在多数文档中频繁出现词语的权重,提高具有区分能力词语的重要性。
5. 计算 TF-IDF 权重
将 TF 和 IDF 相乘,得到每个词在文档中的 TF-IDF 值:
TF-IDF(t, d) = TF(t, d) * IDF(t)
TF-IDF 值越大,说明该词语对当前文档的区分能力越强。
6. 关键词排序与筛选
对文档中所有词语的 TF-IDF 值进行排序,通常选择权重排名靠前的若干词作为关键词,即:
选取 Top-K 词语
或设置阈值进行筛选
最终得到的关键词集合可以用于后续的文本分析任务。
7. 流程小结
基于 TF-IDF 的关键词提取流程可以概括为:
文本输入 → 预处理 → TF 计算 → IDF 计算 → TF-IDF 计算 → 关键词筛选
语料库的创建
1. 什么是语料库
语料库(Corpus)是指在自然语言处理研究中,用于分析和处理语言现象的文本集合。它是对语言实际使用情况的系统性记录,也是文本分析与建模的重要基础。
从应用角度来看,语料库具有以下几个基本特征:
(1)语料库来源于真实语言环境
语料库中所包含的文本材料均来自语言的实际使用场景,如新闻报道、学术论文、网络文本等,而非人为编造的示例语句。这保证了语料分析结果的客观性和可信度。
(2)语料库以电子形式存储和管理
现代语料库通常依托计算机系统进行存储和处理,是以电子计算机为载体的语言资源,为自动化文本分析提供了技术基础。
(3)语料需要经过处理才能发挥价值
原始语料往往结构复杂、噪声较多,只有经过分词、清洗、标注等加工和分析过程,才能转化为可用于计算和建模的有效资源。
2. 如何构建语料库
在 TF-IDF 关键词提取任务中,语料库的构建过程通常包括以下步骤:
首先,将待分析的文本或文档集合读入计算机内存。这些文档可以来自文件系统、数据库或网络数据源。
其次,利用编程工具对文本进行统一管理。在实际应用中,Python 由于其丰富的文本处理库和简洁的语法,被广泛用于语料库的构建与维护。通过 Python,可以方便地完成文本读取、存储以及后续的预处理操作。
在完成上述步骤后,所构建的文本集合即可作为 TF-IDF 计算中的语料库,为逆文档频率(IDF)的统计提供基础数据支持。
如何进行中文分词
在自然语言处理中,分词是文本分析的基础步骤之一。与英文文本不同,英文单词之间天然以空格作为分隔符,而中文文本中词语往往连续书写、没有明显边界。因此,在进行中文关键词提取之前,必须先对文本进行分词处理,将连续的字符序列切分为具有语义意义的词语。
1. 分词前的准备工作
在中文分词之前,通常需要准备两类核心资源:分词工具和停用词库。
(1)分词工具的选择
分词工具是实现中文分词的基础。在 Python 环境中,较为常用的中文分词工具是 jieba(结巴分词)。该工具通过词典匹配与概率模型相结合的方式,对中文文本进行自动切分,具有使用方便、效果稳定等特点。
需要注意的是,jieba 默认词典以通用词汇为主,并不针对特定领域进行优化。当处理医学、法律或专业技术文本时,可以通过自定义词典的方式补充专业术语,从而提高分词的准确性。
(2)停用词库的作用
停用词是指在文本中出现频率较高,但对表达文本核心含义贡献较小的词语。例如"的、了、是"等助词,"我们、他们"等代词,以及部分语气词和虚词。
在关键词提取任务中,如果不对停用词进行过滤,这类高频但信息量较低的词语会干扰 TF-IDF 权重的计算。因此,通常需要提前准备停用词库,在分词完成后将这些词语从结果中剔除。
2. 基于 jieba 的中文分词流程
在完成语料库与相关资源准备后,即可进行中文分词处理。基于 jieba 的分词流程一般包括以下几个步骤:
首先,安装并导入 jieba 分词库,使其能够在 Python 环境中正常调用。
其次,从语料库中读取待处理的文本内容,可以是单篇文本,也可以是多篇文档组成的集合。
然后,调用 jieba 提供的分词接口对文本进行切分。jieba 支持多种分词模式,其中精确模式能够较好地平衡分词准确率与实用性,适合大多数关键词提取场景。
最后,将分词结果与停用词库进行匹配,过滤掉无意义词汇,得到较为干净的词语集合。
3. 分词示例说明
例如,对文本:
"秦始皇陵兵马俑是西安的著名景点,吸引了大量游客前来参观"
进行中文分词,并在分词结果中去除停用词后,可得到如下词语列表:
"秦始皇陵", "兵马俑", "西安", "著名景点", "吸引", "大量", "游客", "参观"
这些词语较为准确地反映了文本的主题内容,为后续基于 TF-IDF 的关键词权重计算提供了良好的基础。
词云图绘制

1. 词云图的基本原理
词云图的核心思想是:
词语的重要性越高,在图中显示得越显眼。
在关键词提取任务中,词语的重要性通常由以下因素决定:
词频大小
TF-IDF 权重大小
在实际应用中,往往使用 TF-IDF 权重作为词云图中词语大小的依据,从而使词云图更加符合文本主题。
2. 词云图在关键词提取中的作用
与表格形式的关键词列表相比,词云图具有以下优势:
直观展示文本主题
便于快速理解文本核心内容
增强结果的可读性和表现力
因此,词云图常被用于:
文本分析结果展示
博客或课程报告可视化
数据分析辅助说明
3. 词云图绘制的基本流程
在中文文本分析中,绘制词云图通常包括以下步骤:
准备分词并过滤停用词后的词语数据
根据 TF-IDF 结果获取词语及其权重
调用词云绘制工具生成词云图
对词云图进行样式调整并展示
python实现案例
有以下句子作为语料库
This is the first document
This document is the second document
And this is the third one
Is this the first document
This line has several words
This is the final document
python
from sklearn.feature_extraction.text import TfidfVectorizer#补充内容:TF-IDF的方式计算
import pandas as pd
inFile = open(r".\task2_1.txt", 'r')
corpus = inFile.readlines()#
vectorizer = TfidfVectorizer() #类,转为TF-IDF的向量转换对象
tfidf = vectorizer.fit_transform(corpus) #传入数据,返回包含TF-IDF的向量值
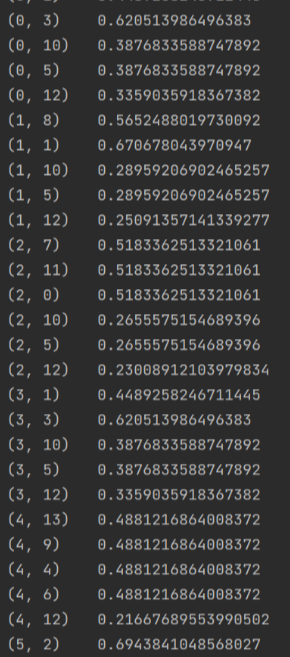
print(tfidf)
wordlist = vectorizer.get_feature_names() #获取特征名称,所有的词
print(wordlist)
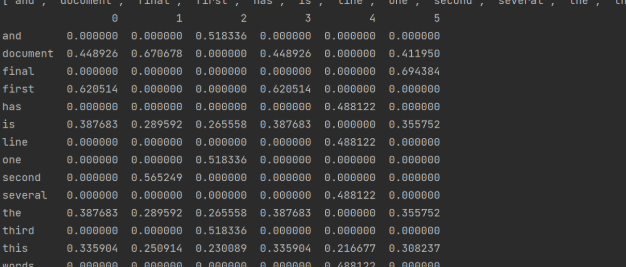
df = pd.DataFrame(tfidf.T.todense(), index=wordlist)#tfidf.T.todense()恢复为稀疏矩阵
print(df)
featurelist = df.iloc[:,5].to_list() #通过索引号获取第2列的内容并转换为列表
resdict = {} #排序以及看输出结果对不对
for i in range(0, len(wordlist)):
resdict[wordlist[i]] = featurelist[i]
resdict = sorted(resdict.items(), key=lambda x: x[1], reverse=True)
print(resdict[2])
#实现,pd实现,把所有的文章中关键词都进行排序,并且将排名在前5的关键词打印输出运行结果