目录
[1. 预训练语言模型底座](#1. 预训练语言模型底座)
[2. 向量生成:池化策略](#2. 向量生成:池化策略)
[3. 归一化与标度调整](#3. 归一化与标度调整)
[3.损失函数:InfoNCE Loss](#3.损失函数:InfoNCE Loss)
四、BGE如何将一个不定长度的句子转换为固定长度的embedding向量?
BGE模型是一个系统工程,其强大并非源于单一创新,而是精心设计的架构 与多阶段、精细化的训练策略共同作用的结果。
一、模型架构
BGE的架构可以理解为"强预训练底座 + 高效的向量生成模块"。
1. 预训练语言模型底座
BGE并非从零开始训练,而是建立在强大的预训练语言模型之上,这是其能力的基石。
- 早期版本 :基于标准的BERT 或RoBERTa架构。这些是经典的"编码器"模型,擅长理解文本的深度语义。
- 最新版本 :采用更先进的预训练模型作为底座,例如FlagAttention 或经过优化的大规模模型。这些底座模型通过以下方式增强了BGE的基础能力:
- 更长的上下文窗口:支持处理更长的文本序列,对于文档级Embedding至关重要。
- 更高效的注意力机制:如FlashAttention,降低了计算成本,提升了训练效率。
- 更优的预训练目标 :除了传统的掩码语言模型,还结合了类似RetroMAE的重构预训练方法。RetroMAE通过更强的文本重构任务,迫使模型学习更全面、更具判别性的句子表示,这对后续的对比学习有极大裨益。
2. 向量生成:池化策略
预训练模型输出的是每个Token的向量。如何将它们聚合为一个固定长度的句子向量,是关键一步。BGE默认采用cls****池化。
- **[CLS]**Token :在BERT系列模型中,输入序列的开头会添加一个特殊的
[CLS]Token。经过多层Transformer编码后,这个Token的向量被认为汇聚了整个句子的信息。 - 优势 :
- 计算高效:直接取用,无需额外计算。
- 被广泛验证:在句子分类、语义匹配等任务上被证明有效。
- 其它可选策略 :BGE也支持
mean pooling(取所有Token向量的平均值),在某些任务上可能表现不同,但cls是其默认和推荐方案。
3. 归一化与标度调整
这是Embedding模型优化中的一个重要技巧。
- 向量归一化 :BGE对最终输出的句子向量进行L2 归一化 ,即将向量的长度缩放到1。这使得相似度计算完全由向量间的夹角(余弦相似度)决定,避免了向量模长带来的干扰,使训练更稳定、检索更高效。
- 温度参数τ :在对比学习损失函数中,有一个关键的温度超参数 τ。BGE在训练中会优化这个参数,它控制着模型对"难负例"的区分强度。一个合适的 τ 值能让模型学习到更清晰的语义边界。
二、核心训练技术
BGE的训练是一个多阶段的、数据和技术驱动的过程。下图清晰地展示了其演进路径和核心技术:
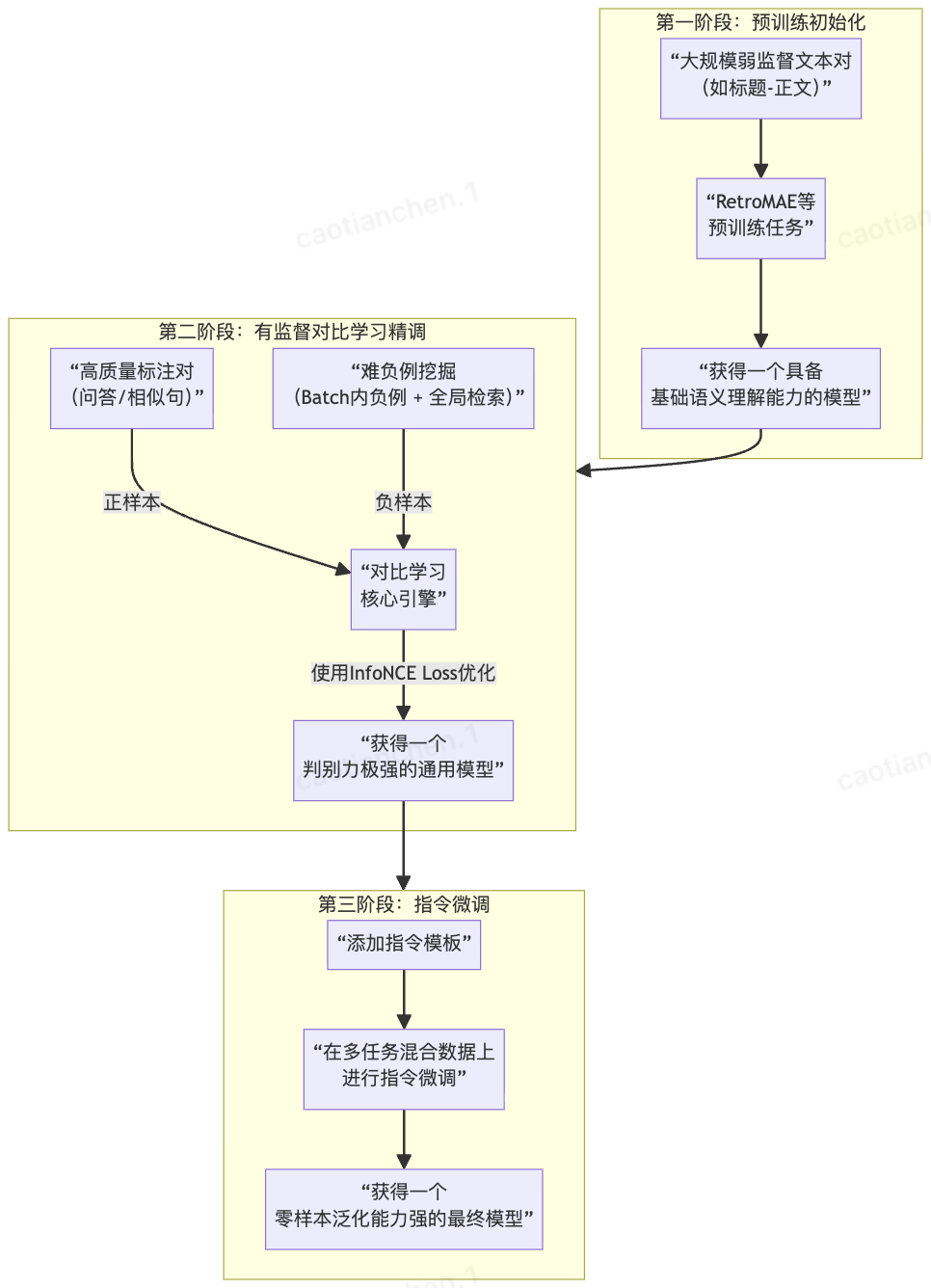
以下是每个阶段的技术详解:
阶段一:预训练初始化
此阶段目标是为模型打下坚实的语义理解基础。
- 数据 :使用大规模弱监督文本对,例如从互联网爬取的(网页标题,正文)、(问题,相关段落)、(锚文本,链接页面)等。这些数据虽然 noisy,但数量庞大,蕴含丰富的世界知识。
bash
# 数据源示例(大规模弱监督文本对)
弱监督文本对 = [
{
"文本A": "什么是Python的装饰器?",
"文本B": "装饰器是Python中修改函数或类的行为的语法糖。它允许在不修改原函数代码的情况下添加功能。",
"来源": "StackOverflow问答对"
},
{
"文本A": "神经网络反向传播算法",
"文本B": "反向传播通过计算损失函数对网络权重的梯度,使用链式法则从输出层向输入层逐层传播误差。",
"来源": "技术博客标题与正文"
},
{
"文本A": "Docker容器化技术",
"文本B": "Docker是一个开源的应用容器引擎,让开发者可以打包应用以及依赖包到一个可移植的镜像中...",
"来源": "维基百科条目"
}
# ... 数千万甚至上亿对类似的技术领域文本
]- 技术 :采用RetroMAE等先进的预训练目标。RetroMAE 通过"编码强、解码弱"的重构任务,迫使编码器生成高质量的句子表示,以帮助一个非常简单的解码器(如单层Transformer)重建原始句子。这比传统的MLM对句子级语义的学习更直接、更有效:
1.数据预处理与准备
(1)数据清洗与过滤
首先对收集到的数亿对弱监督文本进行预处理:
- 文本清洗:移除HTML标签、特殊字符,标准化空白字符,保留中文标点
- 长度过滤:过滤掉过短(如少于5个字符)或过长(如超过512个字符)的文本
- 质量过滤 :
- 移除完全重复的文本对
- 移除内容重叠度过高的文本对(如超过80%相似度)
- 根据来源类型赋予不同权重(如StackOverflow问答对质量高,论坛讨论质量相对低)
- 计算每对文本的"质量评分",基于文本完整性、信息密度等指标
(2)训练样本构建策略
对于每个弱监督文本对(如问题-答案、标题-正文):
- 双向处理 :每对文本的两个部分(文本A和文本B)分别作为独立的训练样本
- 不依赖配对关系:RetroMAE训练时不利用文本对之间的关联性,只处理单个文本
- 大规模批处理:每次训练使用大批量(如4096个)文本,每个文本独立进行掩码和重构
例如,对于"什么是Python的装饰器?"和其答案,会生成两个独立的训练样本,分别学习问题的表示和答案的表示。
2.RetroMAE训练流程
(1)训练核心思想
RetroMAE的核心是"不对称的编码-解码架构":
- 编码器强大:12层Transformer,参数丰富
- 解码器极弱:仅1层Transformer或简单MLP
- 迫使编码器学习信息密集的句子表示,因为解码器无法从高度掩码的输入中获取足够信息
(2)对单个文本的训练步骤
第一步:双重掩码处理
对于每个文本(如"什么是Python的装饰器?"),进行两次不同的掩码:
(1)编码器输入(轻度掩码):
- 掩码率:约15-30%
- 掩码策略:采用标准BERT的MLM策略
- 80%替换为
[MASK]标记 - 10%替换为随机词
- 10%保持原词不变
- 80%替换为
- 目标:编码器能看到大部分上下文,学习正常的语言理解
bash
原句:什么是Python的装饰器?
轻度掩码后:[什么是] [Python] [的] [装饰器] [?]
↓ ↓ ↓ ↓ ↓
保留 [MASK] 保留 [MASK] 保留
编码器输入:"什么是[MASK]的[MASK]?"(2)解码器输入(重度掩码):
- 掩码率:约80-90%,甚至可达99%
- 掩码策略:简单粗暴地掩盖大部分词
- 目标:解码器只能看到极少数词,必须依赖编码器生成的句子向量
bash
原句:什么是Python的装饰器?
重度掩码后:[什么是] [Python] [的] [装饰器] [?]
↓ ↓ ↓ ↓ ↓
[MASK] [MASK] [MASK] 保留 [MASK]
解码器输入:"[MASK][MASK][MASK]装饰器[MASK]"第二步:前向传播过程
(1)编码阶段:
- 轻度掩码的文本输入到**12层Transformer编码器,**编码器输出每个位置的隐藏状态
- 取
[CLS]位置的向量作为句子表示向量(sentence embedding),这个向量需要捕获整个句子的语义信息
(2)解码阶段:
- 重度掩码的文本与句子表示向量一起输入到极简解码器
- 解码器只有1层Transformer,参数很少,能力极弱
- 解码器必须依赖句子表示向量才能重建原始文本
- 解码器预测每个被掩码位置的原始词语
第三步:损失计算与优化
- 重构损失 :
- 计算解码器预测与原始文本的交叉熵损失
- 关键 :只计算被掩码位置的损失,未被掩码的位置不参与损失计算
- 损失函数的数学意义 :
- 最大化:P(原始句子 | 句子向量, 少量未被掩码的词语)
- 由于解码器能力弱,它必须依赖编码器生成的句子向量,这迫使编码器学习生成信息密集的句子向量
- 训练目标 :
- 不是简单地预测几个掩码词(如BERT的MLM),而是从高度残缺的输入 中重建完整句子
- 这要求句子向量包含足够完整的语义信息
(3)训练过程中的关键机制
梯度流不对称性
- 编码器获得强梯度信号:因为解码器能力弱,重构损失主要反映了编码器生成句子向量的质量
- 解码器梯度受限:解码器参数少,且输入信息极度缺乏,无法"作弊"地学习重建
信息瓶颈设计
- 解码器只能通过两个信息源重建句子:
- 极少数未被掩码的词语(如例子中的"装饰器")
- 编码器生成的句子向量
- 由于未被掩码的词语极少(可能只有1-2个),解码器必须主要依赖句子向量
- 这迫使句子向量必须编码几乎完整的句子语义
训练稳定性策略
- 渐进式掩码率:训练初期使用较低的重度掩码率(如70%),后期逐渐增加(至90%)
- 动态温度调整:控制损失函数的"温度"参数,平衡难易样本的学习
- 大批次训练:使用大批次(4096或更大)以获取更稳定的梯度估计
3.训练数据的使用特点
(1)弱监督信号的间接利用
虽然文本对之间有语义关联(如问题和答案),但RetroMAE训练时:
- 不直接使用配对关系:问题和答案分别独立训练
- 间接学习关联性:相似主题的文本会在相近的批次中出现
- 隐含的领域适应:技术领域的文本共享专业术语和表达方式
(2)数据多样性的重要性
- 来源多样性:StackOverflow、技术博客、维基百科、API文档等
- 主题覆盖广度:从基础语法到高级概念,从前端到后端,从理论到实践
- 表达方式差异:正式文档、问答对话、代码注释等不同文体
(3)规模化训练的优势
- 数量优势:数亿对文本提供海量训练样本
- 批内负采样:大批次训练天然提供"对比"信号(不同文本互为隐式负例)
- 语义空间覆盖:覆盖广泛的技术概念和表达方式
4.训练完成后的模型能力
经过第一阶段RetroMAE预训练后,模型获得:
(1)基础语义理解能力
- 词语级理解:理解技术术语的含义和用法
- 句法结构理解:理解复杂的技术表达句式
- 领域知识获取:掌握编程语言、框架、算法的相关知识
(2)句子表示生成能力
- 信息密集的向量 :
[CLS]向量能够编码句子的核心语义 - 语义相似性敏感:语义相似的句子产生相近的向量
- 领域特性编码:技术文本的向量反映其技术内容和难度级别
(3)为后续训练奠定基础
- 良好的初始化:模型参数已经具备基本的技术语言理解能力
- 稳定的表示空间:句子向量空间已经有一定的结构和规律
- 高效的知识迁移:可以快速适应第二阶段的对比学习
5.RetroMAE与标准BERT预训练的关键区别
|--------------|------------------|--------------------------|
| 方面 | 标准BERT (MLM) | RetroMAE |
| 训练目标 | 预测15%的掩码词 | 从高度残缺的文本重建完整句子 |
| 解码器 | 无独立解码器,直接使用编码器输出 | 独立的极简解码器 |
| 掩码策略 | 统一掩码率(15%) | 双重掩码率(轻度15-30%,重度80-90%) |
| 信息流 | 上下文到掩码位置 | 句子向量到所有掩码位置 |
| 能力侧重 | 词语级预测 | 句子级语义压缩与重建 |
| 对句子向量的影响 | 间接优化 | 直接且强制性的优化 |
6.为什么这种训练有效?
RetroMAE的训练可以类比为:
(1)"压缩-解压"测试
- 编码器:压缩专家,需要将句子压缩为紧凑的向量
- 解码器:解压新手,只能基于压缩包和少量提示进行解压
- 训练过程:如果解压效果差,说明压缩专家没有把关键信息放进压缩包
(2)"开卷-闭卷"考试
- 编码器学习阶段:在完整文本上"开卷学习"
- 解码器测试阶段:在高度掩码的文本上"闭卷考试"
- 能力验证:如果编码器学得好,就能帮助解码器通过考试
(3)"信息瓶颈"原理
- 解码器的信息输入被极度限制
- 编码器必须通过句子向量提供几乎所有必要信息
- 这迫使句子向量成为信息的"高效瓶颈"
通过这种训练,BGE的第一阶段获得了高质量的句子编码器,为后续的对比学习和指令微调奠定了坚实基础。编码器学会生成信息丰富、语义准确的句子向量,这些向量能够精确反映文本的语义内容,特别适合用于技术文档的检索和理解任务。
阶段二:有监督对比学习精调
这是BGE能力跃升的核心阶段,目标是从"理解语义"升级为"精准区分语义"。
1.数据
使用高质量的标注数据,如人工标注的语义相似度数据集、高质量的问答对等。
bash
# 人工标注的查询-文档对(正样本)
标注数据 = [
{
"查询": "如何解决Python中的内存泄漏?",
"正文档": "在Python中,内存泄漏通常由循环引用引起。使用gc模块可以检测和回收,或使用weakref避免强引用。",
"标注质量": "专家标注,5星"
},
{
"查询": "TensorFlow和PyTorch的主要区别",
"正文档": "TensorFlow使用静态计算图,部署友好;PyTorch使用动态图,更适合研究和快速原型开发。",
"标注质量": "专家标注,5星"
}
]
# 构建负样本池(技术文档库)
文档库 = [
"Python内存管理基于引用计数和垃圾回收机制...",
"循环引用发生在两个对象相互引用时...",
"TensorFlow 2.0引入了eager execution,使其更像PyTorch...",
"PyTorch由Facebook开发,广泛应用于学术研究...",
"内存泄漏在C++中更常见,因为需要手动管理内存...", # 相关但不完全匹配
"Java使用垃圾回收器自动管理内存...", # 部分相关
"Docker容器内存限制配置方法..." # 不相关
]2.核心技术:难负例挖掘
这是BGE区别于早期模型(如直接使用BERT句向量的)的关键。目标是找到那些与正样本"相似但不相关"的文本作为负样本,迫使模型学习精细的语义差别。
方法1:批量负例
在一个训练批次中,当前样本的正样本与其他所有样本的配对自然形成负例。这是最基本且高效的。
bash
批次 = [
(查询1, 正文档1), # Python内存泄漏
(查询2, 正文档2), # TensorFlow vs PyTorch
(查询3, 正文档3) # Docker网络配置
]
# 对于查询1,负例包括:
# 1. 查询2的正文档(完全不相关)
# 2. 查询3的正文档(完全不相关)
# 3. 自己查询的难负例(相关但不精准)方法2:全局难负例挖掘
- 使用一个初步训练好的模型或BM25等传统方法,为每个查询从海量语料库中检索出一批候选文档。
- 这些候选文档中,除了一个真正的正例,其余的都是"潜在负例"。其中那些与查询在主题、词汇上高度相关但语义不完全匹配的,就是"难负例"。
- 将这些难负例加入训练,模型必须学会区分"高度相关"和"完全匹配",从而学习到非常精细的语义边界。
例如,用第一阶段模型为查询"如何解决Python中的内存泄漏?"检索文档库:
bash
锚点(查询): "如何解决Python中的内存泄漏?"
正例: "在Python中,内存泄漏通常由循环引用引起..." (标注正样本)
负例集:
- "Python内存管理基于引用计数..." (难负例,相关但不精准)
- "循环引用发生在两个对象..." (难负例,概念相关但非解决方案)
- "Java使用垃圾回收器..." (随机负例)
- "Docker容器内存限制..." (随机负例)3.损失函数:InfoNCE Loss
这是对比学习的标准损失函数。其核心思想是:在向量空间中,拉近正样本对的向量距离,同时推远与所有负样本对的向量距离。其公式为:
其中,q是查询,p^+是正样本,p^-是负样本,sim是余弦相似度,τ是温度参数。
**通过第二阶段训练,**得到一个精准的技术文档检索器,例如能够:
- 为"Python内存泄漏"精确匹配解决方案文档,而非一般的内存管理文档
- 清楚区分TensorFlow和PyTorch的对比文档与各自的教程文档
阶段三:指令微调
1.核心思想
指令微调的核心是统一多任务学习。通过给模型添加"指令前缀",我们训练模型理解:"当看到这种指令时,请生成适合该任务的向量表示"。
关键思想:同一个文本,在不同任务下需要不同的向量表示。
例如:
- 用于检索的"批归一化"向量:应该靠近"优化技巧"类文档
- 用于相似度计算的"批归一化"向量:应该靠近"学习率衰减"的向量
- 用于分类的"批归一化"向量:应该靠近"深度学习训练技术"类别中心
2.训练数据
多任务数据混合,在输入文本前添加一个指令前缀。
bash
批次数据示例 = [
# 任务1: 检索任务
{
"指令": "为这个查询生成表示以用于检索相关技术文档:",
"文本": "如何优化深度神经网络的训练速度?",
"任务类型": "retrieval",
"正样本": "梯度累积、混合精度训练、数据预加载等方法可加速训练",
"负样本": ["PyTorch安装教程", "神经网络历史介绍", "激活函数对比"] # 批次内其他文本
},
# 任务2: 语义相似度任务
{
"指令": "为这两个句子生成表示以计算它们的语义相似度:",
"文本": "批归一化能加速训练收敛。##学习率衰减有助于找到更优解。",
"任务类型": "similarity",
"标签": 0.8 # 相似度分数(0-1)
},
# 任务3: 分类任务
{
"指令": "为这个技术问题生成表示以用于分类:",
"文本": "Kubernetes中Pod无法启动,显示ImagePullBackOff错误",
"任务类型": "classification",
"类别": "容器编排/故障排查"
},
# 任务4: 聚类任务
{
"指令": "为这篇技术文档生成表示以用于文档聚类:",
"文本": "React Hooks的设计哲学是让函数组件拥有类组件的能力...",
"任务类型": "clustering"
}
]3.正负样本构建策略
对于检索任务
- 正样本:查询 + 相关文档(如"如何优化训练速度" + "梯度累积方法介绍")
- 负样本 :
- 批次内负例:同一批次中其他查询的文档
- 难负例:与查询相关但不完全匹配的文档(如"神经网络基础理论")
对于相似度任务
- 正样本对:语义相似的句子对
- 负样本对:语义不相似的句子对
4.训练过程
模型输入格式:
bash
输入 = 指令 + 文本
例如:
检索任务输入:"为这个查询生成表示以用于检索相关技术文档:如何优化深度神经网络的训练速度?"
相似度任务输入:"为这两个句子生成表示以计算它们的语义相似度:批归一化能加速训练收敛。##学习率衰减有助于找到更优解。"训练目标:让模型学会根据指令调整其编码方式,使得:
- 相同指令下的相似内容产生相近的向量
- 不同指令下的相同内容产生不同的向量
- 向量表示对特定任务最优
5.损失函数设计
虽然任务是多样的,但都统一使用对比学习损失函数的变体InfoNCE Loss(多任务版本),对于批次中的每个样本 i :
其中:
:指令+文本的向量
- K :负样本数量
不同任务的损失计算:
检索任务损失
- 正样本:相关文档(有监督标注)
- 负样本:批次内其他文档 + 难负例
- 目标:查询向量靠近相关文档,远离不相关文档
相似度任务损失
- 构造三元组:锚点句子、正样本(相似句)、负样本(不相似句)
- 损失:L = \max(0, \text{sim}(锚点, 负样本) - \text{sim}(锚点, 正样本) + \alpha)
- 其中
分类任务损失(可选)
- 在向量空间中进行分类:使用交叉熵损失
- 但不是必须的,因为好的向量表示自然能分离不同类别
6.训练后的模型行为
(1)向量生成示例
bash
# 同一文本,不同指令下的不同向量
text = "批归一化能加速训练收敛"
vec_retrieval = model("为这个查询生成表示以用于检索相关技术文档:" + text)
# 偏向:优化技巧、训练加速、实践方法
vec_similarity = model("为这两个句子生成表示以计算它们的语义相似度:" + text)
# 偏向:技术原理、数学特性、理论解释
vec_classification = model("为这个技术问题生成表示以用于分类:" + text)
# 偏向:深度学习、训练技术、优化算法(2)零样本能力展示
即使训练时没有"代码查重"任务:
bash
# 使用相似度指令的变体
instruction = "为这两段代码生成表示以检测它们的逻辑相似性:"
code1_vec = model(instruction + code1)
code2_vec = model(instruction + code2)
# 模型能合理生成用于代码比对的向量经历指令微调后,得到一个通用的技术领域Embedding模型,能够:
- 通过改变指令适应不同下游任务
- 零样本处理训练中未见过的新任务类型
- 在技术问答、文档分类、代码分析等多种场景下表现良好
与传统多任务学习的区别:
|-----------|-------------|-----------------|
| 方面 | 传统多任务学习 | BGE指令微调 |
| 任务区分 | 不同任务有不同的输出头 | 所有任务共享同一个输出(向量) |
| 输入格式 | 任务ID或特定输入格式 | 自然语言指令 |
| 泛化能力 | 限于训练任务 | 可泛化到新的指令描述的任务 |
| 模型复杂度 | 需要多个输出层 | 单一输出层,更简洁 |
| 可解释性 | 低 | 高(指令本身解释了任务) |
三、BGE成功的设计哲学总结
- 深度而非广度优先 :不追求在训练初期就混合所有类型的数据,而是采用阶段性训练,先在弱监督数据上打基础,再在高质量数据上做精调,最后用指令统一接口。每一步目标明确。
- 面向目标优化 :其所有技术(尤其是难负例挖掘)都强烈指向其核心目标------提升检索精度。这让它在检索任务上表现一骑绝尘。
- 工程化数据闭环:深刻理解"数据决定上限,模型逼近上限"。在数据构建(弱监督对、高质量标注对、难负例挖掘)上投入巨大,形成了强大的数据飞轮。
- 简洁有效的接口设计 :通过指令微调这一巧妙设计,在不增加模型复杂度的前提下,极大地扩展了模型的适用范围和易用性。
总而言之,BGE的架构提供了一个强大的特征提取器,而其多阶段训练技术(特别是难负例挖掘和指令微调)则像一套精密的雕刻刀,将粗糙的语义理解能力,精细地打磨成了适用于实际任务(尤其是检索)的锋利工具。
四、BGE如何将一个不定长度的句子转换为固定长度的embedding向量?
1.分词与编码阶段
目标:将任意长度的文本转换为模型能理解的数字序列
具体步骤:
- 文本预处理:去除多余空格,Unicode标准化等。
- 分词 :使用预训练的WordPiece 或SentencePiece分词器将句子拆分为子词(subword)。
- 添加特殊标记 :
[CLS]:插入在序列开头(用于最终的句子表示)[SEP]:插入在序列结尾(表示序列结束)
- 转换为ID:将每个token映射到词汇表中的整数ID。
- 填充/截断 :统一为固定长度(如512个token),超出部分截断,不足部分填充
[PAD]。 - 创建注意力掩码 :标记哪些位置是真实token,哪些是填充的
[PAD]。
示例:
bash
句子 = "什么是Python的装饰器?"
# 分词结果(假设):
tokens = ["[CLS]", "什么", "是", "python", "的", "装饰", "器", "?", "[SEP]"]
# 转换为ID:
input_ids = [101, 1234, 2345, 3456, 4567, 5678, 6789, 7890, 102]
# 填充到最大长度512:
input_ids = input_ids + [0] * (512 - 9) # 0是[PAD]的ID
# 注意力掩码(1表示真实token,0表示[PAD]):
attention_mask = [1] * 9 + [0] * (512 - 9)2.模型前向传播阶段
目标:通过多层Transformer编码器获取每个token的上下文感知表示
具体过程:
bash
输入层 → 嵌入层 → 12/24层Transformer编码器 → 输出层
(词嵌入+位置嵌入+段落嵌入)(1)嵌入层
- 词嵌入:将每个token ID转换为稠密向量(维度如768/1024)
- 位置嵌入:添加位置信息(告诉模型每个token的位置)
- 段落嵌入:如果是双句输入,区分第一句和第二句
bash
# 例如,对"python"这个词:
token_embedding = Embedding(3456) # -> [0.1, -0.3, 0.5, ...] (768维)
position_embedding = PositionEmbedding(位置=4) # -> [0.2, 0.1, -0.1, ...]
final_embedding = token_embedding + position_embedding(2)Transformer编码器层处理
- 核心:自注意力机制让每个token能够关注序列中所有其他token
- 逐层传递:经过多个Transformer层(BGE-base:12层,BGE-large:24层)
- 每一层输出:每个token都会获得一个更新的向量表示
bash
# 经过第1层后:
layer1_output = TransformerLayer1(初始嵌入) # "python"的表示现在包含了"装饰器"的信息
# 经过第12层后:
layer12_output = TransformerLayer12(layer11_output) # "python"的表示现在包含了整个句子的上下文信息(3)最终输出
- 从最后一层Transformer获取所有token的表示
- 形状为:
[batch_size, sequence_length, hidden_size] - 例如:
[1, 512, 1024]表示1个句子,512个token,每个token1024维
3.池化阶段(关键步骤)
目标:将512个token的向量序列压缩为1个句子向量
BGE默认使用CLS池化策略:
bash
# 从最后一层输出中取出[CLS] token对应的向量
# 形状从 [1, 512, 1024] 变为 [1, 1024]
sentence_embedding = last_hidden_states[:,0,:] # 取第0个位置([CLS])为什么选择CLS token?
- BERT系列模型在预训练时,
[CLS]token被设计为汇聚整个序列信息的特殊token - 在MLM(掩码语言模型)任务中,
[CLS]参与所有token的预测 - 在NSP(下一句预测)任务中,
[CLS]直接用于分类 - 实践证明,取
[CLS]作为句子表示既高效又有效
4.归一化阶段
目标:将向量标准化,便于相似度计算
python
# L2归一化:使向量模长为1
def normalize(embeddings):
norm = torch.norm(embeddings, p=2, dim=1, keepdim=True)
return embeddings / norm.clamp(min=1e-8)
sentence_embedding = normalize(sentence_embedding)为什么需要归一化?
- 稳定训练:防止向量模长过大或过小导致梯度问题
- 高效检索 :归一化后,余弦相似度 = 点积(
cos(A,B) = A·B / (|A||B|) = A·B) - 统一量纲:所有向量都在同一尺度上比较