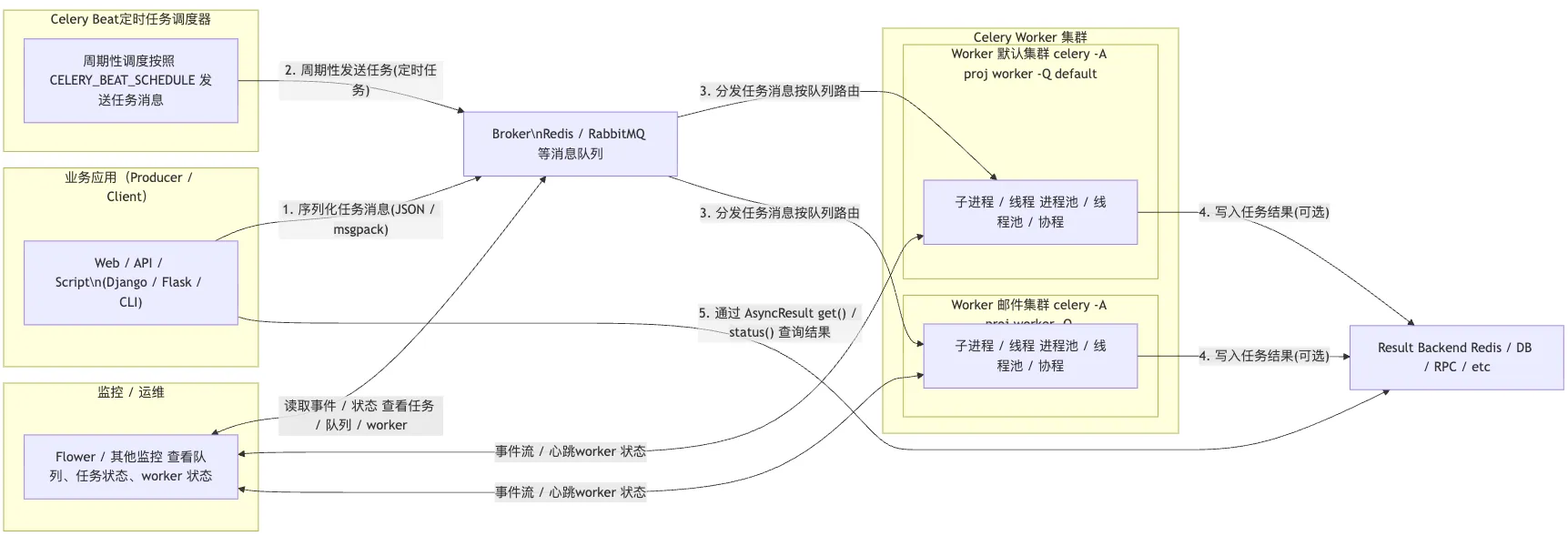
celery主要组件
1)broker消息代理
broker是 Celery 里概念,不是一个独立进程名。Redis、RabbitMQ、Kafka 等都可以是broker。当前示例使用 Redis,那Redis 服务器本身是broker 进程。
2)worker任务执行器
worker 是 Celery 的核心执行进程,属于 Celery 的组件。它负责"监控/消费 broker 队列"和执行任务,而 broker 本身只是外部的消息服务。
主动、持续地轮询(polling)Redis队列
从队列中取出(pop)任务消息
执行任务逻辑
将结果存储回Redis,配置了结果后端情况
构成整个任务流转系统需要以下功能:
1)task任务定义,把实际执行的任务行为定义出来
绑定任务到celery框架
python
@celery_app.task(bind=True)
def process_document(self, document_id: str, content: str) -> Dict[str, Any]:
"""处理文档任务"""
logger.info(f"处理文档: {document_id}")
# sleep 替代实际任务逻辑
time.sleep(2)
return {
"task_id": self.request.id,
"document_id": document_id,
"status": "completed",
"processed_content": f"已处理: {content[:100]}...",
}2)定义celery配置,实例化celery
python
from celery import Celery
from .config import get_celery_config
def get_celery_config() -> Dict[str, Any]:
"""获取 Celery 配置"""
return {
# Redis 作为消息代理
"broker_url": os.getenv("CELERY_BROKER_URL", "redis://localhost:6379/0"),
# Redis 作为结果后端
"result_backend": os.getenv("CELERY_RESULT_BACKEND", "redis://localhost:6379/0"),
# 任务序列化方式
"task_serializer": "json",
"result_serializer": "json",
"accept_content": ["json"],
# 时区设置
"timezone": "Asia/Shanghai",
# 任务结果过期时间(秒)
"result_expires": 3600,
# 任务执行超时时间(秒)
"task_time_limit": 300,
# 任务软超时时间(秒)
"task_soft_time_limit": 240,
# 工作进程数
"worker_concurrency": int(os.getenv("CELERY_WORKER_CONCURRENCY", "4")),
# 任务确认机制
"task_acks_late": True,
# 任务拒绝后重新入队
"task_reject_on_worker_lost": True,
# 任务发送事件
"worker_send_task_events": True,
# 任务预取数量
"worker_prefetch_multiplier": int(os.getenv("CELERY_PREFETCH_MULTIPLIER", "1")),
# 优雅关闭超时时间
"worker_max_tasks_per_child": int(os.getenv("CELERY_MAX_TASKS_PER_CHILD", "1000")),
# 心跳间隔
"broker_heartbeat": 0,
}
# 创建 Celery 应用
celery_app = Celery("ragdemo_tasks")
# 配置 Celery
celery_app.config_from_object(get_celery_config())
# 自动发现任务
celery_app.autodiscover_tasks(["task"])目录结构
python
task/
├── __init__.py # 模块包初始化
└── celery_app.py # 核心Celery模块启动任务管理,执行
python
uv run celery -A task.celery_app worker --loglevel=INFO --concurrency=4-
任务消息存储组件搭建
当前使用的redis作为中间消息、执行结果存储组件。# Redis 作为消息代理broker "broker_url": os.getenv("CELERY_BROKER_URL", "redis://localhost:6379/0"), # Redis 作为结果后端backend "result_backend": os.getenv("CELERY_RESULT_BACKEND", "redis://localhost:6379/0"),
4)任务调用触发
在外部引入celery task任务定义的模块,调用函数
python
# task_id = process_document.delay(data) 简化函数
task = process_document.apply_async(args=[document_id, content], queue='celery')
logger.info(f"提交文档任务: {task.id}")- delay() 是 .apply_async() 的快捷方式,参数更简单
- apply_async() 支持更多配置:队列选择、延迟执行、重试策略等
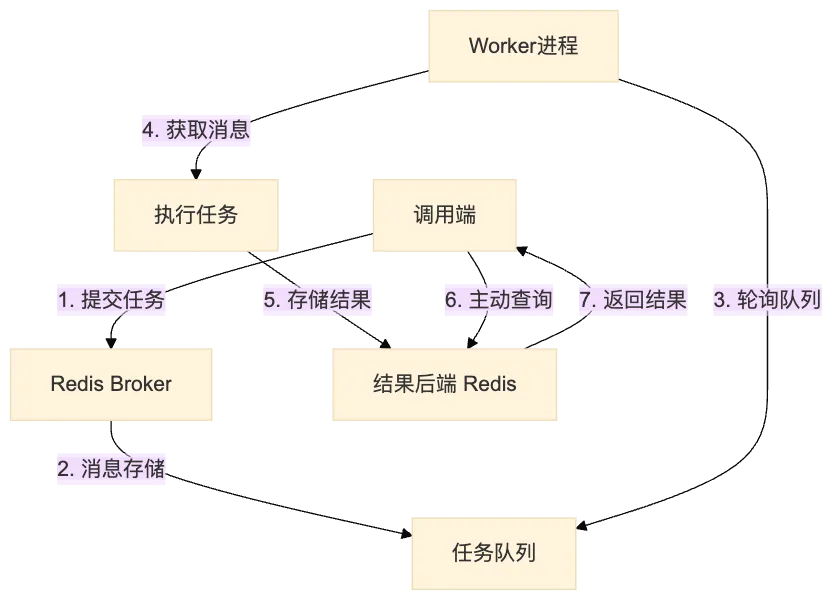
任务调用与结果获取
1)任务调用、提交:
python
result = process_document.delay(data) # 立即返回AsyncResult对象
# 或 result = process_document.apply_async(args=[data]) # 同样返回AsyncResult - AsyncResult对象
- 包含任务ID和状态信息
- 不包含实际结果数据
- 不自动轮询或监控任务完成
- 结果获取需要显式操作
方式一:主动轮询(推荐)
python
result = process_document.delay(data)
# 需要手动检查
while not result.ready():
time.sleep(0.5)
# 获取结果
data = result.get(timeout=10) 方式二:阻塞等待
python
# 这会阻塞当前线程直到任务完成
data = result.get() # 可能无限期等待 方式三:回调函数(异步)
python
result = process_document.apply_async(
args=[data],
link=on_success.s() # 任务完成后的回调
) 
Celery 任务状态机制
Celery 会自动处理任务状态的更新。
工作原理
- 自动状态管理 :当你的任务函数(如 process_document )执行完成并返回结果时,Celery 会自动将任务状态更新为 SUCCESS ,并将返回值存储到 result_backend (这里是 Redis)。
2)状态流转:
python
PENDING → STARTED → SUCCESS/FAILURE- PENDING :任务已提交,等待执行
- STARTED :Worker 开始执行任务(需要 task_track_started=True )
- SUCCESS :任务成功完成(自动设置)
- FAILURE :任务执行出错(自动设置)
代码中返回的字典:
python
return {
"task_id": self.request.id,
"document_id": document_id,
"status": "completed",
"processed_content": f"已处理: {path}",
}这个返回值会被存储为任务的 result(结果),而不是任务的 status(状态)
status:Celery 自动管理(PENDING/STARTED/SUCCESS/FAILURE)
result:返回值,通过 AsyncResult.result 获取
调用端通过 AsyncResult 检查状态:
python
result = AsyncResult(task_id, app=celery_app)
# 检查Celery自动管理的状态
result.status # 'SUCCESS', 'FAILURE', 'PENDING' 等
# 检查是否完成
result.ready() # True/False
# 获取你返回的结果
result.result # 你返回的字典关键配置
配置中有这一行:
python
"result_backend": os.getenv("CELERY_RESULT_BACKEND", "redis://localhost:6379/0"),这个 result_backend 就是用来存储任务状态和结果的。如果没有配置 result_backend,调用端确实无法知道任务是否完成,因为没有地方存储这些信息。
使用celery 调用mineru文档解析出错: daemonic processes are not allowed to have children。
问题原因
这个错误是因为 Celery worker 进程是守护进程(daemon),而 MinerU 的文档解析器内部可能使用了多进程(multiprocessing)来处理文档,Python 不允许守护进程创建子进程。这是一个常见的 Celery + 多进程库的兼容性问题。
解决方案:修改 Celery worker 配置使用 solo 池或 threads 池
最简单有效的方案是修改 worker 启动参数,使用 --pool=solo 或 --pool=threads ,这样就不会有 daemon 进程的限制。
配置中添加 solo 池设置
python
# 工作进程数(使用solo池时此配置无效)
"worker_concurrency": int(os.getenv("CELERY_WORKER_CONCURRENCY", "1")),
# 使用solo池,避免daemon进程不能创建子进程的问题
"worker_pool": "solo",Worker 启动参数使用 --pool=solo
python
worker_args = [
'worker',
'--loglevel=INFO',
'--pool=solo', # 使用solo池,支持任务内部多进程
'--queues=celery',
'--without-gossip',
'--without-mingle',
'--without-heartbeat',
]- solo 池是单线程模式,每次只处理一个任务
- 它允许任务内部使用多进程,因为 worker 进程不是以 daemon 模式运行
- 需要并发处理多个文档,可以启动多个 worker 实例
重启 Worker
修改后需要重启 Celery worker 才能生效:
python
# 停止当前 worker,然后重新启动
celery -A task.celery_app worker --loglevel=INFO --pool=solo--pool=solo vs --pool=threads 的区别
| 池类型 | 并发任务 | 任务内使用 multiprocessing | 适用场景 |
|---|---|---|---|
| solo | 单任务 | 支持 | CPU密集型任务,需要内部多进程 |
| threads | 多任务 | 受GIL限制 | I/O密集型任务 |
| prefork | 多任务 | daemon进程限制 | 默认模式 |
关于 --pool=threads
不推荐用于 MinerU 场景,原因是:
- GIL 限制:Python 的全局解释器锁(GIL)会限制多线程的真正并行执行
- multiprocessing 兼容性问题:虽然 threads 池的 worker 不是 daemon,但在多线程环境下使用 multiprocessing 可能会遇到:
- 资源竞争问题
- 死锁风险
- 线程安全问题
推荐方案
如果需要并行处理多个文档,更好的方案是启动多个 solo 模式的 worker 实例。
--pool=threads 不适合 MinerU 这种内部使用 multiprocessing 的任务,原因:
线程池受 Python GIL 限制
多线程 + multiprocessing 混用容易出问题
启动多个 solo 模式的 worker 实例:
python
# 启动多个worker(每个worker一个独立进程,每个worker内部可以使用multiprocessing)
```python
celery -A task.celery_app worker --loglevel=INFO --pool=solo -n worker1@%h &
celery -A task.celery_app worker --loglevel=INFO --pool=solo -n worker2@%h &
celery -A task.celery_app worker --loglevel=INFO --pool=solo -n worker3@%h &- 每个 worker 可以独立处理一个文档
- 每个任务内部的 multiprocessing 正常工作
- 多个文档可以并行处理(由多个 worker 分别处理)
- 避免了线程安全和 daemon 进程的问题