强化学习算法-DQN代码
1、DQN关键部件
DQN公式
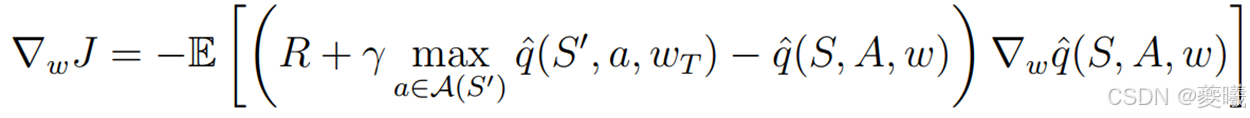
两个技巧
神经网络(两个网络:目标网络、主网络)、经验回放
2、DQN代码
以gym中的车杆CartPole-v1为例,环境设置从gym中获取,只需关注算法本身。
该环境存在四种状态:车位置(Cart Position) 、车速(Cart Velocity) 、杆子的角度(Pole Angle) 、角速度(Pole Angular Velocity),两种动作:0向左、1向右
网络模块:
py
import torch
import torch.nn as nn
class QNetwork(nn.Module):
"""
输入: state, shape = [batch, obs_dim]
输出: q_values, shape = [batch, act_dim]
"""
def __init__(self, obs_dim: int, act_dim: int, hidden_dim: int = 128):
super().__init__()
self.net = nn.Sequential(
nn.Linear(obs_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, act_dim),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
return self.net(x)经验池模块:
py
from __future__ import annotations
from dataclasses import dataclass
from typing import Dict
import numpy as np
import torch
@dataclass
class ReplayBatch:
obs: torch.Tensor # [B, obs_dim] float32
actions: torch.Tensor # [B, 1] int64
rewards: torch.Tensor # [B, 1] float32
next_obs: torch.Tensor # [B, obs_dim] float32
dones: torch.Tensor # [B, 1] float32 (0.0 or 1.0)
class ReplayBuffer:
"""
经典 DQN replay buffer(循环数组实现)
- obs/next_obs: float32
- action: int64
- reward: float32
- done: float32 (0/1)
"""
def __init__(self, obs_dim: int, capacity: int = 100_000):
self.capacity = int(capacity)
self.obs_dim = int(obs_dim)
self.obs = np.zeros((self.capacity, self.obs_dim), dtype=np.float32)
self.next_obs = np.zeros((self.capacity, self.obs_dim), dtype=np.float32)
self.actions = np.zeros((self.capacity, 1), dtype=np.int64)
self.rewards = np.zeros((self.capacity, 1), dtype=np.float32)
self.dones = np.zeros((self.capacity, 1), dtype=np.float32)
self._size = 0
self._ptr = 0
def __len__(self) -> int:
return self._size
def add(self, obs, action: int, reward: float, next_obs, done: bool) -> None:
i = self._ptr
self.obs[i] = np.asarray(obs, dtype=np.float32)
self.next_obs[i] = np.asarray(next_obs, dtype=np.float32)
self.actions[i, 0] = int(action)
self.rewards[i, 0] = float(reward)
self.dones[i, 0] = 1.0 if done else 0.0
self._ptr = (self._ptr + 1) % self.capacity
self._size = min(self._size + 1, self.capacity)
def sample(self, batch_size: int, device: str | torch.device = "cpu") -> ReplayBatch:
if self._size == 0:
raise ValueError("ReplayBuffer is empty. Add some transitions before sampling.")
batch_size = int(batch_size)
idx = np.random.randint(0, self._size, size=batch_size)
obs = torch.as_tensor(self.obs[idx], device=device)
actions = torch.as_tensor(self.actions[idx], device=device)
rewards = torch.as_tensor(self.rewards[idx], device=device)
next_obs = torch.as_tensor(self.next_obs[idx], device=device)
dones = torch.as_tensor(self.dones[idx], device=device)
# obs/reward/done 已经是 float32,actions 是 int64,shape 都是 [B, ...]
return ReplayBatch(obs=obs, actions=actions, rewards=rewards, next_obs=next_obs, dones=dones)主代码:
py
import time
import numpy as np
import gymnasium as gym
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.tensorboard import SummaryWriter
from network import QNetwork # dqn / double_dqn 共用同一份网络代码
from network import QNetwork_duel # dueling_dqn 专用网络
from buffer import ReplayBuffer
def linear_epsilon(step: int, eps_start: float, eps_end: float, eps_decay_steps: int) -> float:
"""线性衰减 epsilon:从 eps_start 逐步降到 eps_end 后保持"""
frac = max(0.0, 1.0 - step / float(eps_decay_steps))
return eps_end + (eps_start - eps_end) * frac
def main():
enable_render = False # 训练时建议 False;想看画面再 True(会变慢)
# ======================
# 1) 创建环境
# ======================
env = gym.make("CartPole-v1", render_mode="human" if enable_render else None)
obs, _ = env.reset()
obs_dim = env.observation_space.shape[0] # CartPole: 4
act_dim = env.action_space.n # CartPole: 2
device = torch.device("cpu")
# ======================
# 2) TensorBoard
# ======================
run_name = time.strftime("dueling_dqn_cartpole_%Y%m%d_%H%M%S")
writer = SummaryWriter(log_dir=f"D:/Users/00807933/Desktop/None2e/none2e_code/RL-note/RL1226/dqn_cartpole/runs/{run_name}")
# ======================
# 3) Q 网络 & Target 网络
# ======================
#q_net = QNetwork(obs_dim, act_dim).to(device)
#q_target = QNetwork(obs_dim, act_dim).to(device)
q_net = QNetwork_duel(obs_dim, act_dim).to(device) # QNetwork_duel
q_target = QNetwork_duel(obs_dim, act_dim).to(device)
# 一开始 target = online
q_target.load_state_dict(q_net.state_dict())
q_target.eval() # target 只 forward,不训练
# ======================
# 4) 优化器 & 损失
# ======================
optimizer = optim.Adam(q_net.parameters(), lr=1e-4)
criterion = nn.SmoothL1Loss() # Huber loss,更稳
# ======================
# 5) Replay Buffer
# ======================
buffer = ReplayBuffer(obs_dim=obs_dim, capacity=50_000)
# ======================
# 6) 超参数
# ======================
gamma = 0.99
batch_size = 64
warmup_steps = 500 #1_000 # 经验池热身:够多了再开始学
total_steps = 100_000
target_update_freq = 500 # 1_000 # 每隔多少 step 同步一次 target
# ε-greedy
eps_start = 1.0 # 初始 epsilon
eps_end = 0.05 # 最终 epsilon
eps_decay_steps = 10_000 # 30_000 # 线性衰减多少 step 到 eps_end
# 可选:梯度裁剪(更稳)
max_grad_norm = 10.0
# ======================
# 7) 训练状态变量
# ======================
step_count = 0
episode_idx = 0
episode_reward = 0.0
# ======================
# 8) 主循环(按 step)
# ======================
while step_count < total_steps:
step_count += 1
# -------- 8.1 计算 epsilon & 选动作(ε-greedy)--------
eps = linear_epsilon(step_count, eps_start, eps_end, eps_decay_steps)
if np.random.rand() < eps:
action = env.action_space.sample()
else:
with torch.no_grad():
x = torch.tensor(obs, dtype=torch.float32, device=device).unsqueeze(0) # [1, obs_dim]
q_values = q_net(x) # [1, act_dim]
action = int(torch.argmax(q_values, dim=1).item())
# -------- 8.2 环境一步 --------
next_obs, reward, terminated, truncated, _ = env.step(action)
done = terminated or truncated
if enable_render:
env.render()
# 存入经验池
buffer.add(obs, action, reward, next_obs, done)
obs = next_obs
episode_reward += reward
# -------- 8.3 episode 结束:打点、打印、reset --------
if done:
episode_idx += 1
ep_r = episode_reward
writer.add_scalar("charts/episode_reward", ep_r, step_count)
writer.add_scalar("charts/epsilon", eps, step_count)
writer.add_scalar("charts/buffer_size", len(buffer), step_count)
print(f"[DQN] step={step_count}, episode={episode_idx}, ep_reward={ep_r:.1f}, eps={eps:.3f}")
obs, _ = env.reset()
episode_reward = 0.0
# -------- 8.4 DQN 更新(TD learning)--------
if len(buffer) >= warmup_steps:
batch = buffer.sample(batch_size, device=device) # 均匀随机采样
# Q(s,a):从 Q(s,·) 里按 action gather 出对应列
# q_net(batch.obs): [B, act_dim], batch.actions: [B,1]
q_sa = q_net(batch.obs).gather(1, batch.actions) # [B,1]
# ===== Vanilla DQN 的 target =====
# y = r + γ(1-done) * max_a' Q_target(s',a')
#with torch.no_grad():
# q_next_max = q_target(batch.next_obs).max(dim=1, keepdim=True)[0] # [B,1]
# target = batch.rewards + gamma * (1.0 - batch.dones) * q_next_max # [B,1]
# ===== Double DQN 的 target =====
# 1) online 选动作:a* = argmax_a Q_online(s', a)
# 2) target 评估动作:Q_target(s', a*)
with torch.no_grad():
next_actions = q_net(batch.next_obs).argmax(dim=1, keepdim=True) # [B,1]
q_next = q_target(batch.next_obs).gather(1, next_actions) # [B,1]
target = batch.rewards + gamma * (1.0 - batch.dones) * q_next # [B,1]
loss = criterion(q_sa, target)
optimizer.zero_grad()
loss.backward()
torch.nn.utils.clip_grad_norm_(q_net.parameters(), max_grad_norm)
optimizer.step()
# TensorBoard:loss / Q值统计
writer.add_scalar("loss/td_loss", loss.item(), step_count)
writer.add_scalar("debug/q_sa_mean", q_sa.mean().item(), step_count)
writer.add_scalar("debug/target_mean", target.mean().item(), step_count)
# -------- 8.5 同步 target 网络 --------
if step_count % target_update_freq == 0:
q_target.load_state_dict(q_net.state_dict())
writer.close()
env.close()
if __name__ == "__main__":
main()