本笔记仅为个人的理解,如果有误欢迎指出
Kinect Programming with Direct3D 11 用DX11在Kinect编程
这篇文章,比起技术性文档,更像是一篇Kinect的说明文,价值不高
Kinect :
Kinect是微软公司开发的体感外设,名称由"kinetics"(动力学)与"connection"(连接)组合而成,开发代号"Natal"。它于2009年6月在E3展首次亮相,2010年11月正式发售,支持Xbox 360及Xbox One主机。通过3D摄像、动态捕捉和语音识别技术,Kinect实现无控制器交互,用户可通过肢体动作和语音指令操控游戏。并荣获吉尼斯"最快销售消费电子设备"世界纪录。其核心技术包括骨骼追踪、面部识别等,并拓展应用于医疗康复、3D建模及科研领域。

Kinect 三个功能:
1, 颜色相机:
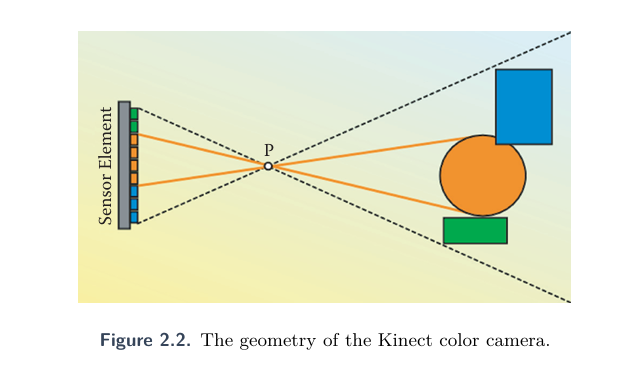
和传送摄像头一样,可见光进入相机镜头照射到感光元件上,生成视频流。采用的针孔相机模型。分辨率范围1280 X 960 到 80 X 60,数据格式为sRGB和YUY格式
2, 深度相机:
Kinect的深度感知系统主要使用了一个红外投影仪和一个红外相机,两个相机叠加后的到如下图(红色那张),这里计算深度的原理并没有细说,文章的意思是通过图像的扭曲推断每个像素的深度。

红外发射器与红外相机存在偏移,它们各自能"看到"的场景部分略有不同。所以有部分黑色的区域获取不了深度信息。

每个像素一个通道保存深度值,剩下三个通道用于保存下一个模块生成的玩家ID,可用的分辨率包括 640 × 480 、320×240 或 80×60.
3, 骨架追踪
骨架追踪是Kinect最大的进步,利用了前面的传感系统,分析深度相机每一帧的每个像素,再应用决策树算法来判断当前像素最可能是人体的哪个部分。
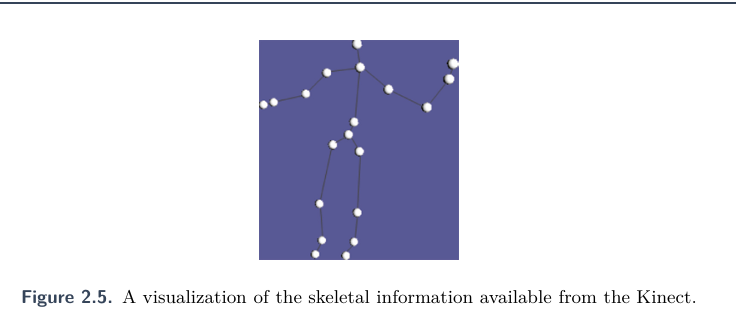
图是计算生成的骨骼信息
Kinect 中的数学原理:
1,针孔相机模型
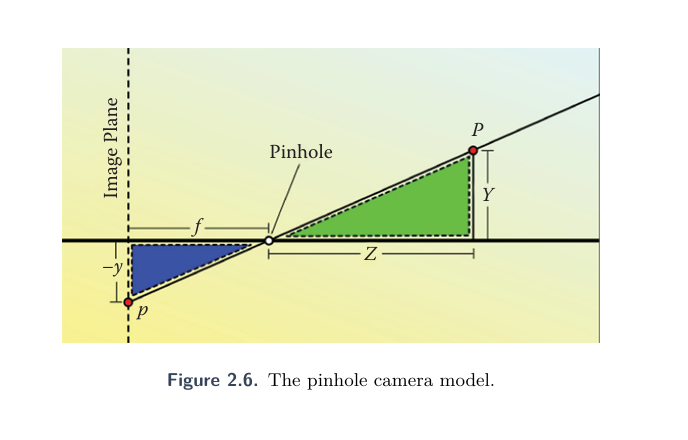
简单来说就是物体透过单一点投射到图像传感器的示意图,利用三角形的相似确定P点投影的二维坐标
2.Kinect坐标系系统
由于深度图的原因,Kinect能够计算出像素点的三维坐标,从而生成观测场景的三维表示。
参考资料: