一、MySQL架构分层解析
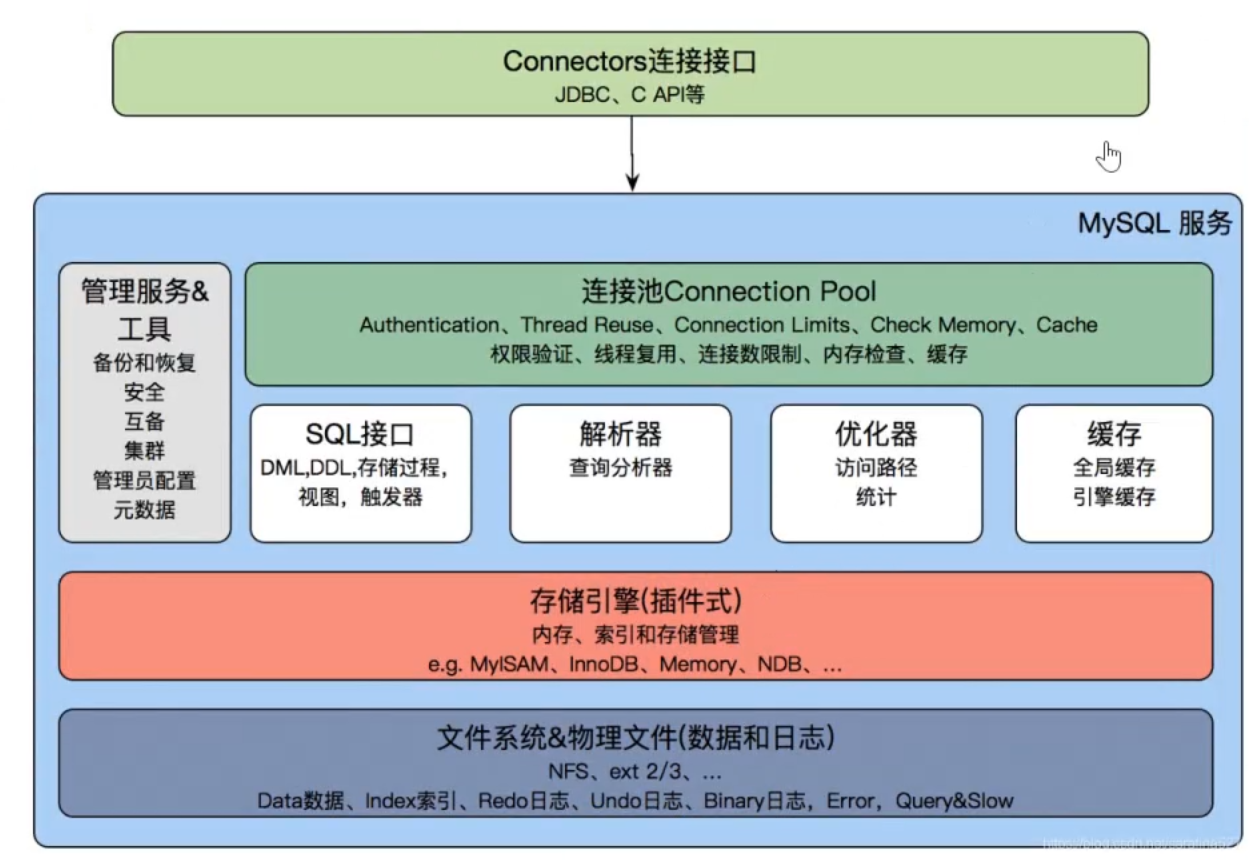
1. Connectors 连接接口层
- 作用:提供不同编程语言 / 工具与 MySQL 服务的通信能力,是客户端和 MySQL 服务之间的桥梁。
- 常见接口:JDBC(Java)、C API、Python Connector、ODBC 等。
- 面试考点:了解不同语言的连接方式,以及连接时的认证流程。
2. MySQL 服务层(核心层)
这是 MySQL 的大脑,负责处理客户端请求、SQL 解析优化、管理连接和提供工具服务。
🔹 管理服务 & 工具
- 功能:提供数据库运维相关的核心能力,包括备份恢复、安全管理、主备 / 集群管理、元数据维护、管理员配置等。
- 面试考点 :常问备份恢复工具(如
mysqldump)、主从复制原理、权限管理机制。
🔹 连接池(Connection Pool)
- 核心作用:高效管理客户端连接,避免频繁创建 / 销毁线程的性能开销。
- 关键特性 :
- Authentication:用户身份验证与权限校验
- Thread Reuse:线程复用(核心性能优化点)
- Connection Limits:连接数限制(防止资源耗尽)
- Check Memory / Cache:内存检查与连接级缓存
- 面试考点 :连接池的作用、线程复用的好处,以及
wait_timeout、max_connections等关键参数。
🔹 SQL 接口
- 功能:接收客户端发送的 SQL 语句,支持 DML(增删改查)、DDL(建表等)、存储过程、视图、触发器等。
- 面试考点:区分 DML/DDL/DCL,以及存储过程和触发器的使用场景与优缺点。
🔹 解析器(Parser)
- 功能:对 SQL 进行词法分析和语法分析,生成解析树(Parse Tree)。如果 SQL 语法错误,会在这里直接报错。
- 面试考点:SQL 解析的基本流程,以及常见的语法错误场景。
🔹 优化器(Optimizer)
- 功能:基于解析树生成最优执行计划,通过统计信息选择代价最低的访问路径(如全表扫描 vs 索引扫描)。
- 面试考点 :优化器的工作原理、索引失效场景、如何通过
EXPLAIN分析执行计划。
🔹 缓存(Cache)
- 功能:缓存 SQL 语句及其结果,相同查询可直接返回缓存结果,提升性能。
- 注意 :MySQL 8.0 已移除查询缓存(Query Cache),因为在高并发场景下缓存失效和锁冲突的代价过高。现在更多依赖 引擎缓存(如 InnoDB 的缓冲池)和业务层缓存(如 Redis)。
- 面试考点:查询缓存的优缺点,以及为什么在新版本中被废弃。
3. 存储引擎层(插件式设计)
- 核心特点:MySQL 采用插件式存储引擎架构,允许为不同表选择不同的存储引擎,以适配不同的业务场景。
- 常见引擎 :
- InnoDB:默认引擎,支持事务、行级锁、外键、崩溃恢复,适合高并发、数据一致性要求高的场景。
- MyISAM:不支持事务和行锁,查询速度快,适合只读或低并发的统计类场景(已逐渐被淘汰)。
- Memory:数据存储在内存中,速度极快,但重启后数据丢失,适合临时表或缓存场景。
- 面试考点:InnoDB 与 MyISAM 的核心区别、InnoDB 的事务隔离级别、MVCC 实现原理。
4. 文件系统 & 物理文件层
- 作用:将数据库的数据、索引、日志等持久化到磁盘文件中。
- 常见文件类型 :
- 数据文件 :
.ibd(InnoDB 表空间文件)、.MYD(MyISAM 数据文件) - 索引文件 :
.MYI(MyISAM 索引文件) - 日志文件:Redo Log(崩溃恢复)、Undo Log(事务回滚)、Binary Log(主从复制、增量备份)、Slow Query Log(慢查询分析)
- 数据文件 :
- 面试考点:Redo Log 与 Binlog 的区别、InnoDB 刷盘机制、慢查询日志的作用与分析。
💡 面试高频串联问题
- 一条 SQL 查询的完整执行流程:客户端 → Connectors → 连接池认证 → SQL 接口 → 解析器 → 优化器 → 执行器 → 存储引擎 → 文件系统 → 返回结果。
- 为什么 InnoDB 是默认引擎:支持事务、行级锁、崩溃恢复,更适合现代互联网高并发、强一致性的业务场景。
- 连接池的性能优化意义:避免频繁创建和销毁线程的开销,通过线程复用和连接数限制,提升系统稳定性和响应速度。
二、MySQL 基础操作实验笔记
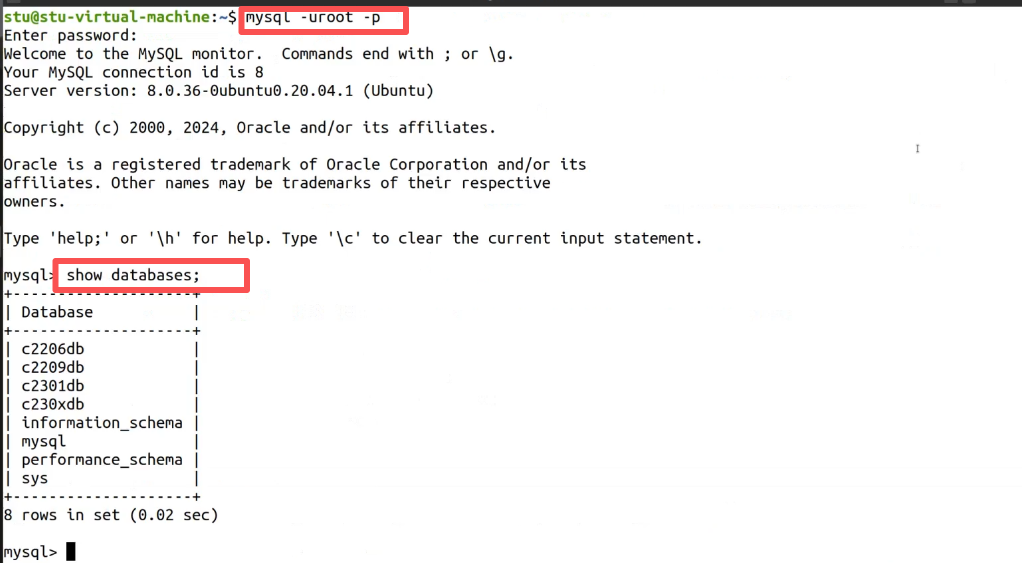
1. 登录 MySQL 服务器
命令
mysql -uroot -p解释
mysql:调用 MySQL 客户端程序-uroot:使用root用户登录(-u后面跟用户名)-p:表示需要输入密码(密码不会明文显示,输入后按回车即可)- 执行后出现
mysql>提示符,说明成功进入 MySQL 交互环境
2. 查看所有数据库
命令
show databases;解释
- 这是一条 SQL 命令,必须以分号
;结尾 - 作用:列出当前 MySQL 服务器上所有的数据库,包括系统自带的库(如
information_schema、mysql、performance_schema、sys)和用户创建的库(如c2206db、c2209db) - 执行后会显示数据库列表和记录数
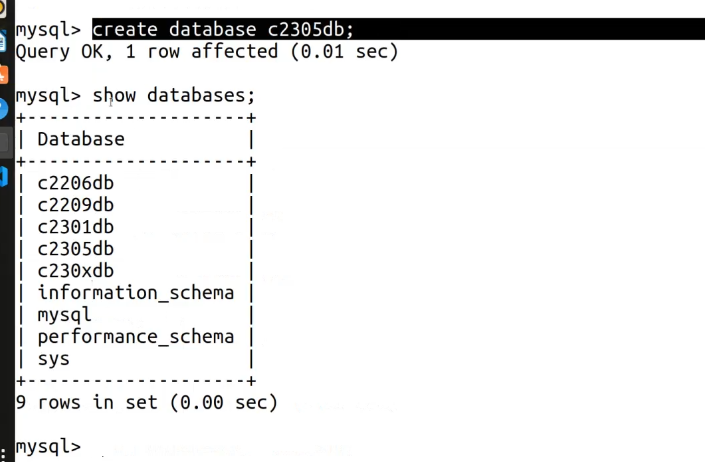
3.创建数据库,并查看历史数据库
①创建数据库命令
create database c2305db;解释
-
create database:这是 MySQL 中创建数据库的关键字组合。 -
c2305db:是你要创建的数据库名称,需要符合 MySQL 命名规则(不能包含特殊字符,不能与现有库名重复)。 -
执行结果 :
plaintext
Query OK, 1 row affected (0.01 sec)Query OK:表示命令执行成功,没有语法或逻辑错误。1 row affected:表示这个操作影响了 1 条 "元数据记录"(即新增了一个数据库的信息)。0.01 sec:是这条命令的执行耗时。
②查看所有数据库(验证创建结果)
命令
show databases;解释
-
这条命令会列出当前 MySQL 服务器上所有的数据库,包括系统默认库和你刚刚创建的用户库。
-
执行结果分析 :
plaintext
+--------------------+ | Database | +--------------------+ | c2206db | | c2209db | | c2301db | | c2305db | ← 你刚刚创建的数据库,已出现在列表中 | c230xdb | | information_schema | | mysql | | performance_schema | | sys | +--------------------+ 9 rows in set (0.00 sec)9 rows in set:现在总共有 9 个数据库,比之前的 8 个多了 1 个,正好对应你新创建的c2305db。- 这一步的作用是验证创建操作是否成功,确保新数据库已经被正确添加到服务器中。
4.进入我们创建的数据库中
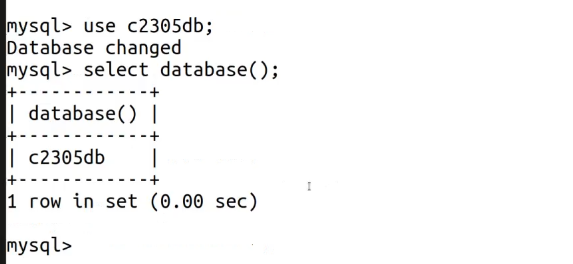
命令
use c2305db;解释
-
use是 MySQL 中切换数据库的关键字。 -
c2305db是你要切换到的目标数据库名称。 -
执行结果 :
plaintext
Database changed这个提示表示你已经成功切换到
c2305db数据库,后续所有的表操作(如创建表、插入数据)都会在这个库中进行。
类比理解(结合下方示意图)
这就好比你从 "仓库大厅" 走进了标有 c2305db 的 "一区仓库",接下来的所有操作都将在这个 "仓库" 里完成。
5. 验证当前所在数据库
命令
select database();解释
-
select database()是一个内置函数,用于查询当前正在使用的数据库。 -
执行结果 :
plaintext
+------------+ | database() | +------------+ | c2305db | +------------+ 1 row in set (0.00 sec)这个结果确认了你当前确实处于
c2305db数据库中,确保后续操作不会跑错库。
🔍 关键注意事项
- 切换库的必要性 :在创建表或插入数据前,必须先通过
use命令切换到目标数据库,否则会报错No database selected。 - 快速验证 :
select database()是一个非常实用的命令,尤其是在操作多个数据库时,能帮你快速确认当前位置,避免误操作。 - 无库切换限制 :你可以随时用
use命令在不同数据库之间切换,无需额外权限(只要你对目标库有访问权限)。
三、数据库分类
1. 关系型数据库(RDBMS)
- 定义:采用关系模型(二维表格模型)组织数据,由表和表之间的联系构成。
- 核心元素:数据行(记录)、数据列(字段)、数据表(行的集合)、数据库(表的集合)。
- 遵循原则:ACID 原则(原子性、一致性、隔离性、持久性)。
- 常见产品:Oracle、MySQL、SQLite、DB2、Microsoft SQL Server。
2. 非关系型数据库(NoSQL)
- 定义:非关系型、分布式存储系统,一般不保证遵循 ACID 原则,以键值对存储,结构不固定。
- 适用场景:高并发读写、海量数据存储、范围查询(如 "以我为半径周围有多少滴滴司机" 这类地理位置场景)。
- 常见产品:Memcache、Redis、MongoDB、HBase。
四、MySQL 服务管理
1. 检查服务状态
bash
# 方式1
service mysql status
# 方式2
systemctl status mysql.service- 输出中
Active: active (running)表示服务正在运行。
2. 启动、停止、重启服务
bash
# 方式1:使用 service 命令
service mysql start # 启动
service mysql stop # 停止
service mysql restart # 重启
# 方式2:使用 init.d 脚本
/etc/init.d/mysql start
/etc/init.d/mysql stop
/etc/init.d/mysql restart- 普通用户执行需在命令前加
sudo获取管理员权限。
五、MySQL 连接与退出
1. 连接数据库
mysql -uroot -p-u:指定用户名(示例中为root)。-p:表示需要输入密码(输入时不显示明文)。- 成功连接后进入交互模式,提示符为
mysql>。
2. 退出数据库
quit;
# 或
exit;六、MySQL 配置文件
1. 配置文件位置
vi /etc/mysql/mysql.conf.d/mysqld.cnf2. 常见配置修改
- 允许远程连接 :将
bind-address = 127.0.0.1改为bind-address = 0.0.0.0,使 MySQL 监听所有网卡。 - 其他配置:端口、字符集、日志路径等也可在此文件中调整。