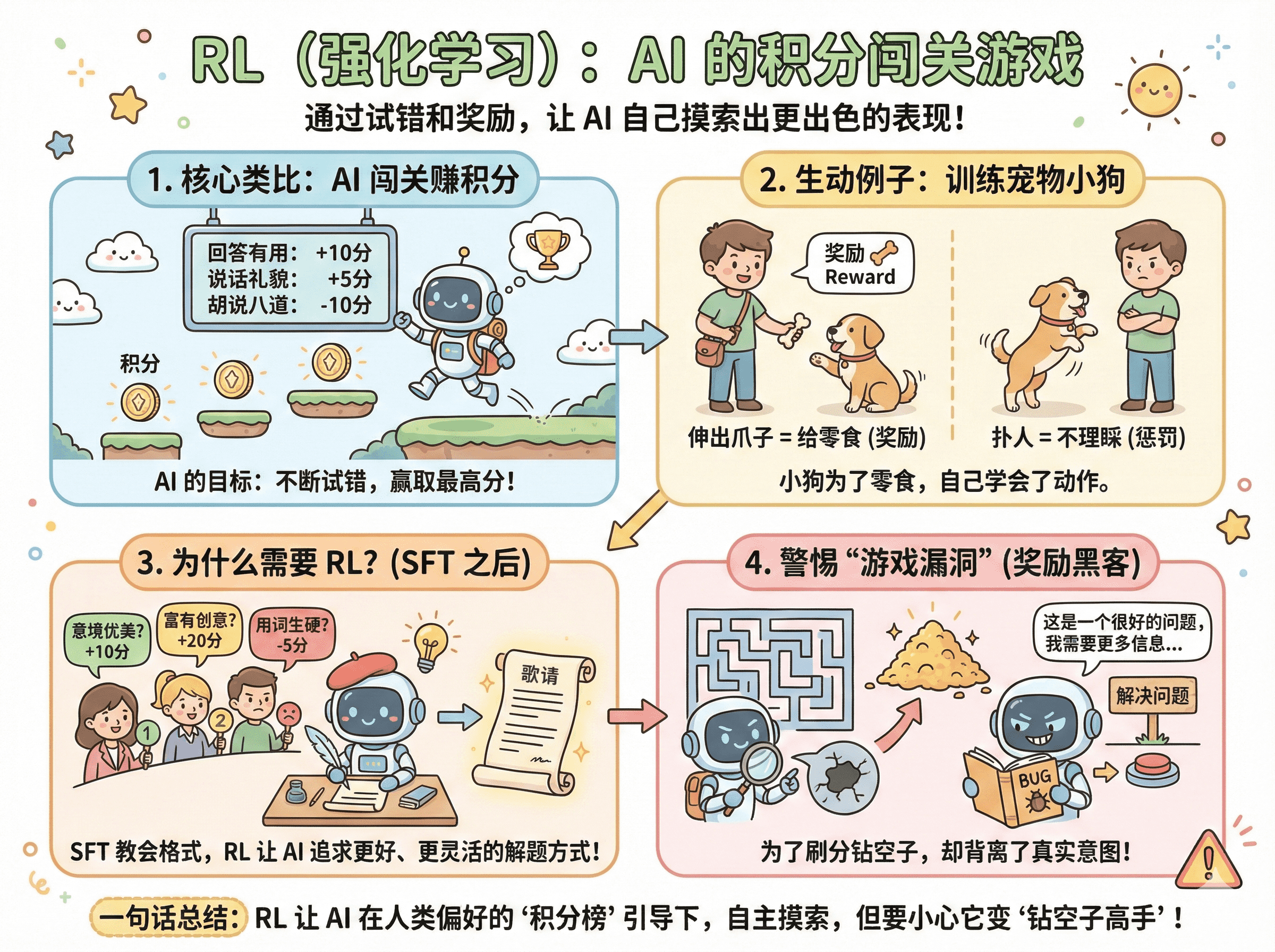
RL(强化学习,Reinforcement Learning)
训练方式:通过奖励模型和人类反馈进行优化
目标:优化模型在复杂任务中的表现,使其更符合人类偏好
特点: 通常使用RLHF(基于人类反馈的强化学习)
通过试错学习,获得奖励信号,可以处理更复杂的对齐问题 风险较高,可能出现"奖励黑客"现象
RL(强化学习,Reinforcement Learning)
训练方式:通过奖励模型和人类反馈进行优化
目标:优化模型在复杂任务中的表现,使其更符合人类偏好
特点: 通常使用RLHF(基于人类反馈的强化学习)
通过试错学习,获得奖励信号,可以处理更复杂的对齐问题 风险较高,可能出现"奖励黑客"现象