1. 前言
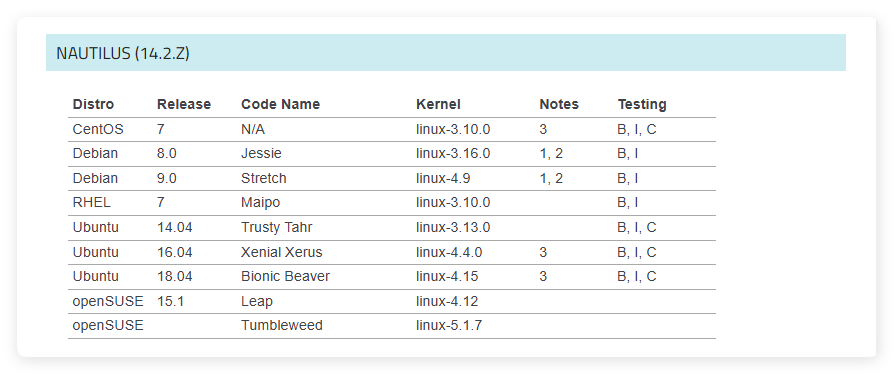
上表中是 Ceph 官方文档给出的 Ceph 14 系列的系统和内核推荐,其中在centos 7、ubuntu 14.04、ubuntu 16.04、ubuntu 18.04上都做了完整的测试。本文将介绍如何在ubuntu 18.04中使用 ceph 原生命令部署一个完整的 ceph 集群,ceph 版本为14.2.22。
2. 准备
2.1. 集群规划
ini
component name component type node ip node name
----------------------------------------------------------------------
[mon.a, mon.b, mon.c] mon 192.168.3.10 node0
[mgr.a, mgr.b, mgr.c] mgr 192.168.3.10 node0
[mds.a, mds.b, mds.c] mds 192.168.3.10 node0
[rgw.a, rgw.b, rgw.c] rgw 192.168.3.10 node0
[osd.0, osd.1, osd.2] osd 192.168.3.10 node02.2. 设置 ceph apt 源
为了加快下载速度,此处使用阿里云开源镜像站:
bash
echo "deb https://mirrors.aliyun.com/ceph/debian-nautilus/ bionic main" > /etc/apt/sources.list.d/ceph.list2.3. 添加 release key
bash
wget -q -O- 'https://mirrors.aliyun.com/ceph/keys/release.asc' | apt-key add -2.4. 更新
bash
apt update2.5. 安装 ceph
bash
apt install ceph ceph-mon ceph-mgr ceph-osd ceph-mds radosgw3. 集群部署
3.1. 创建 client.admin key
在 Ceph 的 cephx 认证体系中,client.admin 是一个预定义的特殊用户,拥有对整个集群的完全访问权限,它可以执行几乎所有管理操作。没有 client.admin,你就没有一个默认的"root"账户来管理集群。换句话说,client.admin 是部署和运维的操作入口。
几乎所有 Ceph 命令行工具(如 ceph, rados, rbd, cephfs 等)在未指定用户时,默认尝试加载 client.admin 的密钥。ceph 14.2.22 中不会自动创建 client.admin key,必须手动创建。测试发现 client.admin key 必须在初始化 mon 之前就创建好,否则后续不好导入到 mon 的 auth 库中,导致 ceph 所有命令都无法使用。
bash
ceph-authtool /etc/ceph/keyring --create-keyring --gen-key -n client.admin \
--cap mon 'allow *' \
--cap osd 'allow *' \
--cap mds 'allow *' \
--cap mgr 'allow *'除了 client.admin key 外,ceph 14.2.22 中会自动创建以下 bootstrap 系列的 key:
bash
client.bootstrap-mds
key: AQD7BW9p5/zTBRAApwYsv603jzAqC2HVZRulgw==
caps: [mon] allow profile bootstrap-mds
client.bootstrap-mgr
key: AQD7BW9pyyPUBRAAD+InmsW8kdJD7RaO9P64Fg==
caps: [mon] allow profile bootstrap-mgr
client.bootstrap-osd
key: AQD7BW9prkfUBRAAOQDCSLcQJv7KyuE7Shzscw==
caps: [mon] allow profile bootstrap-osd
client.bootstrap-rbd
key: AQD7BW9pHm/UBRAACRWOnAmiy2l64lIWDGIwgA==
caps: [mon] allow profile bootstrap-rbd
client.bootstrap-rbd-mirror
key: AQD7BW9po5LUBRAAQSyL0ES1DRxW9X0QdknyDQ==
caps: [mon] allow profile bootstrap-rbd-mirror
client.bootstrap-rgw
key: AQD7BW9pE7XUBRAAmG9hElRA2jb1ChRZ/gVkNQ==
caps: [mon] allow profile bootstrap-rgw3.2. 创建 mon
在部署集群时,必须先部署 mon,mon 是 Ceph 集群的大脑,责维护集群的全局状态信息,负责分发其他组件的通信密钥。所有其他组件在启动和加入集群时,必须与 mon 建立通信。只有 mon 就绪并形成 quorum 后,其他组件服务才能正确加入并协同工作。因此,在部署时必须优先创建 mon。
3.2.1. 创建 mon data
bash
mkdir -p /var/lib/ceph/mon/mon.a
mkdir -p /var/lib/ceph/mon/mon.b
mkdir -p /var/lib/ceph/mon/mon.c3.2.2. 创建 mon key
Ceph 通信机制中使用基于密钥的身份验证机制,mon 之间的通信也是如此。mon key 是整个集群信任体系的起点。如果没有预先生成 mon key,mon 将无法完成认证,也就无法形成初始 quorum,导致集群无法启动。虽然 Ceph 其他组件的密钥通常是由 mon 动态分发,但是 mon 自己的密钥不能从自己获取,必须在启动前静态生成。
bash
ceph-authtool /etc/ceph/keyring --gen-key -n mon. --cap mon 'allow *'因为我将所有的 key 全部写入到同一个文件中:/etc/ceph/keyring,所以只在第一次创建 client.admin key 的时候,才使用--create-keyring参数,这个参数会新建一个 keyring 文件,不管这个文件之前有没有。所以在创建 mon key 的时候,就不再使用--create-keyring参数。后续创建其他组件 key 的过程也同样不在使用--create-keyring参数。
测试发现,在创建 mon key 的时候,mon name 必须是mon.,不能是具体的mon.a这种形式,也不能单独为每个 mon 创建 key。
3.2.3. 创建 monmap
bash
monmaptool --create --clobber --fsid `uuidgen` /etc/ceph/monmap
monmaptool --add a 192.168.3.10:50000 /etc/ceph/monmap
monmaptool --add b 192.168.3.10:50001 /etc/ceph/monmap
monmaptool --add c 192.168.3.10:50002 /etc/ceph/monmapmonmap 创建好之后,可以使用monmaptool --print /etc/ceph/monmap命令来输出 monmap 内容。内容如下:
bash
monmaptool: monmap file /etc/ceph/monmap
epoch 0
fsid 334c5c34-8214-477f-95ba-00991d868126
last_changed 2026-01-17 06:57:21.606165
created 2026-01-17 06:57:21.606165
min_mon_release 0 (unknown)
0: v2:192.168.3.10:50000/0 mon.a
1: v2:192.168.3.10:50001/0 mon.b
2: v2:192.168.3.10:50002/0 mon.c3.2.4. 配置 ceph.conf
新建/etc/ceph/ceph.conf,并追加一下内容:
ini
[global]
fsid = 334c5c34-8214-477f-95ba-00991d868126
mon host = [v2:192.168.3.10:50000] [v2:192.168.3.10:50001] [v2:192.168.3.10:50002]
auth cluster required = cephx
auth service required = cephx
auth client required = cephx
auth allow insecure global id reclaim = false
[mon.a]
mon data = /var/lib/ceph/mon/mon.a
[mon.b]
mon data = /var/lib/ceph/mon/mon.b
[mon.c]
mon data = /var/lib/ceph/mon/mon.c- 上述
global配置中mon host的值必须和monmaptool --add中匹配。 - 上述
mon data是 mon data 目录,这个参数必须要添加,因为在后面初始化 mon data 的时候,如果不指定 mon data 路径,默认会使用/var/lib/ceph/mon/<cluster>-<id>。
3.2.5. 初始化 mon data
bash
ceph-mon --mkfs -i a --monmap=/etc/ceph/monmap --keyring=/etc/ceph/keyring
ceph-mon --mkfs -i b --monmap=/etc/ceph/monmap --keyring=/etc/ceph/keyring
ceph-mon --mkfs -i c --monmap=/etc/ceph/monmap --keyring=/etc/ceph/keyring3.2.6. 修改 mon data 归属
bash
chown -R ceph:ceph /var/lib/ceph/mon3.2.7. 启动 mon
bash
systemctl start ceph-mon@a.service
systemctl enable ceph-mon@a.service
systemctl start ceph-mon@b.service
systemctl enable ceph-mon@b.service
systemctl start ceph-mon@c.service
systemctl enable ceph-mon@c.service至此,如果 mon 正常启动,ceph -s命令可以正常执行并有结果输出。
bash
ceph -s
---------
cluster:
id: 334c5c34-8214-477f-95ba-00991d868126
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 2s)
mgr: no daemons active
osd: 0 osds: 0 up, 0 in
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 0 B used, 0 B / 0 B avail
pgs:如果ceph -s命令没有输出结果或者卡住了,一定是部署失败了。可以在 ceph.conf 文件中global配置项添加debug ms = 1打开客户端调试功能查看问题。
3.3. 创建 mgr
3.3.1. 创建 mgr data
bash
mkdir -p /var/lib/ceph/mgr/mgr.a
mkdir -p /var/lib/ceph/mgr/mgr.b
mkdir -p /var/lib/ceph/mgr/mgr.c3.3.2. 配置 ceph.conf
ini
[mgr.a]
mgr data =/var/lib/ceph/mgr/mgr.a
[mgr.b]
mgr data = /var/lib/ceph/mgr/mgr.b
[mgr.c]
mgr data = /var/lib/ceph/mgr/mgr.c3.3.3. 创建 mgr key
bash
ceph-authtool /etc/ceph/keyring --gen-key -n mgr.a \
--cap mon 'allow profile mgr' \
--cap mds 'allow *' \
--cap osd 'allow *'
ceph-authtool /etc/ceph/keyring --gen-key -n mgr.b \
--cap mon 'allow profile mgr' \
--cap mds 'allow *' \
--cap osd 'allow *'
ceph-authtool /etc/ceph/keyring --gen-key -n mgr.c \
--cap mon 'allow profile mgr' \
--cap mds 'allow *' \
--cap osd 'allow *'3.3.4. 导入 mgr key 到 auth 库中
bash
ceph auth add mgr.a -i /etc/ceph/keyring
ceph auth add mgr.b -i /etc/ceph/keyring
ceph auth add mgr.c -i /etc/ceph/keyring导入 key 到 auth 库中的目的是为了执行ceph auth ls命令能够直接查看到。测试发现,在使用ceph-authtool工具创建 key 的时候,只有 mon 和 client 这两种类型的 key 能够自动添加到 ceph rados 对象中,其他类型的 key 需要手动导入。
3.3.5. 添加 mgr key 到 mgr data
bash
ceph auth export mgr.a > /var/lib/ceph/mgr/mgr.a/keyring
ceph auth export mgr.b > /var/lib/ceph/mgr/mgr.b/keyring
ceph auth export mgr.c > /var/lib/ceph/mgr/mgr.c/keyring3.3.6. 修改 mgr data 目录的归属
bash
chown -R ceph:ceph /var/lib/ceph/mgr3.3.7. 启动 mgr
bash
systemctl start ceph-mgr@a.service
systemctl enable ceph-mgr@a.service
systemctl start ceph-mgr@b.service
systemctl enable ceph-mgr@b.service
systemctl start ceph-mgr@c.service
systemctl enable ceph-mgr@c.service3.4. 创建 osd
Ceph 支持 2 种存储引擎:
filestore和bluestore。filestore 是一个过时的技术,在后续版本中逐渐被 Ceph 弃用,filestore 已经没有任何研究价值,因此本文默认以bluestore为准。
3.4.1. 创建 osd data
bash
mkdir -p /var/lib/ceph/osd/osd.0
mkdir -p /var/lib/ceph/osd/osd.1
mkdir -p /var/lib/ceph/osd/osd.23.4.2. 挂载 osd data 为 tmpfs
bash
mount -t tmpfs tmpfs /var/lib/ceph/osd/osd.0
mount -t tmpfs tmpfs /var/lib/ceph/osd/osd.1
mount -t tmpfs tmpfs /var/lib/ceph/osd/osd.23.4.3. 修改 osd block dev 归属
bash
chown -R ceph:ceph /dev/sdb
chown -R ceph:ceph /dev/sdc
chown -R ceph:ceph /dev/sdd3.4.4. 创建 osd block
bash
ln -snf /dev/sdb /var/lib/ceph/osd/osd.0/block
ln -snf /dev/sdc /var/lib/ceph/osd/osd.1/block
ln -snf /dev/sdd /var/lib/ceph/osd/osd.2/block3.4.5. 配置 osd
ini
[osd.0]
osd objectstore = bluestore
osd data = /var/lib/ceph/osd/osd.0
crush_location = root=default host=virtual-node0
[osd.1]
osd objectstore = bluestore
osd data = /var/lib/ceph/osd/osd.1
crush_location = root=default host=virtual-node1
[osd.2]
osd objectstore = bluestore
osd data = /var/lib/ceph/osd/osd.2
crush_location = root=default host=virtual-node2crush_location是更改 osd 的 crush 位置,ceph 默认最小容灾域级别是host,因为当前是在一台物理机上部署的,为了后续成功创建副本 pool,此时有必要更改。当然也可以在创建 pool 之前新建一个 crush rule 来自定义 crush 规则。
3.4.6. 创建 osd key
bash
ceph-authtool /etc/ceph/keyring --gen-key -n osd.0 \
--cap mon 'allow profile osd' \
--cap mgr 'allow profile osd' \
--cap osd 'allow *'
ceph-authtool /etc/ceph/keyring --gen-key -n osd.1 \
--cap mon 'allow profile osd' \
--cap mgr 'allow profile osd' \
--cap osd 'allow *'
ceph-authtool /etc/ceph/keyring --gen-key -n osd.2 \
--cap mon 'allow profile osd' \
--cap mgr 'allow profile osd' \
--cap osd 'allow *'3.4.7. 导入 osd key 到 auth 库中
bash
ceph auth add osd.0 -i /etc/ceph/keyring
ceph auth add osd.1 -i /etc/ceph/keyring
ceph auth add osd.2 -i /etc/ceph/keyring3.4.8. 添加 osd key 到 osd data
bash
ceph auth export osd.0 > /var/lib/ceph/osd/osd.0/keyring
ceph auth export osd.1 > /var/lib/ceph/osd/osd.1/keyring
ceph auth export osd.2 > /var/lib/ceph/osd/osd.2/keyring3.4.9. 添加 osd key json 到 osd data
bash
echo "{\"cephx_secret\": \"`ceph auth get-key osd.0`\"}" > /var/lib/ceph/osd/osd.0/keyring.json
echo "{\"cephx_secret\": \"`ceph auth get-key osd.1`\"}" > /var/lib/ceph/osd/osd.1/keyring.json
echo "{\"cephx_secret\": \"`ceph auth get-key osd.2`\"}" > /var/lib/ceph/osd/osd.2/keyring.json3.4.10. 创建 osd 并初始化 osd data
bash
uuid=`uuidgen`
ceph osd new $uuid 0 -i /var/lib/ceph/osd/osd.0/keyring.json
ceph-osd -i 0 --mkfs --osd-uuid $uuid --keyring /var/lib/ceph/osd/osd.0/keyring
uuid=`uuidgen`
ceph osd new $uuid 1 -i /var/lib/ceph/osd/osd.1/keyring.json
ceph-osd -i 1 --mkfs --osd-uuid $uuid --keyring /var/lib/ceph/osd/osd.1/keyring
uuid=`uuidgen`
ceph osd new $uuid 2 -i /var/lib/ceph/osd/osd.2/keyring.json
ceph-osd -i 2 --mkfs --osd-uuid $uuid --keyring /var/lib/ceph/osd/osd.2/keyring3.4.11. 修改 osd data 归属
bash
chown -R ceph:ceph /var/lib/ceph/osd3.4.12. 启动服务
bash
systemctl start ceph-osd@0.service
systemctl enable ceph-osd@0.service
systemctl start ceph-osd@1.service
systemctl enable ceph-osd@1.service
systemctl start ceph-osd@2.service
systemctl enable ceph-osd@2.service上述使用systemctl start ceph-osd@0.service方式启动 osd 服务时会失败,原因是/usr/lib/systemd/system/ceph-osd@.service文件会先执行/usr/lib/ceph/ceph-osd-prestart.sh脚本,在这个脚本中需要将data="/var/lib/ceph/osd/${cluster:-ceph}-$id"修改成实际 osd 目录data="/var/lib/ceph/osd/osd.$id"。
以上创建 OSD 的所有过程都可以使用
ceph-volume create这条命令一步完成,这条命令实际上也是一步步执行上面过程,之所以不使用 ceph-volume 工具,主要原因是 osd data 目录没法自定义。ceph-volume 已经将 osd data 目录写死成/var/lib/ceph/osd/${cluster:-ceph}-$id。
到此,一个简单的 Ceph 集群已经部署完成,使用ceph -s查看集群状态如下:
bash
ceph -s
---------
cluster:
id: 334c5c34-8214-477f-95ba-00991d868126
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 30m)
mgr: a(active, since 24m), standbys: b, c
osd: 3 osds: 3 up (since 9m), 3 in (since 9m)
data:
pools: 0 pools, 0 pgs
objects: 0 objects, 0 B
usage: 3.0 GiB used, 12 GiB / 15 GiB avail
pgs:4. 文件存储部署
4.1. 创建 mds
4.1.1. 创建 mds data
bash
mkdir -p /var/lib/ceph/mds/mds.a
mkdir -p /var/lib/ceph/mds/mds.b
mkdir -p /var/lib/ceph/mds/mds.c4.1.2. 配置 ceph.conf
ini
[mds.a]
mds data =/var/lib/ceph/mds/mds.a
[mds.b]
mds data =/var/lib/ceph/mds/mds.b
[mds.c]
mds data =/var/lib/ceph/mds/mds.c4.1.3. 创建 mds key
bash
ceph-authtool /etc/ceph/keyring --gen-key -n mds.a \
--cap mon 'allow profile mds' \
--cap osd 'allow *' \
--cap mds 'allow' \
--cap mgr 'allow profile mds'
ceph-authtool /etc/ceph/keyring --gen-key -n mds.b \
--cap mon 'allow profile mds' \
--cap osd 'allow *' \
--cap mds 'allow' \
--cap mgr 'allow profile mds'
ceph-authtool /etc/ceph/keyring --gen-key -n mds.c \
--cap mon 'allow profile mds' \
--cap osd 'allow *' \
--cap mds 'allow' \
--cap mgr 'allow profile mds'4.1.4. 导入 mds key 到 auth 库中
bash
ceph auth add mds.a -i /etc/ceph/keyring
ceph auth add mds.b -i /etc/ceph/keyring
ceph auth add mds.c -i /etc/ceph/keyring4.1.5. 添加 mds key 到 mds data
bash
ceph auth export mds.a > /var/lib/ceph/mds/mds.a/keyring
ceph auth export mds.b > /var/lib/ceph/mds/mds.b/keyring
ceph auth export mds.c > /var/lib/ceph/mds/mds.c/keyring4.1.6. 修改 mds data 归属
bash
chown -R ceph:ceph /var/lib/ceph/mds4.1.7. 启动 mds
bash
systemctl start ceph-mds@a.service
systemctl enable ceph-mds@a.service
systemctl start ceph-mds@b.service
systemctl enable ceph-mds@b.service
systemctl start ceph-mds@c.service
systemctl enable ceph-mds@c.service4.2. 创建数据池
bash
ceph osd pool create cephfs_data 1 1其中cephfs_data是数据池的名字,1 1分别表示 pg 和 pgp 的数量,因为是测试,所以都设置为 1。
4.3. 创建元数据池
bash
ceph osd pool create cephfs_metadata 1 1其中cephfs_metadata是元数据池的名字,1 1分别表示 pg 和 pgp 的数量,因为是测试,所以都设置为 1。
4.4. 创建文件系统
bash
ceph fs new cephfs cephfs_metadata cephfs_data其中cephfs 为文件系统的名字,该命令将会创建一个名为 cephfs 的文件系统,文件系统的元数据将存在 cephfs_metadata 元数据池中,文件系统的数据将存在 cephfs_data 数据池中。
再次查看集群状态:
bash
ceph -s
---------
cluster:
id: 334c5c34-8214-477f-95ba-00991d868126
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 105m)
mgr: a(active, since 99m), standbys: b, c
mds: cephfs:1 {0=a=up:active} 2 up:standby
osd: 3 osds: 3 up (since 44m), 3 in (since 84m)
data:
pools: 2 pools, 2 pgs
objects: 22 objects, 2.2 KiB
usage: 3.0 GiB used, 12 GiB / 15 GiB avail
pgs: 2 active+clean5. 对象存储部署
5.1. 创建 rgw
5.1.1. 创建 rgw data
bash
mkdir -p /var/lib/ceph/rgw/rgw.a
mkdir -p /var/lib/ceph/rgw/rgw.b
mkdir -p /var/lib/ceph/rgw/rgw.c5.1.2. 配置 rgw
ini
[client.rgw.a]
rgw frontends = "civetweb port=192.168.3.10:50003"
rgw data =/var/lib/ceph/rgw/rgw.a
[client.rgw.b]
rgw frontends = "civetweb port=192.168.3.10:50004"
rgw data =/var/lib/ceph/rgw/rgw.b
[client.rgw.c]
rgw frontends = "civetweb port=192.168.3.10:50005"
rgw data =/var/lib/ceph/rgw/rgw.c上述port=192.168.3.10:50003表示只启动 tcp4 端口监听。如果设置成port=50003,表示同时启动 tcp4 和 tcp6 端口监听。
5.1.3. 创建 rgw key
bash
ceph-authtool /etc/ceph/keyring --gen-key -n client.rgw.a \
--cap mon 'allow rw' \
--cap osd 'allow rwx' \
--cap mgr 'allow rw'
ceph-authtool /etc/ceph/keyring --gen-key -n client.rgw.b \
--cap mon 'allow rw' \
--cap osd 'allow rwx' \
--cap mgr 'allow rw'
ceph-authtool /etc/ceph/keyring --gen-key -n client.rgw.c \
--cap mon 'allow rw' \
--cap osd 'allow rwx' \
--cap mgr 'allow rw'测试发现,rgw 的 name 必须是以client.为前缀。因为 ceph 中没有rgw这个类别,类别只有auth, mon, osd, mds, mgr, client这几种。
5.1.4. 导入 rgw key 到 auth 库中
bash
ceph auth add client.rgw.a -i /etc/ceph/keyring
ceph auth add client.rgw.b -i /etc/ceph/keyring
ceph auth add client.rgw.c -i /etc/ceph/keyring5.1.5. 添加 rgw key 到 rgw data
bash
ceph auth export client.rgw.a > /var/lib/ceph/rgw/rgw.a/keyring
ceph auth export client.rgw.b > /var/lib/ceph/rgw/rgw.b/keyring
ceph auth export client.rgw.c > /var/lib/ceph/rgw/rgw.c/keyring5.1.6. 修改 rgw data 归属
bash
chown -R ceph:ceph /var/lib/ceph/rgw5.1.7. 启动 rgw
bash
systemctl start ceph-radosgw@rgw.a.service
systemctl enable ceph-radosgw@rgw.a.service
systemctl start ceph-radosgw@rgw.b.service
systemctl enable ceph-radosgw@rgw.b.service
systemctl start ceph-radosgw@rgw.c.service
systemctl enable ceph-radosgw@rgw.c.service默认情况下,启动 rgw 服务后,会自动创建与 rgw 服务相关的 pool。再次查看集群状态:
bash
ceph -s
---------
cluster:
id: 334c5c34-8214-477f-95ba-00991d868126
health: HEALTH_OK
services:
mon: 3 daemons, quorum a,b,c (age 106m)
mgr: a(active, since 101m), standbys: b, c
mds: cephfs:1 {0=a=up:active} 2 up:standby
osd: 3 osds: 3 up (since 46m), 3 in (since 85m)
rgw: 3 daemons active (a, b, c)
task status:
data:
pools: 6 pools, 130 pgs
objects: 135 objects, 3.4 KiB
usage: 3.0 GiB used, 12 GiB / 15 GiB avail
pgs: 130 active+clean
io:
client: 21 KiB/s rd, 0 B/s wr, 27 op/s rd, 17 op/s wr6. 块存储部署
6.1. 创建数据池
bash
ceph osd pool create rbd_pool 1 1其中rbd_pool是数据池的名字,1 1分别是 pg 和 pgp 的数量,因为是测试集群,所以都设置为 1。
6.2. 创建 rbd image
bash
rbd create --pool rbd_pool --image image1 --size 1024 --image-format 2 --image-feature layering其中rbd_pool是数据池的名字,image1是镜像的名字,1024是镜像的大小,其他参数不变即可。上述命令将创建一个名为image1的 rbd 镜像。后续通过镜像映射操作就可以像操作磁盘一样来读写 rbd 块设备。