Selenium Web 自动化测试脚本总结
Web 自动化的本质,是模拟人在浏览器里的操作行为:打开浏览器、访问页面、定位元素、输入/点击、做断言验证。Selenium 之所以常用,是因为它把这些动作抽象成了一套稳定的 API,再配合浏览器驱动(WebDriver)就能把"测试步骤"变成"可重复执行的脚本"。
下面按"工程上最常遇到的问题链路"来讲:先跑通 → 再定位稳 → 再等待稳 → 再窗口/弹窗/上传/截图/参数全覆盖。测试概念相关内容会简要收束在文末。
1)先搞清三件套:Selenium + 浏览器驱动 + 浏览器怎么协作
来看 Web 自动化落地需要的三件套:
- 浏览器:最终执行动作的地方
- 浏览器驱动(WebDriver):把自动化指令翻译成浏览器能理解的操作
- Selenium 脚本:你写的 Java 代码,负责发出"打开页面/找元素/点击/断言"的指令
再来看它们的交互流程(非常关键,理解了后面排错就简单):
- Selenium 脚本里会在
ChromeDriverService创建一个服务 - 通过服务启动本地驱动(一般是
localhost:<port>),这是 Selenium 向 WebDriver 发送请求的地址 - Selenium 向驱动发 HTTP 请求,驱动解析请求,打开浏览器并返回
sessionId(后续操作需要携带) - 访问地址、查找元素等动作都通过该服务连接到 WebDriver,再通过
execute发送请求 - 驱动把请求翻译成浏览器可执行的脚本并发送给浏览器,浏览器执行后把结果再经驱动返回给脚本
验证"驱动服务真的存在"的方式也很直观:执行脚本时终端会打印出驱动服务地址和端口信息。
2)驱动管理:别手动下载驱动,交给 WebDriverManager
来看一个现实问题:Chrome/Edge/Firefox 驱动版本经常和浏览器版本"拧巴",手动维护很痛。
解决办法:用 WebDriverManager 做驱动管理,它会自动下载、设置、维护驱动;并且从 v5 起还支持发现本机浏览器、构建 ChromeDriver/FirefoxDriver/EdgeDriver 等对象。
Maven 依赖(示例):
xml
<dependency>
<groupId>io.github.bonigarcia</groupId>
<artifactId>webdrivermanager</artifactId>
<version>5.8.0</version>
<scope>test</scope>
</dependency>3)Selenium 快速上手:一段"百度搜索"脚本跑通全链路
来看最小可运行例子:打开浏览器 → 访问百度 → 输入关键字 → 点击搜索 → 退出。
Selenium 依赖(示例):
xml
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.0.0</version>
</dependency>代码骨架(Java):
java
public void example_test() {
// 驱动程序管理自动化
WebDriverManager.chromedriver().setup();
ChromeOptions options = new ChromeOptions();
// 允许访问所有链接
options.addArguments("--remote-allow-origins=*");
// 1) 打开浏览器
WebDriver driver = new ChromeDriver(options);
// 2) 访问百度
driver.get("https://www.baidu.com");
// 3) 输入关键词
driver.findElement(By.xpath("//*[@id=\"kw\"]")).sendKeys("迪丽热巴");
// 4) 点击"百度一下"
driver.findElement(By.xpath("//*[@id=\"su\"]")).click();
// 5) 关闭浏览器
driver.quit();
}4)元素定位:自动化的核心是"定位必须唯一"
Web 自动化测试的操作核心是:先找到元素,再对元素操作 。常见定位方式很多(id/className/tagName/xpath/cssSelector),实际高频主要是 cssSelector 和 xpath。
4.1 cssSelector:更贴近前端,写起来也短
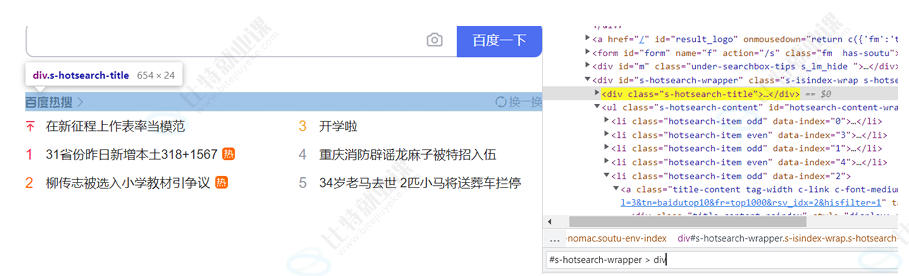
来看 selector 的用途:选中页面指定标签元素。常见写法:
- id 选择器 :
#kw(百度搜索输入框) - 子类/层级选择器 :例如热搜区域:
#s-hotsearch-wrapper > div
4.2 XPath:路径语言,表达力强
来看 XPath 的常用语法点(能覆盖 80% 场景):
- 获取所有节点:
//* - 获取指定标签节点:
//ul、//input - 直接子节点:
/(如//span/input) - 父节点:
..(如//input/..) - 按属性匹配:
//*[@id='kw'] - 按索引取第 N 个:
//div/ul/li[3](注意索引从 1 开始)
4.3 "复制 selector/xpath"很香,但要小心"不唯一"
浏览器右键 Copy selector/xpath 很便捷,但复制出来的表达式不一定满足唯一性 ,有时需要手动改。
来看提醒:元素定位方法必须唯一;不唯一会导致脚本点错对象、偶现失败、甚至误判通过。
5)操作元素:点击、输入、清空、取文本与取属性
定位到元素后,常见操作包括点击、提交、输入、清除、获取文本。
5.1 点击/提交
java
driver.findElement(By.cssSelector("#su")).click();5.2 输入(模拟键盘)
java
driver.findElement(By.cssSelector("#kw")).sendKeys("输入文字");5.3 清空再输入
java
driver.findElement(By.cssSelector("#kw")).sendKeys("我爱游戏");
driver.findElement(By.cssSelector("#kw")).clear();
driver.findElement(By.cssSelector("#kw")).sendKeys("我爱学习");5.4 获取文本 vs 获取属性:别把"文本"和"属性值"混了
- 获取文本:
getText() - 获取属性值:
getAttribute("属性名称")
另外两个经常要用的"页面级信息":
- 当前标题:
getTitle() - 当前 URL:
getCurrentUrl()
6)窗口与句柄:新窗口打开后,脚本并不知道"你眼睛看到的那个窗口"
手工测试靠眼睛判断当前窗口;脚本需要靠 窗口句柄(handle)。
6.1 获取与切换窗口
- 当前窗口句柄:
driver.getWindowHandle() - 所有窗口句柄:
driver.getWindowHandles()
切换到新窗口的常见写法:
java
String curWindow = driver.getWindowHandle();
Set<String> allWindow = driver.getWindowHandles();
for (String w : allWindow) {
if (w != curWindow) {
driver.switchTo().window(w);
}
}注意:执行 driver.close() 之前要先切到未被关闭的窗口。
6.2 窗口大小控制
java
driver.manage().window().maximize();
driver.manage().window().minimize();
driver.manage().window().fullscreen();
driver.manage().window().setSize(new Dimension(1024, 768));7)等待:稳定性的分水岭(强制 / 隐式 / 显式)
代码执行速度通常比页面渲染快,不等待就容易出现"元素还没出来就去找"的误报。来看三种等待方式:
7.1 强制等待:Thread.sleep()
- 优点:简单、调试时好用
- 缺点:浪费时间、影响效率
7.2 隐式等待:全局智能等待
隐式等待会在查找元素时在指定时间内不断尝试,找到就继续,超时才报错。
java
driver.manage().timeouts().implicitlyWait(Duration.ofSeconds(5));它的作用域是整个脚本 (只要 driver 没 quit() 就一直生效)。
7.3 显式等待:带条件的智能等待(更灵活)
显式等待在超时时间内只要满足条件就继续执行:
java
WebDriverWait wait = new WebDriverWait(driver, Duration.ofSeconds(3));
wait.until(ExpectedConditions.elementToBeClickable(By.cssSelector("#id")));常见条件(ExpectedConditions)包括:
elementToBeClickable:元素可见且可点击textToBe:文本符合预期presenceOfElementLocated:DOM 上存在该元素urlToBe:URL 符合预期
7.4 重要结论:不要混合隐式等待和显式等待
来看实验现象:隐式等待 5s + 显式等待 10s,最终等待时间并不稳定(会出现 10s、11s...),因此结论是:不要混用,等待时间可能不可预测。
8)浏览器导航:前进、后退、刷新
打开网站两种写法:
java
driver.navigate().to("https://selenium.dev");
driver.get("https://selenium.dev");前进/后退/刷新:
java
driver.navigate().back();
driver.navigate().forward();
driver.navigate().refresh();9)弹窗处理:页面里找不到元素时,用 Alert
弹窗在页面 DOM 里通常找不到元素,需要切到 Alert:
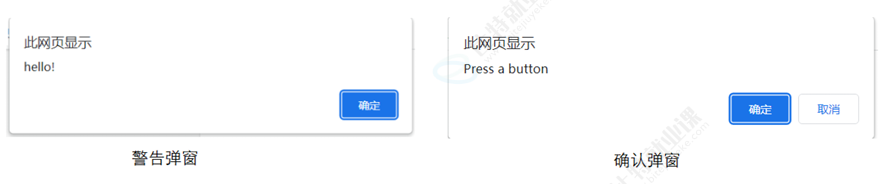
9.1 警告/确认弹窗
java
Alert alert = driver.switchTo().alert();
alert.accept(); // 确认
alert.dismiss(); // 取消9.2 提示弹窗(可输入)
java
Alert alert = driver.switchTo().alert();
alert.sendKeys("hello");
alert.accept();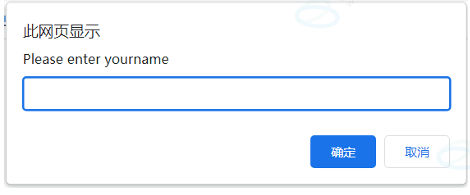
10)文件上传:系统文件选择框不可控,但可以绕过去
点击"上传文件"会弹出系统窗口,这是非 Web 控件,Selenium 无法直接识别。
解决办法:对 <input type="file"> 直接 sendKeys(文件路径):
java
WebElement ele = driver.findElement(By.cssSelector("body > div > div > input[type=file]"));
ele.sendKeys("D:\\selenium2html\\selenium2html\\upload.html");11)截图:让"线上跑挂了但你看不见"的问题可追溯
自动化脚本往往跑在机器上,失败时你不一定能看到现场。截图可以记录当时的错误画面。
需要额外依赖(示例):
xml
<dependency>
<groupId>commons-io</groupId>
<artifactId>commons-io</artifactId>
<version>2.6</version>
</dependency>核心代码:
java
File file = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);
FileUtils.copyFile(file, new File(filename));并且可以做"简单版/带时间戳归档版"的路径管理。
12)浏览器参数:无头模式 + 页面加载策略
12.1 无头模式(Headless)
java
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
ChromeDriver driver = new ChromeDriver(options);12.2 页面加载策略
java
options.setPageLoadStrategy(PageLoadStrategy.NONE);13)测试概念(简要收束):自动化主要服务回归,但不能"神化"
来看几个关键结论:
- 自动化的主要目的常用于回归测试:避免新增功能影响历史功能,需要整体回归。
- 自动化不一定能取代人工:脚本也是人写的,功能变更后脚本需要维护与更新。
- "自动化能大幅降低工作量"这种绝对化表达要小心,更准确的说法是:在一定程度上降低,但前期投入与维护成本真实存在。
- 自动化类型很多:接口自动化、UI 自动化(Web、移动端)等;移动端常依赖模拟器,受环境影响更大,稳定性通常比接口与 Web 自动化更差。
- 来看"自动化测试金字塔":理想状态是更多精力放在单元层,UI 层更少;而实际企业里常出现"冰淇淋蛋筒反模式",UI 自动化过重导致成本高、维护难。自动化需要找到"突破点",当持续运行带来长期成本收益时,价值才会逐渐体现。
Selenium自动化脚本总结
定位要唯一、等待别混用、窗口要切对、失败要留证据(截图/日志)、能用配置别硬编码。