在 RabbitMQ 中,无法路由的消息(即交换机无法将消息路由到任何队列)的处理方式取决于消息发布时的参数配置,主要有以下几种情况:
1. 普通情况(默认行为)
如果消息发布时没有设置特殊参数:
// 默认情况:无法路由的消息直接被丢弃
channel.basicPublish(
"my-exchange", // 交换机名称
"routing-key", // 路由键
null, // 消息属性(没有设置mandatory)
messageBody // 消息体
);结果 :消息被静默丢弃,生产者不会收到任何通知。
2. 使用 mandatory 参数
当设置 mandatory=true 时:
channel.basicPublish(
"my-exchange",
"unroutable-key",
{ mandatory: true }, // 关键参数
messageBody
);
// 添加返回监听器
channel.addReturnListener((returnMessage) => {
console.log("消息无法路由被返回:", {
replyCode: returnMessage.replyCode,
replyText: returnMessage.replyText,
exchange: returnMessage.exchange,
routingKey: returnMessage.routingKey,
body: returnMessage.body.toString()
});
});结果:
-
消息无法路由时,会通过 Basic.Return 命令返回给生产者
-
生产者可以监听并处理这些返回的消息
-
这是推荐的可靠消息发布方式
3. 使用备用交换器(Alternate Exchange,AE)
这是处理无法路由消息的最佳实践:
// 1. 首先声明一个备用交换器(通常是一个Fanout类型)
channel.assertExchange("my-ae", "fanout", { durable: true });
channel.assertQueue("unroutable-messages", { durable: true });
channel.bindQueue("unroutable-messages", "my-ae", "");
// 2. 声明主交换器时指定备用交换器
const args = { "alternate-exchange": "my-ae" };
channel.assertExchange("my-direct-exchange", "direct", {
durable: true,
arguments: args // 设置备用交换器
});工作原理:
发布消息 → 主交换器无法路由 → 自动转发到备用交换器 → 备用交换器路由到专用队列优点:
-
无需生产者设置
mandatory -
所有无法路由的消息都被集中收集
-
可以后续分析、重试或人工处理
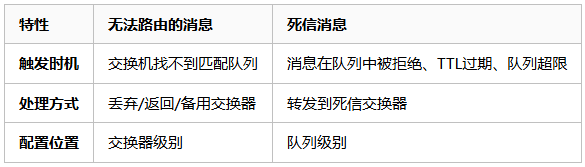
4. 与死信交换器(DLX)的区别
重要区分:无法路由的消息不会进入死信队列(DLQ),除非:
-
使用备用交换器将消息路由到队列
-
该队列配置了死信交换器
-
消息在该队列中过期或被拒绝
5. 实际工作流程示例
场景:订单系统
// 配置备用交换器收集无法路由的订单消息
channel.assertExchange("orders-ae", "fanout", { durable: true });
channel.assertQueue("dead-letters.orders", { durable: true });
channel.bindQueue("dead-letters.orders", "orders-ae", "");
// 主交换器
const args = { "alternate-exchange": "orders-ae" };
channel.assertExchange("orders", "direct", {
durable: true,
arguments: args
});
// 正常队列
channel.assertQueue("orders.process", { durable: true });
channel.bindQueue("orders.process", "orders", "order.created");
// 生产者发布消息
// 如果路由键是 "order.updated"(没有队列绑定)
// 消息会进入 dead-letters.orders 队列6. 最佳实践建议
1.生产环境必选方案:
方案一(推荐):
启用备用交换器 + 监控无法路由消息队列
方案二:
设置 mandatory=true + 实现ReturnListener2.监控和告警:
// 监控无法路由消息队列的长度
channel.assertQueue("unroutable-messages", { durable: true });
// 定期检查队列消息数
const result = channel.checkQueue("unroutable-messages");
if (result.messageCount > threshold) {
sendAlert("发现大量无法路由的消息!");
}3.常见原因分析:
-
路由键拼写错误
-
消费者队列未正确绑定
-
交换器类型与路由规则不匹配
-
动态路由键生成逻辑错误
总结
RabbitMQ 中无法路由的消息有三条可能的路径:
-
默认:静默丢弃(不推荐)
-
通过
mandatory=true:返回给生产者处理 -
通过备用交换器:集中收集到专门队列(最佳实践)
推荐架构:
生产者 → 主交换器(配置备用交换器)
↓(无法路由)
备用交换器(Fanout)
↓
"unroutable.messages"队列
↓
监控系统/人工处理这样既能保证消息不丢失,又能及时发现路由配置问题。
文章转载自: ++佛祖让我来巡山++