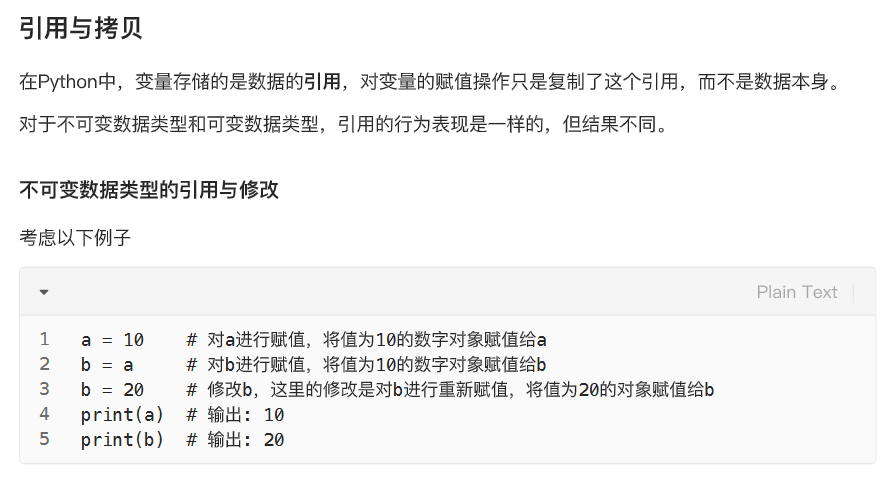
列表:
列表的增删改查
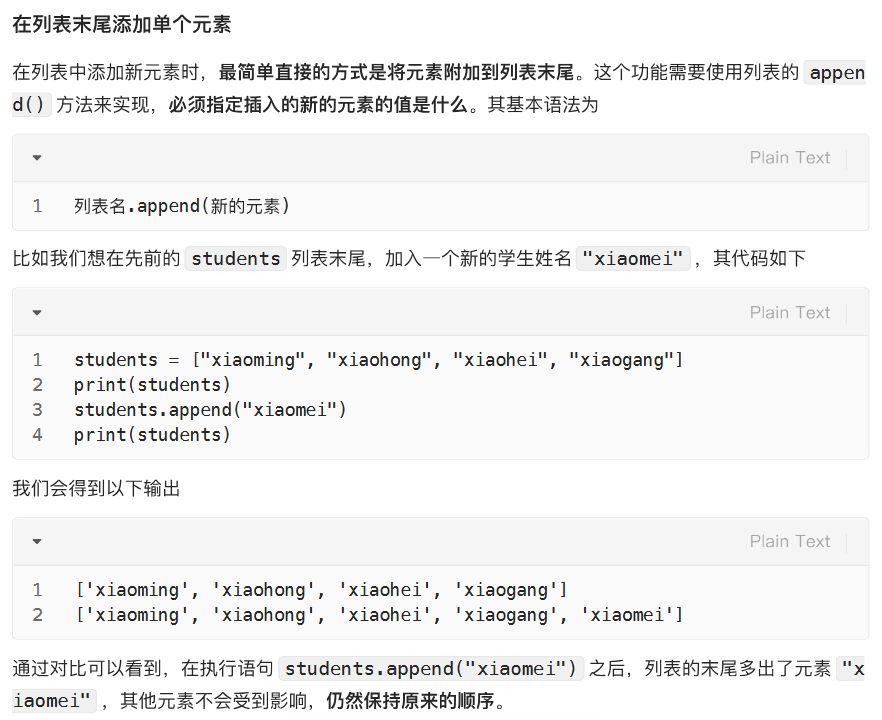
增:在列表末尾添加单个元素
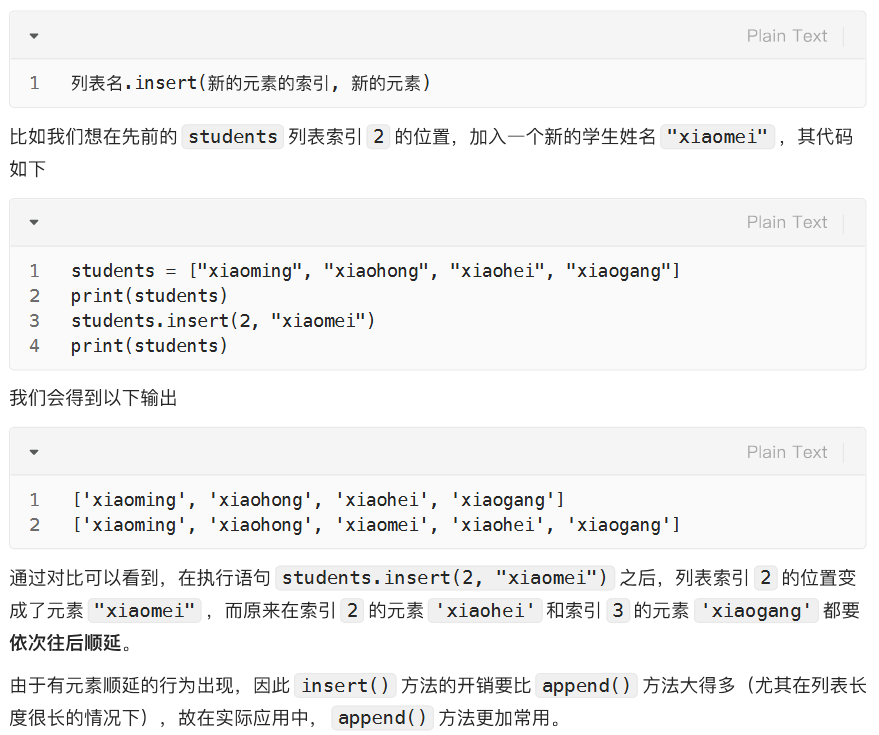
增:在列表中间添加单个元素

增:列表扩展

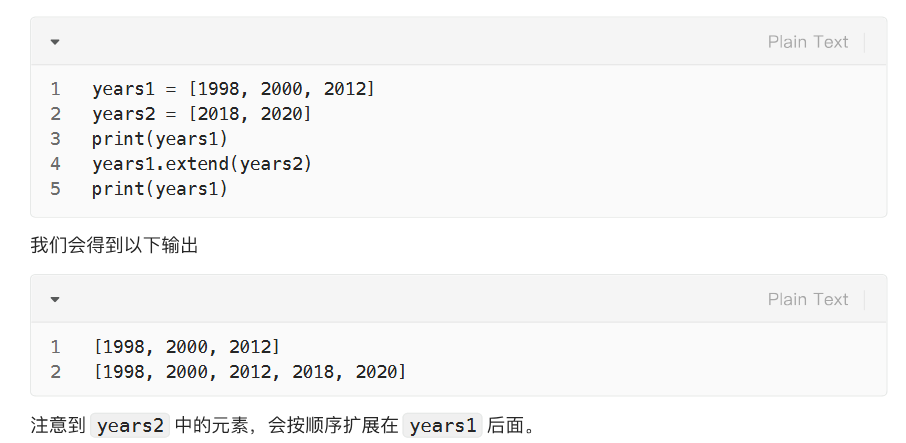
增:列表加法和乘法
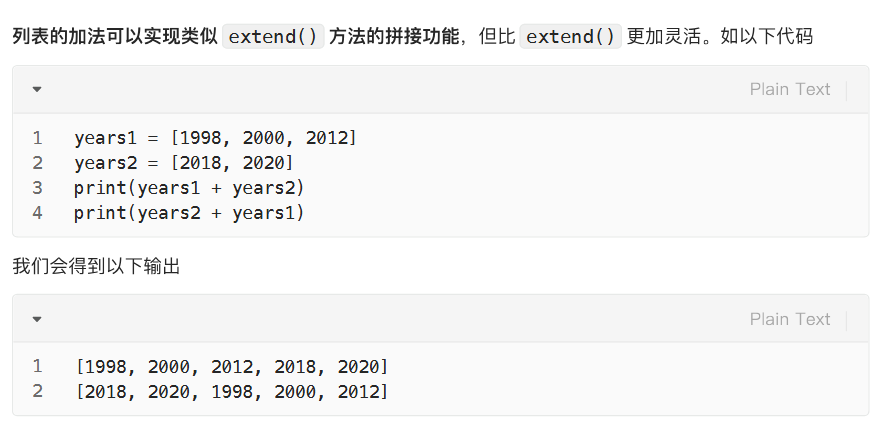
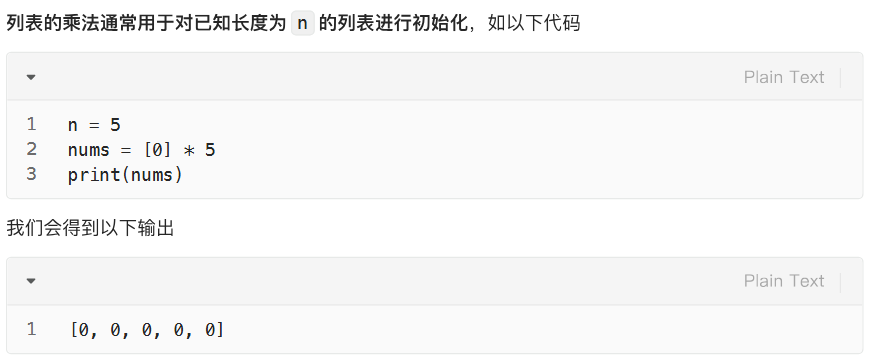
删:删除列表末尾元素
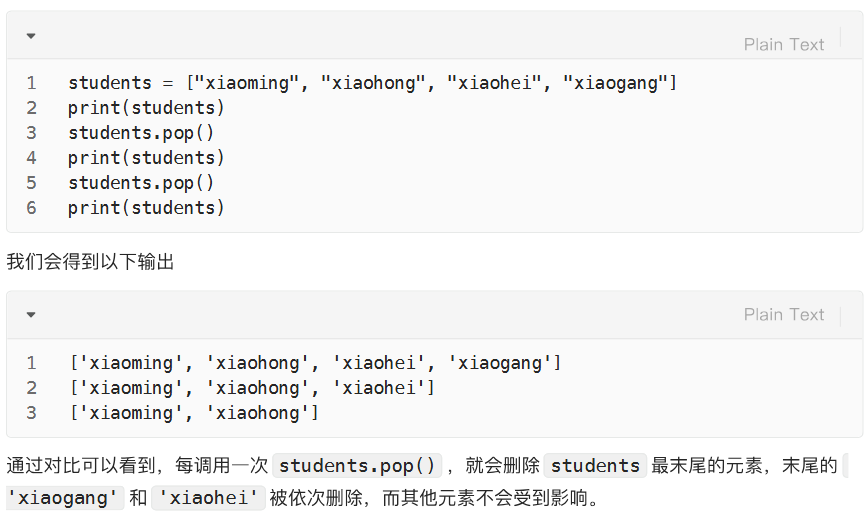
删:根据索引删除列表元素


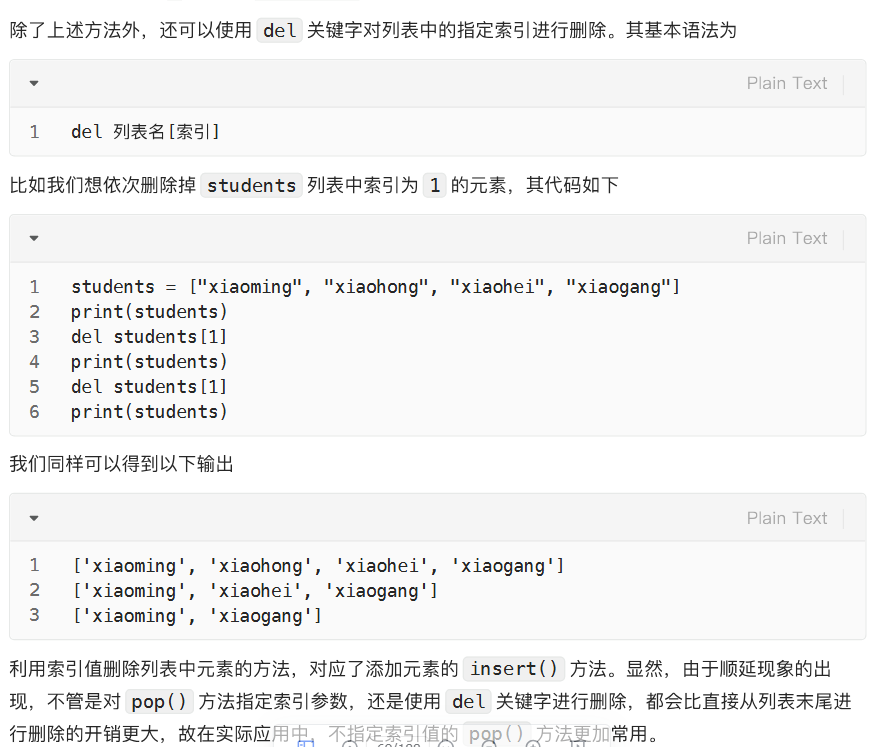
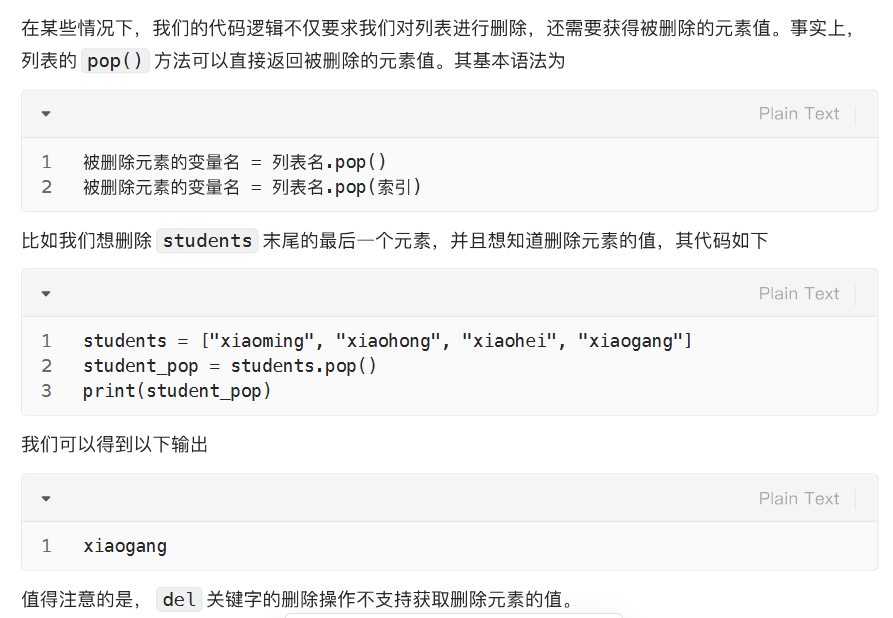
删:获取删除元素值
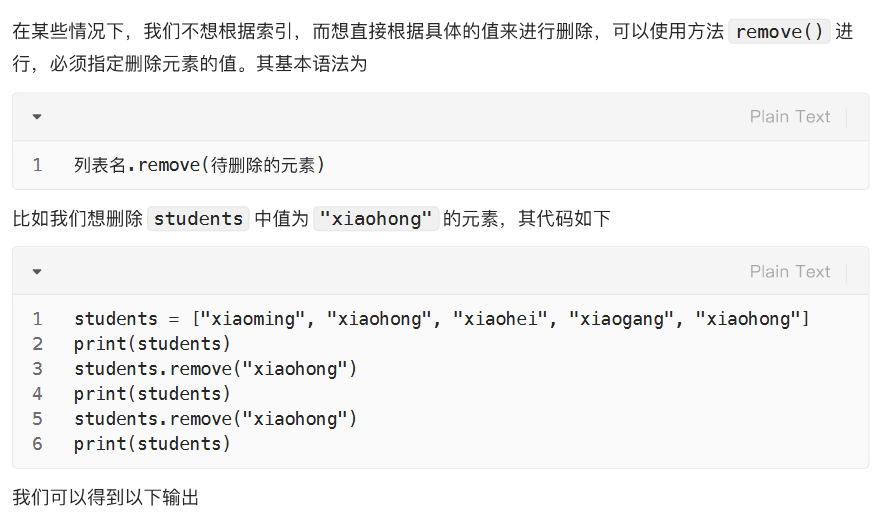
删:根据值删除列表中的元素

改:根据索引修改列表元素
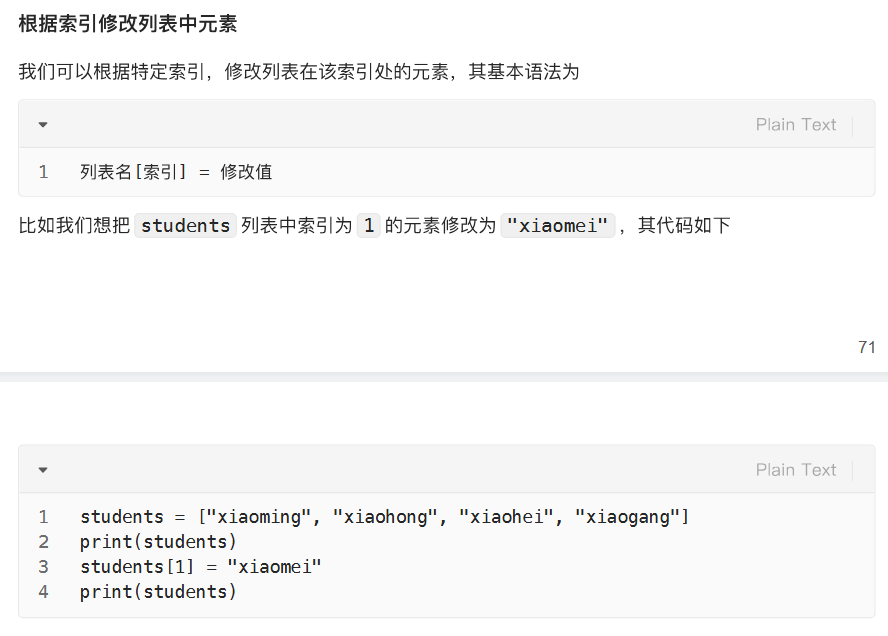
原地修改

列表常用方法和内置函数
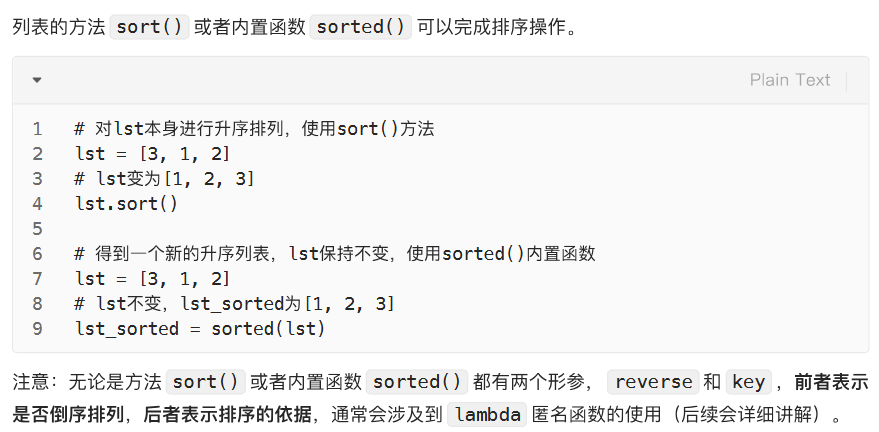
排序:.sort()和 sorted()
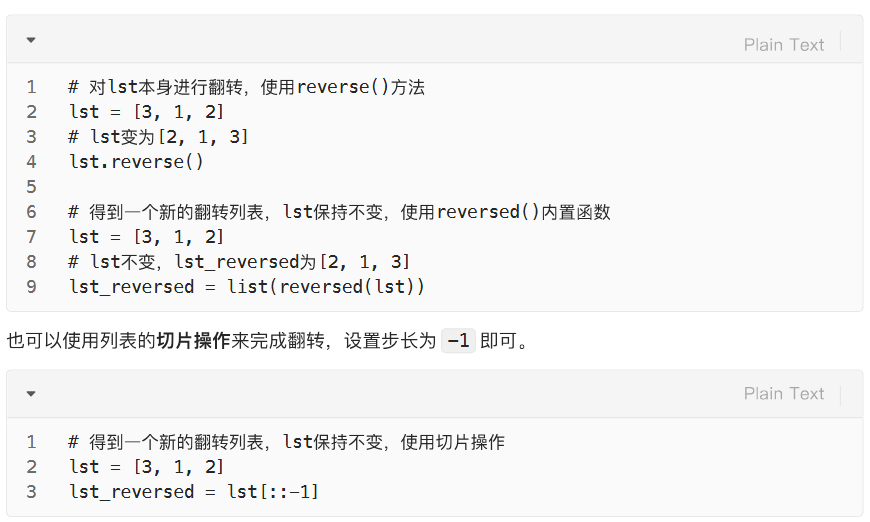
翻转:.reverse() 和 reversed() 以及切片::-1
映射: map()

map() 函数语法:
pythonmap(function, iterable, ...) function -- 函数 iterable -- 一个或多个序列Python 3.x 返回迭代器。
python>>> def square(x) : # 计算平方数 ... return x ** 2 ... >>> map(square, [1,2,3,4,5]) # 计算列表各个元素的平方 <map object at 0x100d3d550> # 返回迭代器 >>> list(map(square, [1,2,3,4,5])) # 使用 list() 转换为列表 [1, 4, 9, 16, 25] >>> list(map(lambda x: x ** 2, [1, 2, 3, 4, 5])) # 使用 lambda 匿名函数 [1, 4, 9, 16, 25] >>>

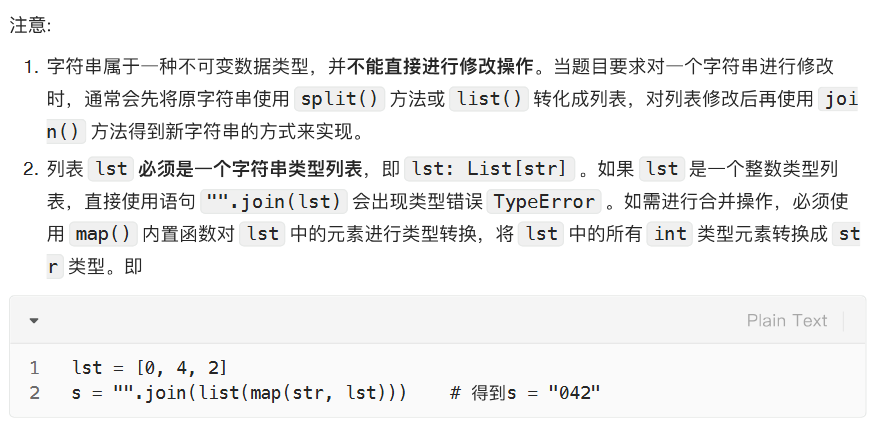
列表与字符串之间的转换
字符串分割为列表 .split()

列表合并为字符串 .join()


ACM模式下列表的输入输出
列表输入



列表输出
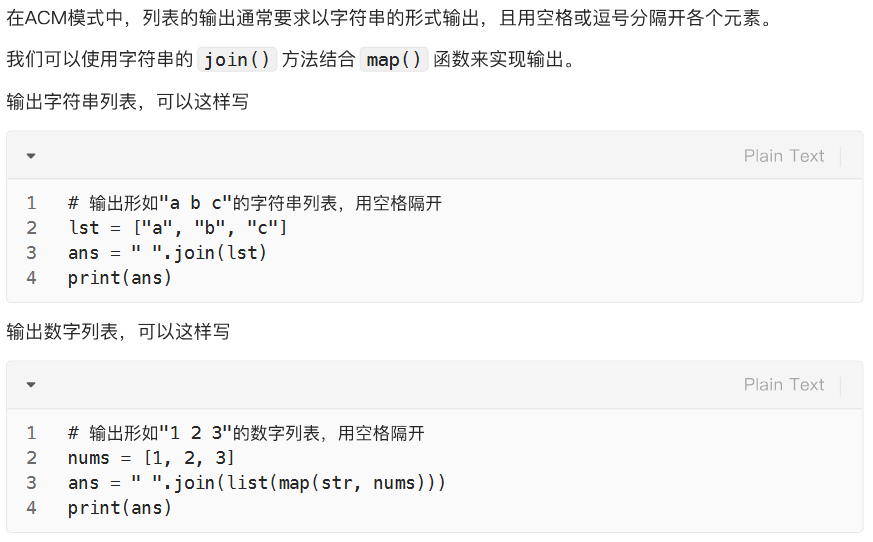
python
list_in = map(int,input().split())
list_in[0] = list_in[-1] = 0
list_out = ''.join(list(map(str, list_in)))
print(list_out)二维列表

二维列表的定义
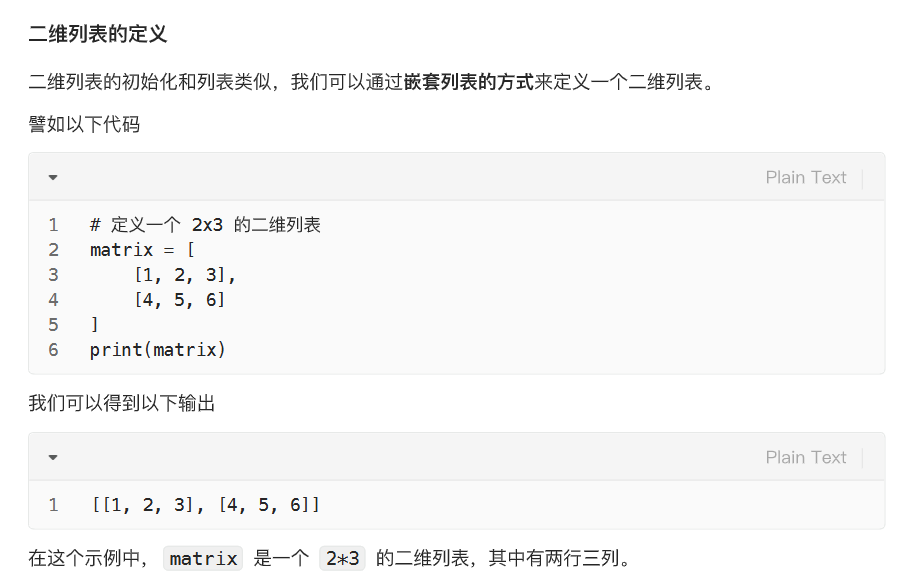
元组
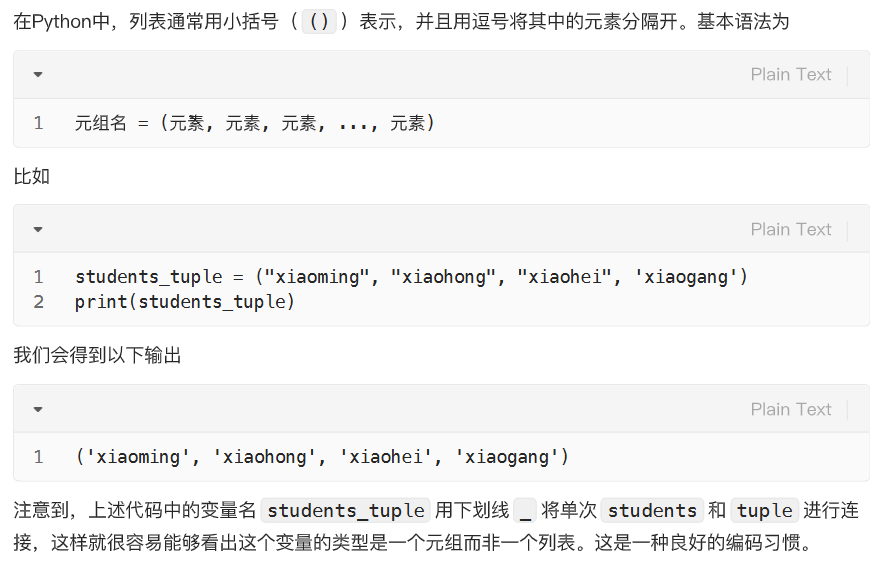
基本格式
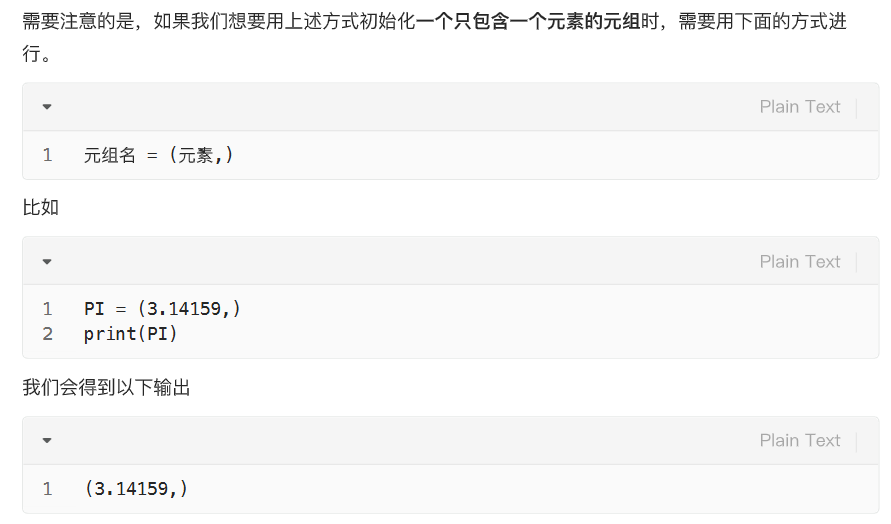
如果尾部不加上逗号:

元组的索引和切片
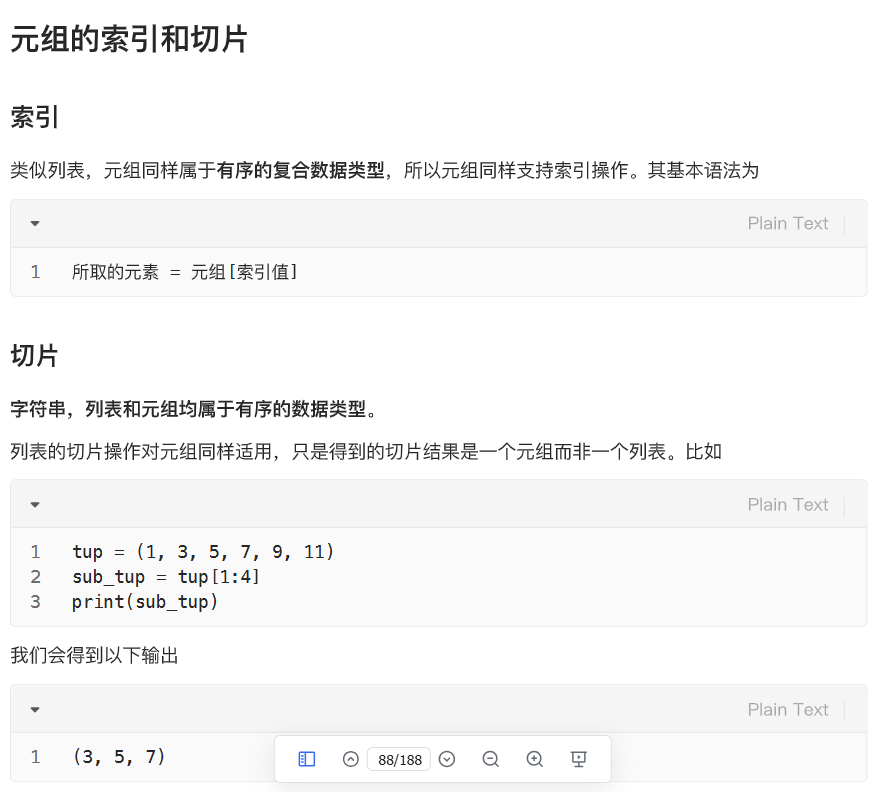
元组的增删改查------转化成列表


函数
形式参数与实际参数



可变参数
除了基础的位置参数、默认参数,可变参数 (*args和**kwargs)更是实战开发中的"高频工具"------它们能让函数接收任意数量的参数,轻松应对不确定输入场景(比如批量处理数据、兼容多版本接口等)。
为什么需要可变参数?
日常编程中,你可能遇到过这样的问题:
- 想写一个"求和函数",但不确定用户会传入2个、3个还是更多数字;
- 想封装一个通用接口调用函数,不同接口的参数名和数量都不一样;
- 想扩展已有函数,不修改原有参数列表的前提下,新增可选项。
如果用普通参数写法,要么需要定义大量默认参数(繁琐且有限),要么直接无法满足需求。而*args和**kwargs正是为解决"参数数量/名称不确定"而生,让函数变得更灵活、更通用。
*args:接收任意数量的"位置参数"
*args 是 "variable-length argument list"(可变长度参数列表)的缩写,核心作用是:让函数接收任意数量的位置参数 ,这些参数会被打包成一个元组(tuple) 供函数内部使用。
- 语法注意:
*是核心标识,args是约定俗成的变量名(可自定义,比如*nums、*values,但建议用args保持可读性)。
1.通用求和函数
需求:写一个函数,能计算任意多个数字的和(1个、2个、10个都可以)。
python
# 用*args实现通用求和
def sum_all(*args):
print("接收的参数打包为元组:", args) # 查看args的类型和内容
total = 0
for num in args:
total += num
return total
# 测试:传入不同数量的参数
print(sum_all(1, 2)) # 传入2个参数 → 输出3
print(sum_all(3, 4, 5)) # 传入3个参数 → 输出12
print(sum_all(10, 20, 30, 40))# 传入4个参数 → 输出100
print(sum_all()) # 传入0个参数 → 输出0(元组为空)
接收的参数打包为元组: (1, 2)
3
接收的参数打包为元组: (3, 4, 5)
12
接收的参数打包为元组: (10, 20, 30, 40)
100
接收的参数打包为元组: ()
02.结合固定参数使用
*args可以和固定位置参数搭配,但要注意:固定参数必须放在*args前面(否则Python无法区分固定参数和可变参数)。
python
# 固定参数(name)+ 可变参数(*args):打印姓名和多个爱好
def print_hobbies(name, *args):
print(f"姓名:{name}")
print("爱好:", end="")
for hobby in args:
print(hobby, end=" ")
print("\n" + "-"*30)
# 测试
print_hobbies("小明", "篮球", "编程", "看电影")
print_hobbies("小红", "画画", "读书")
print_hobbies("小刚") # 可变参数可省略
姓名:小明
爱好:篮球 编程 看电影
------------------------------
姓名:小红
爱好:画画 读书
------------------------------
姓名:小刚
爱好:
------------------------------3.解包元组/列表传入*args
如果已有一个元组或列表,想把其中的元素作为位置参数 传给
*args,可以在传入时加*进行"解包"(避免把整个元组/列表当作一个参数传入)。
python
def multiply(*args):
result = 1
for num in args:
result *= num
return result
# 已有一个列表,想传入函数作为多个参数
nums = [2, 3, 4]
# 错误写法:把整个列表当作一个参数,args = ([2,3,4],)
print(multiply(nums)) # 输出:[2, 3, 4](列表不能直接相乘,实际会报错,这里仅示意)
# 正确写法:用*解包列表,args = (2, 3, 4)
print(multiply(*nums)) # 输出:24(2*3*4)
# 元组同理
nums_tuple = (5, 6)
print(multiply(*nums_tuple)) # 输出:30(5*6)**kwargs:接收任意数量的"关键字参数"
**kwargs 是 "keyword arguments"(关键字参数)的缩写,核心作用是:让函数接收任意数量的关键字参数(key=value形式) ,这些参数会被打包成一个字典(dict) 供函数内部使用。
- 语法注意:
**是核心标识,kwargs是约定俗成的变量名(可自定义,比如**params、**options,建议用kwargs)。 - 关键字参数:传入时必须指定参数名(如
name="张三"),顺序无关。
1.通用配置打印函数
需求:写一个函数,接收任意多个配置项(如
host="localhost"、port=8080),并格式化输出。
python
def print_config(**kwargs):
print("配置项(字典形式):", kwargs)
print("格式化输出:")
for key, value in kwargs.items():
print(f" {key}: {value}")
print("\n" + "-"*30)
# 测试:传入不同数量、不同名称的关键字参数
print_config(host="localhost", port=8080, debug=True)
print_config(username="admin", password="123456", timeout=30)
print_config() # 可省略关键字参数
配置项(字典形式): {'host': 'localhost', 'port': 8080, 'debug': True}
格式化输出:
host: localhost
port: 8080
debug: True
------------------------------
配置项(字典形式): {'username': 'admin', 'password': '123456', 'timeout': 30}
格式化输出:
username: admin
password: 123456
timeout: 30
------------------------------2.结合固定参数和*args使用
**kwargs可以和固定参数、*args搭配,但参数顺序必须严格遵循:
**固定位置参数 → *args → 关键字参数(可固定)→ kwargs
python
# 完整参数顺序示例:固定位置参数 + *args + 固定关键字参数 + **kwargs
def user_info(name, age, *hobbies, gender="未知", **other_info):
print(f"基本信息:姓名={name},年龄={age},性别={gender}")
print(f"爱好:{hobbies if hobbies else '无'}")
print(f"其他信息:{other_info if other_info else '无'}")
print("-"*50)
# 测试
user_info("小明", 20, "篮球", "编程", gender="男", address="北京", phone="123456")
user_info("小红", 18, "画画", "读书", school="XX大学") # 省略gender和other_info
user_info("小刚", 22) # 仅传固定位置参数3.解包字典传入**kwargs
如果已有一个字典,想把其中的键值对作为关键字参数 传给
**kwargs,可以在传入时加**进行"解包"。
python
def register(username, password, **kwargs):
print(f"注册成功:用户名={username},密码={password}")
for key, value in kwargs.items():
print(f" 额外信息:{key}={value}")
# 已有一个字典存储额外信息
extra_info = {"email": "test@xxx.com", "phone": "654321", "vip": True}
# 解包字典传入**kwargs
register("admin", "123456", **extra_info)函数嵌套中的*args和**kwargs
*args和**kwargs在函数嵌套(比如封装第三方库函数、自定义装饰器)中非常实用,能实现"参数透传"(不修改中间函数,直接把参数传给内部函数)。案例:封装requests.get函数
需求:封装一个HTTP请求函数,默认添加超时配置,同时支持用户传入任意请求参数(如headers、params)。
python
import requests
def my_get(url, *args, timeout=10, **kwargs):
"""封装requests.get,默认超时10秒,支持任意额外参数"""
try:
# 透传*args和**kwargs到requests.get
response = requests.get(url, *args, timeout=timeout, **kwargs)
response.raise_for_status() # 抛出HTTP错误
return response.text
except Exception as e:
return f"请求失败:{str(e)}"
# 测试:传入自定义headers和params(通过**kwargs透传)
headers = {"User-Agent": "Mozilla/5.0"}
params = {"key": "python", "page": 1}
result = my_get("https://httpbin.org/get", headers=headers, params=params)
print(result)lambda匿名函数

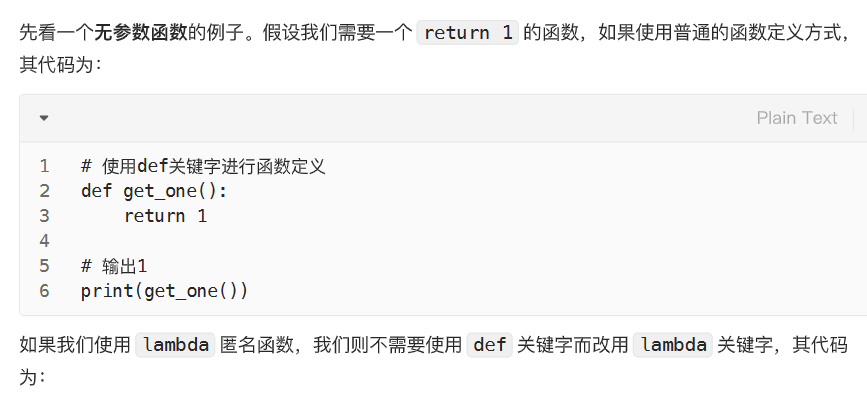
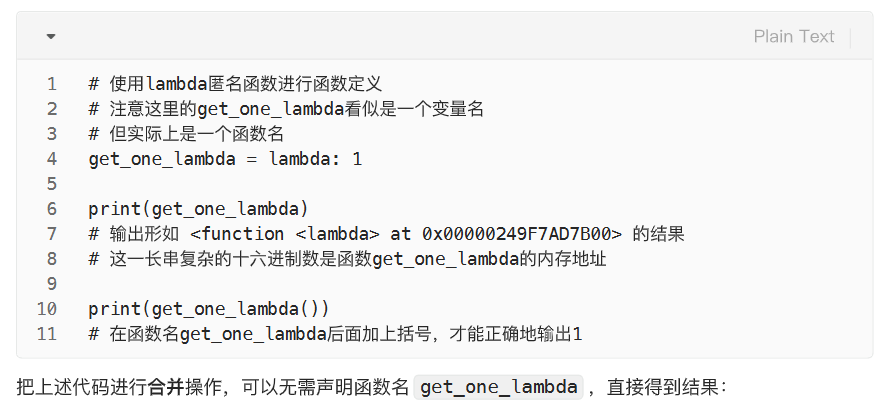
无参数的lambda函数

有参数的lambda函数


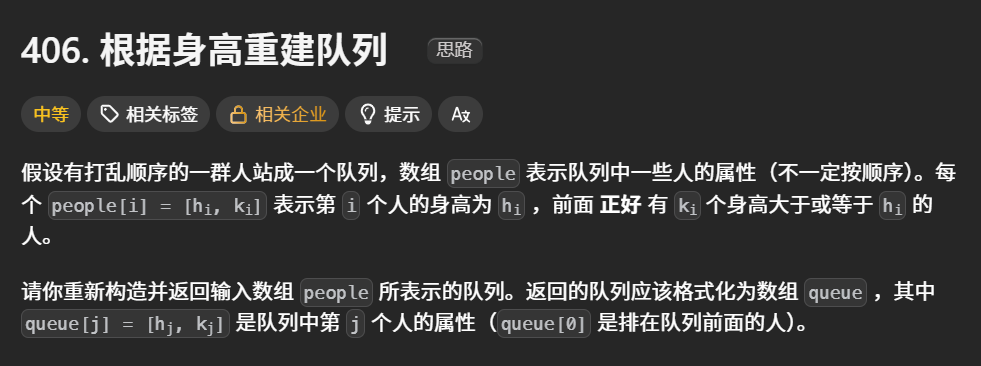
406.根据身高重建队列
首先考虑在一个维度上排序,对高度降序排序,然后对k升序排序。然后遍历people数组,可以确定先加入的都很高,对后面加入的不产生影响,又因为先加入的一定高或等于后加入的,考虑其k参数,也即前面有几个高或相同的,插入到第i位置即可
pythondef reconstructQueue(self, people: List[List[int]]) -> List[List[int]]: people.sort(key=lambda x:(-x[0],x[1])) queue = []Lambda 函数的作用解析
代码中的排序语句是
people.sort(key=lambda x: (-x[0], x[1]))。这里的lambda匿名函数定义了排序的关键规则。
参数
x:代表people列表中的每一个元素,即每个形如[h, k]的二元列表,其中h是身高,k是排在该人前面且身高大于或等于h的人数。返回值
(-x[0], x[1]):这是一个元组,它告诉sort方法如何比较两个元素。Python 在比较两个元组时,会按顺序比较元组内的各个元素。
**
-x[0](即-h)** :首先,按身高h的降序 进行排列。通过在身高前加负号,原本的降序需求(高个子在前)就转化为了对-h的升序(数值越小,负数的绝对值越大,代表身高越高)。这是算法的核心技巧。**
x[1](即k)** :当两人的身高h相同时,则按照k的升序进行排列。
数据类型的可变性

可变与不可变数据类型的引用与拷贝

可变数据类型的浅拷贝 .copy()

这里就像在回溯问题里面,找到了结果之后要加入out.copy或者list(out)或者切片的道理,进行一个浅拷贝,仅仅记录此时的内容
可变数据类型的深拷贝 .deepcopy()



数据类型的可变性对函数的影响

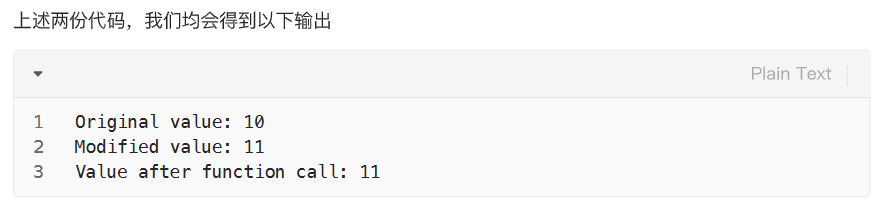
不可变参数类型的影响
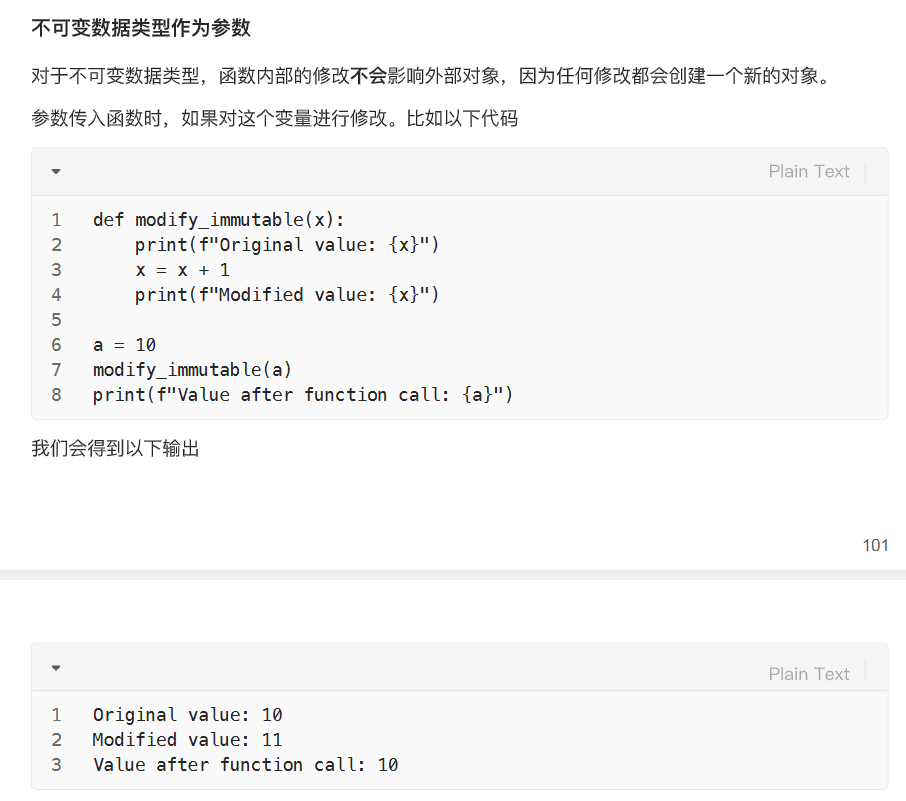

那么应该如何修改呢?有两种方法,第一种是通过函数返回值修改赋值,第二种是给定global关键字,对于不可变数据类型变量声明为全局变量,且无需进行参数传递


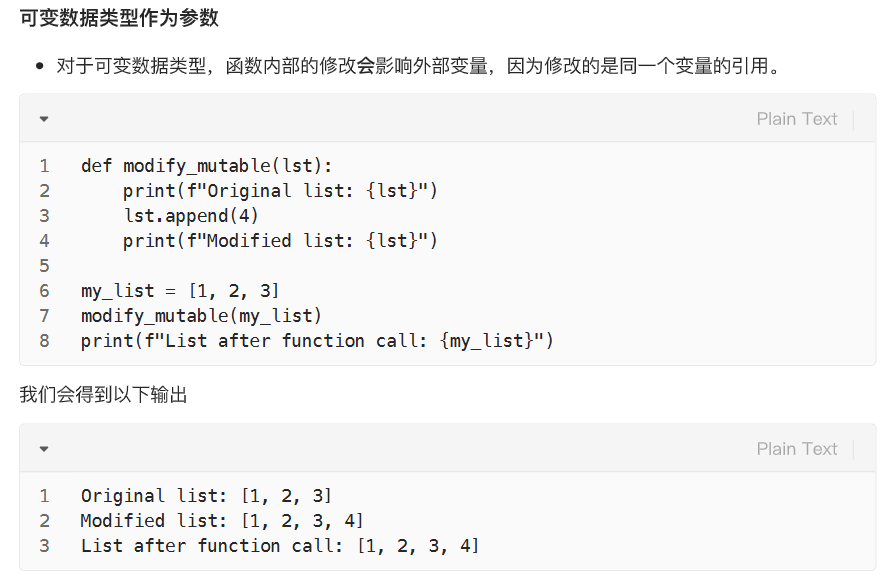
可变参数类型的影响
python中的推导式

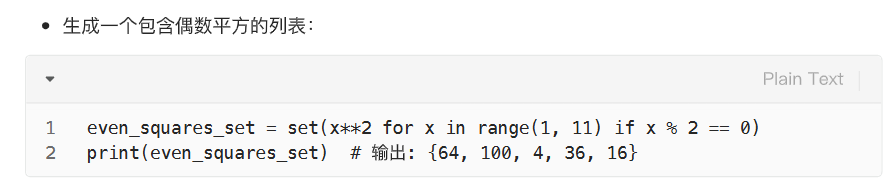
列表推导式
常用的二维数组构建方法就利用了推导式
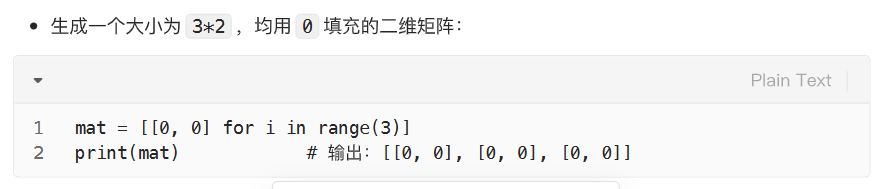
有条件的列表推导式

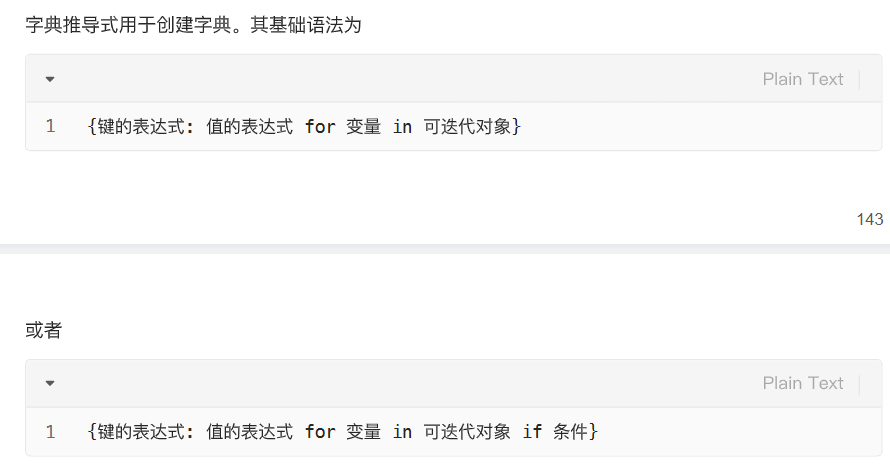
字典推导式

这道题曾经用到过
last = {c:i for i,c in enumerate(s)}
创建一个字典,用于记录字符串
s中每个字符 最后一次出现的位置索引。字典的一个核心特性是:同一个键只能出现一次 。如果同一个键被多次赋值,后面的值会 覆盖 前面的值
**
enumerate(s)**这是关键的第一步。
enumerate()是 Python 的内置函数,它会接收一个可迭代对象(比如字符串、列表),并返回一个枚举对象。这个对象可以在循环中产生由 索引 和 对应的元素值 组成的元组。例如,对于字符串s = "abc",enumerate(s)会生成类似这样的序列:(0, 'a'),(1, 'b'),(2, 'c')。**
for i, c in enumerate(s)**这是一个循环语句,用于遍历
enumerate(s)产生的元组序列。在每次循环中:
i(index) 被赋值为当前的索引(从 0 开始)。
c(character) 被赋值为当前索引对应的字符。**
c:i**这定义了字典的 键值对 。它表示用循环得到的字符
c作为字典的 键 ,用对应的索引i作为该键的 值。**字典推导式
{c:i for i,c in enumerate(s)}**将以上部分组合起来,其执行逻辑是:遍历字符串
s的每一个位置,将每个字符c和它当时的位置索引i组成一个键值对c:i,并放入新字典中。
学习一点0x3f先进思路:「同一字母最多出现在一个片段中」意味着,一个片段若要包含字母 a,那么所有的字母 a 都必须在这个片段中。
s=ababcbacadefegdehijhklij,其中字母 a 的下标在区间 0,8 中,那么包含 a 的片段至少要包含区间 0,8。
字母 下标 下标区间
a 0,2,6,8 0,8
b 1,3,5 1,5
c 4,7 4,7
d 9,14 9,14
e 10,12,15 10,15
f 11 11,11
g 13 13,13
h 16,19 16,19
i 17,22 17,22
j 18,23 18,23
k 20 20,20
l 21 21,21
(0, 'a'), (1, 'b'), (2, 'a'), (3, 'b'), (4, 'c'), (5, 'b'), (6, 'a'), (7, 'c'), (8, 'a'), (9, 'd'), (10, 'e'), (11, 'f'), (12, 'e'), (13, 'g'), (14, 'd'), (15, 'e'), (16, 'h'), (17, 'i'), (18, 'j'), (19, 'h'), (20, 'k'), (21, 'l'), (22, 'i'), (23, 'j')
pythonclass Solution: def partitionLabels(self, s: str) -> List[int]: last = {c:i for i,c in enumerate(s)} res = [] start = end =0 for i,c in enumerate(s): end = max(end, last[c]) if i == end: res.append(end-start+1) start = i+1 return res
集合推导式

集合与字典

集合

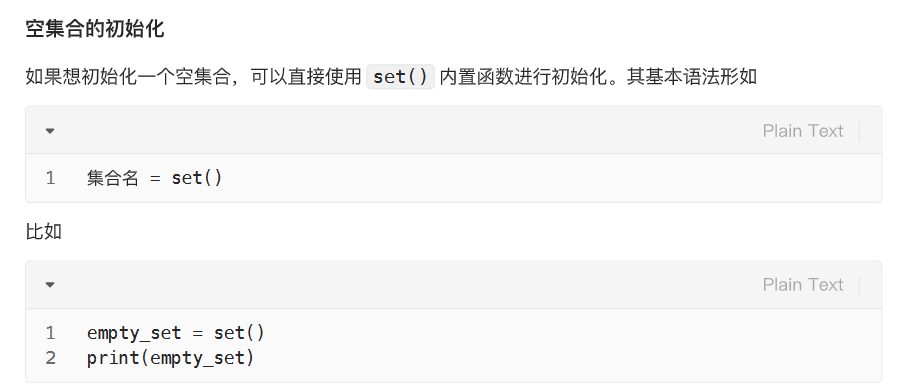
集合的增删改查
查: in


增: add()

删: remove()
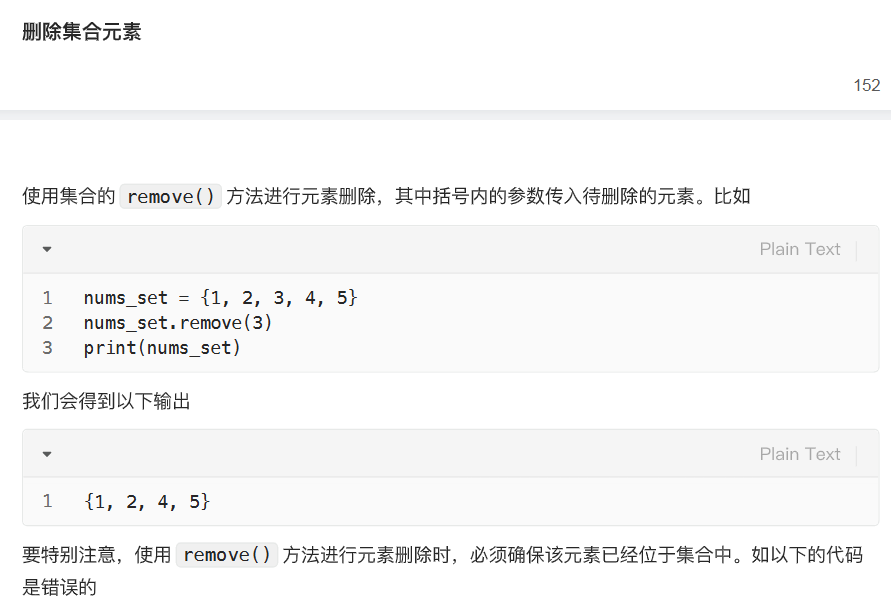
改: 借助add和remove

字典

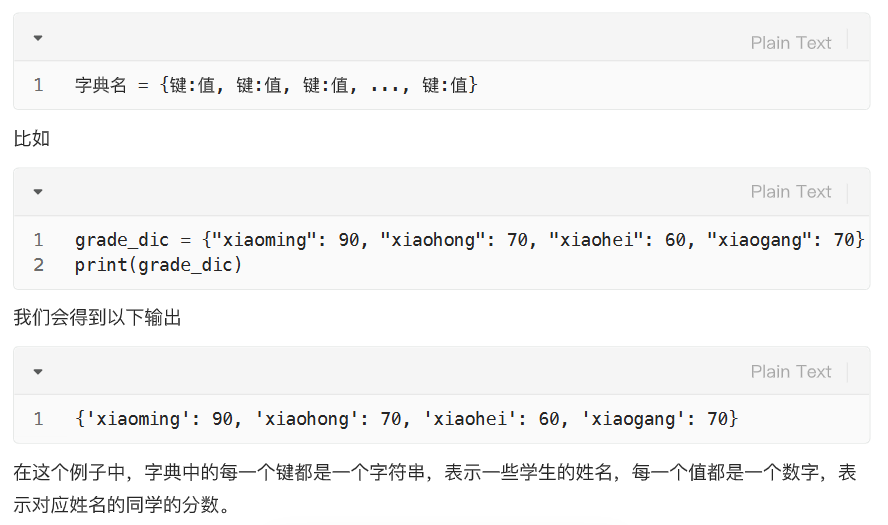

字典的增删改查
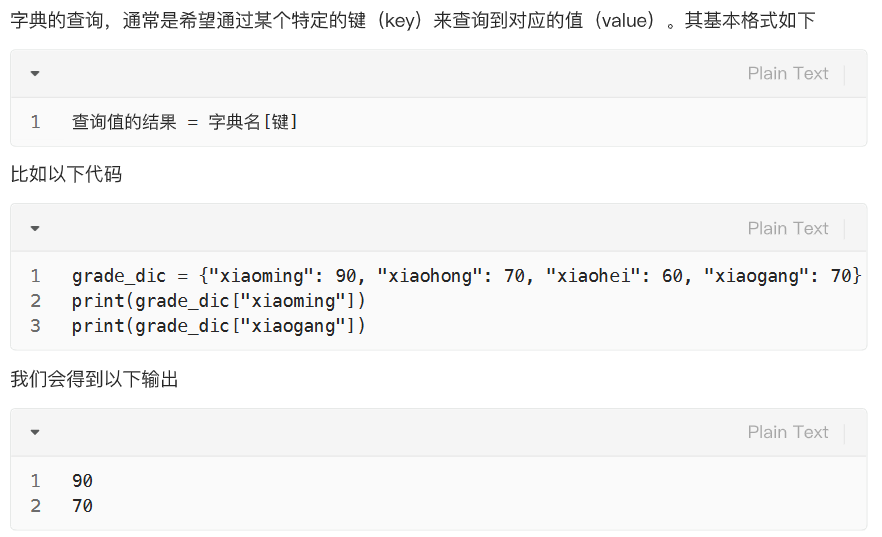
查: 查值 ------ 字典名键 = 值 查键 ------ in
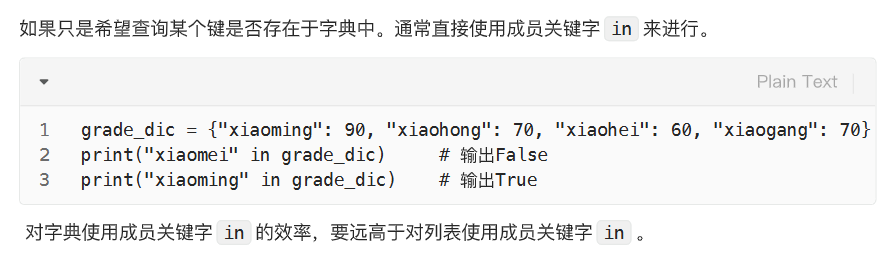
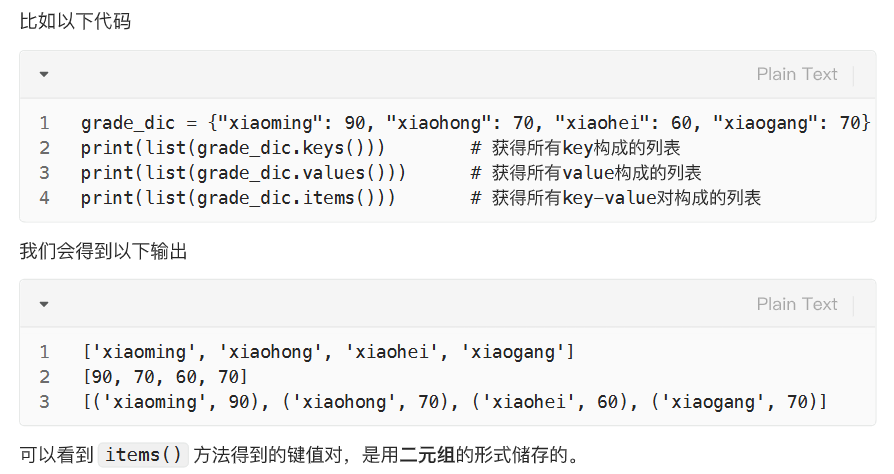
遍历方法


使用字典名或字典名.keys 取键
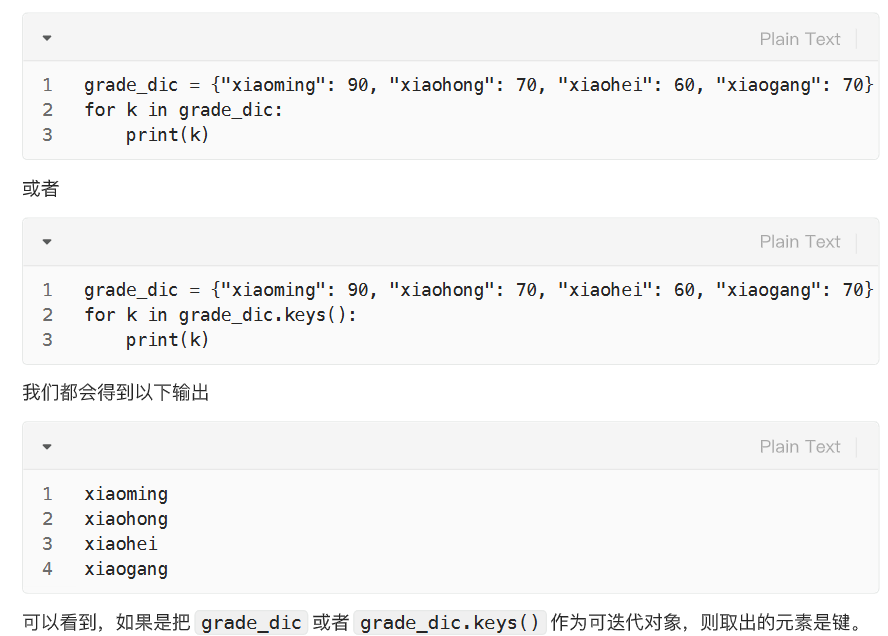
使用字典名.values 取值
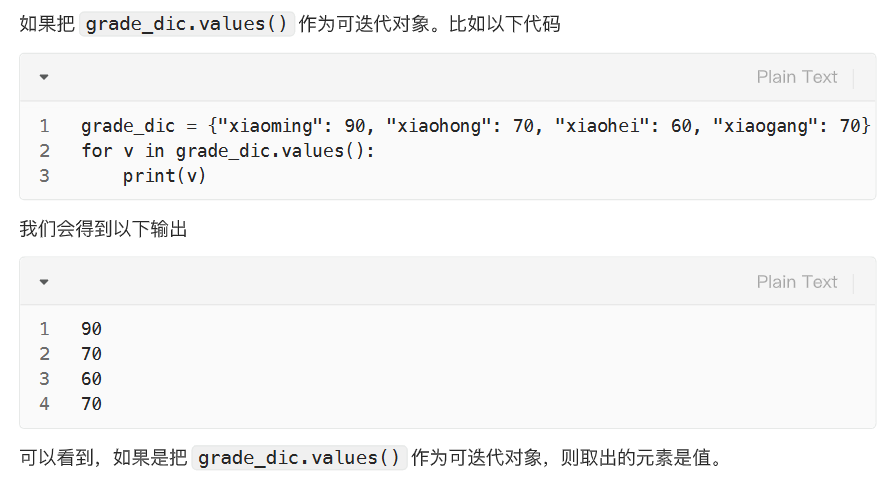
使用字典名.items 取值
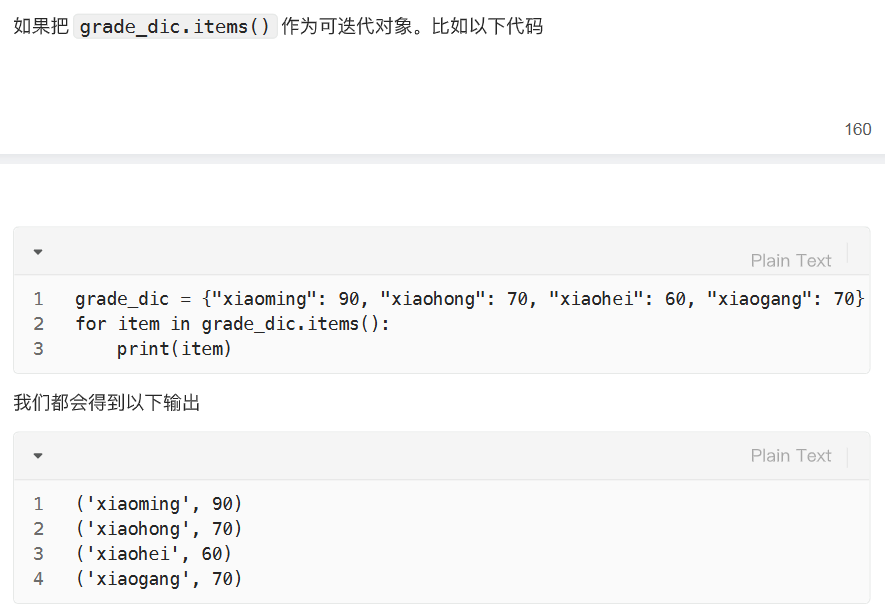
循环获取键和值
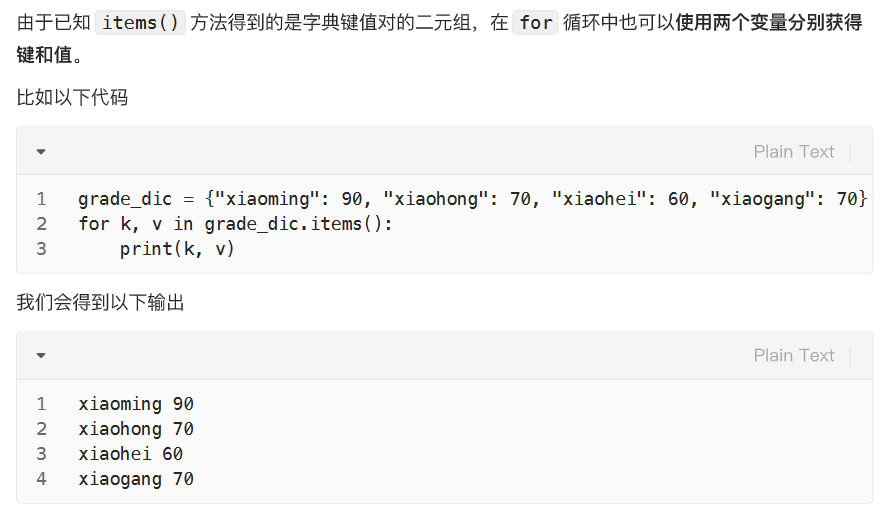
python
book = {"笔记本":10, "高级笔记本":50, "文件夹":7}
for i, j in enumerate(book):
print(i, j)增/改 字典元素


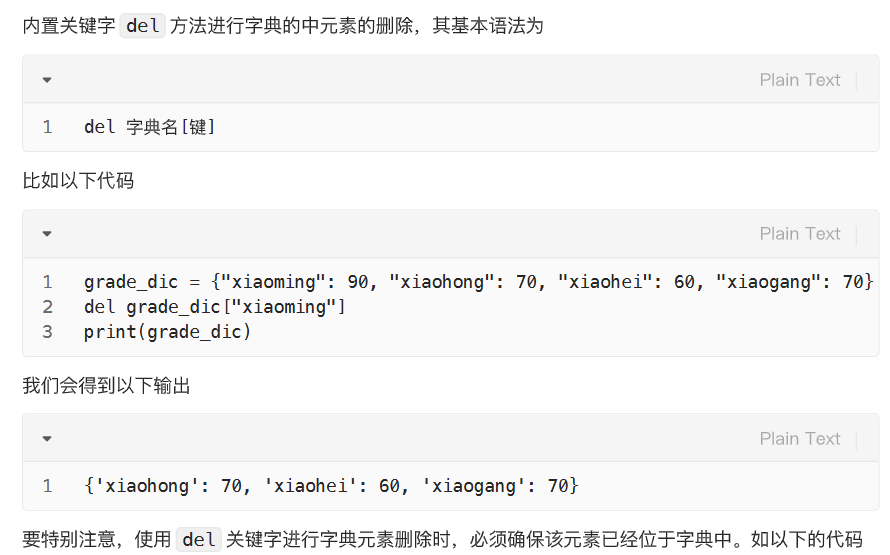
删: del
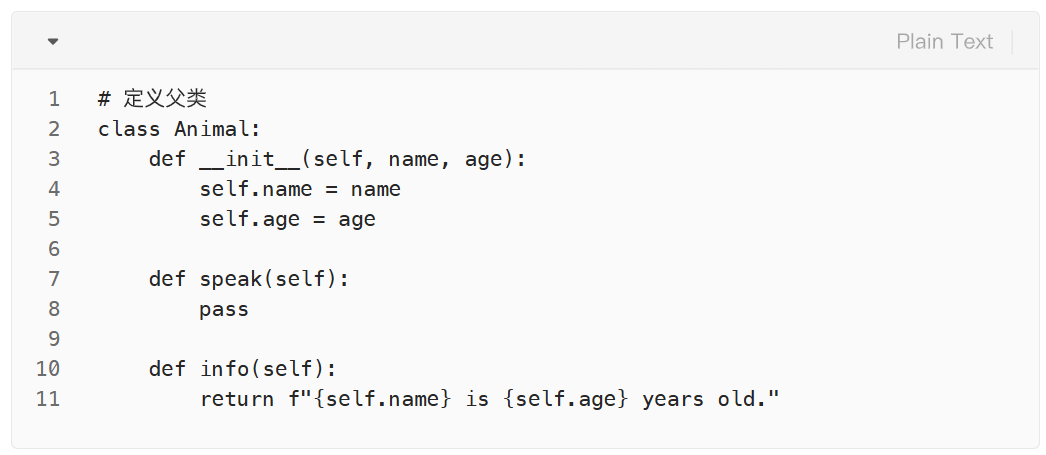
面向对象编程来了
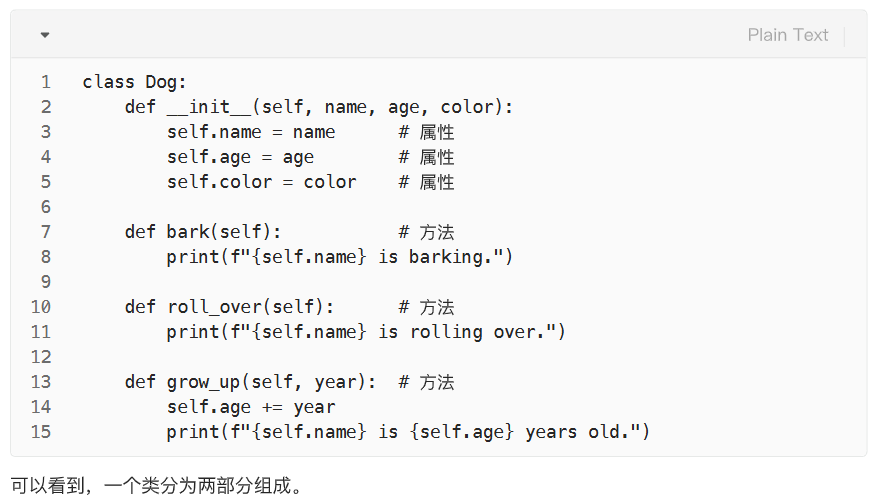
类的组成

类的基础语法
类的定义
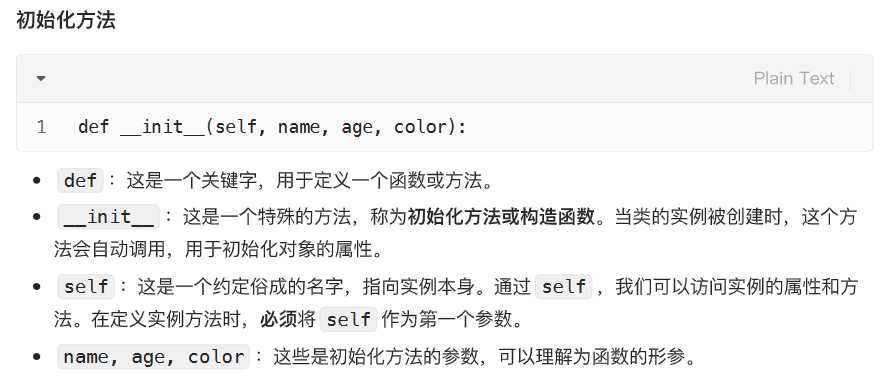
类的初始化方法
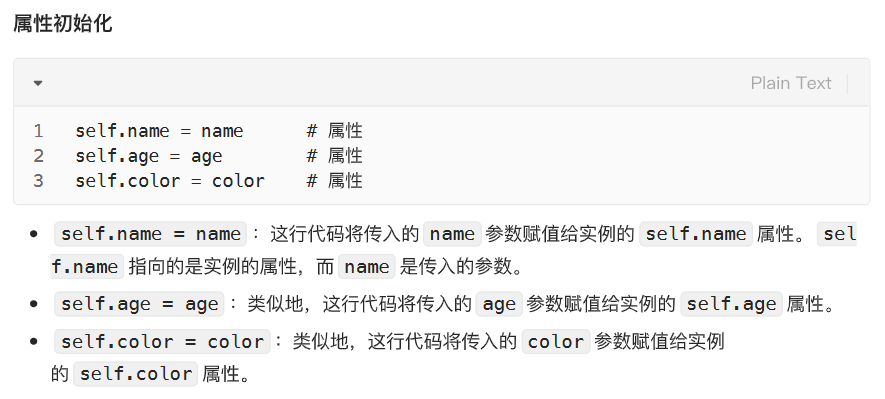
类的属性初始化
类的方法定义

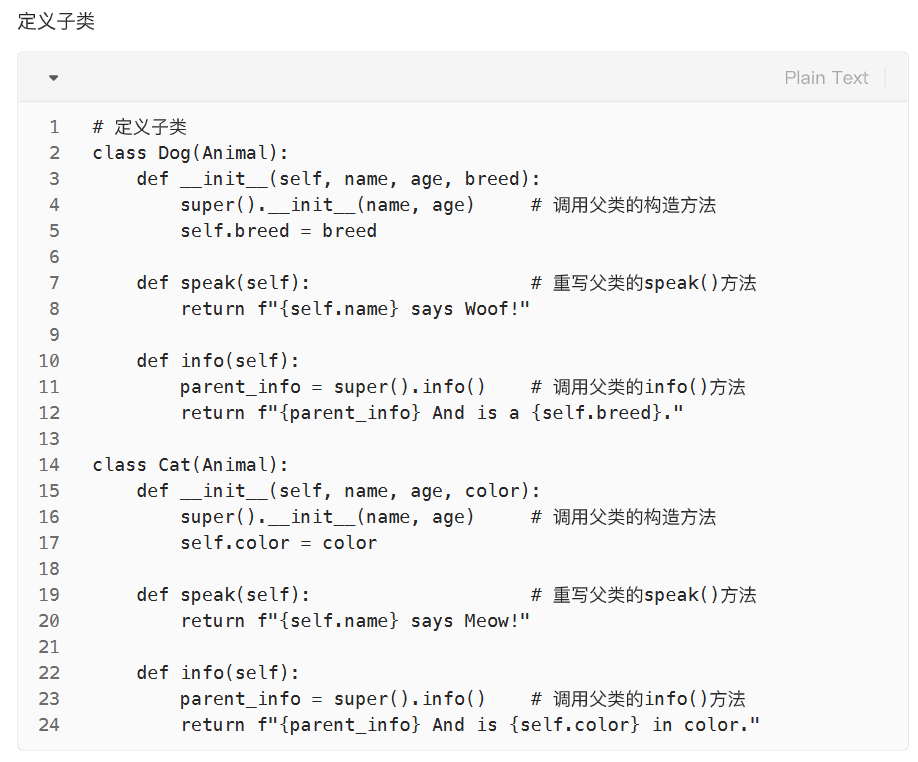
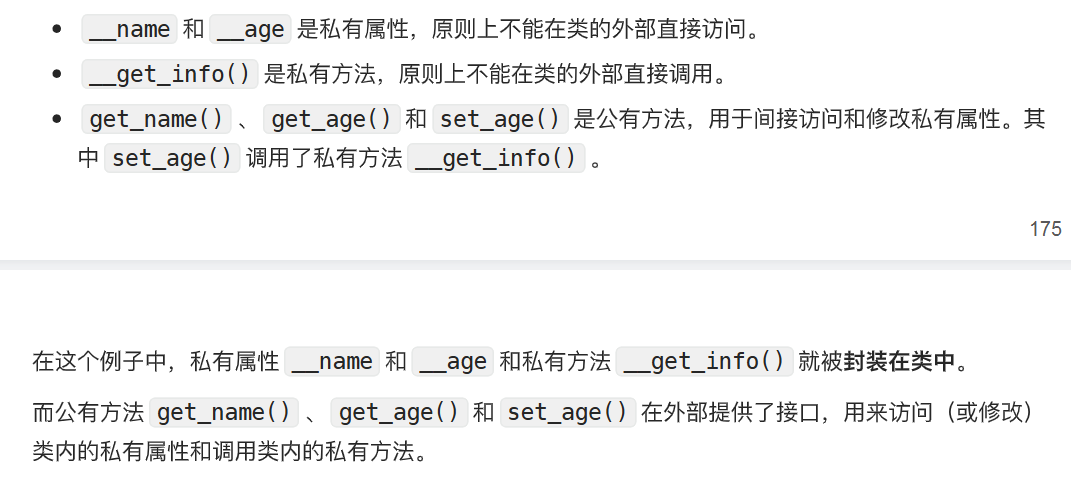
类的公有和私有成员




继承与多态