一、概述
车牌识别是上课时老师给出的作业,刚好自己正在学yolo和pytorch,因此在老师的基础上进行一个拓展和衍生。
目前来说,由于要交作业的情况,模型的大体已经完成,但是由于老师给的数据集和测试机都相对简单,不能很好的适应生产,因此在提交作业后,我继续对该模型进行深入。
我将这次实验分为三个部分--车牌识别、字符识别、嵌入式端部署,本文目前是对车牌的车框进行识别。
二、模型建立
在模型建立中,对于识别车框的问题,我了解的主流方法是HBB、OBB、SEG等方法,但是HBB主要是对于水平框进行定位检测,其没有办法很好的识别旋转框,而SEG分割虽然可以很好的适用旋转,但是其主要用于多边形,甚至于不规则物体,而我们是确定车牌的识别是矩形框,因此使用SEG增加了复杂度以及计算量,这里便选择了OBB方法。
对于模型的选择,目前的主流是yolo、Faster R-CNN、MobileNet+SSD,其中Faster R-CNN精度最高,但是速度最慢,部署最困难,而MobileNet+SSD精度相对较低,但是速度最快,部署最为容易,yolo相对于上述两个模型来说,精度低于Faster R-CNN,但是高于MobileNet+SSD,速度和部署的困难度高于Faster R-CNN,但是低于MobileNet+SSD,由于我想将这个模型部署到树莓派上,但是又不太想丢失精确度,因此选用yolo模型。
| 模型 OBB 版本 | 精度 | 推理速度 | 轻量化程度 | 适合场景 |
|---|---|---|---|---|
| Faster R-CNN-OBB | 顶尖 | 极慢 | 差 | 静态图片、高精度卡口抓拍(非实时) |
| MobileNet+SSD-OBB | 中等 | 较快 | 极致 | 超低算力设备、轻度倾斜车牌 |
| YOLOv8-OBB(官方支持) | 高 | 快 | 中等 | 嵌入式实时视频流、复杂倾斜车牌 |
还有就是yolo的生态更好一些,Faster R-CNN、MobileNet+SSD,尤其是MobileNet+SSD,虽然都是开源的,而Faster R-CNN在pytorch也属于内置函数,但是都不如yolo方便。
| 模型 / 组合 | 能否直接调用 | 开箱即用便捷性 | OBB 支持难度 | 车牌定位适配成本 |
|---|---|---|---|---|
| YOLOv8 | 是(官方工具包) | 极高(一站式) | 低(官方支持) | 极低 |
| Faster R-CNN | 是(torchvision) | 中等(基础检测) | 高(需二次改造) | 中等 |
| MobileNet + SSD | 是(开源复用) | 低(需组合 / 适配) | 很高(需大量改造) | 高 |
最后确定模型选取yolov8n-OBB,对于yolo的其他版本,其实v11相对更好一些,其体积和精确度在理论上都相对好一些(理论上是因为师姐做的项目在对比v11和v8时,发现v8更好一些),但是yolo目前又推出了v26,其专门用于嵌入式端的部署

因此后续等v26成熟一些后,大概会适用v26进行一个部署,本次实验便选取的v8。
至于n、s等v8的内部系列,嵌入式部署一定选用轻量化,因此也是毫无疑问的选取v8n作为本次实验的主要模型。
三、数据集
对于车牌的识别,我们需要大量车牌的数据集,由于网上大多都有,因此不需要自己额外标注,这里我选择CCPD+CRPD,而CCPD我找到了两个数据集(代码所用的数据集网址均在下面标出)

 第一张是CCPD2019中的数据集,而第二张是CCPD_GREEN的数据集,由于生活中大多以蓝色车牌为主,而CCPD2019的车牌大多为蓝色车牌,因此以CCPD2019作为主要数据集,而CCPD_GREEN和CRPD用于微调
第一张是CCPD2019中的数据集,而第二张是CCPD_GREEN的数据集,由于生活中大多以蓝色车牌为主,而CCPD2019的车牌大多为蓝色车牌,因此以CCPD2019作为主要数据集,而CCPD_GREEN和CRPD用于微调
四、处理数据集
该文件名为prepare_obb.py。加上后续的微调,一共需要处理三次数据集,由于三次数据集的处理方法大概相同,因此以第一次的数据集为主要讲解,下述为第一次数据集的处理代码
import os
import cv2
import random
import shutil
kaggle_img_path = './CCPD2019/' # 训练集和验证集的根目录
imgs_path = ['ccpd_base', 'ccpd_blur', 'ccpd_challenge', 'ccpd_db', 'ccpd_fn', 'ccpd_np', 'ccpd_rotate', 'ccpd_tilt', 'ccpd_weather'] # 训练集和验证集
output_dir = './datasets/CCPD_YOLO/' # 将普通格式转化为OBB格式后数据储存的根目录
def process_files(file_list, type):
"""原始数据集处理"""
for src_path in file_list:
filename = os.path.basename(src_path) # 获取图像的文件名
# 解析文件名
points = filename.split('-')
if len(points) == 1:
txt_filename = filename.replace('.jpg', '.txt')
txt_path = os.path.join(output_dir, f'labels/{type}', txt_filename)
with open(txt_path, 'w') as f:
pass
elif len(points) >= 4:
points = points[3]
point = points.split('_')
p1 = point[0].split('&')
p2 = point[1].split('&')
p3 = point[2].split('&')
p4 = point[3].split('&')
# 提取矩形四个顶点坐标
x1, y1 = int(p1[0]), int(p1[1]) # 右下角坐标
x2, y2 = int(p2[0]), int(p2[1]) # 左下角坐标
x3, y3 = int(p3[0]), int(p3[1]) # 左上角坐标
x4, y4 = int(p4[0]), int(p4[1]) # 右上角坐标
# 读取图片获取宽高
img = cv2.imread(src_path)
if img is None:
print(f"无法读取图像:{filename}")
continue
h_img, w_img, _ = img.shape
# 归一化为OBB格式
obb = [x1 / w_img, y1 / h_img, x2 / w_img, y2 / h_img, x3 / w_img, y3 / h_img, x4 / w_img, y4 / h_img]
label_line = f"0 {obb[0]:.6f} {obb[1]:.6f} {obb[2]:.6f} {obb[3]:.6f} {obb[4]:.6f} {obb[5]:.6f} {obb[6]:.6f} {obb[7]:.6f}\n"
# 将OBB数据集写入txt文本中
txt_filename = filename.replace('.jpg', '.txt')
txt_path = os.path.join(output_dir, f'labels/{type}', txt_filename)
with open(txt_path, 'w') as f:
f.write(label_line)
# 复制图片
dst_img_path = os.path.join(output_dir, f'images/{type}', filename)
shutil.copy(src_path, dst_img_path)
print(f'{filename}图片转化成功')
print(f"{type}数据集处理完成。")
def process_img(kaggle_path, num):
"""对CCPD2019中多个文件夹的文件进行处理"""
all_images = []
# 开始处理
print(f"开始处理{kaggle_path}")
images = os.listdir(kaggle_path) # 读取该文件夹中所有文件的文件名
images = random.sample(images, min(len(images), num)) # 打乱数据避免数据集的相似导致模型的死记硬背从而降低验证集的正确率
for f in images:
if f.endswith('.jpg'): # 遍历文件名,找出以.jpg结尾的图像文件
files = os.path.join(kaggle_path, f) # 读取该图像的文件名
all_images.append(files) # 将图像添加进all_images
print(f"遍历{kaggle_path}完成,共找到{len(all_images)}张图片")
# 按照九一交叉验证的方法划分训练集和验证集
l = int(len(all_images) * 0.9)
train_image = all_images[0:l]
val_image = all_images[l:]
print(f"{kaggle_path}训练集创建完成,训练集: {len(train_image)}张")
print(f"{kaggle_path}验证集创建完成,验证集: {len(val_image)}张")
return train_image, val_image
def convert_ccpd_to_obb():
"""数据集转化为yolo格式"""
# 创建YOLO目录结构
for split in ['train', 'val']:
os.makedirs(f'{output_dir}/images/{split}', exist_ok=True)
os.makedirs(f'{output_dir}/labels/{split}', exist_ok=True)
train_images =[]
val_images =[]
# 遍历文件夹,收集所有图片
for img_path in imgs_path:
kaggle_path = os.path.join(kaggle_img_path, img_path) # 读取kaggle数据集的目录名字
# ccpd_base基础、ccpd_blur模糊、ccpd_challenge挑战、ccpd_db双层车牌、ccpd_rotate旋转取10000张图像
if img_path in ['ccpd_base', 'ccpd_blur', 'ccpd_db', 'ccpd_rotate']:
train_image, val_image = process_img(kaggle_path, 10000)
train_images = train_image + train_images
val_images = val_image + val_images
# ccpd_fn远距离、ccpd_np无车牌取5000张图像
elif img_path in ['ccpd_fn', 'ccpd_np']:
train_image, val_image = process_img(kaggle_path, 5000)
train_images = train_image + train_images
val_images = val_image + val_images
# ccpd_tilt倾斜取20000张图像
elif img_path in ['ccpd_tilt']:
train_image, val_image = process_img(kaggle_path, 20000)
train_images = train_image + train_images
val_images = val_image + val_images
# ccpd_weather天气取9000张图像
elif img_path in ['ccpd_weather']:
train_image, val_image = process_img(kaggle_path, 9000)
train_images = train_image + train_images
val_images = val_image + val_images
# ccpd_challenge挑战取8000张图像
elif img_path in ['ccpd_challenge']:
train_image, val_image = process_img(kaggle_path, 8000)
train_images = train_image + train_images
val_images = val_image + val_images
# 打乱数据避免模型的死记硬背
random.shuffle(train_images)
random.shuffle(val_images)
print(f"训练集创建完成,训练集: {len(train_images)}")
print(f"验证集创建完成,验证集: {len(val_images)}")
print(f"开始转化数据")
process_files(train_images, 'train')
process_files(val_images, 'val')
print("所有数据转换完成")
if __name__ == '__main__':
convert_ccpd_to_obb()首先创建yolo的目录格式,其中数据集保存在'./datasets/CCPD_YOLO/'文件下,该文件包含训练集和验证集。然后通过遍历数据集得出所有的文件名,并通过九一交叉验证的方法将数据集分为训练集和验证集。最后便是对于将该数据标定好的信息转化为OBB数据集。(没啥好讲的,比较基础,代码中的注释也还算清楚,因此这里大概讲解一下便略过了)
针对于CCPD数据集中文件名的坐标信息如下:选取第一张图像的名字作为讲解025-95_113-154&383_386&473-386&473_177&454_154&383_363&402-0_0_22_27_27_33_16-37-15.jpg。每个名称都可以拆分成七个字段。
|-------------|-------------------------------------|-----------------------------------------|
| 字段(按照'-'分割) | 值 | 含义 |
| 第一段 | 025 | 车牌区域与整个图片区域的面积比值 |
| 第二段 | 95_113 | 水平倾斜度和垂直倾斜度 |
| 第三段(边框位置) | 154&383_386&473 | 左上角和右下角顶点的坐标 |
| 第四段(矩阵四角位置) | 386&473_177&454_154&383_363&402 | LP 在整个图像中四个顶点的精确(x,y)坐标。这些坐标从右下角的顶点开始计算 |
| 第五段(车牌号码) | 0_0_22_27_27_33_16 | 有效的中国车牌由七个字符组成 |
| 第六段(亮度) | 37 | 车牌区域的亮度 |
| 第七段(模糊度) | 15 | 车牌区域的模糊程度 |
而OBB数据集的标准形式根据yolo提供的官方文档中所示:

其中数据集为ccpd_obb.yaml是Ultralytics框架下定义用于训练旋转框检测模型的数据集和模型配置。其标准格式如下:
五、训练模型
5.1 训练
该文件名为train_obb.py。由于ccpd_sample数据集中数据过多,因此会使用cuda进行加速,首先检查cuda,同时选取使用的GPU,然后加载yolov8n-obb.pt模型,最后对模型进行训练。
而针对于模型的训练使用的代码如下
model.train(
data='ccpd_obb.yaml',
epochs=100,
patience=50, # 50轮不提升则早停
imgsz=640,
batch=16, # 4070 跑 640 分辨率,batch 可以设为 32 甚至 64 以加速
device=device,
workers=8,
close_mosaic=10, # 最后10轮关闭增强,进行高精度微调
cos_lr=True, # 余弦学习率衰减
optimizer='AdamW', # AdamW 对 OBB 模型的收敛通常比默认的 SGD 更稳
amp=True, # 开启自动混合精度训练,极大提升 4070 的训练速度
project='runs/obb',
name='yolo8_ccpd_optimized',
exist_ok=True # 如果名字相同,直接覆盖/继续
)由于嵌入式的算力有限,不适合适用1024的尺寸接受图像,因此丢失一些信息选取640以适配嵌入式的算力。如果还是不行的话,则再往下降,但是降得越多,丢失的信息也越多,训练出来的模型也相对不太好。
close_mosaic=10这一参数是指在最后10轮训练中关闭马赛克增强,而所谓的马赛克增强,其核心目的是提升模型的泛化能力,即让模型适应更多样的环境。启用马赛克增强可以将四五张图像缩放、裁剪、拼接等方法合成为一张图像,这样可以使模型在大局在掌握标注框的特点,后面关闭马赛克增强是因为其在合成为一张图像时会产生一定的噪声,这样会不利于模型检测的精细化。
优化器的选择为yolo中obb模型的默认优化器--AdamW,其结合了自适应学习率和L2正则化,收敛速度最快,对角度回归的梯度震荡有较好的抑制效果,但是精度不如SGD,这里为了训练的速度选取AdamW。
amp是指自动混合精度训练,开启后可以大幅降低显存的占用,同时提升学习效率,并且不会损失模型的精度。
5.2 训练结果
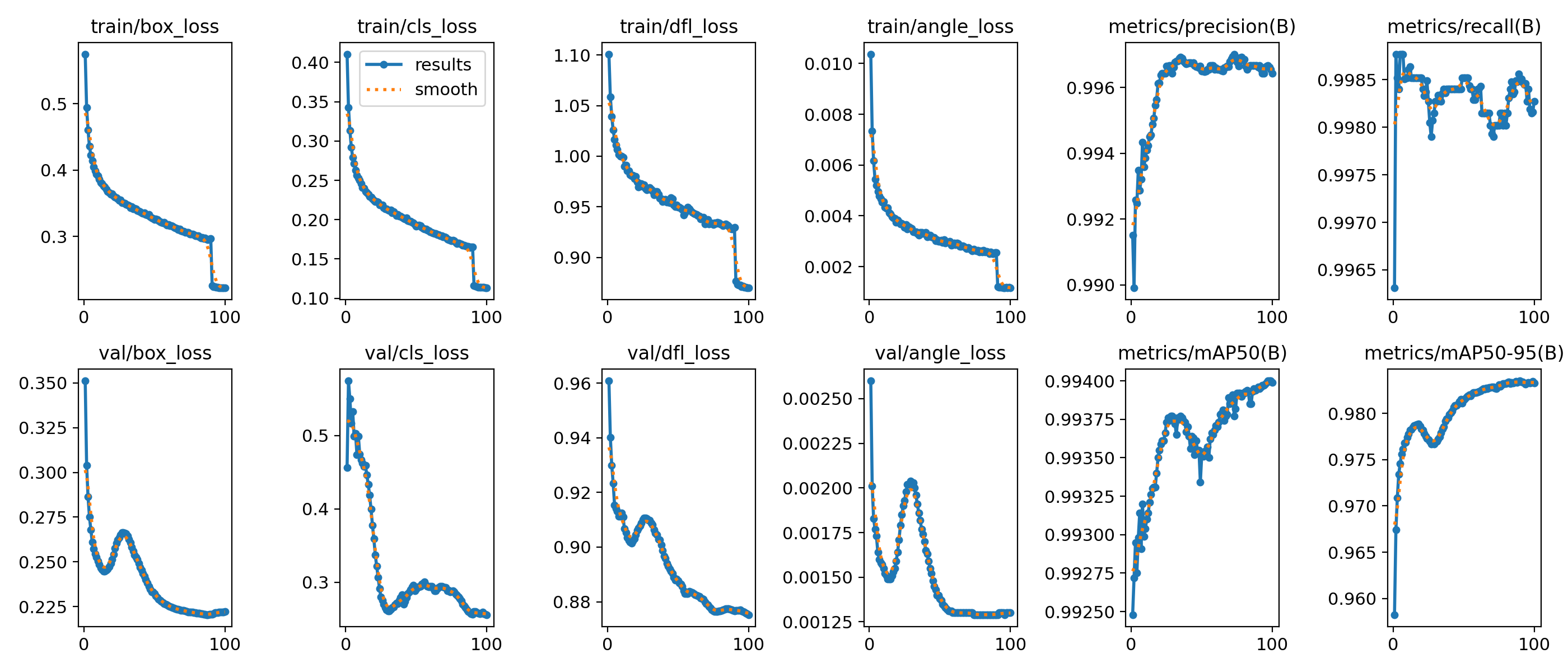
以下是第一次训练的结果
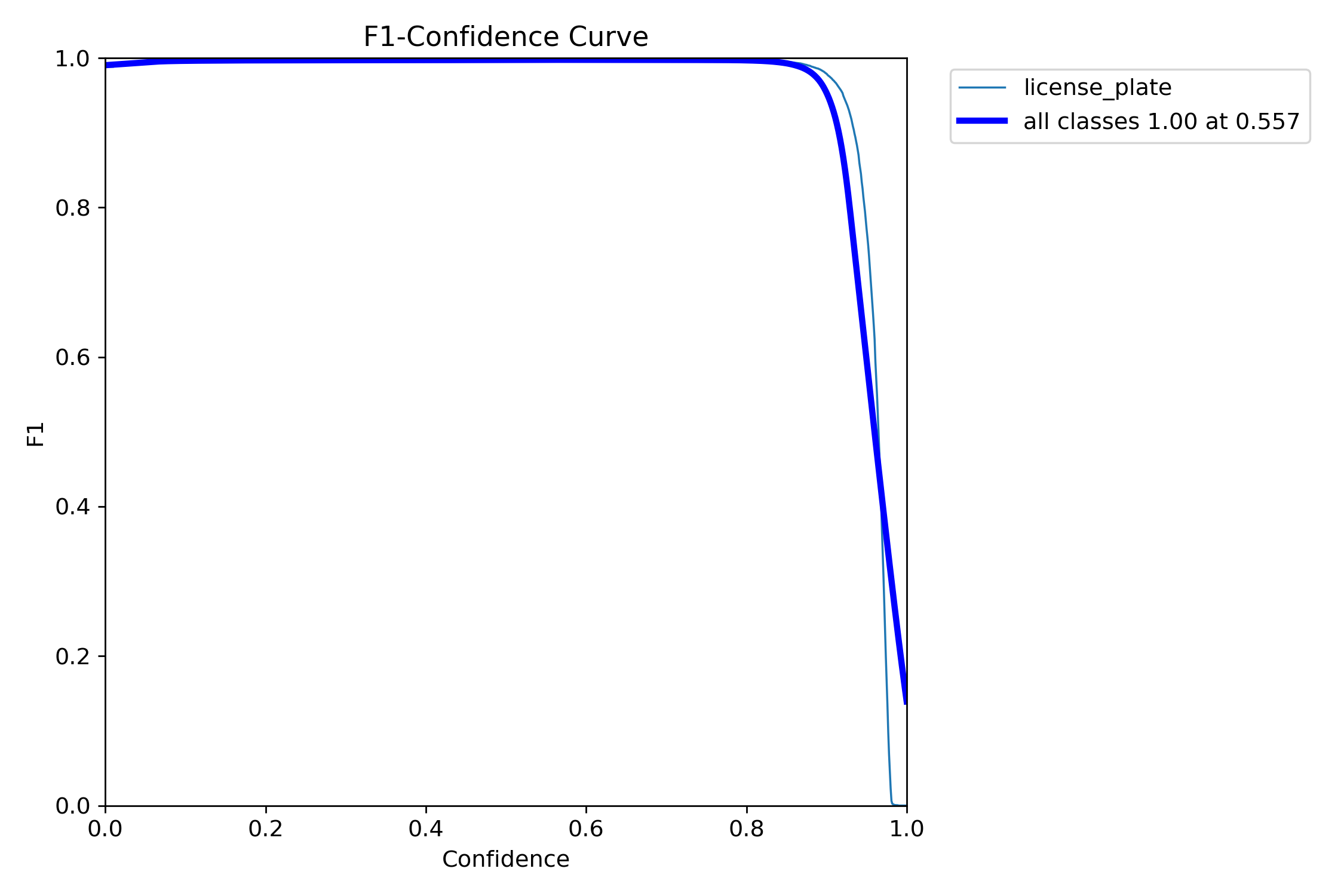
第一张图主要是确定我们后续模型推理时,它的置信度conf,如图可以看出conf为0.557
而后看loss,可以可能出训练集和验证集的损失值整体都趋于下降,如果训练集和验证集损失值都不下降,证明模型没有学习,而如果训练集在下降,但是验证集在后续忽然呈现一个上升的趋势说明模型过拟合了,两个损失值仍还在下降,还没有趋于稳定说明模型的训练轮数不够,需要增加轮数。
最后看P(precision准确率)、R(recall召回率)、mAP50、mAP50-95,可以看出后续轮数其都维持一个较高的水平,模型在最后训练后会自己选取一个最为均衡的权重作为best.pt
| 指标 | 核心作用 | 适用场景 |
|---|---|---|
| 精确率 P | 衡量误检率,看预测框 "准不准" | 筛选高置信度结果,减少后续字符识别的误判 |
| 召回率 R | 衡量漏检率,看模型 "全不全" | 确保监控场景下不遗漏任何车牌 |
| mAP50 | 基础综合指标,看模型 "能不能用" | 快速验证模型效果,嵌入式部署的入门门槛 |
| mAP50-95 | 高级综合指标,看模型 "好不好用" | 提升车牌框定位精度,助力后续字符识别 |
5.3 测试
这里的测试集选取easypr,数据一共256张,在置信度conf为0.557时,其漏检率为8%左右,无误检,因此降低conf为0.3,漏检率仍然高达5%,同时存在5、6张图像的误检,因此可以看出这个模型只具备基础的识别功能,因此需要微调。
六、第一次微调
在发现模型存在局限性后,逐个翻找图像,同时将置信度降为0.1,发现仍存在2%的漏检,因此这2%的图像模型没有提取出任何有用的信息,下图是比较典型的一类,其强光照射下,使原本蓝色的车牌变为了黄色,用于在强光的照射下,使得图像中过多的信息丢失,因此再后续的数据处理中需要将模型调整模型的饱和度、对比度等

除了上述的漏检以外,还模型对于大货车的黄色车牌和新能源汽车的绿色车牌的"自信"都较低,因此在后续的处理中还需要使用黄色车牌和绿色车牌的数据集来训练模型
这里将绿色车牌和黄色车牌分为两次微调,第一次对绿色车牌进行微调,第二次对黄色车牌进行微调。
七、微调数据处理
7.1 第一次微调数据处理
由于都是CCPD数据集,因此主要做法和之前的数据处理相同,但由于是模型的微调,因此使用的数据不易过多,选取5-6000张即可,再少一些也可以,但是至少得保证有3000张,不然模型无法记住车牌的特征。
对于误检的图像,采取过采样的方法,我们将截取误检的地方放入文件夹中,然后在生成其对应的txt文件时,不写入任何内容,将这个图像作为负样本传入图像,但是由于这种图像可能较少,因此可以使其循环50次(自己按照自己的数据集的数量定义),从而增加模型识别其为负样本的权重
最后每次微调都需要选取与新数据集相同数量的图像作为原始数据集,原始数据集的意义在于使模型不要因为传入了新的图像而改变了对于原来图像的处理权重,如果不传入原始数据,可能导致"灾难性遗忘"。
7.2 第二次微调数据处理
第二次使用的数据集为CPRD,其自带txt文件,该txt文件的内容如下

|----------------|---------------------------|
| 数字所在位置(以" "分割) | 含义(坐标均为归一化后的坐标) |
| 第一个数字 | 图中汽车的类型 |
| 第二、三个数字 | 图像汽车车牌的中心点 |
| 第四、五个数字 | 图像车牌的长宽 |
| 后续8个数字 | 图像车牌的四顶点位置(第一个为右下角坐标,顺时针) |
依此来处理数据,注意事项和前面一样,都需要对数据集进行过采样,同时保证有与新数据数量大致相同的原始数据集
八、微调模型训练
8.1 第一次微调模型训练
加载模型选取为之前训练好的模型权重(best.pt),在weights文件夹下存在best.pt和last.pt,第一个权重是模型训练中表现最好的一次权重,而第二个是模型最后一次训练的权重,第二个权重主要在模型未训练完成,中途因错误或其他原因停止后,用户想到继续之前的训练使用。
同时需要记得修改yaml文件,该文件指向模型训练的数据集,由于是新的数据集,因此需要对存放的位置进行修改。
model.train(
data='ccpd_patch.yaml',
epochs=30,
imgsz=640,
batch=8,
device=device,
workers=2,
lr0 = 0.001,
# 提升对黄牌/绿牌的识别力
hsv_h=0.06,
hsv_s=0.5, # 调节饱和度,应对暗光/过曝
hsv_v=0.4, # 调节亮度,应对眩光
scale=0.6, # 增加缩放增强,提高对远距离小车牌的识别
fliplr=0.5, # 左右翻转,增加场景随机性
mosaic=1.0, # 保持开启,增加背景复杂度,降低文字误检
mixup=0.1, # 开启Mixup,有助于解决颜色混淆问题
cos_lr=True, # 余弦学习率衰减
optimizer='AdamW', # AdamW 对OBB模型的收敛通常比默认的 SGD 更稳
amp=True, # 开启自动混合精度训练
project='runs/obb_finetune',
name='yolo8_ccpd_patch',
exist_ok=True, # 如果名字相同,直接覆盖/继续
close_mosaic = 10
)在微调中需要注意,首次选择的学习率和轮数一定要小一些,因此本来加载的便是训练好的模型,学习率太大会导致模型陷入局部最优解甚至无最优解,而轮数太大会导致模型的过拟合。
针对于模型的识别的问题,对模型的hsv(对比度、饱和度、亮度)进行调整,同时加强模型的缩放、翻转等。
8.2 第二次微调模型训练
和上面的第一次微调模型训练相同
model.train(
data='cprd_patch.yaml',
epochs=40,
imgsz=640,
batch=8,
device=device,
workers=2,
lr0 = 0.001,
# 提升对黄牌/绿牌的识别力
hsv_h=0.03,
hsv_s=0.6, # 调节饱和度,应对暗光/过曝
hsv_v=0.7, # 调节亮度,应对眩光
scale=0.6, # 增加缩放增强,提高对远距离小车牌的识别
mosaic=1.0, # 保持开启,增加背景复杂度,降低文字误检
mixup=0.15, # 开启Mixup,有助于解决颜色混淆问题
cos_lr=True, # 余弦学习率衰减
optimizer='AdamW', # AdamW 对 OBB 模型的收敛通常比默认的 SGD 更稳
amp=True, # 开启自动混合精度训练,极大提升 4070 的训练速度
project='runs/obb_finetune_v2',
name='yolo8_ccpd_patch',
exist_ok=True, # 如果名字相同,直接覆盖/继续
close_mosaic = 10
)8.3 微调模型训练结果
在训练过程中,召回率一直不变(如我之前一直在0.905),可能是数据集处理存在问题,也就是说明模型没有看见你框选的车牌。
最后的训练结果如下
|------|----------------------------------------------------------------------------|----------------------------------------------------------------------------|
| | 第一次微调 | 第二次微调 |
| conf | 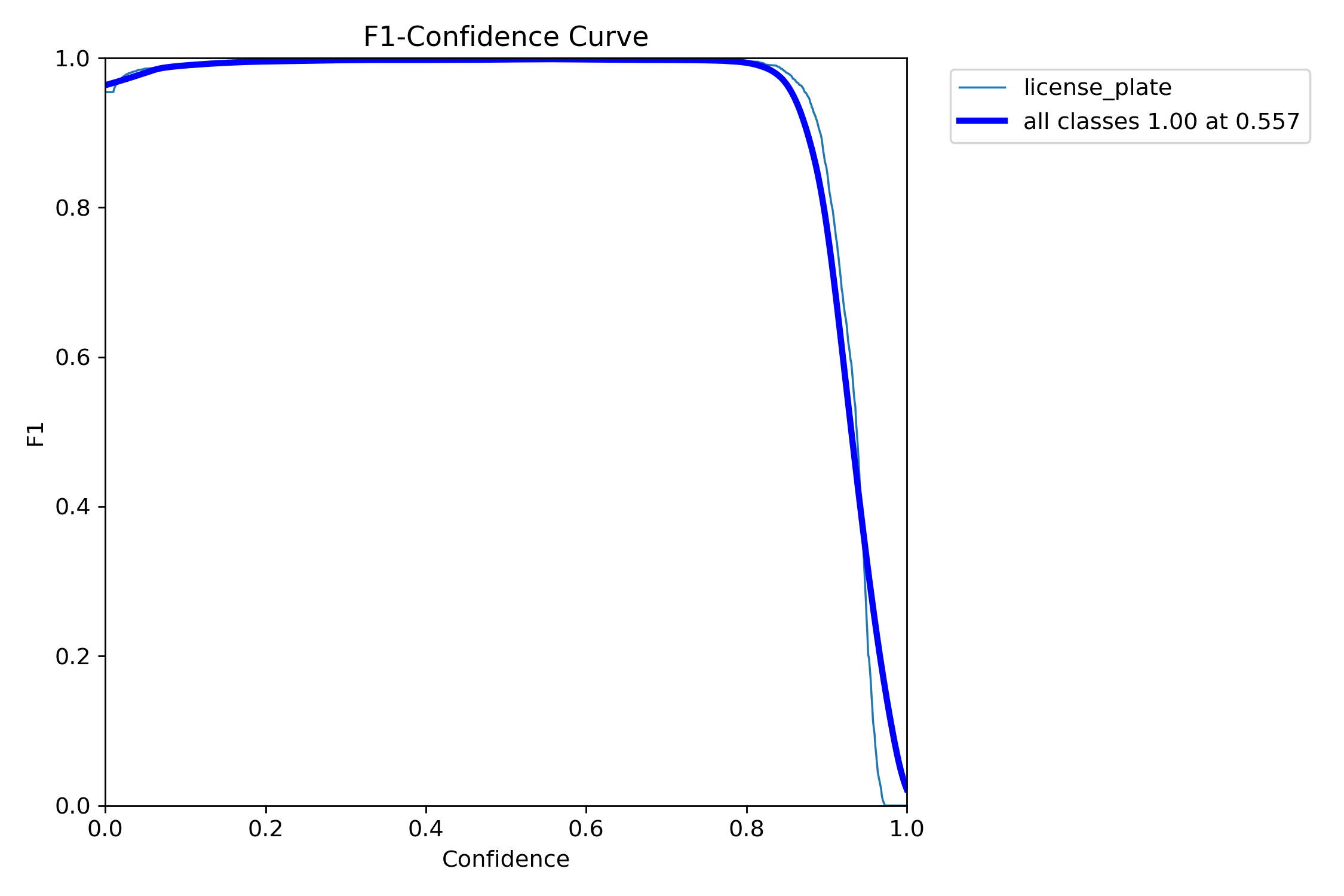 |
| 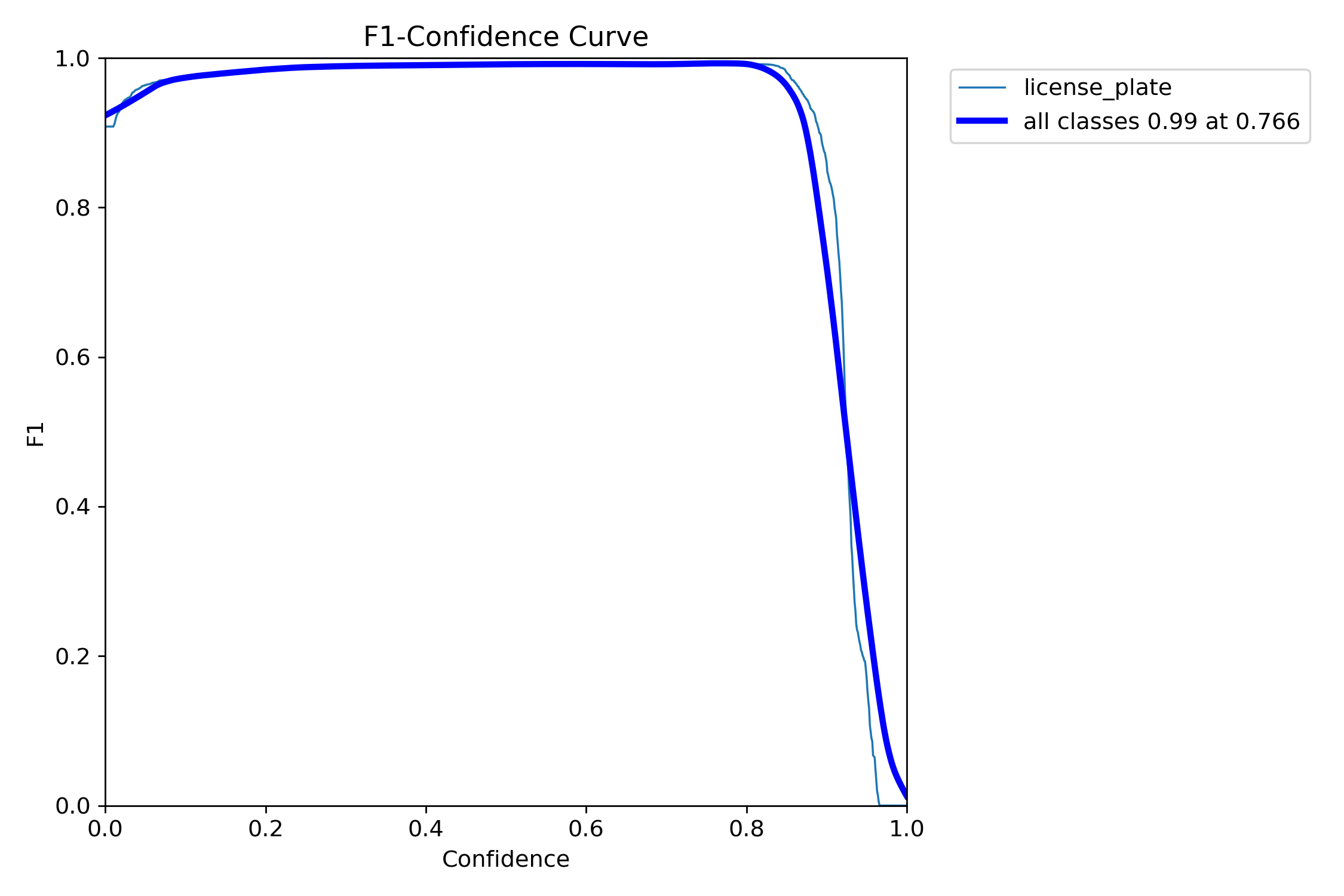 |
|
| loss | 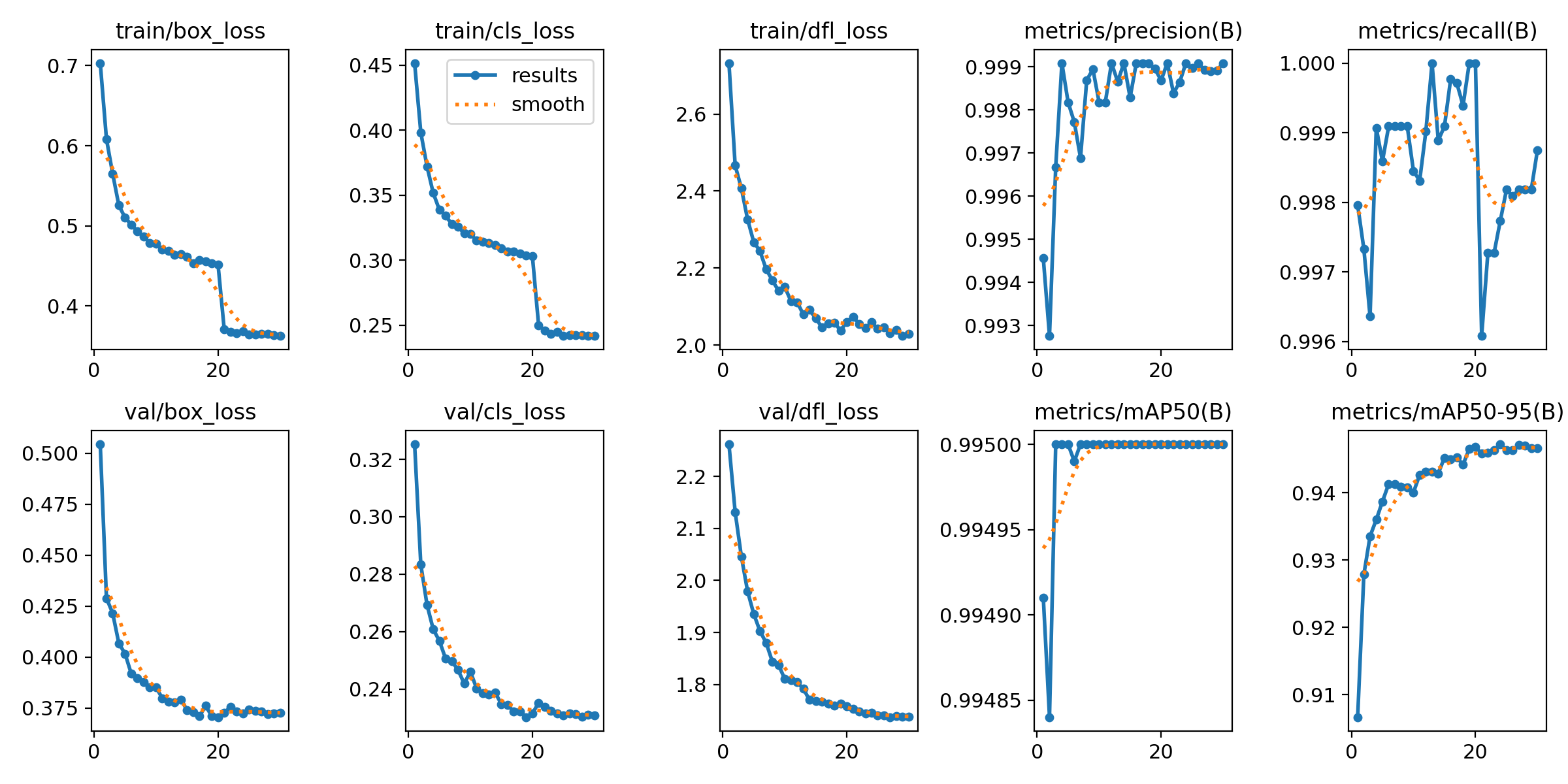 |
| 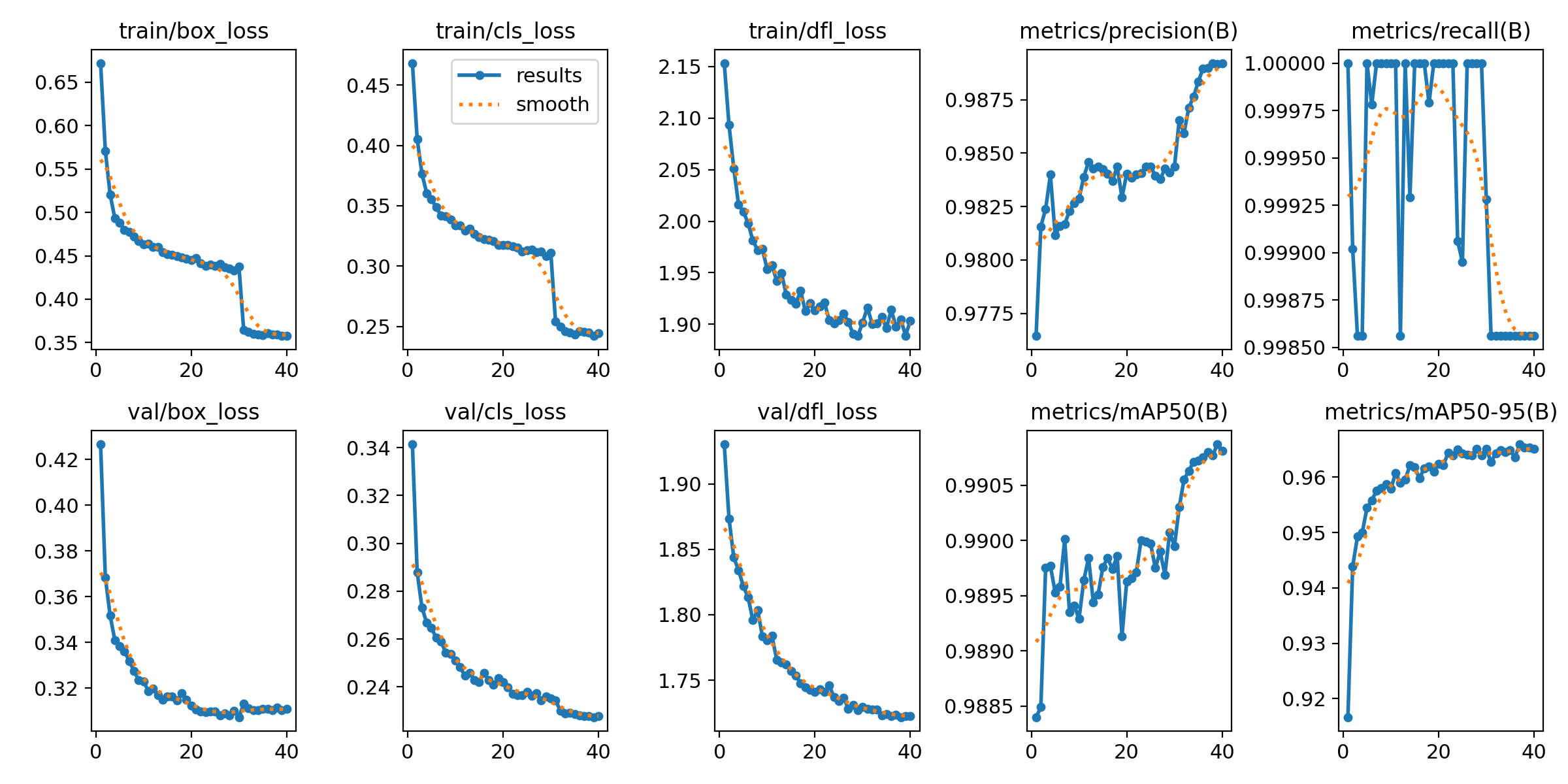 |
|
可以看出两次训练都没有太大问题
8.4 微调模型测试结果
直接使用最后一次模型训练的结果,对数据集进行检测,conf选取为0.7
ccpd_2020_test:5006

未识别率未1.88%
通过多次选取查看识别的图像无误检




其中未识别图像图下:


分辨率都较低,导致图像的信息捕捉不完全,但是conf也相对较高,因此模型具备一个基础的识别功能,同时正确率较高,因此该模型可以作为后续字符识别的前提。
参考文献
yolo-obb
数据集
CCPD_2019
CCPD_GREEN
CRPD_YELLOW
附录
代码(由于整体上传文件太大,因此只上传代码部分)--按顺序上传
prepare_obb.py
import os import cv2 import random import shutil kaggle_img_path = './CCPD2019/' # 训练集和验证集的根目录 imgs_path = ['ccpd_base', 'ccpd_blur', 'ccpd_challenge', 'ccpd_db', 'ccpd_fn', 'ccpd_np', 'ccpd_rotate', 'ccpd_tilt', 'ccpd_weather'] # 训练集和验证集 output_dir = './datasets/CCPD_YOLO/' # 将普通格式转化为OBB格式后数据储存的根目录 def process_files(file_list, type): """原始数据集处理""" for src_path in file_list: filename = os.path.basename(src_path) # 获取图像的文件名 # 解析文件名 points = filename.split('-') if len(points) == 1: txt_filename = filename.replace('.jpg', '.txt') txt_path = os.path.join(output_dir, f'labels/{type}', txt_filename) with open(txt_path, 'w') as f: pass elif len(points) >= 4: points = points[3] point = points.split('_') p1 = point[0].split('&') p2 = point[1].split('&') p3 = point[2].split('&') p4 = point[3].split('&') # 提取矩形四个顶点坐标 x1, y1 = int(p1[0]), int(p1[1]) # 右下角坐标 x2, y2 = int(p2[0]), int(p2[1]) # 左下角坐标 x3, y3 = int(p3[0]), int(p3[1]) # 左上角坐标 x4, y4 = int(p4[0]), int(p4[1]) # 右上角坐标 # 读取图片获取宽高 img = cv2.imread(src_path) if img is None: print(f"无法读取图像:{filename}") continue h_img, w_img, _ = img.shape # 归一化为OBB格式 obb = [x1 / w_img, y1 / h_img, x2 / w_img, y2 / h_img, x3 / w_img, y3 / h_img, x4 / w_img, y4 / h_img] label_line = f"0 {obb[0]:.6f} {obb[1]:.6f} {obb[2]:.6f} {obb[3]:.6f} {obb[4]:.6f} {obb[5]:.6f} {obb[6]:.6f} {obb[7]:.6f}\n" # 将OBB数据集写入txt文本中 txt_filename = filename.replace('.jpg', '.txt') txt_path = os.path.join(output_dir, f'labels/{type}', txt_filename) with open(txt_path, 'w') as f: f.write(label_line) # 复制图片 dst_img_path = os.path.join(output_dir, f'images/{type}', filename) shutil.copy(src_path, dst_img_path) print(f'{filename}图片转化成功') print(f"{type}数据集处理完成。") def process_img(kaggle_path, num): """对CCPD2019中多个文件夹的文件进行处理""" all_images = [] # 开始处理 print(f"开始处理{kaggle_path}") images = os.listdir(kaggle_path) # 读取该文件夹中所有文件的文件名 images = random.sample(images, min(len(images), num)) # 打乱数据避免数据集的相似导致模型的死记硬背从而降低验证集的正确率 for f in images: if f.endswith('.jpg'): # 遍历文件名,找出以.jpg结尾的图像文件 files = os.path.join(kaggle_path, f) # 读取该图像的文件名 all_images.append(files) # 将图像添加进all_images print(f"遍历{kaggle_path}完成,共找到{len(all_images)}张图片") # 按照九一交叉验证的方法划分训练集和验证集 l = int(len(all_images) * 0.9) train_image = all_images[0:l] val_image = all_images[l:] print(f"{kaggle_path}训练集创建完成,训练集: {len(train_image)}张") print(f"{kaggle_path}验证集创建完成,验证集: {len(val_image)}张") return train_image, val_image def convert_ccpd_to_obb(): """数据集转化为yolo格式""" # 创建YOLO目录结构 for split in ['train', 'val']: os.makedirs(f'{output_dir}/images/{split}', exist_ok=True) os.makedirs(f'{output_dir}/labels/{split}', exist_ok=True) train_images =[] val_images =[] # 遍历文件夹,收集所有图片 for img_path in imgs_path: kaggle_path = os.path.join(kaggle_img_path, img_path) # 读取kaggle数据集的目录名字 # ccpd_base基础、ccpd_blur模糊、ccpd_challenge挑战、ccpd_db双层车牌、ccpd_rotate旋转取10000张图像 if img_path in ['ccpd_base', 'ccpd_blur', 'ccpd_db', 'ccpd_rotate']: train_image, val_image = process_img(kaggle_path, 10000) train_images = train_image + train_images val_images = val_image + val_images # ccpd_fn远距离、ccpd_np无车牌取5000张图像 elif img_path in ['ccpd_fn', 'ccpd_np']: train_image, val_image = process_img(kaggle_path, 5000) train_images = train_image + train_images val_images = val_image + val_images # ccpd_tilt倾斜取20000张图像 elif img_path in ['ccpd_tilt']: train_image, val_image = process_img(kaggle_path, 20000) train_images = train_image + train_images val_images = val_image + val_images # ccpd_weather天气取9000张图像 elif img_path in ['ccpd_weather']: train_image, val_image = process_img(kaggle_path, 9000) train_images = train_image + train_images val_images = val_image + val_images # ccpd_challenge挑战取8000张图像 elif img_path in ['ccpd_challenge']: train_image, val_image = process_img(kaggle_path, 8000) train_images = train_image + train_images val_images = val_image + val_images # 打乱数据避免模型的死记硬背 random.shuffle(train_images) random.shuffle(val_images) print(f"训练集创建完成,训练集: {len(train_images)}") print(f"验证集创建完成,验证集: {len(val_images)}") print(f"开始转化数据") process_files(train_images, 'train') process_files(val_images, 'val') print("所有数据转换完成") if __name__ == '__main__': convert_ccpd_to_obb()
train_obb.py
from ultralytics import YOLO import torch def train_model(): """开始训练模型""" # 检查 CUDA 是否可用 if torch.cuda.is_available(): print(f"CUDA就绪! 将使用GPU: {torch.cuda.get_device_name(0)}") device = '0' else: print("未检测到 CUDA") device = 'cpu' # 加载OBB预训练模型 print(f'加载OBB预训练模型') model = YOLO('yolov8n-obb.pt') print(f'模型加载完毕') # 开始训练 print(f'开始训练模型') model.train( data='ccpd_obb.yaml', epochs=100, patience=50, # 50轮不提升则早停 imgsz=640, # 针对树莓派建议设为 640,若追求极致精度再改回 1024 batch=16, # 4070 跑 640 分辨率,batch 可以设为 32 甚至 64 以加速 device=device, workers=8, close_mosaic=10, # 最后10轮关闭增强,进行高精度微调 cos_lr=True, # 余弦学习率衰减 optimizer='AdamW', # AdamW 对 OBB 模型的收敛通常比默认的 SGD 更稳 amp=True, # 开启自动混合精度训练 project='runs/obb', name='yolo8_ccpd_optimized', exist_ok=True # 如果名字相同,直接覆盖/继续 ) if __name__ == '__main__': train_model()
prepare_green_obb.py
import os import cv2 import random import shutil # 补丁数据集(新能源、眩光等) kaggle_img_path = './ccpd_green/' # 训练集和验证集的根目录 imgs_path = ['test', 'train', 'val', 'db'] # 两个不同的训练集和验证集 # 原始数据集(防止遗忘) PATH_2019 = './CCPD2019/' CHOOSE_2019 = ['ccpd_base', 'ccpd_tilt'] # 负样本路径 NEG_SAMPLES_PATH = './hard_negatives/' # 输出目录 output_dir = './datasets/CCPD_YOLO_GREEN/' # 将普通格式转化为OBB格式后数据储存的根目录 def part_train_val(images): """划分训练和验证""" random.shuffle(images) l = int(len(images) * 0.9) return images[:l], images[l:] def process_ccpd_base_tilt(num): """从原数据中提取复习资料,返回完整路径""" train_total = [] val_total = [] for f in CHOOSE_2019: folder_path = os.path.join(PATH_2019, f) if not os.path.exists(folder_path): continue images = [os.path.join(folder_path, img) for img in os.listdir(folder_path) if img.endswith('.jpg')] sampled = random.sample(images, min(len(images), num)) tr, va = part_train_val(sampled) train_total.extend(tr) val_total.extend(va) return train_total, val_total def process_img(folder_path, num): """从新补丁数据中提取图片,返回完整路径""" if not os.path.exists(folder_path): print(f"跳过不存在的目录: {folder_path}") return [] images = [os.path.join(folder_path, f) for f in os.listdir(folder_path) if f.endswith('.jpg') or f.endswith('.png')] return random.sample(images, min(len(images), num)) def process_files(file_list, type): """原始数据集处理""" for src_path in file_list: filename = os.path.basename(src_path) # 获取文件名 # 解析文件名 points = filename.split('-') if len(points) < 4: txt_filename = filename.replace('.jpg', '.txt') txt_path = os.path.join(output_dir, f'labels/{type}', txt_filename) with open(txt_path, 'w') as f: pass elif len(points) >= 4: points = points[3] point = points.split('_') p1 = point[0].split('&') p2 = point[1].split('&') p3 = point[2].split('&') p4 = point[3].split('&') # 提取矩形四个顶点坐标 x1, y1 = int(p1[0]), int(p1[1]) # 右下角坐标 x2, y2 = int(p2[0]), int(p2[1]) # 左下角坐标 x3, y3 = int(p3[0]), int(p3[1]) # 左上角坐标 x4, y4 = int(p4[0]), int(p4[1]) # 右上角坐标 # 读取图片获取宽高 img = cv2.imread(src_path) if img is None: print(f"无法读取图像:{filename}") continue h_img, w_img, _ = img.shape # 归一化为OBB格式 obb = [x1 / w_img, y1 / h_img, x2 / w_img, y2 / h_img, x3 / w_img, y3 / h_img, x4 / w_img, y4 / h_img] label_line = f"0 {obb[0]:.6f} {obb[1]:.6f} {obb[2]:.6f} {obb[3]:.6f} {obb[4]:.6f} {obb[5]:.6f} {obb[6]:.6f} {obb[7]:.6f}\n" # 将OBB数据集写入txt文本中 txt_filename = filename.replace('.jpg', '.txt') txt_path = os.path.join(output_dir, f'labels/{type}', txt_filename) with open(txt_path, 'w') as f: f.write(label_line) # 复制图片 dst_img_path = os.path.join(output_dir, f'images/{type}', filename) shutil.copy(src_path, dst_img_path) print(f'{filename}图片转化成功') print(f"{type}数据集处理完成。") def convert_ccpd_to_obb(): """数据集转化为yolo格式""" # 创建目录 for s in ['train', 'val']: os.makedirs(f'{output_dir}/images/{s}', exist_ok=True) os.makedirs(f'{output_dir}/labels/{s}', exist_ok=True) final_train = [] final_val = [] # 复习原始数据 tr_2019, va_2019 = process_ccpd_base_tilt(3000) final_train.extend(tr_2019) final_val.extend(va_2019) # 处理补丁数据 for sub in imgs_path: p = os.path.join(kaggle_img_path, sub) if sub == 'train': final_train.extend(process_img(p, 3000)) # 3000张新能源/眩光训练 elif sub == 'val': final_val.extend(process_img(p, 500)) # 500张验证 elif sub == 'challenge': # 全选 all_in_sub = process_img(p, 999999) tr, va = part_train_val(all_in_sub) final_train.extend(tr) final_val.extend(va) # 处理误检背景图 (过采样) if os.path.exists(NEG_SAMPLES_PATH): neg_images = [os.path.join(NEG_SAMPLES_PATH, f) for f in os.listdir(NEG_SAMPLES_PATH)] # 将这 7 张图复制 50 份加入训练集,增强模型记忆 for _ in range(50): final_train.extend(neg_images) print(f"准备转换:训练集 {len(final_train)} 张, 验证集 {len(final_val)} 张") process_files(final_train, 'train') process_files(final_val, 'val') if __name__ == '__main__': convert_ccpd_to_obb()
fine_tuning_obb_model.py
from ultralytics import YOLO import torch def train_model(): """开始训练模型""" # 检查 CUDA 是否可用 if torch.cuda.is_available(): print(f"CUDA就绪! 将使用GPU: {torch.cuda.get_device_name(0)}") device = '0' else: print("未检测到 CUDA") device = 'cpu' # 加载OBB预训练模型 print(f'加载OBB预训练模型') model = YOLO('./runs/obb/runs/obb/yolo8_ccpd_optimized/weights/best.pt') print(f'模型加载完毕') # 开始训练 print(f'开始训练模型') model.train( data='ccpd_patch.yaml', epochs=30, imgsz=640, batch=8, device=device, workers=2, lr0 = 0.001, # 提升对黄牌/绿牌的识别力 hsv_h=0.06, hsv_s=0.5, # 调节饱和度,应对暗光/过曝 hsv_v=0.4, # 调节亮度,应对眩光 scale=0.6, # 增加缩放增强,让模型多练练"远距离小车牌" fliplr=0.5, # 左右翻转,增加场景随机性 mosaic=1.0, # 保持开启,增加背景复杂度,压制"文字误检" mixup=0.1, # 开启 Mixup,有助于解决颜色混淆问题 cos_lr=True, # 余弦学习率衰减 optimizer='AdamW', # AdamW 对 OBB 模型的收敛通常比默认的 SGD 更稳 amp=True, # 开启自动混合精度训练 project='runs/obb_finetune', name='yolo8_ccpd_patch', exist_ok=True, # 如果名字相同,直接覆盖/继续 close_mosaic = 10 ) if __name__ == '__main__': train_model()
prepare_yellow_obb.py
import os import shutil import cv2 import random import prepare_green_obb # 补丁数据集 CRPD_YELLOW_PATH = './CRPD/yellow_train/images' # CRPD黄牌原图 CRPD_LABEL_PATH = './CRPD/yellow_train/label' # CRPD标签 # 原始数据集 kaggle_img_path = './ccpd_green/' # 训练集和验证集的根目录 imgs_path = ['test', 'train', 'challenge'] # 两个不同的训练集和验证集 PATH_2019 = './CCPD2019/' CHOOSE_2019 = ['ccpd_base', 'ccpd_tilt'] # 负样本路径 NEG_SAMPLES_PATH = './hard_negatives/' # 输出目录 OUTPUT_DIR = './datasets/CRPD_YOLO_YELLOW/' # 扩充倍数 TRAIN_REPEAT_TIMES = 4 def process_files(file_list, type): """原始数据集处理""" for src_path in file_list: filename = os.path.basename(src_path) # 获取文件名 # 解析文件名 points = filename.split('-') if len(points) < 4: txt_filename = filename.replace('.jpg', '.txt') txt_path = os.path.join(OUTPUT_DIR, f'labels/{type}', txt_filename) with open(txt_path, 'w') as f: pass elif len(points) >= 4: points = points[3] point = points.split('_') p1 = point[0].split('&') p2 = point[1].split('&') p3 = point[2].split('&') p4 = point[3].split('&') # 提取矩形四个顶点坐标 x1, y1 = int(p1[0]), int(p1[1]) # 右下角坐标 x2, y2 = int(p2[0]), int(p2[1]) # 左下角坐标 x3, y3 = int(p3[0]), int(p3[1]) # 左上角坐标 x4, y4 = int(p4[0]), int(p4[1]) # 右上角坐标 # 读取图片获取宽高 img = cv2.imread(src_path) if img is None: print(f"无法读取图像:{filename}") continue h_img, w_img, _ = img.shape # 归一化为OBB格式 obb = [x1 / w_img, y1 / h_img, x2 / w_img, y2 / h_img, x3 / w_img, y3 / h_img, x4 / w_img, y4 / h_img] label_line = f"0 {obb[0]:.6f} {obb[1]:.6f} {obb[2]:.6f} {obb[3]:.6f} {obb[4]:.6f} {obb[5]:.6f} {obb[6]:.6f} {obb[7]:.6f}\n" # 将OBB数据集写入txt文本中 txt_filename = filename.replace('.jpg', '.txt') txt_path = os.path.join(OUTPUT_DIR, f'labels/{type}', txt_filename) with open(txt_path, 'w') as f: f.write(label_line) # 复制图片 dst_img_path = os.path.join(OUTPUT_DIR, f'images/{type}', filename) shutil.copy(src_path, dst_img_path) print(f'{filename}图片转化成功') print(f"{type}数据集处理完成。") def convert_crpd_annotation(img_path, txt_path): """保持之前的转换逻辑不变,确保坐标归一化和顺序正确""" try: img = cv2.imread(img_path) if img is None: return None with open(txt_path, 'r') as f: lines = f.readlines() yolo_labels = [] for line in lines: # 根据你的CRPD txt格式调整分隔符 parts = line.strip().split(' ') # 务必检查CRPD的点序是否为 TL-TR-BR-BL coords = [float(x) for x in parts[5:]] # 归一化 obb = [coords[0], coords[1], coords[2], coords[3], coords[4], coords[5], coords[6], coords[7]] # 写入 YOLO OBB 格式 yolo_labels.append(f"0 {' '.join([f'{x:.6f}' for x in obb])}") return yolo_labels except Exception as e: print(f"Error: {e}") return None def process_batch(image_list, subset_name, repeat_times): """ 通用处理函数 """ target_img_dir = os.path.join(OUTPUT_DIR, f'images/{subset_name}') target_lbl_dir = os.path.join(OUTPUT_DIR, f'labels/{subset_name}') count = 0 for img_file in image_list: src_img = os.path.join(CRPD_YELLOW_PATH, img_file) src_txt = os.path.join(CRPD_LABEL_PATH, img_file.replace('.jpg', '.txt')) if not os.path.exists(src_txt): continue # 解析标签 labels = convert_crpd_annotation(src_img, src_txt) if not labels: continue # 复制 for i in range(repeat_times): # 为了避免文件名冲突,训练集加前缀区分 if repeat_times > 1: new_name = f"{i}_{img_file}" else: new_name = f"{img_file}" # 验证集保持原名或简单前缀 dst_img = os.path.join(target_img_dir, new_name) dst_txt = os.path.join(target_lbl_dir, new_name.replace('.jpg', '.txt')) shutil.copy(src_img, dst_img) with open(dst_txt, 'w') as f: f.write('\n'.join(labels)) count += 1 print(f"[{subset_name}] 处理完成: 原图 {len(image_list)} 张 -> 生成 {count} 张样本") def prepare_crpd_split(): # 创建目录 for s in ['train', 'val']: os.makedirs(f'{OUTPUT_DIR}/images/{s}', exist_ok=True) os.makedirs(f'{OUTPUT_DIR}/labels/{s}', exist_ok=True) # 读取所有图片并打乱 all_imgs = [f for f in os.listdir(CRPD_YELLOW_PATH) if f.endswith('.jpg')] random.seed(42) # 固定种子,保证每次运行划分一致 random.shuffle(all_imgs) # 划分 9:1 split_idx = int(len(all_imgs) * 0.9) train_imgs = all_imgs[:split_idx] # 约 870 张 val_imgs = all_imgs[split_idx:] # 约 97 张 print(f"总计 CRPD 黄牌: {len(all_imgs)}") # 处理训练集 process_batch(train_imgs, 'train', repeat_times=TRAIN_REPEAT_TIMES) # 处理验证集 process_batch(val_imgs, 'val', repeat_times=1) final_train = [] final_val = [] # 复习原始数据 tr_2019, va_2019 = prepare_green_obb.process_ccpd_base_tilt(1500) final_train.extend(tr_2019) final_val.extend(va_2019) for sub in imgs_path: p = os.path.join(kaggle_img_path, sub) if sub == 'train': final_train.extend(prepare_green_obb.process_img(p, 2700)) # 3000张新能源/眩光训练 elif sub == 'val': final_val.extend(prepare_green_obb.process_img(p, 300)) # 500张验证 elif sub == 'challenge': # 全选 all_in_sub = prepare_green_obb.process_img(p, 999999) tr, va = prepare_green_obb.part_train_val(all_in_sub) final_train.extend(tr) final_val.extend(va) # 处理误检背景图 (过采样) if os.path.exists(NEG_SAMPLES_PATH): neg_images = [os.path.join(NEG_SAMPLES_PATH, f) for f in os.listdir(NEG_SAMPLES_PATH)] # 将这 7 张图复制 50 份加入训练集,增强模型记忆 for _ in range(50): final_train.extend(neg_images) print(f"准备转换:原始训练集 {len(final_train)} 张, 原始验证集 {len(final_val)} 张") process_files(final_train, 'train') process_files(final_val, 'val') if __name__ == '__main__': prepare_crpd_split()
fine_tuning_obb_model_two.py
from ultralytics import YOLO import torch def train_model(): """开始训练模型""" # 检查 CUDA 是否可用 if torch.cuda.is_available(): print(f"CUDA就绪! 将使用GPU: {torch.cuda.get_device_name(0)}") device = '0' else: print("未检测到 CUDA") device = 'cpu' # 加载OBB预训练模型 print(f'加载OBB预训练模型') model = YOLO('./runs/obb_finetune/yolo8_ccpd_patch/weights/best.pt') print(f'模型加载完毕') # 开始训练 print(f'开始训练模型') model.train( data='cprd_patch.yaml', epochs=40, imgsz=640, batch=8, device=device, workers=2, lr0 = 0.001, # 提升对黄牌/绿牌的识别力 hsv_h=0.03, hsv_s=0.6, # 调节饱和度,应对暗光/过曝 hsv_v=0.7, # 调节亮度,应对眩光 scale=0.6, # 增加缩放增强,提高对远距离小车牌的识别 mosaic=1.0, # 保持开启,增加背景复杂度,降低文字误检 mixup=0.15, # 开启Mixup,有助于解决颜色混淆问题 cos_lr=True, # 余弦学习率衰减 optimizer='AdamW', # AdamW 对 OBB 模型的收敛通常比默认的 SGD 更稳 amp=True, # 开启自动混合精度训练,极大提升 4070 的训练速度 project='runs/obb_finetune_v2', name='yolo8_ccpd_patch', exist_ok=True, # 如果名字相同,直接覆盖/继续 close_mosaic = 10 ) if __name__ == '__main__': train_model()
test.py
import random import cv2 import os import numpy as np from ultralytics import YOLO import time def preprocess_glare(img): """ 针对强光图片的预处理:Gamma矫正 + CLAHE 这相当于给摄像头戴了一副"墨镜" """ # 转换到 LAB 色彩空间,只处理 L (亮度) 通道 lab = cv2.cvtColor(img, cv2.COLOR_BGR2LAB) l, a, b = cv2.split(lab) # CLAHE (限制对比度自适应直方图均衡化) # 这能把暗处的细节提亮,同时限制亮处的过曝 clahe = cv2.createCLAHE(clipLimit=2.0, tileGridSize=(8, 8)) cl = clahe.apply(l) # 合并通道并转回 BGR limg = cv2.merge((cl, a, b)) enhanced_img = cv2.cvtColor(limg, cv2.COLOR_LAB2BGR) # (可选) Gamma 矫正:压暗高光 # gamma < 1 提亮,gamma > 1 压暗。这里用 1.2 稍微压暗高光 invGamma = 1.0 / 1.2 table = np.array([((i / 255.0) ** invGamma) * 255 for i in np.arange(0, 256)]).astype("uint8") final_img = cv2.LUT(enhanced_img, table) return final_img def cv_imread(file_path): """ 读取中文路径图片的函数 """ # np.fromfile 读取文件内容为二进制流 # cv2.imdecode 将二进制流解码为图像 try: cv_img = cv2.imdecode(np.fromfile(file_path, dtype=np.uint8), cv2.IMREAD_COLOR) return cv_img except Exception as e: print(f"读取图片失败: {file_path}, 错误: {e}") return None class TaskOBB: def __init__(self, model_path): self.model = YOLO(model_path) self.device = '0' def warp_plate(self, poly_pts): """透视变换矫正""" # 将无序的OBB顶点坐标转化为有序的顶点坐标 rect = np.zeros((4, 2), dtype="float32") s = poly_pts.sum(axis=1) # 按列求和(x+y) rect[0] = poly_pts[np.argmin(s)] # 和最小为左上角坐标 rect[2] = poly_pts[np.argmax(s)] # 和最大为右下角坐标 diff = np.diff(poly_pts, axis=1) # 按列求差 rect[1] = poly_pts[np.argmin(diff)] # 差最小为左下角坐标 rect[3] = poly_pts[np.argmax(diff)] # 差最大为右上角坐标 (tl, tr, br, bl) = rect # 使用欧式距离得出定位框的长宽 width = max(int(np.linalg.norm(br - bl)), int(np.linalg.norm(tr - tl))) height = max(int(np.linalg.norm(tr - br)), int(np.linalg.norm(tl - bl))) return width, height def run(self, img_path, mistake_img): """完成任务一""" # 读取图像 img = cv_imread(img_path) if img is None: print(f"警告:无法读取图片 {img_path},跳过该图。") mistake_img.append(img_path) return None, None, mistake_img # 使用模型开始推理 print(f"开始推理{img_path}") results = self.model.predict(img, verbose=False, device = self.device, conf = 0.7, augment = False, imgsz = 640, iou=0.7) img_plot = img.copy() if len(results[0].obb) == 0: print(f"原图未检测到{img_path},尝试抗眩光预处理...") processed_img = preprocess_glare(img_plot) # 再次预测 results = self.model.predict(processed_img, verbose=False, device = self.device, conf = 0.2, augment = False, imgsz = 640, iou=0.7) result = results[0] # 获取结果 if result.obb is not None and len(result.obb) > 0: # 获取 OBB 坐标 location_points = result.obb.xyxyxyxy.cpu().numpy() all_confs = result.obb.conf.cpu().numpy() # 获取置信度用于调试 for i, points in enumerate(location_points): points = points.reshape(4, 2) pts = np.array(points, dtype=np.int32).reshape((-1, 1, 2)) cv2.polylines(img_plot, [pts], True, (0, 255, 0), 3) text_loc = (pts[0][0][0], pts[0][0][1] - 10) cv2.putText(img_plot, f"{all_confs[i]:.2f}", text_loc, cv2.FONT_HERSHEY_SIMPLEX, 0.8, (0, 0, 255), 2) print(f"{img_path}检测到车牌") else: mistake_img.append(img_path) print(f"{img_path}未检测到车牌") return img, img_plot, mistake_img if __name__ == '__main__': model_path = 'runs/obb_finetune_v2/yolo8_ccpd_patch/weights/best.pt' # 训练后的路径 github_img_path = './general_test' detect = './detect/' # 模拟检查模型是否存在 if not os.path.exists(model_path): print("未找到模型,请先运行训练脚本!") else: processor = TaskOBB(model_path) # 不放回随机抽样十个图片 all_files = os.listdir(github_img_path) mistake_img = [] start_time = time.time() for idx, f in enumerate(all_files): res = processor.run(os.path.join(github_img_path, f), mistake_img) if res: img, plot_img, mistake_img = res # 转 RGB cv2.imwrite(os.path.join(detect, f), plot_img) end_time = time.time() time = end_time - start_time print(f"使用时间{time}s") print(f"未识别图像共{len(mistake_img)},未识别率未{len(mistake_img) / len(all_files) * 100:.2f}%") print(mistake_img)