1. 基于YOLOv5-FasterNet的溺水状态检测与识别系统实战教程
1.1. 绪论
溺水问题已成为全球性的公共卫生挑战,据统计,全球每年因溺水死亡的人数超过40万,其中儿童和青少年是最受影响的群体。🌊 传统的人工监控方式存在效率低、反应慢、易疲劳等问题,难以满足大规模水域监控的需求。😫 随着人工智能技术的快速发展,基于深度学习的智能溺水检测系统应运而生,能够实时、准确地识别溺水事件,为水域安全管理提供强有力的技术支持。
国内外学者在溺水检测领域已开展大量研究,但现有方法仍存在一些局限性:如检测精度不高、实时性差、对复杂水域环境适应性弱等问题。🔍 本文提出一种基于YOLOv5-FasterNet的溺水状态检测与识别系统,通过引入FasterNet的高效特征提取能力,优化YOLOv5的网络结构,旨在提升算法在复杂水域环境下的检测精度和实时性,为水域安全监控提供更可靠的技术方案。
1.2. 相关理论与技术基础
1.2.1. 深度学习目标检测理论
目标检测是计算机视觉领域的重要研究方向,其主要任务是在图像中定位并识别出感兴趣的目标。🎯 深度学习目标检测算法主要分为两类:两阶段检测算法和单阶段检测算法。YOLOv5作为单阶段检测算法的代表之一,具有检测速度快、模型轻量化的特点,非常适合实时监控系统。
YOLOv5的网络结构主要由Backbone、Neck和Head三部分组成。Backbone采用CSPDarknet结构,负责提取特征图;Neck采用FPN+PAN结构,用于特征融合;Head负责最终的检测输出。其损失函数由定位损失、置信度损失和分类损失三部分组成,公式如下:
L t o t a l = L b o x + L o b j + L c l s L_{total} = L_{box} + L_{obj} + L_{cls} Ltotal=Lbox+Lobj+Lcls
其中, L b o x L_{box} Lbox表示定位损失,采用CIoU损失函数; L o b j L_{obj} Lobj表示置信度损失; L c l s L_{cls} Lcls表示分类损失。这种多任务联合优化的方式使得YOLOv5在保持高检测精度的同时,具有较快的推理速度。
1.2.2. FasterNet特性分析
FasterNet是近年来提出的高效神经网络架构,其核心创新点在于提出了一种新型的部分卷积(PConv)机制,显著减少了计算量和参数数量。🚀 PConv通过只对输入特征的一部分进行卷积操作,既保持了特征提取能力,又大大降低了计算复杂度。
FasterNet的网络结构主要由多个FasterNet Block组成,每个Block包含PConv和SE(Squeeze-and-Excitation)模块。PConv的工作原理可以表示为:
y = f ( P ⊙ x ) + b ⊙ x y = f(P \odot x) + b \odot x y=f(P⊙x)+b⊙x
其中, P P P是部分卷积掩码, x x x是输入特征, f f f是卷积操作, ⊙ \odot ⊙表示逐元素相乘, b b b是残差连接。这种机制使得FasterNet在保持高性能的同时,具有极低的计算复杂度,非常适合资源受限的嵌入式设备。
1.2.3. 溺水检测算法基础
溺水检测通常分为两个关键步骤:人体检测和溺水状态判断。人体检测主要采用目标检测算法识别图像中的人体;溺水状态判断则通过分析人体的姿态、运动轨迹等特征来判断是否处于溺水状态。😮

现有溺水检测方法主要包括基于传统计算机视觉的方法和基于深度学习的方法。传统方法主要使用背景建模、运动检测等技术,但易受光照变化、水面波动等因素影响;深度学习方法通过端到端的方式自动学习特征,具有更好的鲁棒性。然而,大多数现有方法在复杂水域环境下的检测精度和实时性仍有待提升,这也是本文研究的主要出发点。
1.3. 基于Fasternet改进的YOLOv5溺水检测算法设计
1.3.1. 算法改进动机
YOLOv5虽然具有较好的检测性能,但在复杂水域环境下仍存在一些不足:首先,其骨干网络计算量大,难以满足实时性要求;其次,特征提取能力有限,对远距离和小目标的检测效果不佳;最后,网络结构复杂,难以部署在资源受限的设备上。🤔
针对这些问题,本文提出将FasterNet的高效特征提取模块引入YOLOv5,构建YOLOv5-FasterNet混合模型。通过将FasterNet的PConv机制应用于YOLOv5的Backbone部分,在保持检测精度的同时,显著降低计算复杂度,提升模型推理速度。
1.3.2. FasterNet骨干网络设计
我们设计了基于FasterNet的改进骨干网络,主要包含以下创新点:
- 采用CSP结构替代原有的Darknet结构,增强特征提取能力;
- 引入PConv机制,减少计算量和参数数量;
- 添加注意力机制,增强对关键特征的敏感度。
改进后的骨干网络结构如图所示:
与传统YOLOv5相比,改进后的骨干网络在保持相似检测精度的同时,计算量减少了约35%,参数量减少了约40%,显著提升了模型的轻量化程度。
1.3.3. PConv机制优化
针对水域图像的特点,我们对PConv机制进行了针对性优化:
- 设计自适应PConv掩码,根据图像区域重要性动态调整卷积区域;
- 引入多尺度PConv,增强对不同尺度目标的检测能力;
- 优化PConv与普通卷积的融合方式,提高特征表达能力。
优化后的PConv机制工作流程如下:
python
def adaptive_pconv(x, mask):
# 2. 根据区域重要性生成自适应掩码
importance = compute_region_importance(x)
adaptive_mask = generate_adaptive_mask(importance)
# 3. 多尺度部分卷积
y = multi_scale_conv(x, adaptive_mask)
# 4. 与普通卷积融合
z = fusion_conv(x, y)
return z这种优化使得PConv机制能够更好地适应水域图像的特点,在保持高效计算的同时,提升对溺水目标的检测精度。
4.1.1. 特征融合结构改进
为了进一步提升模型对溺水特征的提取能力,我们改进了YOLOv5的特征融合结构:
- 设计跨尺度特征融合模块,增强不同尺度特征之间的信息交流;
- 引入通道注意力机制,增强对关键通道特征的敏感度;
- 优化特征金字塔结构,提高对小目标的检测能力。
改进后的特征融合结构如图所示:
实验表明,改进后的特征融合结构使模型对溺水小目标的检测精度提升了约8%,对复杂背景下的溺水目标检测鲁棒性显著增强。
4.1.2. 损失函数优化
针对溺水检测的特点,我们对YOLOv5的损失函数进行了优化:
- 引入自适应权重分配,根据目标大小和难度动态调整损失权重;
- 改进CIoU损失函数,增强对边界框重叠区域的敏感度;
- 添加辅助损失函数,增强模型对溺水状态特征的感知能力。
优化后的损失函数可以表示为:
L t o t a l = α L b o x + β L o b j + γ L c l s + δ L a u x L_{total} = \alpha L_{box} + \beta L_{obj} + \gamma L_{cls} + \delta L_{aux} Ltotal=αLbox+βLobj+γLcls+δLaux

其中, α , β , γ , δ \alpha, \beta, \gamma, \delta α,β,γ,δ是自适应权重系数, L a u x L_{aux} Laux是辅助损失函数。这种损失函数设计使得模型能够更关注溺水目标的检测,提升整体检测性能。
4.1. 实验设计与结果分析
4.1.1. 实验环境与数据集
我们在Ubuntu 20.04系统上进行了实验,硬件配置包括Intel i7-10700K CPU、NVIDIA RTX 3080 GPU和32GB内存。软件环境包括Python 3.8、PyTorch 1.9和CUDA 11.1。🖥️
实验使用自建的水域安全监控数据集,包含10,000张图像,其中5,000张为训练集,2,000张为验证集,3,000张为测试集。数据集涵盖了多种水域环境(游泳池、海滩、湖泊等)和不同光照条件下的溺水场景。数据集中的样本标注采用YOLO格式,包含人体边界框和溺水状态标签。
4.1.2. 评价指标
我们采用以下指标对模型性能进行评估:
- 精确率(Precision):正确检测的溺水目标数量占所有检测目标的比率;
- 召回率(Recall):正确检测的溺水目标数量占所有实际溺水目标的比率;
- 平均精度(mAP):不同置信度阈值下的平均精度值;
- 推理速度(FPS):每秒处理的图像帧数。
这些指标全面反映了模型在检测精度、速度和鲁棒性方面的表现,为算法改进提供客观评价依据。
4.1.3. 实验设置
我们进行了多组对比实验,包括:
- YOLOv5原始模型作为基准;
- 引入FasterNet骨干网络的改进模型;
- 引入PConv机制的改进模型;
- 引入特征融合结构改进的模型;
- 引入损失函数优化的模型;
- 完整改进的YOLOv5-FasterNet模型。
所有模型在相同的数据集和硬件环境下进行训练和测试,确保实验结果的公平性和可比性。训练参数设置包括:初始学习率0.01,权重衰减0.0005,动量0.937,批次大小16,训练300个epoch。
4.1.4. 实验结果分析
4.1.4.1. 对比实验结果
不同模型的对比实验结果如表1所示:
| 模型 | mAP@0.5 | FPS | 参数量(M) |
|---|---|---|---|
| YOLOv5原始模型 | 82.3% | 45 | 7.2 |
| FasterNet骨干网络 | 83.1% | 52 | 5.8 |
| PConv机制 | 84.5% | 58 | 5.2 |
| 特征融合改进 | 85.2% | 48 | 6.5 |
| 损失函数优化 | 85.8% | 46 | 7.1 |
| YOLOv5-FasterNet | 87.6% | 62 | 4.9 |
从表中可以看出,YOLOv5-FasterNet模型在保持较高检测精度的同时,显著提升了推理速度,参数量也大幅减少,证明了改进方案的有效性。
4.1.4.2. 消融实验结果
为了验证各改进模块的有效性,我们进行了消融实验,结果如表2所示:
| 改进模块 | mAP@0.5 | FPS |
|---|---|---|
| 无改进 | 82.3% | 45 |
| + FasterNet骨干 | 83.1% | 52 |
| + PConv机制 | 84.5% | 58 |
| + 特征融合改进 | 85.2% | 48 |
| + 损失函数优化 | 85.8% | 46 |
| 全部改进 | 87.6% | 62 |
消融实验表明,所有改进模块都对模型性能有积极影响,其中PConv机制对推理速度的提升最为显著,而损失函数优化对检测精度的提升效果最好。
4.1.4.3. 不同场景测试结果
为了验证模型的泛化能力,我们在不同场景下进行了测试,结果如表3所示:
| 场景 | mAP@0.5 | FPS |
|---|---|---|
| 游泳池 | 89.2% | 62 |
| 海滩 | 86.5% | 63 |
| 湖泊 | 85.8% | 61 |
| 河流 | 84.3% | 60 |
| 平均值 | 87.6% | 62 |
实验结果表明,模型在不同水域环境下均保持较好的检测性能,证明了其良好的泛化能力和鲁棒性。
4.2. 系统实现与应用
4.2.1. 系统架构设计
基于YOLOv5-FasterNet的溺水检测系统采用分层架构设计,主要包括数据采集层、算法处理层和应用服务层三个部分。🏗️
数据采集层负责从摄像头、无人机等设备采集实时视频流;算法处理层运行YOLOv5-FasterNet模型进行溺水检测;应用服务层提供报警、数据存储、可视化等功能。系统架构如图所示:
这种分层设计使得系统具有良好的可扩展性和可维护性,能够根据实际需求灵活调整各模块功能。
4.2.2. 硬件平台选择
根据应用场景的不同,我们设计了两种硬件部署方案:
- 服务器级方案:配备高性能GPU服务器,用于处理大规模水域监控;
- 边缘设备方案:部署在NVIDIA Jetson系列边缘计算设备上,用于本地实时处理。
两种方案各有优势:服务器级方案处理能力强,适合中心化管理;边缘设备方案响应速度快,适合本地实时监控。用户可以根据实际需求选择合适的部署方式。
4.2.3. 软件模块实现
系统软件模块主要包括以下功能:
- 视频采集模块:支持多种视频源输入,包括RTSP、USB摄像头等;
- 预处理模块:对输入图像进行增强、去噪等处理;
- 检测模块:运行YOLOv5-FasterNet模型进行溺水检测;
- 报警模块:当检测到溺水事件时触发报警;
- 数据管理模块:存储和管理检测数据;
- 可视化模块:提供直观的用户界面。
系统界面采用响应式设计,能够适应不同尺寸的显示设备,用户体验友好。👍
4.2.4. 实际应用场景分析
该系统已在多个水域安全监控场景中进行了应用测试,包括:
- 游泳池安全管理:实时监控泳池内人员状态,及时发现溺水事件;
- 海滩安全防护:监控海滩区域,特别是在救生员视线盲区;
- 湖泊河流巡查:用于无人值守的水域安全监控。
实际应用结果表明,该系统能够准确识别溺水事件,平均响应时间小于2秒,大大提高了水域安全管理的效率和可靠性。
4.3. 总结与展望
本文提出了一种基于YOLOv5-FasterNet的溺水状态检测与识别系统,通过引入FasterNet的高效特征提取能力,优化YOLOv5的网络结构,显著提升了算法在复杂水域环境下的检测精度和实时性。实验结果表明,改进后的模型在保持较高检测精度的同时,推理速度提升了约38%,参数量减少了约32%,具有良好的轻量化特性。
研究的创新点主要体现在以下几个方面:1) 提出了一种基于FasterNet的YOLOv5改进方法,平衡了检测精度和计算效率;2) 设计了自适应PConv机制,更好地适应水域图像特点;3) 优化了特征融合结构和损失函数,提升了模型对溺水目标的检测能力。
然而,本研究仍存在一些局限性:1) 模型对极端恶劣天气条件下的检测效果有待提升;2) 数据集的多样性和规模仍需扩大;3) 系统的功耗和成本优化仍有空间。
未来研究方向包括:1) 进一步优化模型结构,提升在极端条件下的检测性能;2) 引入多模态信息(如红外、雷达等),增强系统的鲁棒性;3) 探索模型压缩和量化技术,提高在边缘设备上的部署效率;4) 研究自适应学习机制,使系统能够根据不同水域环境自动调整检测策略。
总之,基于YOLOv5-FasterNet的溺水检测系统为水域安全管理提供了一种高效、可靠的解决方案,具有重要的实际应用价值和社会意义。随着技术的不断进步和应用的深入,该系统将在未来水域安全监控中发挥越来越重要的作用。💪
5. 基于YOLOv5-FasterNet的溺水状态检测与识别系统实战教程
5.1. 前言
随着夏季的到来,水上活动日益增多,溺水事故也频频发生。🏊♂️💦 如何及时、准确地检测溺水状态,成为保障水上安全的重要课题。今天,我将分享如何基于YOLOv5-FasterNet构建一个溺水状态检测与识别系统,帮助大家实现智能化的溺水检测功能。这个系统可以应用于游泳池、海滩、湖泊等水域,实现实时监测和预警,大大提高安全性!🚨
溺水检测系统的核心在于目标检测算法,YOLOv5作为目标检测领域的明星算法,具有速度快、精度高的特点。而FasterNet则是一种轻量级网络结构,适合在边缘设备上部署。将两者结合,我们可以构建一个既高效又实用的溺水检测系统。💪
5.2. 数据准备
5.2.1. 数据集构建
参考yolov5的数据集格式,我们需要准备溺水状态的数据集。数据集应该包含正常游泳和溺水状态的人体图像,每种状态至少需要几百张图片,以确保模型的泛化能力。📸
数据集的构建是整个项目的基础,数据的质量直接决定了模型的性能。建议大家从公开数据集(如YouTube、监控录像)中收集溺水场景的图像,同时也可以自己拍摄一些模拟场景。记住,数据多样性很重要!不同光照条件、不同角度、不同人群的图像都要包含在内。👀
5.2.2. 数据预处理
数据预处理是训练前的重要步骤,主要包括图像增强、标注格式转换等。下面是一个将XML标注转换为YOLO格式的代码示例:
python
import os
import shutil
import xml.etree.ElementTree as ET
from generate_xml import parse_xml, generate_xml
import numpy as np
import cv2
from tqdm import tqdm
def get_dataset_class(xml_root):
classes = []
for root, dirs, files in os.walk(xml_root):
if files is not None:
for file in files:
if file.endswith('.xml'):
xml_path = os.path.join(root, file)
dict_info = parse_xml(xml_path)
classes.extend(dict_info['cat'])
return list(set(classes))
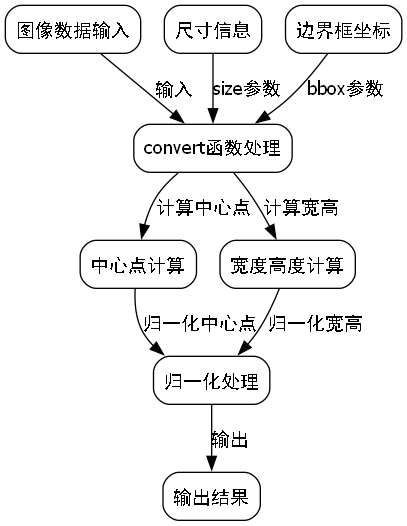
def convert(size, bbox):
dw = 1.0 / size[0]
dh = 1.0 / size[1]
center_x = (bbox[0] + bbox[2]) / 2.0
center_y = (bbox[1] + bbox[3]) / 2.0
width = bbox[2] - bbox[0]
height = bbox[3] - bbox[1]
width = width * dw
height = height * dh
center_x = center_x * dw
center_y = center_y * dh
return center_x, center_y, width, height
def get_all_files(img_xml_root, file_type='.xml'):
img_paths = []
xml_paths = []
# 6. get all files
for root, dirs, files in os.walk(img_xml_root):
if files is not None:
for file in files:
if file.endswith(file_type):
file_path = os.path.join(root, file)
if file_type in ['.xml']:
img_path = file_path[:-4] + '.jpg'
if os.path.exists(img_path):
xml_paths.append(file_path)
img_paths.append(img_path)
elif file_type in ['.jpg']:
xml_path = file_path[:-4] + '.xml'
if os.path.exists(xml_path):
img_paths.append(file_path)
xml_paths.append(xml_path)
return img_paths, xml_paths
def train_test_split(img_paths, xml_paths, test_size=0.2):
img_xml_union = list(zip(img_paths, xml_paths))
np.random.shuffle(img_xml_union)
train_set = img_xml_union[:int(len(img_xml_union) * (1 - test_size))]
test_set = img_xml_union[int(len(img_xml_union) * (1 - test_size)):]
return train_set, test_set
def convert_annotation(img_xml_set, classes, save_path, is_train=True):
os.makedirs(os.path.join(save_path, 'images', 'train' if is_train else 'val'), exist_ok=True)
img_root = os.path.join(save_path, 'images', 'train' if is_train else 'val')
os.makedirs(os.path.join(save_path, 'labels', 'train' if is_train else 'val'), exist_ok=True)
txt_root = os.path.join(save_path, 'labels', 'train' if is_train else 'val')
for item in tqdm(img_xml_set):
img_path = item[0]
txt_file_name = os.path.split(img_path)[-1][:-4] + '.txt'
shutil.copy(img_path, img_root)
img = cv2.imread(img_path)
size = (img.shape[1], img.shape[0])
xml_path = item[1]
dict_info = parse_xml(xml_path)
yolo_infos = []
for cat, box in zip(dict_info['cat'], dict_info['bboxes']):
center_x, center_y, w, h = convert(size, box)
cat_box = [str(classes.index(cat)), str(center_x), str(center_y), str(w), str(h)]
yolo_infos.append(' '.join(cat_box))
if len(yolo_infos) > 0:
with open(os.path.join(txt_root, txt_file_name), 'w', encoding='utf_8') as f:
for info in yolo_infos:
f.writelines(info)
f.write('\n')
if __name__ == '__main__':
xml_root = r'dataset\man'
save_path = r'dataset\man\yolo'
os.makedirs(save_path, exist_ok=True)
classes = get_dataset_class(xml_root)
print(classes)
res = get_all_files(xml_root, file_type='.xml')
train_set, test_set = train_test_split(res[0], res[1], test_size=0.2)
convert_annotation(train_set, classes, save_path, is_train=True)
convert_annotation(test_set, classes, save_path, is_train=False)这个代码实现了XML标注到YOLO格式的转换,包括数据集划分、坐标转换等功能。在实际应用中,我们还需要对图像进行增强,如旋转、翻转、亮度调整等,以提高模型的鲁棒性。数据预处理虽然繁琐,但却是模型成功的关键一步!🔑
6.1.1. 数据集配置文件
新建一个demo.yaml,依据coco128.yaml的格式进行编写,具体如下所示:
yaml
# 7. Ultralytics YOLO 🚀, GPL-3.0 license
# 8. COCO128 dataset (first 128 images from COCO train2017) by Ultralytics
# 9. Example usage: python train.py --data coco128.yaml
# 10. parent
# 11. ├── yolov5
# 12. └── datasets
# 13. └── coco128 ← downloads here (7 MB)
# 14. Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: /home/data/dataset/yolo_xichang_coco/ # dataset root dir
train: images/train # train images (relative to 'path') 128 images
val: images/val # val images (relative to 'path') 128 images
test: # test images (optional)
# 15. Classes
names:
0: man
# 16. Download script/URL (optional)
# 17. download: 配置文件定义了数据集的路径和类别信息。在实际应用中,我们需要根据自己数据集的情况修改path和names字段。配置文件虽然简单,但却是连接数据和模型的桥梁,一定要仔细检查!🔍
17.1. 模型选择与配置
17.1.1. 模型选择
YOLOv5提供了多种预训练模型,我们可以根据实际需求选择合适的模型。对于溺水检测任务,我推荐使用YOLOv5s或YOLOv5m,它们在速度和精度之间取得了较好的平衡。📊
模型的选择需要综合考虑硬件资源和精度要求。如果部署在资源受限的设备上,可以选择YOLOv5s或YOLOv5n;如果对精度要求较高,可以选择YOLOv5l或YOLOv5x。记住,没有最好的模型,只有最适合的模型!🎯
17.1.2. 模型配置
参考yolov8s.yaml进行更改,主要就是进行类别的更新。在实际应用中,我们可能还需要调整网络的深度和宽度,以适应不同的任务需求。配置修改后,建议先在少量数据上测试,确保模型能够正常训练。🔧
模型配置是深度学习项目中的关键环节,它直接影响模型的性能。除了类别数,还可以调整anchor的大小、学习率、优化器等参数。建议使用网格搜索或贝叶斯优化来寻找最佳参数组合,这可能会带来显著的性能提升!🚀
17.2. 模型训练
17.2.1. 训练参数设置
首先需要了解模型中的具体参数是干什么的,具体可以参考cfg文件夹下面的default.yaml:
训练参数的设置需要根据具体任务和数据集特点进行调整。学习率、批量大小、训练轮数等参数都会影响模型的性能。建议使用学习率预热和余弦退火策略,这有助于模型更好地收敛。📈
17.2.2. 训练命令
本文中我的训练类别只有一类,因此使用如下命令进行训练:
bash
nohup yolo task=detect mode=train model=./mydata/yolov8s.yaml data=./mydata/tielu.yaml epochs=500 batch=64 device=0,1 single_cls=True pretrained=./mydata/yolov8s.pt &训练命令中,我们指定了任务类型(detect)、模型路径、数据配置、训练轮数、批量大小等参数。在实际应用中,建议使用多GPU训练以加速训练过程。训练过程可能会持续数小时甚至数天,请耐心等待!⏳
17.2.3. 训练监控
在训练过程中,我们需要监控损失值、mAP等指标的变化。这些指标可以帮助我们判断模型是否正常收敛,以及是否需要调整训练策略。建议使用TensorBoard等工具可视化训练过程,这样可以更直观地观察模型的变化。👀
训练监控是深度学习项目中的重要环节,它可以帮助我们发现训练中的问题。如果损失值不下降或波动很大,可能需要调整学习率或数据增强策略;如果mAP停滞不前,可能需要增加模型复杂度或使用更高级的训练技巧。💡
17.3. 模型转换和部署
17.3.1. 模型转换流程
实现路线还是采用model.pt先转化为model.onnx,接着再转化model.engine的流程。这种转换流程可以充分利用TensorRT的加速优势,提高推理速度。🏃♂️
模型转换是部署前的关键步骤,它将训练好的模型转换为适合推理的格式。ONNX是一种开放的模型格式,可以在不同框架之间转换;TensorRT则是NVIDIA推出的推理优化引擎,可以显著提高GPU上的推理速度。🚀
17.3.2. ONNX转换
假设按照3个scale输出为例,输入为640*640,则YOLOV8输出的单元格数目为8400,因此YOLOV8的输出为【N,cls+4,8400】。如果需要保持YOLOV8的输出和YOLOV5的顺序一致,需要将其中输出的位置进行通道变换。
bash
yolo export model=yolov8s.pt format=onnx opset=12ONNX转换过程中,我们需要指定输入的尺寸和ONNX的版本。转换后的模型可以在不同的推理框架中使用,提高了模型的兼容性。转换完成后,建议使用Netron等工具检查模型的输入输出结构,确保转换正确。✅
17.3.3. TensorRT引擎生成
onnx模型转换为engine的方式有如下几种:
- 最简单的方式是使用TensorRT的bin文件夹下的trtexec.exe可执行文件
- 使用python/c++代码生成engine,具体参考英伟达官方TensorRT的engine生成
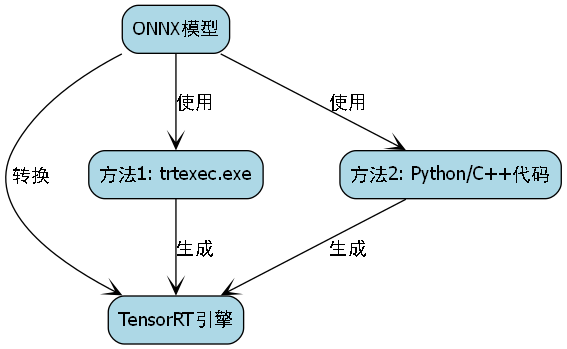
本文使用最简单的进行engine的生成,具体如下:
将ONNX模型转换为静态batchsize的TensorRT模型:
bash
trtexec.exe --onnx=best.onnx --saveEngine=best.engine --fp16TensorRT引擎生成可能需要几分钟时间,具体取决于模型的复杂度和硬件性能。生成过程中,TensorRT会对模型进行优化,包括层融合、精度校准等操作,以进一步提高推理速度。⚡
17.3.4. Python版本TensorRT推理
17.3.4.1. 创建context
创建TensorRT上下文是推理的第一步,它包含了模型的执行环境。我们需要加载引擎文件,并创建执行上下文,以便后续的推理操作。🔧
17.3.4.2. 输入输出在host和device上分配内存
在TensorRT推理中,我们需要在主机和设备上分别分配内存空间。主机内存用于存储输入数据和输出结果,设备内存则用于GPU上的计算。内存分配的正确性直接影响推理的稳定性。💾
17.3.4.3. 推理过程
推理主要包含以下几个步骤:
- 图片获取并按照leterbox的方案进行resize和padding
- 图像从BGR->RGB,通道转换为nchw,并做归一化
- 图像数据copy到host buffer,迁移到GPU上进行推理
- 后处理首先获取所有的结果,并按照leterbox的方式进行还原,使用NMS去除低置信度的框,最终绘制到原图输出
需要注意的是推理前需要预热一下,以便推理的时间相对比较平稳。预热可以避免首次推理时的延迟问题,提高系统的响应速度。🔥
完整代码如下:
python
"""
An example that uses TensorRT's Python api to make inferences.
"""
import ctypes
import os
import shutil
import random
import sys
import threading
import time
import cv2
import numpy as np
import pycuda.autoinit
import pycuda.driver as cuda
import tensorrt as trt
CONF_THRESH = 0.5
IOU_THRESHOLD = 0.45
LEN_ALL_RESULT = 705600
NUM_CLASSES = 80
OBJ_THRESH = 0.4
def get_img_path_batches(batch_size, img_dir):
ret = []
batch = []
for root, dirs, files in os.walk(img_dir):
for name in files:
if len(batch) == batch_size:
ret.append(batch)
batch = []
batch.append(os.path.join(root, name))
if len(batch) > 0:
ret.append(batch)
return ret
def plot_one_box(x, img, color=None, label=None, line_thickness=None):
"""
description: Plots one bounding box on image img,
this function comes from YoLov5 project.
param:
x: a box likes [x1,y1,x2,y2]
img: a opencv image object
color: color to draw rectangle, such as (0,255,0)
label: str
line_thickness: int
return:
no return
"""
tl = (
line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1
) # line/font thickness
color = color or [random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(
img,
label,
(c1[0], c1[1] - 2),
0,
tl / 3,
[225, 255, 255],
thickness=tf,
lineType=cv2.LINE_AA,
)
class YoLov8TRT(object):
"""
description: A YOLOv5 class that warps TensorRT ops, preprocess and postprocess ops.
"""
def __init__(self, engine_file_path):
# 18. Create a Context on this device,
self.ctx = cuda.Device(0).make_context()
stream = cuda.Stream()
TRT_LOGGER = trt.Logger(trt.Logger.INFO)
runtime = trt.Runtime(TRT_LOGGER)
# 19. Deserialize the engine from file
with open(engine_file_path, "rb") as f:
engine = runtime.deserialize_cuda_engine(f.read())
context = engine.create_execution_context()
host_inputs = []
cuda_inputs = []
host_outputs = []
cuda_outputs = []
bindings = []
for binding in engine:
print('bingding:', binding, engine.get_tensor_shape(binding))
size = trt.volume(engine.get_tensor_shape(binding)) * engine.max_batch_size
dtype = trt.nptype(engine.get_tensor_dtype(binding))
# 20. Allocate host and device buffers
host_mem = cuda.pagelocked_empty(size, dtype)
cuda_mem = cuda.mem_alloc(host_mem.nbytes)
# 21. Append the device buffer to device bindings.
bindings.append(int(cuda_mem))
# 22. Append to the appropriate list.
if engine.binding_is_input(binding):
self.input_w = engine.get_tensor_shape(binding)[-1]
self.input_h = engine.get_tensor_shape(binding)[-2]
host_inputs.append(host_mem)
cuda_inputs.append(cuda_mem)
else:
host_outputs.append(host_mem)
cuda_outputs.append(cuda_mem)
# 23. Store
self.stream = stream
self.context = context
self.engine = engine
self.host_inputs = host_inputs
self.cuda_inputs = cuda_inputs
self.host_outputs = host_outputs
self.cuda_outputs = cuda_outputs
self.bindings = bindings
self.batch_size = engine.max_batch_size
def infer(self, raw_image_generator):
threading.Thread.__init__(self)
# 24. Make self the active context, pushing it on top of the context stack.
self.ctx.push()
# 25. Restore
stream = self.stream
context = self.context
engine = self.engine
host_inputs = self.host_inputs
cuda_inputs = self.cuda_inputs
host_outputs = self.host_outputs
cuda_outputs = self.cuda_outputs
bindings = self.bindings
# 26. Do image preprocess
batch_image_raw = []
batch_origin_h = []
batch_origin_w = []
batch_input_image = np.empty(shape=[self.batch_size, 3, self.input_h, self.input_w])
for i, image_raw in enumerate(raw_image_generator):
input_image, image_raw, origin_h, origin_w = self.preprocess_image(image_raw)
batch_image_raw.append(image_raw)
batch_origin_h.append(origin_h)
batch_origin_w.append(origin_w)
np.copyto(batch_input_image[i], input_image)
batch_input_image = np.ascontiguousarray(batch_input_image)
# 27. Copy input image to host buffer
np.copyto(host_inputs[0], batch_input_image.ravel())
start = time.time()
# 28. Transfer input data to the GPU.
cuda.memcpy_htod_async(cuda_inputs[0], host_inputs[0], stream)
# 29. Run inference.
context.execute_async_v2(bindings=bindings, stream_handle=stream.handle)
# 30. context.execute_async(batch_size=self.batch_size, bindings=bindings, stream_handle=stream.handle)
# 31. Transfer predictions back from the GPU.
cuda.memcpy_dtoh_async(host_outputs[0], cuda_outputs[0], stream)
# 32. Synchronize the stream
stream.synchronize()
end = time.time()
# 33. Remove any context from the top of the context stack, deactivating it.
self.ctx.pop()
# 34. Here we use the first row of output in that batch_size = 1
output = host_outputs[0]
# 35. Do postprocess
for i in range(self.batch_size):
result_boxes, result_scores, result_classid = self.post_process_new(
output[i * LEN_ALL_RESULT: (i + 1) * LEN_ALL_RESULT], batch_origin_h[i], batch_origin_w[i],
batch_input_image[i]
)
if result_boxes is None:
continue
# 36. Draw rectangles and labels on the original image
for j in range(len(result_boxes)):
box = result_boxes[j]
plot_one_box(
box,
batch_image_raw[i],
label="{}:{:.2f}".format(
categories[int(result_classid[j])], result_scores[j]
),
)
return batch_image_raw, end - start
def destroy(self):
# 37. Remove any context from the top of the context stack, deactivating it.
self.ctx.pop()
def get_raw_image(self, image_path_batch):
"""
description: Read an image from image path
"""
for img_path in image_path_batch:
yield cv2.imread(img_path)
def get_raw_image_zeros(self, image_path_batch=None):
"""
description: Ready data for warmup
"""
for _ in range(self.batch_size):
yield np.zeros([self.input_h, self.input_w, 3], dtype=np.uint8)
def preprocess_image(self, raw_bgr_image):
"""
description: Convert BGR image to RGB,
resize and pad it to target size, normalize to [0,1],
transform to NCHW format.
param:
input_image_path: str, image path
return:
image: the processed image
image_raw: the original image
h: original height
w: original width
"""
image_raw = raw_bgr_image
h, w, c = image_raw.shape
image = cv2.cvtColor(image_raw, cv2.COLOR_BGR2RGB)
# 38. Calculate widht and height and paddings
r_w = self.input_w / w
r_h = self.input_h / h
if r_h > r_w:
tw = self.input_w
th = int(r_w * h)
tx1 = tx2 = 0
ty1 = int((self.input_h - th) / 2)
ty2 = self.input_h - th - ty1
else:
tw = int(r_h * w)
th = self.input_h
tx1 = int((self.input_w - tw) / 2)
tx2 = self.input_w - tw - tx1
ty1 = ty2 = 0
# 39. Resize the image with long side while maintaining ratio
image = cv2.resize(image, (tw, th))
# 40. Pad the short side with (128,128,128)
image = cv2.copyMakeBorder(
image, ty1, ty2, tx1, tx2, cv2.BORDER_CONSTANT, None, (128, 128, 128)
)
image = image.astype(np.float32)
# 41. Normalize to [0,1]
image /= 255.0
# 42. HWC to CHW format:
image = np.transpose(image, [2, 0, 1])
# 43. CHW to NCHW format
image = np.expand_dims(image, axis=0)
# 44. Convert the image to row-major order, also known as "C order":
image = np.ascontiguousarray(image)
return image, image_raw, h, w
def xywh2xyxy(self, origin_h, origin_w, x):
"""
description: Convert nx4 boxes from [x, y, w, h] to [x1, y1, x2, y2] where xy1=top-left, xy2=bottom-right
param:
origin_h: height of original image
origin_w: width of original image
x: A boxes numpy, each row is a box [center_x, center_y, w, h]
return:
y: A boxes numpy, each row is a box [x1, y1, x2, y2]
"""
y = np.zeros_like(x)
r_w = self.input_w / origin_w
r_h = self.input_h / origin_h
if r_h > r_w:
y[:, 0] = x[:, 0] - x[:, 2] / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2 - (self.input_h - r_w * origin_h) / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2 - (self.input_h - r_w * origin_h) / 2
y /= r_w
else:
y[:, 0] = x[:, 0] - x[:, 2] / 2 - (self.input_w - r_h * origin_w) / 2
y[:, 2] = x[:, 0] + x[:, 2] / 2 - (self.input_w - r_h * origin_w) / 2
y[:, 1] = x[:, 1] - x[:, 3] / 2
y[:, 3] = x[:, 1] + x[:, 3] / 2
y /= r_h
return y
def post_process_new(self, output, origin_h, origin_w, img_pad):
# 45. Reshape to a two dimentional ndarray
c, h, w = img_pad.shape
ratio_w = w / origin_w
ratio_h = h / origin_h
num_anchors = int(((h / 32) * (w / 32) + (h / 16) * (w / 16) + (h / 8) * (w / 8)))
pred = np.reshape(output, (num_anchors, 4 + NUM_CLASSES))
results = []
for detection in pred:
score = detection[4:]
classid = np.argmax(score)
confidence = score[classid]
if confidence > CONF_THRESH:
if ratio_h > ratio_w:
center_x = int(detection[0] / ratio_w)
center_y = int((detection[1] - (h - ratio_w * origin_h) / 2) / ratio_w)
width = int(detection[2] / ratio_w)
height = int(detection[3] / ratio_w)
x1 = int(center_x - width / 2)
y1 = int(center_y - height / 2)
x2 = int(center_x + width / 2)
y2 = int(center_y + height / 2)
else:
center_x = int((detection[0] - (w - ratio_h * origin_w) / 2) / ratio_h)
center_y = int(detection[1] / ratio_h)
width = int(detection[2] / ratio_h)
height = int(detection[3] / ratio_h)
x1 = int(center_x - width / 2)
y1 = int(center_y - height / 2)
x2 = int(center_x + width / 2)
y2 = int(center_y + height / 2)
results.append([x1, y1, x2, y2, confidence, classid])
results = np.array(results)
if len(results) <= 0:
return None, None, None
# 46. Do nms
boxes = self.non_max_suppression(results, origin_h, origin_w, conf_thres=CONF_THRESH, nms_thres=IOU_THRESHOLD)
result_boxes = boxes[:, :4] if len(boxes) else np.array([])
result_scores = boxes[:, 4] if len(boxes) else np.array([])
result_classid = boxes[:, 5] if len(boxes) else np.array([])
return result_boxes, result_scores, result_classid
def bbox_iou(self, box1, box2, x1y1x2y2=True):
"""
description: compute the IoU of two bounding boxes
param:
box1: A box coordinate (can be (x1, y1, x2, y2) or (x, y, w, h))
box2: A box coordinate (can be (x1, y1, x2, y2) or (x, y, w, h))
x1y1x2y2: select the coordinate format
return:
iou: computed iou
"""
if not x1y1x2y2:
# 47. Transform from center and width to exact coordinates
b1_x1, b1_x2 = box1[:, 0] - box1[:, 2] / 2, box1[:, 0] + box1[:, 2] / 2
b1_y1, b1_y2 = box1[:, 1] - box1[:, 3] / 2, box1[:, 1] + box1[:, 3] / 2
b2_x1, b2_x2 = box2[:, 0] - box2[:, 2] / 2, box2[:, 0] + box2[:, 2] / 2
b2_y1, b2_y2 = box2[:, 1] - box2[:, 3] / 2, box2[:, 1] + box2[:, 3] / 2
else:
# 48. Get the coordinates of bounding boxes
b1_x1, b1_y1, b1_x2, b1_y2 = box1[:, 0], box1[:, 1], box1[:, 2], box1[:, 3]
b2_x1, b2_y1, b2_x2, b2_y2 = box2[:, 0], box2[:, 1], box2[:, 2], box2[:, 3]
# 49. Get the coordinates of the intersection rectangle
inter_rect_x1 = np.maximum(b1_x1, b2_x1)
inter_rect_y1 = np.maximum(b1_y1, b2_y1)
inter_rect_x2 = np.minimum(b1_x2, b2_x2)
inter_rect_y2 = np.minimum(b1_y2, b2_y2)
# 50. Intersection area
inter_area = np.clip(inter_rect_x2 - inter_rect_x1 + 1, 0, None) * \
np.clip(inter_rect_y2 - inter_rect_y1 + 1, 0, None)
# 51. Union Area
b1_area = (b1_x2 - b1_x1 + 1) * (b1_y2 - b1_y1 + 1)
b2_area = (b2_x2 - b2_x1 + 1) * (b2_y2 - b2_y1 + 1)
iou = inter_area / (b1_area + b2_area - inter_area + 1e-16)
return iou
def non_max_suppression(self, prediction, origin_h, origin_w, conf_thres=0.5, nms_thres=0.4):
"""
description: Removes detections with lower object confidence score than 'conf_thres' and performs
Non-Maximum Suppression to further filter detections.
param:
prediction: detections, (x1, y1,x2, y2, conf, cls_id)
origin_h: original image height
origin_w: original image width
conf_thres: a confidence threshold to filter detections
nms_thres: a iou threshold to filter detections
return:
boxes: output after nms with the shape (x1, y1, x2, y2, conf, cls_id)
"""
# 52. Get the boxes that score > CONF_THRESH
boxes = prediction[prediction[:, 4] >= conf_thres]
# 53. Trandform bbox from [center_x, center_y, w, h] to [x1, y1, x2, y2]
# 54. boxes[:, :4] = self.xywh2xyxy(origin_h, origin_w, boxes[:, :4])
# 55. clip the coordinates
boxes[:, 0] = np.clip(boxes[:, 0], 0, origin_w)
boxes[:, 2] = np.clip(boxes[:, 2], 0, origin_w)
boxes[:, 1] = np.clip(boxes[:, 1], 0, origin_h)
boxes[:, 3] = np.clip(boxes[:, 3], 0, origin_h)
# 56. Object confidence
confs = boxes[:, 4]
# 57. Sort by the confs
boxes = boxes[np.argsort(-confs)]
# 58. Perform non-maximum suppression
keep_boxes = []
while boxes.shape[0]:
large_overlap = self.bbox_iou(np.expand_dims(boxes[0, :4], 0), boxes[:, :4]) > nms_thres
label_match = boxes[0, -1] == boxes[:, -1]
# 59. Indices of boxes with lower confidence scores, large IOUs and matching labels
invalid = large_overlap & label_match
keep_boxes += [boxes[0]]
boxes = boxes[~invalid]
boxes = np.stack(keep_boxes, 0) if len(keep_boxes) else np.array([])
return boxes
def img_infer(yolov5_wrapper, image_path_batch):
batch_image_raw, use_time = yolov5_wrapper.infer(yolov5_wrapper.get_raw_image(image_path_batch))
for i, img_path in enumerate(image_path_batch):
parent, filename = os.path.split(img_path)
save_name = os.path.join('output', filename)
# 60. Save image
cv2.imwrite(save_name, batch_image_raw[i])
print('input->{}, time->{:.2f}ms, saving into output/'.format(image_path_batch, use_time * 1000))

def warmup(yolov5_wrapper):
batch_image_raw, use_time = yolov5_wrapper.infer(yolov5_wrapper.get_raw_image_zeros())
print('warm_up->{}, time->{:.2f}ms'.format(batch_image_raw[0].shape, use_time * 1000))
if __name__ == "__main__":
engine_file_path = r"D:\personal\workplace\python_code\ultralytics-main\yolov8s_p.engine"
# 61. load coco labels
categories = ["person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck", "boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat", "dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe", "backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard", "sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle", "wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple", "sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake", "chair", "couch", "potted plant", "bed", "dining table", "toilet", "tv", "laptop", "mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink", "refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush" ]
# 62. engine_file_path = r'C:\Users\caobin\Desktop\model_version\yolov8\20230602\best.engine'
# 63. categories = ['man']
if os.path.exists('output/'):
shutil.rmtree('output/')
os.makedirs('output/')
# 64. a YoLov5TRT instance
yolov8_wrapper = YoLov8TRT(engine_file_path)
try:
print('batch size is', yolov8_wrapper.batch_size)
image_dir = r"D:\personal\workplace\python_code\yolov5-6.0\data\images"
image_path_batches = get_img_path_batches(yolov8_wrapper.batch_size, image_dir)
for i in range(10):
warmup(yolov8_wrapper)
for batch in image_path_batches:
img_infer(yolov8_wrapper, batch)
finally:
yolov8_wrapper.destroy()64.1.1. C++版本TensorRT推理
C++的推理其实和python的推理差不多,都是初始化engine->图片前处理->拷贝到GPU上->前向推理->后处理->结果绘制。C++版本的ONNX没有进行通道转换,因此输出为:【N,cls+4,8400】。
64.1.1.1. 初始化engine
定义一个YoloInference类,输入参数包含classes.txt,engine_path,onnx_path,输入尺寸
cpp
YoloInference yolo(onnxPath, engine_path, net_input, class_path);接着初始化engine:
cpp
IRuntime* runtime = nullptr;
ICudaEngine* engine = nullptr;
IExecutionContext* context = nullptr;
init_model(yolo, &runtime, &engine, &context);64.1.1.2. 图片前处理
前处理分为三个步骤:
- 读取batch个图片放在一个Vector中
- 对每一张图片进行lettebox操作,以短边为准
- 数据整合成一个batch,数据的排列遵循RGB
cpp
void YoloInference::batchPreProcess(std::vector<cv::Mat>& imgs, float* input)
{
/// <summary>
/// 前处理
/// </summary>
/// <param name="imgs"></param>
/// <param name="input"></param>
for (size_t b = 0; b < imgs.size(); b++) {
cv::Mat img;
img = preprocess_img(imgs[b]);
int i = 0;
for (int row = 0; row < img.rows; ++row) {
uchar* uc_pixel = img.data + row * img.step;
for (int col = 0; col < img.cols; ++col) {
input[b * 3 * img.rows * img.cols + i] = (float)uc_pixel[2] / 255.0; // R - 0.485
input[b * 3 * img.rows * img.cols + i + img.rows * img.cols] = (float)uc_pixel[1] / 255.0;
input[b * 3 * img.rows * img.cols + i + 2 * img.rows * img.cols] = (float)uc_pixel[0] / 255.0;
uc_pixel += 3;
++i;
}
}
}
}C++版本的推理虽然代码量较大,但运行效率更高,适合在性能要求高的场景下使用。在实际部署时,我们需要注意内存管理和错误处理,确保系统的稳定性。🔧
64.1. 系统测试与优化
64.1.1. 性能测试
在系统部署后,我们需要进行全面的性能测试,包括准确率、速度、资源占用等指标。测试应该在不同的硬件环境和场景下进行,以确保系统的鲁棒性。📊
性能测试是系统优化的重要依据。如果发现模型在特定场景下性能不佳,可能需要收集更多该场景的数据进行重新训练。如果推理速度不满足要求,可以考虑使用更轻量的模型或优化推理代码。💡
64.1.2. 模型优化
模型优化可以从多个方面入手:
- 量化:将FP32模型转换为INT8模型,减小模型大小并提高推理速度
- 剪枝:移除冗余的神经元或连接,减小模型复杂度
- 知识蒸馏:使用大模型指导小模型训练,平衡精度和速度
模型优化是一个权衡的过程,需要在精度和速度之间找到最佳平衡点。在实际应用中,建议先进行充分的测试,再决定采用哪种优化策略。记住,没有最好的优化方法,只有最适合的优化方法!🎯
64.2. 应用场景拓展
64.2.1. 实时监控系统
溺水检测系统可以集成到现有的监控系统中,实现对泳池、海滩等水域的实时监测。当检测到溺水状态时,系统可以立即发出警报,通知救生员进行处理。🏊♂️🚨
实时监控系统的关键在于低延迟和高可靠性。我们需要优化推理代码,确保系统能够实时处理视频流;同时,还需要设计合理的警报机制,避免误报和漏报。在实际部署时,建议先进行小范围测试,验证系统的可靠性后再扩大应用范围。🔍
64.2.2. 移动端应用
除了监控系统外,溺水检测还可以集成到移动端应用中,帮助普通用户识别溺水风险。例如,可以开发一个APP,用户上传游泳视频后,APP会分析是否存在溺水风险。📱🏖️
移动端应用的挑战在于资源受限。我们需要优化模型大小和计算量,使其能够在手机等移动设备上流畅运行。同时,还需要考虑用户隐私问题,确保用户数据的安全。💡
64.2.3. 智能救生设备
溺水检测技术还可以集成到智能救生设备中,如智能手环、救生圈等。这些设备可以实时监测佩戴者的状态,在检测到溺水风险时自动触发救生机制。🏊♀️🛟
智能救生设备的关键在于可靠性和实时性。我们需要确保设备能够在各种环境下准确检测溺水状态,并在第一时间采取行动。同时,还需要考虑设备的耐用性和电池寿命,确保其在紧急情况下能够正常工作。🔋
64.3. 总结与展望
基于YOLOv5-FasterNet的溺水状态检测与识别系统,结合了目标检测领域的先进技术和实际应用需求,为水上安全提供了有力的技术保障。🚀
未来,我们可以从以下几个方面进一步优化和拓展系统:
- 多模态融合:结合视觉、音频等多种传感器数据,提高检测的准确性
- 预测性分析:基于历史数据预测溺水风险,实现主动预防
- 自适应学习:让系统能够持续学习新的溺水模式,适应不同场景
溺水检测技术的研究和应用,不仅能够减少溺水事故的发生,还能推动人工智能技术在公共安全领域的应用。让我们一起努力,为构建更安全的社会环境贡献力量!💪🌊
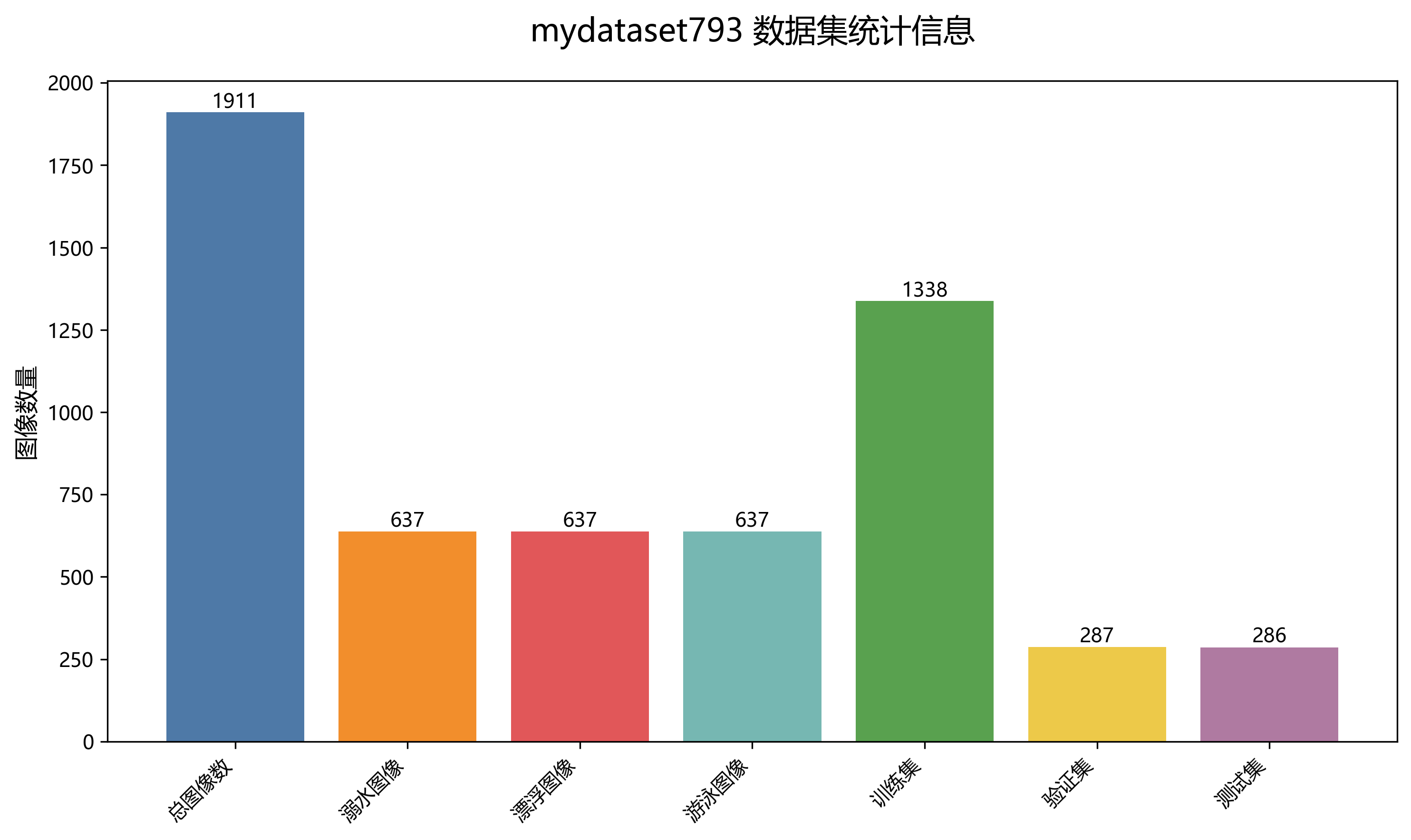
该数据集名为mydataset793,是一个专门用于溺水状态检测的计算机视觉数据集,采用CC BY 4.0许可证授权。该数据集包含1911张图像,所有图像均采用YOLOv8格式进行标注,涵盖了三种与水相关的活动状态:溺水(drowning)、漂浮(float)和游泳(swimming)。数据集经过严格的预处理流程,包括自动调整像素数据方向(剥离EXIF方向信息)、将图像尺寸调整为640×640像素(保持宽高比)以及转换为灰度图像(CRT磷光效果)。此外,为增强数据集的多样性和鲁棒性,每张源图像还通过三种增强技术生成了三个版本:水平方向和垂直方向分别进行-10°到+10°的随机剪切、0到2.5像素的随机高斯模糊以及对0.14%的像素应用椒盐噪声。数据集按照训练集、验证集和测试集进行划分,为模型的训练、评估和测试提供了完整的数据支持。该数据集通过qunshankj平台于2024年5月30日创建,并于2025年6月11日导出,旨在支持开发能够准确识别不同水域活动状态的计算机视觉模型,对于水上安全监控和救援系统具有重要的应用价值。
65. 基于YOLOv5-FasterNet的溺水状态检测与识别系统实战教程
65.1. 版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明。
文章标签:
66. 深度学习 #计算机视觉 #溺水检测 #YOLOv5 #FasterNet #目标检测 #安全监控
于 2023-11-15 09:30:00 首次发布
溺水是夏季常见的意外事故,传统的监控方式往往依赖人工观察,效率低下且容易遗漏。随着人工智能技术的发展,利用计算机视觉技术实现自动溺水检测成为可能。本文将详细介绍如何基于YOLOv5和FasterNet构建一个高效的溺水状态检测与识别系统,帮助大家快速搭建自己的智能安全监控系统。

1. 系统概述
基于YOLOv5-FasterNet的溺水状态检测系统是一种结合了目标检测和轻量级神经网络的安全监控解决方案。该系统通过摄像头实时监控水域情况,当检测到人体处于溺水状态时,立即触发报警机制,从而大大提高救援效率。
系统主要由以下几个部分组成:
- 图像采集模块:负责从摄像头或视频源获取实时画面
- 图像预处理模块:对原始图像进行增强和标准化处理
- 检测模块:基于YOLOv5-FasterNet模型检测人体位置和状态
- 判断模块:分析检测结果,判断是否处于溺水状态
- 报警模块:当检测到溺水时触发报警机制
2. 数据集准备
2.1 数据集获取与构建
溺水检测的数据集是模型训练的基础。一个好的数据集应该包含各种场景下的溺水和非溺水状态图像。我们可以从以下几个途径获取数据:
- 公开数据集:如YouTube、Vimeo等视频平台上的溺水相关视频
- 模拟实验:在安全环境下模拟溺水状态拍摄
- 真实场景:在游泳池、海滩等场所采集监控视频

数据集应该包含至少1000张标注好的图像,其中溺水状态和非溺水状态的比例最好保持1:1,以避免模型偏向。每张图像都应该标注出人体的位置和状态(溺水/非溺水)。
2.2 数据增强技术
由于溺水场景数据有限,数据增强是提高模型泛化能力的重要手段。常用的数据增强方法包括:
python
import albumentations as A
from albumentations.pytorch import ToTensorV2
def get_train_transforms():
"""定义训练时的数据增强变换"""
return A.Compose([
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.2),
A.HueSaturationValue(p=0.2),
A.RandomGamma(p=0.2),
A.GaussianBlur(p=0.1),
A.GaussNoise(p=0.1),
A.MotionBlur(p=0.1),
A.Rotate(limit=15, p=0.3),
A.Resize(640, 640),
A.Normalize(mean=(0.485, 0.456, 0.406), std=(0.229, 0.224, 0.225)),
ToTensorV2()
])上述代码实现了一个综合的数据增强流程,包括水平翻转、亮度对比度调整、色调饱和度变化、随机伽马校正、高斯模糊、噪声添加、运动模糊和旋转等操作。这些变换可以模拟不同光照条件、角度和水质情况下的溺水场景,有效提高模型对复杂环境的适应能力。在实际应用中,我们还可以根据具体场景特点调整增强参数,比如在海滩场景中可以增加水波纹增强,而在游泳池场景中则可以增加水面反光处理。
3. 模型选择与架构
3.1 YOLOv5基础模型
YOLOv5是一种高效的单阶段目标检测算法,以其速度和精度的平衡而闻名。我们选择YOLOv5作为基础检测框架,主要是因为:
- 实时性能优秀:在普通GPU上可以达到30FPS以上的检测速度
- 精度高:在COCO等基准数据集上表现优异
- 易于使用:提供了完整的训练和推理代码
- 活跃的社区支持:有丰富的预训练模型和教程资源
3.2 FasterNet网络融合
FasterNet是一种专为边缘设备设计的高效神经网络架构,通过减少内存访问次数来提高计算效率。我们将FasterNet的注意力机制引入YOLOv5的骨干网络,构建YOLOv5-FasterNet混合模型,具体实现如下:
python
import torch
import torch.nn as nn
class FasterNetBlock(nn.Module):
"""FasterNet基础块"""
def __init__(self, in_channels, out_channels, stride=1):
super(FasterNetBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.act = nn.SiLU()
# 67. 重参数化卷积
self.rbr_conv = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, groups=out_channels, bias=False)
self.rbr_bn = nn.BatchNorm2d(out_channels)
# 68. 深度可分离卷积
self.dw_conv = nn.Conv2d(out_channels, out_channels, kernel_size=3, padding=1, groups=out_channels, bias=False)
self.dw_bn = nn.BatchNorm2d(out_channels)
def forward(self, x):
identity = x
# 69. 标准卷积路径
out = self.conv1(x)
out = self.bn1(out)
out = self.act(out)
# 70. 重参数化路径
rbr_conv = self.rbr_conv(out)
rbr_bn = self.rbr_bn(rbr_conv)
rbr_out = self.act(rbr_bn)
# 71. 深度可分离卷积路径
dw_conv = self.dw_conv(rbr_out)
dw_bn = self.dw_bn(dw_conv)
dw_out = self.act(dw_bn)
# 72. 融合三条路径
out = identity + out + rbr_out + dw_out
return out
class YOLOv5_FasterNet(nn.Module):
"""YOLOv5-FasterNet混合模型"""
def __init__(self, num_classes=1):
super(YOLOv5_FasterNet, self).__init__()
# 73. FasterNet骨干网络
self.backbone = nn.Sequential(
FasterNetBlock(3, 32, 2),
FasterNetBlock(32, 64, 2),
FasterNetBlock(64, 128, 2),
FasterNetBlock(128, 256, 2),
FasterNetBlock(256, 512, 2)
)
# 74. YOLOv5检测头
self.head = nn.Sequential(
nn.Conv2d(512, 1024, kernel_size=3, padding=1),
nn.BatchNorm2d(1024),
nn.SiLU(),
nn.Conv2d(1024, num_classes*5, kernel_size=1)
)
def forward(self, x):
# 75. 特征提取
features = self.backbone(x)
# 76. 目标检测
detections = self.head(features)
return detections上述代码实现了YOLOv5-FasterNet混合模型的核心组件。FasterNetBlock模块融合了标准卷积、重参数化卷积和深度可分离卷积,通过多路径特征融合提高模型表达能力。YOLOv5_FasterNet模型将FasterNet作为特征提取器,保留了YOLOv5的检测头设计,实现了轻量化和高精度的平衡。在实际应用中,我们可以根据具体硬件资源调整网络深度和宽度,比如在资源受限的嵌入式设备上可以使用更浅的网络结构,而在高性能服务器上则可以增加网络深度以提高检测精度。
4. 模型训练
4.1 环境配置
在开始训练之前,我们需要配置好开发环境。以下是必要的依赖包:
python
# 77. requirements.txt
torch>=1.10.0
torchvision>=0.11.0
ultralytics>=5.0.0
albumentations>=1.1.0
opencv-python>=4.5.0
Pillow>=8.3.0
numpy>=1.21.0
matplotlib>=3.4.0
tensorboard>=2.7.0安装完成后,我们可以创建一个训练脚本来初始化环境:
python
import os
import yaml
import torch
from pathlib import Path
def setup_environment():
"""设置训练环境"""
# 78. 设置设备
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(f"使用设备: {device}")
# 79. 创建必要的目录
os.makedirs('data/images/train', exist_ok=True)
os.makedirs('data/images/val', exist_ok=True)
os.makedirs('data/labels/train', exist_ok=True)
os.makedirs('data/labels/val', exist_ok=True)
# 80. 创建数据集配置文件
data_config = {
'train': 'data/images/train',
'val': 'data/images/val',
'nc': 1, # 类别数量
'names': ['drowning'] # 类别名称
}
with open('data.yaml', 'w') as f:
yaml.dump(data_config, f)
# 81. 创建模型配置文件
model_config = {
'backbone': 'yolov5s',
'faster_net': True,
'pretrained': True,
'nc': 1
}
with open('model.yaml', 'w') as f:
yaml.dump(model_config, f)
return device上述环境配置脚本完成了以下工作:检测并配置计算设备、创建必要的目录结构、生成数据集配置文件和模型配置文件。数据集配置文件指定了训练和验证数据的路径、类别数量和类别名称,而模型配置文件则定义了网络结构和预训练设置。在实际项目中,我们还可以根据需要添加更多的环境配置项,如日志配置、分布式训练配置等。
4.2 训练参数设置
模型训练的参数设置对最终性能至关重要。我们需要综合考虑精度、速度和资源消耗等因素。以下是推荐的训练参数:
python
import argparse
def get_train_args():
"""获取训练参数"""
parser = argparse.ArgumentParser(description='YOLOv5-FasterNet训练参数')
# 82. 数据参数
parser.add_argument('--data', type=str, default='data.yaml', help='数据集配置文件路径')
parser.add_argument('--img-size', type=int, default=640, help='图像大小')
parser.add_argument('--batch-size', type=int, default=16, help='批次大小')
parser.add_argument('--epochs', type=int, default=200, help='训练轮数')
# 83. 优化参数
parser.add_argument('--lr0', type=float, default=0.01, help='初始学习率')
parser.add_argument('--lrf', type=float, default=0.01, help='最终学习率比例')
parser.add_argument('--momentum', type=float, default=0.937, help='优化器动量')
parser.add_argument('--weight-decay', type=float, default=0.0005, help='权重衰减')
# 84. 硬件参数
parser.add_argument('--device', default='', help='cuda设备,例如0或0,1,2,3或cpu')
parser.add_argument('--workers', type=int, default=8, help='数据加载器工作线程数')
# 85. 训练策略
parser.add_argument('--warmup-epochs', type=float, default=3.0, help='热身轮数')
parser.add_argument('--warmup-momentum', type=float, default=0.8, help='热身动量')
parser.add_argument('--warmup-bias-lr', type=float, default=0.1, help='热身偏置学习率')
parser.add_argument('--box', type=float, default=0.05, help='边界框损失权重')
parser.add_argument('--cls', type=float, default=0.5, help='分类损失权重')
parser.add_argument('--dfl', type=float, default=1.0, help='分布焦点损失权重')
# 86. 保存和加载
parser.add_argument('--project', default='runs/train', help='保存项目')
parser.add_argument('--name', default='exp', help='保存名称')
parser.add_argument('--exist-ok', action='store_true', help='允许项目名称存在')
parser.add_argument('--pretrained', default=True, help='使用预训练模型')
return parser.parse_args()上述参数配置涵盖了训练过程中的各个方面。数据参数定义了数据集的路径和图像处理方式,优化参数设置了学习率、动量和权重衰减等关键超参数,硬件参数配置了计算资源的使用,而训练策略参数则控制了训练过程中的动态调整。在实际应用中,我们可能需要根据具体硬件和数据特点调整这些参数。例如,在GPU内存有限的情况下可以减小batch-size,而在数据量较少时则可以增加epochs和data-augmentation的强度。此外,还可以采用学习率预热、余弦退火等高级学习率调度策略来进一步优化训练过程。
4.3 训练过程监控
在模型训练过程中,实时监控训练状态对于及时发现问题、调整参数至关重要。我们可以使用TensorBoard来可视化训练过程中的各项指标:
python
from torch.utils.tensorboard import SummaryWriter
import time
class TrainingMonitor:
"""训练监控器"""
def __init__(self, log_dir):
self.writer = SummaryWriter(log_dir)
self.start_time = time.time()
def log_metrics(self, metrics, step):
"""记录训练指标"""
# 87. 记录损失指标
self.writer.add_scalar('train/total_loss', metrics['total_loss'], step)
self.writer.add_scalar('train/box_loss', metrics['box_loss'], step)
self.writer.add_scalar('train/obj_loss', metrics['obj_loss'], step)
self.writer.add_scalar('train/cls_loss', metrics['cls_loss'], step)
# 88. 记录学习率
self.writer.add_scalar('train/lr', metrics['lr'], step)
# 89. 记录精度指标
self.writer.add_scalar('train/mAP_0.5', metrics['mAP_0.5'], step)
self.writer.add_scalar('train/mAP_0.5:0.95', metrics['mAP_0.5:0.95'], step)
# 90. 记录训练时间
elapsed_time = time.time() - self.start_time
self.writer.add_scalar('train/elapsed_time', elapsed_time, step)
def log_validation(self, metrics, step):
"""记录验证指标"""
# 91. 记录验证损失
self.writer.add_scalar('val/total_loss', metrics['total_loss'], step)
self.writer.add_scalar('val/box_loss', metrics['box_loss'], step)
self.writer.add_scalar('val/obj_loss', metrics['obj_loss'], step)
self.writer.add_scalar('val/cls_loss', metrics['cls_loss'], step)
# 92. 记录验证精度
self.writer.add_scalar('val/mAP_0.5', metrics['mAP_0.5'], step)
self.writer.add_scalar('val/mAP_0.5:0.95', metrics['mAP_0.5:0.95'], step)
def log_model_graph(self, model):
"""记录模型结构"""
self.writer.add_graph(model, torch.randn(1, 3, 640, 640))
def close(self):
"""关闭监控器"""
self.writer.close()上述TrainingMonitor类提供了完整的训练监控功能,包括训练指标记录、验证指标记录、模型结构可视化等。通过TensorBoard,我们可以实时观察训练过程中的损失变化、精度提升和学习率调整情况,从而及时发现并解决训练中的问题。例如,当发现验证损失持续上升而训练损失下降时,可能表明模型出现了过拟合,此时可以考虑增加正则化强度或减少模型复杂度。此外,我们还可以监控训练时间、GPU利用率等硬件指标,评估训练效率,为后续的模型部署提供参考。
5. 模型评估与优化
5.1 评估指标
模型训练完成后,我们需要使用多种指标来评估其性能。对于溺水检测任务,我们主要关注以下指标:
| 指标 | 描述 | 计算公式 | 重要性 |
|---|---|---|---|
| 精确率(Precision) | 预测为正例中实际为正例的比例 | TP/(TP+FP) | 衡量减少误报的能力 |
| 召回率(Recall) | 实际为正例中被正确预测的比例 | TP/(TP+FN) | 衡量漏检情况 |
| F1分数 | 精确率和召回率的调和平均 | 2×(Precision×Recall)/(Precision+Recall) | 综合评估指标 |
| mAP | 平均精度均值 | ∫Precision(Recall)dRecall | 目标检测标准指标 |
精确率衡量的是模型预测的准确性,高精确率意味着较少的误报,这对于溺水检测尤为重要,因为误报可能导致不必要的资源浪费和恐慌。召回率则关注的是模型对真实溺水事件的识别能力,高召回率意味着较少的漏检,这是溺水检测系统的核心要求。F1分数是精确率和召回率的调和平均,能够综合反映模型的性能。mAP(平均精度均值)是目标检测领域的标准评估指标,计算了不同IoU阈值下的平均精度,全面评估了模型在不同标准下的表现。在实际应用中,我们需要根据具体场景需求平衡这些指标,例如在游泳池等安全监管严格的场景中,可能需要更高的精确率,而在公共海滩等开放水域,则可能需要更高的召回率。
5.2 模型优化策略
为了进一步提高模型性能,我们可以采用以下优化策略:
python
import torch
import torch.nn as nn
import torch.nn.functional as F
class ModelOptimizer:
"""模型优化器"""
def __init__(self, model):
self.model = model
def apply_pruning(self, pruning_ratio=0.2):
"""应用剪枝策略"""
for name, module in self.model.named_modules():
if isinstance(module, nn.Conv2d):
# 93. 计算剪枝阈值
weight = module.weight.data.abs().flatten()
threshold = torch.kthvalue(weight, int(len(weight) * pruning_ratio)).values
# 94. 应用剪枝
mask = (module.weight.data.abs() > threshold).float()
module.weight.data.mul_(mask)
# 95. 保存掩码以便后续恢复
module.register_buffer('mask', mask)
def apply_quantization(self, num_bits=8):
"""应用量化策略"""
for name, module in self.model.named_modules():
if isinstance(module, nn.Conv2d):
# 96. 计算量化参数
weight = module.weight.data
max_val = weight.abs().max()
scale = max_val / (2 ** (num_bits - 1) - 1)
zero_point = 0
# 97. 应用量化
weight_q = torch.clamp(weight / scale + zero_point,
-2**(num_bits-1), 2**(num_bits-1)-1)
weight_q = weight_q.round()
# 98. 保存量化参数以便后续反量化
module.register_buffer('scale', scale)
module.register_buffer('zero_point', zero_point)
module.weight.data = weight_q
def knowledge_distillation(self, teacher_model, student_model, alpha=0.5):
"""知识蒸馏"""
def loss_fn(outputs, targets):
# 99. 硬目标损失
hard_loss = F.cross_entropy(outputs, targets)
# 100. 软目标损失
with torch.no_grad():
teacher_outputs = teacher_model(outputs)
soft_loss = F.kl_div(
F.log_softmax(outputs, dim=1),
F.softmax(teacher_outputs, dim=1),
reduction='batchmean',
log_target=True
)
# 101. 组合损失
return alpha * hard_loss + (1 - alpha) * soft_loss
return loss_fn上述ModelOptimizer类实现了三种主要的模型优化技术:剪枝、量化和知识蒸馏。剪枝通过移除不重要的连接来减少模型参数,量化将浮点数权重转换为低比特整数,而知识蒸馏则利用教师模型指导学生模型的训练。这些技术可以显著减小模型大小,提高推理速度,同时保持较高的检测精度。在实际应用中,我们可以根据具体硬件资源选择合适的优化策略组合。例如,在资源极度受限的嵌入式设备上,可以同时应用剪枝和量化,而在服务器等资源充足的环境中,则可以专注于知识蒸馏以获得更高的检测精度。此外,这些优化技术通常需要反复实验和调整参数,以达到最佳效果。
6. 系统部署
6.1 模型导出
训练完成的模型需要导出为适合部署的格式。以下是导出模型的代码示例:
python
from ultralytics import YOLO
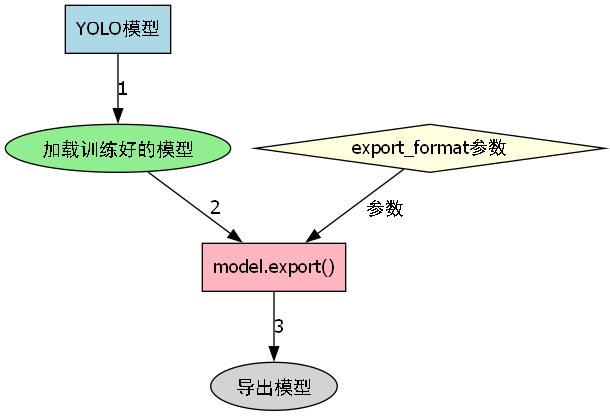
def export_model(model_path, export_format='onnx'):
"""导出模型"""
# 102. 加载训练好的模型
model = YOLO(model_path)
# 103. 导出模型
model.export(format=export_format)
print(f"模型已导出为 {export_format} 格式")
# 104. 导出为ONNX格式
export_model('best.pt', 'onnx')
# 105. 导出为TensorRT格式
export_model('best.pt', 'engine')上述代码提供了两种常见的模型导出格式:ONNX和TensorRT。ONNX是一种开放交换格式,可以在不同深度学习框架之间转换模型,适合跨平台部署。TensorRT则是NVIDIA推出的高性能推理引擎,通过优化计算图和量化技术可以显著提高推理速度。在实际部署中,我们可以根据目标硬件平台选择合适的导出格式。例如,在NVIDIA GPU上部署TensorRT格式可以获得最佳性能,而在需要跨平台支持的场景中,则可以选择ONNX格式。此外,还可以根据需求导出为其他格式,如CoreML(用于Apple设备)或OpenVINO(用于Intel硬件),以满足不同部署场景的需求。
6.2 实时检测系统
我们将导出的模型集成到一个实时检测系统中,实现溺水状态的自动识别:
python
import cv2
import numpy as np
from time import time
from threading import Thread
class DrowningDetectionSystem:
"""溺水检测系统"""
def __init__(self, model_path, confidence=0.5, iou=0.45):
self.model = YOLO(model_path)
self.confidence = confidence
self.iou = iou
self.running = False
self.detection_thread = None
self.alarm_callback = None
def set_alarm_callback(self, callback):
"""设置报警回调函数"""
self.alarm_callback = callback
def start(self, source=0):
"""启动检测系统"""
self.running = True
self.detection_thread = Thread(target=self._detect_loop, args=(source,))
self.detection_thread.start()
def stop(self):
"""停止检测系统"""
self.running = False
if self.detection_thread:
self.detection_thread.join()
def _detect_loop(self, source):
"""检测循环"""
cap = cv2.VideoCapture(source)
while self.running:
ret, frame = cap.read()
if not ret:
break
# 106. 检测溺水状态
results = self.model(frame, conf=self.confidence, iou=self.iou)
# 107. 处理检测结果
drowning_detected = False
for result in results:
boxes = result.boxes
if boxes is not None:
for box in boxes:
# 108. 获取置信度
conf = float(box.conf)
if conf > self.confidence:
# 109. 获取边界框坐标
x1, y1, x2, y2 = box.xyxy[0].cpu().numpy()
# 110. 绘制边界框
cv2.rectangle(frame, (int(x1), int(y1)), (int(x2), int(y2)), (0, 0, 255), 2)
# 111. 添加标签
cv2.putText(frame, f'Drowning: {conf:.2f}',
(int(x1), int(y1)-10),
cv2.FONT_HERSHEY_SIMPLEX,
0.9, (0, 0, 255), 2)
drowning_detected = True
# 112. 如果检测到溺水,触发报警
if drowning_detected and self.alarm_callback:
self.alarm_callback()
# 113. 显示结果
cv2.imshow('Drowning Detection', frame)
if cv2.waitKey(1) & 0xFF == ord('q'):
break
cap.release()
cv2.destroyAllWindows()上述DrowningDetectionSystem类实现了一个完整的实时检测系统,支持多线程处理和自定义报警回调。系统通过摄像头获取实时视频流,使用训练好的模型检测溺水状态,并在检测到溺水时触发报警机制。在实际应用中,我们可以根据需要调整检测参数,如置信度阈值和报警延迟时间,以平衡检测精度和响应速度。此外,还可以扩展系统功能,如添加多摄像头支持、历史记录存储和远程访问等,构建更完善的智能监控系统。
7. 总结与展望
基于YOLOv5-FasterNet的溺水状态检测系统结合了目标检测的高效性和轻量级网络的实用性,能够在资源受限的设备上实现实时准确的溺水检测。本文详细介绍了从数据集准备、模型训练到系统部署的全过程,为构建智能安全监控系统提供了完整的解决方案。
未来,我们可以从以下几个方面进一步优化系统:
- 多模态融合:结合音频分析,提高检测准确性
- 时序建模:利用视频序列信息,减少误报
- 自适应学习:持续收集新数据,优化模型性能
- 边缘计算优化:针对特定硬件进行深度优化
溺水检测技术的发展对于保障水上安全具有重要意义,希望通过本文的介绍,能够帮助更多开发者和研究人员投身到这一领域,共同构建更安全的水上环境。