前言:探寻因果,AI的终极疆域与计算的"叹息之墙"
在人工智能的星辰大海中,我们已经见证了深度学习在图像识别、自然语言处理等领域掀起的滔天巨浪。这些成就,本质上是机器在海量数据中学习"相关性"的胜利。然而,人类智慧的皇冠------理解"因果性"------至今仍是AI领域最艰深、最前沿的挑战之一。知道"牛排的滋滋声"与"美味"高度相关,和理解"高温下的梅拉德反应"是"美味"的原因,是两个认知层面的根本差异。前者让我们成为优秀的模仿者,而后者则赋予我们预测、干预乃至创造世界的能力。
因果发现(Causal Discovery),即从观测数据中推断出变量间的因果关系结构,是开启这扇大门的钥匙。然而,这把钥匙被一道坚不可摧的"计算叹息之墙"所阻挡。这堵墙,在计算机科学中有一个令人望而生畏的名字:NP-hard。
简单来说,当变量数量稍有增加,寻找真实因果图的可能性组合就会以超指数级爆炸式增长,即使是全球最强大的超级计算机,也需耗费宇宙尺度的时间才能完成搜索。这使得传统的、基于约束或评分的因果发现算法在面对高维现实世界问题时,几乎束手无策。我们似乎陷入了一个两难困境:要么满足于浅层的相关性,要么在无穷的计算中耗尽所有资源。然而,一场深刻的范式革命正在悄然发生。一种融合了AI两大流派------连接主义(以神经网络为代表)与符号主义(以逻辑与约束为代表) ------智慧的神经-符号混合架构(Neuro-Symbolic Architecture) ,正以一种惊人的方式,试图"绕过"这堵计算高墙。它不再试图在离散的、组合爆炸的图空间中进行暴力搜索,而是巧妙地将这个NP-hard的离散问题,转化为一个可在连续空间中通过梯度下降求解的优化问题。
这篇解析文章,将带领您踏上一场从计算复杂性理论到前沿AI架构的智力探险。我们将一同:
- 解构"高墙":深入剖析为何因果发现本质上是一个NP-hard问题,理解其计算复杂性的根源。
- 审视"两极":回顾AI的两大思想流派------连接主义与符号主义,分析它们各自在因果发现任务上的优势与局限。
- 见证"融合":详细阐述神经-符号架构的核心思想,揭示它如何将离散的图结构搜索转化为连续的优化,从而"破解"NP-hard魔咒。
- 动手"实践":通过一个基于Python与PyTorch的概念性实训案例,一步步展示如何构建一个基础的神经-符号模型,并将其应用于因果发现任务。
- 跨越"鸿沟":探讨将理论模型应用于真实世界时,必须面对的挑战与高级应对技巧。
这不仅是一次技术的旅程,更是一次思想的碰撞。让我们共同见证,当神经网络的"直觉"与符号逻辑的"严谨"相遇,将为探寻世间因果的终极目标,迸发出何等璀璨的火花。
阅读先决条件
为获得最佳阅读体验,建议读者具备以下背景知识:
- 线性代数基础:理解矩阵、向量及其基本运算。
- 机器学习概念:熟悉损失函数、梯度下降、神经网络(特别是多层感知机)等基本原理。
- Python与PyTorch:能够理解基本的Python语法和PyTorch张量运算及模型构建。
第一部分:不可逾越之山------为何因果发现是NP-hard问题
在深入探讨解决方案之前,我们必须首先对问题的难度有清醒的认识。说因果发现是NP-hard,绝非危言耸听。这一部分,我们将从计算复杂性的基础概念出发,一步步揭示蕴藏在因果发现任务背后的组合爆炸。
第一章:计算复杂性的"度量衡"------理解NP-hard
要理解NP-hard,需要先建立它与"计算问题复杂度"的核心关联------它描述的是一类"至少和NP问题中最难的问题一样难"的问题,是计算机科学中衡量问题求解难度的关键概念。
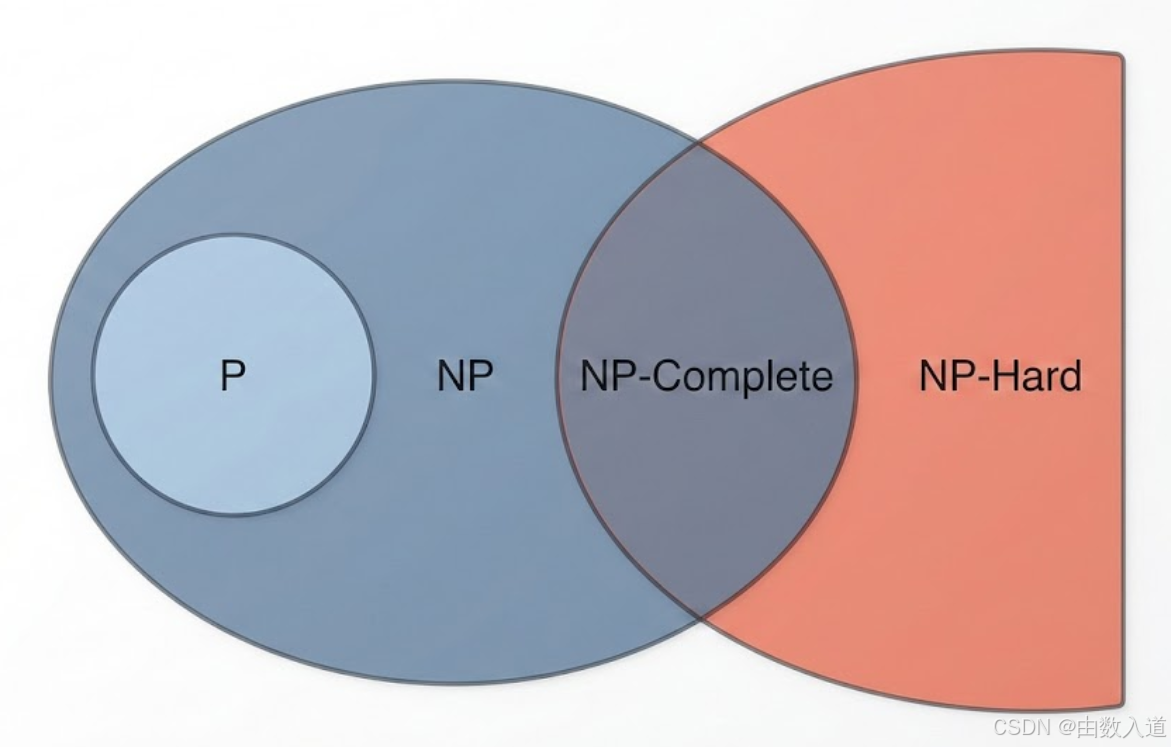
核心定义:P、NP、NP-hard与NP-complete
- P (Polynomial time) :能在多项式时间内解决的问题。这类问题是"简单的"、"高效可解的"。例如,对一个数组进行排序。
- NP (Nondeterministic Polynomial time) :能在多项式时间内验证一个给定解是否正确的问题。注意,这不意味着能高效找到解。例如,"旅行商问题(判定版)":给定一个城市网络和距离,是否存在一条总长度小于K的路径访问所有城市?如果你给我一条路径,我可以在多项式时间内(计算总长度)验证它是否满足条件。所有P类问题都属于NP类。
- NP-hard (Nondeterministic Polynomial-time hard) :一个问题至少和所有NP问题一样难。它的核心特征是:所有NP问题都能在多项式时间内归约(transform)到这个问题上 。这意味着,如果你能找到一个NP-hard问题的多项式时间解法,那么通过归约,所有NP问题都能被高效解决。这将意味着P=NP,而这被学术界普遍认为是不可能的。NP-hard问题本身不一定属于NP类。
- NP-complete (NP完全):一个问题既是NP问题,又是NP-hard问题。它是NP问题中最难的那一类。例如,上面提到的"旅行商问题(判定版)"和著名的"布尔可满足性问题(SAT)"。
实际意义:从"寻找最优解"到"寻找满意解"的妥协
在实践中,一旦一个问题被证明是NP-hard,它就标志着我们几乎不可能找到一个在所有情况下都能在合理时间内给出"精确最优解"的算法。我们的策略必须转变,通常采用以下方法:
- 近似算法(Approximation Algorithms):在多项式时间内找到一个有理论保证的、接近最优解的解。
- 启发式算法(Heuristic Algorithms):基于经验或直觉设计的算法,如遗传算法、模拟退火,它们通常能快速找到一个不错的解,但没有理论保证其质量或最优性。
- 参数化复杂性(Parameterized Complexity):针对问题的某个参数,看算法的复杂度是否可以被限制在该参数的多项式内,而对输入规模是指数的。
理解了NP-hard的"恐怖"之处,我们现在可以将其与因果发现任务直接关联起来。
第二章:从变量到图------因果发现的数学表示
要进行计算分析,我们首先需要将"因果关系"这个哲学概念转化为严谨的数学对象。在现代因果科学中,这通常通过 结构因果模型(Structural Causal Models, SCMs) 和 有向无环图(Directed Acyclic Graphs, DAGs) 来完成。
- 结构因果模型 (SCM) :一个SCM包含一组变量、一组函数以及一组外生噪声。每个变量的值都是由其直接原因(父节点)和对应的外生噪声通过一个函数决定的。
- 例如:
X3 = f3(X1, X2) + U3,表示X1和X2是X3的直接原因。
- 例如:
- 有向无环图 (DAG) :一个DAG
G = (V, E)是SCM的图形化表示。V(Vertices) 是节点集合,代表系统中的变量。E(Edges) 是有向边集合,X1 -> X2表示X1是X2的直接原因。- "无环"是因果的核心要求:一个变量不能是自身的(间接)原因,即图中不存在从一个节点出发最终回到自身的路径。
因果发现的任务,本质上就是在给定一组变量V的观测数据时,从所有可能的DAG空间中,找出最能解释这些数据的那个真实的DAG。
第三章:组合爆炸------因果图搜索空间的NP-hard本质
现在,问题的核心来了:对于n个变量,存在多少个可能的DAG?
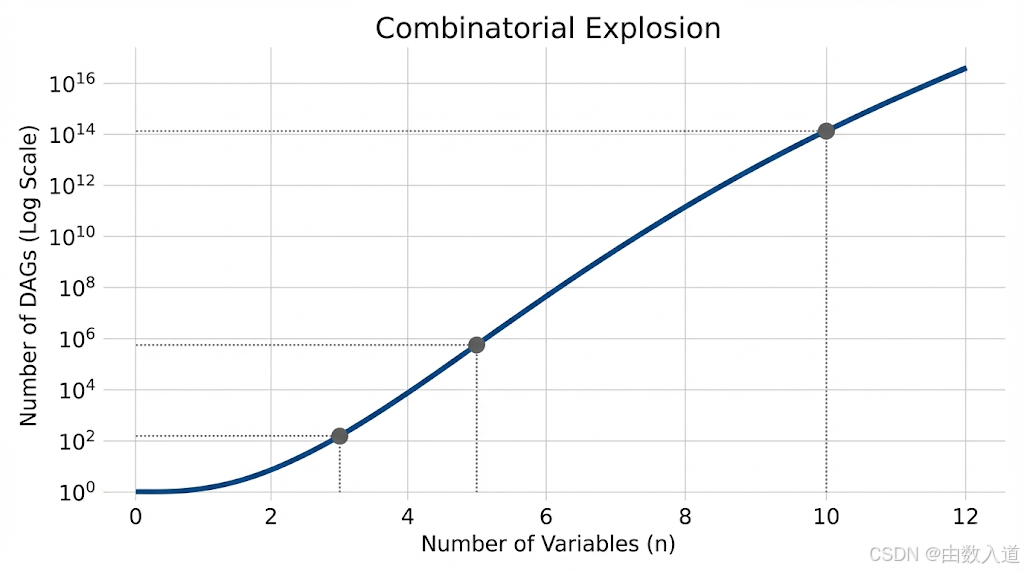
这个问题的答案由一个著名的递归公式给出,我们称之为罗宾逊序列(Robinson's Sequence)。其数量增长速度是惊人的,远超指数级。
- 对于2个变量 (X1, X2),存在3个可能的DAG:
X1 -> X2,X2 -> X1,X1 X2(无连接)。 - 对于3个变量,存在25个可能的DAG。
- 对于5个变量,存在29,281个DAG。
- 对于10个变量,数量约为
7.8 x 10^18。 - 对于20个变量,这个数字已经超出了天文学范畴。
技术深潜:DAG搜索与NP-hard的正式连接
证明"基于评分的DAG学习是NP-hard的"是一个经典的理论结果(由Chickering在1996年证明)。其核心思想是通过归约。
- 选择一个已知的NP-complete问题:例如"在一个图中寻找大小为k的团(Clique)",即找到k个节点,它们之间两两相连。这是一个经典的NP-complete问题。
- 构造归约:我们可以构造一个特殊的因果发现问题实例,使得"能高效解决这个因果发现问题"等价于"能高效解决那个大小为k的团问题"。
- 思路:例如,我们可以设计一个评分函数(如BIC分数),并构造一组数据,使得只有当因果图结构中包含了对应于原图中那个大小为k的团的特定子结构时,评分才会达到最优。
- 结论:因此,如果我们可以多项式时间内找到最优评分的DAG,我们就能多项式时间内判断是否存在大小为k的团。这与"团问题是NP-hard"相矛盾。所以,基于评分的因果发现问题必然是NP-hard的。
传统的因果发现算法,如PC算法(基于约束)或GES算法(基于评分),本质上都是在这个巨大的、离散的图空间中进行搜索、剪枝、评估。尽管它们使用了很多巧妙的技巧(如条件独立性测试)来减少搜索空间,但当变量数量增多、数据信噪比降低时,它们仍然会受困于NP-hard的本质,导致计算成本过高或陷入局部最优。
至此,我们已经清晰地描绘出了那座"不可逾越之山"的轮廓。传统方法在山脚下步履维艰,是时候寻找一条全新的登山路径了。而这条新路,需要从审视AI世界的两大基本力量开始。
第二部分:AI的两大思想流派------连接主义与符号主义的对撞
要理解神经-符号架构的革命性,我们必须先理解它所要融合的两种思想。人工智能的发展史,在很大程度上可以看作是连接主义(Connectionism)和符号主义(Symbolism)两条主线交织、竞争与融合的历史。
第一章:连接主义------数据驱动的"直觉"大师
连接主义,以今天的深度神经网络为最杰出的代表,其核心哲学是:智能涌现于大量简单、相互连接的单元(神经元)的集体行为中。
- 核心思想:模仿生物大脑的结构,通过调整单元间的连接权重来学习。知识被"分布式"地编码在整个网络的权重矩阵中。
- 工作方式 :
- 数据驱动:它需要海量的标注数据进行训练。
- 端到端学习 :给定输入和期望输出,网络通过反向传播 和梯度下降自动调整内部参数,最小化预测与真实值之间的误差(损失函数)。
- 表示学习:它能自动从原始数据中学习出层次化的、有意义的特征表示。例如,在图像中从像素学习到边缘,再到部件,最终到对象。
- 在因果发现中的优势 :
- 强大的函数拟合能力:能够从数据中学习极其复杂的非线性关系,这对于建模现实世界中复杂的因果机制至关重要。
- 可扩展性:能够处理高维数据,且计算过程(尤其是在GPU上)高度并行化。
- 在因果发现中的局限 :
- "黑箱"问题:神经网络学到的是相关性,不是因果性。其内部决策过程不透明,难以解释。它不知道"为什么",只知道"是什么"。
- 缺乏结构化知识:天生不具备处理符号、逻辑和抽象规则的能力。对于像DAG这样的具有严格约束(如"无环")的离散结构,纯粹的神经网络束手无策。它无法直接在模型的输出中强制执行"无环性"。
- 数据饥渴:通常需要大量数据才能获得好的性能。
对于因果发现这个任务,纯粹的连接主义就像一个拥有超强视力但缺乏逻辑推理能力的侦探。他能敏锐地发现所有线索(变量间的相关性),但无法将它们组织成一个没有矛盾(无环)的逻辑链条(因果图)。
第二章:符号主义------逻辑推理的"严谨"学者
符号主义,又称"老式AI"(Good Old-Fashioned AI, GOFAI),是AI早期的主导范式。其核心哲学是:智能的核心是符号的表示与操作。
- 核心思想:人类的思维过程可以被形式化为一套基于符号和逻辑规则的计算过程。知识被显式地表示为事实、规则和逻辑公式。
- 工作方式 :
- 知识表示:使用逻辑语言(如一阶谓词逻辑)或产生式规则(IF-THEN)来编码关于世界的知识。
- 推理引擎:基于这些显式的知识和规则,通过逻辑演绎(如三段论)来进行推理和决策。
- 搜索:在定义好的问题空间(如棋盘游戏的状态空间)中进行搜索,寻找解决方案。
- 在因果发现中的优势 :
- 精确的结构表示:能够完美地表示和操作像DAG这样的离散、结构化对象。检查一个图是否"有环"对符号主义来说是轻而易举的任务。
- 可解释性与严谨性:每一步推理都有明确的逻辑依据,过程完全透明,结果可靠。
- 先验知识的融入:可以方便地将领域专家的知识(例如,"年龄"不可能是"疾病"的结果)作为硬性约束加入到模型中。
- 在因果发现中的局限 :
- 脆弱性:基于规则的系统在面对真实世界数据的噪声和不确定性时,表现非常脆弱。规则是"硬"的,而数据是"软"的。
- 知识获取瓶颈:需要人类专家手动编写所有规则,这是一个极其耗时且难以扩展的过程。
- 计算复杂性:正如我们第一部分所见,当符号主义方法(如基于约束的搜索)直接面对因果发现的组合空间时,会遭遇NP-hard的计算瓶颈。
对于因果发现,纯粹的符号主义就像一个逻辑严密但脱离实际的理论家。他精通所有图论规则,知道什么是合法的因果图,但当面对充满噪声的观测数据时,他不知道哪条规则适用于眼前的证据。
第三章:对撞与融合的必然性
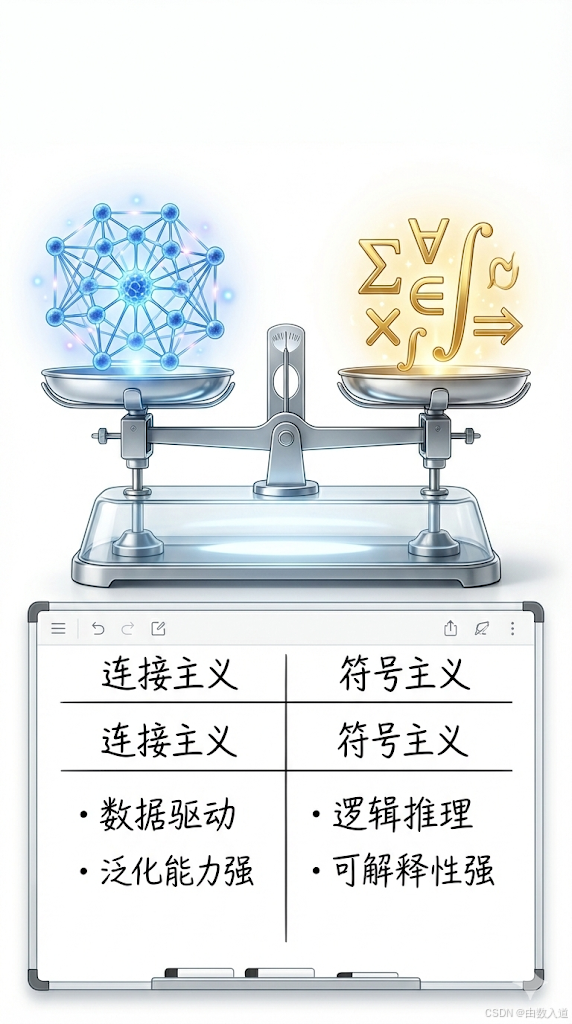
| 特性 | 连接主义 (神经网络) | 符号主义 (逻辑/搜索) |
|---|---|---|
| 数据处理 | 强大,擅长处理噪声、高维、非线性数据 | 脆弱,依赖于清晰、确定性的输入 |
| 知识表示 | 隐式、分布式 (在权重中) | 显式、结构化 (在规则和符号中) |
| 推理能力 | 弱,基于模式匹配的"直觉" | 强,基于逻辑演绎的"严谨"推理 |
| 可解释性 | 差 (黑箱) | 好 (白箱) |
| 结构约束 | 难以处理 (如DAG的无环性) | 轻松处理 (是其核心优势) |
| 计算瓶颈 | 训练可能耗时,但推理快;梯度优化是核心 | 组合空间搜索导致NP-hard问题 |
显然,连接主义和符号主义在因果发现这个任务上,呈现出完美的能力互补性。连接主义擅长从数据中学习"什么看起来是对的"(数据拟合),而符号主义擅长定义"什么必须是对的"(结构约束)。
将两者结合起来,似乎是克服各自局限、通往成功的唯一道路。这正是神经-符号混合架构背后的核心洞见。它要做的,就是让神经网络的"直觉"在符号逻辑的"缰绳"的引导下,朝着正确的方向前进。
第三部分:神经-符号的联姻------从离散搜索到连续优化
这部分是本文的核心。我们将揭开神经-符号架构的神秘面紗,理解它是如何巧妙地将一个NP-hard的离散搜索问题,转化为一个可以通过梯度下降解决的连续优化问题。这一转变,是整个方法论的关键。
第一章:核心思想------用连续的"邻接矩阵"代表离散的"图"
传统方法在离散的图空间中跳跃式搜索,而神经-符号方法的第一步,就是将这个离散空间"连续化"。
-
图的矩阵表示 :一个包含
n个节点的图,其结构可以被一个n x n的 邻接矩阵W所表示。W_ij ≠ 0表示存在一条从节点i指向节点j的边,W_ij = 0则表示没有边。边的"权重"W_ij可以表示因果效应的强度。 -
连续化 :我们不再将
W_ij视为0或1的离散值,而是允许它取任意连续的实数值 。此时,W成为了一个可以被神经网络学习的参数矩阵。W_ij的绝对值大小可以解释为因果关系的强度。 -
神经网络的角色 :我们可以设计一个神经网络模型,其核心可训练参数就包含了这个邻接矩阵
W。神经网络的任务,就是通过学习数据,调整W的值,使得模型能最好地重构数据。
至此,我们已经用连接主义的方式解决了"从数据学习关系强度"的问题。神经网络会通过梯度下降,自动找到一个W,使得基于这个W所代表的因果关系(例如,X_j = Σ_i W_ij * X_i + ...)能够最好地拟合观测数据。这部分对应于损失函数的数据拟合项(Data-fitting Loss)。
然而,我们还面临一个巨大的问题:神经网络找到的这个W,它所代表的图,很可能不是一个DAG !它极有可能包含环路(比如 X1 -> X2 -> X3 -> X1),这在因果上是无意义的。
第二章:符号的"缰绳"------将DAG约束转化为可微函数
这就是符号主义发挥作用的地方。我们需要将"图中无环"这个离散的、逻辑上的硬性约束,转化为一个可以放入神经网络损失函数中的、连续且可微的惩罚项。
技术深潜:DAG的优雅代数性质
一个惊人的数学结论是解决此问题的关键。在Zheng等人于2018年发表的开创性论文 "DAGs with NO TEARS: Continuous Optimization for Structure Learning" 中,他们证明了一个优雅的结论:
令
A = W ◦ W(◦表示逐元素相乘,即A_ij = W_ij^2)。一个由A表示的加权图是DAG,当且仅当trace(e^A) - n = 0。其中:
e^A是矩阵A的指数,定义为e^A = I + A + A^2/2! + A^3/3! + ...trace(...)是矩阵的迹(主对角线元素之和)。n是节点数量。直观理解 :矩阵
A^k的(i, j)元素表示从节点i到节点j的长度为k的路径数量的某种度量。因此,trace(e^A)本质上是对图中所有长度的环路(从一个节点出发回到自身)数量的加权求和。如果图中没有环路(即为DAG),那么所有长度大于0的环路数量都为0,trace(e^A)将精确地等于n(因为e^A的对角线元素会因为单位矩阵I的存在而包含1)。如果存在环路,这个值将严格大于n。
现在,我们有了一个完美的工具!我们可以定义一个惩罚函数h(W):
h(W) = trace(e^(W◦W)) - n
这个函数具有以下美妙的性质:
- 非负性 :
h(W) >= 0。 - 约束满足 :
h(W) = 0当且仅当W代表的图是一个DAG。 - 可微性 :最关键的是,
h(W)相对于W是完全可微的。这意味着我们可以计算它的梯度,并将其用于梯度下降!
第三章:混合损失函数------数据与逻辑的交响乐
现在,我们可以构建神经-符号混合架构的核心------混合损失函数(Hybrid Loss Function)。
L(W) = L_data(W) + λ * h(W)
这个损失函数由两部分构成:
-
L_data(W)(数据拟合项) :这是连接主义的部分。它衡量由W定义的因果模型在多大程度上能够拟合观测数据。例如,对于线性模型,这可以是简单的均方误差(MSE)。
L_data(W) = (1/2N) * || X - XW ||_F^2(其中||.||_F是弗罗贝尼乌斯范数) -
λ * h(W)(结构约束项) :这是符号主义的部分。h(W)是我们的DAG约束函数,λ是一个超参数,用于平衡数据拟合与结构约束的重要性。当h(W)不为0时(即图中有环),它会产生一个巨大的惩罚,迫使优化过程调整W以消除环路。
优化过程的动态演绎:
- 初始化 :随机初始化邻接矩阵
W。此时的图结构是随机的,很可能包含环路。 - 迭代优化 :在每一步梯度下降中:
- 计算
L_data的梯度:这会告诉W如何调整以更好地拟合数据。趋势是"在相关性强的地方增加边的权重"。 - 计算
h(W)的梯度:如果W中存在环路,这个梯度会指向一个"打破环路"的方向,通常是减小构成环路的边的权重。 - 联合更新 :将两个梯度加权(由
λ控制)相加,更新W。
- 计算
- 收敛 :经过足够多的迭代,优化过程会找到一个
W*,它同时满足两个条件:L_data(W*)很小(模型很好地拟合了数据)。h(W*)趋近于0(W*所代表的图结构是一个DAG)。
革命性的转变
通过这个框架,我们完成了一次惊人的"维度转换":
- 从 :在一个
N_DAGs(n)个离散对象的组合空间中进行搜索(NP-hard)。 - 到 :在一个
n x n维的连续实数空间中进行梯度下降优化(计算上是可行的)。
我们没有"解决"NP-hard问题本身(因为P很可能不等于NP),而是通过一种全新的表示和优化方法,绕过了它的组合爆炸特性。我们找到了一条可以攀登山峰的平缓坡道,而不是在悬崖峭壁上徒劳地寻找抓手。
第四部分:动手实践------神经-符号因果发现的概念性实训
理论是灰色的,而生命之树常青。这一部分,我们将通过一个具体的、简化的案例,使用Python和PyTorch来展示上述思想是如何转化为实际代码的。
免责声明 :本案例旨在教学和概念验证,而非一个生产级的、功能完备的因果发现库。我们将专注于核心机制的实现,并使用一个简单的线性高斯模型。现实世界的应用需要处理非线性、潜变量、数据类型等更多复杂性。
第一章:问题设定与数据生成
假设我们有一个包含4个变量 (X0, X1, X2, X3) 的系统。其真实的因果结构(Ground Truth DAG)如下:
X0 -> X1X0 -> X2X1 -> X3X2 -> X3
(Image: [一个使用matplotlib或graphviz生成的清晰DAG图,展示X0到X1/X2,X1/X2到X3的结构])
我们将使用线性结构因果模型来生成数据:
X0 = N0X1 = 0.8 * X0 + N1X2 = -0.9 * X0 + N2X3 = 0.5 * X1 + 0.6 * X2 + N3
(其中Ni是来自标准正态分布的独立噪声)
现在,我们用代码生成一些观测数据。
Pro-Tip: 为保证实验结果可复现,始终在代码开头设置随机种子。
python
# 代码示例 1:生成模拟数据
import torch
import numpy as np
import networkx as nx
import matplotlib.pyplot as plt
# 设置随机种子以保证可复现
torch.manual_seed(42)
np.random.seed(42)
# 定义真实因果图的邻接矩阵 W_true
# W_ij 表示 i -> j 的边的权重
n_vars = 4
W_true = torch.zeros(n_vars, n_vars)
W_true[0, 1] = 0.8
W_true[0, 2] = -0.9
W_true[1, 3] = 0.5
W_true[2, 3] = 0.6
# 生成数据
n_samples = 1000
# 线性模型 X = Z @ A.T, 其中 A 是拓扑排序后的邻接矩阵
# 为了简单,我们直接按拓扑顺序生成
X = torch.zeros(n_samples, n_vars)
noise = torch.randn(n_samples, n_vars) * 0.5 # 加入一些噪声
# 根据拓扑排序生成数据
ordered_nodes = [0, 1, 2, 3] # 拓扑排序:X0, X2, X1, X3
X[:, 0] = noise[:, 0]
X[:, 1] = X[:, 0] * W_true[0, 1] + noise[:, 1]
X[:, 2] = X[:, 0] * W_true[0, 2] + noise[:, 2]
X[:, 3] = X[:, 1] * W_true[1, 3] + X[:, 2] * W_true[2, 3] + noise[:, 3]
print("数据维度:", X.shape)
# 输出: 数据维度: torch.Size([1000, 4])我们的任务是:只给模型看X,让它自己恢复出W_true所代表的因果结构。
第二章:构建神经-符号模型
我们将把整个模型封装在一个PyTorch的nn.Module中。这个模型的核心,就是那个我们将要学习的邻接矩阵W。
python
# 代码示例 2:定义模型和DAG约束函数
import torch.nn as nn
class NeuroSymbolicCausalModel(nn.Module):
def __init__(self, n_vars):
super(NeuroSymbolicCausalModel, self).__init__()
# 1. 核心参数:可学习的邻接矩阵 W
# 初始化为对角线为0的随机矩阵
self.W = nn.Parameter(torch.randn(n_vars, n_vars))
self.W.data.uniform_(-0.1, 0.1) # 较小的随机初始化
self.W.data.fill_diagonal_(0) # 节点不能有指向自身的环
def forward(self, X):
# 2. 数据拟合部分:线性模型的重构
# X_hat = X @ W
X_reconstructed = torch.matmul(X, self.W)
return X_reconstructed
def h_func(self):
# 3. 符号约束部分:DAG惩罚函数
# h(W) = trace(e^(W◦W)) - n
d = self.W.shape[0]
# 矩阵指数计算
M = torch.matrix_exp(self.W * self.W) # 逐元素相乘
# 计算迹并减去维度
h = torch.trace(M) - d
return h
def get_loss(self, X, lambda_reg):
# 4. 混合损失函数
# 数据拟合损失 (MSE)
X_reconstructed = self.forward(X)
loss_data = 0.5 / X.shape[0] * torch.sum((X - X_reconstructed)**2)
# 结构约束损失
loss_structure = self.h_func()
# 混合损失
total_loss = loss_data + lambda_reg * loss_structure
return total_loss, loss_data, loss_structure第三章:训练与发现
现在我们来设置训练循环,使用Adam优化器通过梯度下降来学习W。
Common Pitfall : 正则化系数
lambda_reg的选择非常关键。如果太小,模型可能无法完全消除环;如果太大,可能会牺牲数据拟合度。通常需要进行一些调整。
python
# 代码示例 3:训练循环
# 实例化模型
model = NeuroSymbolicCausalModel(n_vars)
# 设置超参数
learning_rate = 1e-3
n_epochs = 15000
lambda_reg = 0.1
# 设置优化器
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
print("开始训练...")
for epoch in range(n_epochs):
optimizer.zero_grad()
# 强制对角线为0
model.W.data.fill_diagonal_(0)
# 计算混合损失
total_loss, loss_data, loss_structure = model.get_loss(X, lambda_reg)
# 反向传播和优化
total_loss.backward()
optimizer.step()
if epoch % 1000 == 0:
print(f"Epoch {epoch:5d}: Total Loss={total_loss.item():.4f}, "
f"Data Loss={loss_data.item():.4f}, "
f"Structure Loss={loss_structure.item():.8f}")
print("训练完成!")
# 获取学习到的邻接矩阵
W_learned = model.W.detach().clone()
print("\n真实邻接矩阵 W_true:\n", W_true.round(decimals=2))
print("\n学习到的邻接矩阵 W_learned (原始):\n", W_learned.round(decimals=2))第四章:结果分析与可视化
训练完成后,W_learned是一个包含很多小数值的稠密矩阵。我们需要进行后处理,通常是设置一个阈值来过滤掉弱连接,从而得到一个稀疏的图结构。
python
# 代码示例 4:结果可视化
# 后处理:设置阈值
threshold = 0.3
W_learned_adj = (torch.abs(W_learned) > threshold).int()
print("\n学习到的邻接矩阵 W_learned (阈值后):\n", W_learned_adj)
# 可视化函数
def plot_graph(adj_matrix, title):
# networkx期望的格式是 (from, to),所以我们需要转置
G = nx.from_numpy_array(adj_matrix.T.numpy(), create_using=nx.DiGraph)
pos = nx.circular_layout(G)
plt.figure(figsize=(6, 6))
nx.draw(G, pos, with_labels=True, node_color='skyblue', node_size=2000,
font_size=18, font_weight='bold', arrows=True, arrowsize=25,
width=2.0, edge_color='gray')
plt.title(title, size=20)
plt.show()
# 可视化真实图和学习到的图
plot_graph(W_true, "True Causal Graph")
plot_graph(W_learned_adj, "Learned Causal Graph")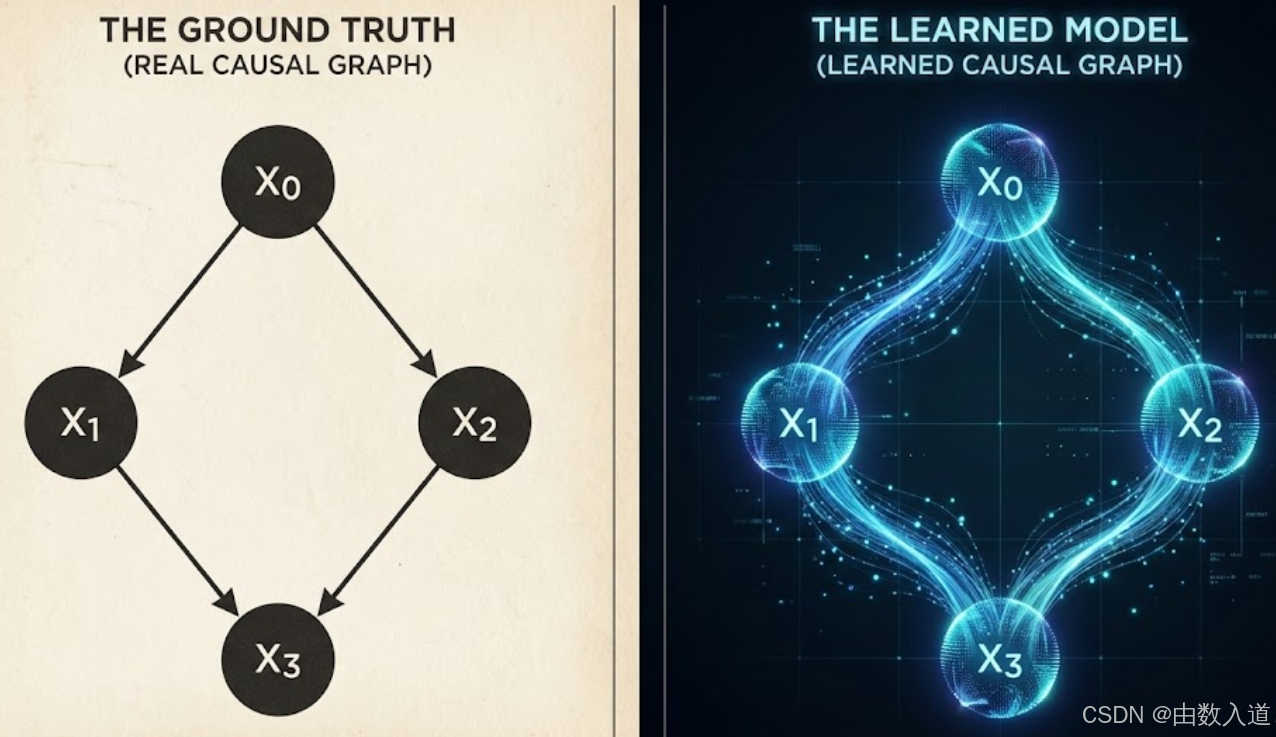
第五部分:从理论到现实的鸿沟------实践中的挑战与高级技巧
我们在第四部分的概念验证中,一切似乎都完美地运行。然而,通往稳健的真实世界应用的道路上布满了陷阱。本章将深入探讨在实践中必须面对的四大核心挑战及其应对策略。
第一章:超参数的"炼金术":λ与学习率的微妙平衡
混合损失函数 L(W) = L_data(W) + λ * h(W) 中的正则化系数 λ 是最关键的超参数。
λ过小 : 优化器将过度关注数据拟合 (L_data),而忽视结构约束。结果可能是学习到的图虽然能很好地解释数据,但依然包含细微的环(h(W)不完全为零),或者收敛速度极慢。λ过大: 结构约束将占据主导地位。优化器会迅速将图变为一个DAG,但可能以牺牲数据拟合度为代价,导致发现的因果关系过于稀疏,甚至丢失了真实存在的弱因果连接。
高级技巧:
- 退火策略 (Annealing) :在训练初期使用一个较小的
λ,让模型先自由地从数据中学习关系,然后逐渐增大λ,迫使模型在后期"整理"结构,消除环路。 - 双阶段优化 : 一些更高级的方法采用交替优化策略。例如,固定
W优化一个阶段以拟合数据,然后固定数据拟合部分,专门优化以减小h(W)。
第二章:马尔可夫等价类:观测数据的"视界极限"
这是一个根本性的理论限制。对于某些不同的因果图,它们所能产生的观测数据分布是完全相同的。这些图构成了一个马尔可夫等价类 (Markov Equivalence Class)。
- 典型例子 :
X -> Y和Y -> X。仅从X和Y的联合分布数据来看,我们无法区分这两种情况。它们是马尔可夫等价的。更复杂的例子是所谓的"v-结构"(X -> Z <- Y),它是可识别的,但X -> Y -> Z和X <- Y <- Z等链式结构则不可区分。
实践意义:
纯粹基于观测数据的梯度下降方法,可能会在等价类中的多个解之间徘徊,或者收敛到其中任意一个。输出的结果不应被视为唯一的"真理",而应被理解为"与数据兼容的最佳DAG之一"。要打破这种模糊性,唯一的方法是引入额外信息,如:
- 干预数据 (Interventional Data) :如果我们能主动干预
X,观察Y的变化,就能确定方向。 - 领域先验知识 (Domain Priors):例如,在生物学中,我们知道"基因表达"导致"蛋白质浓度",而不是相反。
第三章:优化的稳定性与循环的"幽灵"
尽管 h(W) 函数在理论上能保证收敛到DAG,但在有限的训练步数和数值精度下,优化过程可能最终得到一个h(W)非常接近零但不完全为零的解。这意味着图中可能还残留着权重极低的"幽灵循环"。
高级技巧:
- 硬阈值化后检查 : 在训练结束后,对学习到的
W应用阈值,然后用标准的图算法(如深度优先搜索)检查是否存在环路。 - 迭代重加权最小二乘 (Iteratively Reweighted Least Squares) :一些高级算法在优化过程中迭代地对
h(W)的惩罚项进行加权,对潜在的循环边施加越来越大的"压力",从而更稳定地消除它们。
第四章:假设被打破时:非线性与非高斯噪声的挑战
我们的案例基于线性关系 和高斯噪声的强假设。当这些假设不成立时:
- 非线性关系 :
X = XW模型会完全失效。此时,需要将线性模型替换为更强大的函数逼近器,例如,用多层感知机(MLP)来表示每个变量与其父节点之间的关系。这会使损失函数和优化过程变得复杂得多,但也是处理真实世界非线性的必由之路。 - 非高斯噪声 : 这是一个机遇!Lingo-LiNGAM等经典算法证明,当噪声为非高斯分布时,
X -> Y和Y -> X的马尔可夫等价性可以被打破!这意味着,通过对数据分布的更高阶矩(不仅仅是协方差)进行建模,我们有可能仅从观测数据中识别出更精确的因果方向。将这一思想融入神经-符号框架是当前的一个活跃研究领域。
第六部分:更广阔的地平线------挑战、前沿与未来
我们已经成功地演示了神经-符号架构在因果发现中的核心原理和基础实践。然而,这仅仅是一个开始。通往通用、鲁棒的因果发现工具的道路上,依然充满挑战与机遇。
第一章:当前的挑战与局限性
- 潜变量(Unobserved Confounders) :我们的模型假设所有相关变量都已被观测到。如果存在一个未被观测到的共同原因(例如,
Z -> X且Z -> Y),模型可能会错误地推断出X和Y之间存在直接的因果关系。处理潜变量是因果推断中最困难的问题之一。 - 可扩展性与稳定性 :虽然该方法在理论上可扩展到数百甚至数千个变量,但在实践中,高维优化问题的稳定性和对超参数(如
λ)的敏感性仍然是一个挑战。 - 数据要求:尽管比纯符号方法更适应数据,但这类方法仍然需要足够多的高质量数据来保证结果的可靠性。
第二章:前沿研究方向
学术界和工业界的研究者们正在积极探索解决上述挑战的路径,展现出百花齐放的态势:
1. 连续优化的深化与扩展
这是对我们本文所讨论方法的直接演进,专注于解决其核心假设的局限性:
- 处理非线性: 使用更复杂的神经网络结构,如生成对抗网络(GANs)或归一化流(Normalizing Flows),来建模非线性的因果机制。
- 拥抱潜变量: 发展能够推断出潜变量存在的模型,或者在存在潜变量的情况下,给出部分可靠的因果结论。
- 融合多源数据: 结合观测数据和干预数据(Interventional Data),后者是主动改变某个变量的值后收集的数据,能够提供更强的因果证据。
2. 强化学习驱动的组合搜索
这是一种截然不同的神经-符号思路。它将因果图的构建过程建模为一个 强化学习(RL) 问题:
- 智能体 (Agent): 一个神经网络。
- 环境 (Environment): 当前构建的因果图。
- 动作 (Action): "添加边"、"删除边"或"反转边"。
- 奖励 (Reward) : 基于某个评分函数(如BIC分数)的变化。
智能体通过试错学习一个策略,以最高效的方式修改图结构,从而最大化最终的图评分。这里的"神经"部分是策略网络,"符号"部分则是对离散图结构的直接操作和评分。这种方法更接近传统的搜索算法,但用神经网络来指导搜索方向,避免了暴力穷举。
3. 基于生成模型的因果推断
利用生成对抗网络(GANs)或归一化流(Normalizing Flows)等深度生成模型,可以直接对数据的联合分布进行建模。
- 思路 : 如果一个因果图
G是正确的,那么基于G的结构因果模型应该能够生成与真实数据分布非常相似的假数据。 - 实现: 我们可以设计一个判别器来区分真实数据和由不同候选图生成的假数据。能够"骗过"判别器的图,就是更好的候选因果图。这种方法在处理复杂的非线性和非高斯噪声方面具有巨大潜力。
4. 因果表示学习与大语言模型的融合
- 因果表示学习(Causal Representation Learning): 这是一个更宏大的目标,旨在从高维原始数据(如图像、文本)中直接学习出具有因果意义的、低维的表示,而不仅仅是变量间的关系图。
- 与大语言模型(LLMs)的结合 : 利用LLMs中蕴含的海量世界知识作为强大的因果先验 。例如,在开始搜索之前,可以向LLM提问:"'海拔高度'和'年平均气温'哪个更可能是原因?" LLM的回答可以用来约束图的搜索空间(例如,禁止
气温 -> 海拔这条边),极大地降低了NP-hard问题的实际搜索难度。
第三章:结论------新范式的曙光
我们从因果发现的NP-hard困境出发,见证了连接主义与符号主义两大AI流派的局限与互补,并最终深入探索了神经-符号混合架构如何通过将离散搜索转化为连续优化,为这一古老难题提供了全新的、强大的解决方案。
这不仅是因果发现领域的一项技术突破,更是一种深刻的哲学启示:智能的真正力量或许并非源于单一的、纯粹的方法,而在于不同范式之间的巧妙融合。 神经网络的模式识别能力为我们提供了处理复杂现实数据的"直觉",而符号逻辑的严谨性则为这种直觉套上了"理性的缰绳",确保它在正确的结构化道路上前行。
未来,随着这些技术的不断成熟,我们有理由相信,AI将不仅仅是预测未来的"水晶球",更有可能成为我们理解和改造世界的"手术刀"。从药物研发、气候变化建模到社会经济政策制定,精准的因果推断能力将是开启下一个科技与社会进步浪潮的关键。