指令及理论
- 1、cat指令
- [2、more & less](#2、more & less)
- [3、head & tail](#3、head & tail)
- 4、管道
- 4、date指令,与时间戳
- 5、cal指令
- 6、查找命令
1、cat指令
1.1、基本用法
cat,concatenate,意为"链接、串联"。
cat的作用是:查看指定文件的内容
选项:
-n:带上行号。
-s:不输出连续的多行空行,连续多行空行处只输出一行空行。
-b:对非空输出行进行编号,空行不编号。
使用nano指令编辑文件内容:
nano [文件名]打开----->写数据----->^X退出----->保存(yes)----->回车
我们用nano指令,给文件data.txt写好内容后,执行cat -n data.txt:
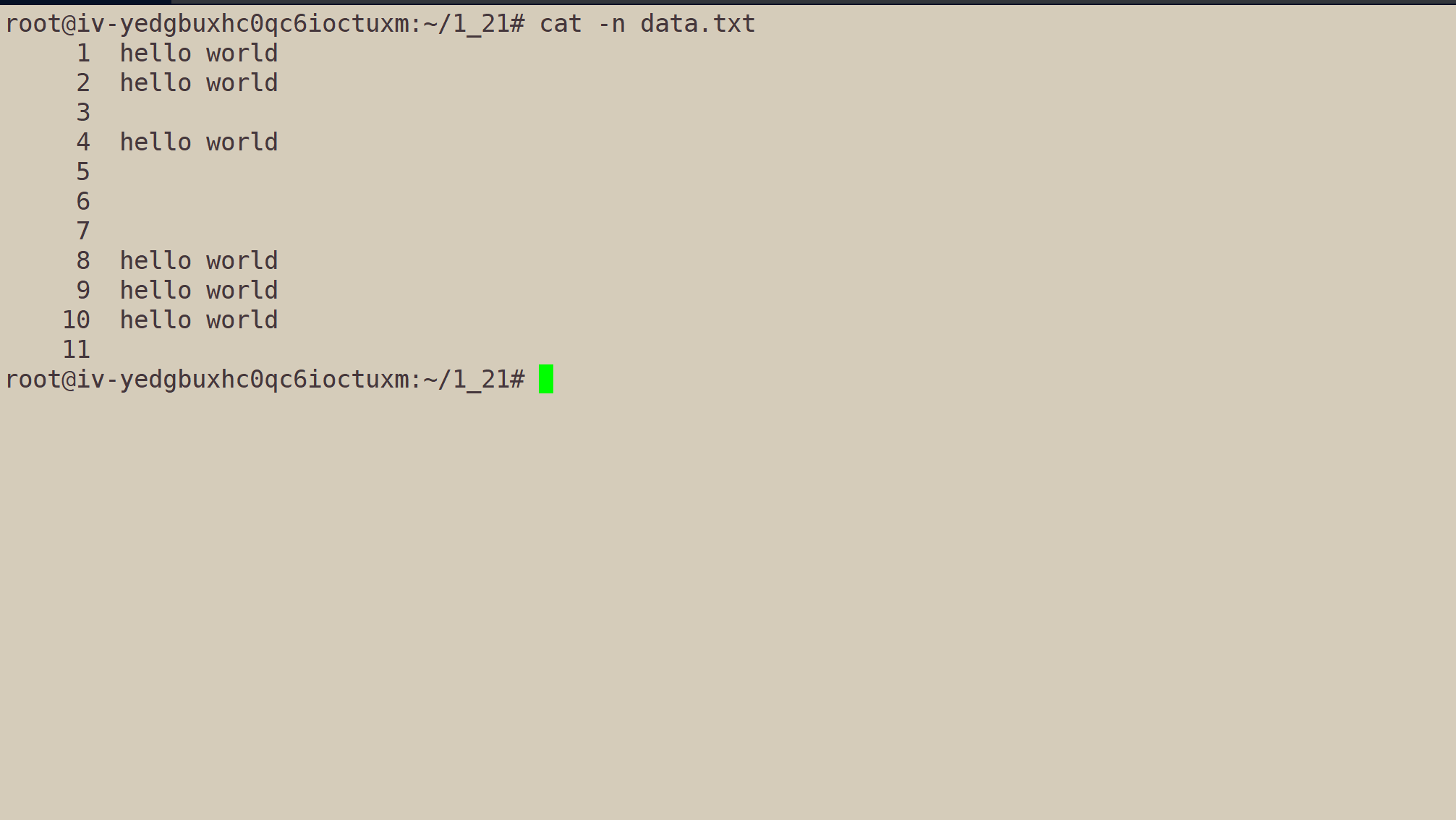
data.txt内容,就带上了行号。
再执行cat -s data.txt:
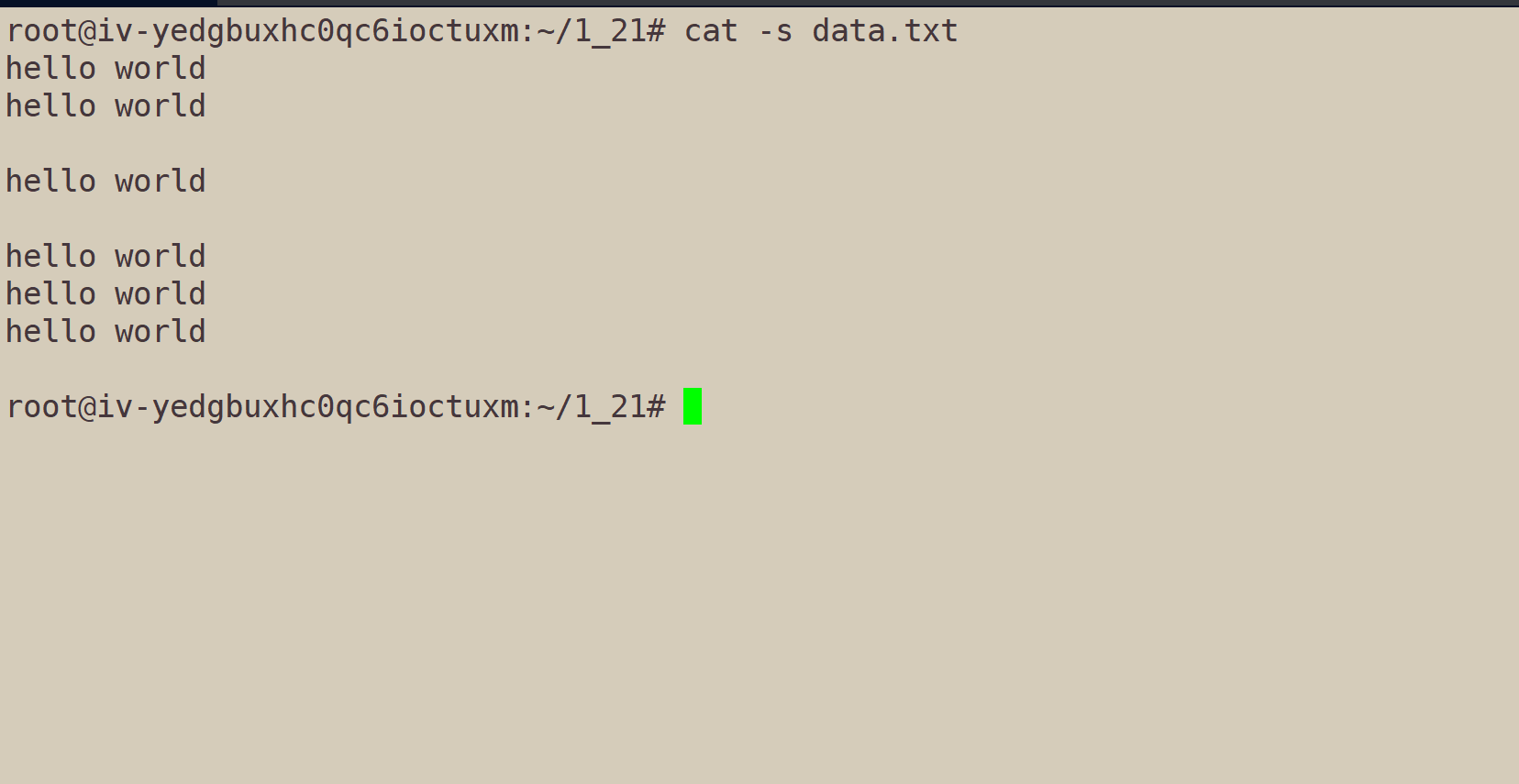
内容中,多个行号,就变成了一个行号。
再执行cat -b data.txt:

有内容的一行,带上了行号;空行就没有行号。
在Linux系统中,查看小文件、小算法、小的配置文件,之类的很短的代码,使用cat查看,就很方便。
但如果我们不想从头查看,想从末尾开始查看呢?
我们就把cat反转一下,变成tac。
1.2、tac指令
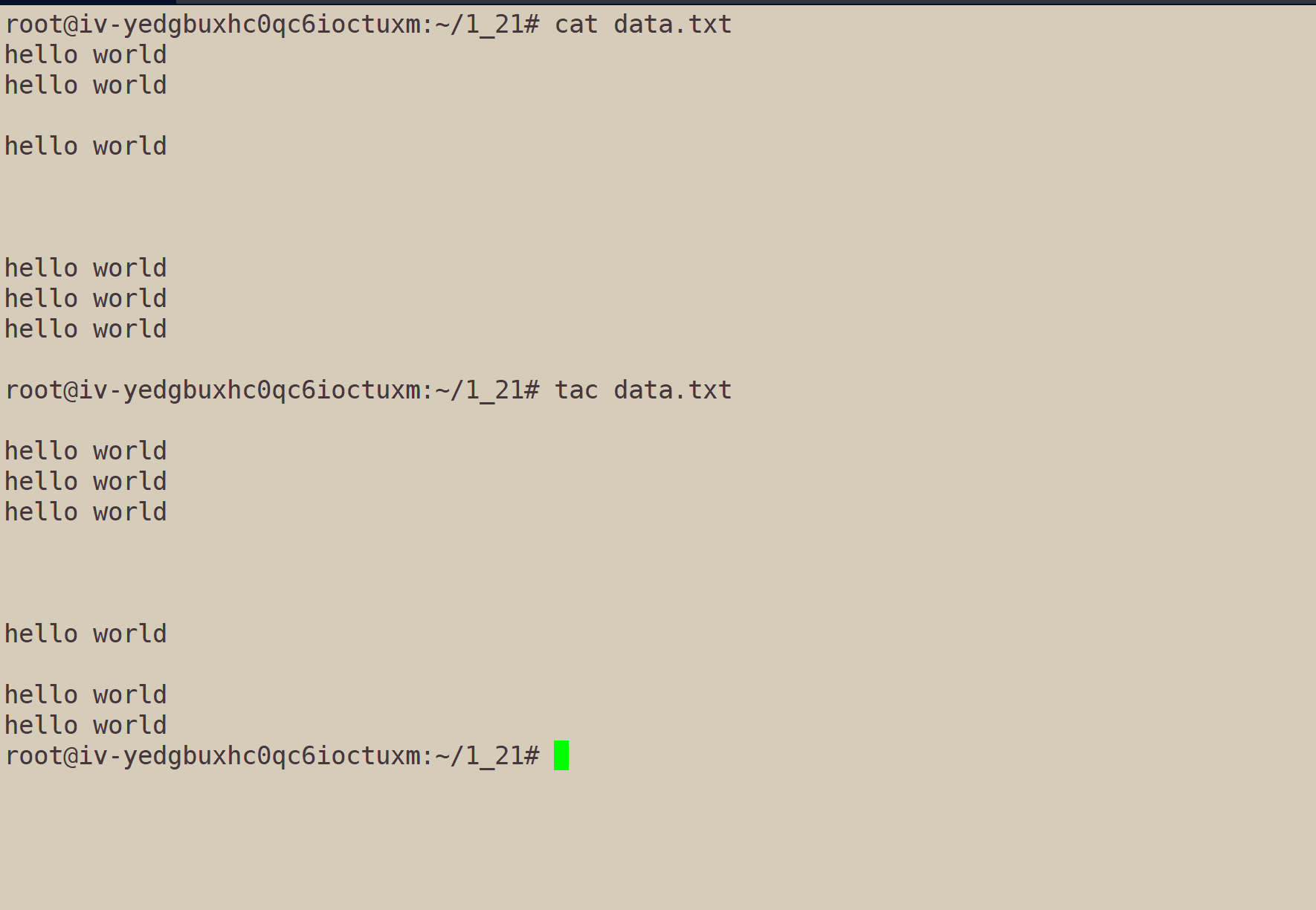
tac的作用,就是从末尾开始,查看文件。
但是,当我们有了一个大文件data1.txt,再使用cat,就要刷屏了。
Linux循环语句示例:
i=0;while [$i -le 10]; do echo"hello $i"; let i++; done

所以,此时cat不合适,那么我们就要学习另外两个指令:more、less。
2、more & less
执行指令
more data1.txt,系统会先打满整个屏幕,然后:1、按回车键,一行一行往下显示内容
2、/999,查看往后最近的有999关键词的地方

more相比cat的好处是,more不会刷屏。
但是,more指令有一个缺点:不支持上翻,翻过了就看不到了。
所以,我们还有less指令。
执行指令
less data1.txt,系统会先打满整个屏幕,这时,我们可以上翻、下翻,也可以查找包含关键词的内容。
我们又不想逐行逐行地翻,于是就有了指令head、tail。
3、head & tail
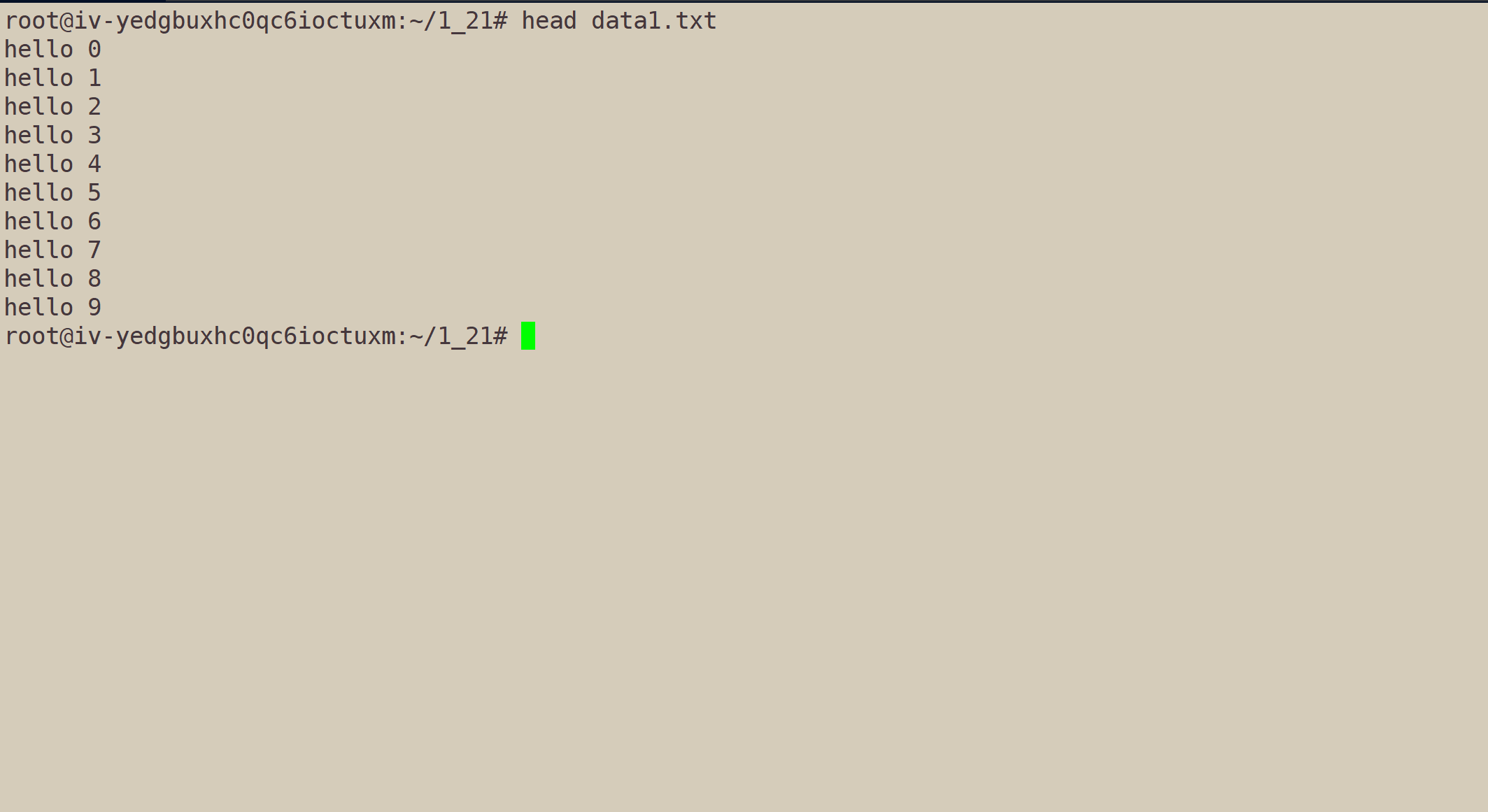
当我们执行
head data1.txt,系统默认显示文件内容的前10行。
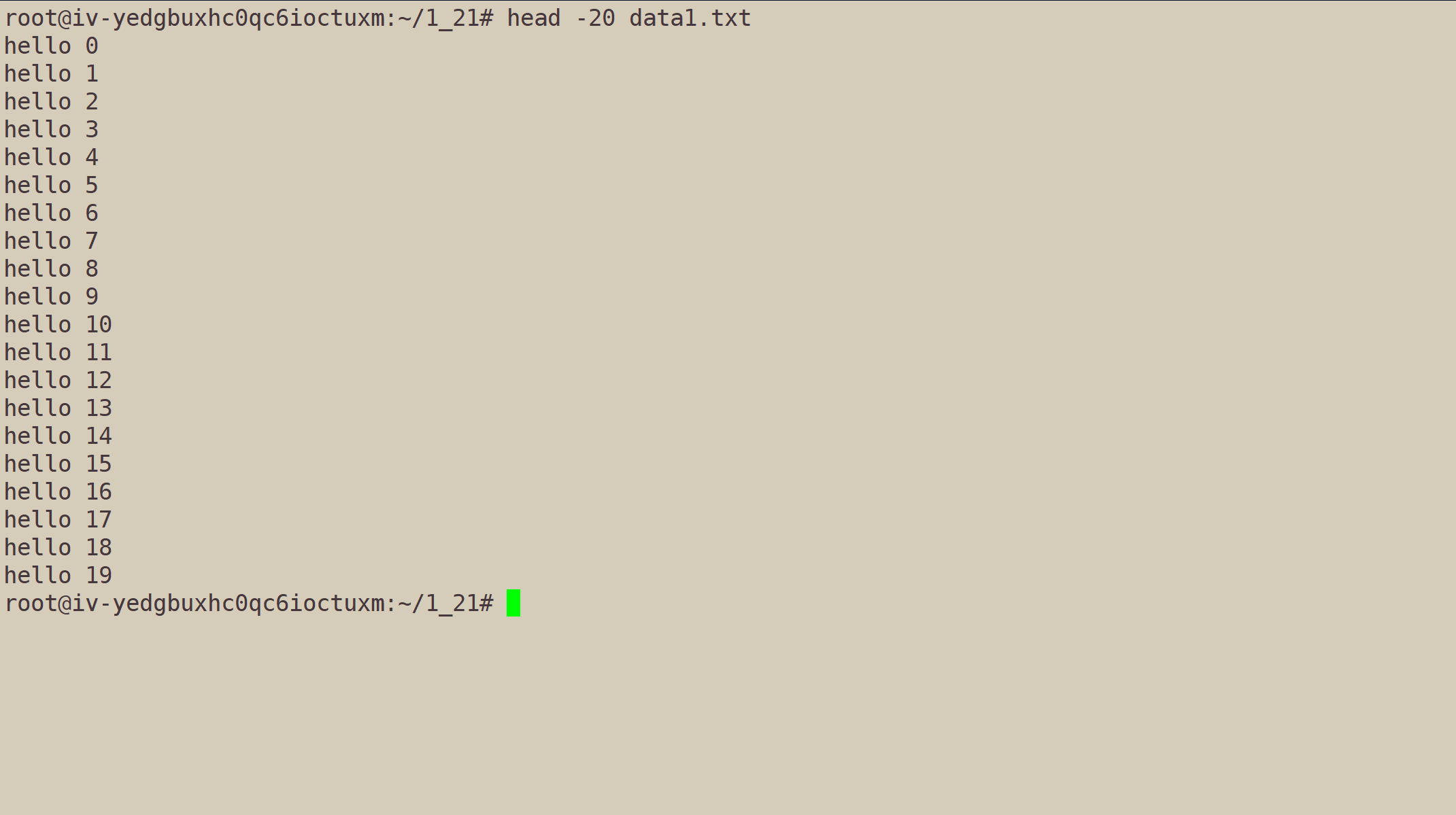
我们也可以指定行数:
head -n[行数] data1.txt。其中n可省略。
想从末尾开始看,用tail。
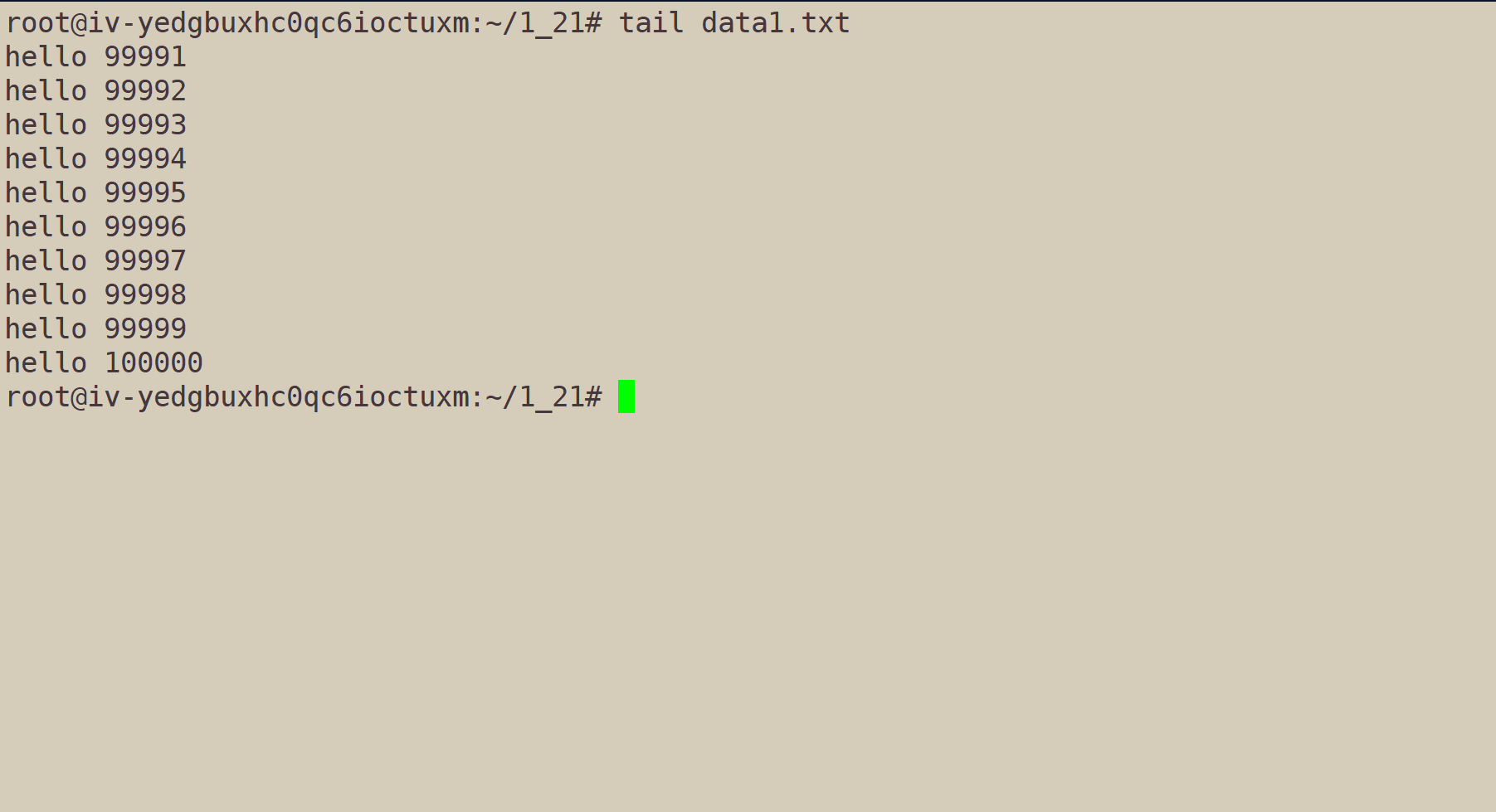
当我们执行
tail data1.txt,系统默认显示文件内容的后10行。
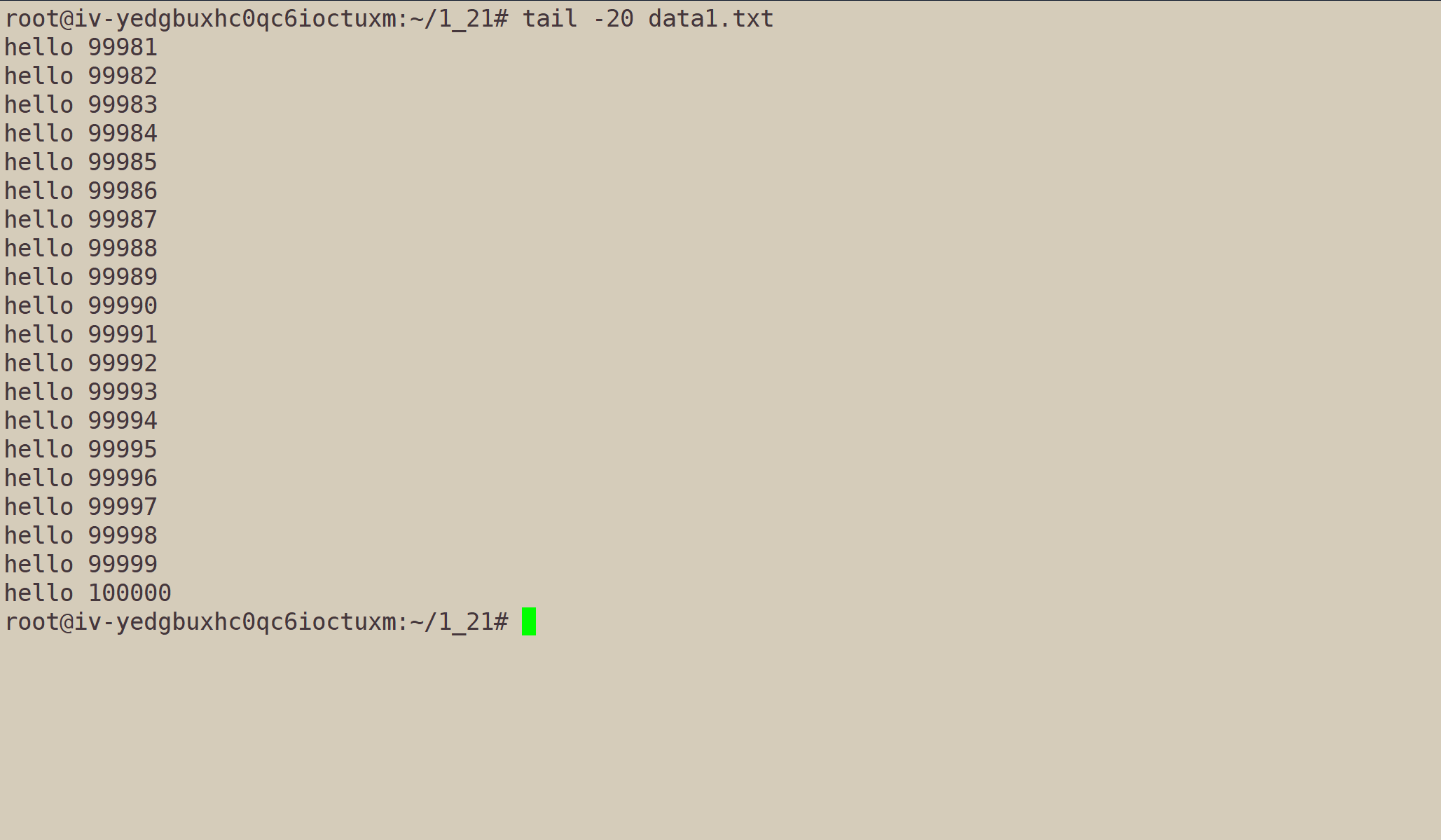
我们也可以指定行数:
tail -n[行数] data1.txt。其中n可省略。
4、管道
4.1、引子
我们想直接得到data1.txt文件中第5000~5010行中的内容。此时,单凭一个指令,无法做到。
所以我们可以:
- 利用head指令,将前5011行,输入到一个临时文件。
- 再利用tail指令,输出后11行。
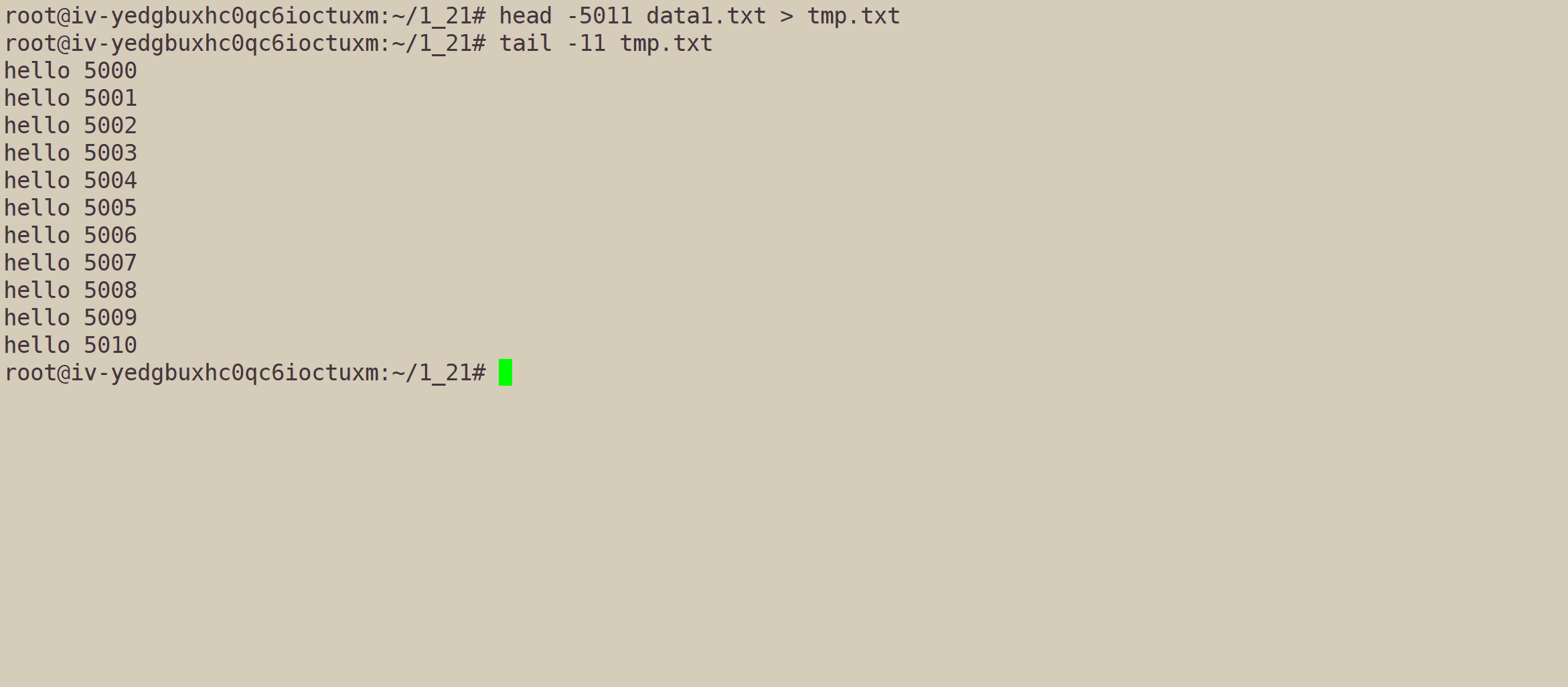
目标达成了。但是我们不仅用了两个指令,还新建了一个临时文件,不太简洁。
其实我们可以只使用一条命令,就可以完成这部操作:
cpp
head -5011 data1.txt | tail -11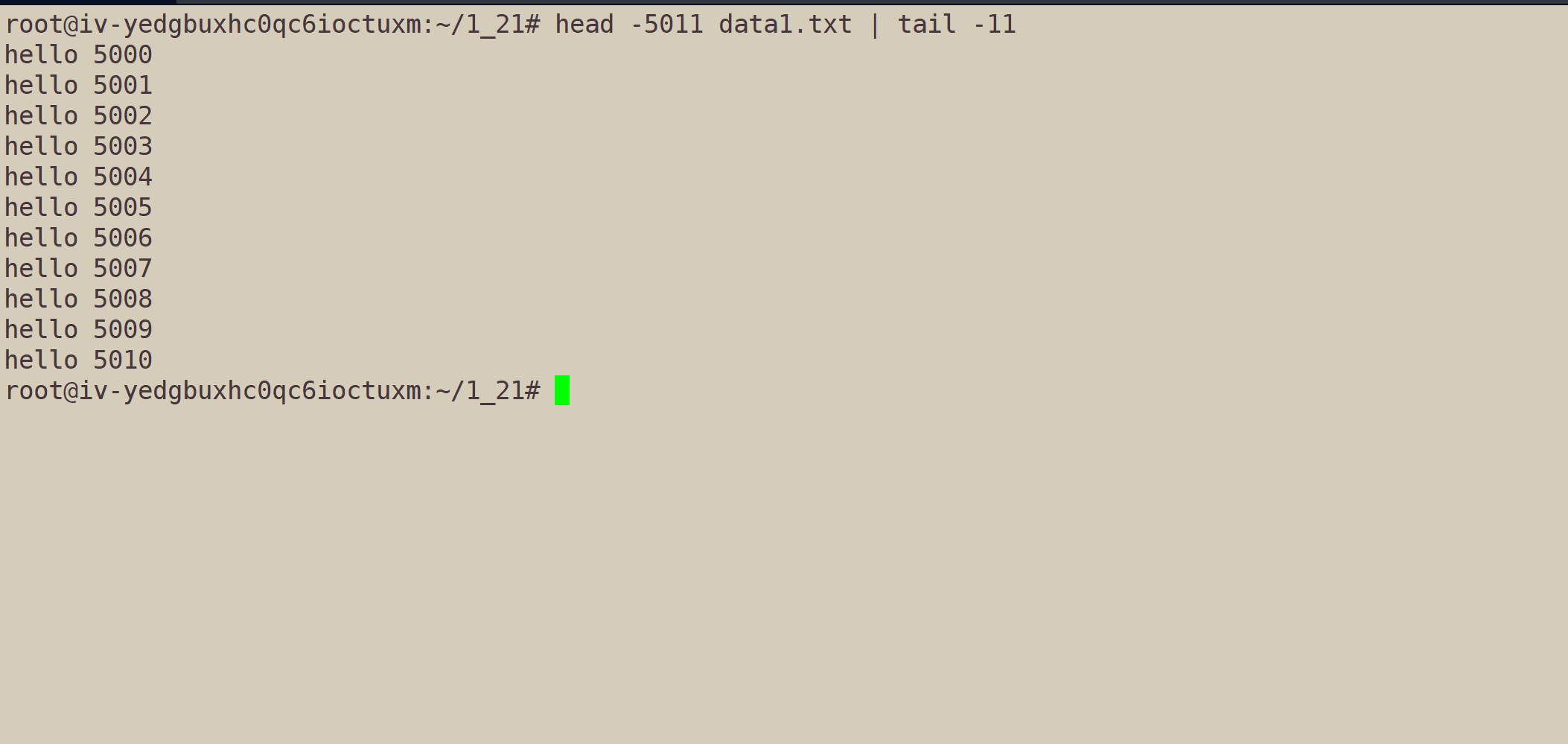
这里我们使用了 | ,这就是管道。
4.2、管道的理解
我们知道,现实的管道,其中一个特点,是有入口和出口。
另外一个特点,是管道输送的,往往是有价值的东西,比如石油、天然气等等。
而在互联网公司,数据是最重要的资源。软件用户的信息,可以用管道输送数据。
示意图:
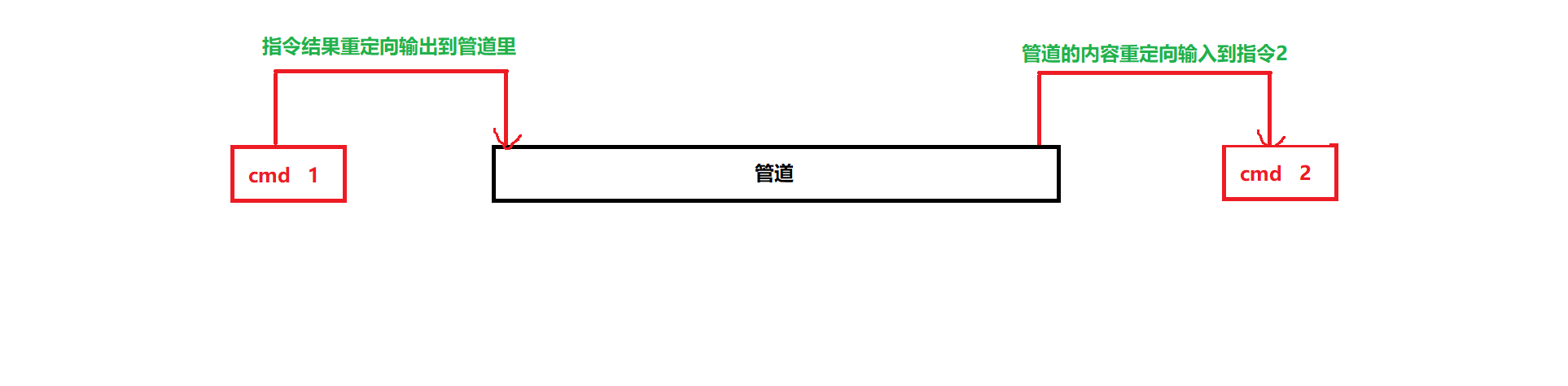
我们把这个具有入口、出口、资源,并且单向的文件,叫做管道文件。
我们可以把 | 认为成是一个内存文件,内存文件是会随着设备的重启而消失的(而磁盘文件不会)。
有了管道,我们就可以实现命令的级联,从而批量化操作文件。
比如,我们想得到5000~5010的倒置的文件:
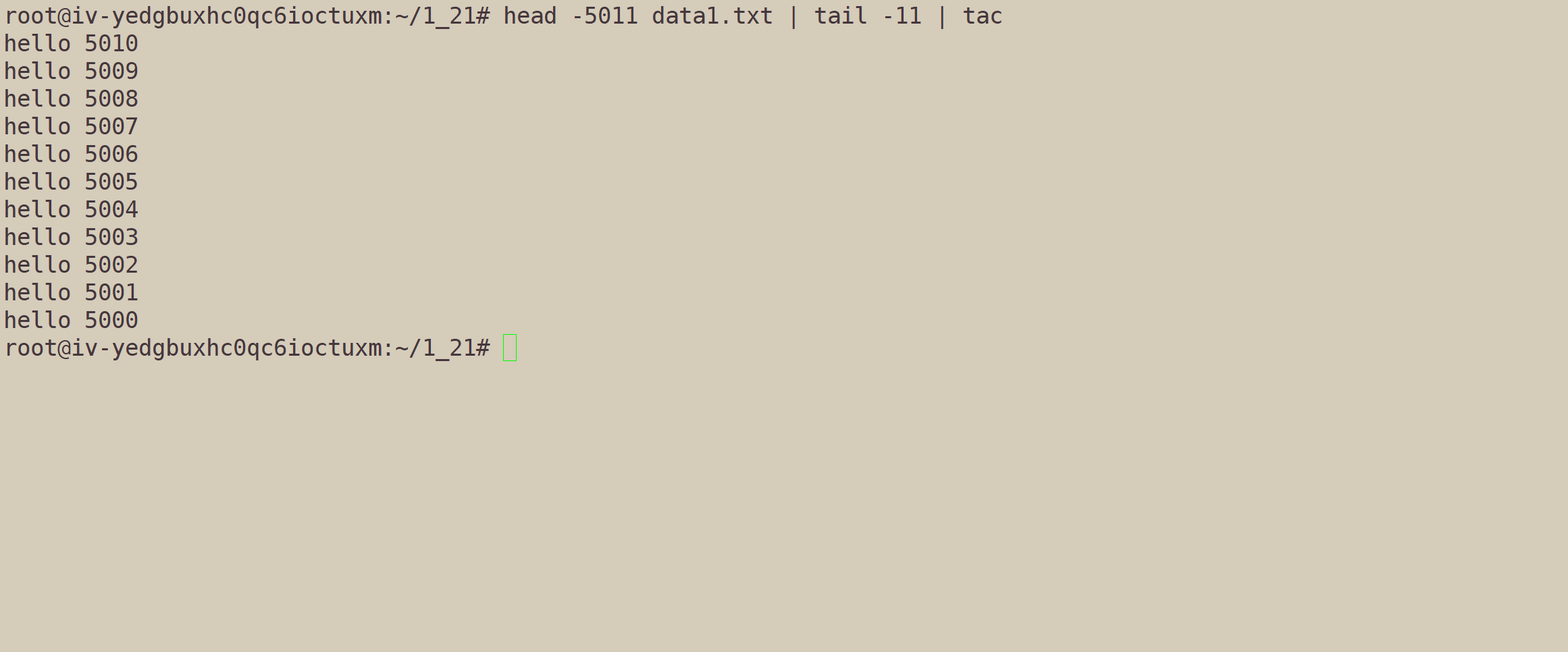
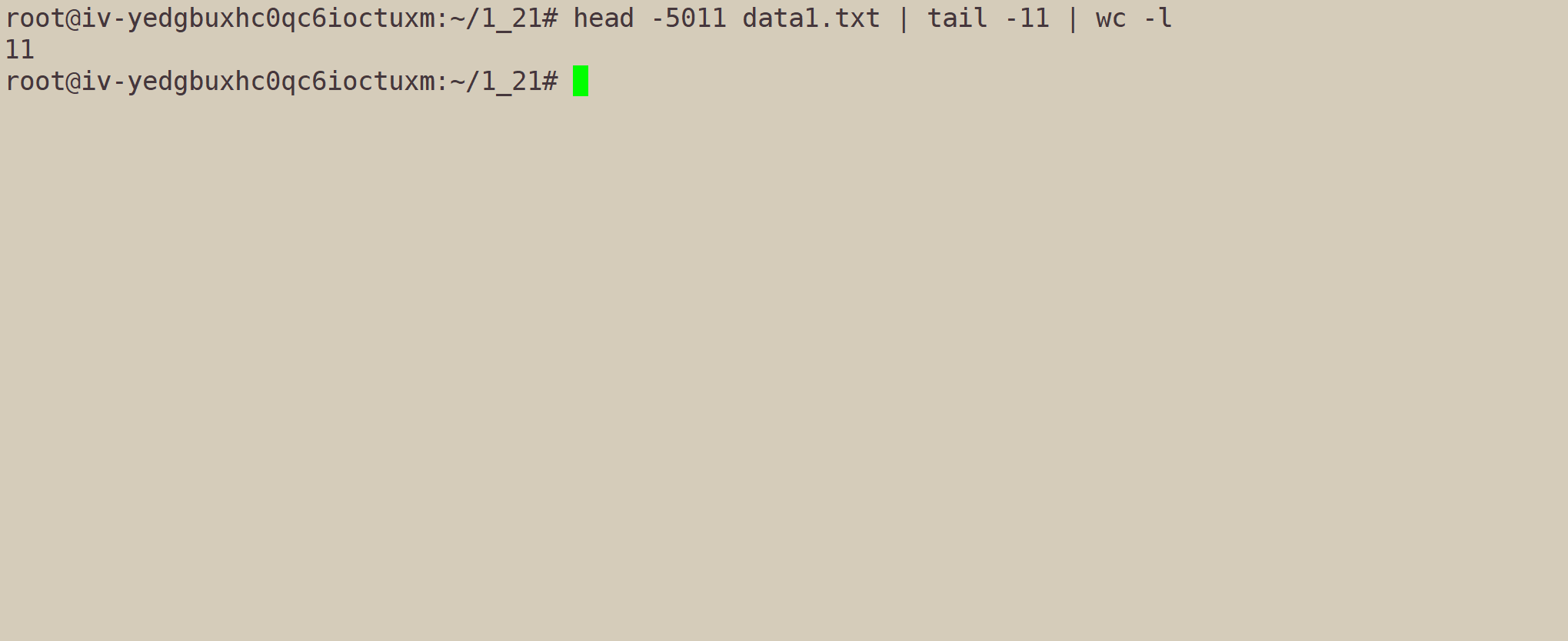
使用wc -l显示一共有多少行:
添加使用less指令:

4.3、命名管道
其实,上面的管道,是匿名管道。
Linux里存在一种文件,叫做命名管道 。
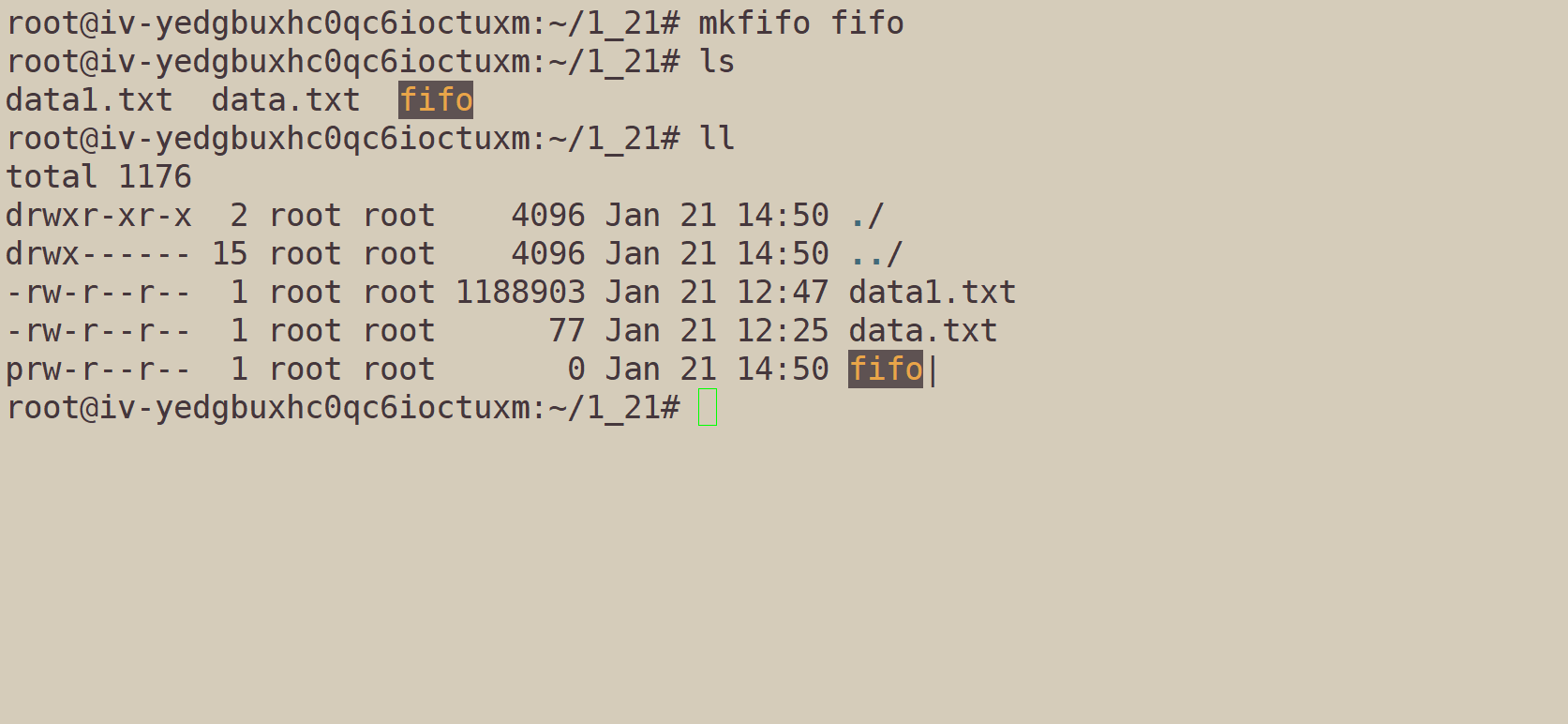
我们创建了一个文件fifo,其属性以p开头(pipe),fifo就是命名管道文件。
命名管道的使用方法,和匿名管道一样。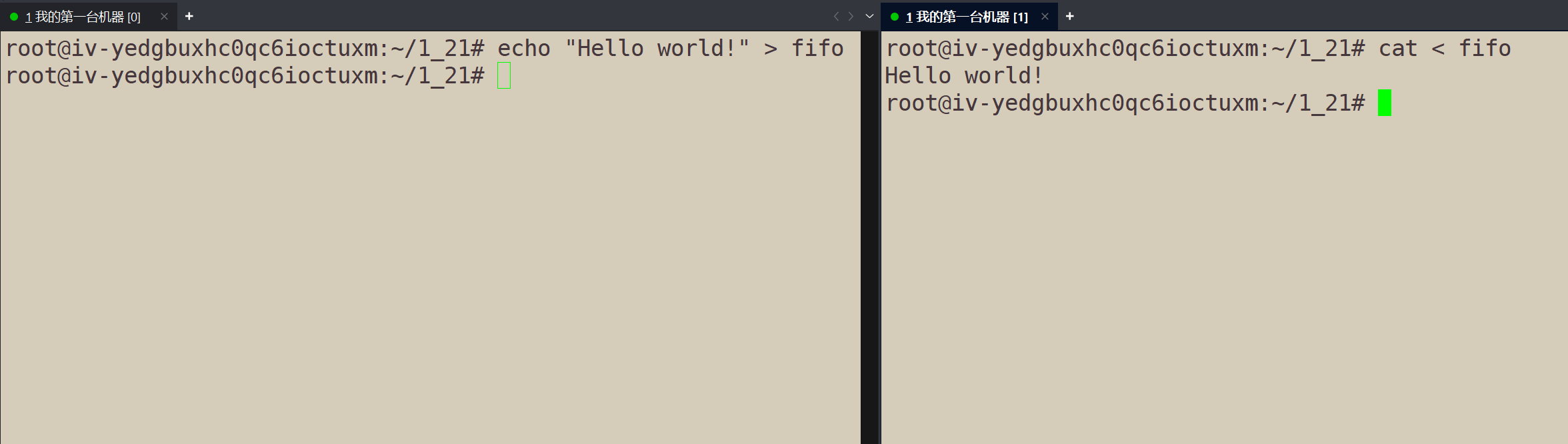
利用fifo文件,玩一玩这个指令:
while :; do echo "Hello!"; sleep 1; done > fifo。
所以,我们当前就认识了四种Linux文件类型(第一个字符区分):
d -----> 目录
短横杠 -----> 普通文件
c -----> 字符文件
p -----> 管道文件
cat fifoVScat < fifo效果一样,但是底层实现不一样。
main函数可以带参数?
4、date指令,与时间戳
date指令,顾名思义,就是获取时间。
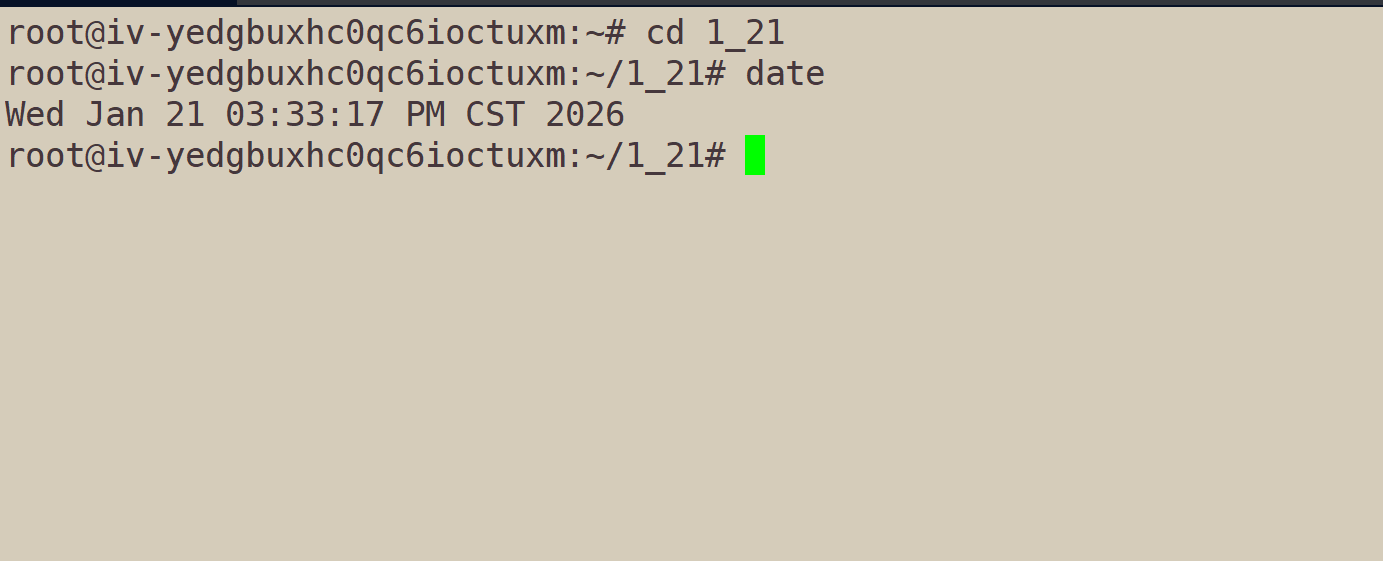
获取年份:date +%Y
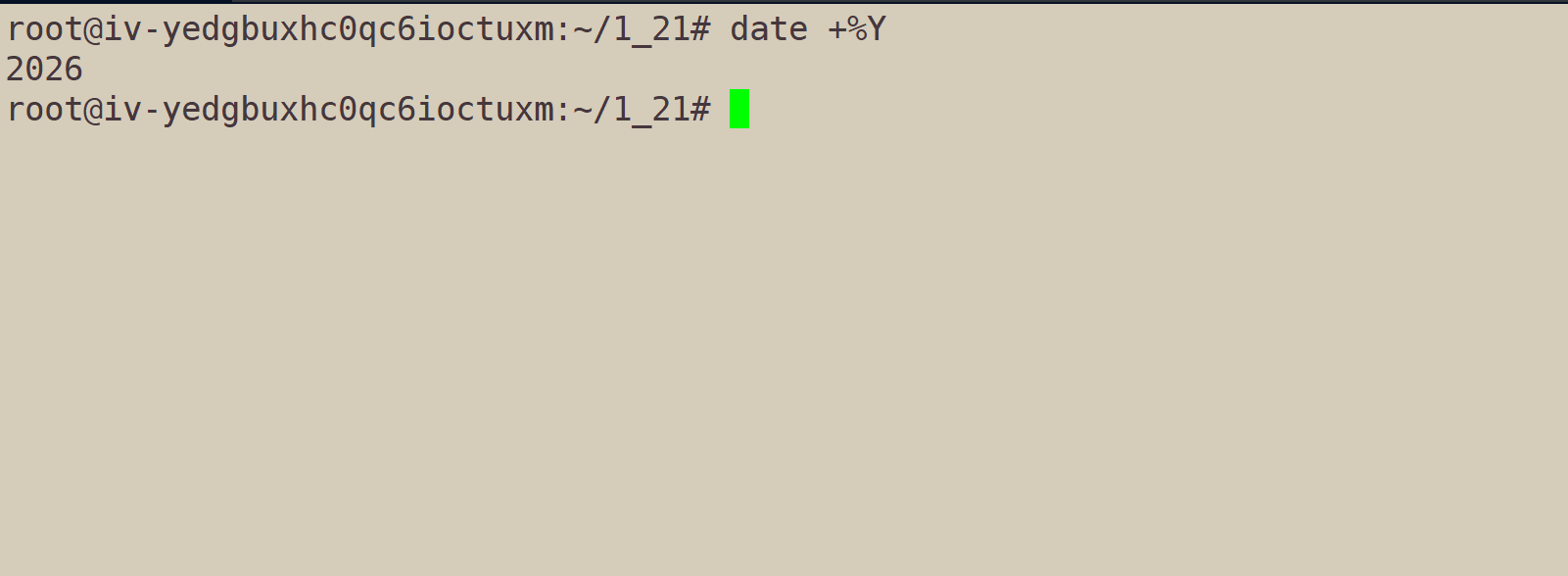
获取年、月:date +%Y-%m
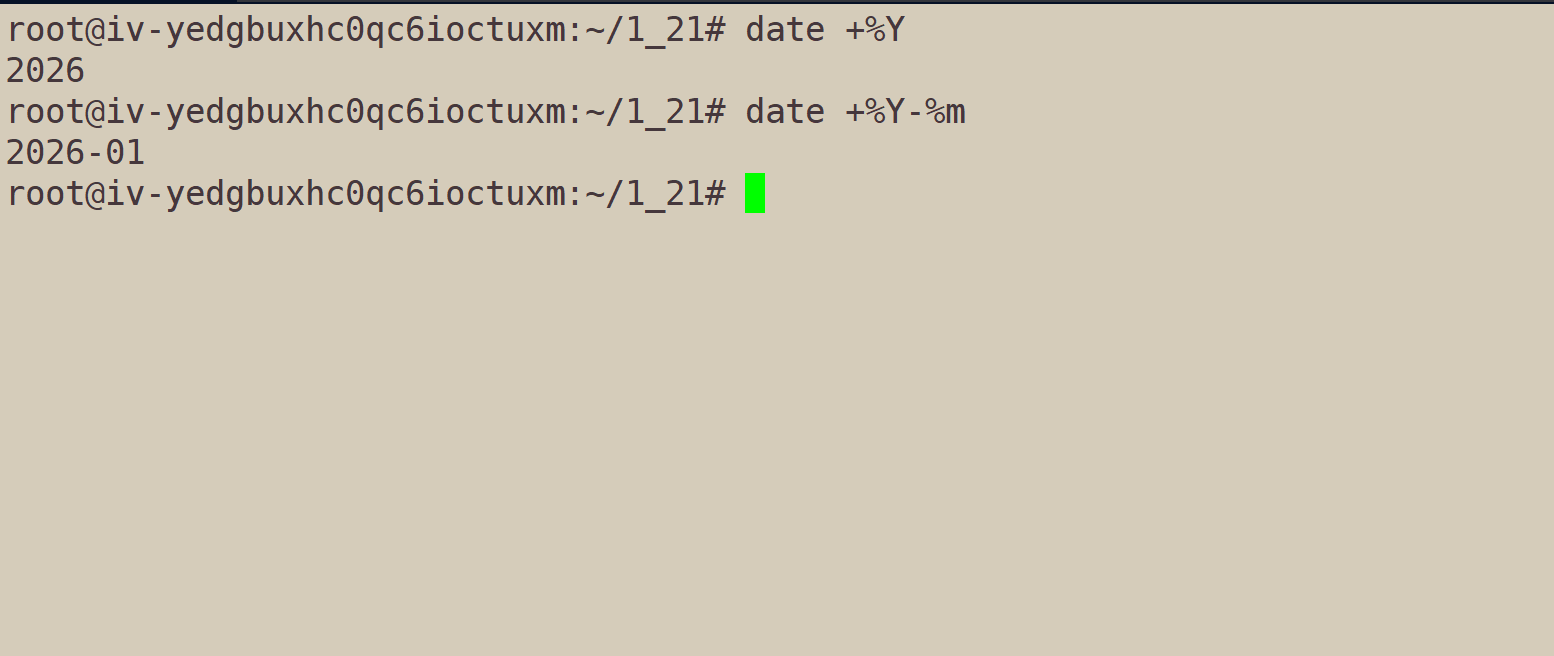
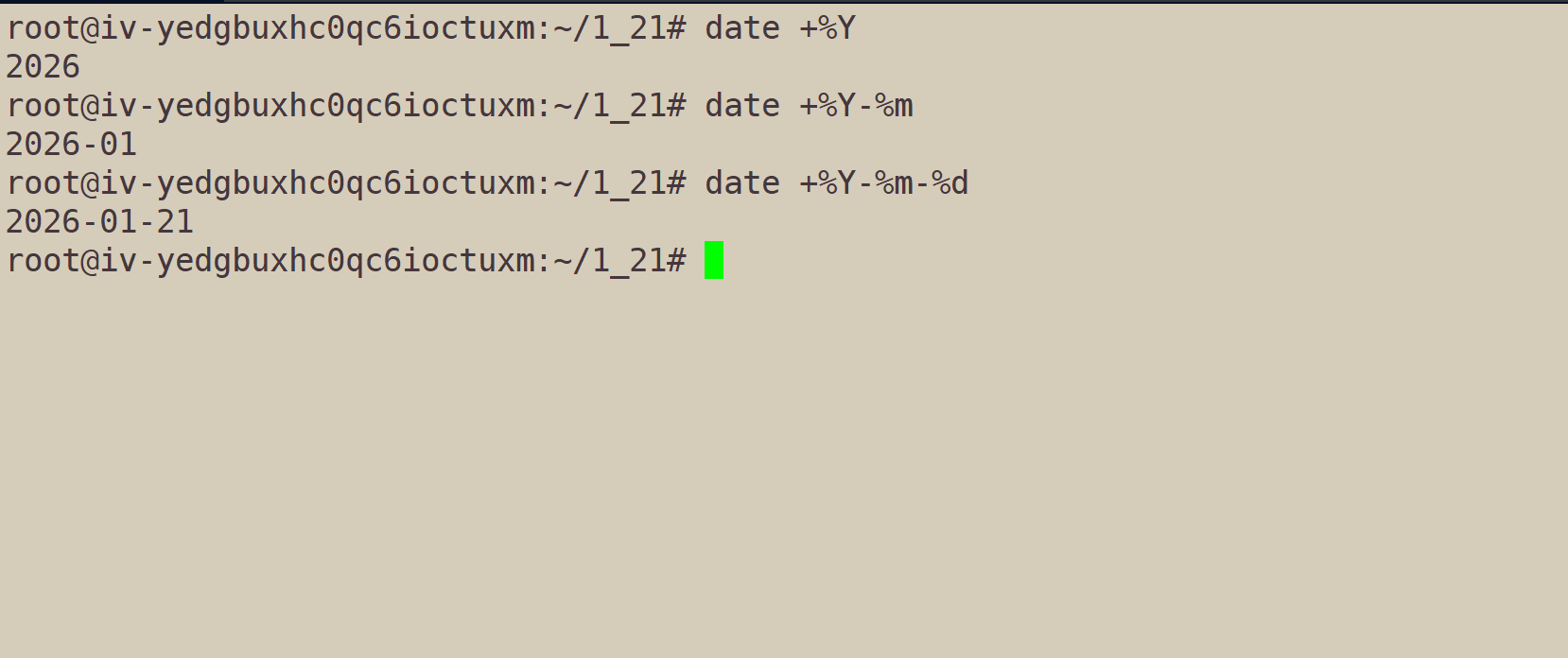
获取年、月、日:date +%Y-%m-%d
获取当前准确到秒的时间:date +%Y-%m-%d_%H:%M:%S
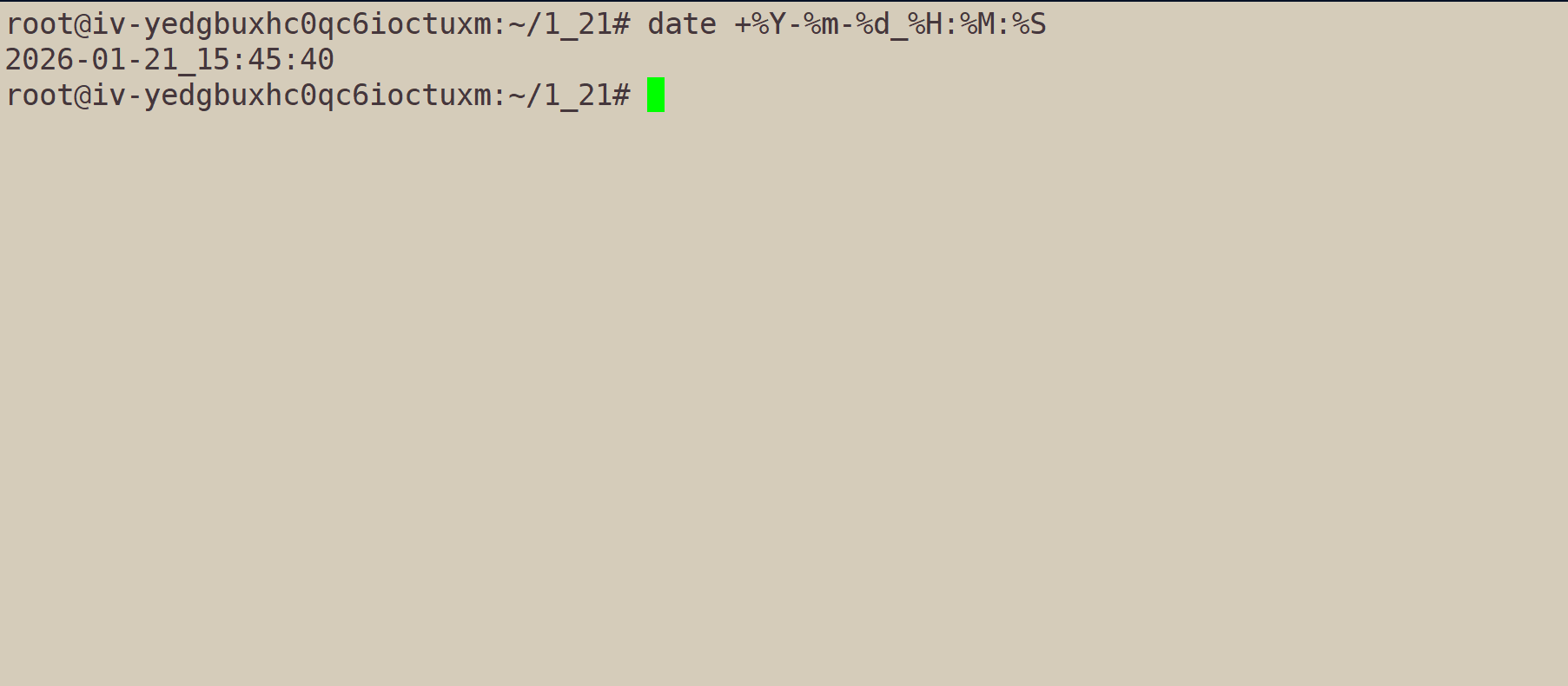
但是,但我们使用指令date +%s,我们会得到一个非常大的数字:
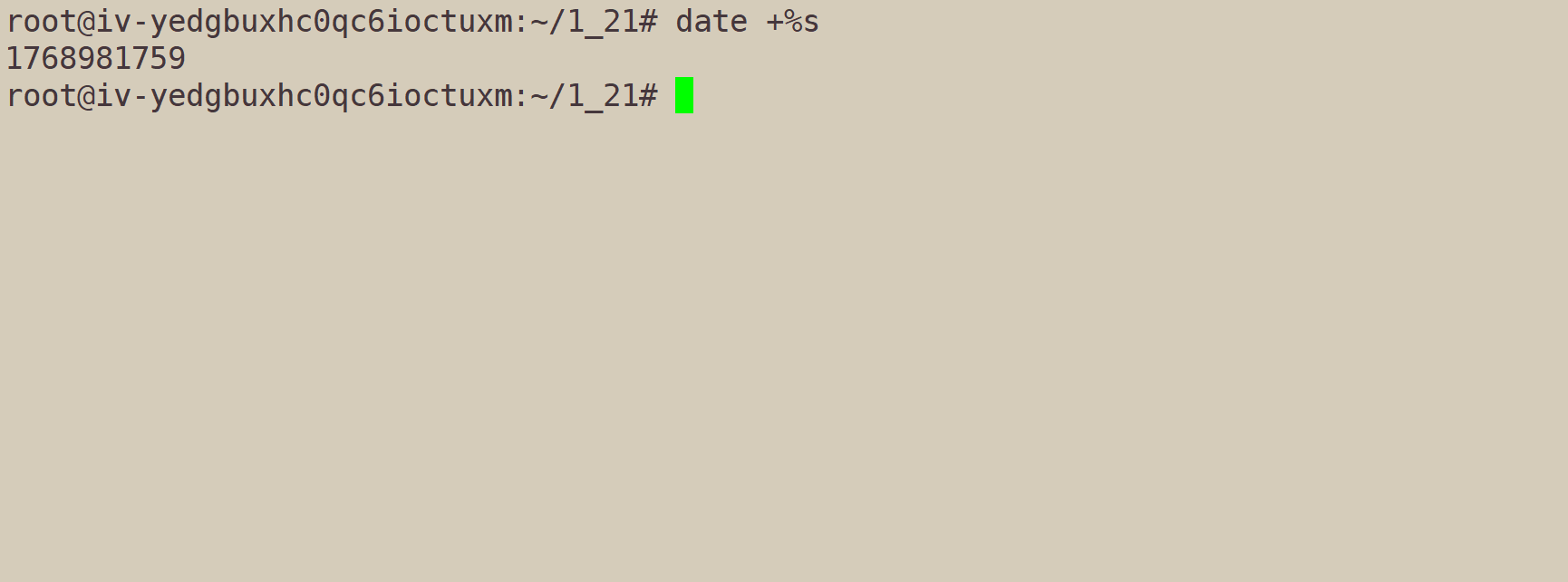
4.1、什么是时间戳
时间戳,就是从1970年1月1日,00:00开始,到现在,经过的的秒数。
利用这个时间戳,经过换算,形成不同地区的时间,这就是时差。
如何将时间戳,换成可读性较好的时间?
cpp
date +%Y-%m-%d_%H:%M:%S -d @[时间戳]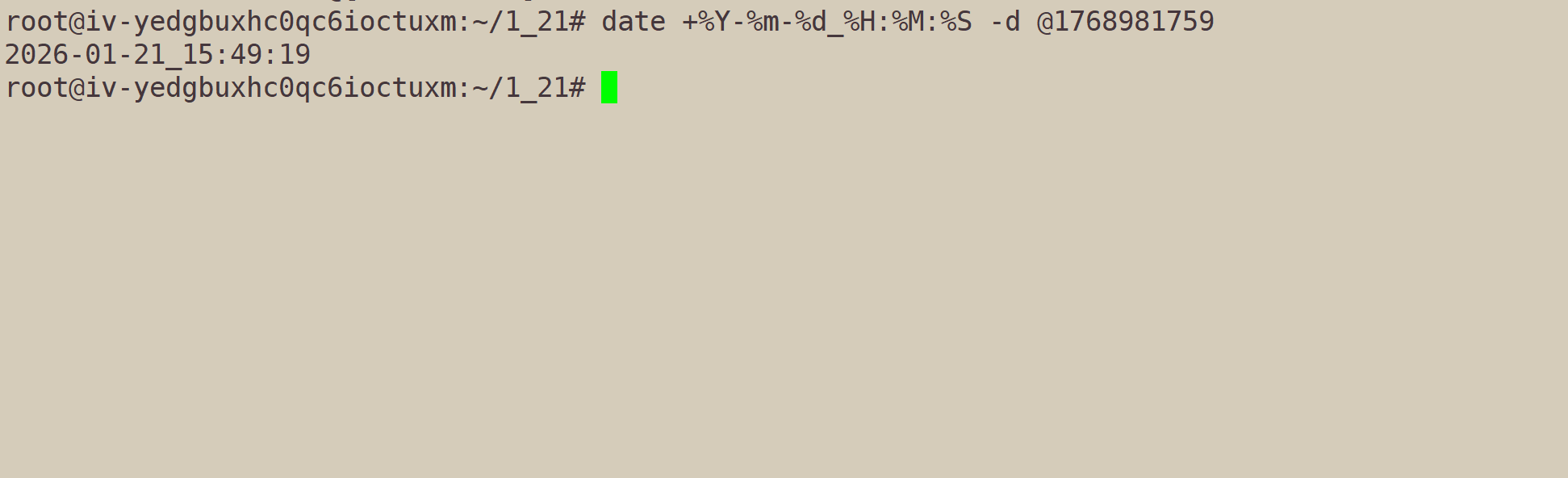
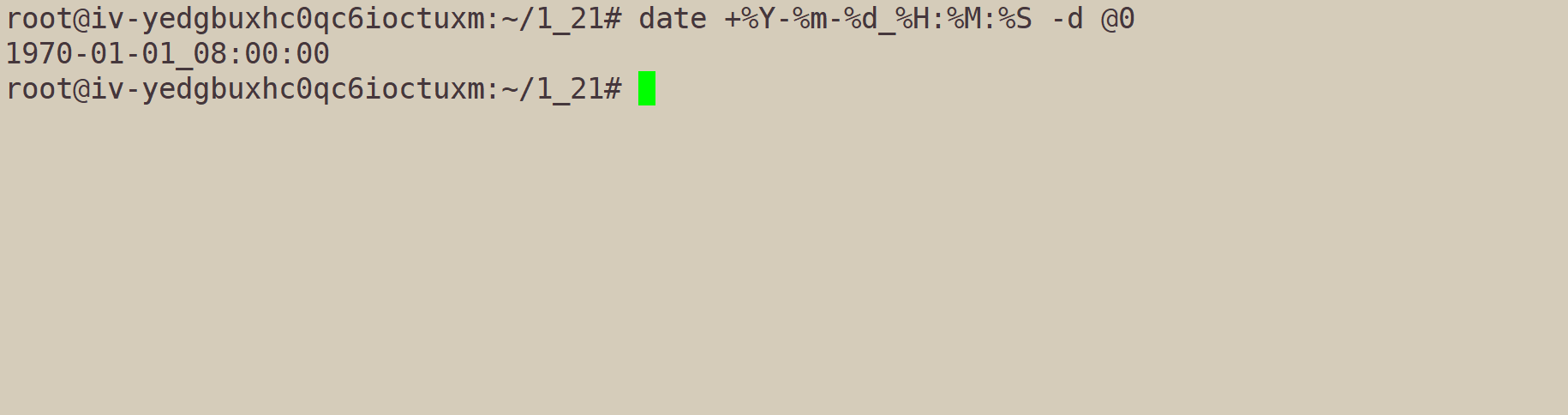
中国在东八区,所以@0是这样的:
4.2、时间戳的问题和应用
时间戳是不断加1的,溢出了怎么办?
就会出现大乱,但是自会有人解决。
时间,在计算机里是很重要的。比如日志。
大型软件,运行过程中,都要携带日志。日志,是大型软件运行状况检测的载体,方便问题的排查。而一个日志,必须有时间。
5、cal指令
这条指令,作用是获取日历。
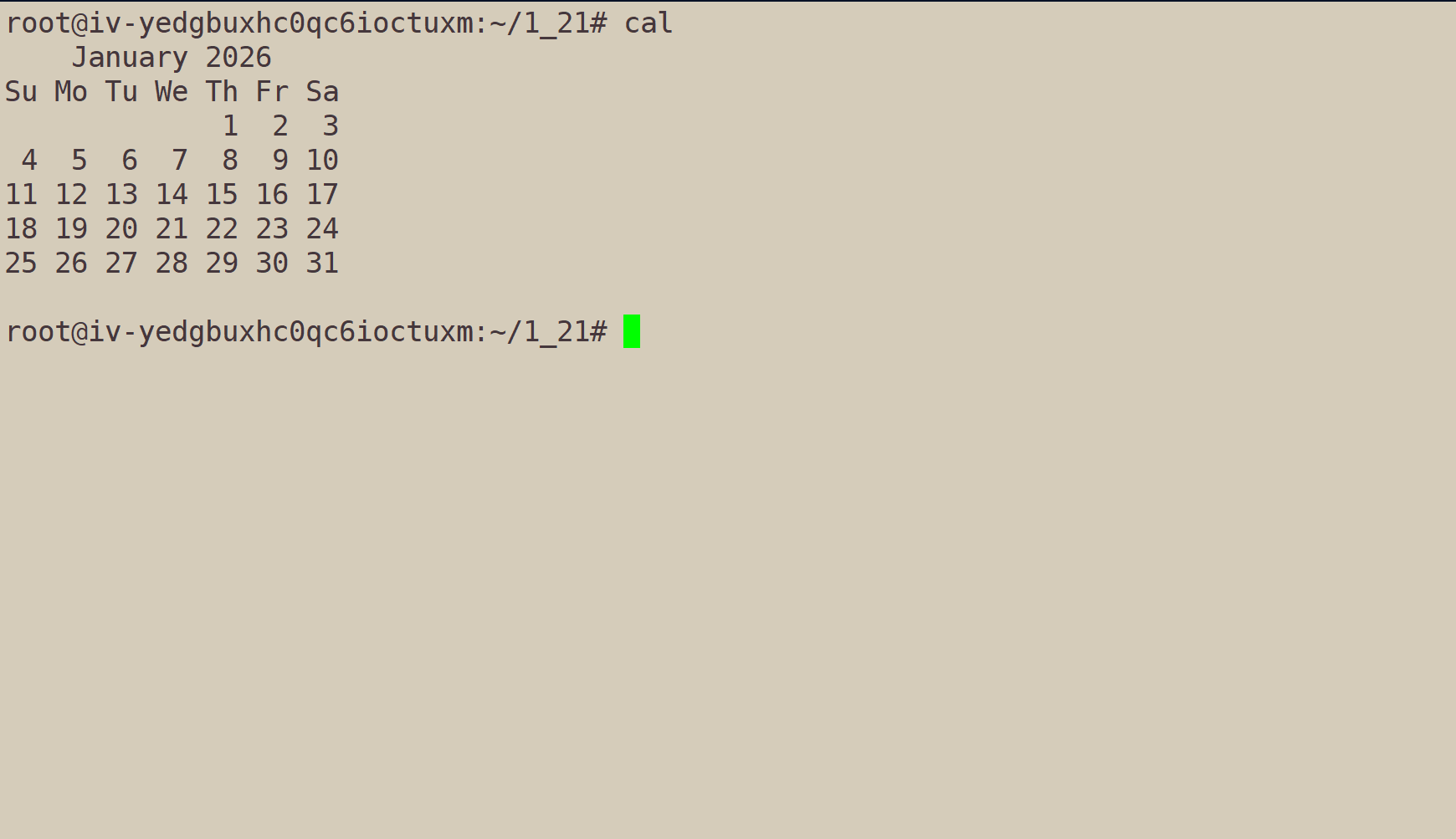
cal:获取当前所在的月份。
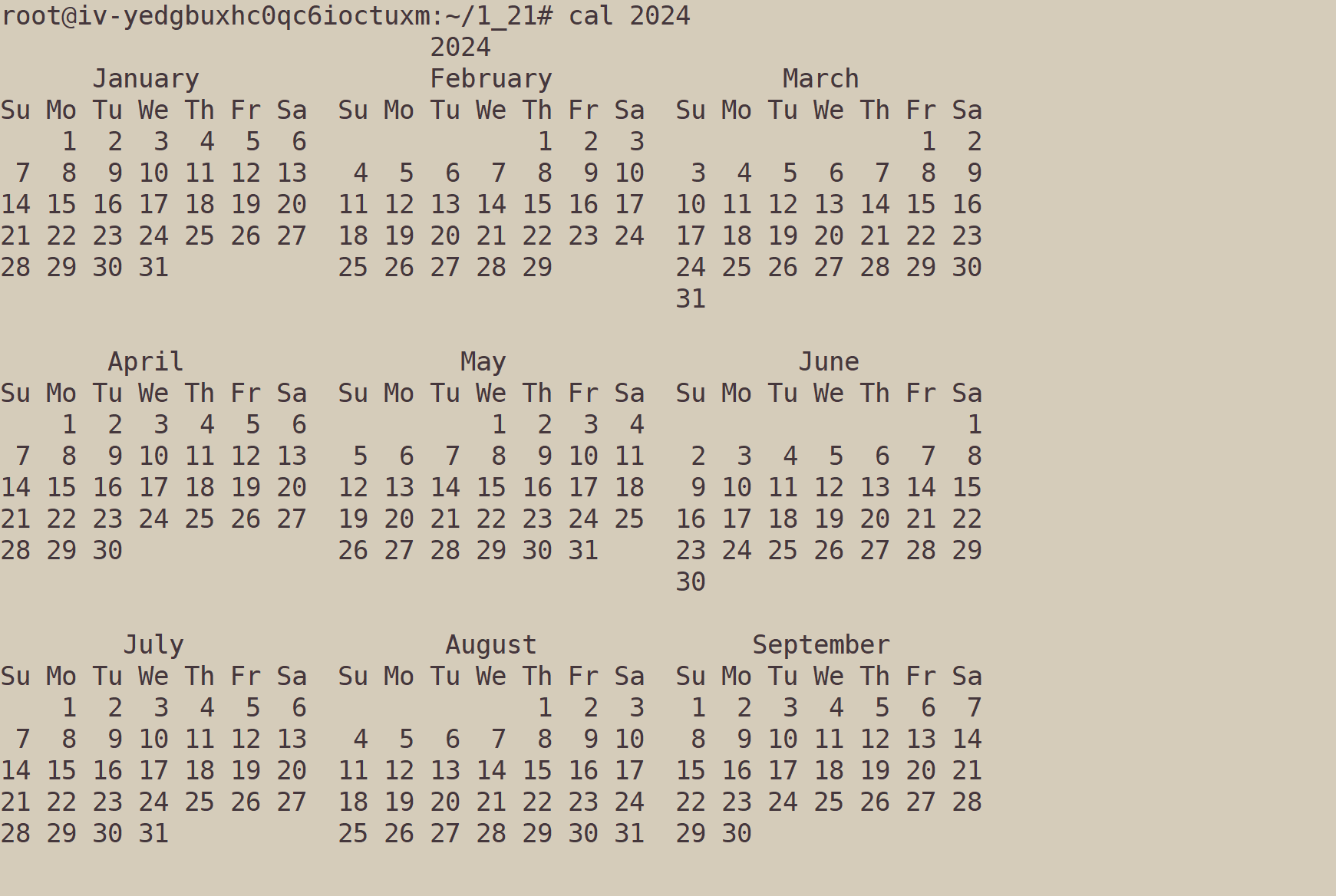
cal 2024:获取2024年一年的日历。
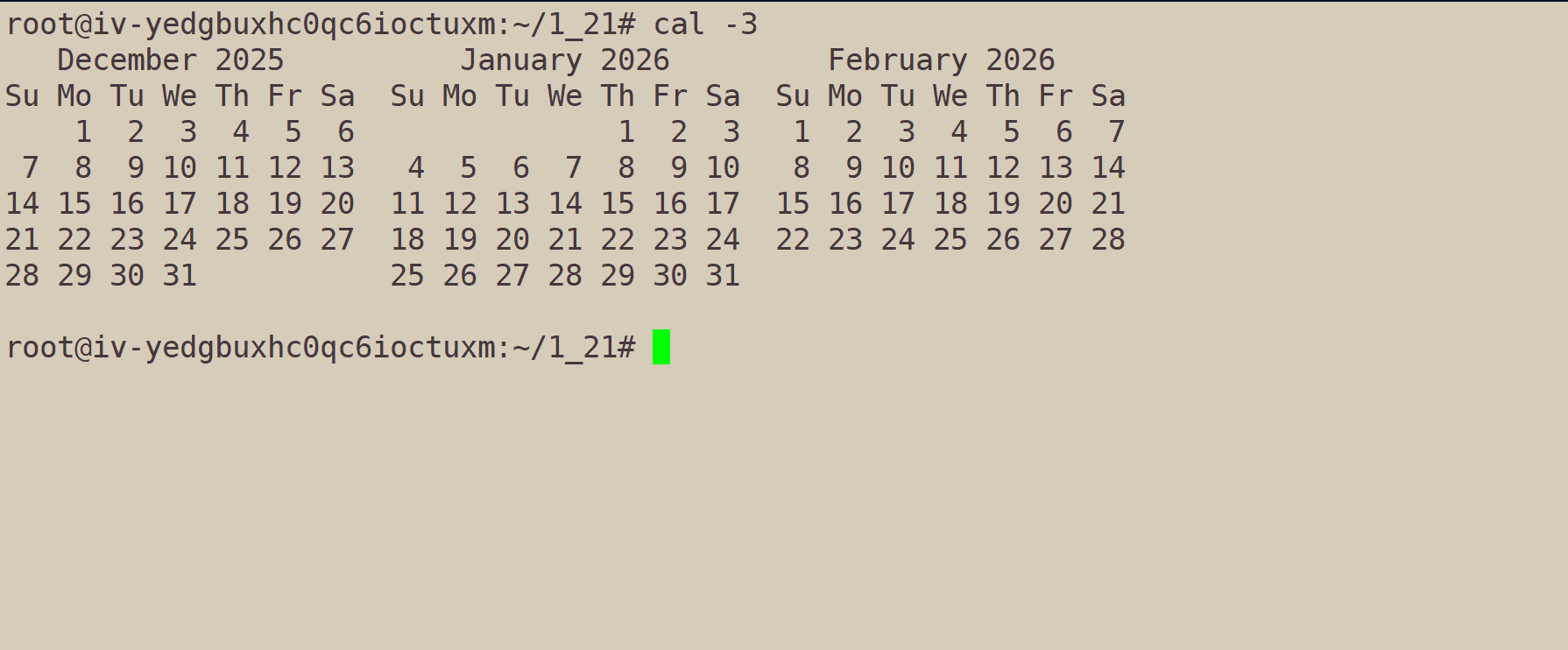
cal -3:获取最近3个月的日历。
6、查找命令
6.1、which
专门用来查找特定指令所在的路径。
6.2、find
find指令,一般是用来查找文件的。
用法是:find [路径] -name [文件名]。其中,-name是选项的其中一种,也就是说,这条命令,是在指定路径下,按名字查找文件。
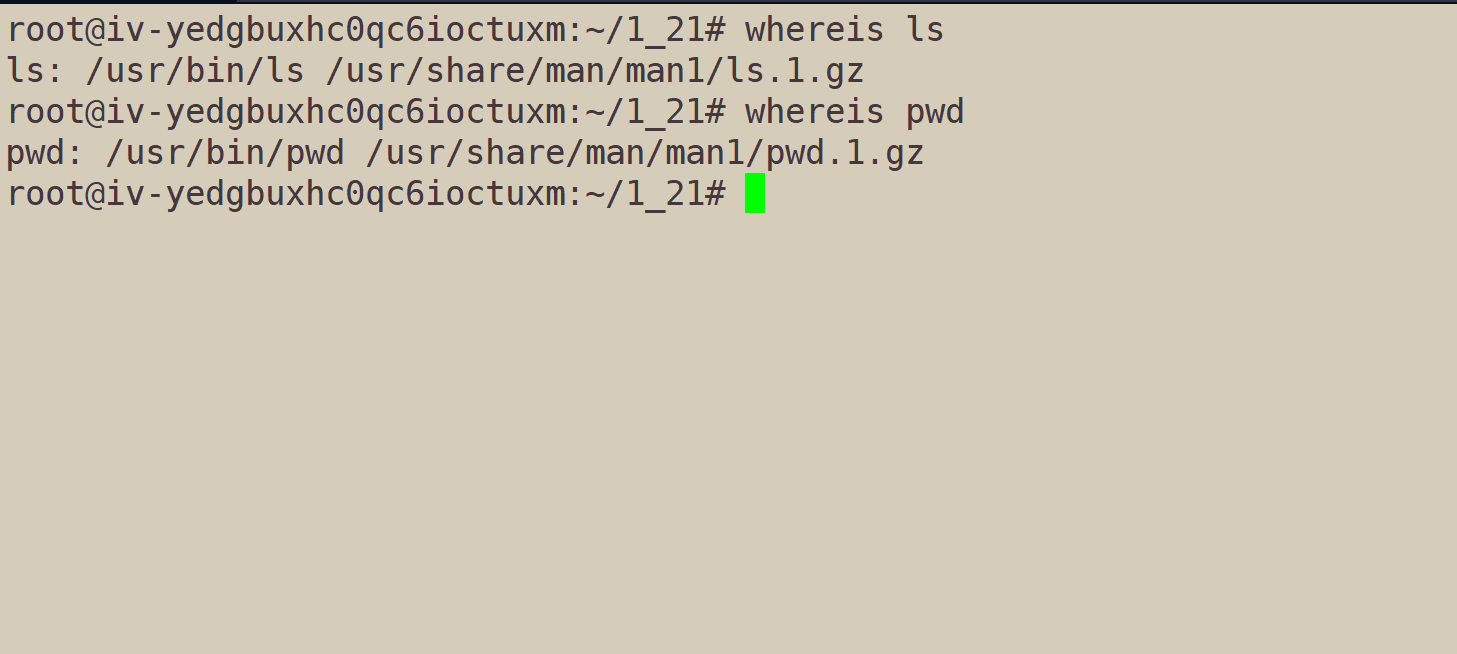
6.3、whereis
这条指令,是用来,在系统指定路径下查找:程序的原、二进制文件、手册。也就是查找命令、安装包、对应文档。
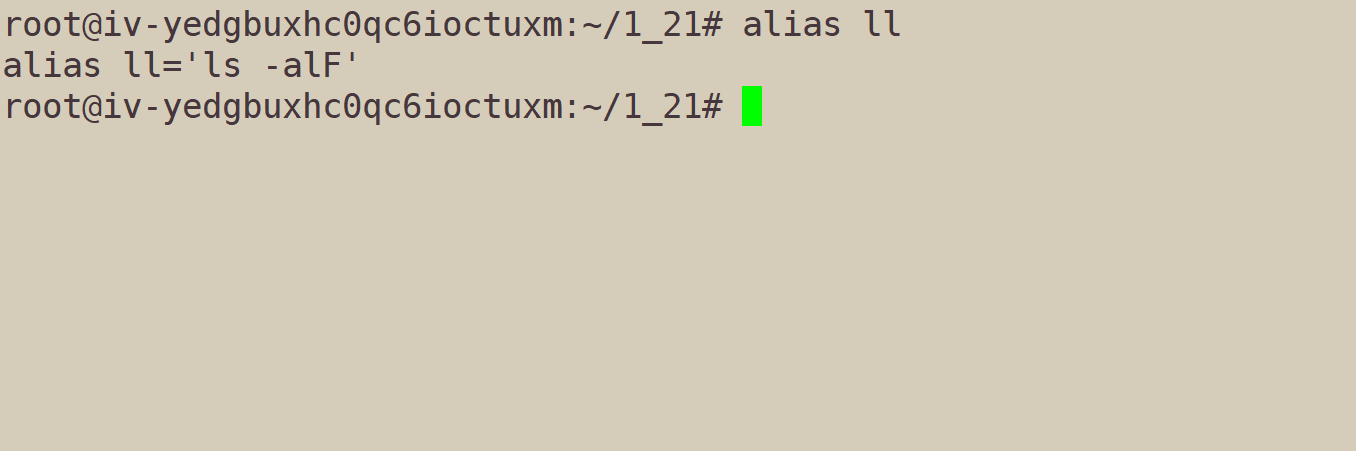
6.4、alias
这条指令,不仅可以给指令取别名,还可以查看别名指令对应的原指令。
6.5、grep
命令:grep '999' data1.txt
此时,grep将data1.txt中的内容,进行读取,然后返回包含999关键字的内容。这是行过滤 行为。

行过滤日志:grep "root" /var/log/syslog.1
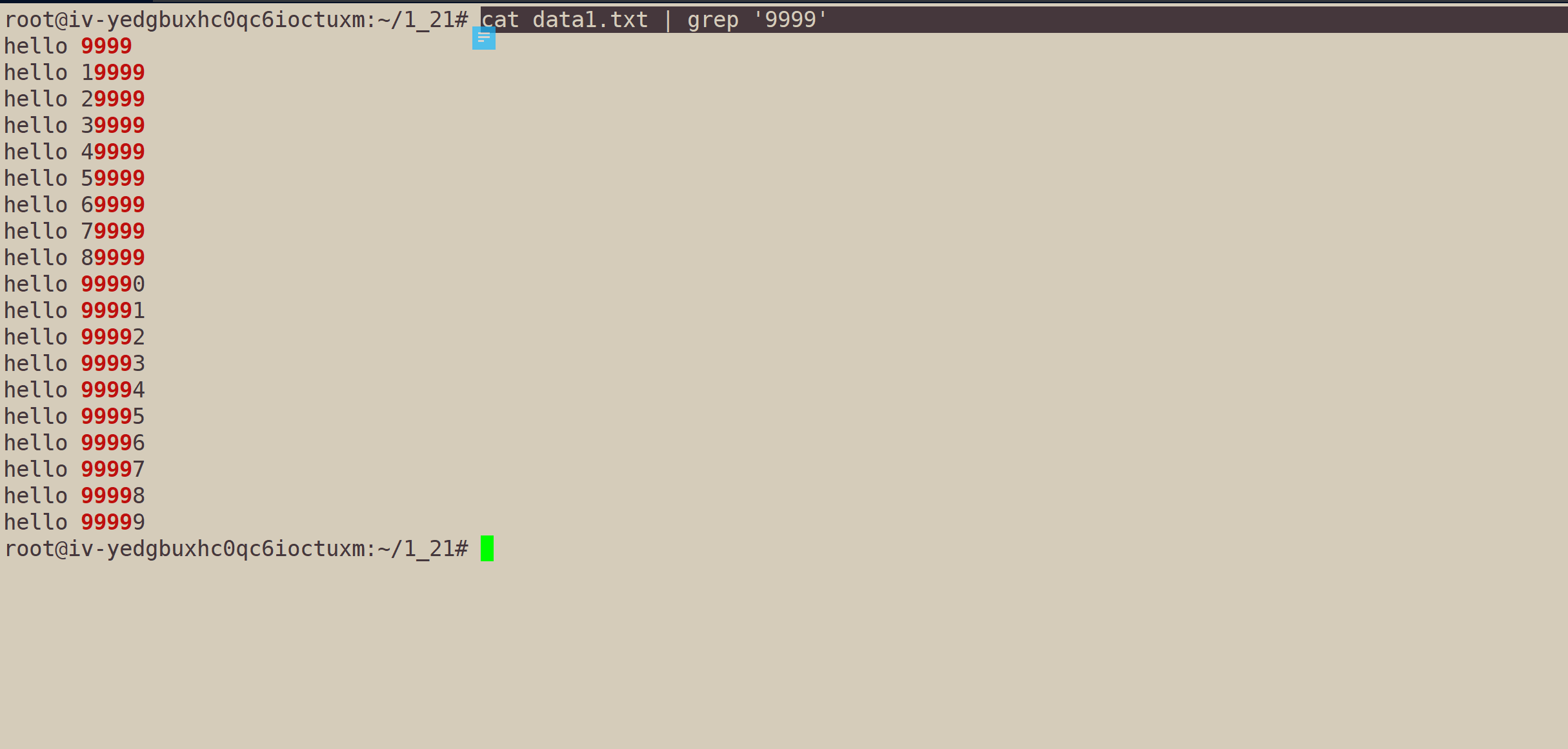
组合使用:cat data1.txt | grep '9999'
6.5.1、grep的作用
样例一:
比较机器的好坏,就可以比较错误的多少。而要在日志中查找错误信息,我们就可以使用grep来过滤。
样例二:
我们查进程:
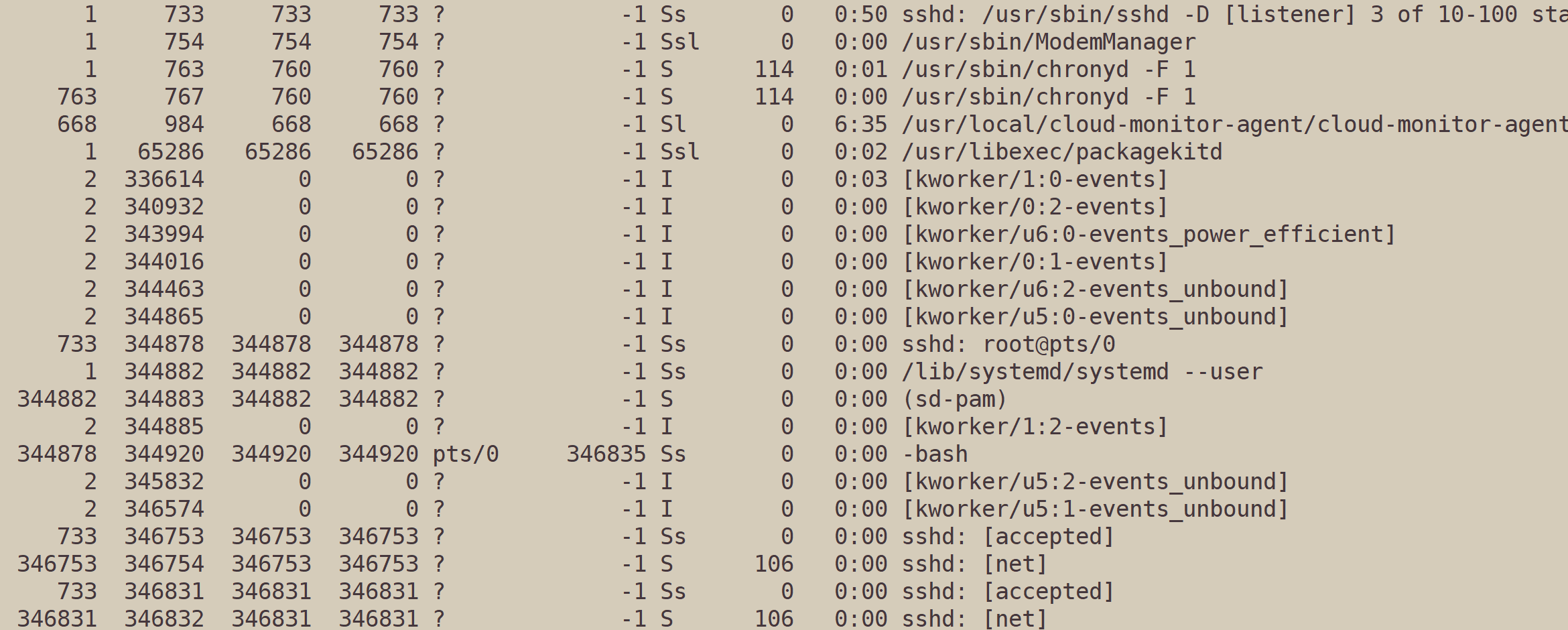
太多了。
组合使用grep,把带关键词的内容过滤出来:

所以,grep可以:
- 分析日志。
- 分析程序信息。
- 分析文件信息。
6.5.2、grep的选项
我们以当前的data2.txt为操作对象,演示grep的一些选项。
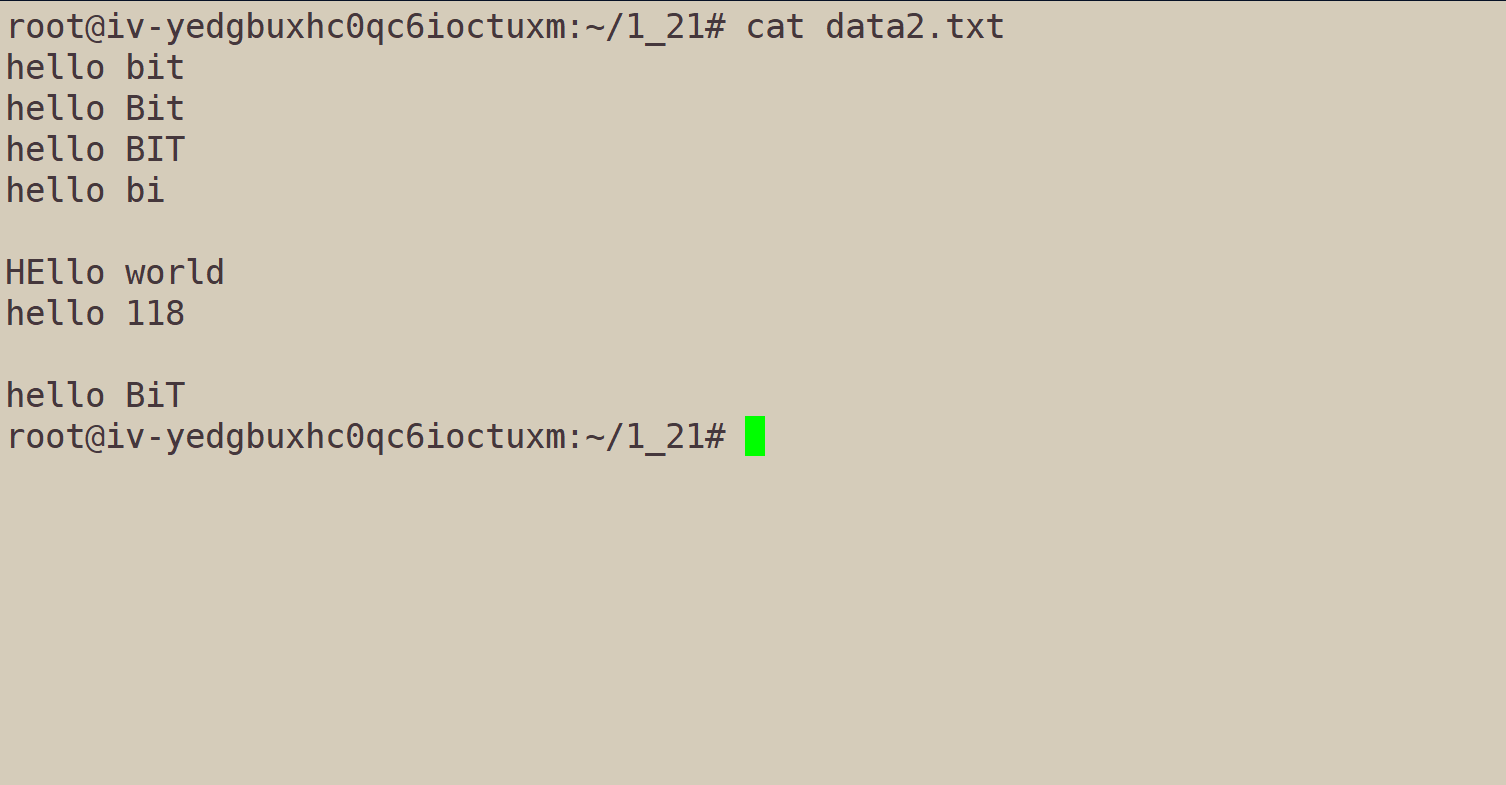
grep "hello" data2.txt:输出包含严格遵守大小写"hello"的文本
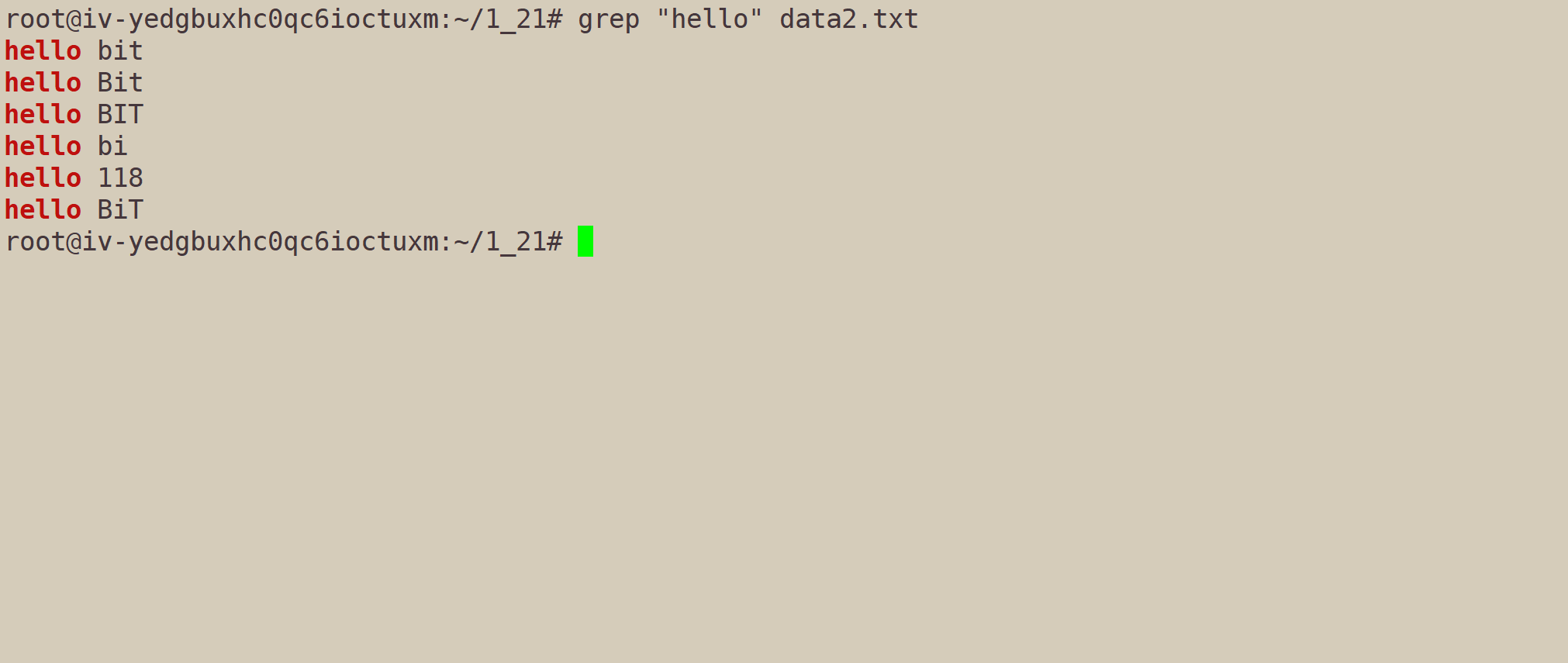
grep -i "hello" data2.txt:不考虑大小写(ignore)
grep -v "bit" data2.txt:输出不包含"bit"的文本(invert match反向匹配)
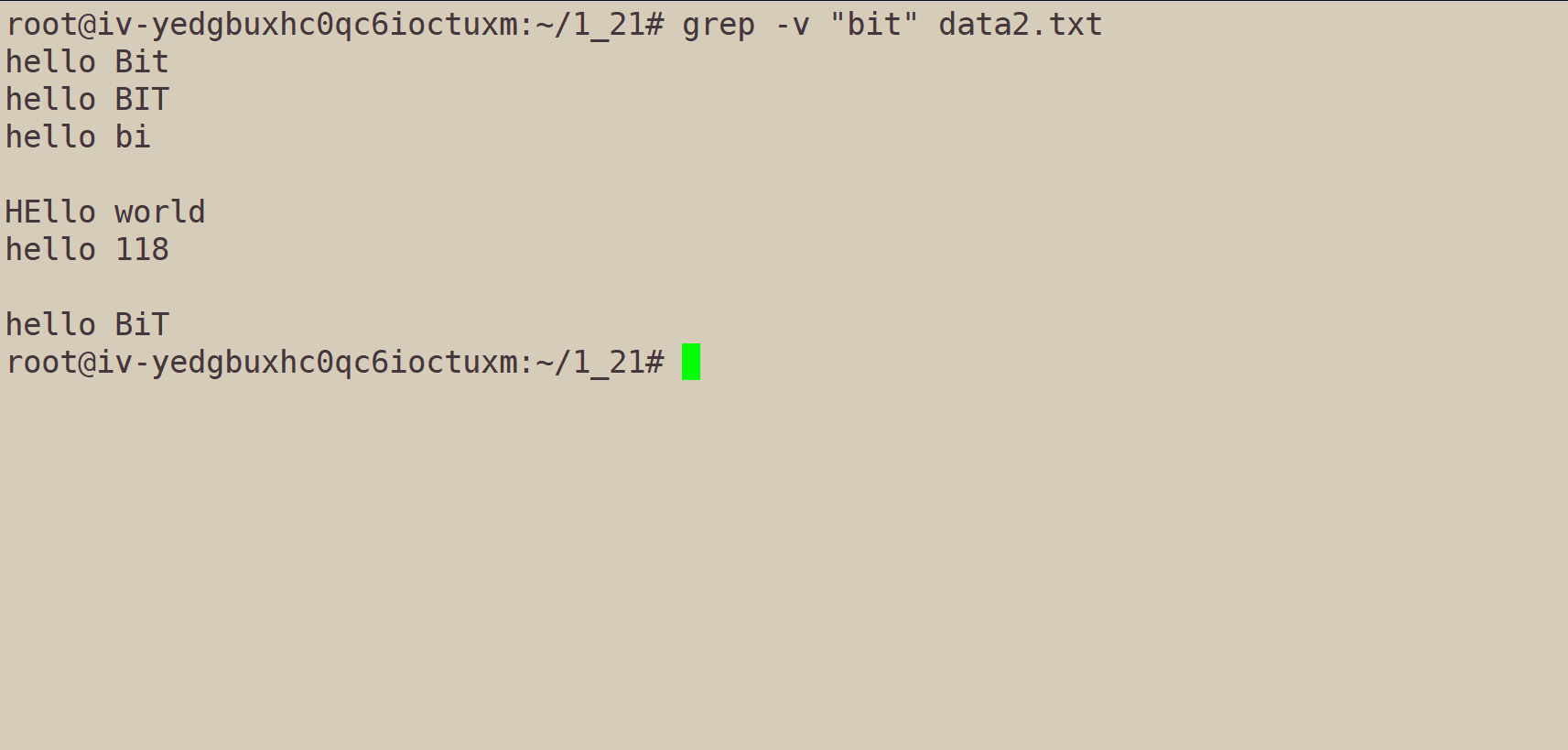
grep -iv "bit" data2.txt:
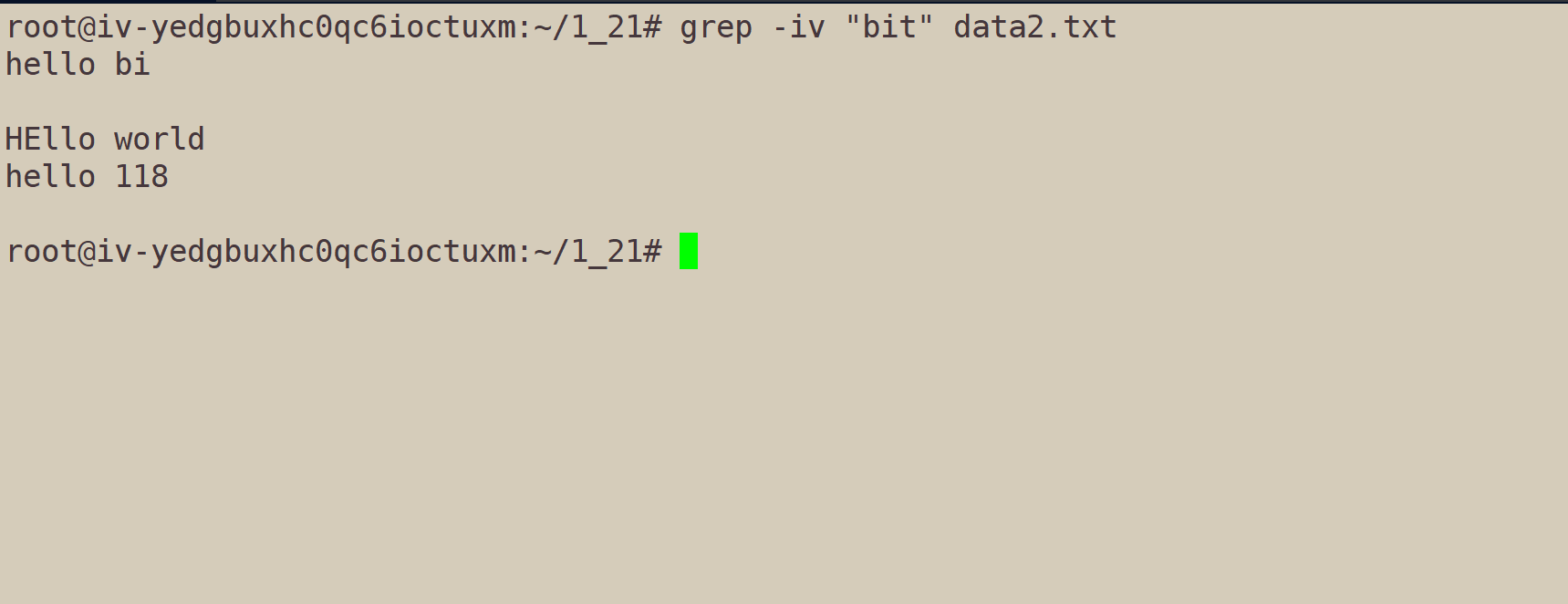
就得到了没有bit、Bit啥的东西了。
grep -n "bit" data2.txt:查找含严格bit的文本,并附上行号(number)
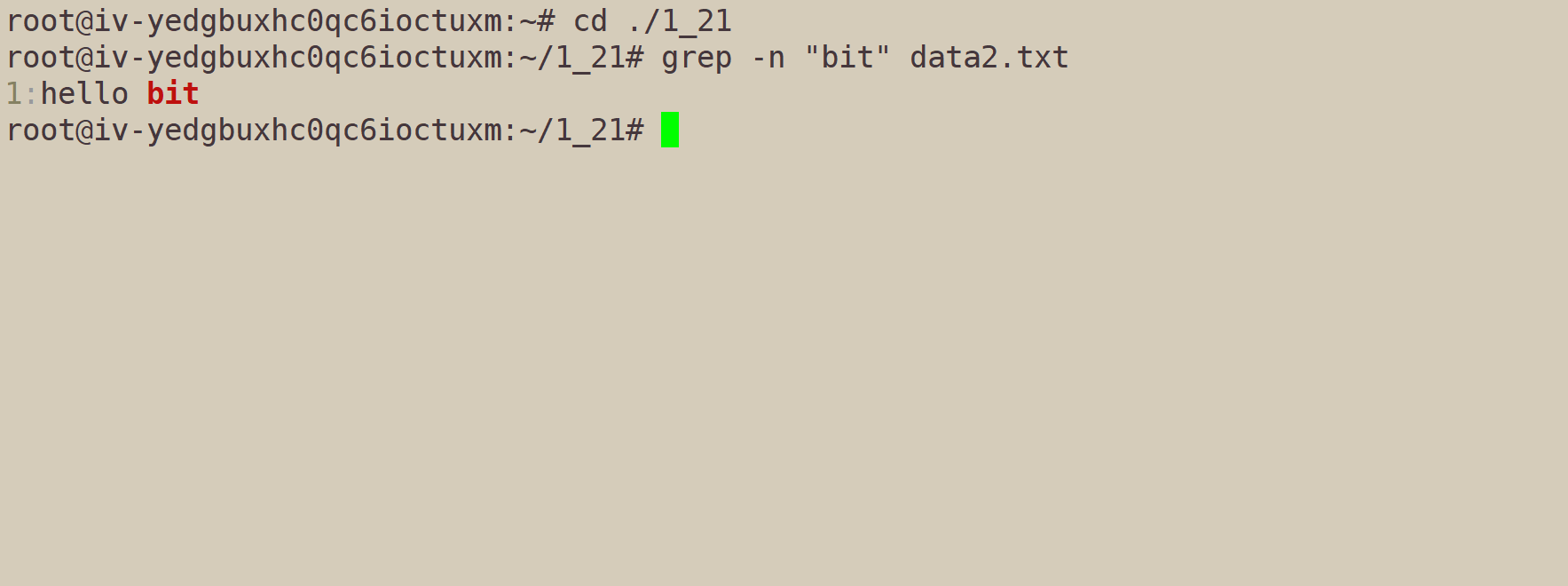
之后,就可以组合使用。