Kafka 安装部署
一、环境准备
1. 服务器规划
| 节点角色 | 服务器IP | 容器名称 | 节点ID(KAFKA_NODE_ID) | 控制器端口(CONTROLLER) | broker端口(PLAINTEXT) |
|---|---|---|---|---|---|
| Kafka节点1 | ip1 | kafka-157 | 1 | 9093 | 9092 |
| Kafka节点2 | ip2 | kafka-158 | 2 | 9093 | 9092 |
| Kafka节点3 | ip3 | kafka-159 | 3 | 9093 | 9092 |
2. 前置条件
-
所有节点安装 Docker 和 Docker Compose
-
网络互通 :三个节点之间需开放
9092(broker通信)和9093(控制器通信)端口,关闭防火墙或配置白名单。 -
目录准备 :每个节点创建数据和日志目录,并赋予权限:
bash# 在 ip1、ip2、ip3 分别执行 mkdir -p /data/kafka/data /data/kafka/logs chmod -R 777 /data/kafka # 生产环境建议精细化权限(如设置容器用户ID)
二、集群配置文件(docker-compose.yml)
1. 节点1(ip1)配置文件 kafka.yml
yaml
version: "3.8"
services:
kafka:
image: apache/kafka:3.8.0 # 官方镜像
container_name: kafka-157 # 容器名称,需唯一
hostname: kafka-157 # 容器 hostname,用于集群识别
restart: always # 故障自动重启
ports:
- "9092:9092" # broker 对外服务端口(PLAINTEXT协议)
- "9093:9093" # controller 集群通信端口
environment:
# 核心配置(集群必改项)
KAFKA_NODE_ID: 1 # 节点唯一ID(1/2/3,不可重复)
KAFKA_PROCESS_ROLES: broker,controller # 当前节点角色:既是broker也是controller(3.3+ 新架构,无需独立controller节点)
KAFKA_LISTENERS: PLAINTEXT://0.0.0.0:9092,CONTROLLER://0.0.0.0:9093 # 监听地址(0.0.0.0表示所有网卡)
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://ip1:9092 # 对外暴露的地址(客户端连接用,需替换为节点实际IP)
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT # listener与协议映射
KAFKA_CONTROLLER_LISTENER_NAMES: CONTROLLER # 指定控制器通信的listener名称
KAFKA_CONTROLLER_QUORUM_VOTERS: 1@ip1:9093,2@ip2:9093,3@ip3:9093 # 控制器集群投票节点(node_id@ip:port)
# 存储与日志配置
KAFKA_LOG_DIRS: /var/lib/kafka/data # 数据存储目录(映射到宿主机/data/kafka/data)
KAFKA_LOG_RETENTION_HOURS: 168 # 日志保留时间(7天)
KAFKA_LOG_SEGMENT_BYTES: 1073741824 # 单个日志段大小(1GB)
KAFKA_LOG_RETENTION_CHECK_INTERVAL_MS: 300000 # 日志清理检查间隔(5分钟)
# Topic默认配置
KAFKA_NUM_PARTITIONS: 18 # 默认分区数(根据业务调整,建议偶数)
KAFKA_DEFAULT_REPLICATION_FACTOR: 3 # 默认副本因子(3节点集群建议3,保证高可用)
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 3 # 偏移量 topic 副本因子(需 ≥ 3)
KAFKA_TRANSACTION_STATE_LOG_REPLICATION_FACTOR: 3 # 事务日志副本因子
KAFKA_TRANSACTION_STATE_LOG_MIN_ISR: 2 # 事务日志最小同步副本数
# 性能与安全配置
KAFKA_MIN_INSYNC_REPLICAS: 2 # 最小同步副本数(需 ≤ 副本因子,建议副本因子-1)
KAFKA_AUTO_CREATE_TOPICS_ENABLE: "false" # 禁止自动创建topic(需手动创建,避免垃圾topic)
KAFKA_UNCLEAN_LEADER_ELECTION_ENABLE: "false" # 禁止非同步副本成为leader(保证数据一致性)
KAFKA_NUM_NETWORK_THREADS: 4 # 网络线程数(处理客户端请求,建议CPU核心数的1-2倍)
KAFKA_NUM_IO_THREADS: 8 # IO线程数(处理磁盘IO,建议CPU核心数的2-4倍)
KAFKA_HEAP_OPTS: "-Xms2G -Xmx2G" # JVM堆内存(建议为物理内存的50%,最大不超过32G)
networks:
- kafka-net # 自定义网络(如需跨主机通信,需替换为overlay网络或host网络)
volumes:
- /data/kafka/data:/var/lib/kafka/data # 数据目录挂载(宿主机:容器内)
- /data/kafka/logs:/opt/kafka/logs # 日志目录挂载
deploy:
resources:
limits:
cpus: '4' # CPU限制(根据服务器配置调整,建议4核以上)
memory: 4G # 内存限制(需大于堆内存,预留系统和缓存空间)
networks:
kafka-net:
driver: bridge # 单主机用bridge;跨主机需用overlay(如Docker Swarm)或host网络2. 节点2(ip2)和节点3(ip3)配置调整
节点2和节点3的配置文件与节点1基本一致,只需修改以下参数:
| 参数 | 节点2(ip2)调整 | 节点3(ip3)调整 |
|---|---|---|
container_name |
kafka-158 | kafka-159 |
hostname |
kafka-158 | kafka-159 |
KAFKA_NODE_ID |
2 | 3 |
KAFKA_ADVERTISED_LISTENERS |
PLAINTEXT://ip2:9092 | PLAINTEXT://ip3:9092 |
三、启动集群
1. 分别在三个节点启动容器
bash
# 在 ip1、ip2、ip3 节点分别执行
docker-compose -f kafka.yml up -d2. 检查容器状态
bash
# 查看容器是否运行
docker ps | grep kafka
# 查看日志(确认无错误,如控制器选举、集群连接成功)
docker logs -f kafka-157 # 替换为对应节点的容器名称日志关键成功标志:
- 节点1日志出现
Controller quorum initialized successfully(控制器集群初始化成功)。 - 所有节点日志出现
Joined group as a follower或Became leader(集群共识达成)。
四、集群验证
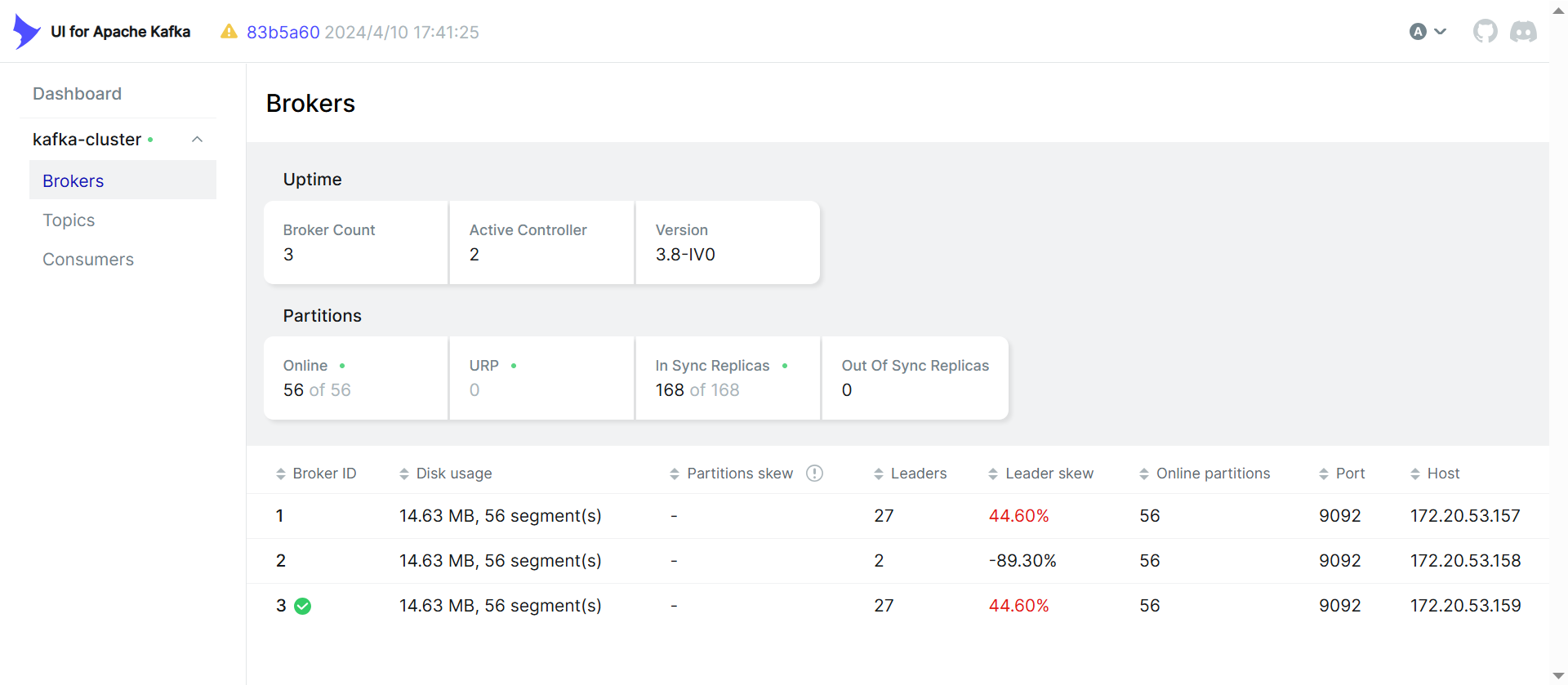
1. 检查集群节点状态
五、性能压测与优化
1. 压测工具使用(内置 kafka-producer-perf-test.sh)
bash
# 在容器内执行(向 isrm-test 压入 100万条消息,每条1KB)
/opt/kafka/bin/kafka-producer-perf-test.sh \
--topic isrm-test \
--num-records 1000000 \
--record-size 1024 \
--throughput -1 \ # 不限速,测试最大吞吐量
--producer-props bootstrap.servers=ip1:9092,ip2:9092,ip3:9092
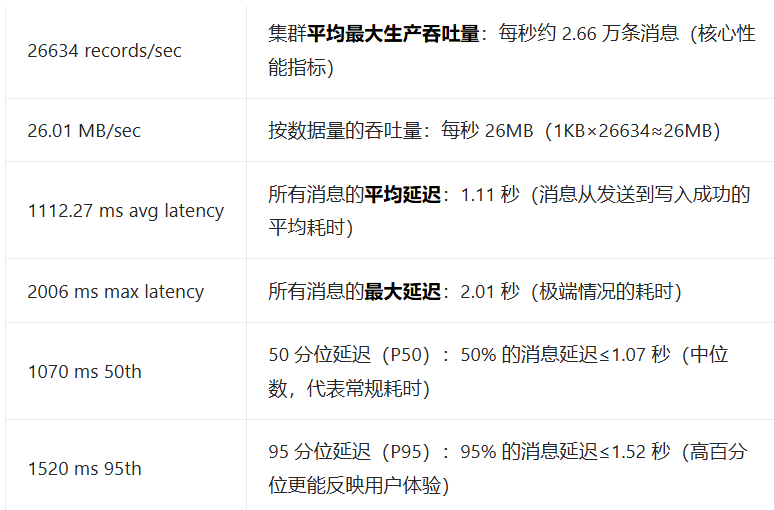
2. 常见性能问题优化
(1)客户端压测失败(吞吐量不足)
- 检查服务器资源:确保每个节点 CPU 使用率 < 80%,内存充足(避免 swap)。
- 调整 JVM 堆内存 :若堆内存过小(如 < 2G),可增大
KAFKA_HEAP_OPTS(如-Xms4G -Xmx4G,需同步调整deploy.resources.memory)。 - 优化网络线程 :增加
KAFKA_NUM_NETWORK_THREADS(如 8,CPU核心数的2倍)和KAFKA_NUM_IO_THREADS(如 16)。
(2)副本同步延迟
- 检查磁盘 IO :使用
iostat -x 1查看磁盘 IO 使用率,若%util接近 100%,需更换 SSD 或调整日志目录到独立磁盘。 - 减少同步副本数 :非核心 topic 可降低
replication-factor(如 2),但核心业务建议保持 3。
六、注意事项
-
跨主机网络:若三个节点在不同服务器,Docker 默认 bridge 网络无法跨主机通信,需:
- 方案1:使用
network_mode: host(直接使用宿主机网络,需确保端口不冲突)。 - 方案2:搭建 Docker Swarm 并使用 overlay 网络(适合大规模集群)。
- 方案1:使用
-
数据备份 :定期备份
/data/kafka/data目录(Kafka 数据目录),避免数据丢失。 -
版本兼容性 :客户端 SDK 版本需与 Kafka 服务端版本兼容(建议客户端版本 ≥ 服务端版本,或遵循 Kafka 版本兼容性文档)。
-
监控集成 :建议通过 Prometheus + Grafana 监控 Kafka 指标(如
kafka_server_BrokerTopicMetrics_MessagesInPerSec吞吐量、kafka_controller_ActiveControllerCount控制器状态等)。
七、总结
通过 Docker Compose 部署 Kafka 3.8.0 集群,核心在于配置文件中控制器集群(CONTROLLER_QUORUM_VOTERS)、节点 ID、监听地址的正确设置,以及确保三节点网络互通。部署完成后,需通过创建 topic、生产消费消息验证集群功能,并根据压测结果优化资源配置,确保高可用和高性能。