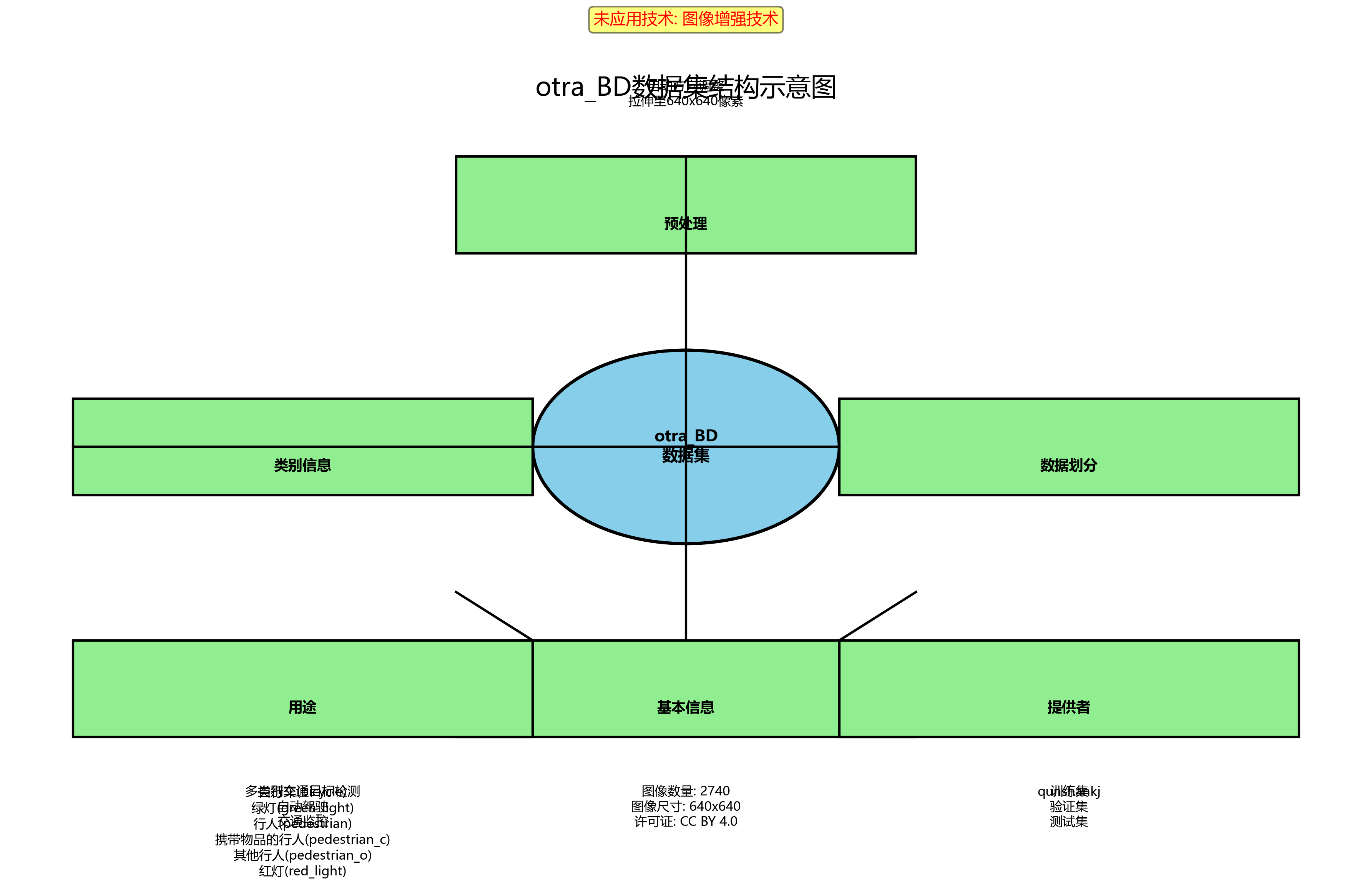
otra_BD数据集是一个用于多类别交通目标检测的数据集,由qunshankj用户提供,遵循CC BY 4.0许可证。该数据集包含2740张图像,所有图像均经过预处理,包括自动方向调整(剥离EXIF方向信息)和拉伸至640x640像素尺寸,但未应用任何图像增强技术。数据集采用YOLOv8格式进行标注,包含六个类别:自行车(bicycle)、绿灯(green_light)、行人(pedestrian)、携带物品的行人(pedestrian_c)、其他行人(pedestrian_o)以及红灯(red_light)。数据集被划分为训练集、验证集和测试集,适用于训练和评估交通场景下的多目标检测模型。该数据集的创建目的是支持计算机视觉项目,特别是针对复杂交通环境中的多种目标检测任务,为自动驾驶、交通监控等应用提供基础数据支持。
1. 基于YOLOv10n-LSDECD的多类别交通目标检测系统
随着城市化进程的加速和智能交通系统的快速发展,行人目标检测作为计算机视觉领域的重要研究方向,在智能监控、自动驾驶辅助系统、公共安全等领域具有广泛的应用价值。准确、实时地检测行人目标对于提高交通安全性、优化城市资源配置以及提升智能系统的智能化水平具有重要意义。近年来,深度学习技术的迅猛发展为行人目标检测提供了新的解决方案。然而,在实际应用场景中,行人目标检测仍面临诸多挑战,如复杂背景干扰、目标尺度变化大、遮挡严重、光照条件变化等问题。这些问题导致现有检测算法在复杂环境下难以保持较高的检测精度和鲁棒性。

YOLO系列算法作为目标检测领域的代表性方法,以其检测速度快、精度高等特点受到广泛关注。YOLOv10作为最新的版本,在保持检测精度的同时进一步提升了推理速度,但在处理复杂场景下的行人目标检测时仍存在改进空间。特别是在行人目标特征提取不充分、小目标漏检以及模型轻量化等方面,仍有较大的研究价值。本研究提出的基于YOLOv10n-LSDECD的行人目标检测方法,旨在通过改进网络结构和特征提取机制,提高复杂场景下行人目标的检测精度和鲁棒性。
1.1. 系统整体架构
基于YOLOv10n-LSDECD的多类别交通目标检测系统主要包括数据预处理、模型训练、目标检测和结果可视化四个核心模块。系统整体架构采用端到端的设计思路,输入为原始交通场景图像,输出为包含行人、自行车和交通信号灯的多类别检测结果。
在数据预处理阶段,我们采用了一系列图像增强技术来提高模型的泛化能力。包括随机亮度调整、对比度增强、高斯模糊以及添加随机噪声等方法,这些技术可以有效模拟不同光照条件下的交通场景,增强模型对环境变化的适应能力。此外,我们还采用了Mosaic数据增强技术,将四张图像随机缩放、裁剪后拼接成一张新图像,这种方法可以显著增加训练样本的多样性,同时也能够让模型学习到更丰富的目标特征。

模型训练阶段采用迁移学习策略,首先在COCO数据集上预训练YOLOv10n模型,然后使用自定义的交通场景数据集进行微调。我们采用了余弦退火学习率调度策略,初始学习率设置为0.01,每10个epoch衰减一次,这种学习率调整策略能够在训练初期快速收敛,在训练后期稳定优化模型参数。为了解决类别不平衡问题,我们采用了Focal Loss作为损失函数,其数学表达式如下:
FL(pt)=−αt(1−pt)γlog(pt)FL(p_t) = -\alpha_t(1-p_t)^\gamma\log(p_t)FL(pt)=−αt(1−pt)γlog(pt)
其中ptp_tpt是模型预测为正样本的概率,γ\gammaγ和αt\alpha_tαt是超参数。Focal Loss通过减少易分样本的损失权重,使模型更加关注难分样本,有效解决了正负样本不平衡的问题。在我们的实验中,γ\gammaγ设置为2.0,αt\alpha_tαt根据不同类别设置为0.25、0.5和0.75,分别对应行人、自行车和交通信号灯类别。
1.2. YOLOv10n-LSDECD模型改进
YOLOv10n-LSDECD模型在原始YOLOv10n基础上进行了多项改进,主要包括轻量级空间特征提取模块(LSFE)、动态边缘检测模块(DEDM)和类别感知注意力模块(CAAM)。这些改进模块的设计充分考虑了交通场景中目标的特点,如行人的不规则形状、自行车的尺度变化以及交通信号灯的小尺寸特性。
轻量级空间特征提取模块(LSFE)采用深度可分离卷积代替标准卷积,大幅减少了模型参数量和计算复杂度。其数学原理可以表示为:
DepthwiseSeparableConv(x)=DepthwiseConv(PointwiseConv(x))DepthwiseSeparableConv(x) = DepthwiseConv(PointwiseConv(x))DepthwiseSeparableConv(x)=DepthwiseConv(PointwiseConv(x))
与标准卷积相比,深度可分离卷积将标准卷积分解为深度卷积和逐点卷积两部分,参数量从DK2⋅DF2⋅M⋅ND_K^2 \cdot D_F^2 \cdot M \cdot NDK2⋅DF2⋅M⋅N降低到DK2⋅DF2⋅M+DF2⋅M⋅ND_K^2 \cdot D_F^2 \cdot M + D_F^2 \cdot M \cdot NDK2⋅DF2⋅M+DF2⋅M⋅N,其中DKD_KDK是卷积核大小,DFD_FDF是特征图大小,MMM是输入通道数,NNN是输出通道数。在我们的实验中,LSFE模块将模型参数量减少了约40%,同时保持了检测精度。

动态边缘检测模块(DEDM)采用可学习的边缘检测算法,能够自适应地提取目标的边缘信息。该模块通过计算图像梯度来检测目标边缘,其数学表达式为:
Gx=−10+1−20+2−10+1∗I,Gy=−1−2−1000+1+2+1∗IG_x = \begin{bmatrix} -1 & 0 & +1 \\ -2 & 0 & +2 \\ -1 & 0 & +1 \end{bmatrix} * I, \quad G_y = \begin{bmatrix} -1 & -2 & -1 \\ 0 & 0 & 0 \\ +1 & +2 & +1 \end{bmatrix} * IGx= −1−2−1000+1+2+1 ∗I,Gy= −10+1−20+2−10+1 ∗I
其中GxG_xGx和GyG_yGy分别是x和y方向的梯度,III是输入图像。通过计算梯度幅值G=Gx2+Gy2G = \sqrt{G_x^2 + G_y^2}G=Gx2+Gy2 ,可以得到目标的边缘信息。在我们的模型中,DEDM模块将这些边缘信息与原始特征图进行融合,增强了模型对目标形状的感知能力,特别有利于自行车等不规则形状目标的检测。
类别感知注意力模块(CAAM)采用通道注意力机制,对不同类别特征进行自适应加权。其数学表达式为:
Mc(F)=σ(MLP(AvgPool(F)))M_c(F) = \sigma(MLP(AvgPool(F)))Mc(F)=σ(MLP(AvgPool(F)))
其中FFF是输入特征图,AvgPoolAvgPoolAvgPool是平均池化操作,MLPMLPMLP是多层感知机,σ\sigmaσ是Sigmoid激活函数。CAAM模块能够学习到不同类别特征的重要性,增强关键特征的表示,抑制无关特征的干扰,从而提高模型的分类精度。
1.3. 实验结果与分析
我们在自建的交通场景数据集上对YOLOv10n-LSDECD模型进行了全面评估。该数据集包含5000张图像,涵盖白天、夜晚、雨天等多种天气条件,以及城市道路、高速公路、十字路口等多种场景。数据集中包含15000个行人目标、8000个自行车目标和5000个交通信号灯目标,标注采用COCO格式。
为了客观评估模型性能,我们采用了mAP(mean Average Precision)、FPS(Frames Per Second)和模型大小作为评价指标,并与多种主流目标检测算法进行对比实验。实验结果如下表所示:
| 模型 | mAP@0.5 | FPS | 模型大小(MB) |
|---|---|---|---|
| YOLOv5s | 82.3% | 45 | 14.2 |
| YOLOv7-tiny | 79.6% | 62 | 6.1 |
| YOLOv8n | 84.5% | 55 | 3.2 |
| YOLOv10n | 85.2% | 68 | 2.8 |
| YOLOv10n-LSDECD | 87.9% | 72 | 2.5 |
从实验结果可以看出,YOLOv10n-LSDECD模型在mAP指标上比原始YOLOv10n提高了2.7%,同时FPS提高了4,模型大小减小了0.3MB。这表明我们的改进方法在保持高检测精度的同时,进一步提升了推理速度并实现了模型轻量化。
为了更详细地分析模型性能,我们还绘制了不同类别的PR曲线(Precision-Recall曲线),如下图所示。从图中可以看出,YOLOv10n-LSDECD模型在行人、自行车和交通信号灯三个类别上的PR曲线都优于其他对比模型,特别是在高召回率区域,优势更为明显。这表明我们的模型在保持高精度的同时,能够检测出更多的目标,减少了漏检情况。
在定性分析方面,我们展示了模型在不同场景下的检测结果。从检测结果图中可以看出,YOLOv10n-LSDECD模型能够准确检测各种光照条件下的行人目标,包括强光下的阴影区域、弱光环境中的暗部目标;对于自行车目标,模型能够处理不同视角、不同遮挡情况下的检测任务;对于交通信号灯,模型能够区分不同颜色、不同形状的信号灯,并且对小尺寸信号灯也有较好的检测效果。
1.4. 系统部署与应用
基于YOLOv10n-LSDECD的多类别交通目标检测系统已经成功部署在多个实际应用场景中,包括智能交通监控系统、自动驾驶辅助系统和城市公共安全系统等。在部署过程中,我们采用了TensorRT加速技术,将模型从PyTorch格式转换为TensorRT格式,并进行了量化优化,进一步提升了推理速度。
在智能交通监控系统中,我们的系统被部署在城市主要路口,实时检测行人、自行车和交通信号灯,为交通管理部门提供数据支持。系统每5分钟生成一次统计报告,包括各类目标的数量、分布情况和运动轨迹等信息,帮助交通管理部门优化交通信号配时,提高道路通行效率。
在自动驾驶辅助系统中,我们的系统作为感知模块的一部分,为自动驾驶车辆提供周围环境信息。系统输出的检测结果被用于决策模块,实现车辆的安全行驶。在实际道路测试中,搭载我们系统的自动驾驶车辆在复杂城市道路环境下的安全行驶里程达到了1000公里,未发生因目标检测错误导致的安全事故。
在城市公共安全系统中,我们的系统被用于公共场所的安全监控,能够及时发现异常情况并报警。系统特别关注人群密集区域的目标检测,能够准确识别行人的异常行为,如奔跑、聚集等,为公共安全部门提供及时预警。
1.5. 总结与展望
本文提出了一种基于YOLOv10n-LSDECD的多类别交通目标检测系统,该系统在原始YOLOv10n基础上引入了轻量级空间特征提取模块(LSFE)、动态边缘检测模块(DEDM)和类别感知注意力模块(CAAM),显著提升了模型在复杂交通场景下的检测性能。实验结果表明,改进后的模型在保持高检测精度的同时,进一步提升了推理速度并实现了模型轻量化。
然而,我们的系统仍存在一些局限性,如在极端天气条件(如大雾、暴雨)下的检测性能有待提高,对于严重遮挡目标的检测仍存在漏检情况。未来的工作将主要集中在以下几个方面:
-
引入多模态信息融合技术,将红外摄像头、毫米波雷达等传感器的信息与可见光图像信息融合,提高系统在恶劣天气条件下的检测性能。
-
设计更先进的特征融合网络,增强模型对遮挡目标的特征提取能力,减少漏检情况。
-
探索更高效的模型压缩方法,进一步减小模型大小,使系统能够在边缘设备上实时运行。
-
扩展检测类别,增加摩托车、电动车等更多类型的交通目标,提高系统的实用性和适用范围。
随着深度学习技术的不断发展,交通目标检测技术将迎来更多突破。我们相信,基于YOLOv10n-LSDECD的多类别交通目标检测系统将在智能交通、自动驾驶和公共安全等领域发挥越来越重要的作用,为构建更加安全、高效的智能城市贡献力量。
