怎么判断为加速乐
删除cookie或用无痕模式打开会发送三个请求,其中前两个请求为521,最后一个为200

且第一个会set-cookie __jsluid_s
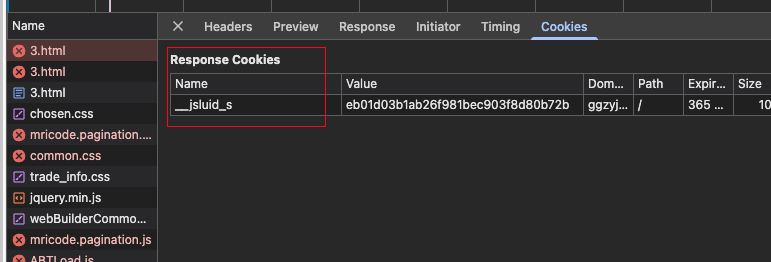
第二个请求需要传递两个参数
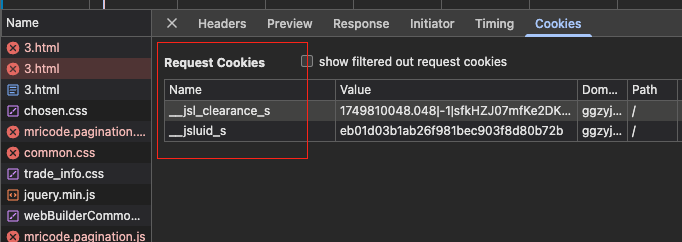
这种格式就可以判断为加速乐反爬
加速乐逆向过程
数据获取分为3次请求, 第一次请求获取两个参数, 第二次请求需要携带这两个参数请求,会得到一段js代码,这段js代码会覆盖对第一次请求获取到的其中一个参数,得到最后的结果,后续我们只需要携带这两个参数进行请求就可以获取到数据了
第一次请求我们需要获取到__jsluid_s和__jsl_clearance_s 其中__jsluid_s在响应表头中,直接提取即可
print(response.headers['Set-Cookie']) # 运行结果 # __jsluid_s=83b70696e03a23757557106ac9d2df52; max-age=31536000; path=/; HttpOnly; SameSite=None; secure
而__jsl_clearance_s 在 响应结果
第一次请求响应结果
<script>document.cookie=('_')+('_')+('j')+('s')+('l')+('_')+('c')+('l')+('e')+('a')+('r')+('a')+('n')+('c')+('e')+('_')+('s')+('=')+((+true)+'')+(2+5+'')+(-~(4)+'')+(1+3+'')+(([2]+0>>2)+'')+((1+[2]>>2)+'')+(-~(3)+'')+(9+'')+(+!+[]+'')+(-~false+'')+('.')+(+!+[]*2+'')+((1+[2])/[2]+'')+(-~0+'')+('|')+('-')+(-~[]+'')+('|')+('d')+('k')+('P')+(1+6+'')+('c')+('p')+('X')+('G')+('K')+(4+'')+('Y')+('p')+('%')+(+!+[]*2+'')+('F')+('e')+('f')+('t')+('f')+('v')+('e')+('w')+('i')+([2]*(3)+'')+((1+[2]>>2)+'')+('R')+('F')+('N')+('k')+('%')+((2^1)+'')+('D')+(';')+(' ')+('M')+('a')+('x')+('-')+('a')+('g')+('e')+('=')+(1+2+'')+(2+4+'')+((+[])+'')+(~~[]+'')+(';')+(' ')+('P')+('a')+('t')+('h')+('=')+('/')+(';')+(' ')+('S')+('a')+('m')+('e')+('S')+('i')+('t')+('e')+('=')+('N')+('o')+('n')+('e')+(';')+(' ')+('S')+('e')+('c')+('u')+('r')+('e');location.href=location.pathname+location.search</script>
响应状态
<Response [521]>
我们需要从<script> 标签中提取 document.cookie 的赋值内容,并使用execjs库获得执行结果,即为__jsl_clearance_s的值
这个正则表达式可以精确地捕获从 document.cookie= 之后到第一个分号 ; 之前的所有内容
python
document\.cookie=(.*?);location
js_code = response.text
match = re.search("document\.cookie=(.*?);location", js_code)
cookies_js = match.group(1)
cookie = execjs.eval(cookies_js)
print(cookie)
# 运行结果
# __jsl_clearance_s=1754536678.211|-1|OM8cgyRTMeBQNNWb%2B1NuLaJkAR8%3D; Max-age=3600; Path=/; SameSite=None; Secure第二次请求我们需要带着这两个cookie请求, 然后得到它返回的js
这段js的核心内容是go函数, go函数的大概原理是从chars中选两个字符拼接在bts的两个字符串中间,再使用ha的加密算法与ct的值进行判断,当某两个chars的的运行结果匹配时,那么拼接后的最后结果就是加工后的__jsl_clearance_s参数的值
我们在这里将它转化为对应的python代码
python
def go(data):
chars = data["chars"]
for i in chars:
for j in chars:
cookie = data["bts"][0] + i + j + data["bts"][1]
if data['ha'] == 'md5':
encrypt = md5()
elif data['ha'] == 'sha1':
encrypt = sha1()
elif data['ha'] == 'sha256':
encrypt = sha256()
encrypt.update(cookie.encode(encoding='utf-8'))
if encrypt.hexdigest() == data['ct']:
return cookie最后,我们携带着__jsluid_s和__jsl_clearance_s这两个参数再次访问网址就可以拿到数据了
如果遇到的jsl较为特殊或者进行了魔改, 可以使用下面的代码根据实际情况进行修改
get类型
python
import json
import re
import execjs
import requests
from hashlib import md5, sha1, sha256
def go(data):
chars = data["chars"]
for i in chars:
for j in chars:
cookie = data["bts"][0] + i + j + data["bts"][1]
if data['ha'] == 'md5':
encrypt = md5()
elif data['ha'] == 'sha1':
encrypt = sha1()
elif data['ha'] == 'sha256':
encrypt = sha256()
encrypt.update(cookie.encode(encoding='utf-8'))
if encrypt.hexdigest() == data['ct']:
return cookie
def jsl(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36',
}
response = requests.get(url, headers=headers)
cookie = response.headers['Set-Cookie'].split(';')[0].split('=')
cookies = {cookie[0]: cookie[1]}
cookie = re.findall(r'(cookie=.*?)location', response.text)[0]
js_code = "function get_cookies(){"+cookie+"return cookie}"
cookie = execjs.compile(js_code).call('get_cookies').split(';')[0].split('=')
cookies.update({cookie[0]: cookie[1]})
response = requests.get(url, cookies=cookies, headers=headers)
jsl = go(json.loads(re.findall(r'go\((.*?)\)', response.text)[1]))
cookies["__jsl_clearance_s"] = jsl
# return cookies
response = requests.get(url, headers=headers, cookies=cookies)
print(response.text)
print(response)
return response
if __name__ == '__main__':
jsl("https://ggzyjyzx.tl.gov.cn/jyxx/trade_info.html")post类型
python
import json
import re
import execjs
import requests
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/137.0.0.0 Safari/537.36",
}
cookies = {
}
url = "https://ggzyjyzx.tl.gov.cn/EpointWebBuilder/rest/secaction/getSecInfoListYzm"
data = {
"siteGuid": "7eb5f7f1-9041-43ad-8e13-8fcb82ea831a",
"categoryNum": "003006",
"content": "",
"pageIndex": "1",
"pageSize": "10",
"YZM": "",
"ImgGuid": "",
"startdate": "",
"enddate": "",
"xiaqucode": "",
"hytype": "",
"zhaobiaofangshi": ""
}
response = requests.post(url, headers=headers, cookies=cookies, data=data)
print(response)
if response.status_code == 200:
print(response.json())
else:
// go函数使用 get类型中的
from jsl import go
response = requests.get(url, headers=headers)
cookie = response.headers['Set-Cookie'].split(';')[0].split('=')
jsl_cookies = {cookie[0]: cookie[1]}
cookie = re.findall(r'(cookie=.*?)location', response.text)[0]
js_code = "function get_cookies(){" + cookie + "return cookie}"
cookie = execjs.compile(js_code).call('get_cookies').split(';')[0].split('=')
jsl_cookies.update({cookie[0]: cookie[1]})
response = requests.get(url, cookies=jsl_cookies, headers=headers)
jsl = go(json.loads(re.findall(r'go\((.*?)\)', response.text)[1]))
jsl_cookies["__jsl_clearance_s"] = jsl
print(f"jsl_cookies: {jsl_cookies}")
cookies.update(jsl_cookies)
response = requests.post(url, headers=headers, cookies=cookies, data=data)
print(response)
print(response.text)