LLM知识随笔(二)--BERT
文章目录
- LLM知识随笔(二)--BERT
- 一、BERT:公认的里程碑
-
- [1. BERT与GPT之间的区别:](#1. BERT与GPT之间的区别:)
- 2.单向编码与双向编码的区别
- 二、BERT的结构:强大的特征提取能力
-
- 1.ELMo、GPT、BERT三者区别
- 2.BERT的模型结构
- [3.BERT 之无监督训练](#3.BERT 之无监督训练)
- [4.BERT 之语言掩码模型(MLM)](#4.BERT 之语言掩码模型(MLM))
- [5.BERT 之下句预测(NSP)](#5.BERT 之下句预测(NSP))
-
- [5.1 为何引入下句预测?](#5.1 为何引入下句预测?)
- [5.2 具体做法](#5.2 具体做法)
- [5.2 作用](#5.2 作用)
- [6.BERT 之输入表示](#6.BERT 之输入表示)
- [三、BERT 下游任务改造](#三、BERT 下游任务改造)
- 总结
一、BERT:公认的里程碑
地位 :公认的里程碑式模型
最大的优点 :最大的优点不是创新,而是集大成者
意义 :从大量无标记数据集中训练得到的深度模型,可以显著提高各项自然语言处理任务的准确率。
如何成为集大成者:参考ELMO 模型的双向编码思想 + 借鉴GPT 用 Transformer 作为特征提取器的思路 + 采用word2vec 所使用的 CBOW 方法
1. BERT与GPT之间的区别:
| GPT | BERT |
|---|---|
| 使用 Transformer Decoder 作为特征提取器、具有良好的文本生成能力 | 使用了 Transformer Encoder 作为特征提取器 + 与其配套的掩码训练方法 |
| 当前词的语义只能由其前序词决定,并且在语义理解上不足 | 虽然使用双向编码让 BERT 不再具有文本生成能力,但是 BERT 的语义信息提取能力更强 |
2.单向编码与双向编码的区别
| 单向编码 | 双向编码 |
|---|---|
| 只会考虑 "今天天气很",以人类的经验,大概率会从 "好"、"不错"、"差"、"糟糕" 这几个词中选择,这些词可以被划为截然不同的两类 | 会同时考虑上下文的信息,即除了会考虑 "今天天气很" 这五个字,还会考虑 "我们不得不取消户外运动" 来帮助模型判断,则大概率会从 "差"、"糟糕" 这一类词中选择 |
二、BERT的结构:强大的特征提取能力
1.ELMo、GPT、BERT三者区别
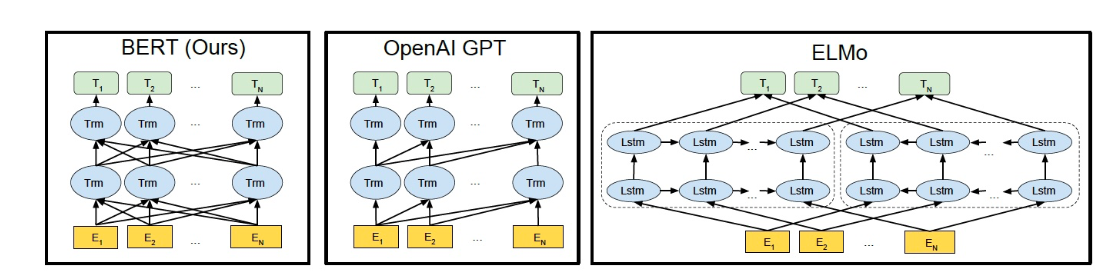
| ELMo | GPT | BERT | |
|---|---|---|---|
| 网络 | 使用自左向右编码和自右向左编码的两个 LSTM 网络 | 使用 Transformer Decoder 作为 Transformer Block | 使用 Transformer Encoder 作为 Transformer Block,并且将 GPT 的单向编码改成双向编码 |
| 目标函数 | 分别以 P ( w i ∣ w 1 , ... , w i − 1 ) P(w_i \mid w_1, \ldots, w_{i-1}) P(wi∣w1,...,wi−1) 和 P ( w i ∣ w i + 1 , ... , w n ) P(w_i \mid w_{i+1}, \ldots, w_n) P(wi∣wi+1,...,wn)为目标函数独立训练 | 以 P ( w i ∣ w 1 , ... , w i − 1 ) P(w_i \mid w_1, \ldots, w_{i-1}) P(wi∣w1,...,wi−1)为目标函数进行训练 | 以 P ( w i ∣ w 1 , ... , w i − 1 , w i + 1 . . . , w n ) P(w_i \mid w_1, \ldots, w_{i-1},w_{i+1}...,w_n) P(wi∣w1,...,wi−1,wi+1...,wn)为目标函数进行训练 |
| 编码方式 | 得到的特征向量以拼接的形式实现双向编码,本质上还是单向编码,只不过是两个方向上的单向编码的拼接而成的双向编码 | 用 Transformer Block 取代 LSTM 作为特征提取器,实现了单向编码 | 双向编码器 |
| 其他 | 是一个标准的预训练语言模型,即使用 Fine-Tuning 模式解决下游任务 | BERT 舍弃了文本生成能力,换来了更强的语义理解能力 |
2.BERT的模型结构
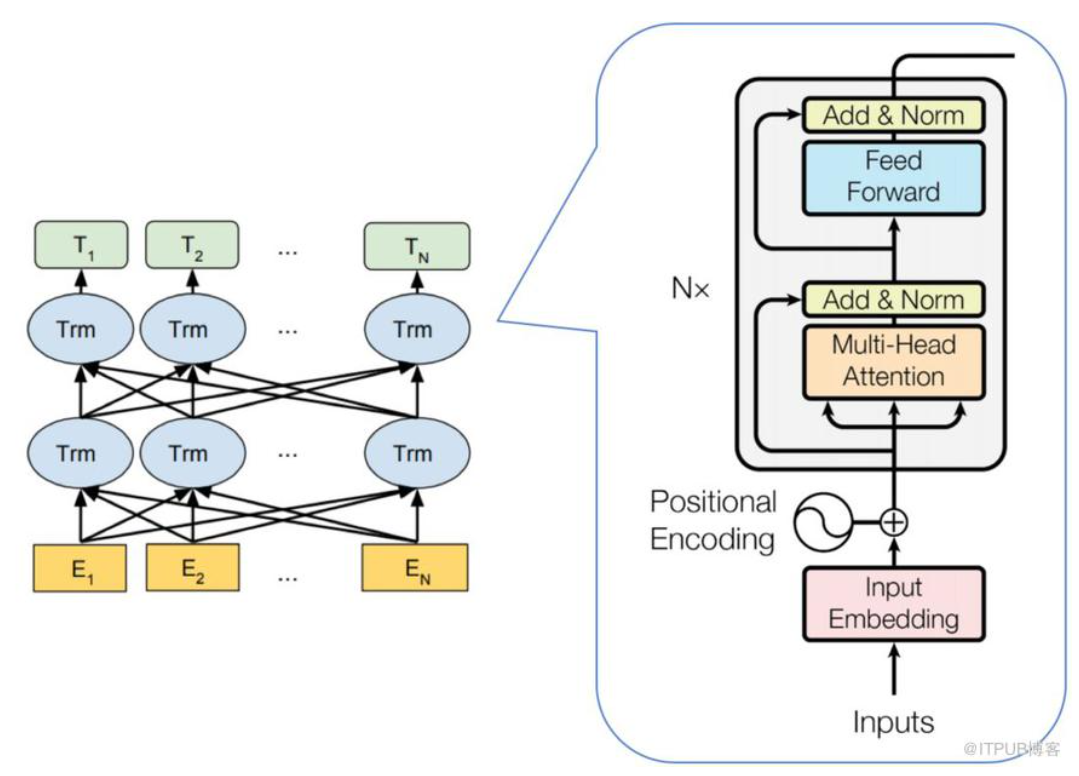
从上图可以发现,BERT 的模型结构其实就是 Transformer Encoder 模块的堆叠。在模型参数选择上,论文给出了两套大小不一致的模型。
BERTBASE: L = 12,H = 768,A = 12,总参数量为 1.1 亿
BERTLARGE: L = 24,H = 1024,A = 16,总参数量为 3.4 亿
其中 L 代表 Transformer Block 的层数;H 代表特征向量的维数(此处默认 Feed Forward 层中的中间隐层的维数为 4H);A 表示 Self-Attention 的头数,使用这三个参数基本可以定义 BERT的量级。
BERT 参数量级的计算公式:

训练过程也是很花费计算资源和时间
3.BERT 之无监督训练
BERT 采用二段式训练方法:
- 第一阶段: 使用易获取的大规模无标签余料,来训练基础语言模型
- 第二阶段:根据指定任务的少量带标签训练数据进行微调训练。
训练方式:
| 语义理解能力 | 句子之间的理解能力 |
|---|---|
| 用语言掩码模型(MLM)方法训练 | 用下句预测(NSP)方法训练 |
4.BERT 之语言掩码模型(MLM)
BERT选用深度双向编码器原因:作者认为,使用自左向右编码和自右向左编码的单向编码器拼接而成的双向编码器,在性能、参数规模和效率等方面,都不如直接使用深度双向编码器强大。
由于无法使用标准语言模型的训练模式,BERT 借鉴完形填空任务和 CBOW 的思想,使用语言掩码模型(MLM )方法训练模型。
| 名称 | 解释 |
|---|---|
| BERT 借鉴完形填空任务和 CBOW 的思想 | 使用语言掩码模型(MLM )方法训练模型 |
| MLM 方法 | 随机去掉句子中的部分 token(单词),然后模型来预测被去掉的 token 是什么。这样实际上已经不是传统的神经网络语言模型(类似于生成模型)了,而是单纯作为分类问题,根据这个时刻的 hidden state 来预测这个时刻的 token 应该是什么,而不是预测下一个时刻的词的概率分布了。 |
| 掩码词 | 随机去掉的 token |
在训练中,掩码词将以 15% 的概率被替换成 MASK,也就是说随机 mask 语料中 15% 的 token,这个操作则称为掩码操作。注意:在CBOW 模型中,每个词都会被预测一遍。
在训练中,掩码词将以 15% 的概率被替换成 MASK,也就是说随机 mask 语料中 15% 的 token,这个操作则称为掩码操作。
❗注意:在CBOW 模型中,每个词都会被预测一遍。
这样设计 MLM 的训练方法会引入弊端 :在模型微调训练阶段或模型推理(测试)阶段,输入的文本中将没有 MASK,进而导致产生由训练和预测数据偏差导致的性能损失。
👇
解决方法:
BERT 并没有总用 MASK 替换掩码词,而是按照一定比例选取替换词。在选择 15% 的词作为掩码词后这些掩码词有三类替换选项
- 80% 训练样本中:将选中的词用 MASK 来代替,例如:
python
"地球是[MASK]八大行星之一"- 10% 的训练样本中:选中的词不发生变化,该做法是为了缓解训练文本和预测文本的偏差带来的性能损失,例如:
python
"地球是太阳系八大行星之一"- 10% 的训练样本中:将选中的词用任意的词来进行代替,该做法是为了让 BERT 学会根据上下文信息自动纠错,例如:
"地球是苹果八大行星之一"
这么做的好处?
编码器不知道哪些词需要预测的,哪些词是错误的,因此被迫需要学习每一个 token 的表示向量,另外作者也表示双向编码器比单项编码器训练要慢,进而导致BERT 的训练效率低了很多,但是实验也证明 MLM 训练方法可以让 BERT 获得超出同期所有预训练语言模型的语义理解能力,牺牲训练效率是值得的。
5.BERT 之下句预测(NSP)
5.1 为何引入下句预测?
在很多自然语言处理的下游任务中,如问答和自然语言推断,都基于两个句子做逻辑推理,而语言模型并不具备直接捕获句子之间的语义联系的能力,或者可以说成单词预测粒度的训练到不了句子关系这个层级,为了学会捕捉句子之间的语义联系,BERT 采用了下句预测(NSP )作为无监督预训练的一部分。
5.2 具体做法
BERT 输入的语句将由两个句子构成,其中,50% 的概率将语义连贯的两个连续句子作为训练文本(连续句对一般选自篇章级别的语料,以此确保前后语句的语义强相关),另外 50% 的概率将完全随机抽取两个句子作为训练文本。
连续句对:CLS今天天气很糟糕SEP下午的体育课取消了SEP
随机句对:CLS今天天气很糟糕SEP鱼快被烤焦啦SEP
SEP 标签表示分隔符。
CLS 表示标签用于类别预测,结果为 1,表示输入为连续句对;结果为 0,表示输入为随机句对。
5.2 作用
通过训练 CLS 编码后的输出标签,BERT 可以学会捕捉两个输入句对的文本语义,在连续句对的预测任务中,BERT 的正确率可以达到 97%-98%。
6.BERT 之输入表示
BERT 在预训练阶段 使用了前文所述的两种训练方法,在真实训练中一般是两种方法混合使用。
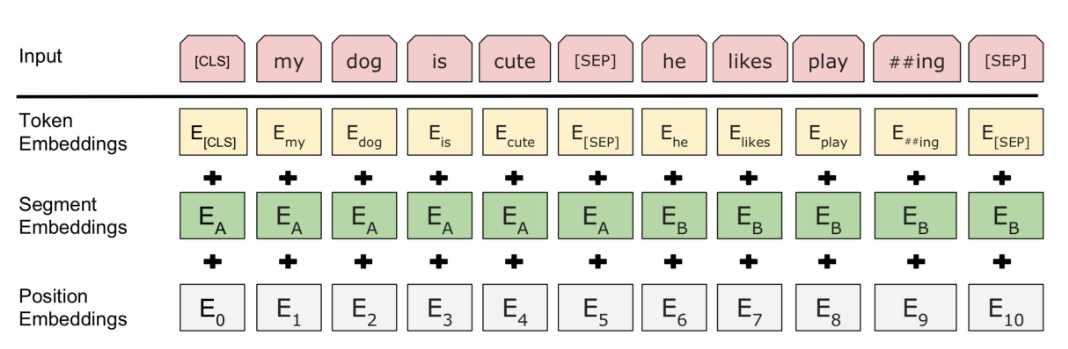
由于 BERT 通过 Transformer 模型堆叠而成,所以 BERT 的输入需要两套 Embedding 操作:
- 第一套: One-hot 词表映射编码(对应下图的 Token Embeddings);
- 第二套: 位置编码(对应下图的 Position Embeddings)。不同于 Transformer 的位置编码用三角函数表示,BERT 的位置编码将在预训练过程中训练得到(训练思想类似于Word Embedding 的 Q 矩阵)
- 额外的一套:由于在 MLM 的训练过程中,存在单句输入和双句输入的情况,因此 BERT 还需要一套区分输入语句的分割编码(对应下图的 Segment Embeddings),BERT 的分割编码也将在预训练过程中训练得到
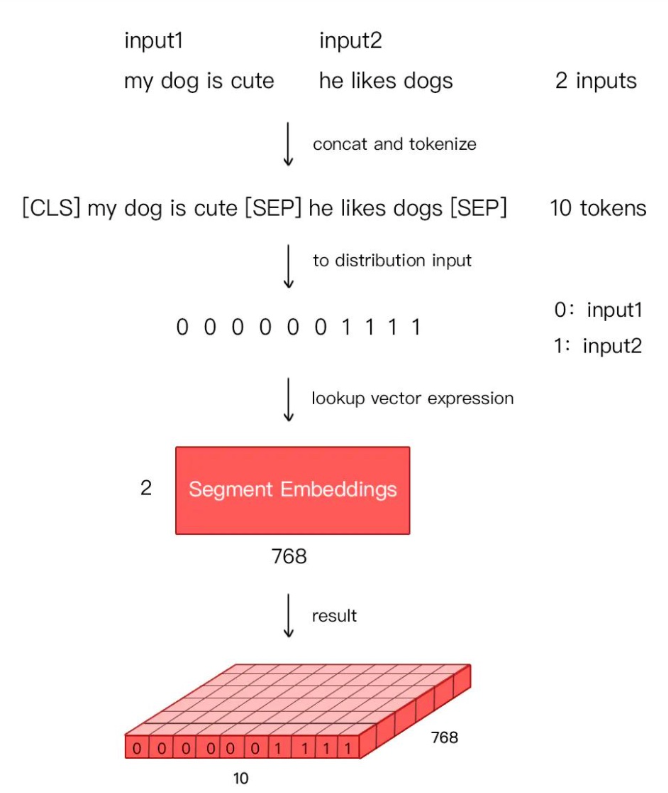
对于分割编码,Segment Embeddings 层只有两种向量表示。前一个向量是把 0 赋给第一个句子中的各个 token,后一个向量是把 1 赋给第二个句子中的各个 token 。如果输入仅仅只有一个句子,那么它的 segment embedding 就是全 0,下面我们简单举个例子描述下:
CLSI like dogsSEPI like catsSEP 对应编码 0 0 0 0 0 1 1 1 1
SEPI Iike dogs and catsSEP 对应编码 0 0 0 0 0 0 0
三、BERT 下游任务改造
BERT 根据自然语言处理下游任务的输入和输出的形式,将微调训练支持的任务 分为四类: 句对分类、单句分类、文本问答和单句标注
接下来我们将简要的介绍下 BERT 如何通过微调训练适应这四类任务的要求。
1.句对分类
定义:给定两个句子,判断它们的关系,称为句对分类。(例如判断句对是否相似、判断后者是否为前者的答案)
针对句对分类任务
BERT 在预训练过程中就使用了 NSP 训练方法 获得了直接捕获句对语义关系的能力。
如下图所示,句对用 SEP 分隔符拼接成文本序列,在句首加入标签 CLS,将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。
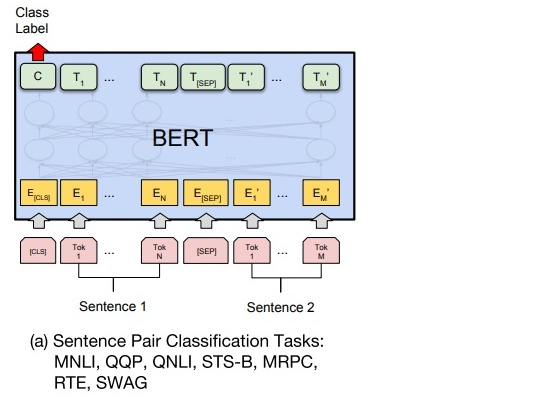
针对二分类任务
BERT 不需要对输入数据和输出数据的结构做任何改动,直接使用与 NSP 训练方法一样的输入和输出结构就行。
针对多分类任务
需要在句首标签 CLS 的输出特征向量后接一个全连接层和 Softmax 层,保证输出维数与类别数目一致,最后通过 arg max 操作(取最大值时对应的索引序号)得到相对应的类别结果。
任务:判断句子 "我很喜欢你" 和句子 "我很中意你" 是否相似
输入改写:"CLS我很喜欢你SEP我很中意你"
取 "CLS" 标签对应输出:0.02, 0.98
通过 arg max 操作得到相似类别为 1(类别索引从 0 开始),即两个句子相似
2.单句分类
定义:给定一个句子,判断该句子的类别,统称为单句分类。(例如判断情感类别、判断是否为语义连贯的句子)
①针对单句二分类任务
无须对 BERT 的输入数据和输出数据的结构做任何改动。
如下图所示,单句分类在句首加入标签 CLS,将句首标签所对应的输出值作为分类标签,计算预测分类标签与真实分类标签的交叉熵,将其作为优化目标,在任务数据上进行微调训练。
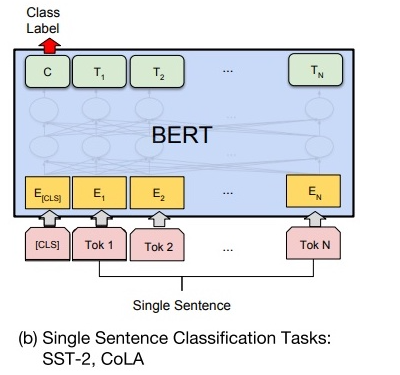
②针对多分类任务
需要在句首标签 CLS 的输出特征向量后接一个全连接层和 Softmax 层,保证输出维数与类别数目一致,最后通过 argmax 操作得到相对应的类别结果。
下面给出语义连贯性判断任务的实例:
任务:判断句子"海大球星饭茶吃" 是否为一句话
输入改写:"CLS海大球星饭茶吃"
取 "CLS" 标签对应输出:0.99, 0.01
通过 arg max 操作得到相似类别为 0,即这个句子不是一个语义连贯的句子
3.文本问答
定义:给定一个问句和一个蕴含答案的句子,找出答案在后这种的位置,称为文本问答(例如给定一个问题(句子 A),在给定的段落(句子 B)中标注答案的其实位置和终止位置。)
文本问答任何和前面讲的其他任务有较大的差别,无论是在优化目标上,还是在输入数据和输出数据的形式上,都需要做一些特殊的处理。
为了标注答案的起始位置和终止位置,BERT 引入两个辅助向量 s(start,判断答案的起始位置) 和 e(end,判断答案的终止位置)。
3.1 BERT 判断句子 B 中答案位置的做法
如下图所示,BERT 判断句子 B 中答案位置的做法👇
将句子 B 中的每一个次得到的最终特征向量 T i ′ T_{i}^{'} Ti′经过全连接层(利用全连接层将词的抽象语义特征转化为任务指向的特征)后,分别与向量 s 和 e 求内积,对所有内积分别进行 softmax 操作,即可得到词 Tok m(m∈1,M)作为答案其实位置和终止位置的概率。最后,去概率最大的片段作为最终的答案。
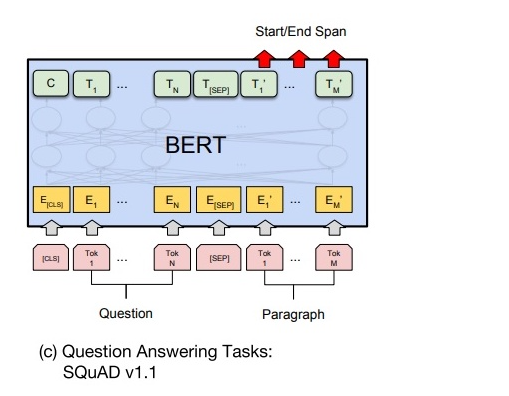
3.2 文本回答任务的微调训练使用的两个技巧
① 用全连接层把 BERT 提取后的深层特征向量转化为用于判断答案位置的特征向量
② 引入辅助向量 s 和 e 作为答案其实位置和终止位置的基准向量,明确优化目标的方向和度量方法
下面给出文本问答任务的实例:
任务:给定问句 "今天的最高温度是多少",在文本 "天气预报显示今天最高温度 37 摄氏度" 中标注答案的起始位置和终止位置
输入改写:"CLS今天的最高温度是多少SEP天气预报显示今天最高温度 37 摄氏度"
BERT Softmax 结果:
| 篇章文本 | 天气 | 预报 | 显示 | 今天 | 最高温 | 37 | 摄氏度 |
|---|---|---|---|---|---|---|---|
| 起始位置概率 | 0.01 | 0.01 | 0.01 | 0.04 | 0.10 | 0.80 | 0.03 |
| 终止位置概率 | 0.01 | 0.01 | 0.01 | 0.03 | 0.04 | 0.10 | 0.80 |
对 Softmax 的结果取 arg max,得到答案的起始位置为 6,终止位置为 7,即答案为 "37 摄氏度"
4.单句标注
定义:给定一个句子,标注每个次的标签,称为单句标注。(例如给定一个句子,标注句子中的人名、地名和机构名。)
单句标注任务和 BERT 预训练任务具有较大差异,但与文本问答任务较为相似。
如下图所示,在进行单句标注任务时,需要在每个词的最终语义特征向量之后添加全连接层,将语义特征转化为序列标注任务所需的特征,单句标注任务需要对每个词都做标注,因此不需要引入辅助向量,直接对经过全连接层后的结果做 Softmax 操作,即可得到各类标签的概率分布。
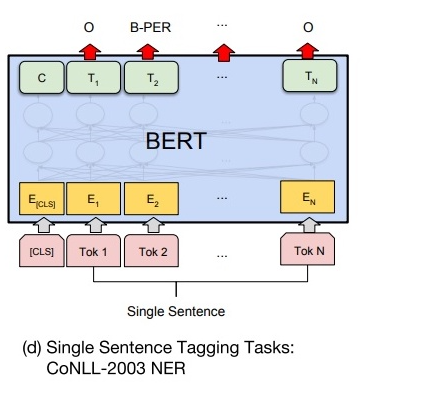
由于 BERT 需要对输入文本进行分词操作,独立词将会被分成若干子词,因此 BERT 预测的结果将会是 5 类(细分为 13 小类):
- O(非人名地名机构名,O 表示 Other)
- B-PER/LOC/ORG(人名/地名/机构名初始单词,B 表示 Begin)
- I-PER/LOC/ORG(人名/地名/机构名中间单词,I 表示 Intermediate)
- E-PER/LOC/ORG(人名/地名/机构名终止单词,E 表示 End)
- S-PER/LOC/ORG(人名/地名/机构名独立单词,S 表示 Single)
将 5 大类的首字母结合,可得 IOBES,这是序列标注最常用的标注方法。
下面给出命名实体识别(NER)任务的示例:
任务:给定句子 "爱因斯坦在柏林发表演讲",根据 IOBES 标注 NER 结果
输入改写:"CLS爱 因 斯坦 在 柏林 发表 演讲"
BERT Softmax 结果:
| BOBES | 爱 | 因 | 斯坦 | 在 | 柏林 | 发表 | 演讲 |
|---|---|---|---|---|---|---|---|
| O | 0.01 | 0.01 | 0.01 | 0.90 | 0.01 | 0.90 | 0.90 |
| B-PER | 0.90 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 |
| I-PER | 0.01 | 0.90 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 |
| E-PER | 0.01 | 0.01 | 0.90 | 0.01 | 0.01 | 0.01 | 0.01 |
| S-LOC | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 | 0.01 |
对 Softmax 的结果取 arg max,得到最终地 NER 标注结果为:"爱因斯坦" 是人名;"柏林" 是地名
总结
BERT最大的亮点在于效果好及普适性强,几乎所有 NLP 任务都可以套用 Bert 这种两阶段解决思路,而且效果应该会有明显提升。