音频 AI 训练模型对高质量、多样化的音频数据需求极高,而 SoundCloud 是全球最大的音频分享社区之一,包含数百万曲目和丰富的元数据,是进行音频分析、生成和增强等任务的理想来源。然而,由于 SoundCloud 的动态内容渲染、API 限制和风控策略,如何安全高效地抓取和利用这些数据成为一项工程挑战。
在这篇完整指南中,我们将讨论抓取 SoundCloud 数据涉及的合规背景、技术策略、关键难点以及如何利用代理构建稳定、可扩展的数据采集管道。

1. 为什么选择 SoundCloud 作为数据源?
SoundCloud 平台拥有多样化的内容类型:
-
各类独立音乐、电子作品、播客等,覆盖广泛的音频风格和质量;
-
每首作品都携带丰富的元数据,如艺术家、播放量、标签等;
-
社区生成的播放列表、分类标签等可以帮助构建更结构化的数据集;
-
部分创作者使用 Creative Commons 等开放授权,为研究提供更安全的使用空间。
这些特点让 SoundCloud 成为构建高质量 AI 训练集尤其是音乐生成、音频分类和音频增强任务的优质数据源。
2. 抓取SoundCloud数据前必须知道的规则与限制
2.1 API Rate Limits
SoundCloud 官方 API 对请求频率有明确限制,例如对可播放流的请求在每 24 小时窗口内存在最大阈值。超过限制会返回 HTTP 429 Too Many Requests 的错误响应,表明已经达到调用上限。
即使不使用官方 API,模仿用户行为访问站点也可能遇到相似的限流,尤其是在短时间内对大量页面发起请求时。
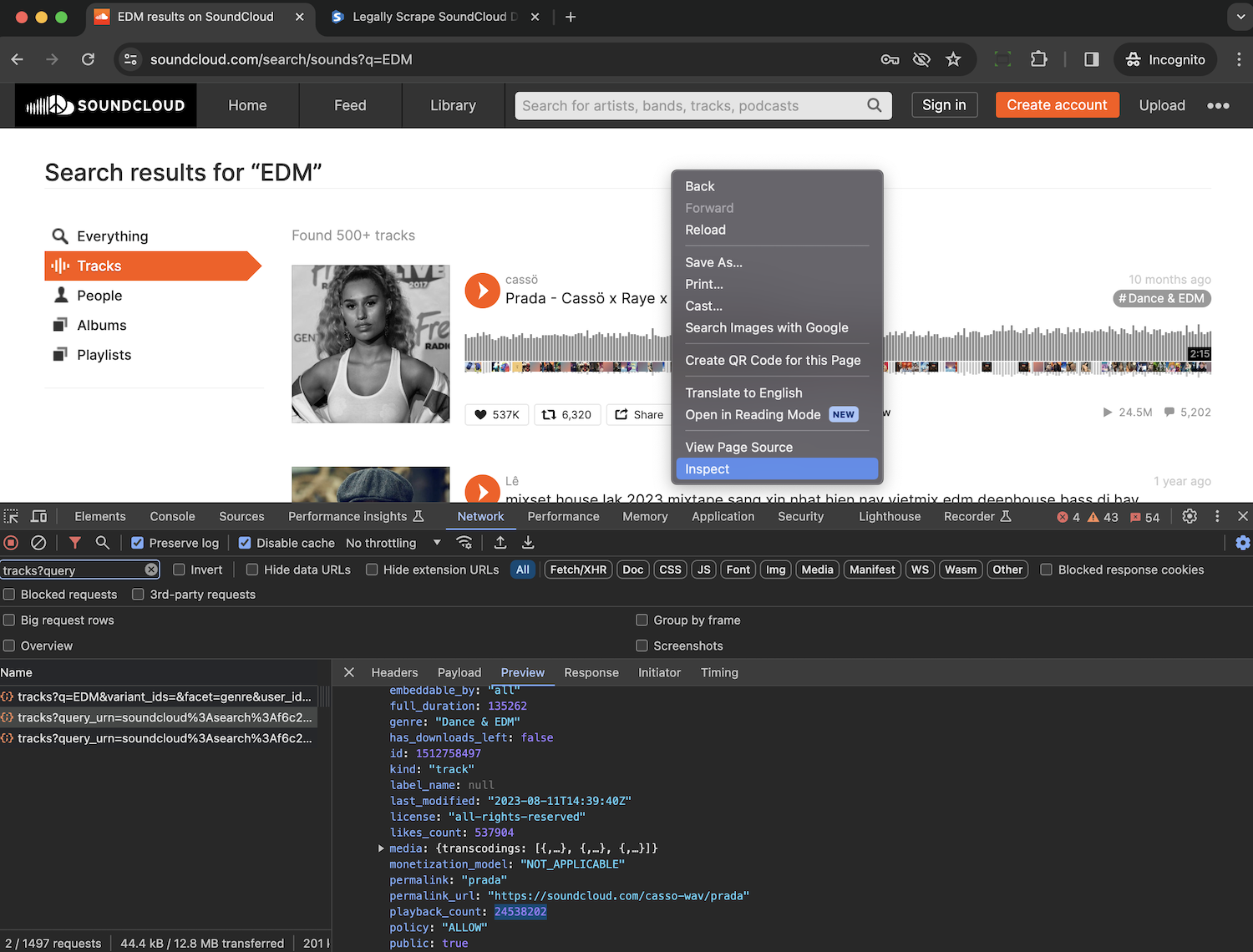
3. 合规性与伦理风险
在开展抓取工作之前,务必关注几项重要问题:
-
内容使用授权:SoundCloud 的服务条款和创作者的许可权利决定了该数据能否用于训练 AI 模型;并不是所有内容都是开放授权。
-
创作者权益保护:直接抓取并商业化使用未授权的音频数据可能侵害艺术家权益,带来法律争议。
-
透明性与免责声明:在使用抓取数据构建 AI 产品或研究时,建议明确标注数据来源与用途,尊重创作者的合法权利。
开展抓取前,务必审阅平台的服务条款和适用的数据使用政策。
4. 技术难点:抓取动态网站与反爬措施
4.1 动态渲染与 JavaScript 内容加载
SoundCloud 的页面是由 JavaScript 动态渲染的,传统的 HTTP 请求往往只能获得空 HTML。要抓取有效数据,需要模拟浏览器环境或使用能执行 JavaScript 的抓取工具。
常见技术选项包括:
-
Headless 浏览器(如 Puppeteer):通过编程控制浏览器加载页面,从渲染后的 DOM 中提取数据。
-
Web Scraping API 服务:一些服务提供自动处理动态渲染和反爬措施的 API,直接返回清洗过的结构化数据。

4.2 IP 限制与风控
SoundCloud 会监测异常请求模式,例如短时间内大量请求来自同一 IP,这类行为触发风控导致:
-
请求被拒绝(HTTP 403/429)
-
IP 被暂时或永久封禁
-
为避免这种限制,需要做好 IP 代理轮换、会话保持和请求节律控制:
-
使用大量异地 IP 轮换
-
在多个请求之间加入延迟
-
设置失败后退避重试策略
-
模拟正常浏览行为(User-Agent、Referer、Cookies)
这些方法是构建稳定抓取系统的基础。
5. 构建可扩展的数据采集策略
下面是一个适用于 AI 训练场景的数据抓取架构思路:
5.1 明确抓取目标字段
在动手写代码之前,先定义你需要的数据字段,例如:
-
音频播放地址
-
艺术家名字和 ID
-
标签、类别、播放量
-
评论、时间戳等
这种明确的数据定义有助于后续清洗和标注工作。
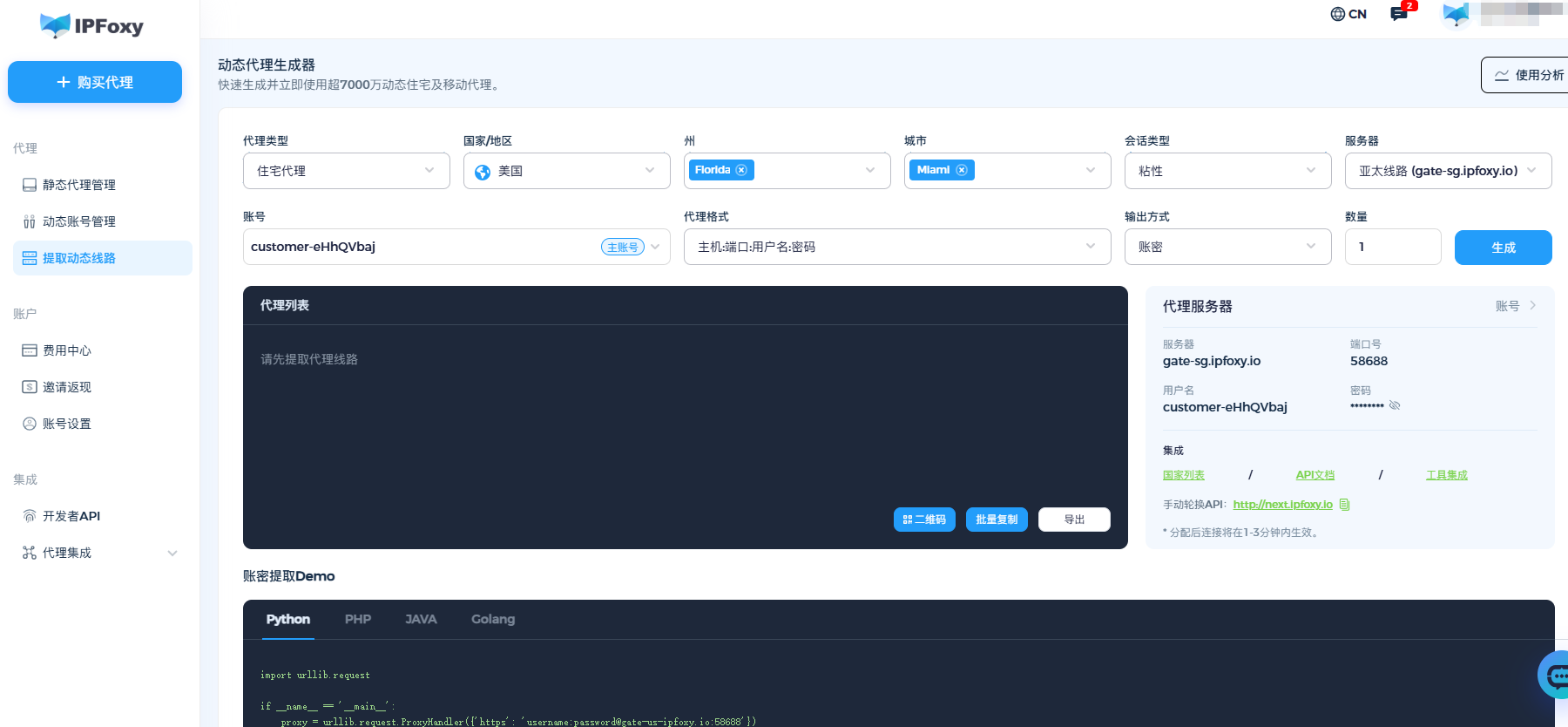
5.2 使用代理 + 会话管理策略
抓取中代理建议选择动态轮换的IP服务,比如IPFoxy提供的动态住宅IP代理,可以快捷地结合脚本爬取,以下是其动态IP池测试下来的效果测评:
-
大规模 IP 池与智能轮换:池子大重复率低,避免单个 IP 触发限流和封禁;
-
会话保持与区域定位:可以维持稳定连接体验,可以城市级定位;
-
可观测性与日志记录:有完整的仪表盘与IP日志,有助判定失败原因及自动调整策略。
例如,在实际抓取中,可以设定以下策略来提升成功率和效率:
-
联系目标域名时先发起少量测试请求
-
如果连续出现 HTTP 403/429,则自动切换到新 IP 或更换区域
-
对同一浏览器会话使用 Sticky Session ID
-
设置最大并发数与指数退避重试机制
6. 实践建议
对于大多数 AI 项目而言,抓取数据的过程可以分为三个阶段:
6.1 验证阶段
先构建最小可运行的流程,用少量样本验证抓取逻辑和字段正确性。
6.2 规模化抓取
当验证通过后,增加并发、使用更完善的代理策略,并将抓取结果导入数据仓库。
6.3 持续更新与监控
抓取程序不仅要跑一次,还要持续获取最新内容,并对失败率、封禁事件设定自动告警与处理机制。
7. 数据清洗与训练准备
抓取只是第一步,收集来的音频和元数据还需要经过清洗、转换和增强,例如:
-
统一音频格式
-
处理缺失字段
-
构建训练标签
-
数据增强(噪声注入、采样率变换等)
这些操作会显著提升音频 AI 模型的泛化能力。
8. 结语
抓取 SoundCloud 数据用于 AI 模型训练是技术上可行的,但同时涉及合规、风控和伦理议题。通过合理设计抓取架构、采用代理服务以及严谨的数据处理流程,你可以构建一个高质量、可持续的音频数据采集管道。