引入
之前学习c++和c语言的时候,经常会提到,堆区,栈区,常量区这些概念,为了直观的了解,我们来看这张图:
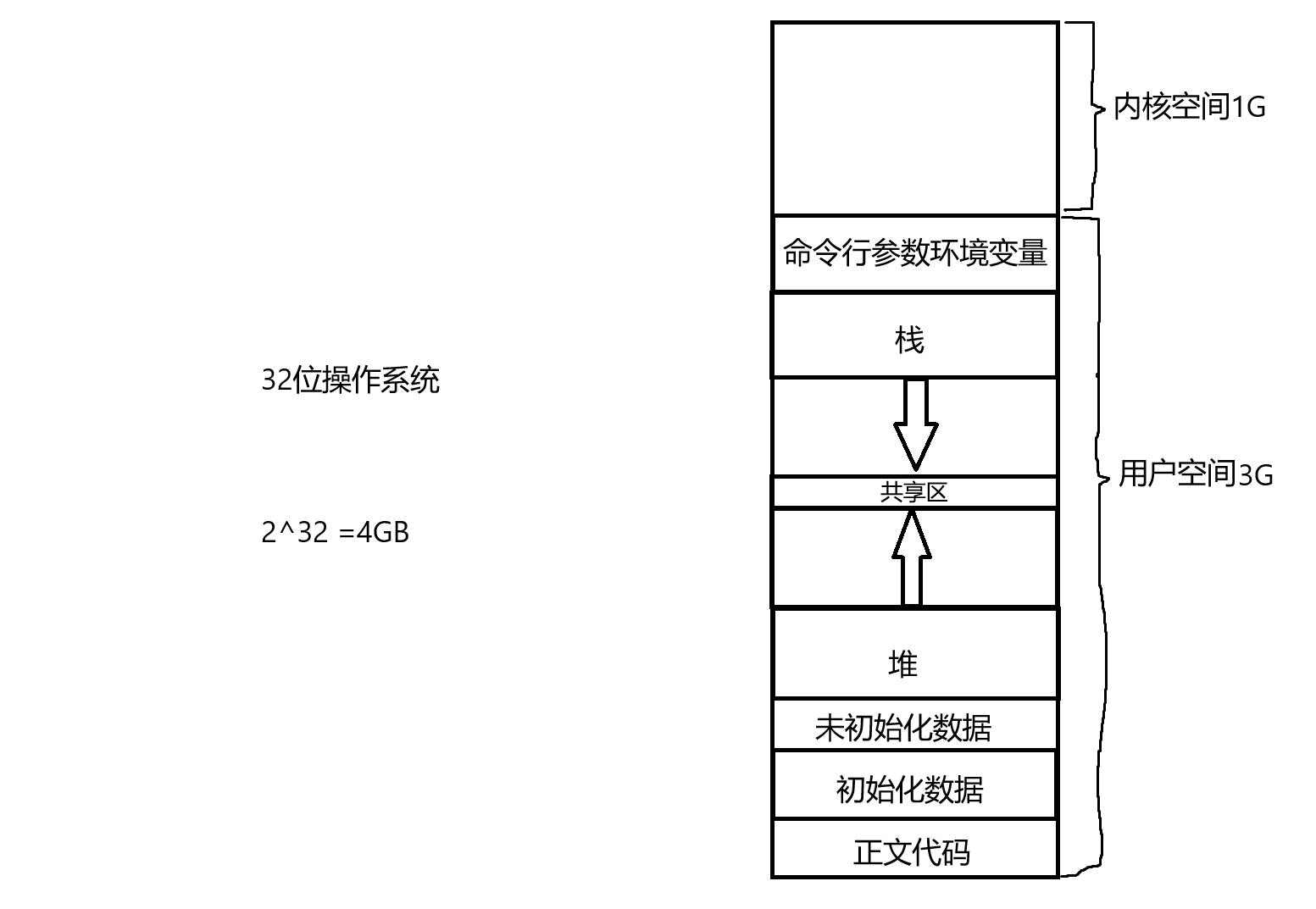
以32位操作系统为例,其4GB地址空间划分为1GB内核空间和3GB用户空间。内核空间由所有进程共享,存储操作系统内核代码、数据及驱动程序,用户程序无权直接访问;而用户空间则为每个进程独立分配,按地址从低到高依次包含以下区域:
- 正文代码区:存储可执行机器指令,具有只读和可共享特性
- 初始化数据区:保存已初始化的全局变量和静态变量,程序启动时即完成内存分配
- 未初始化数据区:存放未初始化的全局变量和静态变量,启动时自动初始化为0,在可执行文件中不占用实际空间
- 堆区:采用向上增长机制,新分配内存地址递增(如从0x10000000增至0x10001000),通过malloc等分配器管理动态内存,有效应对内存碎片化
- 共享区:存储动态链接库和共享内存,支持多进程共享
- 栈区:采用向下增长机制,新栈帧地址递减(如从0xFFFF0000降至0xFFFEFFFC),通过调整栈指针实现高效内存管理,符合LIFO原则,主要用于函数调用和局部变量存储
- 命令行参数与环境变量区:位于用户空间最高地址处,保存程序启动参数
这种堆栈对立增长的设计不仅满足不同内存管理需求,还能有效检测栈溢出(当栈指针侵入堆区时触发异常)。同时,用户空间与内核空间的严格隔离确保了系统安全性。
接下来我们来实际的看一下内存分布:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_unval;
int g_val = 100;
int main(int argc, char* argv[], char* env[])
{
const char* str = "helloworld";
printf("code addr: %p\n", main);
printf("init global addr: %p\n", &g_val);
printf("uninit global addr: %p\n", &g_unval);
static int test = 10;
char* heap_mem = (char*)malloc(10);
char* heap_mem1 = (char*)malloc(10);
char* heap_mem2 = (char*)malloc(10);
char* heap_mem3 = (char*)malloc(10);
printf("heap addr: %p\n", heap_mem); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem1); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem2); //heap_mem(0), &heap_mem(1)
printf("heap addr: %p\n", heap_mem3); //heap_mem(0), &heap_mem(1)
printf("test static addr: %p\n", &test); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem1); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem2); //heap_mem(0), &heap_mem(1)
printf("stack addr: %p\n", &heap_mem3); //heap_mem(0), &heap_mem(1)
printf("read only string addr: %p\n", str);
for (int i = 0; i < argc; i++)
{
printf("argv[%d]: %p\n", i, argv[i]);
}
for (int i = 0; env[i]; i++)
{
printf("env[%d]: %p\n", i, env[i]);
}
return 0;
}执行结果:
code addr: 0x59d9d1bca189
init global addr: 0x59d9d1bcd010
uninit global addr: 0x59d9d1bcd01c
heap addr: 0x59d9e1fde6b0
heap addr: 0x59d9e1fde6d0
heap addr: 0x59d9e1fde6f0
heap addr: 0x59d9e1fde710
test static addr: 0x59d9d1bcd014
stack addr: 0x7fffdd7bd550
stack addr: 0x7fffdd7bd558
stack addr: 0x7fffdd7bd560
stack addr: 0x7fffdd7bd568
read only string addr: 0x59d9d1bcb004
argv[0]: 0x7fffdd7be609
env[0]: 0x7fffdd7be611
env[1]: 0x7fffdd7be621
env[2]: 0x7fffdd7be63a
env[3]: 0x7fffdd7be647
env[4]: 0x7fffdd7be65c
env[5]: 0x7fffdd7be66c
env[6]: 0x7fffdd7be67d
env[7]: 0x7fffdd7bed96
env[8]: 0x7fffdd7bedbe
env[9]: 0x7fffdd7bedef
env[10]: 0x7fffdd7bee11
env[11]: 0x7fffdd7bee28
env[12]: 0x7fffdd7bee33
env[13]: 0x7fffdd7bee53
env[14]: 0x7fffdd7bee5d
env[15]: 0x7fffdd7bee74
env[16]: 0x7fffdd7bee7c
env[17]: 0x7fffdd7bee92
env[18]: 0x7fffdd7beeae
env[19]: 0x7fffdd7beed1
env[20]: 0x7fffdd7bef12
env[21]: 0x7fffdd7bef7a
env[22]: 0x7fffdd7befad
env[23]: 0x7fffdd7befc1
env[24]: 0x7fffdd7befd4
env[25]: 0x7fffdd7befe6果然和我们之前学到的一样,但是这里的内存地址真的是物理上的地址吗?接下来看下一段代码
#include <unistd.h>
#include<stdio.h>
int gval =0;
int main()
{
pid_t id = fork();
if(id == 0)
{
while(1)
{
printf("子进程:gval:%d,&gval:%p,pid:%d,ppid:%d\n",gval,&gval,getpid(),getppid());
sleep(1);
gval++;
}
}
else if(id >0)
{
while(1)
{
printf("父进程:gval:%d,&gval:%p,pid:%d,ppid:%d\n",gval,&gval,getpid(),getppid());
sleep(1);
}
}
return 0;
}编译运行:
父进程:gval:0,&gval:0x5f5a113bf014,pid:3655427,ppid:3647837
子进程:gval:0,&gval:0x5f5a113bf014,pid:3655428,ppid:3655427
父进程:gval:0,&gval:0x5f5a113bf014,pid:3655427,ppid:3647837
子进程:gval:1,&gval:0x5f5a113bf014,pid:3655428,ppid:3655427
父进程:gval:0,&gval:0x5f5a113bf014,pid:3655427,ppid:3647837
子进程:gval:2,&gval:0x5f5a113bf014,pid:3655428,ppid:3655427
子进程:gval:3,&gval:0x5f5a113bf014,pid:3655428,ppid:3655427
父进程:gval:0,&gval:0x5f5a113bf014,pid:3655427,ppid:3647837
子进程:gval:4,&gval:0x5f5a113bf014,pid:3655428,ppid:3655427
父进程:gval:0,&gval:0x5f5a113bf014,pid:3655427,ppid:3647837
父进程:gval:0,&gval:0x5f5a113bf014,pid:3655427,ppid:3647837
子进程:gval:5,&gval:0x5f5a113bf014,pid:3655428,ppid:3655427
子进程:gval:6,&gval:0x5f5a113bf014,pid:3655428,ppid:3655427
父进程:gval:0,&gval:0x5f5a113bf014,pid:3655427,ppid:3647837
父进程:gval:0,&gval:0x5f5a113bf014,pid:3655427,ppid:3647837
子进程:gval:7,&gval:0x5f5a113bf014,pid:3655428,ppid:3655427
子进程:gval:8,&gval:0x5f5a113bf014,pid:3655428,ppid:3655427
父进程:gval:0,&gval:0x5f5a113bf014,pid:3655427,ppid:3647837
父进程:gval:0,&gval:0x5f5a113bf014,pid:3655427,ppid:3647837
子进程:gval:9,&gval:0x5f5a113bf014,pid:3655428,ppid:3655427
子进程:gval:10,&gval:0x5f5a113bf014,pid:3655428,ppid:3655427
父进程:gval:0,&gval:0x5f5a113bf014,pid:3655427,ppid:3647837
子进程:gval:11,&gval:0x5f5a113bf014,pid:3655428,ppid:3655427
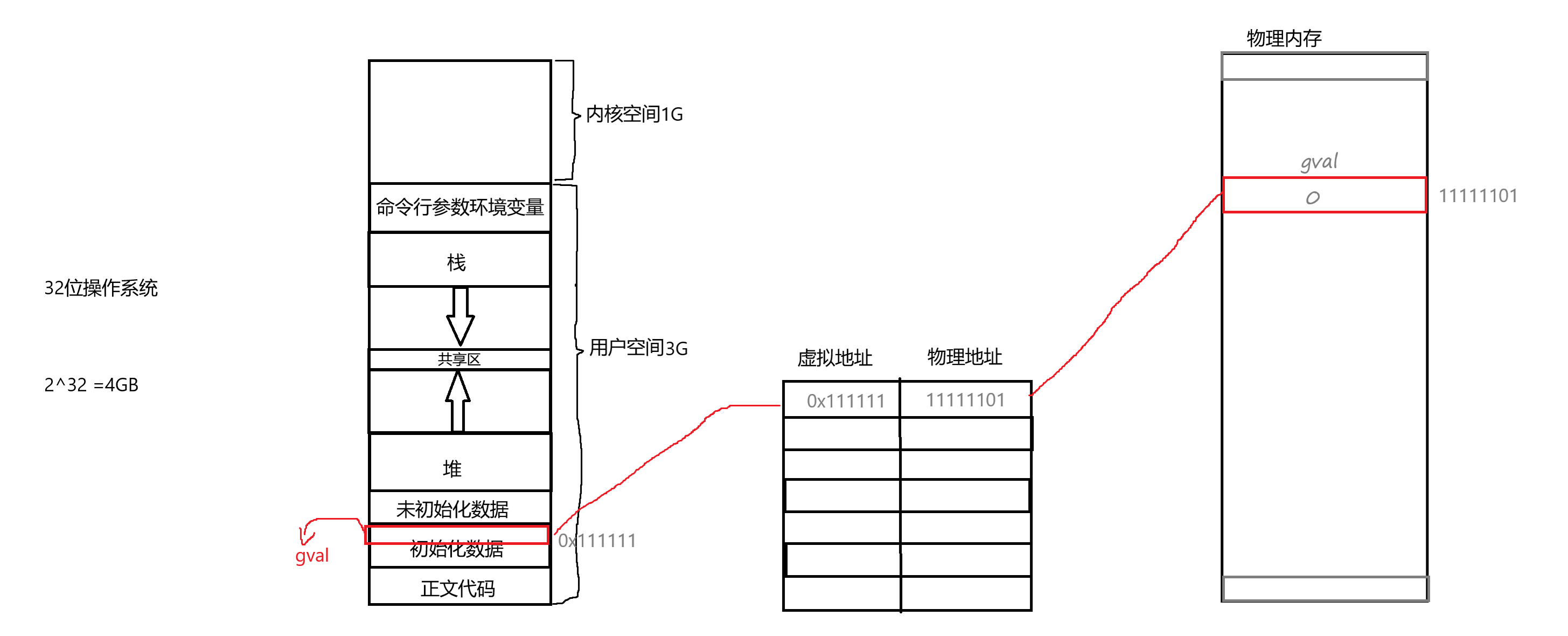
父进程:gval:0,&gval:0x5f5a113bf014,pid:3655427,ppid:3647837我们之前提到了,fork创建子进程时,会有写时拷贝的机制,刚开始时,父子进程可能会指向同一块资源,当任意进程对资源进行操作时,就会新开一块空间出来把原来的值拷贝过去再修改。但是这里的运行结果中父子进程的gval地址却相同,而且子进程的gval已经修改。这非常的不合理,一个地址上出现了两个值,所以我们这里说的地址肯定不可能是物理地址!这种地址叫虚拟地址。
进程地址空间
进程内存加载原理
我们都知道不是单个单个数据被加载到内存的,只有进程能够被加载到内存,一个进程就有一个虚拟地址空间和内存上的空间做映射,页表就是这个做映射的中介。
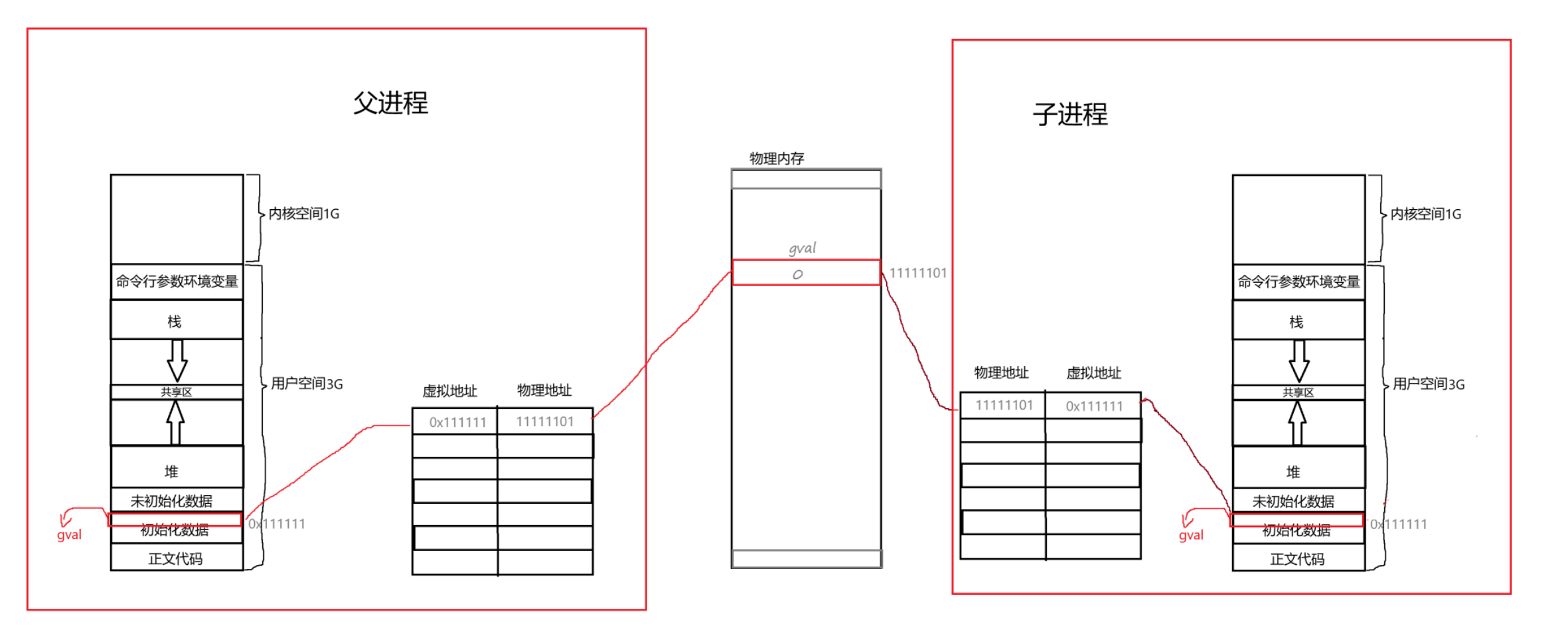
子进程在被创建时会继承父进程的代码和数据,同样也会继承父进程的页表,这是浅拷贝。
但是进程是有独立性的,所以当子进程对gval进行修改时,系统会为它开辟一块新的空间将原来的gval拷贝过去然后修改并改变页表的映射。
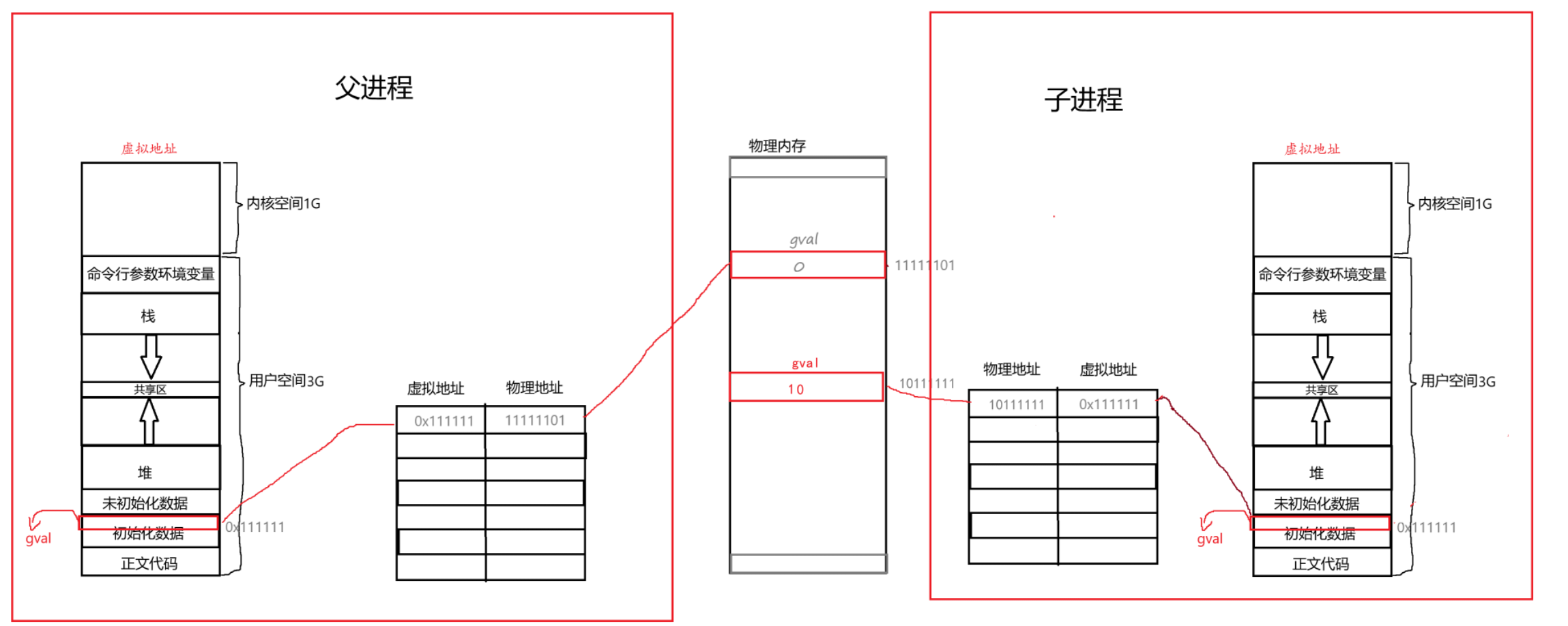
这里也回答了我们在刚学进程遗留下的一个问题,为什么fork之后,id可以即等于0又大于零,虽然都叫id但是本质上它们的物理空间已经不同了。
#include<stdio.h>
#include<unistd.h>
#include<sys/types.h>
int main()
{
printf("父进程开始运行!%d\n",getpid());
pid_t id = fork();
if(id==0)
{
while(1)
{
sleep(1);
printf("我是子进程:%d,我的父进程是%d\n",getpid(),getppid());
}
}
else if(id > 0)
{
while(1)
{
sleep(1);
printf("我是父进程:%d,我的父进程是%d\n",getpid(),getppid());
}
}
else
{
perror("fork");
return 1;
}
}
------------------------------------------------
版权声明:本文为CSDN博主「prettyxian」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/prettyxian/article/details/156109858虚拟地址是个结构体
怎么理解虚拟地址和进程地址空间呢?
用这样一个例子来理解,老板(操作系统) 开了一家大公司(计算机)。公司有一间巨大的、真实的物理仓库(物理内存),里面摆满了货架(内存条)。新员工(进程) 入职时,老板都会给他一本专属的"虚拟仓库规划图"(进程地址空间),并告诉他:
"看,这一整层4GB的仓库(32位系统)都归你一个人管!这里是你的办公区(栈),那里是你的原料区(堆),那边是公共资料区(共享库)...地址从0x00000000到0xffffffff都标好了,你随便用!"
员工很开心,因为他觉得自己拥有独立、完整、连续的仓库,可以心无旁骛地工作,完全不用担心和别的员工抢货架。
然而,真相是:
-
"规划图"不是真实的货架位置:员工规划图上的"A区-01号位"(虚拟地址),并不直接对应真实物理仓库里的"第三排-第五个货架"(物理地址)。
-
真正的调度靠"秘书处"(MMU+页表):公司里有一个高效的秘书处(内存管理单元MMU + 页表)。每当员工说"我要去A区-01号位取货"时,秘书处会立刻查阅该员工的专属翻译本(页表),找到这个虚拟位置实际对应的物理货架地址,然后默默带他过去。
-
"饼"真的很大,但吃得少:大部分员工根本用不完4GB。秘书处非常精明,它只会在员工真正需要某个货架时(访问内存时),才在物理仓库里为他分配一个真实的货架,并记录在翻译本上。这就是延迟分配/按需分配。
-
"共享会议室"(共享内存/只读代码):对于一些公共资料(如公司规章制度、共享代码库),秘书处会让多个员工的翻译本指向物理仓库里的同一份原件,这样既节省空间,又能保证大家看到的内容一致。
-
"隔离与安全":因为每个员工都只认自己的规划图,并通过自己的翻译本访问仓库。所以员工A永远无法通过自己的规划图,直接指定去到员工B的物理货架。这完美实现了进程隔离。就算员工A的规划图乱了(进程崩溃),也绝不会影响到员工B的货物。(进程的独立性)
老板(OS)要管理员工(进程)的同时,也要管理给员工们画的饼,先描述再组织,通过结构体变量储存虚拟地址的信息,所以虚拟地址的本质其实是一个结构体对象!struct mm_struct。
// 简化的内核数据结构关系
struct task_struct {
// ... 很多其他字段 ...
struct mm_struct *mm; // 指向进程地址空间描述符
// ...
};
struct mm_struct {
// 管理用户空间虚拟地址的核心字段
unsigned long start_code, end_code; // 代码段起止
unsigned long start_data, end_data; // 数据段起止
unsigned long start_brk, brk; // 堆区起止 (brk是堆顶指针)
unsigned long start_stack; // 栈起始地址
unsigned long arg_start, arg_end; // 命令行参数区
unsigned long env_start, env_end; // 环境变量区
// 页表
pgd_t *pgd; // 指向页全局目录 (Page Global Directory)
};无需记录每个区域的每一个地址,只记录开头和结尾,通过各个区域开头和结尾的位置就能控制各个区域,这就像画饼时不需要画出饼上的每一粒芝麻,只需要画出饼的外轮廓和内部几个主要区域的分界线。通过start_brk和brk,内核就知道了堆区在哪、有多大;通过start_stack,内核就知道了栈从哪里开始生长。为什么这么设计呢?这样设计有什么好处?
-
以不变应万变:代码段、数据段加载后固定不变,只需记录一次边界
-
以一点控全局 :通过移动
brk一个指针,就能控制整个堆区的扩展 -
以简单防复杂 :只需比较
地址 >= start && 地址 < end,就能完成合法性检查 -
以局部代整体:通过维护少数边界值,就能间接管理整个4GB空间
动态加载过程
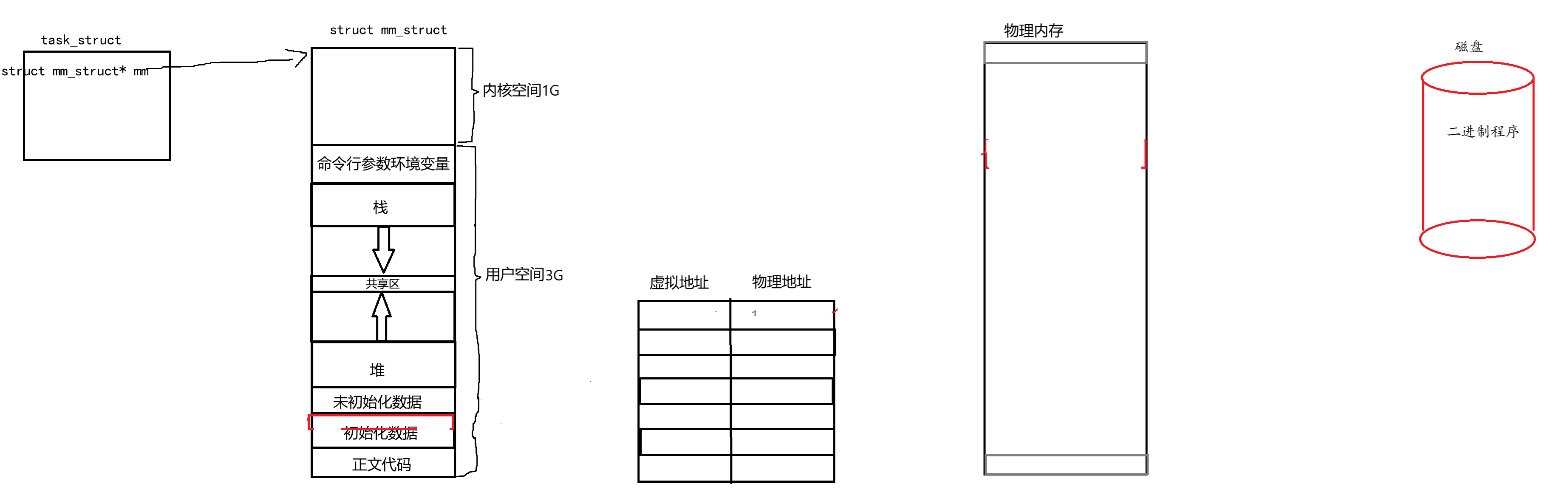
进程创建时系统会给进程申请一个task_struct,在这个过程中,系统会读取文件的格式信息来了解要代码和数据的大致信息,然后在虚拟地址中开辟空间,比如代码的大小为100字节,操作系统就会为代码在虚拟内存中开辟相应100个字节。然后操作系统会为代码和数据开辟100个字节的物理内存,将代码和数据加载到物理内存。
最后操作系统会为在页表中将虚拟地址和物理地址做映射。
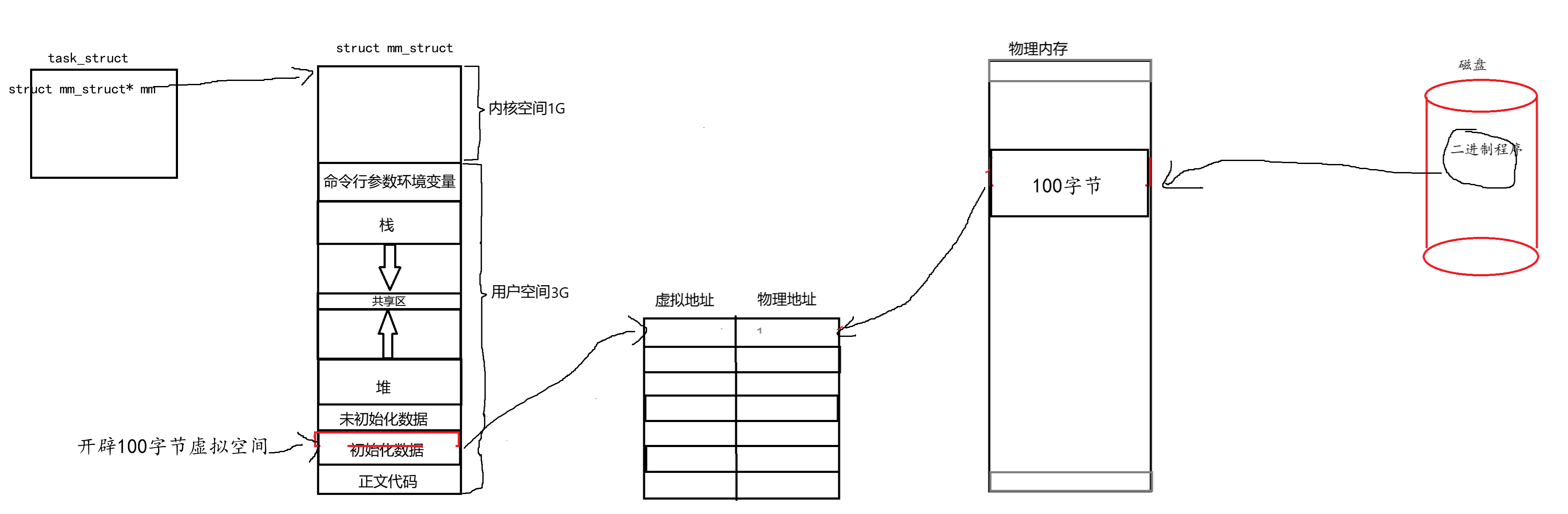
进程拿到的是虚拟地址,会通过页表的映射最终访问到物理内存。
为什么要用虚拟地址
无序变有序
虚拟地址为上层用户提供了连续的内存访问体验,尽管底层物理内存可能并不连续。这种设计极大简化了程序员的开发工作。有了虚拟地址,磁盘中文件可以加载到内存的任何位置,页表会给它们做映射,上层用户拿到的永远都是规律连续的虚拟地址。
物理内存的实际状况: 在长期运行的系统环境中,物理内存往往呈现高度碎片化状态。即使系统拥有10GB的空闲内存,要分配1MB的连续物理内存空间都可能面临挑战。
虚拟内存的应对方案: 操作系统通过页表机制,将连续的虚拟地址映射到可能分散的物理页帧。这种映射既保持了程序员视角下的内存连续性,又让操作系统能够高效利用碎片化的物理资源。
该架构的关键优势:
**编程简化:**开发者无需考虑物理内存的实际分布情况
资源优化:碎片化的物理内存得到充分利用
**容量扩展:**通过页面置换技术,虚拟地址空间可超越物理内存限制
**共享便捷:**多个进程可通过不同虚拟地址映射共享同一物理页(如共享内存和动态库)
类比城市规划:
虚拟地址如同城市门牌系统:1号、2号、3号...排列有序
物理内存则像实际建筑:1号可能位于小巷,2号临街而建,3号远在郊区
页表扮演邮递员角色:准确关联门牌号与实际建筑位置
这种"连续性的抽象"是现代软件开发的重要基石。程序员在简洁的抽象层上工作,而操作系统则在底层处理所有复杂细节。
保护物理内存
权限机制在这里能得到印证,页表中还包含一个专门的权限位。比如说"hello world"存在常量区的时候,在修改的时候页表会意识到,在常量区没有修改权限,不能修改。
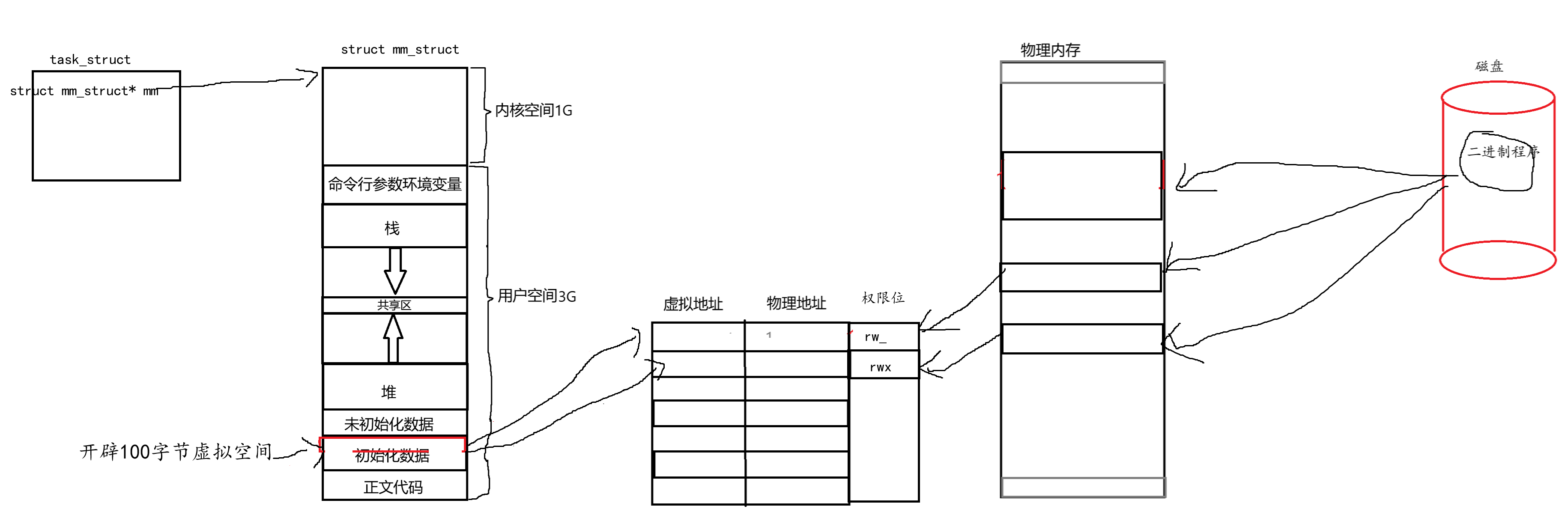
进程要拿到的是虚拟地址,会通过页表的映射最终访问物理内存,页表中有一个权限位会标记进程对相应文件的权限,如果没有w权限就不能修改文件。
野指针
操作系统对各内存区域的数据处理策略存在差异。物理内存释放后,页表项可能保留也可能被清除。若页表项被清除,用户程序访问该虚拟地址时将因找不到映射关系而崩溃;这就是野指针。
进程状态也能在这里得到映射,当内存空间不足的时,不紧要的进程的代码和数据会被移出内存,到磁盘的交换区中。这时候会保留页表页,只是去除了其中的物理地址,当进程再次被加载的时候页表又会重新映射。操作系统把这三个页表的状态枚举出来了。
// 页表项的存在状态机
enum page_state {
// 状态A:正常映射(代码/数据在物理内存中)
// PTE: present=1, pfn=0x12345, dirty=0/1, accessed=1
// 示例:正在使用的堆栈数据
// 状态B:已交换出(在磁盘交换区)
// PTE: present=0, swap_entry=0xabcde
// 注:Linux利用present=0但其他位存储交换位置信息
// 示例:很久未访问的代码页
// 状态C:未映射/已释放
// PTE: present=0, 其他位=0 或 特殊标记
// 示例:野指针指向的已释放内存
};内存管理和进程管理一定程度上解耦合
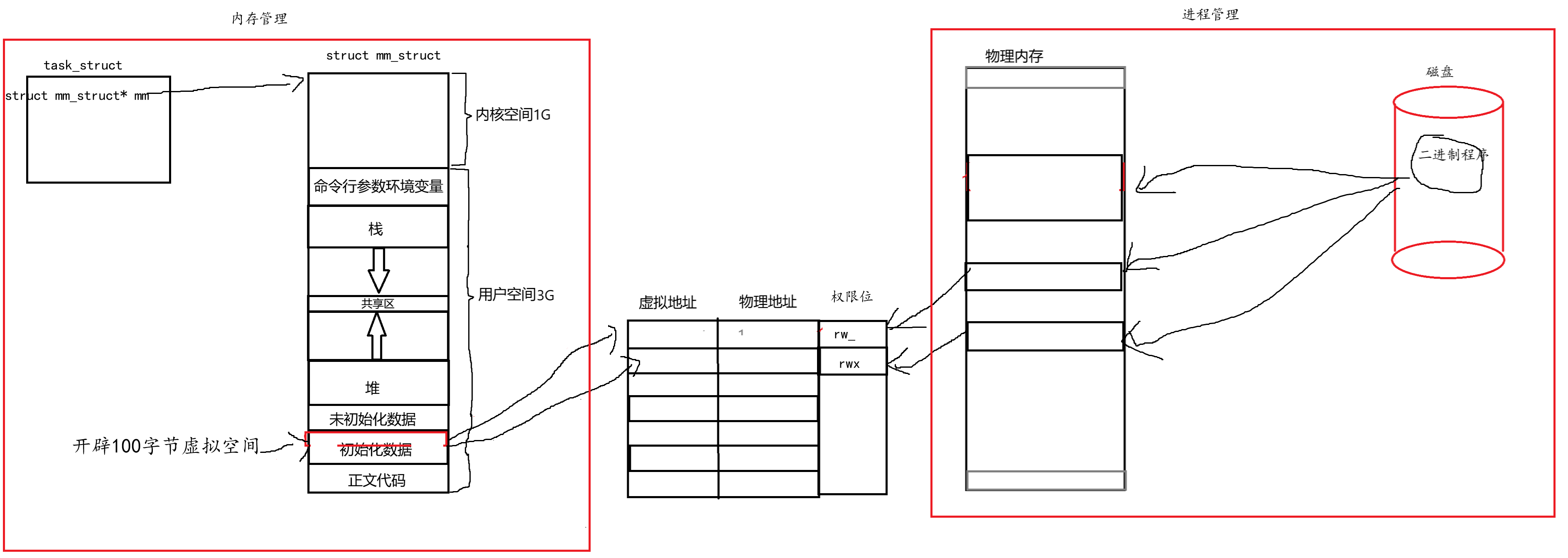
虚拟内存机制实现了内存管理与进程管理的部分解耦。通过引入虚拟地址空间,当申请新内存时,只需修改页表映射而无需调整PCB中的指针。即使进程被挂起后重新加载,也无需逐个修改指针,大大简化了内存管理操作。
补充
-
系统可以仅加载代码和数据的基本结构(如 task_struct 和 mm_struct)以及页表。此时物理内存不会被实际加载,系统会标记这部分内容为待加载状态,当真正需要访问这些代码和数据时才会将其载入内存。
-
在创建进程时,系统首先建立进程控制块(PCB),随后为其分配虚拟地址空间,最后才会根据实际需求加载相应的物理内存内容。
扩展
堆区中变量的地址分布是离散的,由于多次malloc分配的地址可能位于不同位置,仅通过管理堆区的起始和结束地址无法有效控制整个堆区空间。所以mm_struct只是对不同区域的边界划分,具体的管理工作则由vm_area_struct结构体来实现。
// task_struct 与 mm_struct 的关联
struct task_struct {
// ...
struct mm_struct *mm; // 进程的地址空间
struct mm_struct *active_mm; // 活跃地址空间
// ...
};
// mm_struct 与 vm_area_struct 的双向关联
struct mm_struct {
// VMA管理
struct vm_area_struct *mmap; /* list of VMAs - VMA链表头 */
struct rb_root mm_rb; /* VMA红黑树根 - 快速查找 */
struct vm_area_struct *mmap_cache; /* 上次查找的VMA缓存 */
// 关键计数器
int map_count; /* number of VMAs - VMA数量 */
// 同步保护
struct rw_semaphore mmap_sem; /* 保护VMA操作 */
spinlock_t page_table_lock; /* 保护页表和某些计数器 */
// 页表管理
pgd_t *pgd; /* 页全局目录 - 页表根 */
// 统计信息
unsigned long total_vm; /* 总虚拟内存大小 */
unsigned long locked_vm; /* 被锁定的内存 */
unsigned long pinned_vm; /* 被固定的内存 */
unsigned long data_vm; /* 数据段大小 */
unsigned long exec_vm; /* 代码段大小 */
unsigned long stack_vm; /* 栈大小 */
// ...
};
// vm_area_struct 反向指向 mm_struct
struct vm_area_struct {
struct mm_struct *vm_mm; /* 所属的mm_struct - 关键反向指针! */
unsigned long vm_start; /* 区域起始地址 */
unsigned long vm_end; /* 区域结束地址 */
// 链接结构
struct vm_area_struct *vm_next; /* 下一个VMA */
struct vm_area_struct *vm_prev; /* 上一个VMA(某些架构)*/
struct rb_node vm_rb; /* 红黑树节点 */
// 属性
unsigned long vm_flags; /* 权限标志 */
// ...
};