在 Encoder-Decoder 结构模型中,通常采用 "加噪自编码" 的预训练思路: 先对输入序列进行一定形式的 "噪声/扰动" 处理,再让模型根据这份 "带噪声的序列" 来 重构 或 还原 出原始序列。具体而言,常见做法主要有以下几种:
1 Span Corruption (文本段落损坏/填空)
这是 T5 模型最经典的做法。它不是一个字一个字地抹去,而是随机挖掉一小段话。
核心逻辑: 把原文中的一段或几段连续文字替换成特殊的符号(如 MASK 或 Sentinel)。
训练目的: 让模型学会根据上下文联想出缺失的长片段信息。
例子:
- 原文: "北京是中国的首都,它是一座拥有三千多年历史的古都。"
- Encoder 输入(加噪): "北京是 MASK_1 首都,它是一座 MASK_2 的古都。"
- Decoder 输出(目标): "MASK_1 中国的 MASK_2 拥有三千多年历史。"
2 Denoising Auto-Encoder (去噪自编码)
这在 BART 模型中非常常见。它对文本的破坏方式更"暴力"、更多样,目的是让模型具备极强的纠错和重组能力。
常见加噪操作:
- 词序打乱: 把句子里的词随机换位置。
- 随机删除: 随机删掉一些词。
- 词替换: 把某个词换成一个完全无关的词。
例子:
- 原文: "机器学习是人工智能的一个重要分支。"
- Encoder 输入(乱序+删除): "重要 机器学习 人工智能 分支。"
- Decoder 输出(还原): "机器学习是人工智能的一个重要分支。"
3 多任务多目标掩码 (Unified Text-to-Text)
这是 T5 和 Flan-T5 能够处理各种任务的秘诀。它将所有 NLP 任务都统一看作是 "文字到文字" 的变换。
核心逻辑: 在输入序列前加上一个指令(Prompt),告诉模型现在要做什么任务。
例子:
-
翻译任务:
输入:"翻译成英文:我爱学习。"
输出:"I love learning."
-
摘要任务:
输入:"总结:一长段关于气候变化的报道"
输出:"全球气候变暖趋势加剧。"
-
问答任务:
输入:"问题:中国的首都在哪里?"
输出:"北京。"
4 基于 Encoder-Decoder 架构阐述为什么要这样做的细节
1. Encoder-Decoder 架构带来的问题:我们需要打破恒等映射

2. Encoder 的职责:学习 "鲁棒" 的特征表示

3. Decoder 的职责:学习 "自回归生成" 的逻辑
根据 Encoder 提供的背景信息,一个词接一个词地生成结果。

4. Decoder 如何根据 Encoder 提供的背景信息,一个词接一个词地生成结果
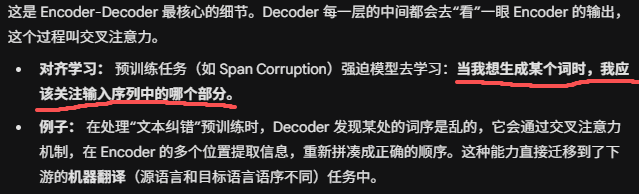
需要在二者之间建立关键纽带,交叉注意力 (Cross-Attention) 的训练。
Transformer的概念学习:
https://blog.csdn.net/weixin_57128596/article/details/154795289?spm=1001.2014.3001.5501