技术选型与架构设计
技术栈选择
- Python:作为主要开发语言,用于实现爬虫和Web应用
- Flask:轻量级Web框架,用于搭建后端服务
- BeautifulSoup:HTML解析库,用于提取网页数据
- SQLite3:轻量级数据库,用于存储电影信息
- Echarts:数据可视化库,用于展示评分分布和词频统计
- WordCloud:词云生成库,用于生成电影名称词云图
项目架构
核心代码实现
网络爬虫实现
python
# 导入必要的库
import urllib.request
from bs4 import BeautifulSoup
import re
import sqlite3
import xlwt
# 定义爬取函数
def get_movie_info(url):
# 发送HTTP请求
response = urllib.request.urlopen(url)
html = response.read().decode('utf-8')
# 解析HTML页面
soup = BeautifulSoup(html, 'html.parser')
# 提取电影信息
movies = []
movie_items = soup.find_all('div', class_='item')
for item in movie_items:
movie = {}
# 提取电影排名
movie['rank'] = re.findall(r'\d+', item.find('em').text)[0]
# 提取电影名称
movie['title'] = item.find('span', class_='title').text
# 提取评分
movie['rating'] = item.find('span', class_='rating_num').text
# 提取评价人数
movie['votes'] = re.findall(r'\d+', item.find('div', class_='star').find_all('span')[-1].text)[0]
# 提取一句话概述
quote = item.find('span', class_='inq')
movie['quote'] = quote.text if quote else ''
movies.append(movie)
return movies
# 主函数
def main():
base_url = 'https://movie.douban.com/top250?start='
movies = []
# 爬取10页数据
for i in range(0, 250, 25):
url = base_url + str(i)
page_movies = get_movie_info(url)
movies.extend(page_movies)
# 保存到Excel文件
save_to_excel(movies)
# 保存到SQLite数据库
save_to_sqlite(movies)
if __name__ == '__main__':
main()Web应用实现
python
# 导入必要的库
from flask import Flask, render_template, request
import sqlite3
import jieba
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import numpy as np
from PIL import Image
# 初始化Flask应用
app = Flask(__name__)
# 首页路由
@app.route('/')
def index():
return render_template('index.html')
# 电影列表路由
@app.route('/movies')
def movies():
# 从数据库中获取电影信息
conn = sqlite3.connect('top250.db')
cursor = conn.cursor()
cursor.execute('SELECT * FROM movies')
movies = cursor.fetchall()
conn.close()
return render_template('movies.html', movies=movies)
# 评分分布路由
@app.route('/rating')
def rating():
# 从数据库中获取评分数据
conn = sqlite3.connect('top250.db')
cursor = conn.cursor()
cursor.execute('SELECT rating FROM movies')
ratings = cursor.fetchall()
conn.close()
# 处理评分数据
rating_distribution = {}
for rating in ratings:
rating = float(rating[0])
rating_range = f"{int(rating)}-{int(rating)+0.9}"
if rating_range in rating_distribution:
rating_distribution[rating_range] += 1
else:
rating_distribution[rating_range] = 1
return render_template('rating.html', rating_distribution=rating_distribution)
# 词频统计路由
@app.route('/wordcloud')
def wordcloud():
# 从数据库中获取电影名称
conn = sqlite3.connect('top250.db')
cursor = conn.cursor()
cursor.execute('SELECT title FROM movies')
titles = cursor.fetchall()
conn.close()
# 对电影名称进行分词
words = []
for title in titles:
words.extend(jieba.lcut(title[0]))
# 生成词云图
wordcloud = WordCloud(
font_path='simhei.ttf',
background_color='white',
mask=np.array(Image.open('cat.jpg'))
).generate(' '.join(words))
# 保存词云图
wordcloud.to_file('static/wordcloud.png')
return render_template('wordcloud.html')
# 启动应用
if __name__ == '__main__':
app.run(debug=True)项目成果与展示
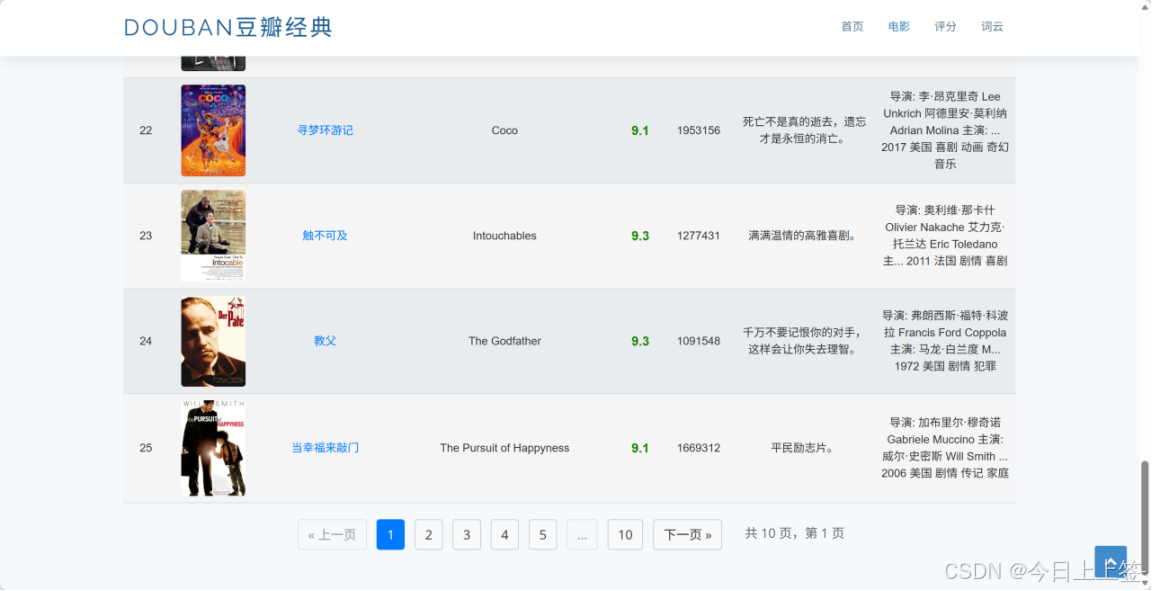
本项目成功爬取豆瓣电影Top250的完整信息,涵盖电影排名、名称、评分、评价人数和一句话概述等核心数据,并将数据持久化存储到Excel文件和SQLite数据库中。基于Flask框架搭建的Web应用实现了四大核心功能模块:首页展示项目简介与热门电影推荐、电影列表页呈现完整Top250电影信息、评分分布页通过Echarts可视化展示不同评分区间的电影数量与占比、词云页生成以猫咪图片为背景的电影名称高频词汇云图,全方位满足用户对电影信息的浏览、查询和分析需求。
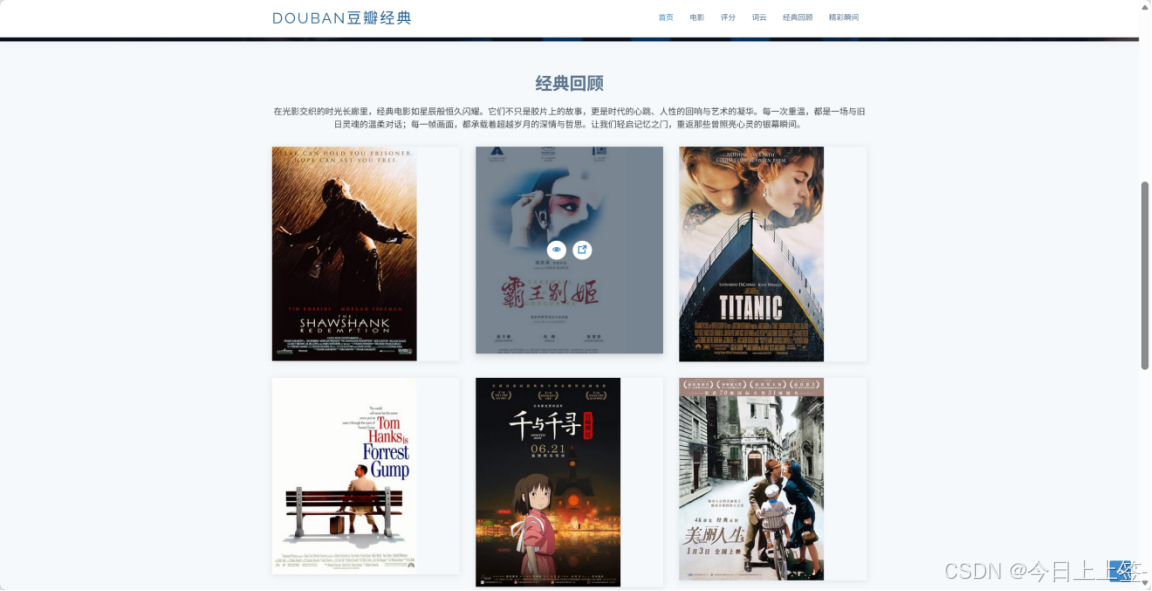

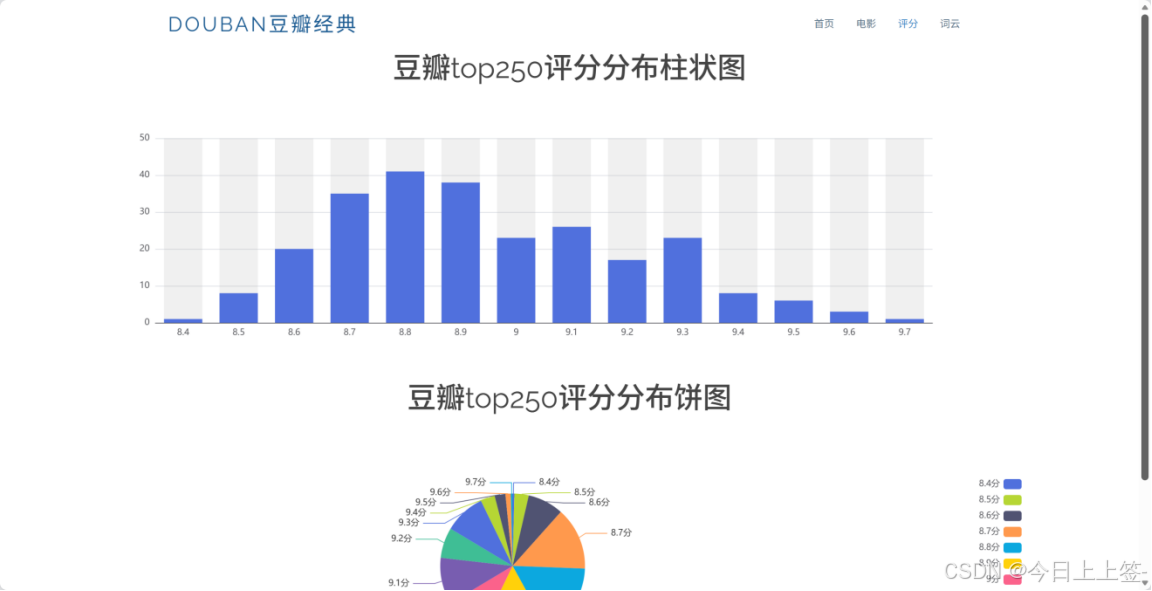
项目总结与展望
通过这个项目,我不仅提升了Python编程能力,还学习了网络爬虫、数据处理和Web开发等技术。项目中遇到的主要挑战是豆瓣反爬虫机制的处理。
未来进一步优化的方面:
- 实现电影搜索和筛选功能
- 增加用户评论和评分功能
- 优化词云图生成算法,提高展示效果
这个项目展示了我在Python开发、数据处理和Web应用开发方面的能力,也为我今后的学习和工作打下了坚实的基础。