目录
[CMS(Concurrent Mark Sweep, 并发标记清除)](#CMS(Concurrent Mark Sweep, 并发标记清除))
[G1(Garbage First)回收器](#G1(Garbage First)回收器)
jdk(Java Development Kit) Java开发工具包 JRE+开发工具(编译器(javac),调试器等)
jre(Java Runtime Enviroment)Java运行时环境 JVM+工具类(String 等等)
jvm Java虚拟机 将字节码 解释 / 编译 为机器码执行,也是java可以一次编程,到处运行的核心
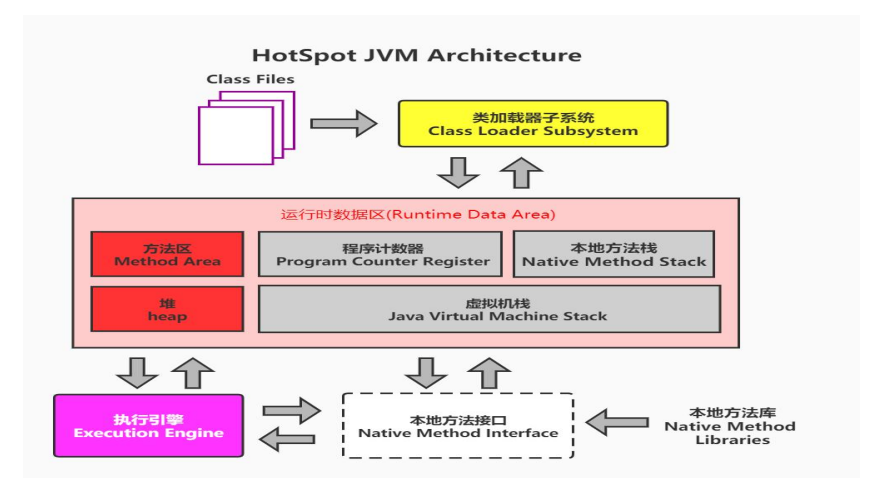
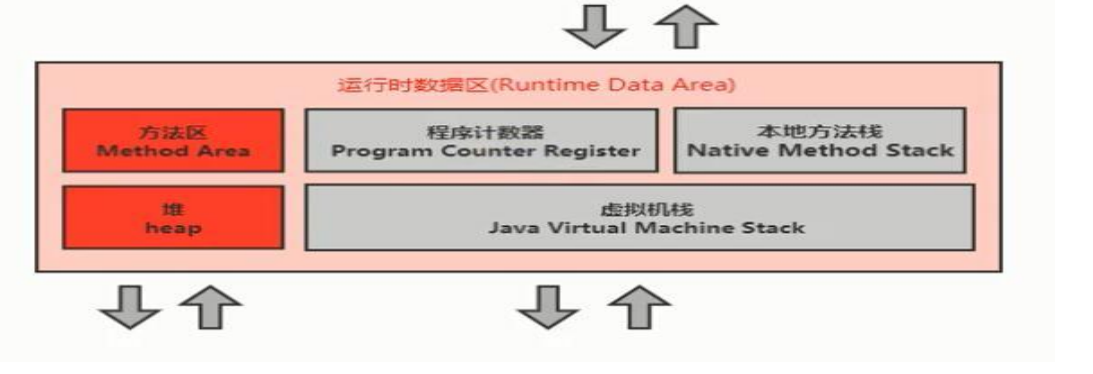
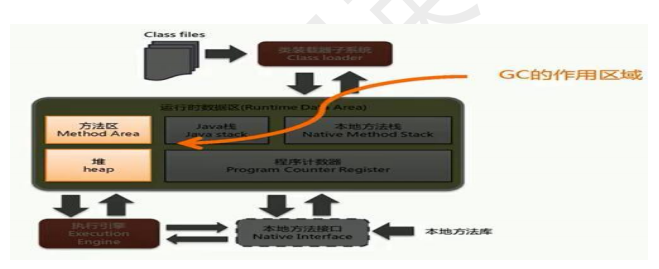
JVM整体组成部分
类加载系统:将硬盘里的字节码加载到内存里
运行时数据区:负责存储运行时的各种数据
执行引擎:将字节码编译为机器码执行
本地方法接口:调用非java的方法,比如hashCode(获取对象的地址)
类加载系统
作用
将硬盘中的字节码加载到内存中(运行时数据区)
类什么时候被加载
1.类里面写了main方法,执行main方法时会调用
2.new这个类的对象
3.反射机制调用时
4.调用这个类的静态成员
那么什么时候不会被加载呢?
1.例子:Hello\[\] hello = new Hello \[\] 此时类就没有被加载,因为创建的是数组对象,Hello这个类只是作为类型
2.访问类里面的静态常量,比如 final static int a = 10; 直接返回静态常量的值
如果是static int a = 10;这是静态变量,也就是类的静态成员,会加载类
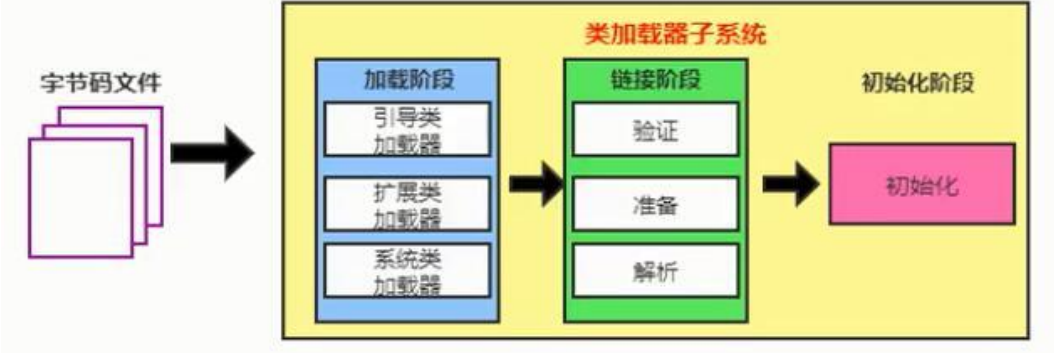
类加载的流程是什么(了解)
加载:以字节流形式读取文件
链接:验证,准备,解析
初始化:主要给静态变量成员赋值
类加载器
类加载器就是加载类的实践者
不同的类是由不同的类加载器加载的
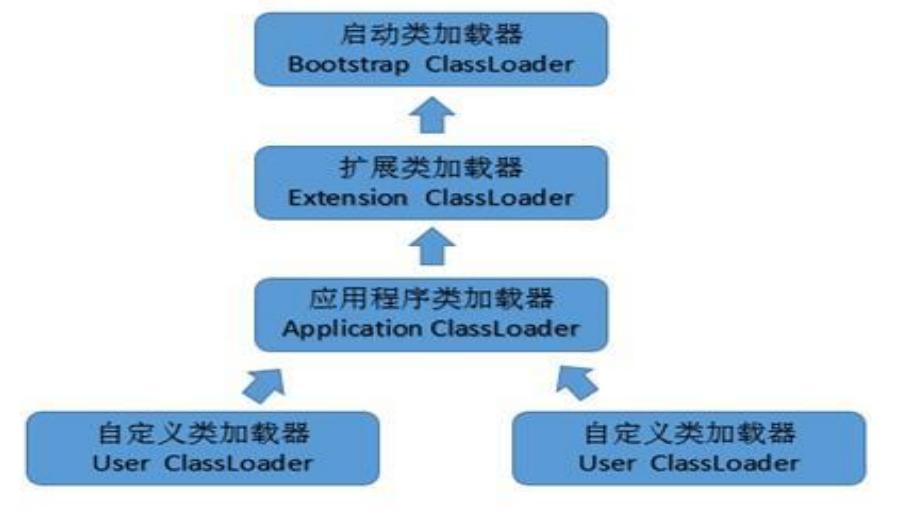
类加载器分为三类:
启动类加载器(引导类加载器):不是用java语言写的,使用c/c++写的,负责加载虚拟机最核心的类库
扩展类加载器:使用Java语言写的
应用程序类加载器:使用Java语言写的,负责加载程序员在项目中写的类(target/class)
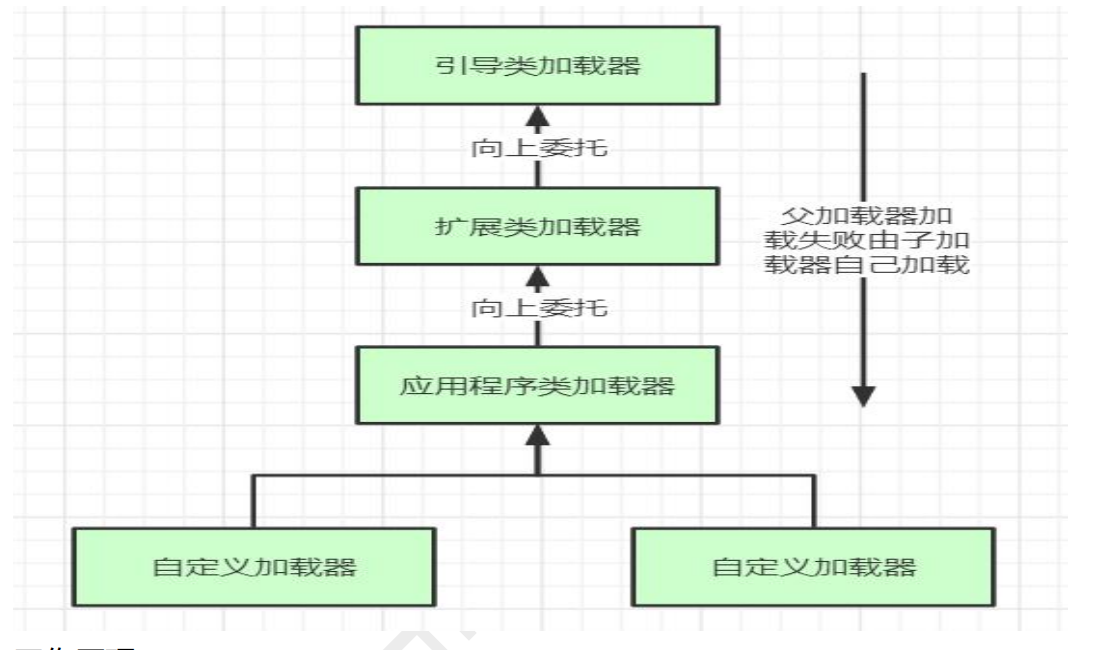
双亲委派机制
当传来类加载的任务时,会优先委派给上级的类加载器加载,依次递归,直到传到最上层的启动类加载器,如果上级类加载器找到类时,成功返回,如果没有,则委派给下一级类加载器,如果找到了,成功返回, 如果没有,则报ClassNotFoundException。
那为什么要设计双亲委派机制呢?
为了安全,避免了自己定义 的类,替换了系统中的核心类
有一个作用是,当我们自己构造了一个java.lang.String类,在双亲委派机制下,会让启动类加载器找到类库中的String类,而不会被我们自己写的String类覆盖。
如何打破双亲委派机制呢?
可以自定义类加载器
运行时数据区
类加载器把类的信息加载到内存时,存储到运行时数据区
根据运行时数据区的不同功能,可以分为五个部分:
程序计数器
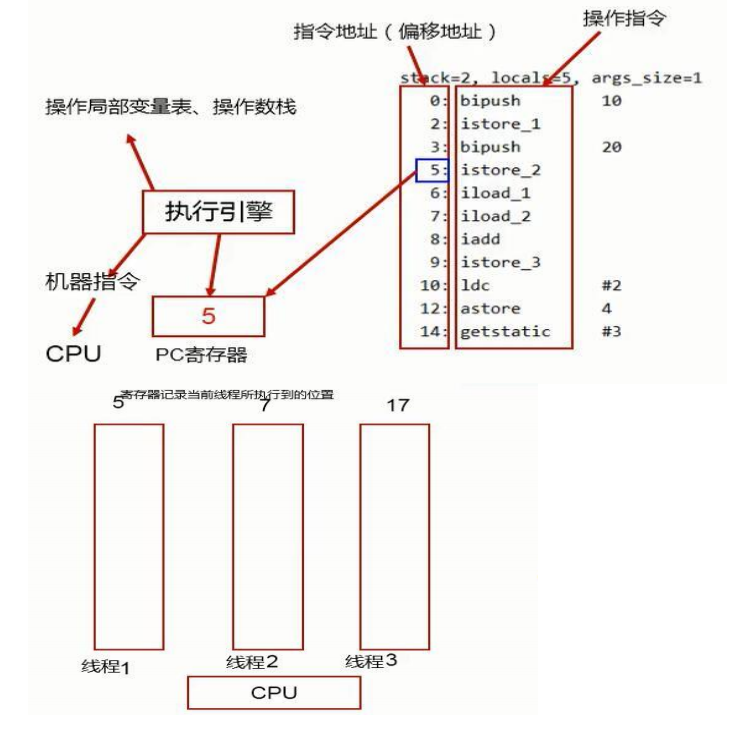
程序计数器是记录线程执行的指令集的位置,因为线程在执行时,CPU要进行切换执行,所以要记录线程执行的位置。 java是高级语言,每一条高级语言要分解成好几条指令执行
特点:
1.程序计数器是占用内存最小的一块区域,也是运行速度最快的区域
2.程序计数器是线程私有的,每个线程都有属于自己的程序计数器,程序计数器的生命周期和线程的生命周期一样
3.程序计数器是运行时数据区唯一一个不会出现内存异常的区域
虚拟机栈
虚拟机栈是运行单位,管理程序如何执行,一个方法被调用,就入栈,运行结束,就出栈
虚拟机主要用来运行Java语言写的方法
特点:
1.线程私有的,每个线程中调用的方法都在线程对应的虚拟机栈中运行
2.A线程的方法无法调用B线程中的方法
3.栈中存储局部变量
4.虚拟机栈中不存在垃圾回收
5.虚拟机栈中存在内存溢出(例如 递归调用太深)
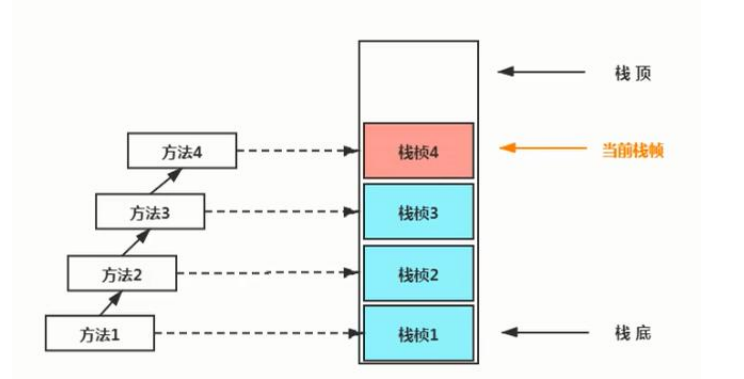
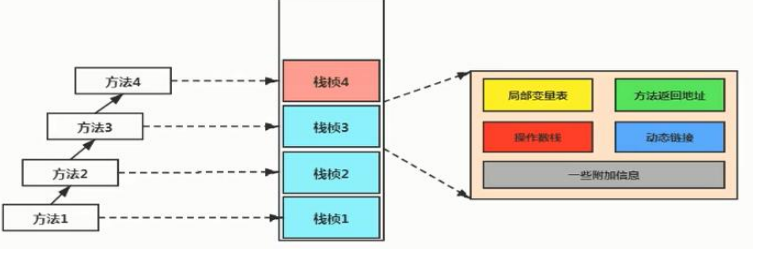
一个方法被压入到虚拟机栈中以后称为栈帧
栈帧的内部结构:
局部变量表(存储局部变量的值)
java
public void test() {
int a=10;//基本类型存储他的值
int b=10;
String s=new String();//引用类型存储他的地址,地址在堆中
}操作数栈:就是用来计算的区域
java
public void test() {
int a=10;//先从局部变量表中拿到a和b 的值
int b=10;
int c = a + b;//然后到操作数栈中进行计算,把运算结果赋给c,然后把写回到局部变量表中
}
本地方法栈
本地方法:在Java程序中,不由Java语言编写的方法
本地方法是由native修饰,没有方法体
因为Java是上层语言(开发上层应用程序),没有权限直接与硬件进行交互(比如读取内存或硬盘中的数据)
本地方法栈:本地方法栈是运行单位,一个本地方法被调用,就入栈,运行结束,就出栈
特点:
1.线程私有
2.没有垃圾回收
3.存在内存溢出情况
堆
堆:用来存储Java中创建的对象
特点:
1.线程共享的
2.可以通过设置参数来改变堆的大小
3.存在内存溢出情况
4.是GC(Garbage Collection)垃圾回收的重点区域
5.是运行时数据区内存最大的一块空间
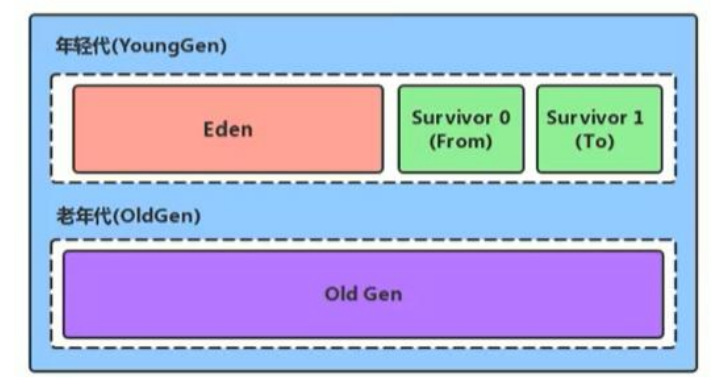
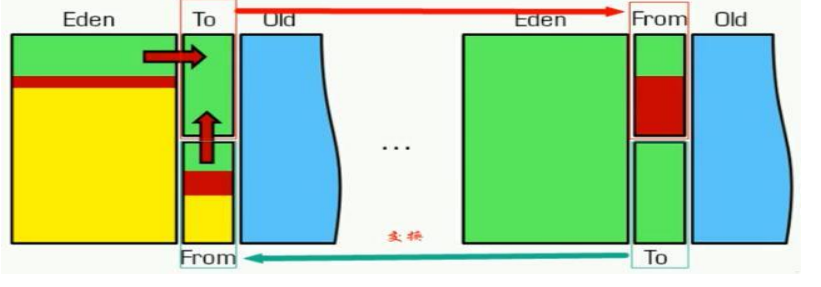
堆内存区域划分
新生代(区):伊甸园区 幸存者0 幸存者1
老年代(区)
为什么要分代(区)
根据对象的存活时间,大小放在不同的区域,不同的区域有不同的垃圾回收算法
会频繁的回收新生代,较少回收老年代
可以对回收算法扬长避短
对象创建分配内存的过程
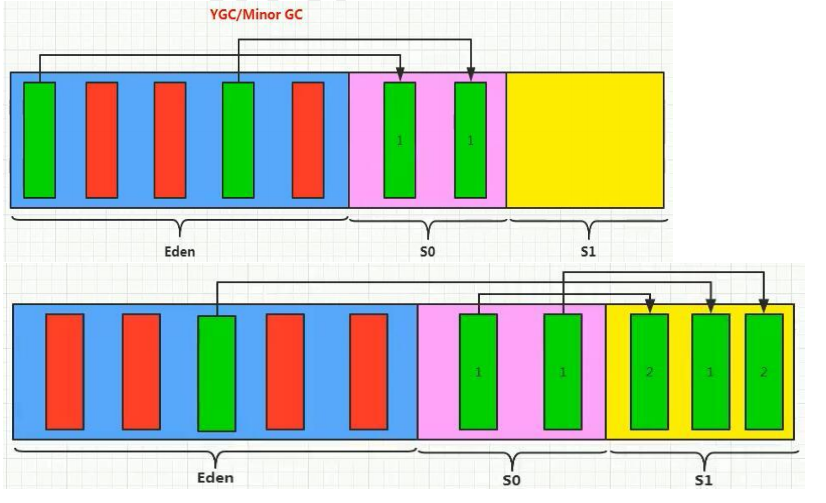
1.第一次创建的对象一般都分在伊甸园区(内存很大的对象会直接分配到老年区)
2.当垃圾回收来临时,伊甸园区没有被回收的对象进入幸存者0区,清空伊甸园区
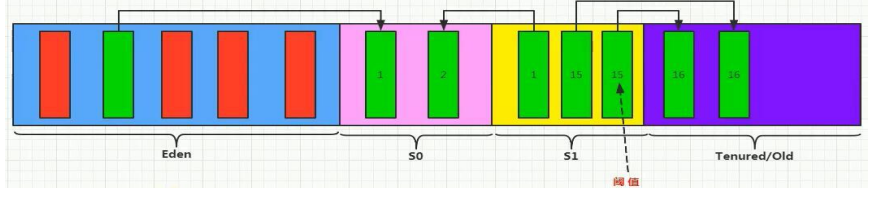
3.当下一次垃圾回收来临时,伊甸园区和幸存者0区没有被回收的对象进入幸存者1区,伊甸园区和幸存者0区被清空
4.当一个对象在经历15词垃圾回收后,他就会进入老年区
堆空间参数:
涉及到jvm调优
理解是要根据实际的需要,来调整jvm中原有的一些参数,比如堆的初始化大小
官网地址:
https://docs.oracle.com/javase/8/docs/technotes/tools/unix/java.html
-XX:+PrintFlagsInitial
查看所有参数的默认初始值
-Xms:初始堆空间内存
-Xmx:最大堆空间内存
-Xmn:设置新生代的大小
-XX:MaxTenuringTreshold:设置新生代垃圾的最大年龄
-XX:+PrintGCDetails 输出详细的 GC 处理日志
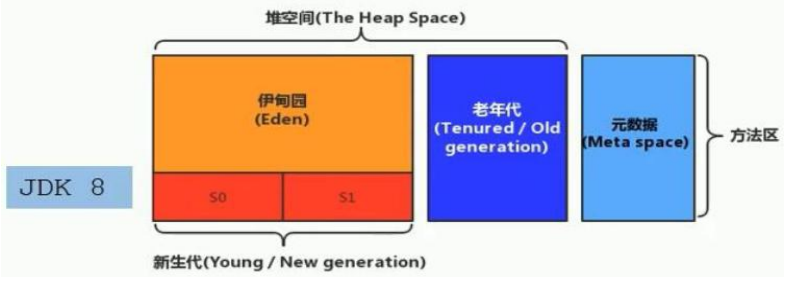
方法区
方法区主要是用来加载类信息的(变量,方法,静态常量...)以及编译器编译后的字节码
特点:
1.方法区也是线程共享的
2.也存在内存溢出情况
3.方法区的大小也是可以设置的,方法区的大小决定 可以加载多少类
方法区的垃圾回收
方法区也存在垃圾回收,主要是回收类信息
但是类信息回收是比较苛刻的:
1.该类以及派生的子类所创建的对象全都已经不再被使用,而且已经被回收了
2.该类的类加载器被回收了
3.该类的Class对象也不存在了,如果Class对象还存在,那么就说明可能该类信息还会被使用
本地方法接口
虚拟机中负责调用本地方法的入口,本地方法在本地方法栈中(运行时数据区)运行
什么是本地方法: 被nativa修饰,没有方法体的方法,是操作系统提供的方法
为什么要调用本地方法:因为Java是上层开发应用程序的语言,无法和计算机的硬件(内存,硬盘,外设(喇 叭))交互,需要用本地操作系统提供的方法
执行引擎(黑盒)
执行引擎在虚拟机中主要负责将虚拟机中的字节码 编译/翻译 成机器码
.java------>jdk(javac)编译------>.class 开发阶段
.class------>执行引擎编译------>机器码 运行阶段
什么是解释器?什么是JIT编译器?
解释器/解释执行: 比如sql,HTML,css,js,python,不需要整体编译,而是由解释器一行一行的执行
特点:执行速度慢,但不需要花费时间编译
编译执行:先把代码整体进行编译,生成另一种文件格式
特点:执行速度快,但需要花费时间编译
jvm的执行引擎在将字节码编译为机器码的时候,采取的是半解释,半编译的机制
开始时,可以先采用解释执行,立即投入到编译工作中
等到编译好之后,采用编译执行
垃圾回收(重点)
什么是垃圾?
垃圾就是内存中已经没有任何引用指向的对象就叫做垃圾对象
如果不对垃圾进行回收,会导致新的对象没有足够的空间存储,进而导致内存溢出(Out Of Memory 简称OOM)
早期的垃圾回收
早期的垃圾回收都是手动释放 malloc() free()
如果忘记回收垃圾。那么就会造成内存泄漏(对象不再使用,但还占据着内存空间)
垃圾回收的重点区域
堆: 频繁回收新生代,较少回收老年代
方法区:虽然回收条件比较苛刻,但是也存在垃圾回收
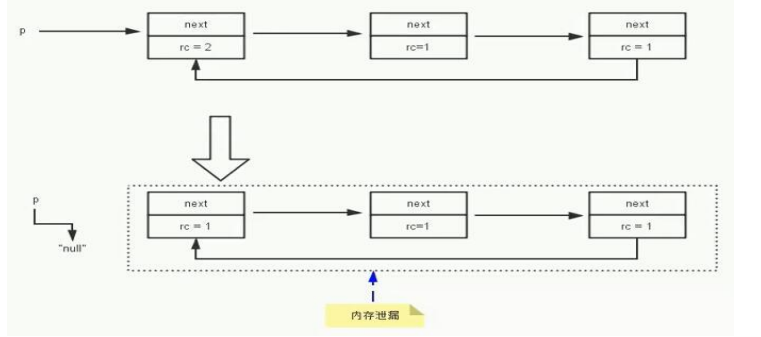
内存溢出和内存泄漏
内存溢出:内存空间不足以运行程序,会报出内存异常(Out Of Memory 简称OOM)---->ERROR 一般程序我
们只能处理异常
内存泄漏:当一些对象已经不再被使用,却没有被回收,会一直占据着内存
比如: 对象中提供了close();方法的对象
1.数据库链接对象
2.Socket链接对象
3.IO读取文件的对象
垃圾回收相关算法
垃圾标记阶段算法
垃圾标记阶段的目的:判断那些对象是垃圾对象
垃圾标记阶段涉及两个算法:引用计数算法(现在的虚拟机中已经不再使用了)
可达性分析算法
引用计数算法
思想:给对象加入一个字段用来记录该对象被引用的数量,有一个引用指向对象,计数器就加一,有一个引用断
开,计数器就减一。
优点:实现思路简单
缺点: 1.会造成额外的时间和空间开销
2.不能解决对象循环引用的问题,比如ABC三个对象循环引用,但是可能与外界没有引用,此时虽然三个对象的计数器都是1 ,但是他们并没有被引用
可达性分析算法(根搜索算法,也可以叫追踪性分析算法)
思想:从一些活跃的对象开始进行搜索,只要和和根对象有关联的对象,就不是垃圾对象,如果和根对象没有关
联,即使和其他对象存在引用关系,也会被判定为垃圾对象。
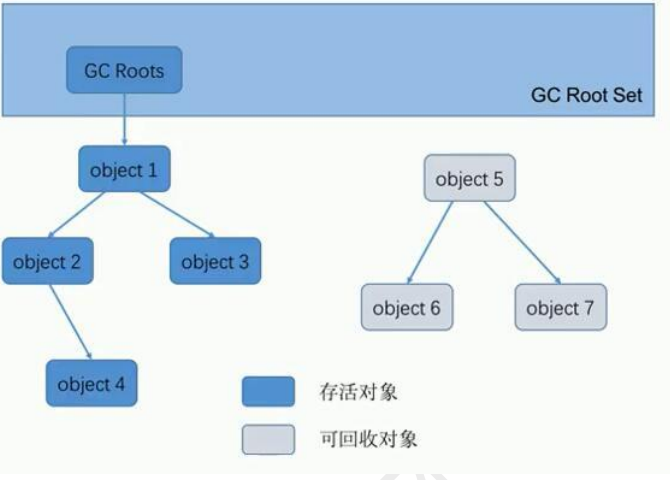
可以成为根对象的对象:
1.虚拟机栈中对象,运行中的方法引用的对象
2.虚拟机内部的Class对象,类加载器,异常类
3.类中的一些静态成员变量
4.与同步锁有关的 对象
对象的finallization机制
主要是Object类中的finalize()方法------------------------------------>final finally finalize区分
finalize方法在对象被判定为垃圾对象之后,在被垃圾回收真正回收之前由虚拟机执行
在finalize中执行最后要执行的功能
finalize只被执行一次
由于finalize()存在,所以对象分为三种状态:
1.可触及的:有引用指向的对象
2.可复活的:已经被判定为垃圾对象,但是还没有被回收,可能在finalize()方法中复活
3.不可触及的:finalize已经被执行过,又被判定为垃圾对象,最后被回收
垃圾回收阶段算法
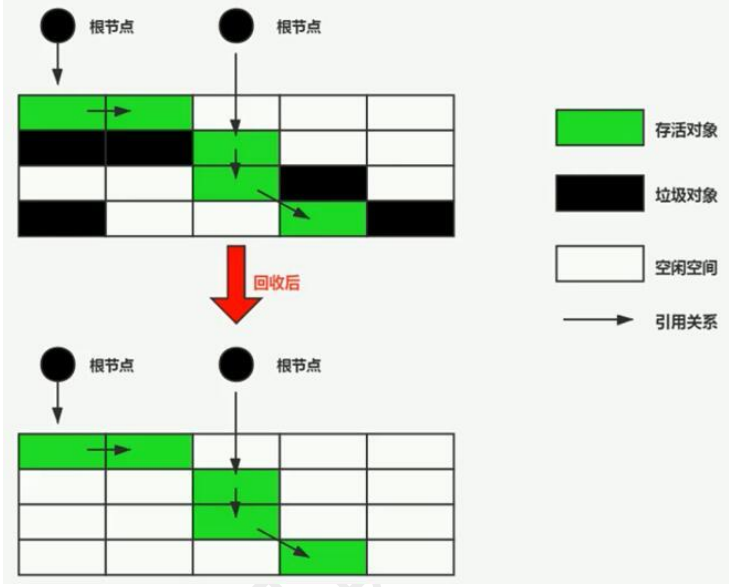
标记-复制算法:
把内存分为几块,把正在使用的内存块的存活对象,复制到另一块内存中,从内存块的位置开始摆放,清空正在使用的内存。
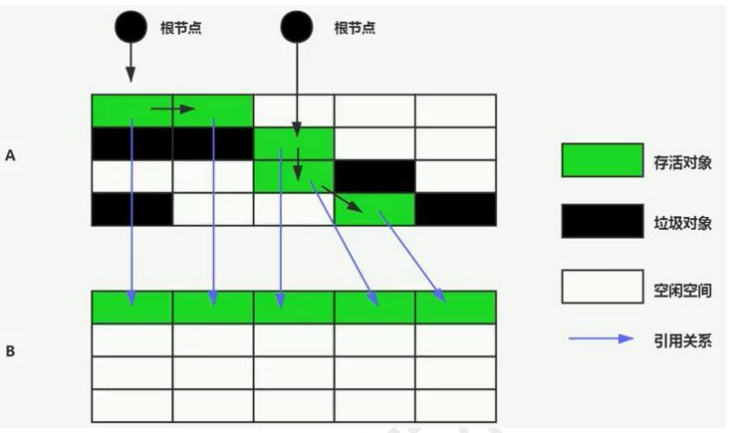
对象会被移动,适合存活对象少,垃圾对象多的情况,特别适合回收新生代的垃圾对象。
标记-清除算法:
存活对象不会被移动,把垃圾对象的地址记录在一个空闲列表中,有新的对象到来时,把新的对象分配到空闲列表中的内存地址上,覆盖垃圾对象。
适合老年代的回收,因为存活对象多且内存占用大,不需要移动对象
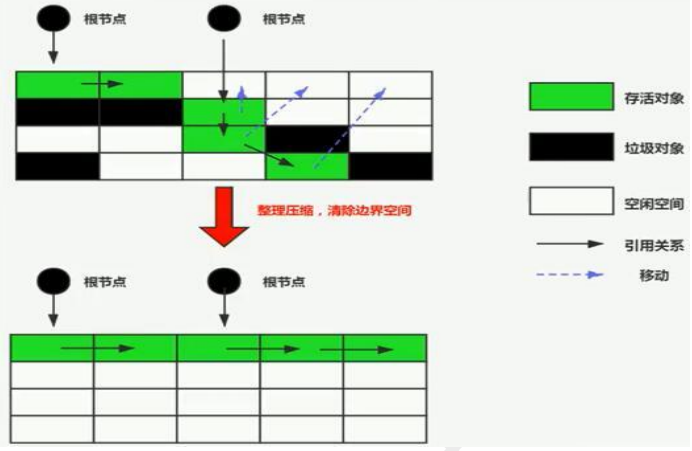
标记-压缩算法:
将存活对象压到内存的一端,重新排列,将边界外的空间清理,释放内存碎片,效果就像进行了一次标记-清除算法之后,进行了一次内存碎片整理。
也是适合老年代的垃圾回收
分代收集
为什么要用分代收集?
垃圾回收器
标记阶段和回收阶段的算法都是理论层面的,而垃圾回收器而垃圾回收的实践者
垃圾回收器分类:
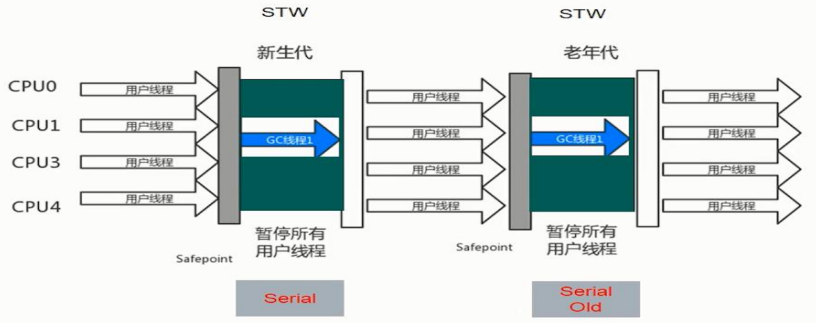
**按照线程数量分:**单线程垃圾回收器------------>只有一个线程进行垃圾回收
多线程垃圾回收器------------>多个线程进行垃圾回收
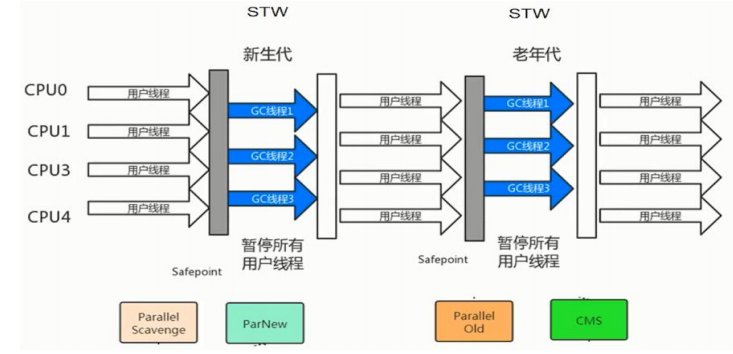
**从工作模式分:**独占式垃圾回收器,当垃圾回收线程执行时,其他的线程会暂时停止执行
(STW ------>stop the world)
并发式垃圾收集器,当垃圾线程执行时,可以允许其他线程并发执行

从回收的空间分:新生代垃圾回收器
老年代垃圾回收器
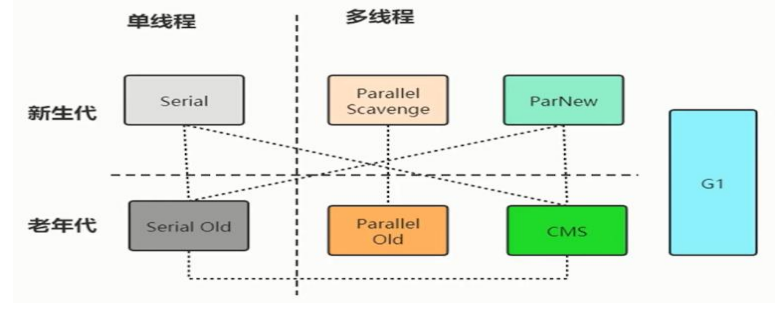
HotSpot 垃圾收集器
图中展示了 7 种作用于不同分代的收集器,如果两个收集器之间存在连线, 则说明它们可以搭
配使用。虚拟机所处的区域则表示它是属于新生代还是老年代 收集器。
Serial,Serial Old,ParNew,Parallel Scavenge,Parallel Old,CMS,G1
两款很重要的垃圾回收器
CMS(Concurrent Mark Sweep, 并发标记清除)
这款垃圾回收器首创了垃圾回收线程和其他线程同时执行
CMS收集器是以获取最短回收停顿 时间为目标的收集器(追求低停顿),它在垃圾收集时使得
用户线程和 GC 线程并发执行,因此在垃圾收集过程中用户也不会感到明显的卡顿。
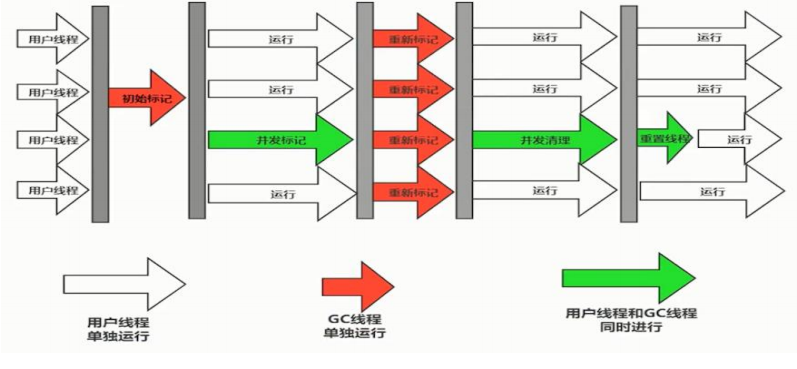
初始标记:垃圾回收线程独占的
并发标记:用户程序线程和垃圾回收线程同时执行
重新标记:垃圾回收线程独占的
并发清理:其他线程和垃圾回收线程同时执行
重置线程:用户程序线程和垃圾回收线程同时执行
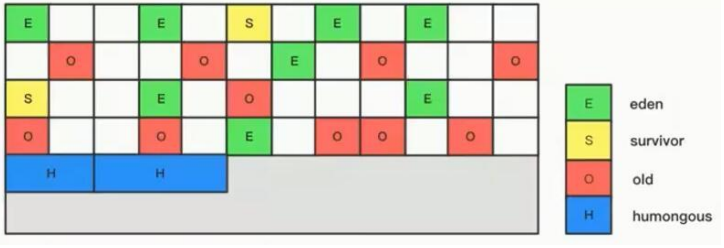
G1(Garbage First)回收器
G1是面向服务器端的垃圾回收器,也继承了CMS中用户线程和垃圾回收线程同时执行的特点
G1 垃圾回收期可以做到对整个堆进行垃圾回收,不再区分新生代,老年代
垃圾回收性能高
为什么叫G1(垃圾优先)
把每个分区又分为若干个小的区域,会对每个小的区域进行跟踪,优先回收垃圾最多的区域
查看 JVM 垃圾回收器设置垃圾回收器
打印默认垃圾回收器
-XX:+PrintCommandLineFlags -version
JDK 8 默认的垃圾回收器
年轻代使用 Parallel Scavenge GC
老年代使用 Parallel Old GC
打印垃圾回收详细信息
-XX:+PrintGCDetails -version
设置默认垃圾回收器
Serial 回收器
-XX:+UseSerialGC 年轻代使用 Serial GC, 老年代使用 Serial Old GC
ParNew 回收器
-XX:+UseParNewGC 年轻代使用 ParNew GC,不影响老年代。
CMS 回收器
-XX:+UseConcMarkSweepGC 老年代使用 CMS GC。
G1 回收器
-XX:+UseG1GC 手动指定使用 G1 收集器执行内存回收任务。
-XX:G1HeapRegionSize 设置每个 Region 的大小。