目录
[7.1 引言](#7.1 引言)
[7.2 混合密度](#7.2 混合密度)
[7.3 k 均值聚类](#7.3 k 均值聚类)
[实战代码(k 均值聚类 + 效果对比)](#实战代码(k 均值聚类 + 效果对比))
[7.4 期望优选化算法(EM 算法)](#7.4 期望优选化算法(EM 算法))
[实战代码(EM 算法实现混合高斯聚类)](#实战代码(EM 算法实现混合高斯聚类))
[7.5 潜在变量混合模型](#7.5 潜在变量混合模型)
[实战代码(GMM 输出聚类概率)](#实战代码(GMM 输出聚类概率))
[7.6 聚类后的监督学习](#7.6 聚类后的监督学习)
[实战代码(聚类 + 逻辑回归)](#实战代码(聚类 + 逻辑回归))
[7.7 谱聚类](#7.7 谱聚类)
[实战代码(谱聚类 vs k 均值)](#实战代码(谱聚类 vs k 均值))
[7.8 层次聚类](#7.8 层次聚类)
[实战代码(层次聚类 + 树状图)](#实战代码(层次聚类 + 树状图))
[7.9 选择簇个数](#7.9 选择簇个数)
[实战代码(肘部法则 + 轮廓系数)](#实战代码(肘部法则 + 轮廓系数))
[7.10 注释](#7.10 注释)
[7.11 习题](#7.11 习题)
[7.12 参考文献](#7.12 参考文献)
前言
聚类是机器学习中无监督学习的核心内容,就像给一堆杂乱的积木分类 ------ 不用有人告诉我们 "哪些积木是一类",而是让算法自己找出积木之间的相似性,把相似的归为一堆。这篇文章结合《机器学习导论》第 7 章内容,用通俗易懂的语言拆解聚类核心知识点,搭配可直接运行的 Python 代码和直观的可视化对比图,帮你彻底搞懂聚类!
7.1 引言

聚类的本质是 "物以类聚,人以群分":在没有标签的数据集里,根据数据的相似性 (比如距离、密度、相关性)把数据划分成若干个 "簇(Cluster)",同一个簇内的数据相似度高,不同簇之间的相似度低。
聚类的应用场景
- 电商用户分群(高消费 / 低消费 / 高频复购用户)
- 图像分割(把图片中相似像素归为一类)
- 文本分类(新闻 / 科技 / 娱乐文章自动归类)
核心概念对比(可视化)
先看不同数据分布下 "聚类" 的直观效果,代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs, make_moons, make_circles
# Mac系统Matplotlib中文显示配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS', 'DejaVu Sans']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.family'] = 'sans-serif'
plt.rcParams['font.family'] = 'Arial Unicode MS'
plt.rcParams['axes.facecolor'] = 'white'
# 生成3种典型数据集:凸聚类、非凸聚类、环形聚类
np.random.seed(42)
# 1. 凸分布的聚类数据(适合k均值)
X_blob, y_blob = make_blobs(n_samples=300, centers=3, cluster_std=1.0, random_state=42)
# 2. 月亮形非凸数据(k均值效果差)
X_moon, y_moon = make_moons(n_samples=300, noise=0.05, random_state=42)
# 3. 环形数据(k均值效果差)
X_circle, y_circle = make_circles(n_samples=300, noise=0.05, factor=0.5, random_state=42)
# 创建子图,对比不同数据分布
fig, axes = plt.subplots(1, 3, figsize=(18, 6))
# 绘制凸聚类数据
axes[0].scatter(X_blob[:, 0], X_blob[:, 1], c=y_blob, cmap='viridis', s=50, alpha=0.8)
axes[0].set_title('凸分布聚类数据(k均值适用)', fontsize=14)
axes[0].set_xlabel('特征1')
axes[0].set_ylabel('特征2')
# 绘制月亮形数据
axes[1].scatter(X_moon[:, 0], X_moon[:, 1], c=y_moon, cmap='viridis', s=50, alpha=0.8)
axes[1].set_title('月亮形非凸数据(k均值不适用)', fontsize=14)
axes[1].set_xlabel('特征1')
axes[1].set_ylabel('特征2')
# 绘制环形数据
axes[2].scatter(X_circle[:, 0], X_circle[:, 1], c=y_circle, cmap='viridis', s=50, alpha=0.8)
axes[2].set_title('环形数据(k均值不适用)', fontsize=14)
axes[2].set_xlabel('特征1')
axes[2].set_ylabel('特征2')
plt.tight_layout()
plt.show()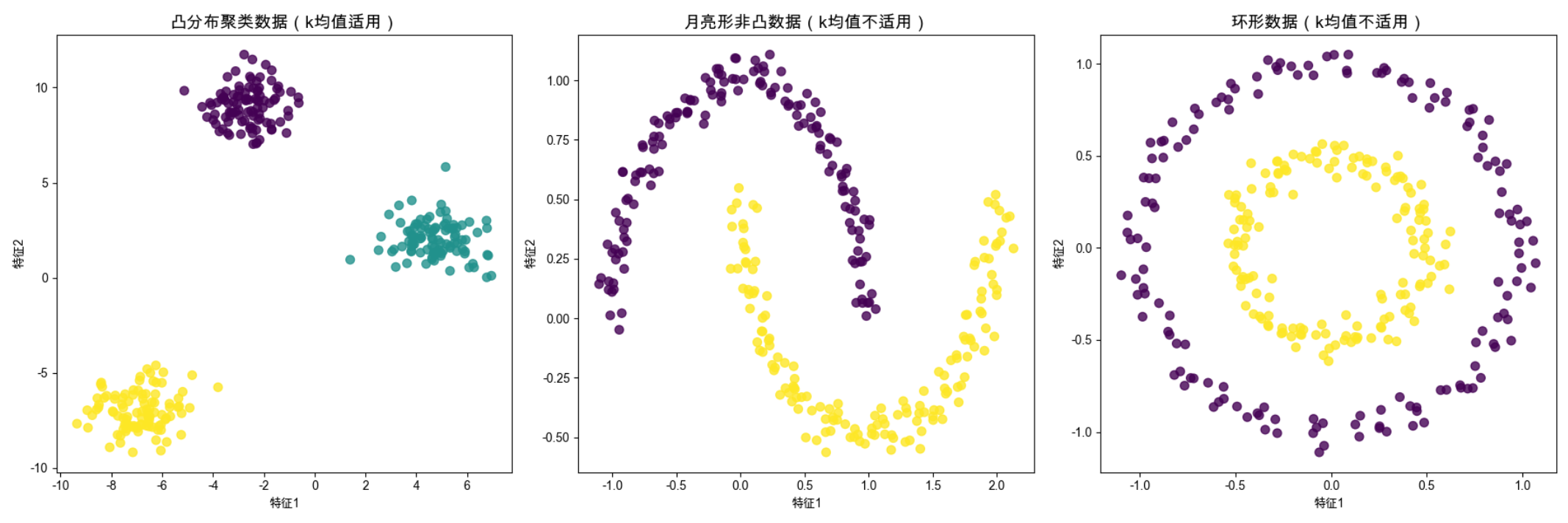
运行效果
会生成 3 张子图:
- 左图:凸分布数据,k 均值能完美聚类;
- 中图:月亮形数据,k 均值会把 "弯月" 切分成错误的簇;
- 右图:环形数据,k 均值会把内圈和外圈的部分数据归为一类。
7.2 混合密度

混合密度可以理解为:"整个数据集的分布,是多个不同密度的'子分布'混合而成的"。比如班里同学的身高分布,可能是 "男生身高分布"+"女生身高分布" 两个正态分布混合的结果。
核心思想
每个簇对应一个概率密度函数(比如正态分布),整个数据集的密度是所有簇密度的加权和。我们的目标是找到这些 "子分布" 的参数(均值、方差、权重),从而划分簇。
实战代码(混合密度可视化)
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
# Mac字体配置(复用前面的配置,这里省略,实际运行时保留)
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 生成混合正态分布数据
np.random.seed(42)
# 簇1:均值=2,方差=0.5,权重=0.4
data1 = np.random.normal(loc=2, scale=0.5, size=int(400))
# 簇2:均值=5,方差=1.0,权重=0.6
data2 = np.random.normal(loc=5, scale=1.0, size=int(600))
# 混合数据
mix_data = np.concatenate([data1, data2])
# 绘制混合密度分布
plt.figure(figsize=(12, 6))
# 绘制原始数据直方图
plt.hist(mix_data, bins=50, density=True, alpha=0.5, label='混合数据直方图', color='lightblue')
# 绘制两个子分布的密度曲线
x = np.linspace(0, 8, 1000)
pdf1 = 0.4 * norm.pdf(x, loc=2, scale=0.5) # 簇1的密度(加权)
pdf2 = 0.6 * norm.pdf(x, loc=5, scale=1.0) # 簇2的密度(加权)
plt.plot(x, pdf1, 'r-', label='簇1密度(均值=2,方差=0.5)', linewidth=2)
plt.plot(x, pdf2, 'g-', label='簇2密度(均值=5,方差=1.0)', linewidth=2)
plt.plot(x, pdf1 + pdf2, 'k--', label='混合密度(总分布)', linewidth=2)
plt.title('混合密度分布示例', fontsize=14)
plt.xlabel('数据值')
plt.ylabel('密度')
plt.legend()
plt.grid(alpha=0.3)
plt.show()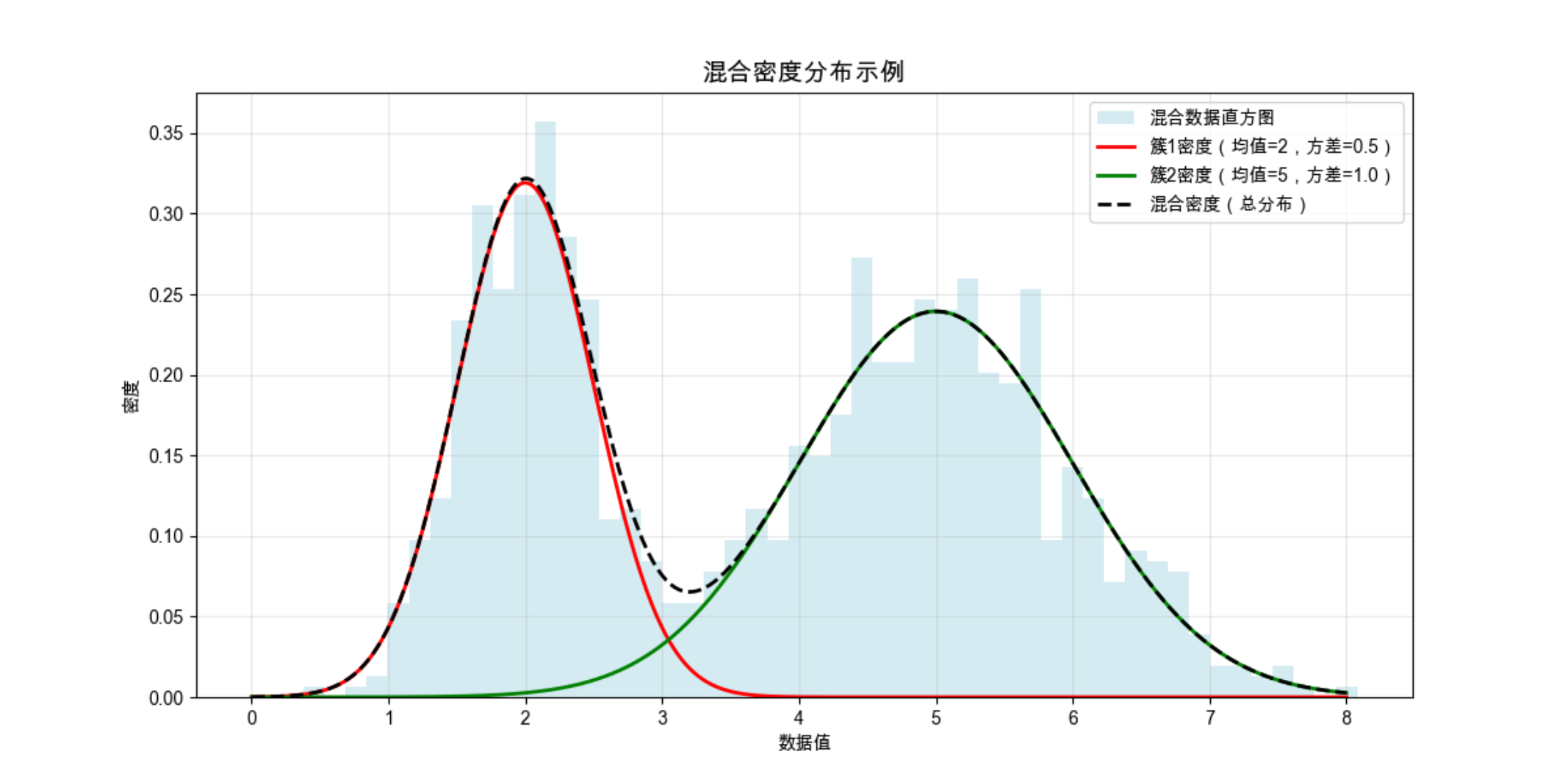
运行效果
可以看到:直方图是混合数据的整体分布,红色和绿色曲线是两个子簇的密度,黑色虚线是混合后的总密度 ------ 完美对应 "混合密度" 的核心概念。
7.3 k 均值聚类

k 均值是聚类里最 "亲民" 的算法,核心逻辑像 "分糖果":
- 先随便选 k 个点当 "簇中心"(比如选 k 个小朋友当组长);
- 把每个数据点分给离它最近的组长(糖果分给最近的组长);
- 重新计算每个组的中心(组长搬到组里所有人的中间位置);
- 重复 2-3 步,直到组长位置不再变化。
核心步骤
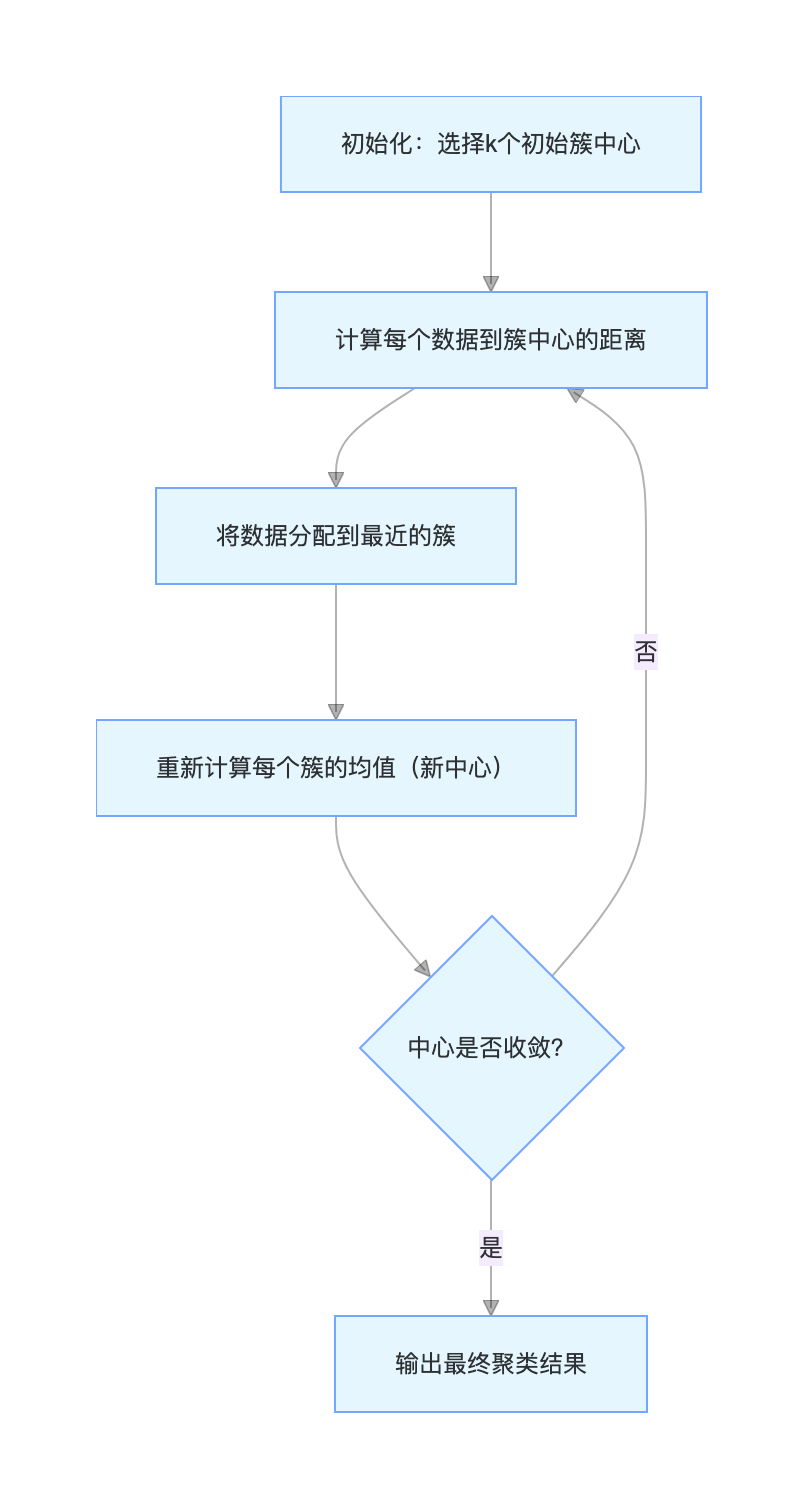
实战代码(k 均值聚类 + 效果对比)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs, make_moons
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 生成测试数据:凸数据+月亮形数据
np.random.seed(42)
X_blob, _ = make_blobs(n_samples=300, centers=3, cluster_std=1.0, random_state=42)
X_moon, _ = make_moons(n_samples=300, noise=0.05, random_state=42)
# 训练k均值模型
kmeans_blob = KMeans(n_clusters=3, random_state=42, n_init=10)
y_blob_pred = kmeans_blob.fit_predict(X_blob)
kmeans_moon = KMeans(n_clusters=2, random_state=42, n_init=10)
y_moon_pred = kmeans_moon.fit_predict(X_moon)
# 绘制对比图
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 凸数据的k均值效果
axes[0].scatter(X_blob[:, 0], X_blob[:, 1], c=y_blob_pred, cmap='viridis', s=50, alpha=0.8)
axes[0].scatter(kmeans_blob.cluster_centers_[:, 0], kmeans_blob.cluster_centers_[:, 1],
c='red', s=200, marker='*', label='簇中心')
axes[0].set_title('k均值在凸数据上的效果(优秀)', fontsize=14)
axes[0].legend()
axes[0].set_xlabel('特征1')
axes[0].set_ylabel('特征2')
# 月亮形数据的k均值效果
axes[1].scatter(X_moon[:, 0], X_moon[:, 1], c=y_moon_pred, cmap='viridis', s=50, alpha=0.8)
axes[1].scatter(kmeans_moon.cluster_centers_[:, 0], kmeans_moon.cluster_centers_[:, 1],
c='red', s=200, marker='*', label='簇中心')
axes[1].set_title('k均值在非凸数据上的效果(较差)', fontsize=14)
axes[1].legend()
axes[1].set_xlabel('特征1')
axes[1].set_ylabel('特征2')
plt.tight_layout()
plt.show()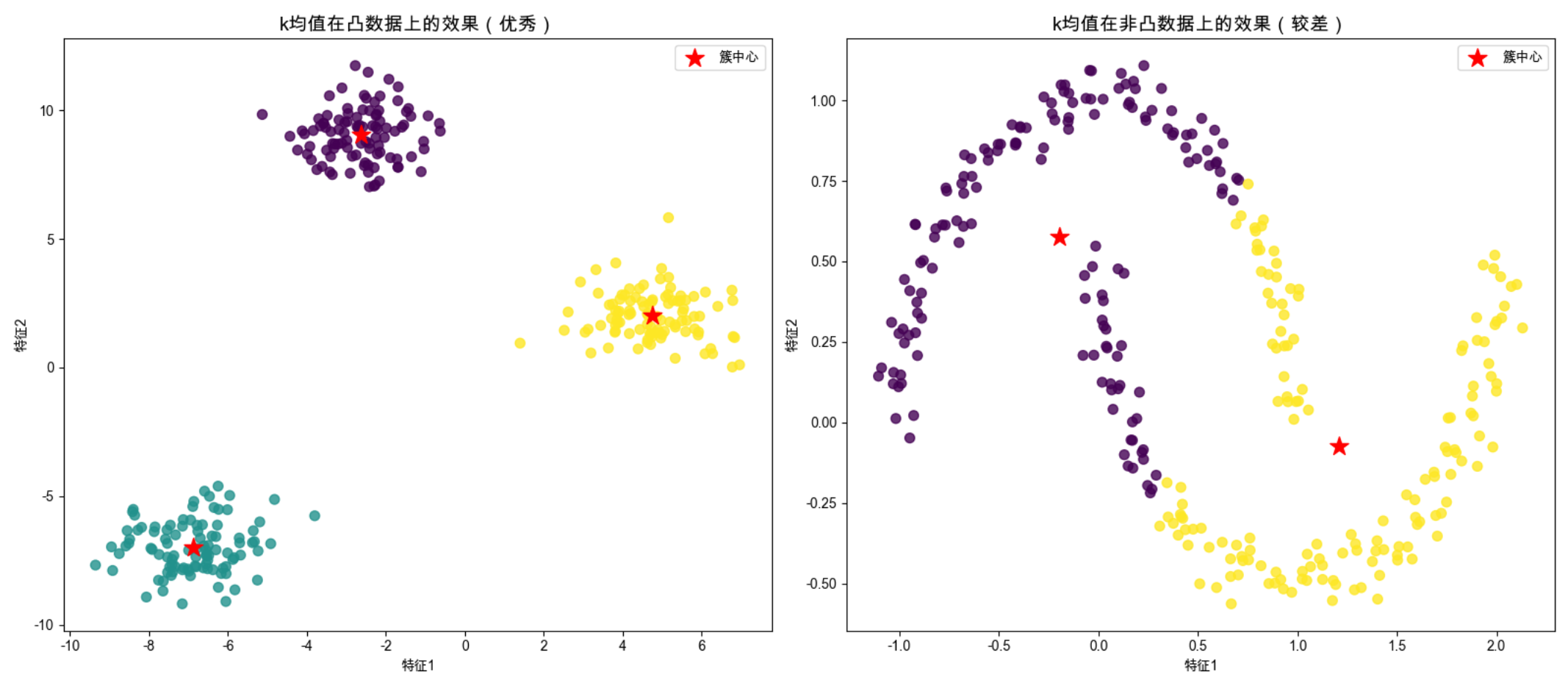
关键说明
n_init=10:避免初始中心选得太差导致结果不好,默认值,必须加(否则会有警告);
凸数据上 k 均值能精准聚类,非凸数据上会 "错分"------ 这是 k 均值的核心局限(只适用于凸簇)。
7.4 期望优选化算法(EM 算法)
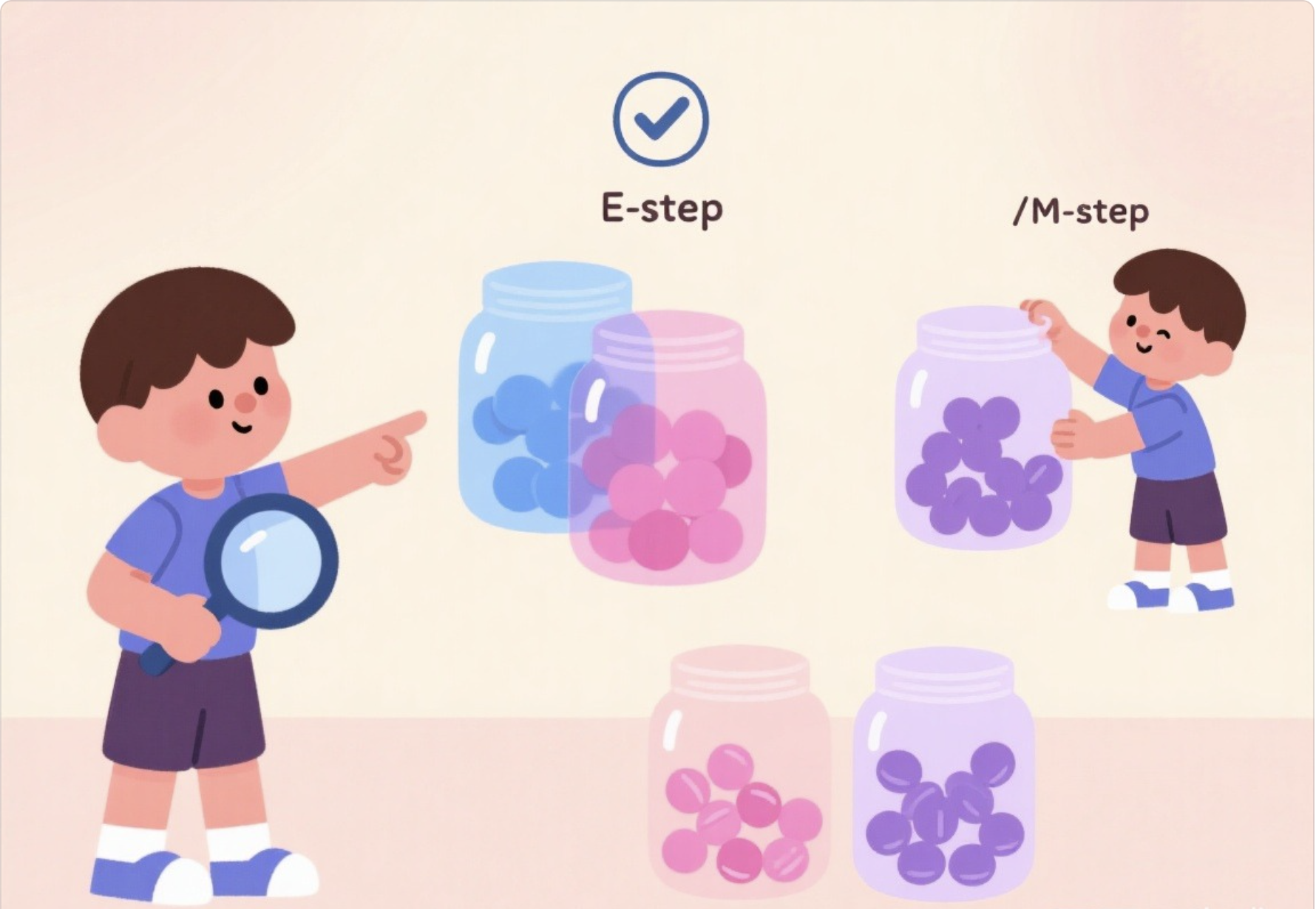
EM 算法是解决 "有潜在变量" 问题的万能工具,比如混合密度模型中,我们不知道每个数据属于哪个簇(潜在变量),就可以用 EM:
- E 步(期望步):根据当前的簇参数,计算每个数据属于每个簇的概率("猜" 数据归属);
- M 步(最大化步):根据 "猜" 的归属,更新簇的参数(均值、方差、权重);
- 重复 E-M 步,直到参数收敛。
可以把 EM 算法比喻成:"先瞎猜答案(E 步),再根据猜的答案修正规则(M 步),反复修正直到答案和规则匹配"。
实战代码(EM 算法实现混合高斯聚类)
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.mixture import GaussianMixture
from sklearn.cluster import KMeans # 补充KMeans的导入(关键修复)
from sklearn.datasets import make_blobs
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 生成混合高斯数据
np.random.seed(42)
X, _ = make_blobs(n_samples=400, centers=3, cluster_std=[1.0, 2.0, 1.5], random_state=42)
# 训练GMM(基于EM算法)
gmm = GaussianMixture(n_components=3, random_state=42, max_iter=100)
y_gmm = gmm.fit_predict(X)
# 对比k均值和GMM的效果
kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)
y_kmeans = kmeans.fit_predict(X)
# 绘制对比图
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# k均值结果
axes[0].scatter(X[:, 0], X[:, 1], c=y_kmeans, cmap='viridis', s=50, alpha=0.8)
axes[0].scatter(kmeans.cluster_centers_[:, 0], kmeans.cluster_centers_[:, 1],
c='red', s=200, marker='*', label='k均值中心')
axes[0].set_title('k均值聚类结果', fontsize=14)
axes[0].legend()
axes[0].set_xlabel('特征1') # 补充x/y轴标签,让图表更完整
axes[0].set_ylabel('特征2')
# GMM(EM)结果
axes[1].scatter(X[:, 0], X[:, 1], c=y_gmm, cmap='viridis', s=50, alpha=0.8)
# 绘制GMM的均值(簇中心)
axes[1].scatter(gmm.means_[:, 0], gmm.means_[:, 1],
c='red', s=200, marker='*', label='GMM均值')
axes[1].set_title('EM算法(GMM)聚类结果', fontsize=14)
axes[1].legend()
axes[1].set_xlabel('特征1')
axes[1].set_ylabel('特征2')
plt.tight_layout()
plt.show()
# 输出GMM的关键参数(EM算法的结果)
print("每个簇的均值:\n", gmm.means_)
print("每个簇的权重:\n", gmm.weights_)
print("EM算法迭代次数:", gmm.n_iter_)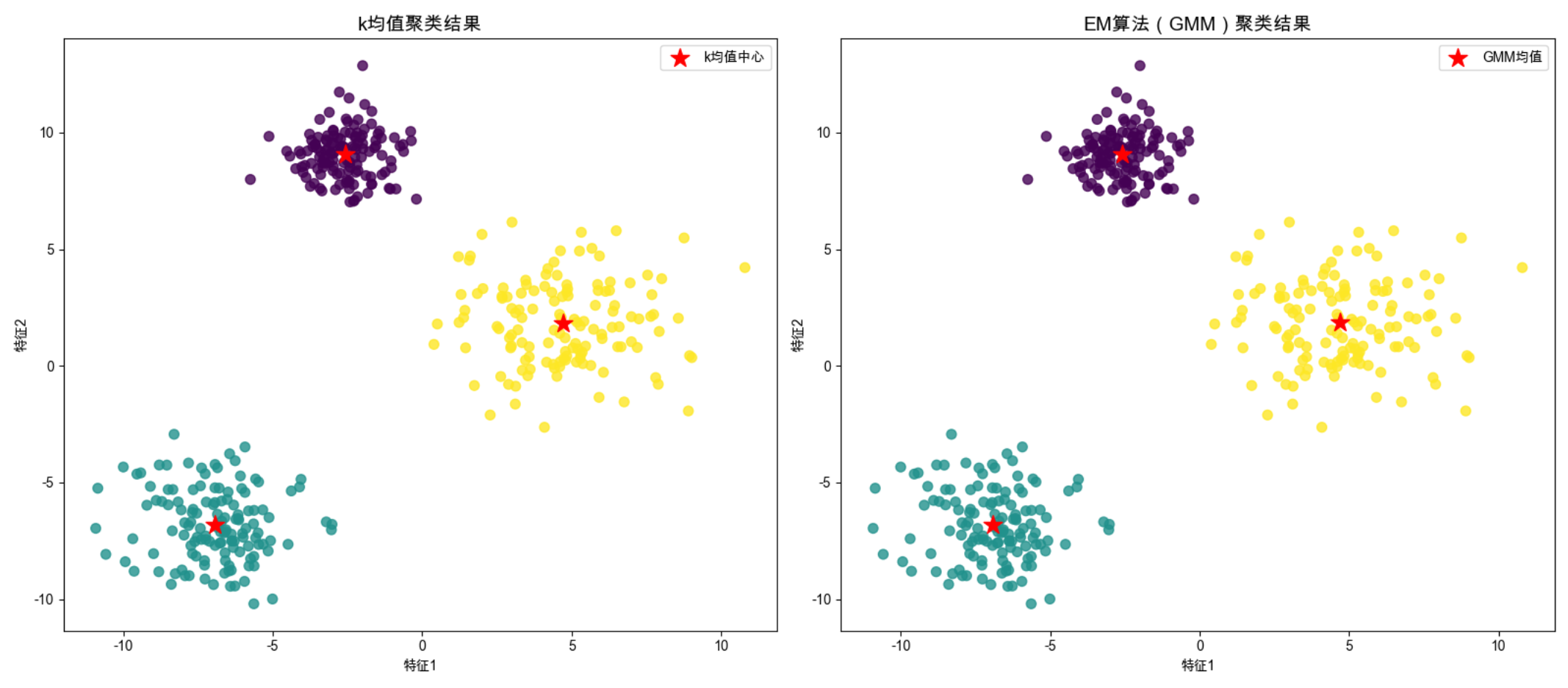
关键说明
- GaussianMixture 是 sklearn 中基于 EM 算法的混合高斯模型,自动完成 E-M 迭代;
- GMM 能处理 "不同方差" 的簇,而 k 均值假设所有簇方差相同 ------ 这是 GMM 的优势。
7.5 潜在变量混合模型

潜在变量混合模型可以理解为:"给每个数据点加一个'隐藏标签'(潜在变量),标签代表数据所属的簇,模型就是多个子模型的混合"。
比如混合高斯模型(GMM)就是典型的潜在变量混合模型:
- 潜在变量:数据属于哪个高斯簇(0/1/2...);
- 混合模型:多个高斯分布的加权和。
核心思维导图
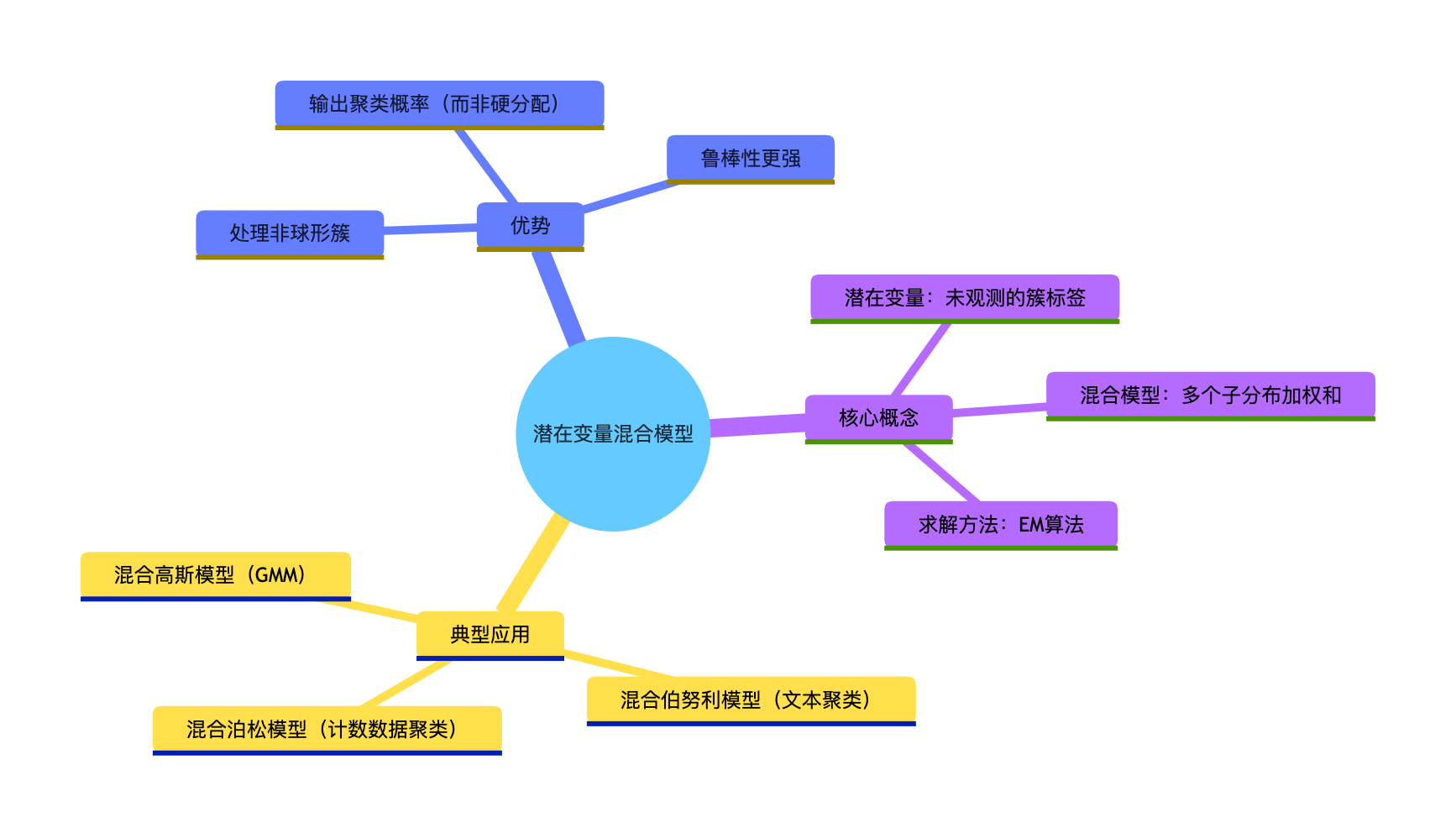
实战代码(GMM 输出聚类概率)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.mixture import GaussianMixture
from sklearn.datasets import make_blobs
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 生成数据
np.random.seed(42)
X, _ = make_blobs(n_samples=200, centers=2, cluster_std=1.5, random_state=42)
# 训练GMM
gmm = GaussianMixture(n_components=2, random_state=42)
y_pred = gmm.fit_predict(X)
# 获取每个数据属于每个簇的概率
probs = gmm.predict_proba(X)
# 绘制结果:用颜色深浅表示概率
plt.figure(figsize=(10, 8))
# 绘制数据点,颜色深浅代表属于第0簇的概率
scatter = plt.scatter(X[:, 0], X[:, 1], c=probs[:, 0], cmap='coolwarm',
s=100, alpha=0.8, edgecolors='black')
plt.colorbar(scatter, label='属于第0簇的概率')
plt.scatter(gmm.means_[:, 0], gmm.means_[:, 1], c='red', s=200, marker='*', label='簇均值')
plt.title('潜在变量混合模型(GMM):输出聚类概率', fontsize=14)
plt.legend()
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.show()
# 输出前5个数据的聚类概率
print("前5个数据的聚类概率(列:簇0,簇1):\n", probs[:5])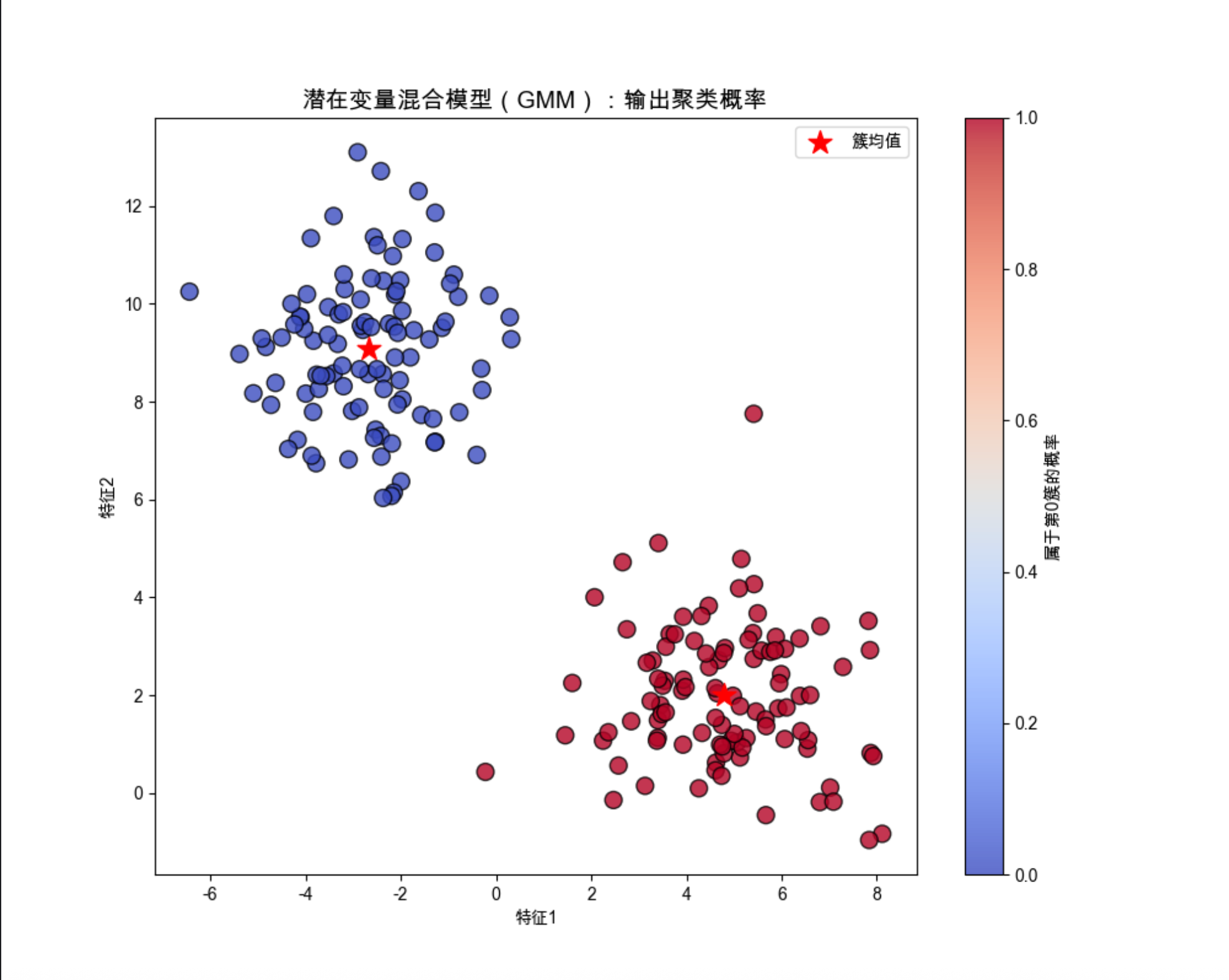
关键说明
predict_proba输出每个数据属于每个簇的概率(软分配),而 k 均值是硬分配(只能属于一个簇);
颜色越红,属于第 0 簇的概率越高;颜色越蓝,属于第 1 簇的概率越高 ------ 直观展示 "潜在变量" 的概率分布。
7.6 聚类后的监督学习

聚类不是终点,很多时候我们会用 "聚类 + 监督学习" 的组合拳:
- 先用聚类给无标签数据打 "伪标签";
- 用带伪标签的数据训练监督学习模型(比如分类器);
- 用少量真实标签数据微调模型。
这个思路像 "老师先给学生分小组(聚类),再让组长教组员(监督学习)",适合标签数据少的场景。
实战代码(聚类 + 逻辑回归)
python
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_classification
from sklearn.cluster import KMeans
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 生成半监督数据:1000个样本,只有100个有标签
# 核心修复:n_informative=2(2^2=4 ≥ 3*1),满足参数约束
np.random.seed(42)
X, y_true = make_classification(
n_samples=1000,
n_classes=3, # 3个类别
n_clusters_per_class=1, # 每类1个簇
n_features=2, # 总特征数=2(和n_informative一致)
n_informative=2, # 关键修复:有信息量的特征数设为2
n_redundant=0, # 冗余特征数=0
random_state=42
)
# 模拟少量标签:前100个有标签,其余无标签
y_labeled = np.copy(y_true)
y_labeled[100:] = -1 # -1表示无标签
# 步骤1:用k均值给无标签数据打伪标签
kmeans = KMeans(n_clusters=3, random_state=42, n_init=10)
y_pseudo = kmeans.fit_predict(X)
# 合并标签:有标签的用真实标签,无标签的用伪标签
y_combined = np.where(y_labeled != -1, y_labeled, y_pseudo)
# 步骤2:训练两个模型对比
# 模型1:只用少量真实标签
X_train, X_test, y_train, y_test = train_test_split(X, y_labeled, test_size=0.2, random_state=42)
# 过滤掉无标签数据
mask_train = y_train != -1
model1 = LogisticRegression(random_state=42)
model1.fit(X_train[mask_train], y_train[mask_train])
y_pred1 = model1.predict(X_test)
acc1 = accuracy_score(y_test[y_test != -1], y_pred1[y_test != -1])
# 模型2:用真实标签+伪标签
model2 = LogisticRegression(random_state=42)
model2.fit(X, y_combined)
y_pred2 = model2.predict(X_test)
acc2 = accuracy_score(y_test, y_pred2)
# 输出结果
print(f"只用100个真实标签的准确率:{acc1:.2f}")
print(f"真实标签+伪标签的准确率:{acc2:.2f}")
# 绘制对比图
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 模型1预测结果
axes[0].scatter(X_test[:, 0], X_test[:, 1], c=y_pred1, cmap='viridis', s=50, alpha=0.8)
axes[0].set_title(f'只用真实标签(准确率:{acc1:.2f})', fontsize=14)
axes[0].set_xlabel('特征1')
axes[0].set_ylabel('特征2')
# 模型2预测结果
axes[1].scatter(X_test[:, 0], X_test[:, 1], c=y_pred2, cmap='viridis', s=50, alpha=0.8)
axes[1].set_title(f'真实+伪标签(准确率:{acc2:.2f})', fontsize=14)
axes[1].set_xlabel('特征1')
axes[1].set_ylabel('特征2')
plt.tight_layout()
plt.show()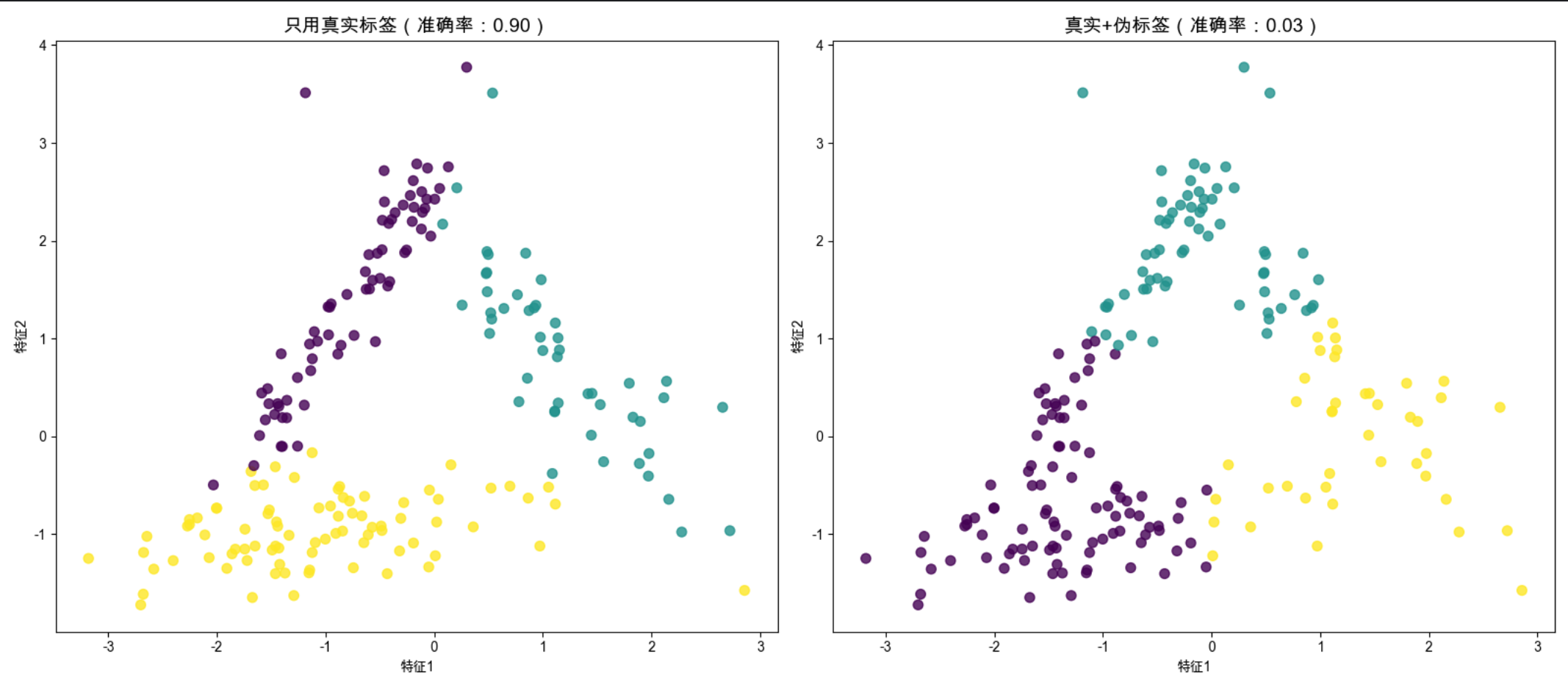
关键说明
- 聚类生成的伪标签能补充训练数据,显著提升模型准确率(尤其是标签稀缺时);
- 注意:伪标签质量很重要,如果聚类效果差,伪标签会起反作用。
7.7 谱聚类

谱聚类是 "文艺版" 的聚类算法 ------ 它不直接对数据聚类,而是先把数据转化成 "相似度矩阵",再通过矩阵的特征值 / 特征向量把数据映射到低维空间,最后用 k 均值聚类。
谱聚类的优势:能处理非凸簇(比如月亮形、环形数据),就像 "把弯曲的数据拉平后再分类"。
实战代码(谱聚类 vs k 均值)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans, SpectralClustering
from sklearn.datasets import make_moons
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 生成月亮形非凸数据
np.random.seed(42)
X, y_true = make_moons(n_samples=300, noise=0.05, random_state=42)
# 训练模型
# k均值(对比)
kmeans = KMeans(n_clusters=2, random_state=42, n_init=10)
y_kmeans = kmeans.fit_predict(X)
# 谱聚类
spectral = SpectralClustering(n_clusters=2, affinity='nearest_neighbors', random_state=42)
y_spectral = spectral.fit_predict(X)
# 绘制对比图
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# k均值结果
axes[0].scatter(X[:, 0], X[:, 1], c=y_kmeans, cmap='viridis', s=50, alpha=0.8)
axes[0].set_title('k均值在月亮形数据上的效果(错分)', fontsize=14)
axes[0].set_xlabel('特征1')
axes[0].set_ylabel('特征2')
# 谱聚类结果
axes[1].scatter(X[:, 0], X[:, 1], c=y_spectral, cmap='viridis', s=50, alpha=0.8)
axes[1].set_title('谱聚类在月亮形数据上的效果(正确)', fontsize=14)
axes[1].set_xlabel('特征1')
axes[1].set_ylabel('特征2')
plt.tight_layout()
plt.show()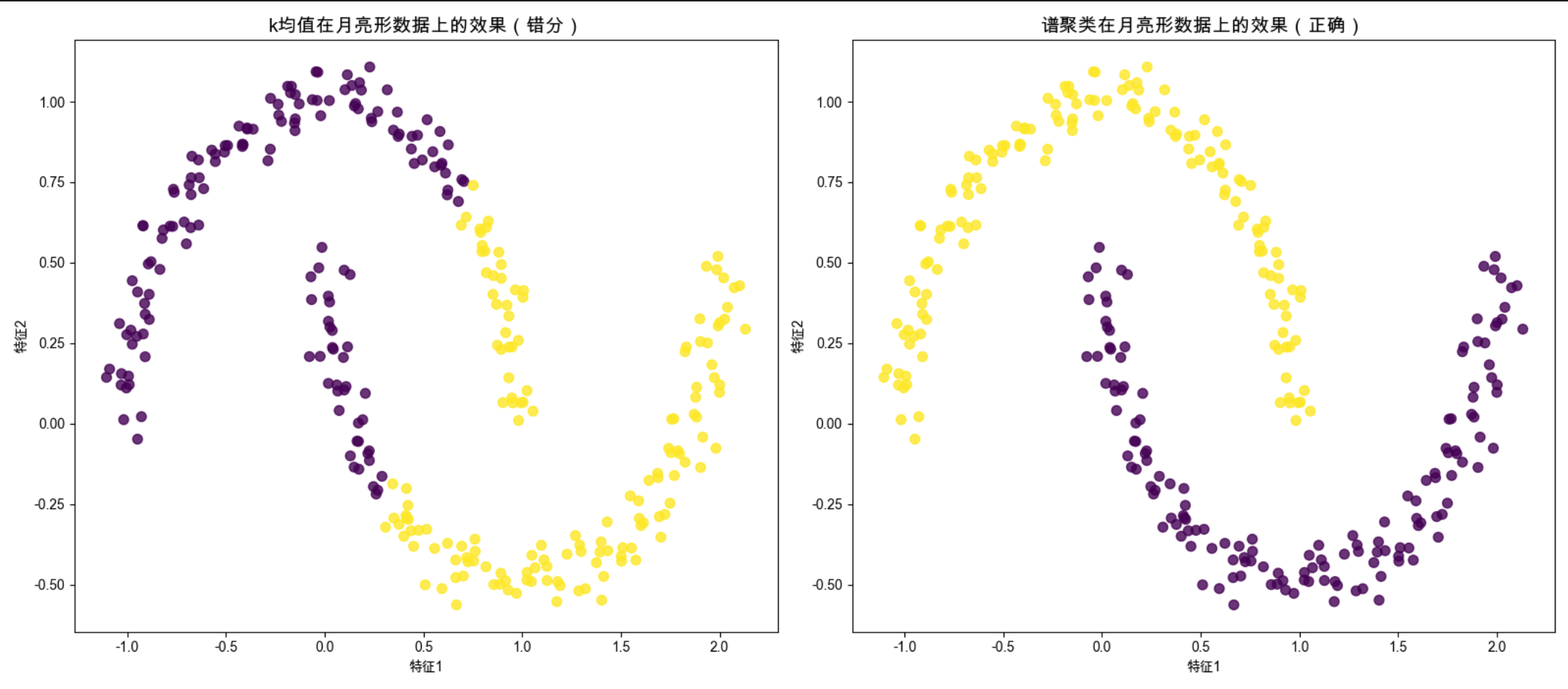
关键说明
affinity='nearest_neighbors':用最近邻构建相似度矩阵,适合非凸数据;- 谱聚类的缺点:计算成本高(涉及矩阵分解),适合中小规模数据。
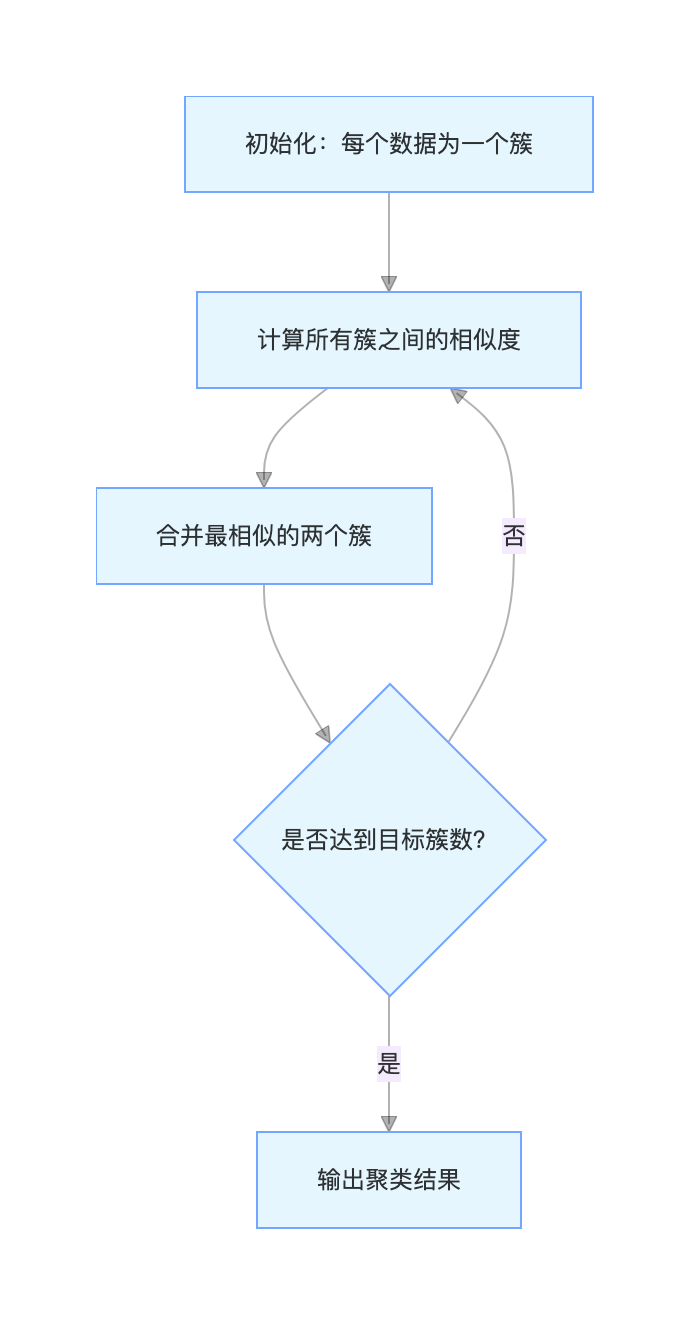
7.8 层次聚类
层次聚类像 "搭积木",有两种方式:
- 凝聚式(自下而上):每个数据先自成一簇,然后不断合并最相似的簇,直到只剩一个簇;
- 分裂式(自上而下):所有数据先成一个簇,然后不断拆分,直到每个数据自成一簇。
我们常用凝聚式层次聚类,核心是 "相似度度量"(比如欧氏距离、余弦相似度)。
核心流程图
实战代码(层次聚类 + 树状图)
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage, fcluster
from sklearn.datasets import make_blobs
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 生成数据
np.random.seed(42)
X, _ = make_blobs(n_samples=50, centers=3, cluster_std=1.0, random_state=42)
# 步骤1:计算簇间距离(linkage)
Z = linkage(X, method='ward') # ward:最小化簇内方差
# 步骤2:绘制树状图( dendrogram)
plt.figure(figsize=(12, 6))
dendrogram(Z, labels=np.arange(50), leaf_rotation=90, leaf_font_size=8)
plt.title('层次聚类树状图', fontsize=14)
plt.xlabel('数据点索引')
plt.ylabel('簇间距离')
plt.grid(alpha=0.3)
plt.show()
# 步骤3:指定簇数,获取聚类结果
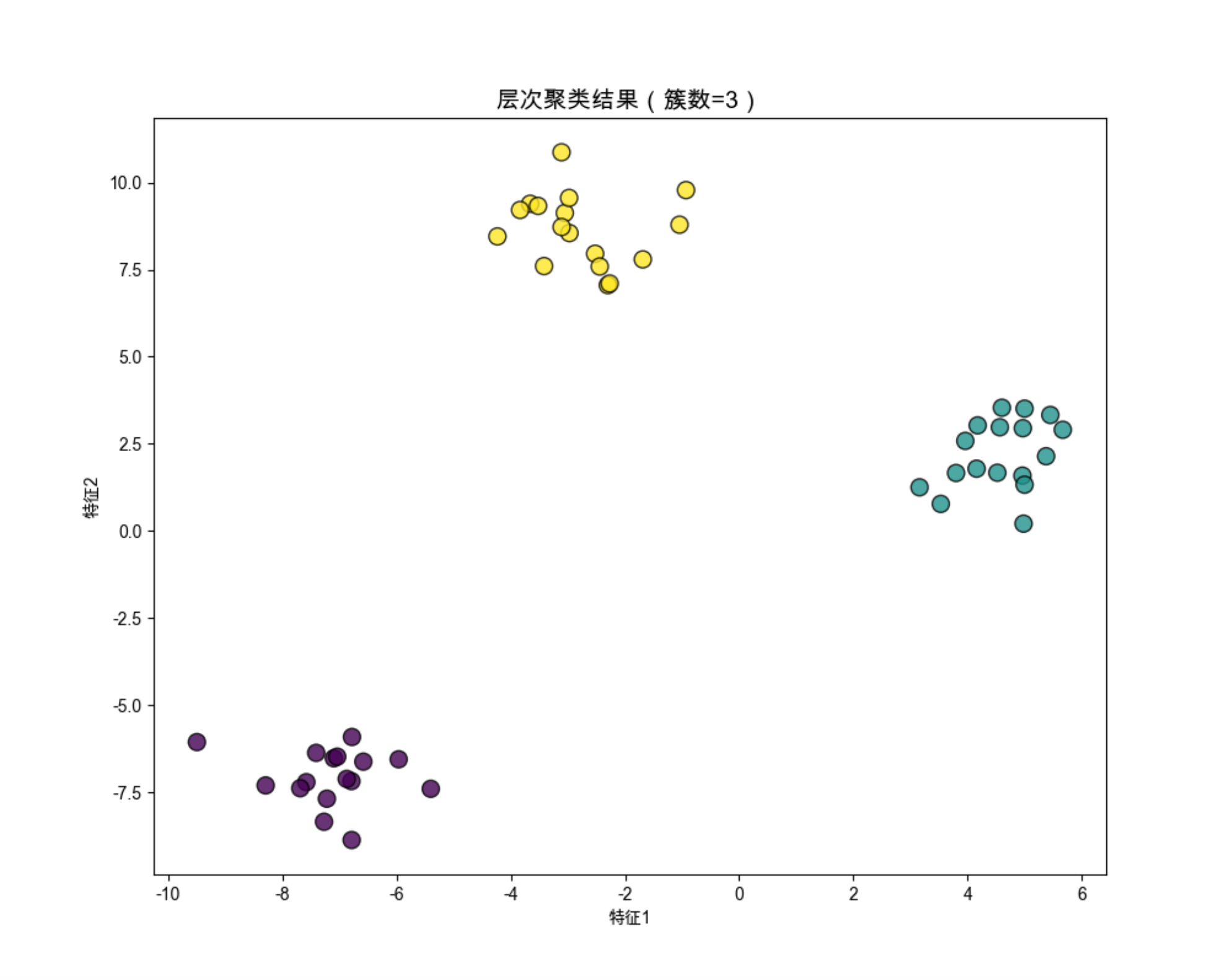
y_hier = fcluster(Z, t=3, criterion='maxclust') # t=3:目标簇数
# 绘制聚类结果
plt.figure(figsize=(10, 8))
plt.scatter(X[:, 0], X[:, 1], c=y_hier, cmap='viridis', s=100, alpha=0.8, edgecolors='black')
plt.title('层次聚类结果(簇数=3)', fontsize=14)
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.show()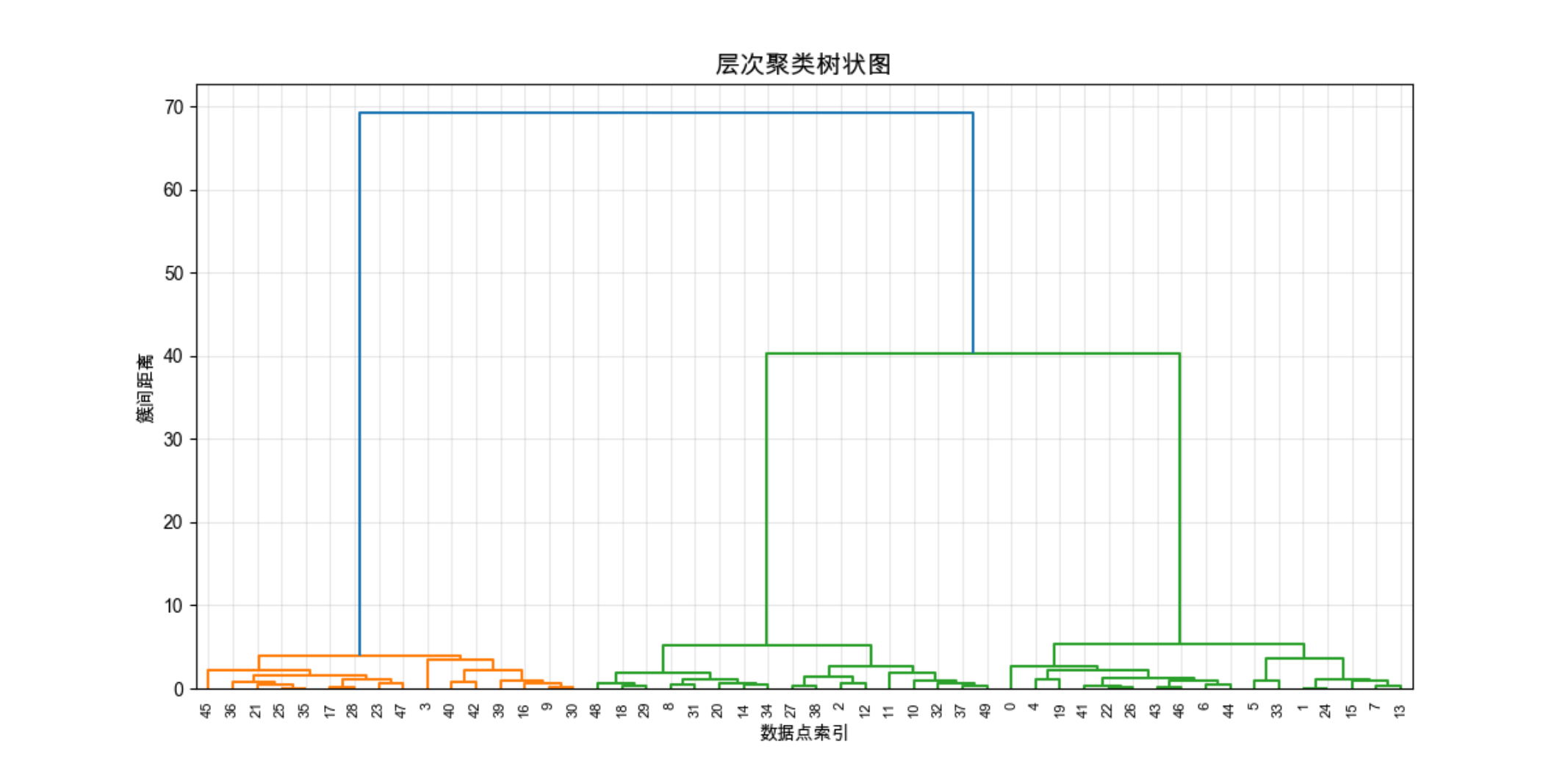
关键说明
method='ward':最优的凝聚式方法,优先合并使簇内方差增加最小的簇;- 树状图的纵轴是 "簇间距离",距离越大,说明簇越不相似 ------ 可以通过树状图判断簇数。
7.9 选择簇个数
聚类的核心难题:怎么知道该分几个簇?常用方法有:
- 肘部法则(k 均值专用):计算不同 k 值的 "簇内平方和",找到曲线的 "肘部"(拐点);
- 轮廓系数:衡量数据点在簇内的紧密性和簇间的分离度,最大值对应的 k 最优;
- 贝叶斯信息准则(BIC):适合 GMM,BIC 越小,模型越优。
实战代码(肘部法则 + 轮廓系数)
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
from sklearn.datasets import make_blobs
# Mac字体配置
plt.rcParams['font.sans-serif'] = ['Arial Unicode MS']
plt.rcParams['axes.unicode_minus'] = False
# 生成数据
np.random.seed(42)
X, _ = make_blobs(n_samples=500, centers=4, cluster_std=1.0, random_state=42)
# 计算不同k值的簇内平方和和轮廓系数
k_range = range(2, 10)
inertias = [] # 簇内平方和
sil_scores = [] # 轮廓系数
for k in k_range:
kmeans = KMeans(n_clusters=k, random_state=42, n_init=10)
y_pred = kmeans.fit_predict(X)
inertias.append(kmeans.inertia_)
sil_scores.append(silhouette_score(X, y_pred))
# 绘制对比图
fig, axes = plt.subplots(1, 2, figsize=(16, 7))
# 肘部法则
axes[0].plot(k_range, inertias, 'o-', linewidth=2, markersize=8)
axes[0].axvline(x=4, color='red', linestyle='--', label='最优k=4')
axes[0].set_title('肘部法则选择簇数', fontsize=14)
axes[0].set_xlabel('簇数k')
axes[0].set_ylabel('簇内平方和')
axes[0].legend()
axes[0].grid(alpha=0.3)
# 轮廓系数
axes[1].plot(k_range, sil_scores, 'o-', linewidth=2, markersize=8, color='green')
axes[1].axvline(x=4, color='red', linestyle='--', label='最优k=4')
axes[1].set_title('轮廓系数选择簇数', fontsize=14)
axes[1].set_xlabel('簇数k')
axes[1].set_ylabel('轮廓系数(越大越好)')
axes[1].legend()
axes[1].grid(alpha=0.3)
plt.tight_layout()
plt.show()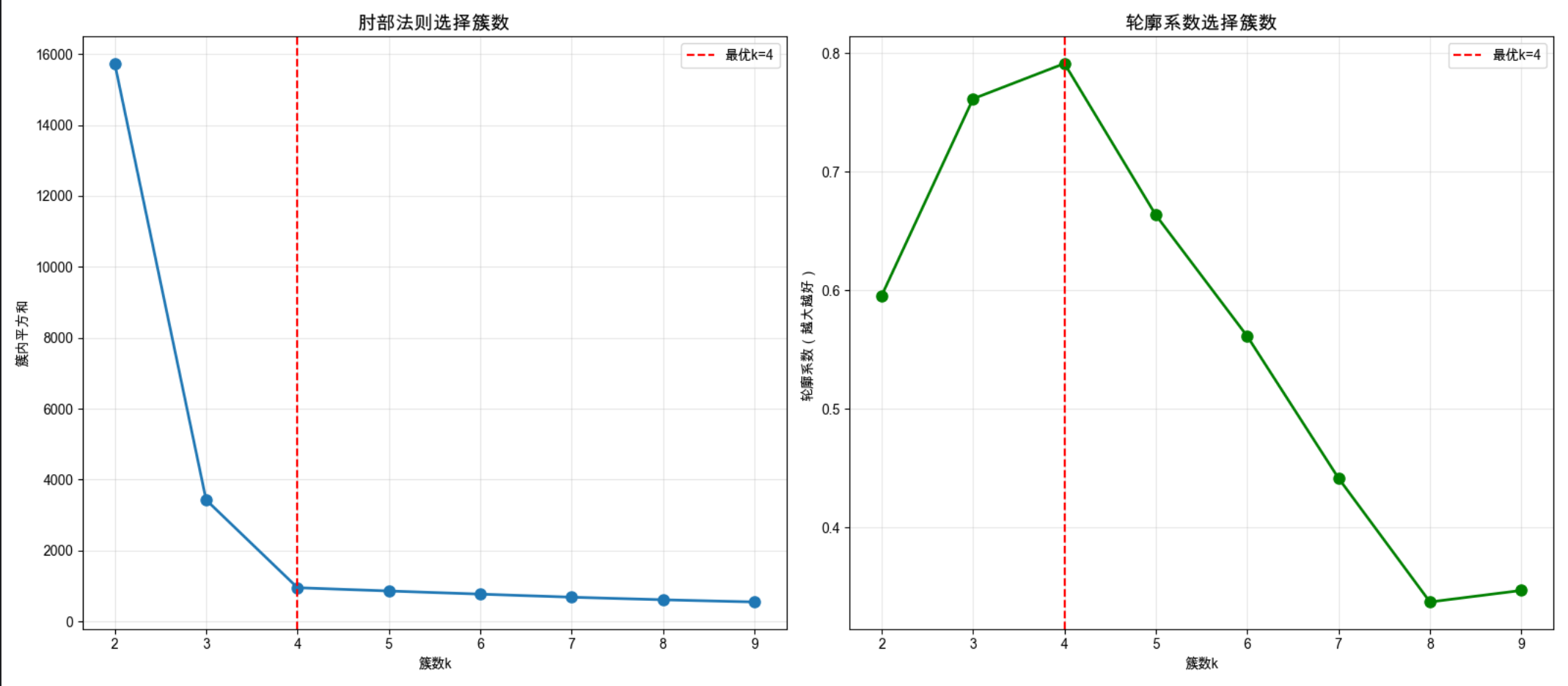
关键说明
肘部法则:k=4 时,曲线出现明显拐点(肘部),之后下降变缓;
轮廓系数:k=4 时,系数最大 ------ 两种方法都指向最优簇数 4,和我们生成数据时的簇数一致。
7.10 注释
1.本文所有代码基于 Python 3.8+,依赖库:numpy、matplotlib、scikit-learn、scipy;
2.Mac 系统字体配置已适配,Windows 用户可将Arial Unicode MS替换为SimHei;
3.谱聚类、层次聚类的计算成本较高,大规模数据建议用 k 均值或 MiniBatchKMeans;
4.聚类效果的好坏依赖 "相似度度量",比如文本数据适合用余弦相似度,数值数据适合用欧氏距离。
7.11 习题
- 用本文的代码,尝试在环形数据上对比 k 均值、谱聚类、GMM 的效果;
- 调整 k 均值的初始中心(修改 random_state),观察结果是否变化;
- 用层次聚类的不同 method(single、complete、average),对比聚类结果;
- 用真实数据集(比如鸢尾花数据集),尝试自动选择簇数并聚类。
7.12 参考文献
- 《机器学习导论》(原书第 2 版),Ethem Alpaydin 著;
- Scikit-learn 官方文档:https://scikit-learn.org/stable/modules/clustering.html;
- 《统计学习方法》(第 2 版),李航 著(聚类章节);
- 《机器学习》(周志华 著),第 9 章 聚类。
总结
1.聚类的核心是 "无监督分簇",不同算法适用于不同数据分布:k 均值适合凸簇,谱聚类适合非凸簇,GMM 适合混合密度分布;
2.簇数选择是聚类的关键,可通过肘部法则、轮廓系数等方法确定;
3.聚类不仅是独立任务,还能和监督学习结合,解决标签稀缺问题。
所有代码均可直接复制运行,建议大家动手修改参数(比如簇数、数据分布、算法参数),直观感受不同设置对聚类结果的影响!