文章目录
-
- 一、目标定位
- 二、地标检测
- 三、搭建一个目标检测算法
-
- [3.1 滑动窗口目标检测算法](#3.1 滑动窗口目标检测算法)
- [3.2 基于卷积的滑动窗口目标检测算法](#3.2 基于卷积的滑动窗口目标检测算法)
- [3.3 YOLO(You Only Look Once)算法](#3.3 YOLO(You Only Look Once)算法)
-
- [3.3.1 边界框预测](#3.3.1 边界框预测)
- [3.3.2 并交化](#3.3.2 并交化)
- [3.3.3 非最大值抑制](#3.3.3 非最大值抑制)
- [3.3.4 锚框](#3.3.4 锚框)
- [3.3.5 YOLO算法](#3.3.5 YOLO算法)
- [3.3.6 YOLO算法的代码实现](#3.3.6 YOLO算法的代码实现)
- 四、使用unet进行语义分割
-
- [4.1 什么是语义分割?](#4.1 什么是语义分割?)
- [4.2 转置卷积](#4.2 转置卷积)
- [4.3 unet的工作原理](#4.3 unet的工作原理)
一、目标定位
我们常见图像分类,图像中单个标签分类及定位以及对象检测,如下图所示:

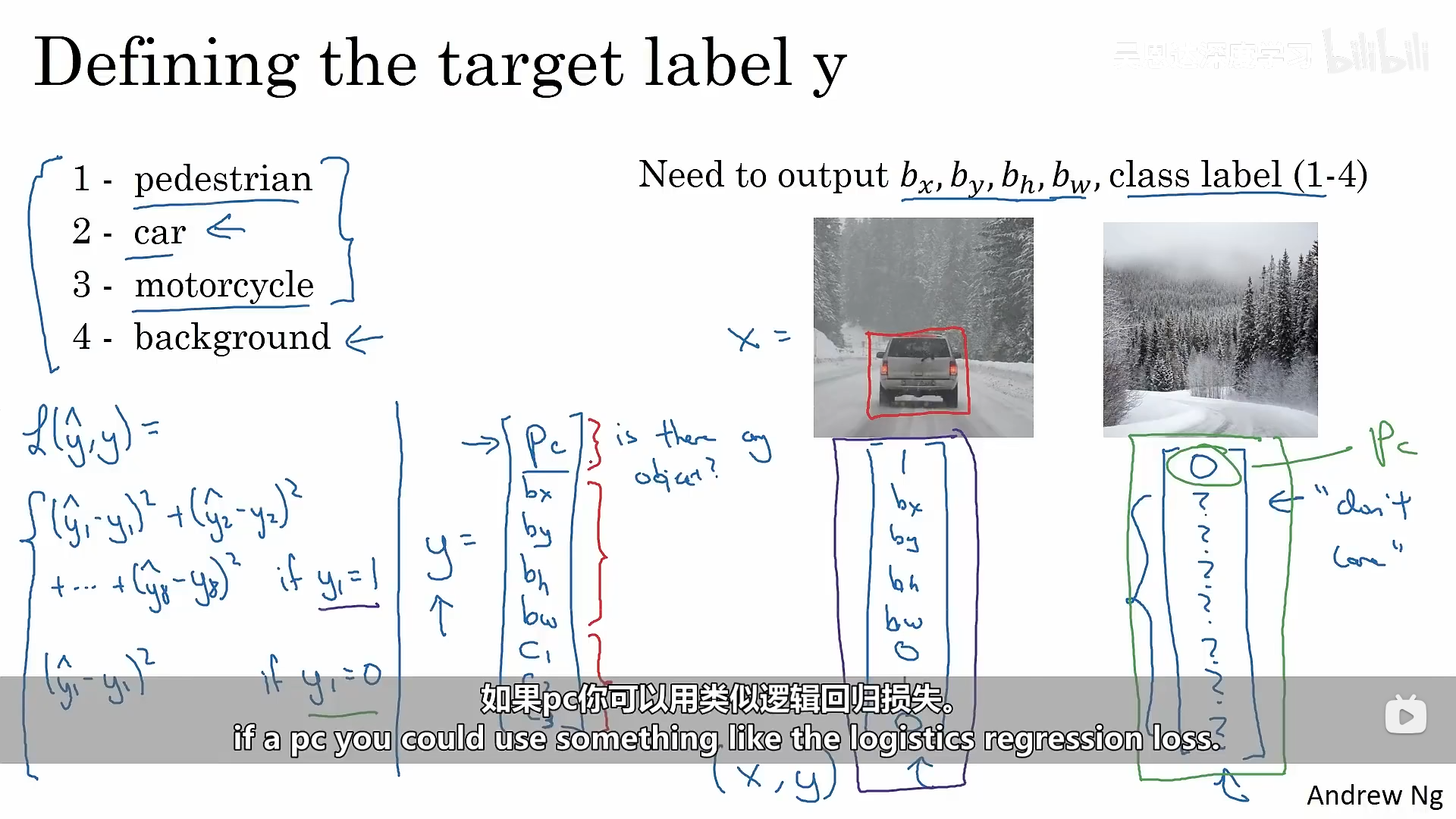
在进行定位时,我们网络最终除了要输出分类之外,还需要输出标签的位置信息(边界框:bx,by,bw,bh)。如下图所示。

那我们如何定义目标值y呢,y里面包含了几个部分(Pc:是否包含某个对象、bx、by、bw、bh、0:不是第一个类别、1:属于某个类别...),目标值y定义完之后,我们的损失函数应该如何定义呢?下图中给出了当我们使用均方误差作为损失函数时分成了两种情况进行讨论:(Pc为1或者0)
二、地标检测
我们上述说到的目标定位是需要输出一个具体的定位边界框,而地标检测只需要输出重要的点和图像的(X,Y)坐标。比如说我现在需要识别图像中人的眼角的位置,这时候我们可以建立一个神经网络模型,它的输出层只输出两个数字,当然我们也可以修改神经网络,让它学习多个特征,输出人脸部的所有重要的关键特征的坐标。同样这种方式也适用于人体姿态检测。

三、搭建一个目标检测算法
学会使用一个卷积神经网络和滑动窗口的检测算法进行目标检测。下面以构建一个汽车目标检测算法为示例进行讲解。
3.1 滑动窗口目标检测算法
训练一个基本的能够识别某一窗口大小的 图像中的汽车检测模型主要需要以下几个步骤:搭建训练数据集------使用卷积神经网络对数据集进行训练------输出识别结果。

接下来我们需要将其应用在滑动窗口中去,在我们的测试图像中从左上角开始,依次滑动固定大小的窗口进行汽车识别,遍历完整个图像之后,我们可以再次使用不同大小的窗口去遍历图像再次进行识别。在这其中只要有某个窗口被分类为1就说明整张图像中的该窗口处是有汽车的,这种检测方式就被称之为滑动窗口检测。

这个算法有一个很明显的确定,当我们的步长设置得比较大时,算法的效果就会变差,但是当我们的移动步长设置地较小时,整个算法执行下来的计算成本又太大。
3.2 基于卷积的滑动窗口目标检测算法
在卷积网络中的后面部分也就是全连接网络部分,我们可以将这部分修改为卷积网络,如下图所示:
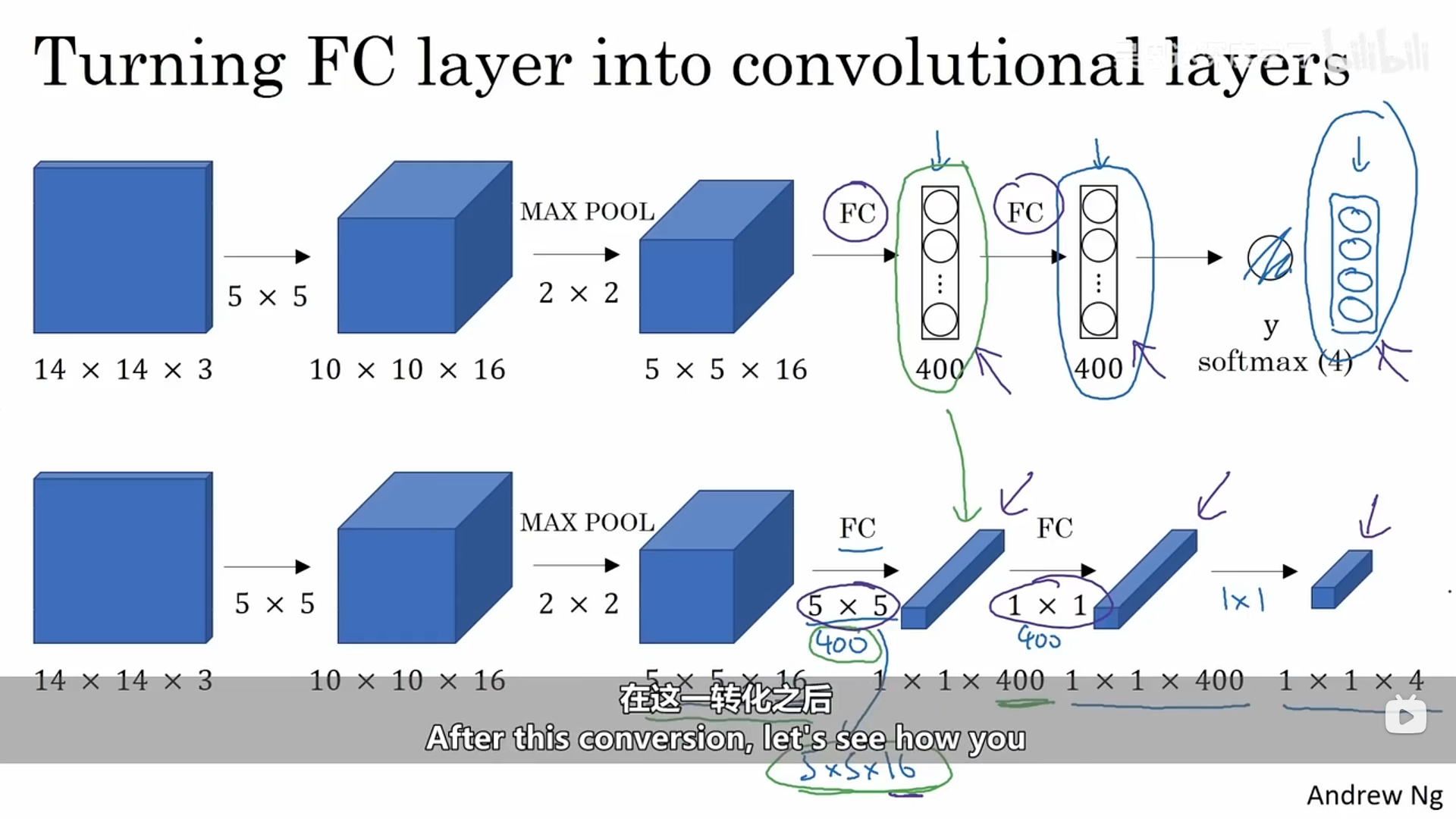
转换之后,我们接下来看一看如何用卷积的形式实现滑动窗口目标检测,试想一下我们的卷积池化等操作也是对图像中某一窗口进行线性组合的过程,而刚开始我们所说的滑动窗口目标检测算法也是窗口进行移动的过程。我们这里已经训练好了一个神经网络,接下来我们需要对原图像进行滑动窗口目标检测,使用的检测模型就是我们刚刚训练好的那个卷积神经网络,这里我们就可以直接对原图像进行模型中的卷积及池化操作,那么输出的最终结果的每一个部分都对应着对原图像某一个窗口(窗口大小为训练的卷积神经网络的输入图像的大小)进行的目标检测。具体操作如下所示:
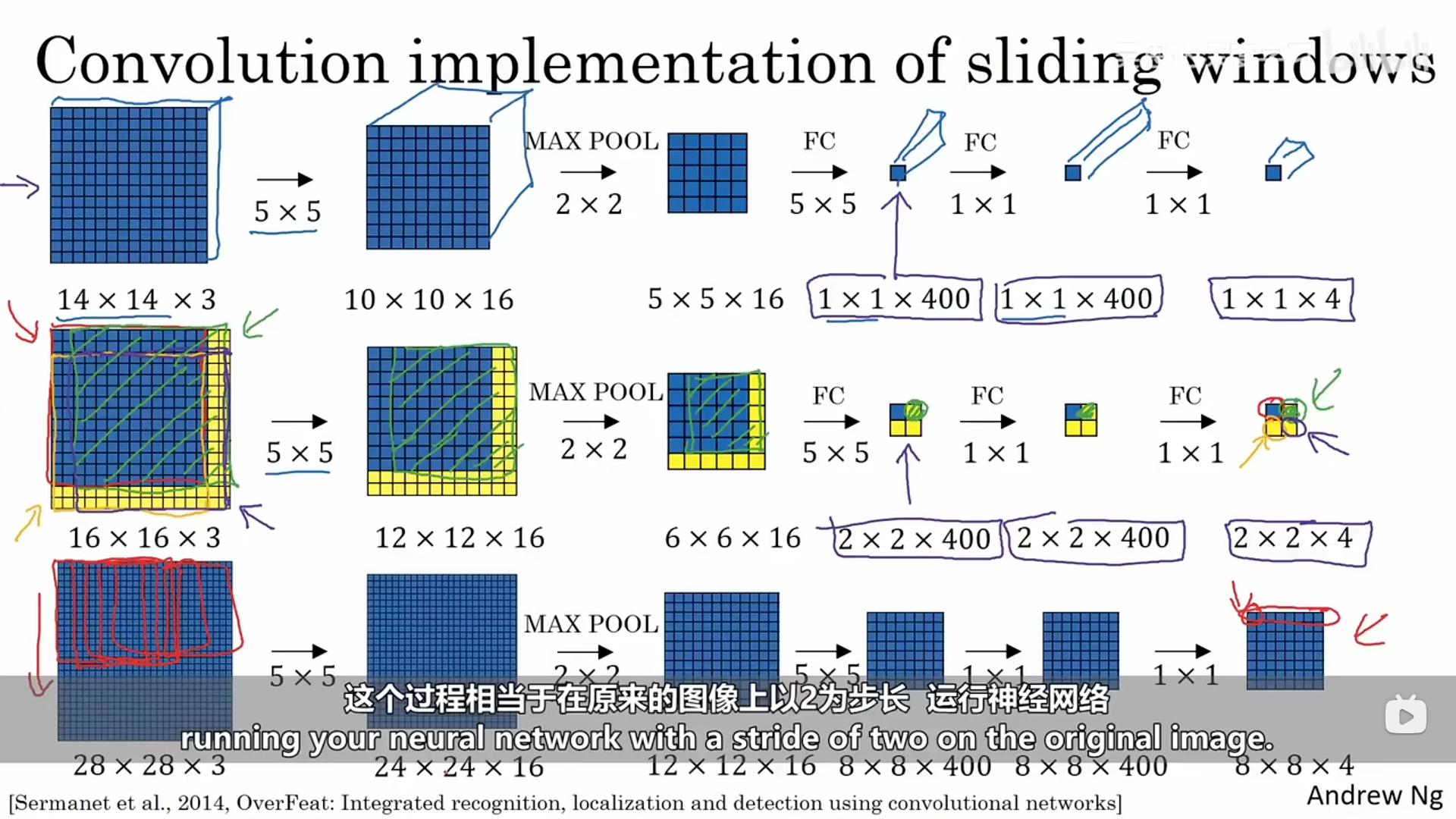
我们可以对比一下这两个方法,第一种是训练完一个汽车识别卷积神经网络之后,使用类似于剪裁的形式(滑动窗口的形式)对每一个窗口进行识别;而第二种方式则是直接对测试图像进行汽车识别卷积网络中的卷积池化等操作,最终结果的每一个部分都对应着原图像的某一个窗口大小(汽车识别卷积网络的输入图像大小)进行识别的最终结果。简化了整个操作过程。这个方法仍然存在一个缺点:窗口边框的定位并不精确。
3.3 YOLO(You Only Look Once)算法
3.3.1 边界框预测
YOLO(You Only Look Once)算法是一个比较好的能够精确输出边界框的算法。
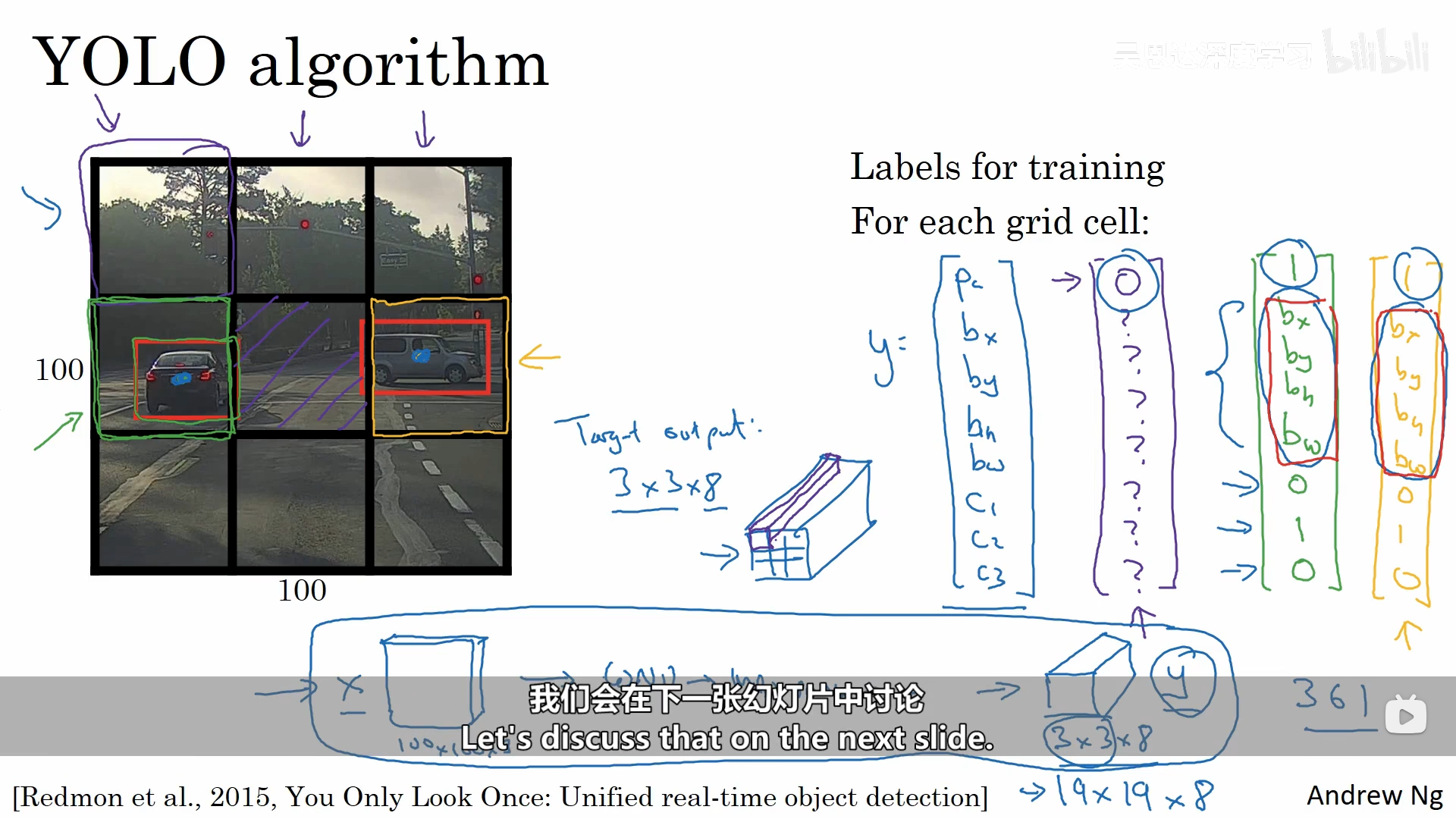
这个算法跟我们之前讲的基于卷积的滑动窗口目标检测算法非常类似,不同之处在于,图像在进行检测时,获得的目标的具体位置,会计算出一个中心的位置,再根据中心点的位置将它分配到包含该中心点的网格中,所以对于每一个目标物,即使它跨越了多个网格,它也只会被分配到众多网格中的一个当中去。
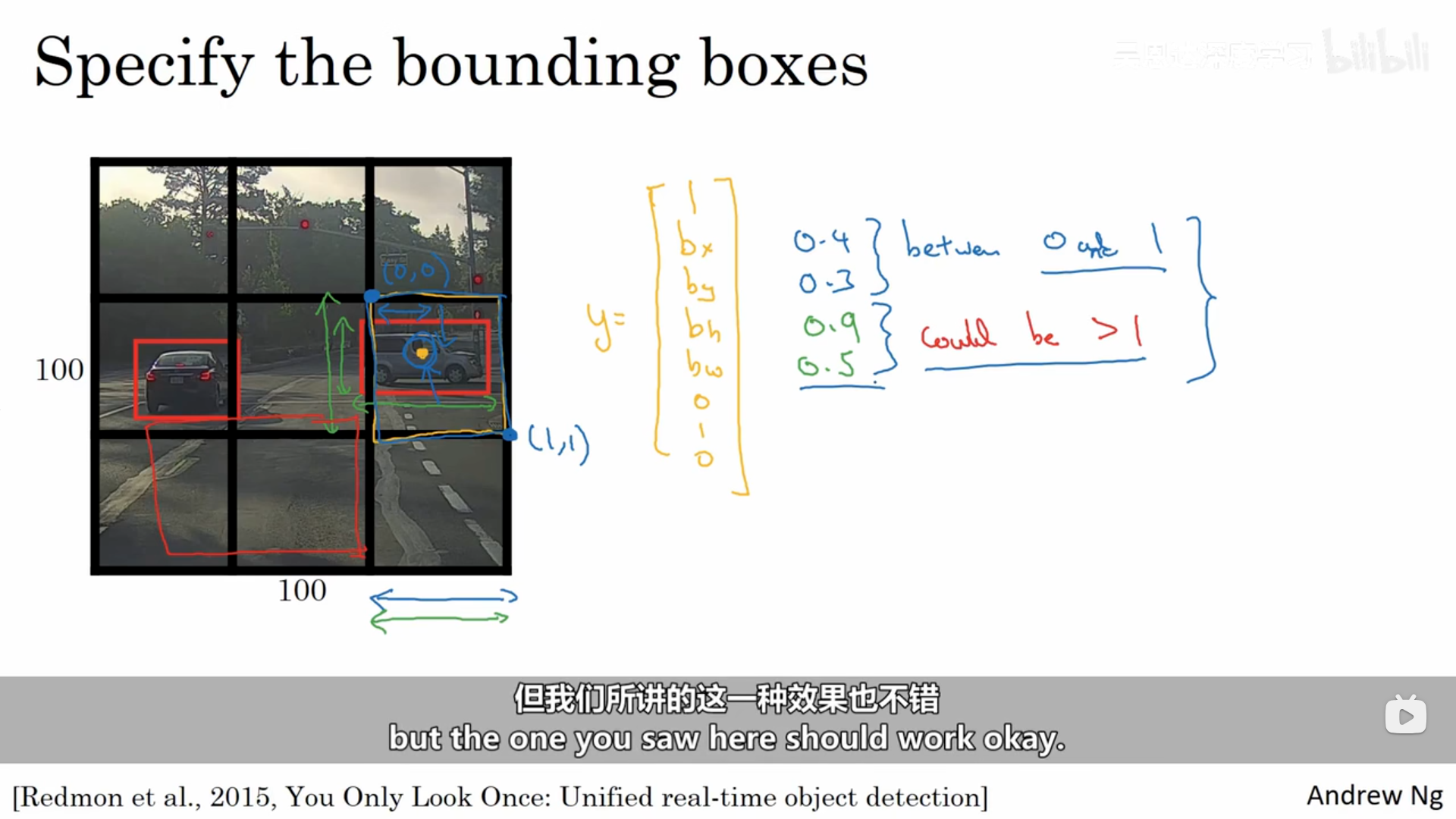
其中有一个细节,我们的bx、by、bh、bw是如何确定的呢?其中的bx、by是相对于该网格的左上角来说的,它们的取值是在0和1之间的,而bh和bw是相对于该网格的长宽来进行取值的,它们的取值是可能大于1 的。
3.3.2 并交化
我们应该如何判断目标检测算法有效呢?接下来我们会学习一个函数交并比,它既可以用来评价目标检测算法,也可以往目标检测算法中加入其他特征部分来进一步改进算法。
交并比函数(IoU):计算的就是我们预测的边界框与实际的边界框的交集和并集的比值。即IoU是两个边界框重叠程度的一个度量值,当IoU大于0.5,结果就会被判定为正确。

3.3.3 非最大值抑制
非最大值抑制是确保你的算法只对每个对象得到一个检测的方法。下面有一个示例进行具体讲解:

图像被划分为了多个网格,从技术上来说,中心点只会将目标划分到其中一个网格中去,然而在对网格进行目标定位时,其中有多个网格都会被识别为车,接下来我们看非最大值抑制是如何做的。它首先会看每一个检测结果的相关概率,它会取其中的最大值,剩下的方框以及所有和你刚输入的那个结果有着多重叠的、有着高IoU值得方形区域将会被抑制,也就是其他概率得方框将会被调暗。

下面说一下该算法的细节(以单个目标识别为例)。

3.3.4 锚框
目前我们讲过的目标检测中每个单元格只能检测一个对象,我们可以使用锚框来使得一个单元格可以检测多个对象。这里我们可以更改输出:当某一个网格中存在多个对象时,我们可以预先定义两个不同的形状,称作锚框,接下来我们需要将两个预测跟两个锚框关联起来。接下来定义交叉标签。
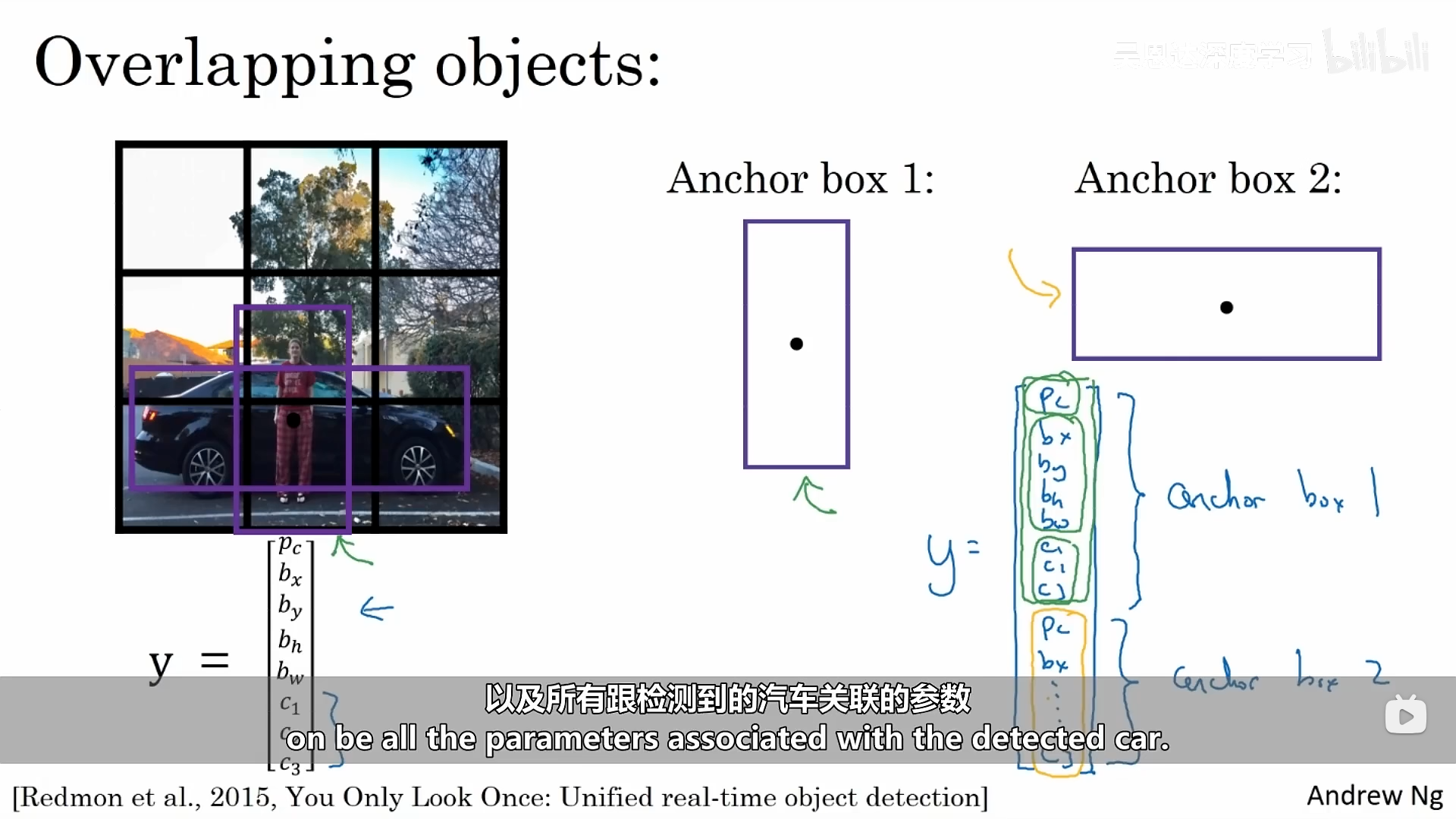
现在,每个对象都被指定给跟之前一样的网格单元和一个IoU值最高、具有对象形状的锚框。,

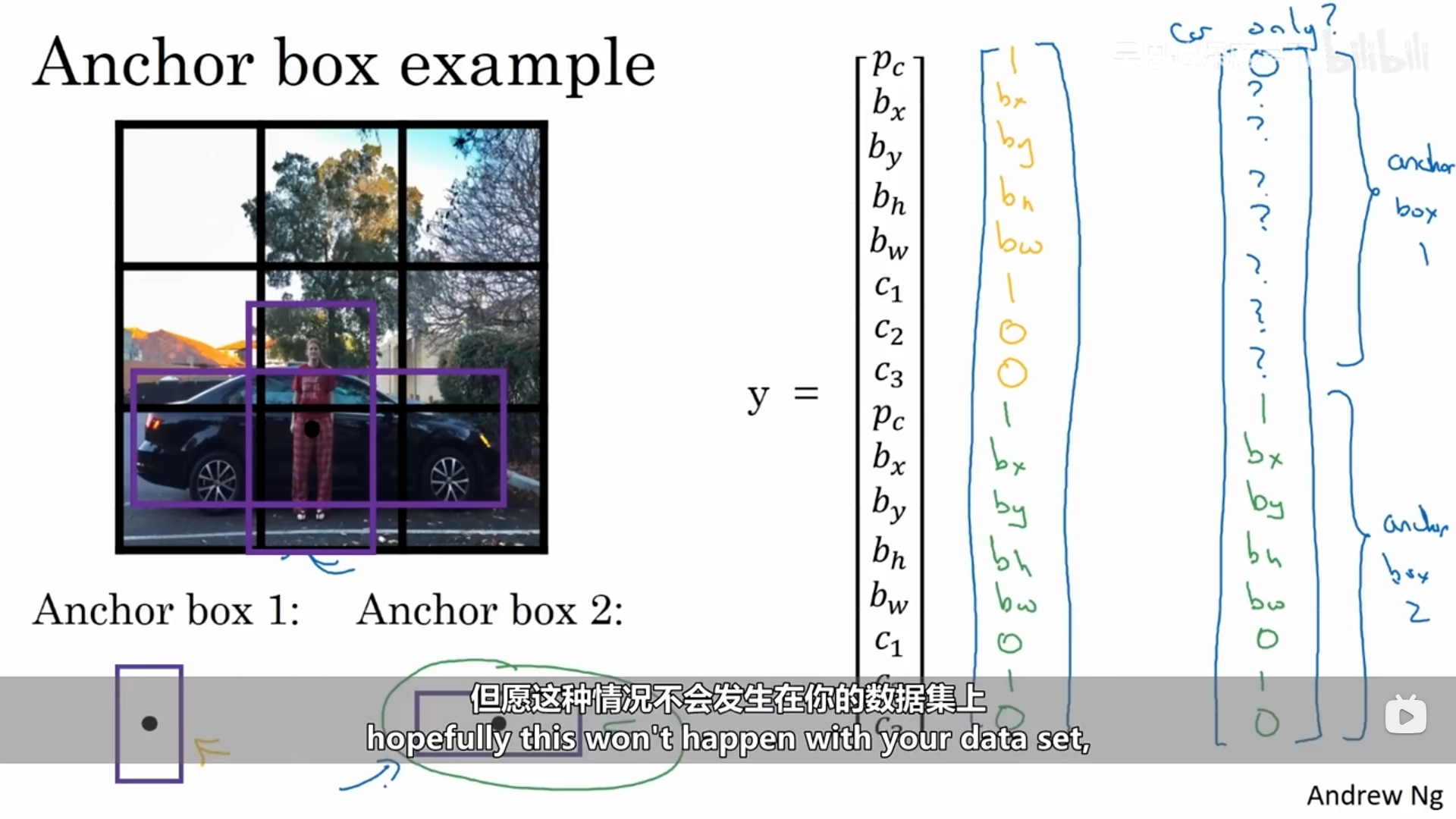
我的理解,算法定义了两个锚框(可以定义多个),锚框的形状我们可以自己进行定义,计算预测的边界框与锚框的IoU,IoU大的代表该锚框代表了该类别,该部分的分类标签也就代表了该类别。上述示例的红色的锚框就跟人的分类标签联系起来。
3.3.5 YOLO算法
训练:这里选择了两个锚框
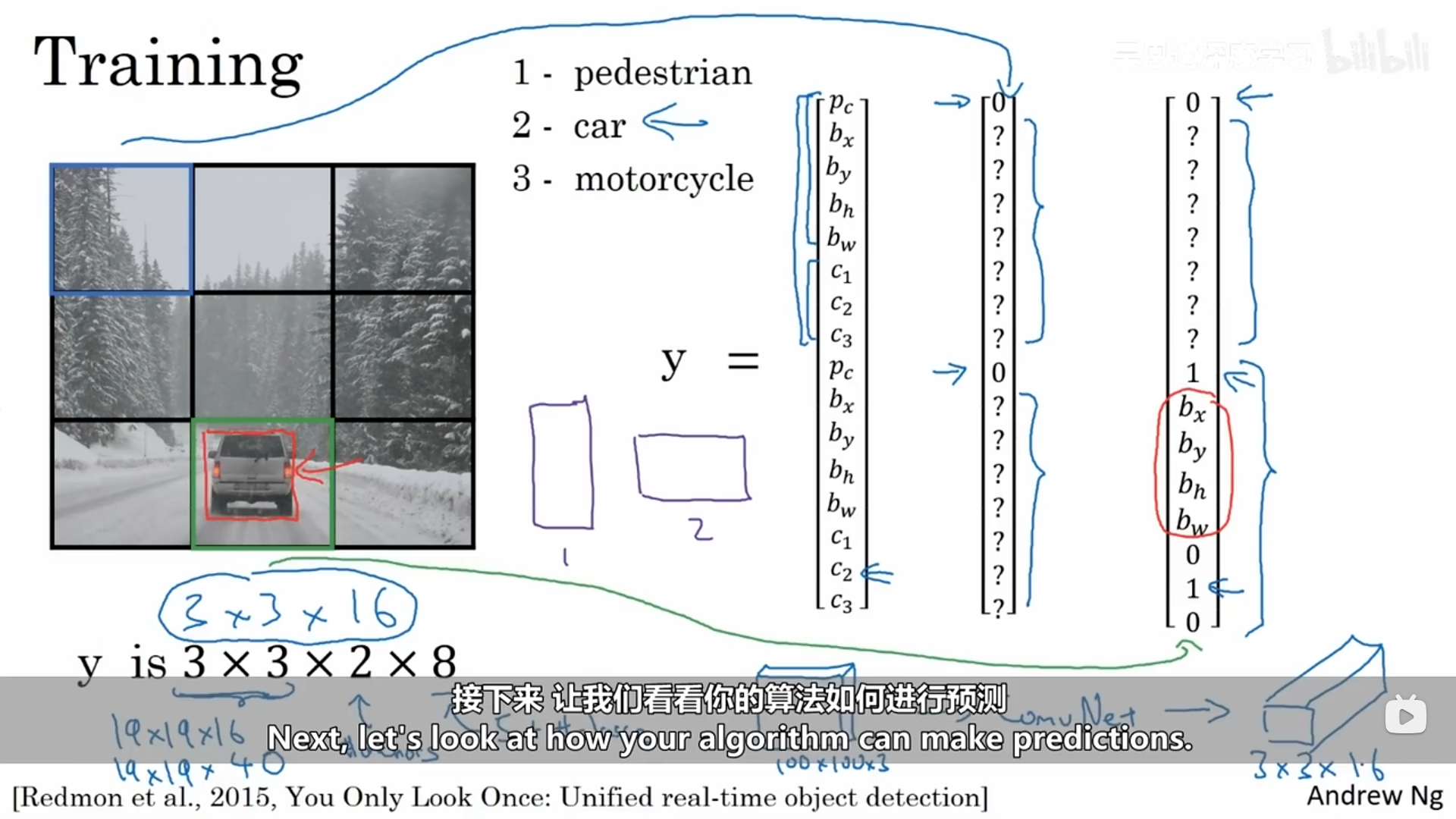
预测:
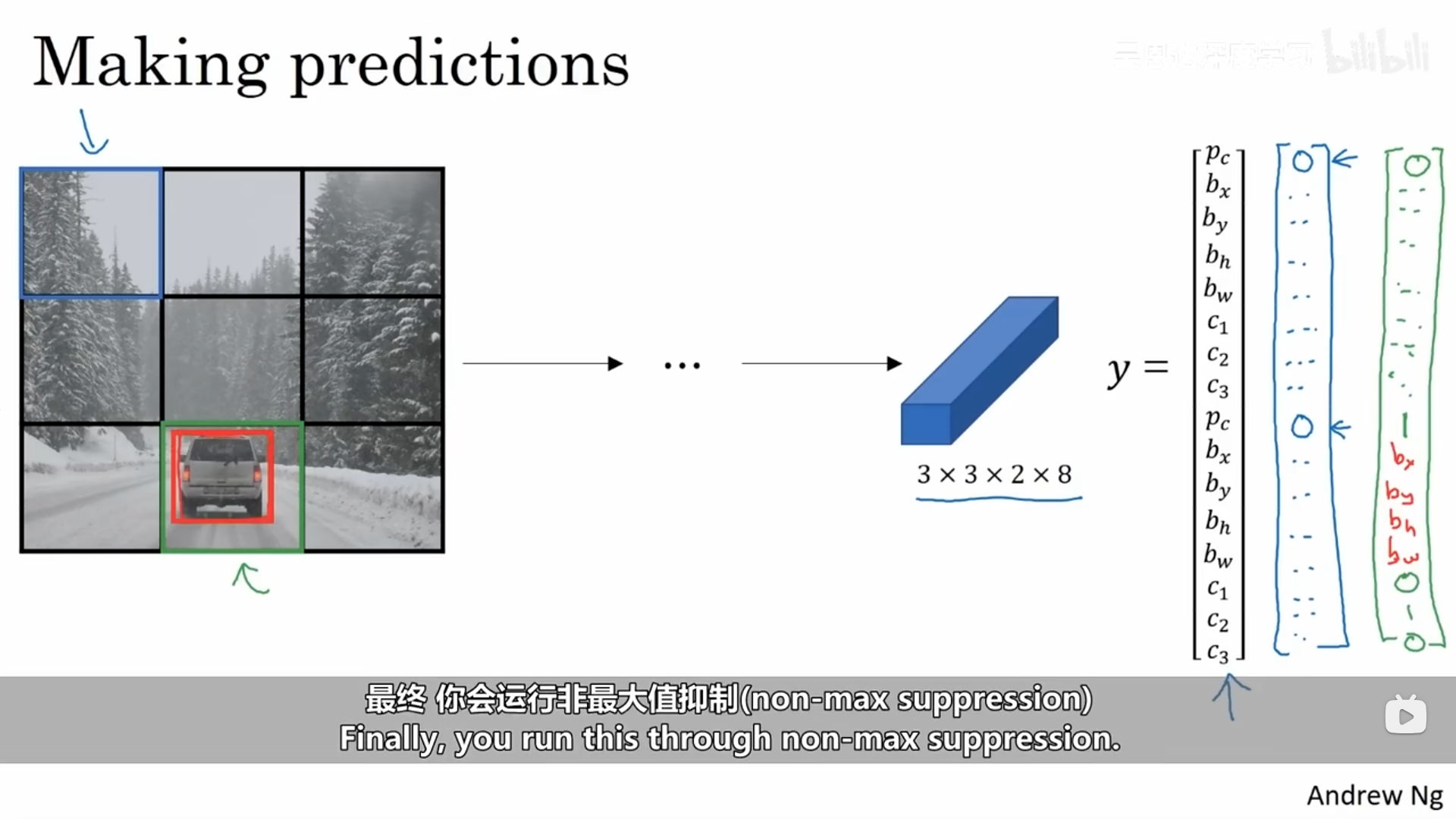
非最大值抑制:

3.3.6 YOLO算法的代码实现
YOLO是一种流行算法,因为它能够实现高精度,同时还能实时运行。这种"只看一次"的算法在图像上"只看一次",这意味着只需要通过网络进行一次前向传播,就可以做出预测。在非最大抑制之后,它会输出识别的对象以及包围框。这里我们有80 个类,使用YOLO来进行目标检测,那么可以将类标签表示为 1 到 80 的整数,或者 80 维向量(80 个数字),其中第一个数字是 1,其余数字都是 0。视频教程使用了后一种表示方式;在本笔记本中,我们将使用两种表示方式,具体取决于哪一种对特定步骤来说更方便。

使用多个锚框允许我们可以在一个网格中识别到多个对象,每一个锚框对应一个置信度。如何定义,就是通过修改模型进行深度卷积之后的输出进行编码,使每一个网格中存在5个锚框的信息,具体如下图所示:
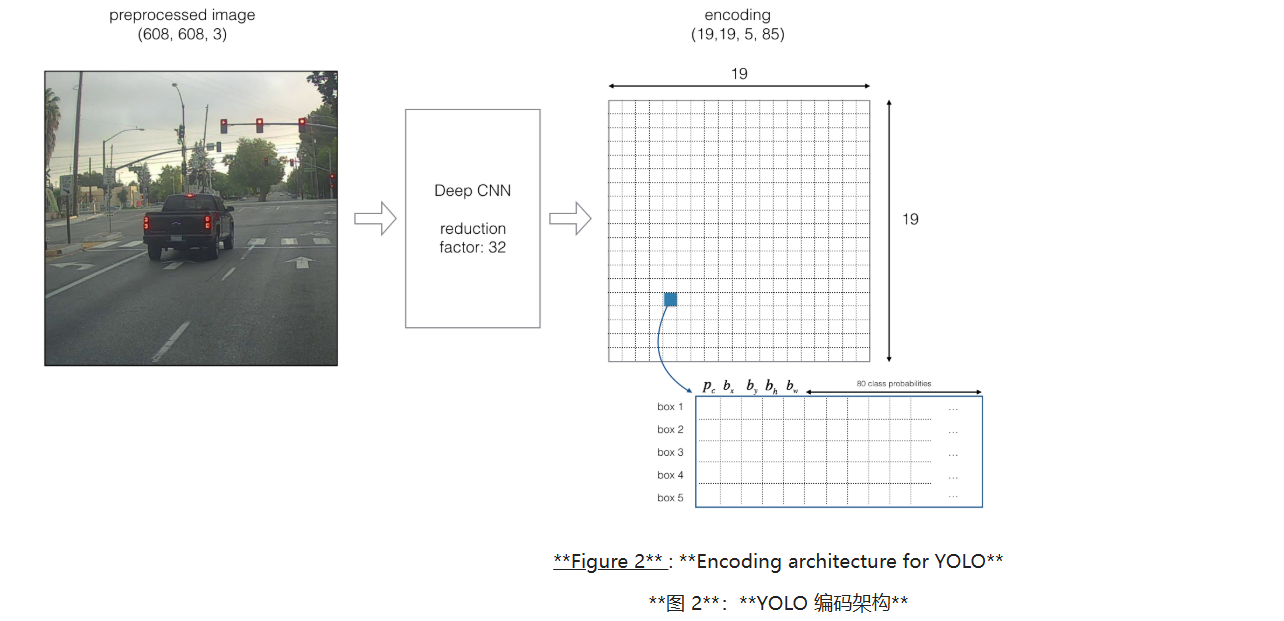
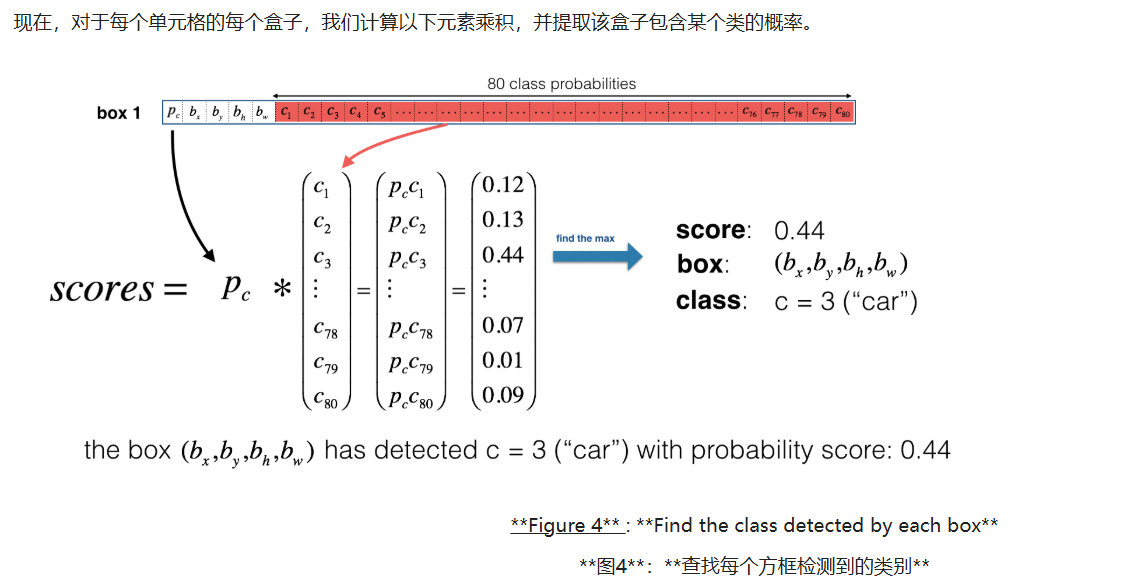

plain
# GRADED FUNCTION: yolo_filter_boxes
def yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold = .6):
"""Filters YOLO boxes by thresholding on object and class confidence.
Arguments:
box_confidence -- tensor of shape (19, 19, 5, 1)
boxes -- tensor of shape (19, 19, 5, 4)
box_class_probs -- tensor of shape (19, 19, 5, 80)
threshold -- real value, if [ highest class probability score < threshold], then get rid of the corresponding box
Returns:
scores -- tensor of shape (None,), containing the class probability score for selected boxes
boxes -- tensor of shape (None, 4), containing (b_x, b_y, b_h, b_w) coordinates of selected boxes
classes -- tensor of shape (None,), containing the index of the class detected by the selected boxes
Note: "None" is here because you don't know the exact number of selected boxes, as it depends on the threshold.
For example, the actual output size of scores would be (10,) if there are 10 boxes.
"""
# Step 1: Compute box scores
### START CODE HERE ### (≈ 1 line)
box_scores = box_confidence * box_class_probs # 计算每个候选框对每个类别的得分:物体置信度 * 类别条件概率
### END CODE HERE ###
# Step 2: Find the box_classes thanks to the max box_scores, keep track of the corresponding score
### START CODE HERE ### (≈ 2 lines)
box_classes = K.argmax(box_scores, axis=-1) # 对最后一维(80类)取最大值的索引,得到每个框预测的类别id
box_class_scores = K.max(box_scores, axis=-1) # 对最后一维(80类)取最大值本身,得到每个框的最佳类别得分
### END CODE HERE ###
# Step 3: Create a filtering mask based on "box_class_scores" by using "threshold". The mask should have the
# same dimension as box_class_scores, and be True for the boxes you want to keep (with probability >= threshold)
### START CODE HERE ### (≈ 1 line)
filtering_mask = box_class_scores >= threshold # 生成布尔掩码:最佳类别得分>=阈值的框保留,否则过滤掉
### END CODE HERE ###
# Step 4: Apply the mask to scores, boxes and classes
### START CODE HERE ### (≈ 3 lines)
scores = tf.boolean_mask(box_class_scores, filtering_mask) # 用掩码过滤得分,保留通过阈值的框的得分(一维None,)
boxes = tf.boolean_mask(boxes, filtering_mask) # 用掩码过滤boxes,保留通过阈值的框坐标(None,4)
classes = tf.boolean_mask(box_classes, filtering_mask) # 用掩码过滤类别id,保留通过阈值的框对应类别(None,)
### END CODE HERE ###
return scores, boxes, classes即使在对类别的得分进行阈值过滤后,仍然会得到很多重叠的框。用于选择正确框的第二个过滤器称为非最大抑制 (NMS)。
plain
# GRADED FUNCTION: iou
def iou(box1, box2):
"""Implement the intersection over union (IoU) between box1 and box2
Arguments:
box1 -- first box, list object with coordinates (x1, y1, x2, y2)
box2 -- second box, list object with coordinates (x1, y1, x2, y2)
"""
# Calculate the (y1, x1, y2, x2) coordinates of the intersection of box1 and box2. Calculate its Area.
### START CODE HERE ### (≈ 5 lines)
xi1 = max(box1[0], box2[0]) # 交集左上角的 x 坐标:取两个框 x1 的最大值
yi1 = max(box1[1], box2[1]) # 交集左上角的 y 坐标:取两个框 y1 的最大值
xi2 = min(box1[2], box2[2]) # 交集右下角的 x 坐标:取两个框 x2 的最小值
yi2 = min(box1[3], box2[3]) # 交集右下角的 y 坐标:取两个框 y2 的最小值
inter_area = max(0, xi2 - xi1) * max(0, yi2 - yi1) # 计算交集面积(防止不相交时出现负数)
### END CODE HERE ###
# Calculate the Union area by using Formula: Union(A,B) = A + B - Inter(A,B)
### START CODE HERE ### (≈ 3 lines)
box1_area = (box1[2] - box1[0]) * (box1[3] - box1[1]) # 计算 box1 的面积
box2_area = (box2[2] - box2[0]) * (box2[3] - box2[1]) # 计算 box2 的面积
union_area = box1_area + box2_area - inter_area # 并集面积 = 两个面积之和 - 交集面积
### END CODE HERE ###
# compute the IoU
### START CODE HERE ### (≈ 1 line)
iou = inter_area / union_area # IoU = 交集面积 / 并集面积
### END CODE HERE ###
return iou
plain
# GRADED FUNCTION: yolo_non_max_suppression
def yolo_non_max_suppression(scores, boxes, classes, max_boxes = 10, iou_threshold = 0.5):
"""
Applies Non-max suppression (NMS) to set of boxes
Arguments:
scores -- tensor of shape (None,), output of yolo_filter_boxes()
boxes -- tensor of shape (None, 4), output of yolo_filter_boxes() that have been scaled to the image size (see later)
classes -- tensor of shape (None,), output of yolo_filter_boxes()
max_boxes -- integer, maximum number of predicted boxes you'd like
iou_threshold -- real value, "intersection over union" threshold used for NMS filtering
Returns:
scores -- tensor of shape (, None), predicted score for each box
boxes -- tensor of shape (4, None), predicted box coordinates
classes -- tensor of shape (, None), predicted class for each box
Note: The "None" dimension of the output tensors has obviously to be less than max_boxes. Note also that this
function will transpose the shapes of scores, boxes, classes. This is made for convenience.
"""
max_boxes_tensor = K.variable(max_boxes, dtype='int32') # tensor to be used in tf.image.non_max_suppression()
K.get_session().run(tf.variables_initializer([max_boxes_tensor])) # initialize variable max_boxes_tensor
# Use tf.image.non_max_suppression() to get the list of indices corresponding to boxes you keep
### START CODE HERE ### (≈ 1 line)
nms_indices = tf.image.non_max_suppression(boxes, scores, max_boxes, iou_threshold=iou_threshold) # 执行NMS,返回保留下来的框索引
### END CODE HERE ###
# Use K.gather() to select only nms_indices from scores, boxes and classes
### START CODE HERE ### (≈ 3 lines)
scores = K.gather(scores, nms_indices) # 根据保留索引,从scores中取出对应得分
boxes = K.gather(boxes, nms_indices) # 根据保留索引,从boxes中取出对应坐标
classes = K.gather(classes, nms_indices) # 根据保留索引,从classes中取出对应类别
### END CODE HERE ###
return scores, boxes, classes
plain
# GRADED FUNCTION: yolo_eval
def yolo_eval(yolo_outputs, image_shape = (720., 1280.), max_boxes=10, score_threshold=.6, iou_threshold=.5):
"""
Converts the output of YOLO encoding (a lot of boxes) to your predicted boxes along with their scores, box coordinates and classes.
Arguments:
yolo_outputs -- output of the encoding model (for image_shape of (608, 608, 3)), contains 4 tensors:
box_confidence: tensor of shape (None, 19, 19, 5, 1)
box_xy: tensor of shape (None, 19, 19, 5, 2)
box_wh: tensor of shape (None, 19, 19, 5, 2)
box_class_probs: tensor of shape (None, 19, 19, 5, 80)
image_shape -- tensor of shape (2,) containing the input shape, in this notebook we use (608., 608.) (has to be float32 dtype)
max_boxes -- integer, maximum number of predicted boxes you'd like
score_threshold -- real value, if [ highest class probability score < threshold], then get rid of the corresponding box
iou_threshold -- real value, "intersection over union" threshold used for NMS filtering
Returns:
scores -- tensor of shape (None, ), predicted score for each box
boxes -- tensor of shape (None, 4), predicted box coordinates
classes -- tensor of shape (None,), predicted class for each box
"""
### START CODE HERE ###
# Retrieve outputs of the YOLO model (≈1 line)
box_confidence, box_xy, box_wh, box_class_probs = yolo_outputs # 从yolo_outputs中取出四个输出张量
# Convert boxes to be ready for filtering functions
boxes = yolo_boxes_to_corners(box_xy, box_wh) # 将中心点+宽高(box_xy, box_wh)转换为角点坐标(x1,y1,x2,y2)/(y1,x1,y2,x2)形式
# Use one of the functions you've implemented to perform Score-filtering with a threshold of score_threshold (≈1 line)
scores, boxes, classes = yolo_filter_boxes(box_confidence, boxes, box_class_probs, threshold=score_threshold) # 先按分数阈值过滤掉低置信度框
# Scale boxes back to original image shape.
boxes = scale_boxes(boxes, image_shape) # 将(相对608x608)的预测框缩放回原图尺寸(image_shape)
# Use one of the functions you've implemented to perform Non-max suppression with a threshold of iou_threshold (≈1 line)
scores, boxes, classes = yolo_non_max_suppression(scores, boxes, classes, max_boxes=max_boxes, iou_threshold=iou_threshold) # 对剩余框做NMS,去除高度重叠框
### END CODE HERE ###
return scores, boxes, classes注意:YOLO模型只是在进行预测的时候只需要按照之前训练时候的卷积池化操作向前传播一次就可以了。训练的时候还是多次:向前传播+向后传播。
四、使用unet进行语义分割
语义分割的目标是绘制检测到的对象周围的仔细轮廓,以便确切知道哪个像素属于对象,哪个不属于。
4.1 什么是语义分割?

上图中的左边两幅图片是对图像进行了目标检测,但是这对于自动驾驶来说往往是不够的,而图三则对图像进行了语义分割,绿色部分就为我们展示了可驱动的平面,提供了更加精确的物体分割位置。下面展示了图像分割技术在医学图像上面的应用:
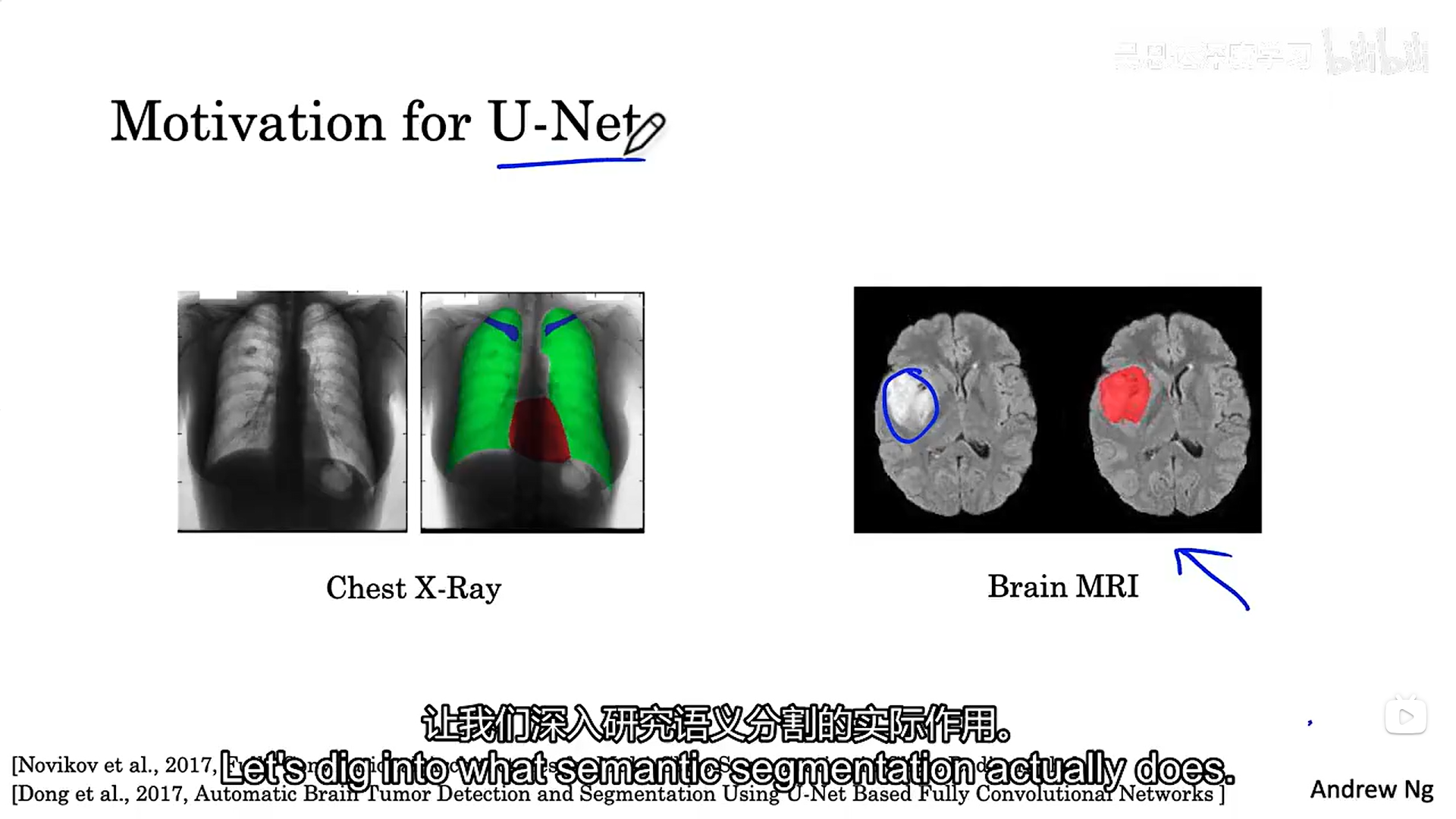
分割技术能够更好的帮助我们将病灶或者肿瘤从图像当中分割出来。
就我们现在所学的东西如何能够做到将一幅图像中的汽车分割出来呢:当然我们可以使用目标检测技术对图像进行识别,如下图所示:

什么样的神经网络可以做到呢?
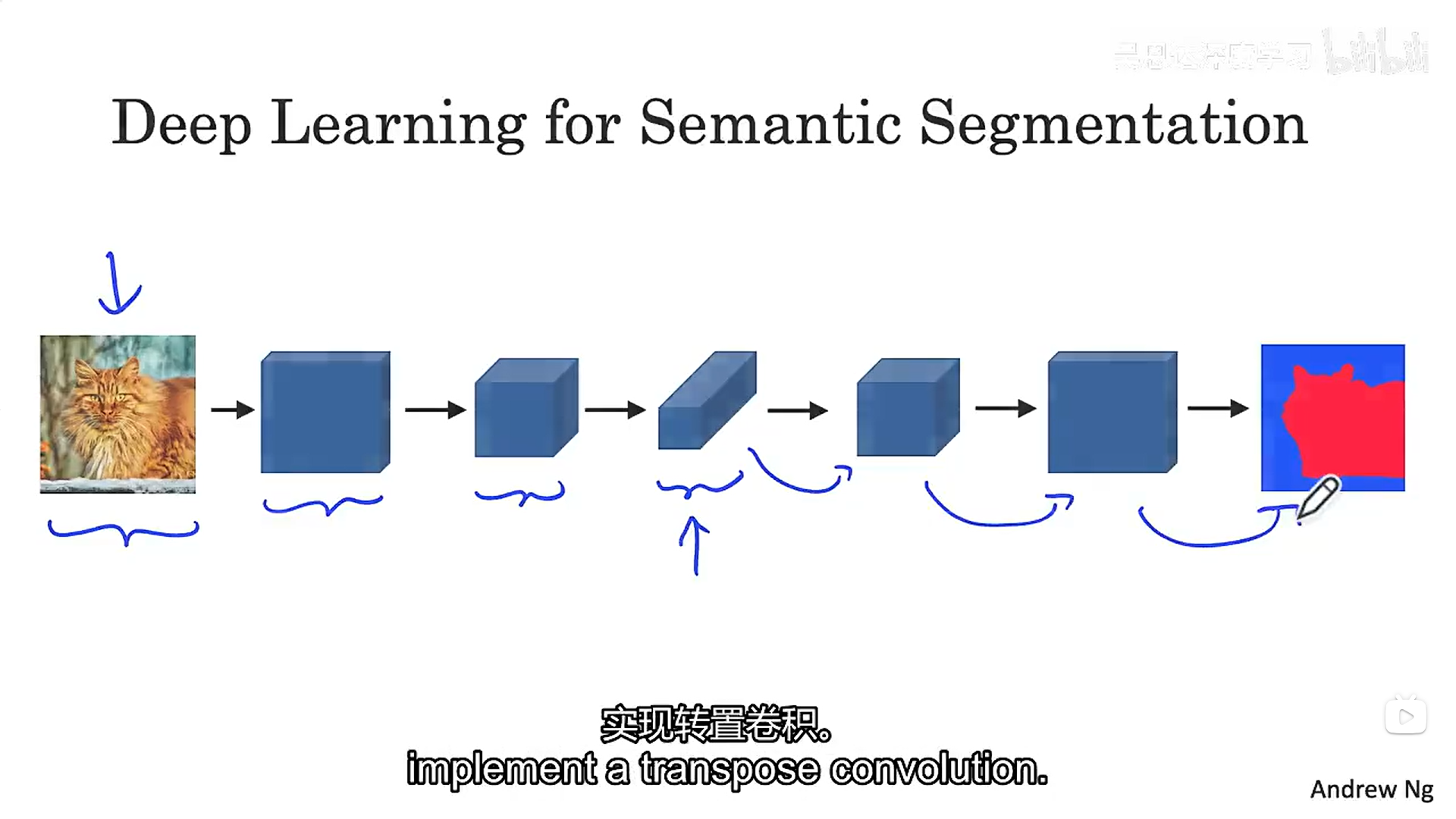
我们学过的对象检测,它会使得我们图像的尺寸变得越来越小,而图像分割是保留原尺寸大小的,意味着在对象检测流程中的某个部分我们就需要开始使用一些技术使我们图像的尺寸恢复到之前的大小(转置卷积),并且也要求能够对图像进行精准的分割。
4.2 转置卷积
首先我们先来看看一般卷积与转置卷积的区别:
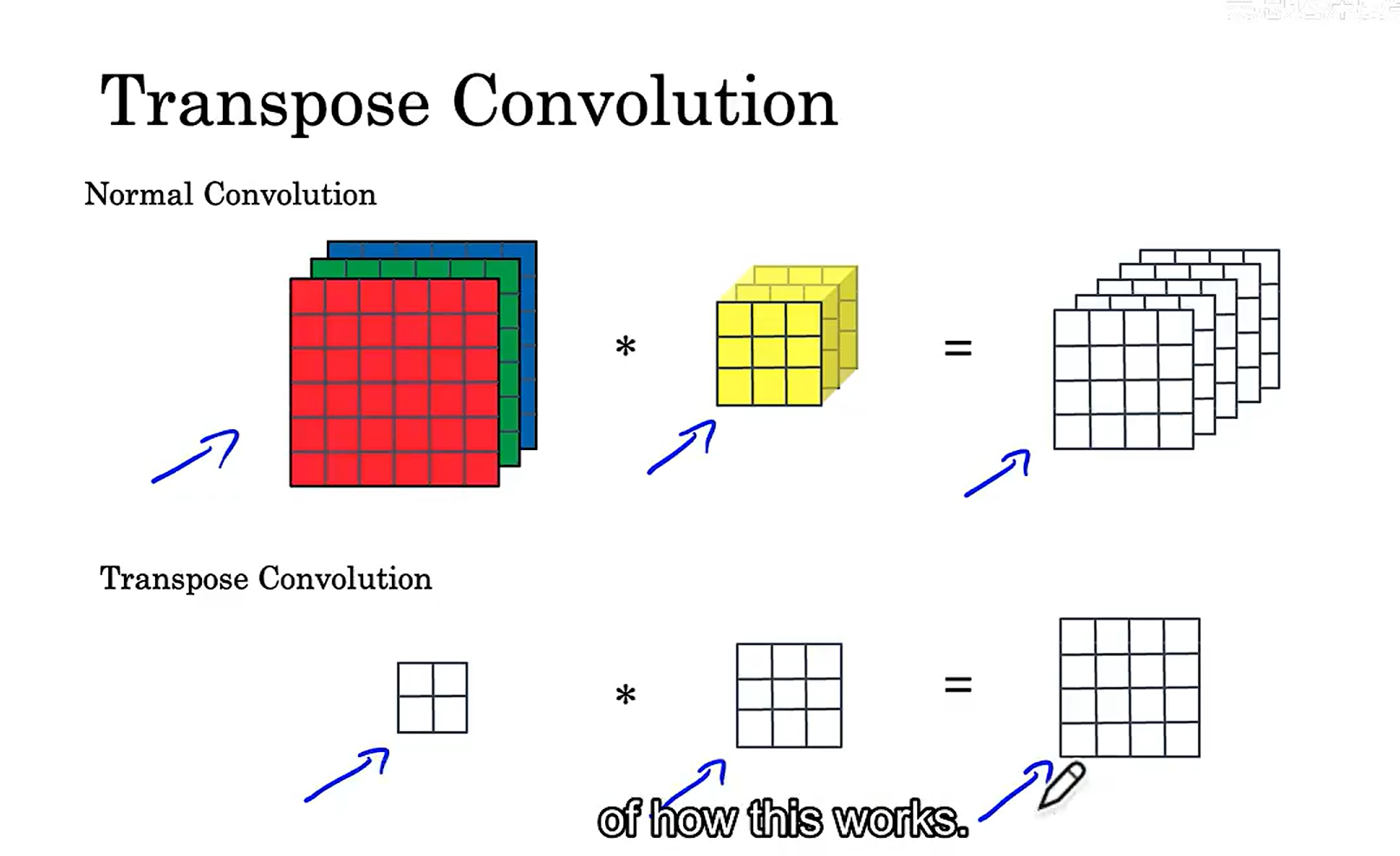
转置卷积:填充是针对输出来做的,接下来我们具体看看是如何进行卷积操作(图示)的。
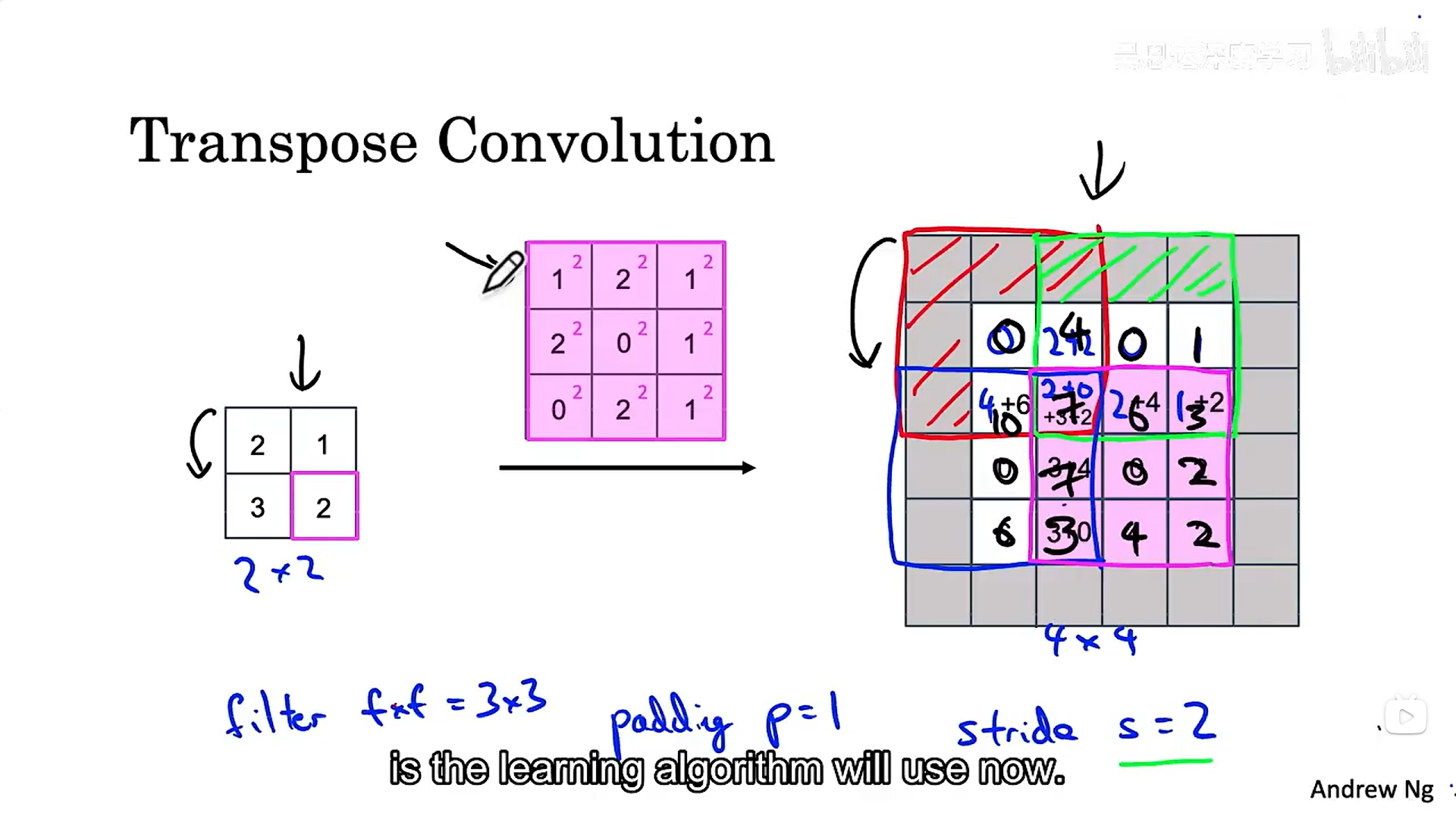
整个操作总结下来就是对原图像中的每个部分都进行卷积操作,填充部分不进行卷积,卷积有重叠的部分就进行相加,滑动到悬挂位置不进行卷积。
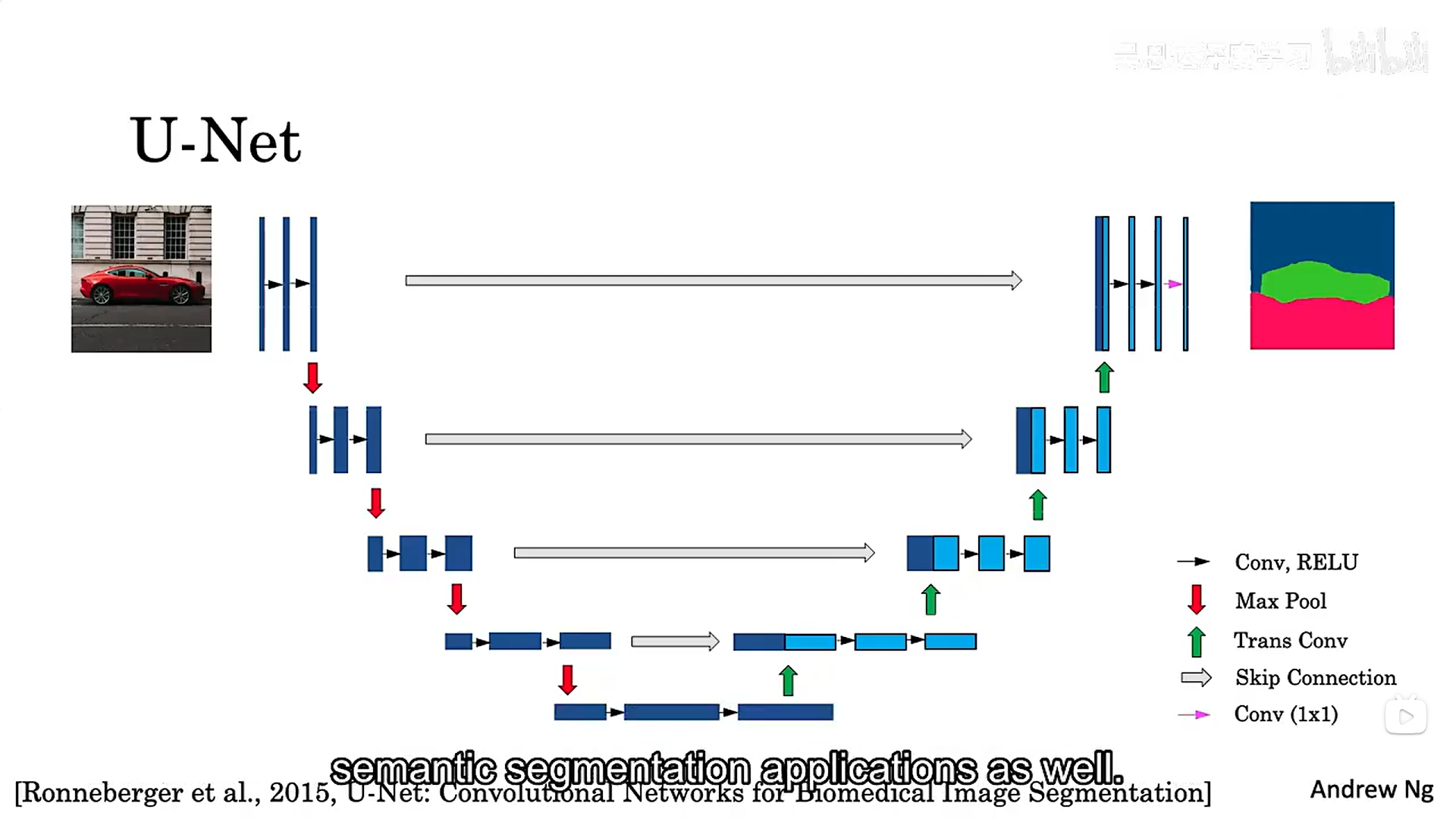
4.3 unet的工作原理
unet网络中存在跳跃连接,为什么要做样做呢?我们在网络的前半部分进行普通卷积的过程,对图像信息进行了压缩,导致图像丢失了很多空间及其他细粒度信息,跳跃连接的作用是它允许神经网络在它可以捕获的地方获取这种非常高分辨率、低级别的特征。
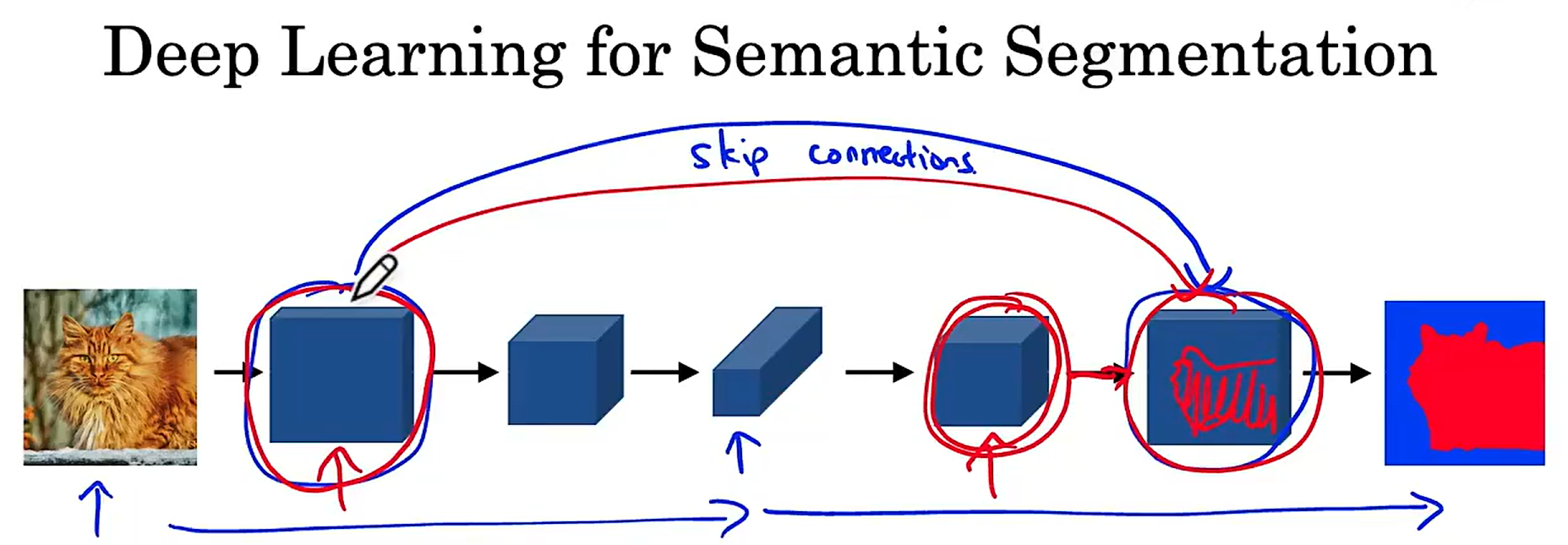
下面这张图像就是unet网络的内容: