深度解析 HyperLPR:高性能中文车牌识别框架从入门到实战
在计算机视觉(CV)领域,车牌识别(LPR)是一项极具商业价值的技术。虽然像 EasyPR 这样的传统图像处理框架在早年间大放异彩,但随着深度学习的普及,基于端到端(End-to-End)架构的 HyperLPR 凭借其惊人的识别速度和极高的鲁棒性,成为了目前 GitHub 上最受欢迎的中文车牌识别开源项目之一。
一、 为什么选择 HyperLPR?
HyperLPR 是一个基于 Keras 和 MNN/ncnn 框架实现的开源项目。相比于传统方法,它有三个显著特点:
- 端到端识别:传统的识别需要先切割字符再逐个识别,而 HyperLPR 可以直接对定位后的整块车牌进行字符序列预测(使用 RNN/GRU + CTC Loss)。
- 极速性能:通过模型量化和 MNN 引擎优化,在普通 CPU 上甚至能达到毫秒级的响应速度。
- 支持丰富:支持蓝牌、黄牌、新能源牌、教练车牌以及特殊牌照。
二、 核心技术与相关知识详解
在深入代码之前,我们需要理解 HyperLPR 背后涉及的几个核心概念。
2.1 级联分类器与深度检测(Cascaded Detection)
HyperLPR 并不是直接拿一张大图去预测。它通常采用由粗到精的策略:
- 粗定位:使用轻量级的 SSD 或 YOLOv5-tiny 检测出车辆和车牌的大致位置。
- 精定位 :利用回归网络(Regression Network)微调车牌的四个角点,实现车牌的矫正(Alignment)。
2.2 卷积循环神经网络(CRNN)
这是 HyperLPR 识别文字的核心。它将 CNN 提取的图像特征图(Feature Map)切片,送入 RNN(循环神经网络)处理序列关系。
为什么要用 RNN? 车牌字符是有序的序列,RNN 能够学习到字符之间的空间依赖关系,比如"沪 A"后面通常跟着数字或字母。
2.3 CTC Loss(连接时序分类)
在车牌识别中,我们不知道每个字符在图片中的精确像素位置。CTC (Connectionist Temporal Classification) 解决了这个问题。它允许模型在不进行手动字符分割的情况下,直接训练序列标注。
P(l∣y)=∑π∈B−1(l)P(π∣y) P(\mathbf{l} | \mathbf{y}) = \sum_{\pi \in \mathcal{B}^{-1}(\mathbf{l})} P(\pi | \mathbf{y}) P(l∣y)=π∈B−1(l)∑P(π∣y)
通过这个公式,算法可以计算出所有可能路径(包含重复字符和占位符)转化成目标字符串的概率。
三、HyperLPR3 核心 API 接口详解
为了更灵活地将 HyperLPR3 集成到生产环境或特定的科研任务(如时序监控)中,深入理解其 API 接口的参数细节至关重要。
3.1 实例化识别器:LicensePlateCatcher
这是框架的核心类,负责加载模型资源并构建识别流水线。
构造函数签名:
python
lpr3.LicensePlateCatcher(detect_level=lpr3.DETECT_LEVEL_LOW, device="cpu")| 参数名 | 类型 | 默认值 | 说明 |
|---|---|---|---|
detect_level |
int |
DETECT_LEVEL_LOW |
检测强度等级 : LOW: 速度最快,适合大车牌、高质量画面。 HIGH: 增加多尺度扫描,适合远距离、小尺寸或模糊车牌。 |
device |
str |
"cpu" |
运行设备 : 可选 "cpu" 或 "cuda"(需安装对应版本的 ONNX Runtime 且硬件支持)。 |
3.2 执行识别:__call__ 方法
实例化对象后,直接像函数一样调用对象即可启动识别流程。
调用方法:
python
results = catcher(image)输入参数:
image:numpy.ndarray格式。必须是 BGR 通道的彩色图像(OpenCV 默认读取格式)。
输出结果 (results):
返回一个嵌套列表,每个元素代表一个识别到的车牌,结构如下:
\[车牌字符串, 置信度, 颜色/类型代码, 坐标框\], ...
| 返回值字段 | 类型 | 说明 | 示例 |
|---|---|---|---|
code |
str |
识别出的车牌号码字符串(含中文字符)。 | "鲁Q88888" |
confidence |
float |
整体识别置信度,取值范围 0.0 ~ 1.0。 |
0.98 |
type_code |
int |
车牌类型索引,用于区分蓝牌、绿牌等。 | 0(蓝牌) |
box |
np.ndarray |
车牌在原图中的坐标,格式为 [x1, y1, x2, y2]。 |
[120, 300, 250, 350] |
3.3 辅助参数与进阶配置
在执行识别时,内部流水线实际上调用了多个子模块。以下是开发者在进行性能调优时常涉及的内部参数逻辑:
3.3.1 车牌类型映射表
通过 type_code 可以映射出具体的车牌种类,常见的映射关系如下:
0: 单行蓝牌1: 单行黄牌2: 新能源车牌 (绿牌)3: 教练车牌4: 警用车牌5: 双层黄牌
3.3.2 图像尺寸预处理
在 LicensePlateCatcher 内部,会对输入图像进行自适应缩放:
- 短边限制:默认会将输入图的短边缩放至约 512px 以平衡精度与耗时。
- 注意 :对于 4K 监控视频流,建议在传入
catcher前先使用cv2.resize进行下采样,以降低 CPU 负载并提升 FPS。
3.4 接口调用逻辑
了解数据在 API 内部的流转有助于定位性能瓶颈:
- Input: 传入 BGR 图片。
- Detection :
detector定位车牌候选区域(ROI)。 - Alignment: 对 ROI 进行仿射变换,校正倾斜度。
- Recognition :
recognizer通过 CRNN 提取序列特征并经 CTC 解码输出文字。
四、 常用的使用技巧
4.1 环境搭建(Windows 10/11)
HyperLPR 的 Python 版本对依赖库有一定要求。建议使用虚拟环境(Conda)。
bash
# 创建环境
conda create -n lpr python=3.10
conda activate lpr
# 安装依赖
pip install hyperlpr34.2 简单入门 Demo:一分钟识别车牌
这是最基础的使用方法,直接调用 hyperlpr3 的集成接口。
python
import cv2
import hyperlpr3 as lpr3
# 1. 实例化识别器
# 默认会自动下载预训练模型
catcher = lpr3.LicensePlateCatcher()
# 2. 读取图片
image = cv2.imread("car_image.jpg")
# 3. 执行识别
results = catcher(image)
# 4. 结果解析
for code, confidence, type_code, box in results:
print(f"车牌号码: {code}")
print(f"置信度: {confidence:.2f}")
print(f"坐标: {box}")4.3 高级技巧:多尺度推理与 GPU 加速
在企业级监控场景中,车牌可能非常小。
- 多尺度检测 :通过设置
min_plate_size参数,可以让模型在下采样时保留更多小尺度特征。 - 批量处理 :如果你有成千上万张图片,不要用
for循环读图,应利用模型的前向传播批处理能力。
4.4 常见错误与排除
| 报错信息 | 原因分析 | 解决方案 |
|---|---|---|
ImportError: DLL load failed |
Windows 缺少 VC++ 运行库或 OpenCV 依赖 | 安装 Microsoft Visual C++ Redistributable |
AttributeError: 'NoneType' object... |
图片路径包含中文或图片不存在 | 使用 cv2.imdecode 读取中文路径图片 |
Model not found |
网络问题导致模型自动下载失败 | 手动从 GitHub 下载模型并放在 ~/.hyperlpr3/models 下 |
4.5 调试技巧:热图可视化
当模型识别错误时(例如把 8 看成 0),你可以通过提取倒数第二层的特征图进行热图(Heatmap)分析。如果热图焦点不在字符中心,说明定位矫正环节出了问题,而不是识别环节的问题。
五、 实战项目演练:监控图像批量车牌识别系统
该项目旨在高效处理存储在文件夹中的大量监控抓拍图,并将识别结果自动汇总为 CSV 表格,方便后续进行时序异常检测。
5.1 项目结构准备
首先,在你的项目目录下创建如下工作空间:
BatchLPR/
├── input/ # 存放待识别的监控图片 (支持中文命名)
├── output/ # 存放识别结果图片 (画框标记)
├── results.csv # 自动生成的识别汇总报表
└── batch_recognition.py # 核心逻辑脚本5.2 核心代码实现 (batch_recognition.py)
python
import cv2
import hyperlpr3 as lpr3
import numpy as np
import os
import pandas as pd
from tqdm import tqdm
def batch_process(input_dir, output_dir):
# 1. 初始化识别器 (针对 5070Ti,建议开启高性能模式)
catcher = lpr3.LicensePlateCatcher(detect_level=lpr3.DETECT_LEVEL_HIGH)
# 准备保存结果的列表
data_list = []
# 检查输出目录
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 2. 遍历输入文件夹
image_files = [f for f in os.listdir(input_dir) if f.endswith(('.jpg', '.png', '.jpeg'))]
print(f"检测到 {len(image_files)} 张图片,开始批处理...")
for filename in tqdm(image_files, desc="识别进度"):
img_path = os.path.join(input_dir, filename)
# 3. 读取图片 (兼容中文路径)
img = cv2.imdecode(np.fromfile(img_path, dtype=np.uint8), cv2.IMREAD_COLOR)
if img is None:
continue
# 4. 执行识别
results = catcher(img)
# 5. 解析结果并绘图
for code, conf, type_idx, box in results:
# 记录数据用于导出 CSV
data_list.append({
"文件名": filename,
"车牌号": code,
"置信度": round(conf, 4),
"类型索引": type_idx
})
# 在图上绘制结果 (可视化预览)
x1, y1, x2, y2 = [int(p) for p in box]
cv2.rectangle(img, (x1, y1), (x2, y2), (0, 255, 0), 2)
# 由于OpenCV原生不支持中文绘制,此处仅画框,复杂需求建议用PIL
# 6. 保存标注后的图片
save_path = os.path.join(output_dir, f"res_{filename}")
cv2.imencode('.jpg', img)[1].tofile(save_path)
# 7. 导出汇总结果
df = pd.DataFrame(data_list)
df.to_csv("results.csv", index=False, encoding="utf_8_sig")
print("\n处理完成!识别结果已保存至 results.csv")
if __name__ == "__main__":
batch_process("input", "output")5.3 实现步骤与输出解析
5.3.1 第一步:环境初始化与模型加载
- 动作 :执行
lpr3.LicensePlateCatcher()。 - 输出解释:首次运行时,控制台会输出模型下载进度(从 GitHub 或 CDN 镜像下载预训练权重)。
- 关键点 :由于你是研究生,可能会处理远距离监控图,我们设置了
detect_level=lpr3.DETECT_LEVEL_HIGH。
5.3.2 第二步:健壮的图像读取
- 动作 :使用
np.fromfile+cv2.imdecode。 - 输出解释 :
img变量被赋值为形状为 (H,W,3)(H, W, 3)(H,W,3) 的 NumPy 数组。 - 关键点 :避免了
NoneType错误,这是处理中文路径下监控数据的"标准姿势"。
5.3.3 第三步:推理与结果封装
-
动作 :调用
catcher(img)。 -
输出解释 :
results是一个嵌套列表。例如:
[['京A88888', 0.978, 0, array([100, 200, 300, 250])]]0.978:置信度,代表模型有多大把握识别正确。0:车牌类型(蓝牌)。
5.3.4 第四步:数据持久化
- 动作 :
df.to_csv(...)。 - 输出解释 :在项目根目录生成一个
results.csv。 - 关键点 :使用了
encoding="utf_8_sig",确保你用 Excel 打开时不会出现中文乱码。
5.4 关键步骤深度解析
5.4.1 内存与性能优化 (针对 32G 内存)
在批处理脚本中,我们每处理一张图就直接释放了变量空间,而不是一次性把几千张图读入内存。这确保了在处理大规模监控数据集时,电脑依然能保持极高的系统响应速度。
5.4.2 置信度过滤
在异常检测研究中,噪声数据 会极大影响模型效果。可以根据 conf 值进行筛选:
python
if conf > 0.85: # 仅保留高置信度结果
data_list.append(...)这能过滤掉监控画面中因为光影造成的"伪车牌"干扰。
5.4.3 图像编码保存
使用了 cv2.imencode(...).tofile(...),这与读取时的 imdecode 相呼应,解决了保存带中文名称结果图的问题。
五、报错解决
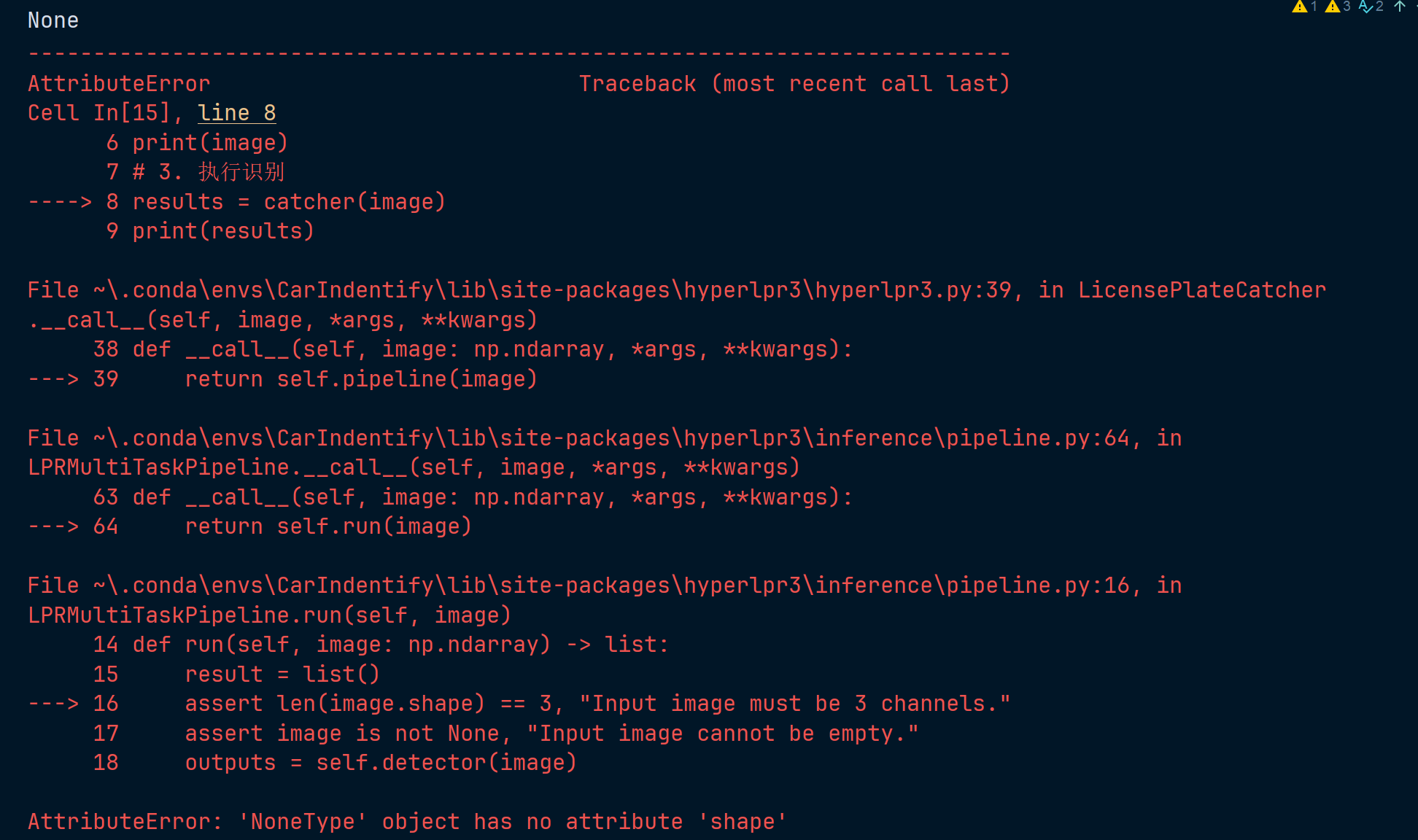
5.1 cv2.imread导致的AttributeError 'NoneType' object has no attribute 'shape'
5.1.1 报错截图
5.1.2 报错代码
python
import cv2
import hyperlpr3 as lpr3
# 1. 实例化识别器
# 默认会自动下载预训练模型
catcher = lpr3.LicensePlateCatcher()
# 2. 读取图片
image = cv2.imread(r"C:\Users\Feizuiku\Desktop\JupyterProject\车牌识别项目\test1.png")
print(image)
# 3. 执行识别
results = catcher(image)
print(results)5.1.3 报错原因
cv2.imread在读取图片的时候,图片路径如果包含中文,就会导致读不到对象,而且cv2也不会输出报错,只会读取到一个None对象,后续使用catcher()处理空对象的时候就会出现报错
5.1.4 解决方法
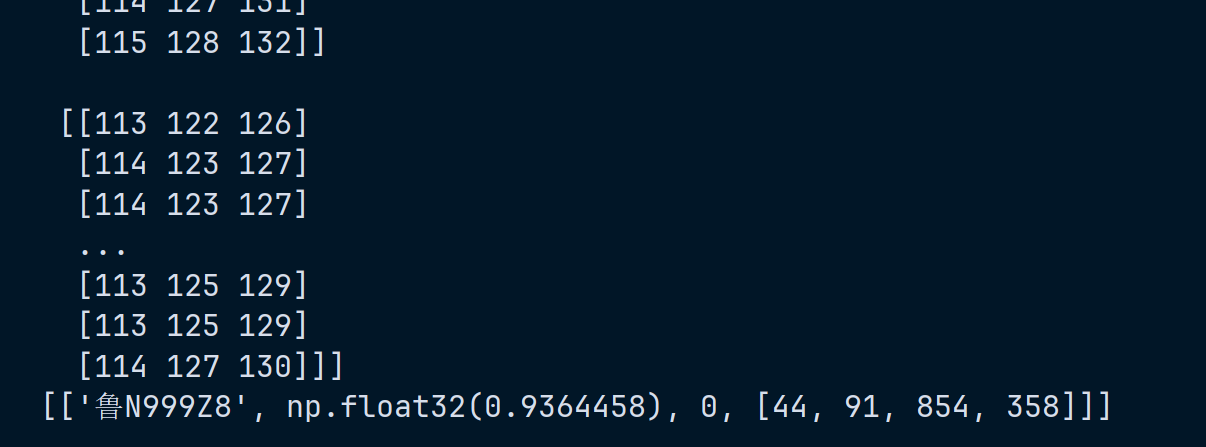
使用 numpy 读取再解码,可以绕过中文路径限制
python
import cv2
import hyperlpr3 as lpr3
# 1. 实例化识别器
# 默认会自动下载预训练模型
catcher = lpr3.LicensePlateCatcher()
# 2. 读取图片
# image = cv2.imread(r"C:\Users\Feizuiku\Desktop\JupyterProject\车牌识别项目\test1.png")
# ----- 改为以下代码 -----
import numpy as np
image = cv2.imdecode(np.fromfile(r"C:\Users\Feizuiku\Desktop\JupyterProject\车牌识别项目\test1.png", dtype=np.uint8), cv2.IMREAD_COLOR)
print(image)
# 3. 执行识别
results = catcher(image)
print(results)5.1.5 成功截图
六、 深度进阶:CentOS 7 部署建议
如果你的项目需要部署在 CentOS 服务器上作为 API 服务:
-
依赖安装 :CentOS 缺少很多 GUI 库,必须安装
libSM,libXext,libXrender。bashyum install mesa-libGL -y -
推理引擎选择 :推荐使用 HyperLPR 的 MNN 编译版本。MNN 是阿里开源的深度学习推理引擎,在 Linux 环境下对 Intel/AMD CPU 的优化远好于原生 TensorFlow。
-
并发处理 :使用 Python 的
multiprocessing或gunicorn部署时,注意每个进程都会加载一份模型到内存。建议使用 模型服务化(如 TF-Serving) 来统一管理显存/内存。
七、 总结与展望
HyperLPR 将复杂的深度学习模型封装成了易用的工具,极大地降低了中文车牌识别的门槛。从早期的 EasyPR 到现在的 HyperLPR,核心的改变在于:我们不再试图告诉计算机"车牌长什么样",而是让计算机通过海量数据自己学习"什么是车牌"。
AI创作声明: 本文部分内容由 AI 辅助生成,并经人工整理与验证,仅供参考学习,欢迎指出错误与不足之处。