对象存储(如MinIO)是存储所有类型数据的理想底层"湖盆",因为它存储的是最原始的二进制对象(Blob),本身不关心和解析数据内容的结构。它的角色就像一个巨大的、隔间完全相同的仓库,你可以把任何东西(无论是整齐的箱子、零散的物品还是半装好的包裹)放进去,它只负责安全地保存。数据的"结构"是由上层的计算引擎和表格式来解释和管理的。
一、结构化 半结构化 非结构化 数据入湖
不同类型的数据如何通过数据湖架构,最终以文件形式存入MinIO:
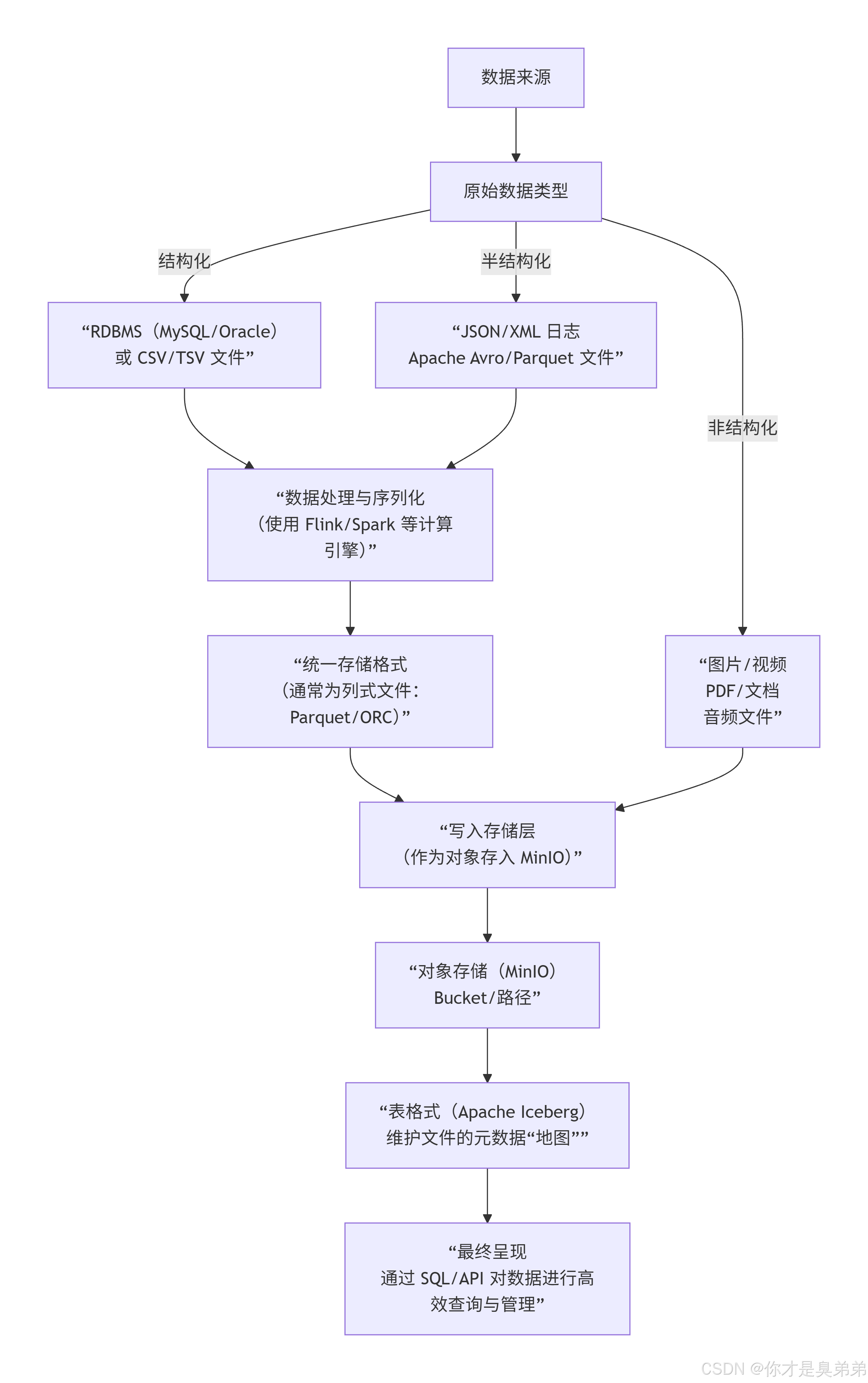
二、各类数据在MinIO中的具体形态
-
非结构化数据(MinIO最直接的存储对象)
-
是什么 :图片
.jpg/.png、视频.mp4、音频.mp3、文档.pdf/.docx。 -
如何存 :直接将这些文件作为对象上传到MinIO的桶中。
-
路径示例 :
s3://my-minio-bucket/images/photo001.jpg
-
-
半结构化数据(需要轻量解析)
-
是什么:JSON日志行、XML文件、Apache Avro/Parquet文件。
-
如何存 :同样直接作为对象存储。例如,一个
log.json文件或一个已经序列化好的.parquet文件。 -
路径示例 :
s3://my-minio-bucket/logs/2026-01-24.json
-
-
结构化数据(需要借助计算引擎和表格式)
-
是什么:来自MySQL/Oracle的关系型表数据,或规整的CSV文件。
-
如何存 :这是数据湖架构的核心价值所在。你不能直接把MySQL的
.ibd文件扔进去。而是需要:-
使用 Flink CDC 、Sqoop 等工具将数据从数据库实时或批量导出。
-
通过 Flink 、Spark 等计算引擎,将数据序列化为高效的列式存储文件格式(如 Apache Parquet 或 ORC)。
-
将这些Parquet文件作为对象写入MinIO。
-
同时,由 Apache Iceberg 在元数据层记录这些Parquet文件的集合,并构建出完整的"表",包括Schema、分区信息等。
-
-
三、数据流示例
假设你有一个MySQL的用户表,需要实时同步到数据湖进行分析:
-
同步与转换 :
MySQL->(通过Flink CDC实时捕获变更)->Apache Flink(处理并转换为Parquet格式)-> 写入MinIO的特定路径。 -
元数据管理 :在写入每个Parquet文件后,
Flink会向Apache Iceberg提交一次事务,更新元数据,声明"用户表的最新数据包含了这个新文件"。 -
最终查询 :分析师通过
Trino或Spark执行SELECT * FROM iceberg_catalog.db.user_table WHERE ...。查询引擎会:-
首先连接
Iceberg获取表的元数据。 -
根据元数据中的统计信息(如分区、列的最大最小值)快速定位到存储在
MinIO中的相关Parquet文件。 -
最后只读取这些必要的文件,返回结果。
-
MinIO作为存储层,完美扮演了"湖"的角色,有能力且非常适合存储所有类型的数据 。而数据的"结构化"能力,是由其上层的 Apache Iceberg(表格式) 和 Apache Flink/Spark(计算引擎) 共同赋予的。这正是现代数据湖 "存储与计算分离"、"数据与元数据分离" 架构的威力所在。