AlexNet
文章目录
- *AlexNet*
-
- [1 模型背景](#1 模型背景)
- [2 模型结构](#2 模型结构)
- [3 模型框架代码](#3 模型框架代码)
AlexNet 神经网络是美国学者Alex Krizhevsky 于2012年在论文ImageNet classification with deep convolutional neural networks中提出的。
该方法的提出在当时乃至现在都是具有里程碑意义的,他是当前卷积神经网络的基本范式,同时也是该网络开创了通过加深神经网络来实现精度的提升;也是它将非线性激活函数ReLU 函数第一次提出并引入,同时采用了DropOut 机制来防止出现过拟合的问题。是当时深度最深,计算量最大,模型参数最多的神经网络模型,并赢下了当时的ImageNet比赛。
虽然模型的架构已经非常的老,但是仍然由很多值得学习的地方。
1 模型背景
1998 年Tann LeCun 等人提出了卷积神经网络的奠基之作LeNet-5 模型之后卷积神经网络就进入了历史的寒冬。大概整整10年都没有出现特别先进的思想特别厉害的算法来对卷积深度学习进行改进。直到斯坦福大学的教授李飞飞用了许多年的时间和他的同学们一起做成了当时最大最强的数据集ImageNet 数据集并开源在网络之上,卷积神经网络又进入了一次新的热潮,其中最先跳脱而出的便是AlexNet。
ImageNet 数据集有大概1400 多万张图片, 超过2万多种分类,是当时最大的数据集,没有之一
当时比较出名的卷积神经网路就是LeNet-5 神经网络。如下图所示。然而该LeNet-5神经网络的训练精度在ImageNet上的过低。因此就需要尽可能的提升精度,但是现在的提升精度的方法并不多,人们只有猛拉深度这种办法了。
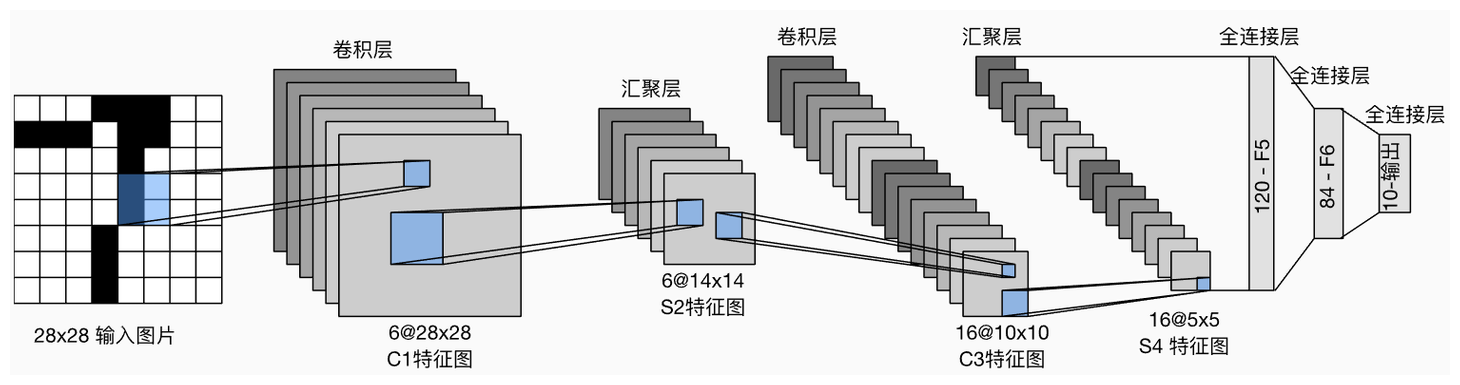
对此AlexNet就沿用了猛拉深度的思想,采用了八层网络架构来实现这个模型。
为什么人家不用超深的网络呢,实际上哈经济基础决定上层建筑,当时的GPU性能很低,就连AlexNet我们现在认为特别不行的模块都需要训练整整三天而且用了两个GPU才完成的。
可见技术的发展并不仅仅是软件算法的层面更是工业以及硬件等的整体提升。
论文的引言部分也说到:"最后,网络的大小主要受到当前GPU 上可用内存量以及我们愿意容忍的训练时间的限制。 我们的网络需要5 到6 天的时间在两个 GTX 580 3GB GPU 上进行训练。 我们所有的实验都表明,只需等待更快GPU和更大的数据集可用,我们的结果就可以得到改善"。
2 模型结构
为了提高训练的精度AlexNet使用了当时最大的深度,整整使用了八层进行训练。其中包括五个卷积层以及三个线性层。如下图所示。
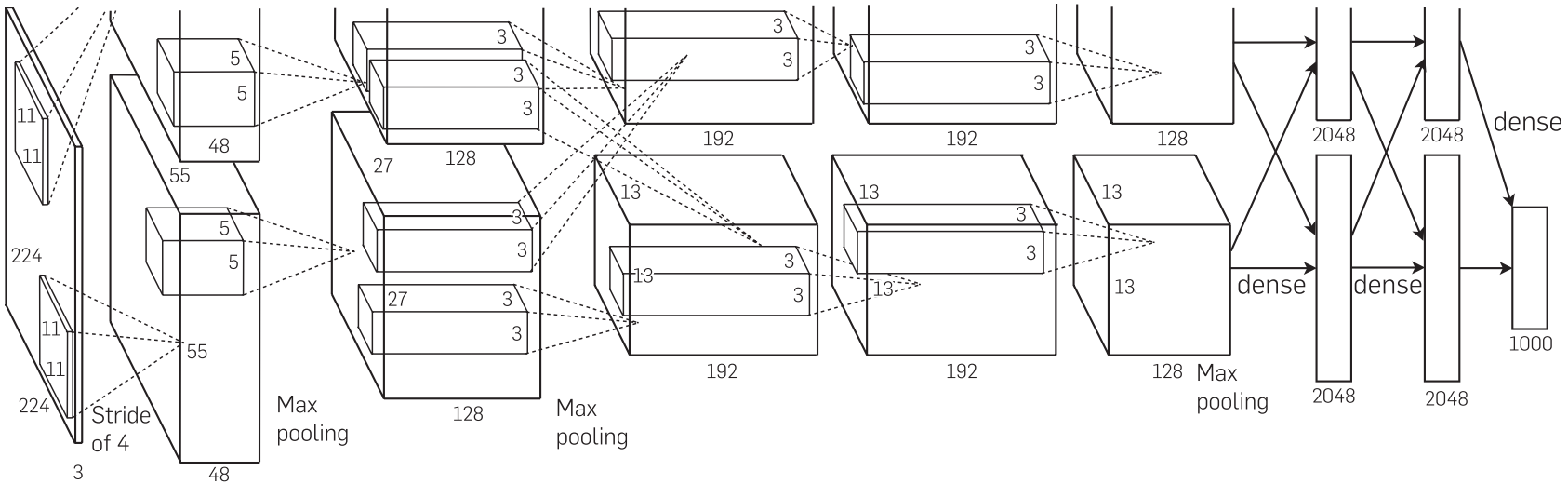
不知道大家有没有发现,这个网络结构的上半部分好像被截断了,感觉像是截图的有些问题一样。实际上并非如此,如此绘制是由它自己的一些想法的。当时的GPU 算例较低,因此只可以进行双GPU 训练的方式,那么两个GPU训练自然就与两个通道啦。
那么根据这个图片我们就可以使用自己的语言来说一下他整体的结构框架。该模型总共包括了八层,其中有五个卷积层和三个线性层:
这个网络架构主要基于ImageNet数据集的,该数据集的图片大小是三通道彩色图片。
- 该层卷积的卷积核大小为11 ,步长为4 ,填充为2 。并且总共有96个卷积核。实现下采样的功能。
- 该层卷积的卷积核大小为5 ,步长为1 ,填充为2 .并且总共有256个卷积核。实现特征的提取。
- 该层卷积的卷积核大小为3 ,步长为1 ,填充为1 ,并且总共有384个卷积核。实现特征的提取。
- 该层卷积的卷积核大小为3,步长为1 ,填充为1,并且总共有384个卷积核。实现特征的提取。
- 该层卷积的卷积核大小为3 ,步长为1,填充为1 ,并且总共有256个卷积核。实现特征的提取。
- 该线性层的输入数据为 256 × 6 × 6 256\times 6\times 6 256×6×6,输出数据为2048。
- 该线性层的输入数据为2048,输出数据为2048。
- 该线性层的输入数据为2048,输出数据为1000。
!CAUTION
注意,上面的*(1,2)层卷积层后面需要更上一组最大池化层 MaxPool*,最大池化层的参数在论文的4.4节提到,采用 k e r n e l = 3 , s t r i d e = 2 kernel=3,stride=2 kernel=3,stride=2的池化方式。
其次在进入线性层之前,需要引入DropOut机制函数,尽可能避免出现过拟合的情况出现。
最后在网络结构这里,我们还需要站在当时的角度来看看这篇文章在当时最强的地方是什么:
我们认为他最强的地方莫过于提出了一种非线性函数作为激活函数 R e L U = m a x ( 0 , x ) ReLU=max(0,x) ReLU=max(0,x),这个函数长得非常的简单。
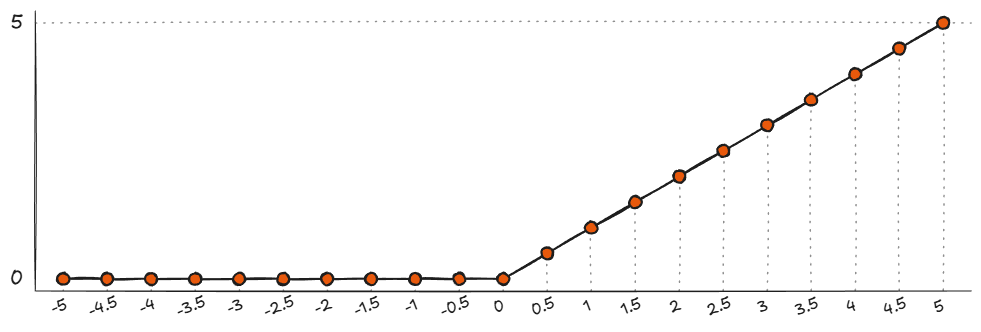
大道至简,这个函数成为现在最常用的激活函数没有之一!
3 模型框架代码
那么单个GPU的网络架构如下图所示。
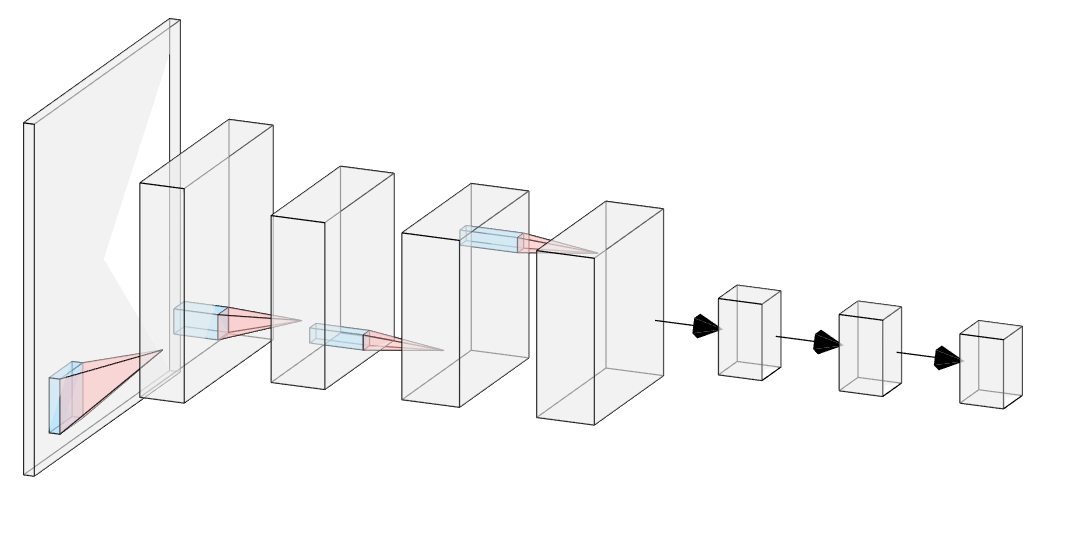
有了这个架构我们就可以进行AlexNet的代码编程。这里主要使用的是Pytorch框架进行撰写
python
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
import numpy as np
import torchvision
from torchvision import transforms, datasets
import torch.optim as optim
import time
from tqdm import tqdm
import os
from torch.cuda.amp import autocast, GradScaler
class AlexNet(nn.Module):
'''AlexNet 神经网络模块,这里就不再分两个GPU训练了,直接写在单个GPU上面进行训练
'''
def __init__(self , num_classes= 20):
super(AlexNet , self).__init__()
# input size = 224*224*3
self.Conv1 = nn.Conv2d(in_channels = 3 , out_channels = 96 , kernel_size = 11 , stride = 4 , padding = 2)
self.Relu1 = nn.ReLU(inplace=True)
self.maxpool1 = nn.MaxPool2d(kernel_size=3 , stride = 2)
# input size = 27*27*96
self.Conv2 = nn.Conv2d(in_channels = 96 , out_channels = 256 , kernel_size=5 , stride=1 , padding = 2)
self.Relu2 = nn.ReLU(inplace=True)
self.maxpool2 = nn.MaxPool2d(kernel_size = 3 , stride = 2)
# input size = 13*13*256
self.Conv3 = nn.Conv2d(in_channels = 256 , out_channels = 192*2 , kernel_size= 3 , stride = 1 , padding = 1)
self.Relu3 = nn.ReLU(inplace=True)
# input size = 13*13*384
self.Conv4 = nn.Conv2d(in_channels = 384 , out_channels=384 , kernel_size = 3 , stride=1 , padding=1)
self.Relu4 = nn.ReLU(inplace=True)
# input size = 13*13*384
self.Conv5 = nn.Conv2d(in_channels = 384 , out_channels =256 , kernel_size = 3 , stride = 1 , padding = 1)
self.Relu5 = nn.ReLU(inplace=True)
self.maxpool3 = nn.MaxPool2d(kernel_size = 3 , stride = 2)
self.avgpool = nn.AdaptiveAvgPool2d((6,6))
# input size = 6*6*256
self.dropout1 = nn.Dropout(p=0.5)
self.fc1 = nn.Linear(in_features = 256*6*6 , out_features=2048 , bias = True)
self.Relu6 = nn.ReLU(inplace=True)
# input size = 2048
self.fc2 = nn.Linear(in_features=2048 , out_features=2048 , bias = True)
self.Relu7 = nn.ReLU(inplace=True)
self.dropout2 = nn.Dropout(p=0.5)
# input size = 2048
self.fc3 = nn.Linear(in_features=2048 , out_features=num_classes , bias = True)
self.Softmax = nn.Softmax(dim=1)
def forward(self , x):
x = self.Conv1(x)
x = self.Relu1(x)
x = self.maxpool1(x)
x = self.Conv2(x)
x = self.Relu2(x)
x = self.maxpool2(x)
x = self.Conv3(x)
x = self.Relu3(x)
x = self.Conv4(x)
x = self.Relu4(x)
x = self.Conv5(x)
x = self.Relu5(x)
x = self.maxpool3(x)
x = self.avgpool(x)
x = self.dropout1(x)
x = x.view(x.size(0) , -1)
x = self.fc1(x)
x = self.Relu6(x)
x = self.fc2(x)
x = self.Relu7(x)
x = self.dropout2(x)
x = self.fc3(x)
return x