1 背景
生成式自回归模型不适合做嵌入模型 ,因为它们在训练中使用 causal mask 进行 next token prediction 的
模式使得 output 对 prompt 的理解分散在多个隐藏状态中。
Q1 为什么"输出"对"输入"的理解会分散到多个隐藏状态中?
一般嵌入模型如 BERT 使用的是双向注意力(Bidirectional Attention)。在 Bert 中,每一个词的隐藏状态都与前后词相关(因为能看到全句的所有词)。因此,整个句子的含义被"揉"进了每一个词向量里。
但在自回归模型中:
- 信息不对等: 第 1 个词的隐藏状态只包含它自己;第 10 个词的隐藏状态包含了前 10 个词的信息。
- 分散性: 整个 Prompt(提示词)的语义理解并不是集中在某一个向量里,而是随着生成过程不断累积的。你很难只拿出一个向量(比如最后一个词的向量)就说它完美代表了整个句子的"嵌入(Embedding)"。
核心矛盾:预测 vs. 压缩
嵌入模型(Embedding)的目标是 "压缩": 它要把一整句话的语义浓缩成一个定长的向量(比如 768 维),方便你做搜索或聚类。
像是一个阅读理解专家。他把整篇文章读完、读透,然后给你写一个简短的总结。
生成模型(Generative)的目标是 "接龙": 它的隐藏状态是为了预测下一个词服务的。它更关注"接下来该说什么",而不是"这段话整体是什么意思"。
自回归模型 (GPT): 像是一个说书人。他边说边想下一句,虽然他脑子里有逻辑,但他的状态是随着故事推进而变化的。你很难在他刚说出第一句时,就要求他给出一个能代表整场评书的精炼总结。
总结:
这就是为什么早期的嵌入模型多采用 Encoder-only (如 BERT) 架构,因为这种架构允许每个词"瞻前顾后",从而产生更紧凑、更全面的语义表示。而 GPT 这种 Decoder-only 架构天然就是为了"向前看"设计的。
RQ1 EOS对应的隐藏状态
OpenAI
Text and Code Embeddings by Contrastive Pre-Training
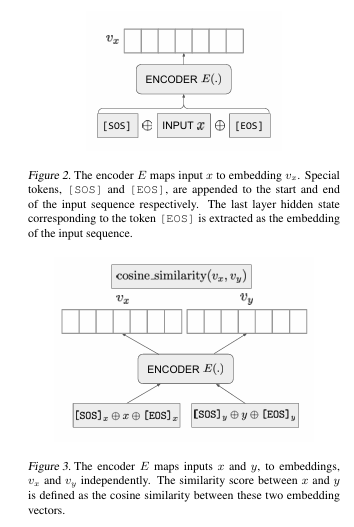
这篇论文介绍了使用 EOS(End of Sentence) 标己对应的最后一层隐藏层向量 作为整个文档的嵌入表示。这种方法的基本假设是,由于GPT是一个生成式模型,因此在生成EOS之前,模型需要对整个文档的上下文信息有一个很好的理解。因此,EOS对应的隐藏向量包含了整个文档的语义信息。
RQ2 Max Pooling Hidden:池化聚合
这种方法假设语义信息分布在所有 token 的向量中,通过数学聚合得到一个全局表示。
- 均值池化 (Average Pooling): 将文档中所有词在最后一层的隐藏层向量相加求平均 。它的基本逻辑是 "集思广益",认为 全局语义是由所有词共同构成的 。
- 最大池化 (Max Pooling): 在文档中所有词每个维度上选择数值最大的元素 。这种方法更倾向于捕捉文档中最显著、最突出的语义特征,类似于 "划重点"。
RQ3 Weighted Hidden:加权聚合 (SGPT 方案)
这是由 SGPT 模型提出的一种更符合自回归特性的方法。
核心逻辑: 由于 Causal Mask 的存在,序列中越靠后的 token 实际上"看过"的前文越多。例如,第 10 个词的向量包含了前 9 个词的信息,而第 1 个词只包含它自己。(越往后信息量越多)
加权方案: 赋予靠后的 token 更高的权重,通过线性加权的方式进行聚合。

例子:

Q2 为什么不直接取最后一个词的向量?
最后一个词既然包含了前 n-1 个词的信息,从直观上来想,可以将其作为句子表示呀。为什么还要对前面的词进行家权求和呢?

结论: 直接取最后一个词就像是只听演讲者的总结陈词;而加权平均则是听取整场演讲,但给总结陈词更高的权重。显然,后者得到的理解会更全面。
4 相关代码
python
import torch
from transformers import GPT2Tokenizer, GPT2Model
# 加载 GPT-2 模型和分词器
model_name = "gpt2"
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2Model.from_pretrained(model_name)
# 输入文本
text = "This is an example sentence."
# 对输入文本进行编码
input_ids = tokenizer.encode(text, return_tensors="pt") # shape: [1, seq_len]
# 获取模型的输出(关闭梯度计算)
with torch.no_grad():
outputs = model(input_ids)
# 提取最后一层隐藏层向量(batch_size, seq_len, hidden_size)
last_hidden_state = outputs.last_hidden_state
# 获取 EOS 标记的 ID
eos_token_id = tokenizer.eos_token_id
# 查找 EOS 标记在输入序列中的位置(注意:GPT-2 默认不会自动加 EOS!)
# 所以我们先检查是否真的有 EOS
if eos_token_id in input_ids[0]:
eos_position = (input_ids[0] == eos_token_id).nonzero(as_tuple=True)[1].item()
# 获取 EOS 对应的最后一层隐藏层向量(取 batch=0,位置=eos_position)
eos_hidden_vector = last_hidden_state[0, eos_position, :]
print("✅ EOS hidden vector:", eos_hidden_vector)
else:
print("⚠️ 输入文本中未包含 EOS token。GPT-2 默认不添加 EOS。")
# 如果你想强制加 EOS,可以这样:
# input_ids = tokenizer.encode(text + tokenizer.eos_token, return_tensors="pt")
# 然后重新运行模型- **(input_ids == eos_token_id):**这是一个 Boolean Mask(布尔掩码) 操作。它会返回一个和 input_ids 形状完全一样的 Tensor,其中只有等于 EOS ID 的位置是 True,其他地方都是 False。
- **.nonzero(as_tuple=True):寻找 Tensor 中所有 非零(在布尔中即为 True)**元素的坐标。设置 as_tuple=True 后,它会返回一个元组。对于二维张量,元组包含两个部分:行坐标数组, 列坐标数组。
- **1:**由于我们需要的是 EOS 在句子里的"位置"(即哪一列),所以我们要取返回元组的第二个元素(索引为 1 的列坐标)。如果 0 则是返回的哪一行。
- **.item():**将只有一个元素的 Tensor 转换为一个 Python 标量(Scalar),比如整数 2。