安装基础依赖
打开终端,输入:
# 更新系统
sudo apt update && sudo apt upgrade -y
# 安装编译工具
sudo apt install git build-essential cmake python3 python3-pip -y 安装系统包版本 numpy
sudo apt update
sudo apt install python3-numpy -y这一步保证你可以编译 llama.cpp 和运行 Python 脚本。
下载并编译 llama.cpp
install_llama.sh
#!/bin/bash
set -e # 有错误直接退出,别默默翻车
REPO_URL="https://github.com/ggerganov/llama.cpp"
DIR_NAME="llama.cpp"
BUILD_DIR="build"
echo "== llama.cpp 一键构建脚本 =="
# 1. 检查源码是否存在
if [ ! -d "$DIR_NAME" ]; then
echo "[INFO] 未检测到 llama.cpp,开始下载..."
export http_proxy=http://192.168.1.131:7897
export https_proxy=http://192.168.1.131:7897
git clone "$REPO_URL"
echo "[OK] 下载完成"
else
echo "[OK] 已存在 llama.cpp,跳过下载"
fi
cd "$DIR_NAME"
# 2. 检查 build 目录
if [ ! -d "$BUILD_DIR" ]; then
echo "[INFO] 创建 build 目录"
mkdir "$BUILD_DIR"
else
echo "[OK] build 目录已存在"
fi
cd "$BUILD_DIR"
# 3. CMake + 编译
echo "[INFO] 开始 CMake 配置"
cmake -DCMAKE_BUILD_TYPE=Release ..
echo "[INFO] 开始编译(make -j1)"
make -j1
echo "== llama.cpp 编译完成 =="-j1 限制单线程,避免 OOM
编译完成后生成 可执行文件
测试:
cd ~/llama.cpp/build/bin
./test-backend-opsTesting 1 devices
Backend 1/1: CPU
Skipping CPU backend
1/1 backends passed
OK
设置 HTTP/HTTPS 代理(临时)网络不好时候
export http_proxy=http://192.168.1.131:7897
export https_proxy=http://192.168.1.131:7897-
编译后生成的
main可执行文件,就是推理程序。 -
llama.cpp 支持 ARM CPU,所以 S805 可以直接跑。
下载模型 https://huggingface.co/search/full-text?q=TinyLLM+%2F+GGUF 搜索关键词 TinyLLM / GGUF
进入模型目录:
cd ~
mkdir models
cd /root/models然后用 wget 直接:
wget --no-check-certificate --secure-protocol=TLSv1_2
https://huggingface.co/Qwen/Qwen2.5-Coder-0.5B-Instruct-GGUF/resolve/main/qwen2.5-coder-0.5b-instruct-q5_0.gguf或者电脑下载后 scp拷贝过去
scp qwen2.5-coder-0.5b-instruct-q5_0.gguf root@192.168.1.157:/root/models一键下载脚本 dl.sh
#!/bin/bash
# 使用方法: ./dl.sh <下载链接> [保存文件名]
# 示例:
# ./dl.sh https://huggingface.co/Qwen/Qwen2.5-Coder-0.5B-Instruct-GGUF/resolve/main/qwen2.5-coder-0.5b-instruct-q5_0.gguf
# 设置代理
export http_proxy=http://192.168.1.131:7897
export https_proxy=http://192.168.1.131:7897
URL="$1"
FILENAME="$2"
if [ -z "$URL" ]; then
echo "请提供下载链接"
exit 1
fi
# 如果没有指定文件名,自动从 URL 提取
if [ -z "$FILENAME" ]; then
FILENAME=$(basename "$URL")
fi
echo "开始下载: $URL"
echo "保存为: $FILENAME"
wget --no-check-certificate --secure-protocol=TLSv1_2 -c "$URL" -O "$FILENAME" --tries=5 --timeout=30
if [ $? -eq 0 ]; then
echo "下载完成: $FILENAME"
else
echo "下载失败,请检查网络或代理设置"
fi运行
-
-m:模型文件路径 -
-p:输入提示(传感器数据或指令) -
-n:生成 token 数量(这里 10 个就够)
root目录下
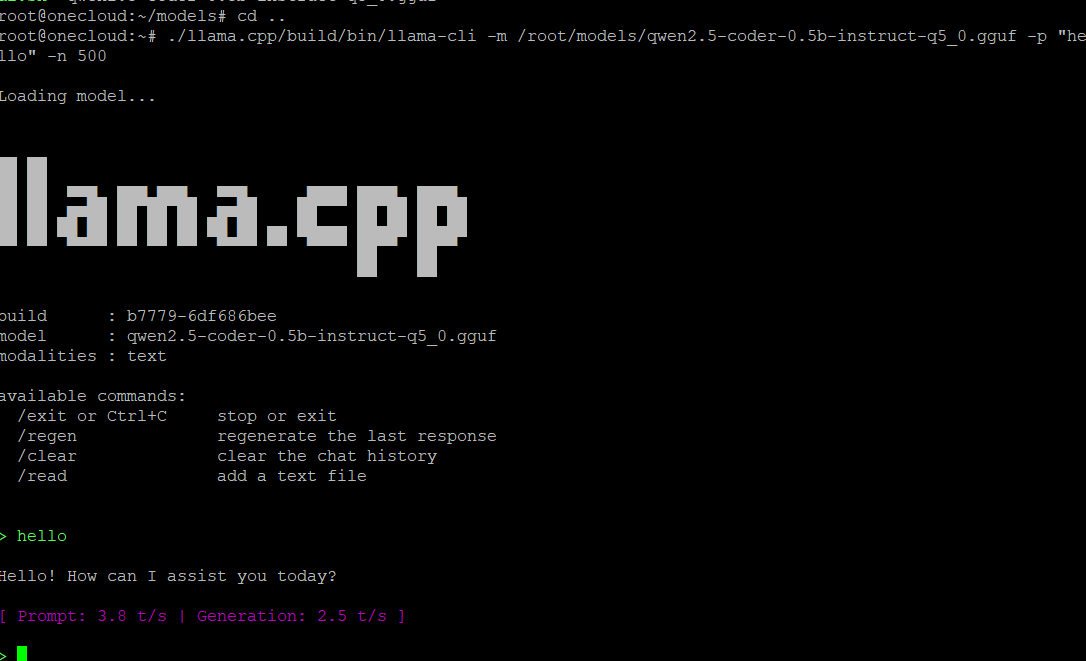
./llama.cpp/build/bin/llama-cli -m /root/models/qwen2.5-coder-0.5b-instruct-q5_0.gguf -p "hello" -n 500效果
一键启动脚本 start.sh
#!/bin/bash
MODEL_FILE=${1:-"qwen2.5-coder-0.5b-instruct-q5_0.gguf"}
MODEL_PATH="$HOME/models/$MODEL_FILE"
if [ ! -f "$MODEL_PATH" ]; then
echo "错误:模型文件 $MODEL_PATH 不存在!"
exit 1
fi
CTX_SIZE=1024
N_PREDICT=512
TEMP=0.3
THREADS=4
echo "开始加载模型:$MODEL_FILE"
echo "参数:上下文=$CTX_SIZE,生成token数=$N_PREDICT,温度=$TEMP,线程数=$THREADS"
"$HOME/llama.cpp/build/bin/llama-cli" \
-m "$MODEL_PATH" \
-c $CTX_SIZE \
-n $N_PREDICT \
--temp $TEMP \
--threads $THREADS \
--color auto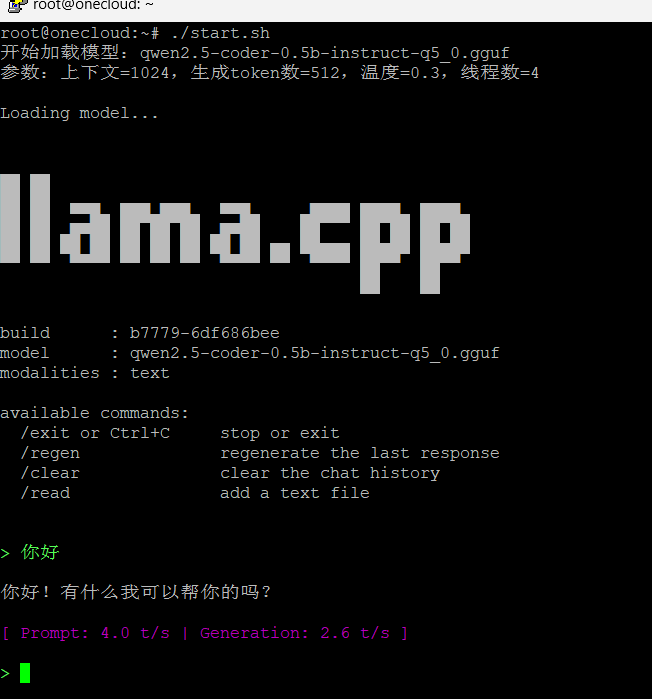
扩展
安装open webui
docker run -d \
--name open-webui \
-p 3000:8080 \
-e OPENAI_API_BASE_URL=http://192.168.1.191:8080/v1 \
-e OPENAI_API_KEY=sk-local \
--restart unless-stopped \
ghcr.io/open-webui/open-webui:main运行服务端模式
/root/llama.cpp/build/bin/llama-server \
-m /root/models/qwen2.5-coder-0.5b-instruct-q8_0.gguf \
-c 2048 \
--host 0.0.0.0 \
--port 8080测试服务端
curl http://127.0.0.1:8080/v1/models响应:
{"models":{"name":"qwen2.5-coder-0.5b-instruct-q8_0.gguf","model":"qwen2.5-coder-0.5b-instruct-q8_0.gguf","modified_at":"","size":"","digest":"","type":"model","description":"","tags":\["","capabilities":"completion","parameters":"","details":{"parent_model":"","format":"gguf","family":"","families":"","parameter_size":"","quantization_level":""}}],"object":"list","data":{"id":"qwen2.5-coder-0.5b-instruct-q8_0.gguf","object":"model","created":1769056357,"owned_by":"llamacpp","meta":{"vocab_type":2,"n_vocab":151936,"n_ctx_train":32768,"n_embd":896,"n_params":630167424,"size":669763072}}}
API使用:chatbox里面导入