在每一步控制并定制代理执行
中间件提供了一种更严格控制智能体内部发生事情的方法。中间件适用于以下用途:
- 通过日志记录、分析和调试跟踪智能体行为。
- 转换提示、工具选择和输出格式。
- 增加了重试、后备和提前终止逻辑。
- 应用速率限制、保护栏和个人身份识别(PII)检测。
通过传递给 create_agent 添加中间件:
python
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware, HumanInTheLoopMiddleware
agent = create_agent(
model=llm,
tools=[...],
middleware=[
SummarizationMiddleware(...),
HumanInTheLoopMiddleware(...)
],
)目录
[2.3.Model call limit(模型限制)](#2.3.Model call limit(模型限制))
[2.4.Tool call limit(工具限制)](#2.4.Tool call limit(工具限制))
[2.5.Model fallback(模型备用)](#2.5.Model fallback(模型备用))
[2.6.PII detection(个人信息检测)](#2.6.PII detection(个人信息检测))
[2.7.To-do list(待办列表)](#2.7.To-do list(待办列表))
[2.8.LLM tool selector(大模型工具选择)](#2.8.LLM tool selector(大模型工具选择))
[2.9.Tool retry(工具重试)](#2.9.Tool retry(工具重试))
[2.10.Context editing(清除工具调用历史输出)](#2.10.Context editing(清除工具调用历史输出))
[2.11.Shell tool(会话工具)](#2.11.Shell tool(会话工具))
[2.12.File search(文件搜索)](#2.12.File search(文件搜索))
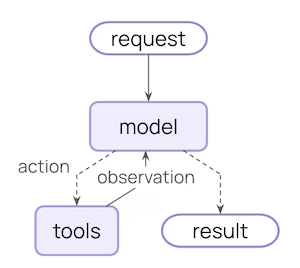
1.智能体循环
核心智能体循环包括调用模型,让模型选择执行工具,然后在调用工具不复存在时完成:
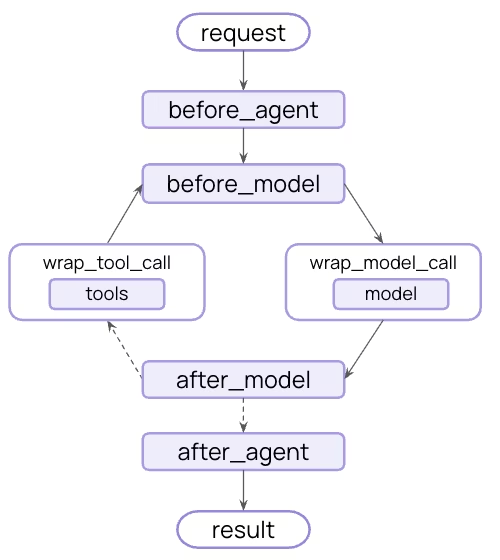
中间件在每一步之前和之后都暴露了钩子:
2.内置中间件
面向常见智能体用例的预构建中间件
LangChain 为常见场景提供了预构建的中间件。每个中间件都已准备好生产环境,并可根据你的具体需求配置。
以下中间件适用于任何大型语言模型提供商:
| Middleware | Description |
|---|---|
| SummarizationSummarizationSummarization | 接近tokens限制时自动总结对话记录。 |
| Human-in-the-loop | 暂停执行以供人工批准工具调用。 |
| Model call limit | 限制模型调用次数,以防止过高成本。 |
| Tool call limit | 通过限制呼叫次数来控制工具执行。 |
| Model fallback | 当主模式失败时,会自动回退到其他模式。 |
| PII detection | 检测并处理个人身份信息(PII)。 |
| To-do list | 为客服人员配备任务规划和跟踪能力。 |
| LLM tool selector | 在调用主模型之前,先用 LLM 选择相关工具。 |
| Tool retry | 用指数回撤自动重试失败的工具调用。 |
| Model retry | 自动用指数退回方式重试失败的模型调用。 |
| LLM tool emulator | 用 LLM 模拟工具执行以进行测试。 |
| Context editing | 通过修剪或清理工具使用来管理对话上下文。 |
| Shell tool | 向智能体开放一个持久的shell会话以执行命令。 |
| File search | 在文件系统文件上提供 Glob 和 Grep 搜索工具。 |
2.1.Summarization(摘要)
当接近令牌限制时自动总结对话历史,保留近期消息同时压缩旧上下文。摘要适用于以下情况:
- 长时间的对话超出上下文窗口。
- 多回合对话,历史悠久。
- 在保持完整对话上下文的重要应用中。
在https://blog.csdn.net/qq_58602552/article/details/157140199?spm=1001.2014.3001.5502
短期记忆模块也提到了
API reference: SummarizationMiddleware
| 参数名称 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| model | string | BaseChatModel |
- | 用于生成摘要的模型。可以是模型标识符字符串(如 'openai:gpt-4o-mini')或 BaseChatModel 实例。 |
| trigger | ContextSize | list[ContextSize] | None |
- | 触发摘要的条件。 1. 单个 ContextSize:必须满足该条件。 2. 列表:满足任一条件即触发(OR 逻辑)。 3. 未提供:不会自动触发摘要。 条件类型:fraction (0-1浮点数), tokens (整数), messages (整数)。 |
| keep | ContextSize |
('messages', 20) |
摘要后保留的上下文数量。必须指定且仅指定一种类型: 1. fraction (0-1浮点数)。 2. tokens (整数)。 3. messages (整数)。 |
| token_counter | function |
字符计数 | 自定义的 Token 计数函数。 |
| summary_prompt | string |
内置模板 | 自定义摘要提示词模板。若未指定,使用内置模板。注意:模板中必须包含 {messages} 占位符。 |
| trim_tokens_to_summarize | number |
4000 |
生成摘要时包含的最大 Token 数量。在摘要前,消息会被修剪以适应此限制。 |
| summary_prefix | string |
默认前缀 | 添加到摘要消息前的前缀。 |
| max_tokens_before_summary | number |
- | 已弃用 请改用 trigger: {"tokens": value}。 |
| messages_to_keep | number |
- | 已弃用 请改用 keep: {"messages": value}。 |
python
from langchain.agents import create_agent
from langchain.agents.middleware import SummarizationMiddleware
from langgraph.checkpoint.memory import InMemorySaver
from langchain_core.runnables import RunnableConfig
from langchain_community.chat_models import ChatTongyi # 导入千问
# --- 1. 初始化千问模型 ---
# 这里需要两个模型:一个用于主对话(大模型),一个用于做摘要(小模型/快模型)
# 假设你有对应的 Qwen 模型 ID
llm_main = ChatTongyi(model="qwen-max", temperature=0) # 主力模型
llm_mini = ChatTongyi(model="qwen-turbo", temperature=0) # 用于快速摘要的模型
# --- 2. 配置检查点 ---
checkpointer = InMemorySaver()
# --- 3. 创建 Agent ---
agent = create_agent(
model=llm_main, # 使用 Qwen-Max
tools=[],
middleware=[
SummarizationMiddleware(
# 指定用于生成摘要的模型 (使用更快的 qwen-turbo)
model=llm_mini,
# 触发条件:当 Token 数量超过 4000 时启动摘要
trigger=("tokens", 4000),
# 保留策略:在摘要后,保留最近的 20 条消息不被总结(只总结更早的历史)
keep=("messages", 20)
)
],
checkpointer=checkpointer,
)
2.2.Human-in-the-loop(人机参与)
在执行工具调用前,暂停执行,以便人工批准、编辑或拒绝。人机介入有助于以下用途:
- 需要人工批准的高风险作(例如数据库写入、金融交易)。
- 必须有人监督的合规工作流程。
- 长期对话,人工反馈引导经纪人。
人工环路(HITL)中间件允许你为智能体工具调用添加人工监督。当模型提出可能需要审查的动作时------例如写入文件或执行 SQL------中间件可以暂停执行并等待决策。
它通过将每个工具调用与可配置的策略进行对照来实现。如果需要干预,中间件会发出中断, 停止执行。图状态通过 LangGraph 的持久层保存,因此执行可以安全地暂停并稍后继续。
随后由人工决策决定下一步发生:动作可以按原样批准( approve )、执行前修改( edit ),或带反馈拒绝( reject )。
2.2.1.中断决策类型
中间件定义了三种内置的人类响应中断的方式:
| 决策类型 | 描述 | 示例用例 |
|---|---|---|
| ✅ approve | 该行动按现状批准并执行,无需更改。 | 按原文发送邮件草稿 |
| ✏️ edit | 工具调用执行时经过修改。 | 发送邮件前请更换收件人 |
| ❌ reject | 工具调用被拒绝,并在对话中添加了解释。 | 拒绝邮件草稿并说明如何重写 |
每个工具可用的决策类型取决于你在 interrupt_on 中配置的策略。当多个工具调用同时暂停时,每个作都需要独立决策。决策必须按照中断请求中出现的动作顺序提供。
2.2.2.中断配置
使用 HITL 时,在创建智能体时将中间件添加到代理的middleware列表中。你可以通过映射工具动作与每个动作允许的决策类型来配置它。当工具调用与映射中的动作匹配时,中间件会中断执行。
python
from langchain.agents import create_agent
from langchain.agents.middleware import HumanInTheLoopMiddleware
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model="gpt-4o", # 指定使用的AI模型
tools=[write_file_tool, execute_sql_tool, read_data_tool], # 可调用的工具列表
# 中间件配置,用于控制人工干预流程
middleware=[
HumanInTheLoopMiddleware(
# 定义哪些工具执行时需要人工确认
interrupt_on={
"write_file": True, # write_file工具:允许所有操作(批准、编辑、拒绝)
"execute_sql": {"allowed_decisions": ["approve", "reject"]}, # execute_sql工具:只允许批准或拒绝,不可编辑
"read_data": False, # read_data工具:安全操作,无需人工批准
},
# 中断消息的前缀 - 会与工具名称和参数组合形成完整的消息
# 例如:"Tool execution pending approval: execute_sql with query='DELETE FROM...'"
# 单个工具可以在其interrupt配置中通过指定"description"来覆盖此默认前缀
description_prefix="待批准的工具执行", # 中文描述前缀
# 其他可用参数(示例):
# max_retries=3, # 最大重试次数
# auto_approve_after=None, # 超时后自动批准(秒)
# request_timeout=30, # 等待人工响应的超时时间
),
],
# 人工干预流程需要检查点机制来处理工具执行中断
# 在生产环境中,建议使用持久化检查点,如AsyncPostgresSaver
checkpointer=InMemorySaver(), # 使用内存中的检查点存储(开发/测试用)
# 其他可选参数示例:
# system_message="你是一个数据处理助手,执行任何可能产生副作用的操作前都需要人工确认。", # 系统提示词
# verbose=True, # 启用详细日志
# max_iterations=10, # 最大迭代次数限制
)2.2.3.响应中断
当你调用智能体时,它会运行,直到完成或中断被触发为止。当工具调用与你 interrupt_on 配置的策略匹配时,会触发中断。
在这种情况下,**调用结果会包含一个 __interrupt__ 字段,显示需要复核的动作。**然后你可以向审核员展示这些动作,并在决定给出后继续执行。
python
from langgraph.types import Command
# 人机协同利用了LangGraph的持久化层
# 必须提供thread_id来将执行与会话线程关联,
# 这样会话才能被暂停和恢复(这是人工审核所需的)
config = {"configurable": {"thread_id": "some_id"}}
# 运行图直到遇到中断点
result = agent.invoke(
{
"messages": [
{
"role": "user",
"content": "从数据库中删除旧记录",
}
]
},
config=config # 传入配置
)
# 中断信息包含完整的人机协同请求,包括action_requests和review_configs
print(result['__interrupt__'])
# 输出示例:
# [
# Interrupt(
# value={
# 'action_requests': [
# {
# 'name': 'execute_sql',
# 'arguments': {'query': 'DELETE FROM records WHERE created_at < NOW() - INTERVAL \'30 days\';'},
# 'description': '工具执行等待批准\n\n工具: execute_sql\n参数: {...}'
# }
# ],
# 'review_configs': [
# {
# 'action_name': 'execute_sql',
# 'allowed_decisions': ['approve', 'reject'] # 允许的决策
# }
# ]
# }
# )
# ]
# 以批准决策恢复执行
agent.invoke(
Command( # 使用Command对象
resume={"decisions": [{"type": "approve"}]} # 或使用"reject"拒绝
),
config=config # 使用相同的thread_id来恢复暂停的会话
)2.2.4.决策类型
使用 approve 来批准工具调用,按原样执行,不做修改。
python
agent.invoke(
Command(
# 决策以列表形式提供,每个待审核动作对应一个决策
# 决策的顺序必须与`__interrupt__`请求中
# 列出的动作顺序保持一致
resume={
"decisions": [
{
"type": "approve", # 审批通过
}
]
}
),
config=config # 使用相同的thread_id来恢复暂停的会话
)2.2.5.流式的人机交互
你可以用 stream() 代替 invoke(), 在智能体运行和处理中断时实时获取更新。用 stream_mode=['updates', 'messages'] 来流式传输智能体进度和 LLM tokens。
python
from langgraph.types import Command
config = {"configurable": {"thread_id": "some_id"}}
# 流式传输代理进度和LLM token,直到遇到中断
for mode, chunk in agent.stream(
{"messages": [{"role": "user", "content": "从数据库中删除旧记录"}]},
config=config,
stream_mode=["updates", "messages"], # 流模式:更新信息和消息
):
if mode == "messages":
# LLM token
token, metadata = chunk
if token.content:
print(token.content, end="", flush=True) # 实时输出token内容
elif mode == "updates":
# 检查是否遇到中断
if "__interrupt__" in chunk:
print(f"\n\n中断信息: {chunk['__interrupt__']}")
# 人工决策后继续流式传输
for mode, chunk in agent.stream(
Command(resume={"decisions": [{"type": "approve"}]}), # 恢复执行,使用批准决策
config=config,
stream_mode=["updates", "messages"], # 流模式:更新信息和消息
):
if mode == "messages":
token, metadata = chunk
if token.content:
print(token.content, end="", flush=True) # 实时输出token内容2.2.6.执行生命周期
中间件定义了一个 after_model 钩子,在模型生成响应后运行,但在任何工具调用执行之前:
- 智能体调用模型生成响应。
- 中间件检查工具调用的响应。
- 如果有调用需要人工输入,中间件会构建包含
action_requests和review_configs的HITLRequest,并进行调用中断。 - zhi等待人类的决定。
- 基于
HITLResponse的决策,中间件执行已批准或编辑的调用,综合 ToolMessage 的拒绝调用,并恢复执行。
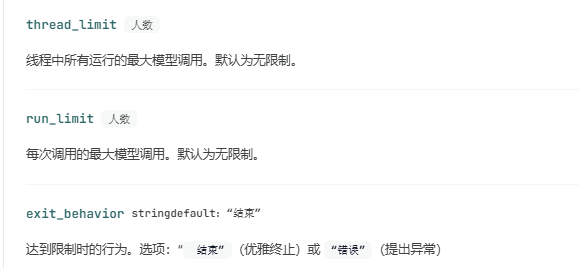
2.3.Model call limit(模型限制)
限制模型调用次数,以防止无限循环或过高成本。模型调用限制适用于以下情况:
- 防止失控智能体调用过多 API。
- 对生产部署实施成本控制。
- 在特定呼叫预算内测试座席行为。
ModelCallLimitMiddleware:
python
from langchain.agents import create_agent
from langchain.agents.middleware import ModelCallLimitMiddleware
from langgraph.checkpoint.memory import InMemorySaver
agent = create_agent(
model=llm,
checkpointer=InMemorySaver(), # Required for thread limiting
tools=[],
middleware=[
ModelCallLimitMiddleware(
thread_limit=10,
run_limit=5,
exit_behavior="end",
),
],
)
2.4.Tool call limit(工具限制)
通过限制工具调用次数来控制智能体执行,无论是全局调用所有工具还是针对特定工具。工具调用限制适用于以下情况:
- 防止对昂贵外部 API 的过度调用。
- 限制网络搜索或数据库查询。
- 对特定工具使用强制执行速率限制。
- Protecting against runaway agent loops.
python
from langchain.agents import create_agent
from langchain.agents.middleware import ToolCallLimitMiddleware
agent = create_agent(
model="gpt-4o",
tools=[search_tool, database_tool],
middleware=[
# Global limit
ToolCallLimitMiddleware(thread_limit=20, run_limit=10),
# Tool-specific limit
ToolCallLimitMiddleware(
tool_name="search",
thread_limit=5,
run_limit=3,
),
],
)tool_name
具体限制的工具名称。如果未提供,则全球所有工具均适用限制。
thread_limit
线程中所有运行(对话)中最大工具调用次数。在同一线程 ID 下,跨多个调用持续存在。需要检查点来维持状态。没有线程就没有线程限制。
run_limit
每次调用的最大工具调用(一个用户消息→响应周期)。每收到一条新用户消息就会重置。没有就意味着没有得分限制。注意:至少必须指定thread_limit或run_limit中的一个。
exit_behavior
达到极限时的行为:
"continue"(默认)- 阻止超出工具调用并出现错误信息,允许其他工具和模型继续。模型根据错误信息决定何时结束。'error'- 提出ToolCallLimitExceededError异常,立即停止执行"end"------立即通过ToolMessage和 AI 消息停止执行,针对超出的工具调用。只有限制单个工具时才有效;如果其他工具有待处理调用,则会触发NotImplementedError。
2.5.Model fallback(模型备用)
当主模型失败时,自动回退到其他模型。模型回退适用于以下用途:
- 构建能够处理模型故障的韧性代理。
- 通过回归更便宜的模型来优化成本。
- OpenAI、Anthropic 等平台的提供者冗余。
python
from langchain.agents import create_agent
from langchain.agents.middleware import ModelFallbackMiddleware
agent = create_agent(
model="gpt-4o",
tools=[],
middleware=[
ModelFallbackMiddleware(
"gpt-4o-mini",
"claude-3-5-sonnet-20241022",
),
],
)2.6.PII detection(个人信息检测)
使用可配置策略检测并处理对话中的个人身份信息(PII)。PII 检测适用于以下用途:
- 医疗保健和金融应用,要求合规。
- 需要清理日志的客服人员。
- 任何处理敏感用户数据的应用程序。
PIIMiddleware:
python
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware
agent = create_agent(
model="gpt-4o",
tools=[],
middleware=[
PIIMiddleware("email", strategy="redact", apply_to_input=True),
PIIMiddleware("credit_card", strategy="mask", apply_to_input=True),
],
)| 参数名 | 类型 | 描述 |
|---|---|---|
entity_type |
str |
指定要识别和处理的 PII(个人身份信息)实体的类型。例如,"email"、"credit_card"、"phone_number"、"ssn" (社会安全号码) 等。 |
strategy |
str |
指定对识别出的 PII 实体应用的处理策略。 * "redact":将其完全删除或替换为占位符。 * "mask":将其部分字符替换(如用 * 或 X)以达到隐藏效果。 * "hash":将其进行哈希加密处理。具体可用的策略也取决于中间件的实现。 |
apply_to_input |
bool |
一个布尔值,指定该中间件是否应用于发送给模型的输入(用户查询)。 |
apply_to_output |
bool |
一个布尔值,指定该中间件是否应用于模型返回的输出(模型响应)。 |
**kwargs |
dict |
其他特定于中间件实现的关键字参数。例如,某些实现可能允许传递 mask_char='*' 来指定掩码使用的字符,或者 placeholder="[REDACTED]" 来指定删除时使用的占位符。这些高级选项依赖于具体库的文档。 |
自定义检测器:
你可以通过提供detector 参数来创建自定义的个人信息类型。这让你能够发现与你使用场景相关的模式,而不仅仅是内置的类型。
定制探测器的2种方式:
- 正则表达式模式字符串- 简单模式匹配
- 自定义函数------带验证的复杂检测逻辑
python
from langchain.agents import create_agent
from langchain.agents.middleware import PIIMiddleware
import re
# 方法 1: 使用字符串形式的正则表达式模式
agent1 = create_agent(
model="gpt-4o",
tools=[],
middleware=[
# 中间件:用于检测和阻止 OpenAI API Key (以 sk- 开头,后跟 32 位字母数字)
PIIMiddleware(
# 定义 PII 实体类型名称
"api_key",
# 定义用于检测 PII 的正则表达式模式 (字符串形式)
detector=r"sk-[a-zA-Z0-9]{32}",
# 指定检测到 PII 时的处理策略:阻止 (block)
strategy="block",
),
],
)
# 方法 2: 使用已编译的正则表达式对象
agent2 = create_agent(
model="gpt-4o",
tools=[],
middleware=[
# 中间件:用于检测并掩码处理电话号码
PIIMiddleware(
# 定义 PII 实体类型名称
"phone_number",
# 定义用于检测 PII 的正则表达式模式 (编译后的 Pattern 对象)
detector=re.compile(r"\+?\d{1,3}[\s.-]?\d{3,4}[\s.-]?\d{4}"), # 匹配 +区号 分隔符 数字 的格式
# 指定检测到 PII 时的处理策略:掩码 (mask),即部分隐藏
strategy="mask",
),
],
)
# 方法 3: 使用自定义的检测函数
def detect_ssn(content: str) -> list[dict[str, str | int]]:
"""
检测社会安全号码 (SSN) 并进行基本验证。
返回一个包含 'text', 'start', 和 'end' 键的字典列表。
"""
# 在函数内部导入 re,虽然通常建议在文件顶部导入,但这里演示可行
import re
matches = [] # 存储找到的有效 SSN 信息
# 定义 SSN 的基础格式正则表达式 (ddd-ddd-dddd)
pattern = r"\d{3}-\d{2}-\d{4}"
# 遍历内容中所有匹配项
for match in re.finditer(pattern, content):
ssn = match.group(0) # 获取完整的匹配文本
# 基本验证:前三位不能是 000, 666, 或者在 900-999 范围内
first_three = int(ssn[:3]) # 提取前三位数字
# 如果通过验证,则将其添加到结果列表中
if first_three not in [0, 666] and not (900 <= first_three <= 999):
matches.append({
"text": ssn, # 找到的 SSN 文本
"start": match.start(), # SSN 在原字符串中的起始索引
"end": match.end(), # SSN 在原字符串中的结束索引
})
return matches # 返回包含有效 SSN 位置信息的列表
agent3 = create_agent(
model="gpt-4o",
tools=[],
middleware=[
PIIMiddleware(
"ssn",
detector=detect_ssn,
strategy="hash",
),
],
)
- 用户输入 (请求) : "我的订单号是 123456789,我的邮箱是
my_private_email@example.com,我需要修改收货地址。我的身份证号是 123456789012345678,请发一份电子发票到这个邮箱。"- PII 检测作用 :
- 检测 : 中间件识别出
my_private_email@example.com(邮箱) 和123456789012345678(身份证号)。- 处理 : 根据预设策略,比如
strategy="mask",输入在发送给 AI 模型前被处理成:"我的订单号是 123456789,我的邮箱是m***l,我需要修改收货地址。我的身份证号是 12345678,请发一份电子发票到这个邮箱。"
自定义探测器功能特征-- 检测函数必须接受字符串(内容),并返回匹配:返回带有text、start和 end 的词典列表:
python
def detector(content: str) -> list[dict[str, str | int]]:
return [
{"text": "matched_text", "start": 0, "end": 12},
# ... more matches
]2.7.To-do list(待办列表)
为智能体提供复杂多步骤任务的任务规划和跟踪能力。待办事项清单适用于以下用途:
- 复杂的多步骤任务需要在多个工具间协调。
- 长期运营,进度可见性非常重要。
python
from langchain.agents import create_agent
from langchain.agents.middleware import TodoListMiddleware
agent = create_agent(
model="gpt-4o",
tools=[read_file, write_file, run_tests],
middleware=[TodoListMiddleware()],
)
python
from langchain.agents import create_agent
from langchain_community.chat_models import ChatTongyi
from langchain_core.tools import tool
from langchain.agents.middleware import TodoListMiddleware
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.output_parsers import StrOutputParser
import os
# --- 2. 自定义工具函数定义 ---
# 这些是智能体可以调用的实际功能
@tool
def calculate_bmi(weight_kg: float, height_m: float) -> float:
"""计算身体质量指数。公式:体重(kg) / 身高(m)的平方"""
bmi = weight_kg / (height_m ** 2)
return round(bmi, 2)
@tool
def get_health_risk_category(bmi: float) -> str:
"""根据BMI数值判断健康风险等级"""
if bmi < 18.5:
return "偏瘦:可能存在营养不良风险。建议增加营养摄入。"
elif 18.5 <= bmi < 24:
return "正常:体重健康!请继续保持。"
elif 24 <= bmi < 28:
return "超重:存在一定的慢性病风险。建议适当运动。"
else:
return "肥胖:存在较高的健康风险。建议咨询医生或营养师。"
@tool
def search_nutrition_info(query: str) -> str:
"""联网搜索特定食物或营养相关的知识"""
# 这里可以集成 Tavily 或其他搜索工具
# 为了简化,我们直接返回一个模拟结果
return f"模拟搜索结果:关于 '{query}' 的权威建议是多喝水,保持均衡饮食。"
# 将工具放入列表
tools = [calculate_bmi, get_health_risk_category, search_nutrition_info]
# --- 3. 配置 TodoListMiddleware ---
# 创建中间件,帮助智能体规划复杂步骤
todo_middleware = TodoListMiddleware(
system_prompt=(
"你正在协助一个健康顾问智能体。请监控其思考过程:\n"
"- 当用户提到体重、身高时,规划'计算BMI'。\n"
"- 当得到BMI数值后,规划'评估健康风险'。\n"
"- 如果用户询问如何改善,规划'搜索营养建议'。\n"
"请保持待办事项具体且有序。"
)
)
# --- 4. 构建提示词 (Prompt) ---
# 定义系统的角色和指令
system_message = SystemMessage(content=(
"你是一个专业的健康顾问。你的工作流程是:\n"
"1. 先获取用户的身高(米)和体重(千克)。\n"
"2. 调用工具计算BMI。\n"
"3. 根据BMI结果评估用户的健康状况。\n"
"4. 如果用户有需求,提供饮食或运动建议。"
))
# 创建提示词模板
prompt = ChatPromptTemplate.from_messages([
system_message,
# TodoListMiddleware 会自动在这里注入待办清单状态
# 不需要手动添加,中间件会自动处理
("human", "{input}"),
])
x=TodoListMiddleware(
system_prompt="你正在协助一个健康顾问智能体。请监控其思考过程。",
tool_description="calculate_bmi:计算身体质量指数。公式:体重(kg) / 身高(m)的平方。get_health_risk_category:根据BMI数值判断健康风险等级.search_nutrition_info:联网搜索特定食物或营养相关的知识。",
)
# --- 5. 组装智能体 ---
# 将中间件注入到流程中
agent = create_agent(
model=llm,
tools=tools,
middleware=[x],
)
# 由于 create_agent 返回的是 Runnable,我们直接调用
agent_runnable = prompt | agent
# --- 6. 执行任务 ---
if __name__ == "__main__":
user_input = "我身高1.75米,体重80公斤。你觉得我的健康状况怎么样?如果我想减肥,有什么建议?"
print("👤 用户提问:", user_input)
print("\n📋 智能体思考过程:")
# 执行调用
result = agent_runnable.invoke({"input": user_input})
for msg in result["messages"]:
msg.pretty_print()
2.8.LLM tool selector(大模型工具选择)
在调用主模型之前,先用 LLM 智能选择相关工具。LLM 工具选择器适用于以下用途:
- 智能体拥有许多工具(10+),大多数工具在查询中并不相关。
- 通过过滤无关工具来减少tokens使用。
- 提升模型聚焦和准确性。
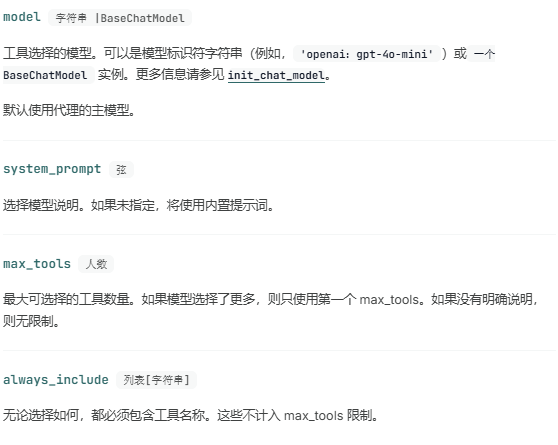
这种中间件使用结构化输出,询问 LLM 哪些工具对当前查询最相关。结构化输出模式定义了可用的工具名称和描述。模型提供者通常会在幕后将这些结构化输出信息添加到系统提示符中。
LLMToolSelectorMiddleware
python
from langchain.agents import create_agent
from langchain.agents.middleware import LLMToolSelectorMiddleware
agent = create_agent(
model="gpt-4o",
tools=[tool1, tool2, tool3, tool4, tool5, ...],
middleware=[
LLMToolSelectorMiddleware(
model="gpt-4o-mini",
max_tools=3,
always_include=["search"],
),
],
)
2.9.Tool retry(工具重试)
自动重试失败的工具调用,并可配置指数退回。工具重试适用于以下用途:
- 处理外部 API 调用中的瞬态故障。
- 提升依赖网络工具的可靠性。
- 打造能够优雅处理临时错误的韧性代理。
这里模型重试和工具从试都差不多:
ToolRetryMiddleware/ModelRetryMiddleware
python
from langchain.agents import create_agent
from langchain.agents.middleware import ToolRetryMiddleware
agent = create_agent(
model="gpt-4o",
tools=[search_tool, database_tool],
middleware=[
ToolRetryMiddleware(
max_retries=3,
backoff_factor=2.0,
initial_delay=1.0,
),
],
)| 参数名 | 类型 | 默认值 | 描述 |
|---|---|---|---|
| max_retries | 数字 | 2 |
初始通话后的最大重试次数(默认情况下共尝试 3 次)。 |
| tools | 列表BaseTool | str | None |
应用重试逻辑的工具或工具名称列表。如果为 None,则应用于所有工具。 |
| retry_on | 元组类型\[例外, ...] | callable | (Exception,) |
要么是一组需要重试的异常类型,要么是一个可调用对象,如果需要重试则返回 True。 |
| on_failure | 字符串 | callable | 'return_message' |
所有重试用尽后的行为。选项: 1. 'return_message':返回包含错误细节的工具消息(允许 LLM 处理故障)。 2. 'raise':重新抛出异常(停止代理执行)。 3. 自定义调用:处理异常并返回 ToolMessage 内容的字符串。 |
| backoff_factor | 数字 | 2.0 |
指数退避的乘数。每次重试等待时间为 initial_delay * (backoff_factor ** retry_number)。设置为 0.0 以实现恒定延迟。 |
| initial_delay | 数字 | 1.0 |
第一次重试前的初始延迟(秒数)。 |
| max_delay | 数字 | 60.0 |
重试间最大延迟(秒数限制),限制指数式退避的增长。 |
| jitter | 布尔 | true |
是否在延迟中加入随机抖动(±25%)以避免"雷鸣群"效应。 |
2.10.Context editing(清除工具调用历史输出)
**通过清除旧工具调用输出,在达到令牌限制时管理对话上下文,同时保留近期结果。**这有助于在长时间对话中保持上下文窗口的可控性,尤其是涉及大量工具调用时。上下文编辑适用于以下情况:
- 长时间对话中,许多超出令牌限制的工具调用
- 通过移除不再相关的旧工具输出来降低tokens成本
- 只维护最新的 N 工具会得到上下文
python
from langchain.agents import create_agent
from langchain.agents.middleware import ContextEditingMiddleware, ClearToolUsesEdit
agent = create_agent(
model="gpt-4o",
tools=[],
middleware=[
ContextEditingMiddleware(
edits=[
ClearToolUsesEdit(
trigger=100000,
keep=3,
),
],
),
],
)| 参数名 | 默认值 | 描述 |
|---|---|---|
| edits | [ClearToolUsesEdit()] |
可应用的 ContextEdit 策略列表。 |
| token_count_method | 'approximate' |
计数令牌的方法。选项: 1. 'approximate':使用近似估算。 2. 'model':使用模型精确计数。 |
| trigger | 100000 |
触发编辑的代币计数阈值。当对话总tokens数超过此数值时,旧的工具输出将被清除。 |
| clear_at_least | 0 |
编辑执行时,最低需要回收的tokens数量。如果设置为 0,则可以清除所需的所有内容。 |
| keep | 3 |
必须保存的最新工具结果数量。这些最新的结果永远不会被清除。 |
| clear_tool_inputs | False |
是否清除 AI 消息中原有的工具调用参数。当设置为 True 时,工具调用参数将被替换为空对象。 |
| exclude_tools | () |
不会被清除的工具名称列表。这些特定工具的输出将永远保留。 |
| placeholder | '[cleared]' |
插入的占位符文本,用于表示工具输出已被清除。这将替换原始的工具消息内容。 |
2.11.Shell tool(会话工具)
向智能体开放一个持久的shell会话以执行命令。Shell 工具中间件适用于以下用途:
- 需要执行系统命令的智能体
- 开发与部署自动化任务
- 测试与验证工作流程
- 文件系统作与脚本执行
ShellToolMiddleware,
python
from langchain.agents import create_agent
from langchain.agents.middleware import (
ShellToolMiddleware,
HostExecutionPolicy,
)
agent = create_agent(
model="gpt-4o",
tools=[search_tool],
middleware=[
ShellToolMiddleware(
workspace_root="/workspace",
execution_policy=HostExecutionPolicy(),
),
],
)| 参数名 | 类型 | 描述 |
|---|---|---|
| workspace_root | str | Path | None | Shell 会话的基础目录。如果省略,智能体开始时会创建一个临时目录,结束时会被移除。 |
| startup_commands | tuplestr, ... | liststr | str | None | 会话开始后顺序执行的可选命令。 |
| shutdown_commands | tuplestr, ... | liststr | str | None | 会话关闭前执行的可选命令。 |
| execution_policy | BaseExecutionPolicy | None | 执行策略,控制超时、输出限制和资源配置。选项: 1. HostExecutionPolicy :默认的完全主机访问;最适合可信环境(代理已运行在容器/虚拟机中)。 2. DockerExecutionPolicy :为每次智能体运行启动独立的 Docker 容器,提供更强的隔离。 3. CodexSandboxExecutionPolicy:重用 Codex CLI 沙箱,实现额外的系统调用/文件系统限制。 |
| redaction_rules | tupleRedactionRule, ... | listRedactionRule | None | 可选的编辑规则,用于在返回模型前对命令输出进行净化。注意 :编辑规则是在执行后应用的,使用 HostExecutionPolicy 时不会阻止秘密或敏感数据的窃取。 |
| tool_description | str | None | 可选覆盖,用于注册的 Shell 工具描述。 |
| shell_command | Sequencestr | str | None | 可选的 Shell 可执行文件(字符串)或参数序列,用于启动持久会话。 |
| env | Mappingstr, Any | None | 可选的环境变量,可以提供给 Shell 会话。命令执行前,数值会被强制转换为字符串。 |
2.12.File search(文件搜索)
在文件系统上提供 Glob 和 Grep 搜索工具。文件搜索中间件适用于以下用途:
- 代码探索与分析
- 按名称模式查找文件
- 使用正则表达式搜索代码内容
- 需要文件发现的大型代码库
FilesystemFileSearchMiddleware:
python
from langchain.agents import create_agent
from langchain.agents.middleware import FilesystemFileSearchMiddleware
agent = create_agent(
model="gpt-4o",
tools=[],
middleware=[
FilesystemFileSearchMiddleware(
root_path="/workspace",
use_ripgrep=True,
),
],
)
python
from langchain.agents import create_agent
from langchain.agents.middleware import FilesystemFileSearchMiddleware
from langchain.messages import HumanMessage
# 创建一个智能体(Agent)
agent = create_agent(
model=llm, # 指定使用的语言模型
tools=[], # 定义可用的工具列表(此处为空,因为工具由中间件自动提供)
middleware=[
# 文件系统搜索中间件
# 该中间件会自动向智能体添加 glob_search 和 grep_search 工具
FilesystemFileSearchMiddleware(
root_path="D:\pythonProject\python--研究生\智能体学习\langchain\学习第八天--中间件", # 设置搜索的根目录路径
use_ripgrep=True, # 启用 ripgrep 工具进行更快的文本搜索(如果系统已安装)
max_file_size_mb=10, # 设置最大文件大小限制(单位:MB),超过此大小的文件将被跳过
),
],
)
# 现在智能体可以使用 glob_search(文件名搜索)和 grep_search(内容搜索)工具了
# 调用智能体,传入用户消息
result = agent.invoke({
"messages": [HumanMessage("查找所有包含"async-def"的Python文件")]
# 消息内容:查找包含 'async def' 的所有 Python 文件
})
for msg in result["messages"]:
msg.pretty_print()
# 执行流程预测:
# 1. 智能体首先使用 glob_search(pattern="**/*.py") 查找所有 Python 文件。
# 2. 然后使用 grep_search(pattern="async def", include="*.py") 在找到的文件中搜索特定文本。