一、论文信息
Adam Wieckowski et al., VVC Search Space Analysis Including an Open, Optimized Implementation, IEEE Transactions on Consumer Electronics, 2022.
二、核心问题与动机
- VVC 的效率与代价:VVC标准旨在提供比 HEVC 高约50%的压缩效率(即在相同主观质量下节省约50%的比特率)。然而,这种效率提升伴随着计算复杂度的急剧增加。使用官方参考软件(VTM for VVC, HM for HEVC)进行测试,在随机访问(Random Access)配置下,VVC的编码时间大约是HEVC的8倍,解码时间约为2倍。
- 复杂度来源的模糊性 :编码时间的增加可能源于两个方面:
- 算法本身的复杂度:VVC引入了许多新的、更复杂的编码工具(如更灵活的块划分、新的预测模式等),这些工具在执行时本身就比HEVC的对应工具更耗时。
- 搜索空间的扩大:VVC提供了远多于HEVC的编码选项(例如,更多的块划分类型、更多的预测模式)。为了找到最优或接近最优的编码方案,编码器需要评估更多的可能性,这极大地增加了搜索的工作量。
- 现有分析的局限性 :直接比较参考软件(VTM vs HM)的运行时间无法区分上述两个因素。VTM本身并非为速度优化而设计,而HM相对成熟。此外,不同实现(如优化过的编码器)之间的运行时间比较也无法直接反映标准本身带来的搜索空间变化。
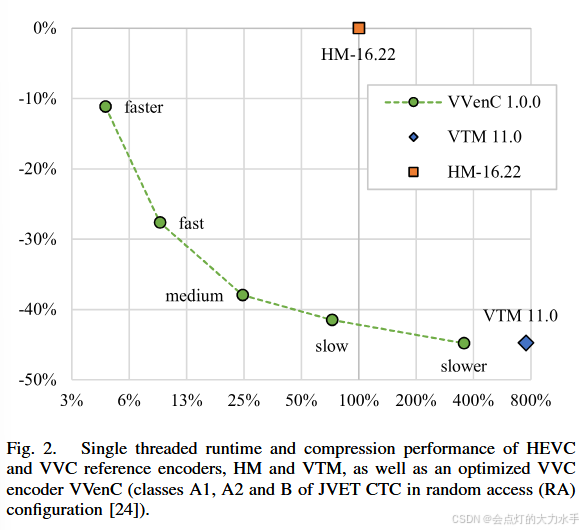
图2(Figure 2):编码时间分解(Encoding Time Breakdown)
- 目的:展示不同编码器在各个主要编码模块上的时间消耗分布。
- 对比对象 :HEVC 的 HM、VVC 的 VTM,以及优化后的 VVenC(使用
slower预设)。 - 关键信息
- 将总编码时间按功能模块划分,例如:
- 运动估计/运动补偿(ME/MC)
- Merge 候选搜索
- 变换与量化(T/Q)
- 熵编码(CABAC)
- 环路滤波(去块滤波 + SAO + ALF)
- CU 划分与模式决策(即 RDO 搜索主循环)
- 核心发现
- VTM 在几乎所有模块上的耗时都显著高于 HM,尤其在 CU 划分与 RDO 搜索部分占比最大。
- VVenC 虽然也基于 VVC 工具集,但通过算法优化(如减少不必要的 RDO 测试),使得各模块耗时明显低于 VTM,尤其在搜索主循环上效率提升显著。
- 将总编码时间按功能模块划分,例如:
- 意义:说明 VVC 复杂度增加不仅来自新工具本身,更来自 exhaustive 搜索;而 VVenC 的优化有效降低了各环节开销。
三、论文的主要贡献
为了解决上述问题,论文提出了以下核心工作:
-
提出一种经验性的搜索空间量化方法
- 论文的核心创新在于定义了一套与具体软件实现和硬件平台无关的指标,用于量化编码器在给定搜索算法下实际探索的"搜索空间"大小。
- 分区搜索空间 (Partitioning Search Space,
SP):衡量一个像素平均被包含在多少种不同的候选块划分结构中进行模式搜索。它反映了编码器在决定如何分割图像(CU 划分)时所做的决策量。SP = 1表示每个像素只被考虑一次(理想情况,无搜索);值越大,表示搜索越exhaustive。 - 编码模式搜索空间 (Coding Mode Search Space,
SQ):衡量一个像素平均参与了多少次完整的率失真优化(RDO)过程中的量化操作。量化是RDO中计算密集的部分,因此用它来代表对单个块内各种编码模式(如帧内/帧间预测模式、变换类型等)的测试次数。 - 组合搜索空间 (Combined Search Space,
S):定义为S = SP * SQ,综合反映了编码器为每个像素做出最终编码决策所需进行的完整编码/解码循环(即RDO测试)的平均次数。
-
对多个编码器实现进行实证分析
- 论文使用上述指标,对三种编码器进行了测量和比较:
- HM 16.22:HEVC的官方参考软件。
- VTM 11.0:VVC的官方参考软件。
- VVenC 1.0.0 :由Fraunhofer HHI开发的一个开源且高度优化的VVC 编码器。VVenC提供了从
faster到slower的多个预设(presets),代表了不同的编码速度与压缩效率的权衡点。
- 关键发现 :
- VVC搜索空间巨大 :VTM的组合搜索空间
S远大于 HM,证实了搜索空间的扩大是VVC编码复杂度增加的主要原因。 - VVenC的有效性 :即使是追求最高压缩效率的
VVenC slower预设,其搜索空间也略小于VTM,并且得益于底层优化,运行速度超过 VTM 两倍。更重要的是,通过主动限制搜索空间(例如,在fast,medium等预设中减少允许的递归划分深度、禁用某些工具、引入早期终止策略),VVenC能够将搜索空间S降低到甚至低于HM的水平,从而实现了比 HM 更快的编码速度,同时仍能提供显著优于HEVC的压缩增益(例如,VVenC faster比HM快,且BD-rate增益达 11%)。 - 权衡关系:论文清晰地展示了编码速度、压缩效率和搜索空间大小三者之间的权衡关系。减少搜索空间是降低编码时间最有效的手段,但会牺牲一定的压缩效率。
- VVC搜索空间巨大 :VTM的组合搜索空间
- 论文使用上述指标,对三种编码器进行了测量和比较:
-
深入剖析复杂度构成
- 除了搜索空间指标,论文还通过低开销性能分析(profiling)对比了VVenC、VTM和HM在不同编码模块(如运动搜索、Merge候选搜索、去块滤波、自适应环路滤波ALF等)上的时间消耗。
- 这揭示了VVC复杂度增加的具体来源(如更复杂的运动模型、更多的 Merge候选),并说明了VVenC的优化不仅体现在CU搜索循环(被
SP/SQ捕获)内,也体现在循环外的处理(如ALF、去块滤波)上。
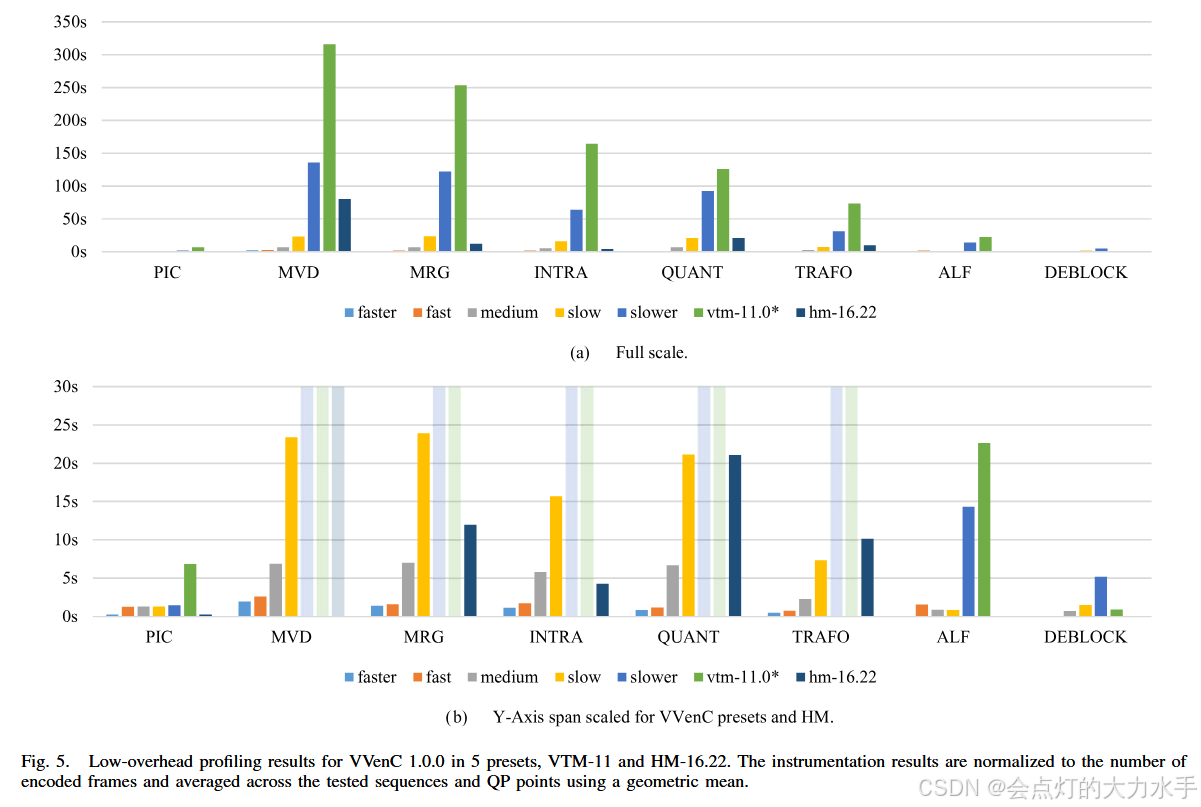
图5(Figure 5):组合搜索空间(Combined Search SpaceS)与 BD-rate 的权衡关系
- 目的 :可视化搜索空间大小(
S)之间的关系。 - 横轴 :组合搜索空间
S(对数尺度),反映编码器的"搜索努力程度"。 - 纵轴:相对于 HM 的 BD-rate(负值表示码率节省,即性能更好)。
- 数据点
- 包含 HM、VTM,以及 VVenC 的多个预设(如
faster,fast,medium,slow,slower)。
- 包含 HM、VTM,以及 VVenC 的多个预设(如
- 关键观察
- VTM 的
S值最高,BD-rate 最好(约 -48%),但搜索成本极高。 - HM 的
S较低,BD-rate 为 0(作为基准)。 - VVenC 的各预设点形成一条平滑的 Pareto 前沿:随着
S增大(搜索更 exhaustive),BD-rate 改善;反之,S减小则速度更快但压缩效率略降。 - 特别地,VVenC 的
faster和fast预设的S值甚至低于 HM,但 BD-rate 仍为负(如 -11%),说明在比 HEVC 更快的速度下,仍能获得压缩增益。
- VTM 的
- 意义 :清晰揭示了"搜索空间--压缩效率--编码速度"三者的内在权衡,并证明通过控制
S,VVC 可在实用速度下部署。
四、结论与意义
- 核心结论:VVC编码复杂度的显著增加,主要归因于其巨大的编码选项所带来的搜索空间膨胀,而非仅仅是单个算法的计算开销增加。
- 实践意义:论文证明了通过智能地修剪搜索空间(例如,VVenC所做的),可以在可接受的压缩效率损失下,将 VVC 编码器的运行速度提升数十倍,使其在实际应用中变得可行。VVenC本身就是一个成功的范例。
- 方法论意义 :提出的
SP、SQ和S指标为客观比较不同视频编码器(甚至是不同标准的编码器)的搜索算法复杂度提供了一个有价值的、实现无关的工具。
这篇论文不仅深入分析了VVC复杂度高的根本原因,更重要的是提供了一套量化工具,并通过 VVenC的实例证明了高效 VVC编码的关键在于对庞大搜索空间的有效管理,而非仅仅依赖底层代码优化。这对于VVC的实际部署和未来视频编码标准的设计都具有重要的指导意义。