文章目录
- 1、前言
- 2、先看个有趣的问题
- 3、背景知识:优化器是什么
-
- [3.1 梯度下降的直觉](#3.1 梯度下降的直觉)
- [3.2 Adam 为什么这么流行](#3.2 Adam 为什么这么流行)
- 4、论文核心发现:跳过更新反而更好?
-
- [4.1 "跳过更新"这个反常识的做法](#4.1 "跳过更新"这个反常识的做法)
- [4.2 为什么跳过反而更好?](#4.2 为什么跳过反而更好?)
- [5、MAGMA 方法详解](#5、MAGMA 方法详解)
-
- [5.1 从随机跳过到智能跳过](#5.1 从随机跳过到智能跳过)
- [5.2 动量对齐------智能决策的实现](#5.2 动量对齐——智能决策的实现)
- 6、实验结果
-
- [6.1 大模型预训练效果](#6.1 大模型预训练效果)
- [6.2 令人惊讶的数字](#6.2 令人惊讶的数字)
- 7、总结与启示
-
- [7.1 用生活类比收尾](#7.1 用生活类比收尾)
- [7.2 三大核心价值](#7.2 三大核心价值)
🍃作者介绍:25届双非本科网络工程专业,阿里云专家博主,深耕 AI 原理 / 应用开发 / 产品设计。前几年深耕Java技术体系,现专注把 AI 能力落地到实际产品与业务场景。
🦅个人主页:@逐梦苍穹
📕所属专栏:🌩
专栏① :人工智能; 🌩专栏② :速通人工智能相关论文🐼GitHub主页:https://github.com/XZL-CODE
✈ 您的一键三连,是我创作的最大动力🌹

1、前言
如果有人告诉你:"学生每天偶尔摸鱼不学习,反而比每天埋头苦读的学生考试成绩更好",你信吗?
绝大多数人第一反应肯定是:这不可能!学习就应该越努力越好,哪有偷懒反而变强的道理?
然而,Google DeepMind 的研究人员最近发表了一篇令整个优化器研究圈大跌眼镜的论文:在训练大型语言模型时,随机跳过约 50% 的参数更新 ,结果模型性能不仅没有下降,反而比每次都"乖乖全量更新"的标准做法提升了接近 20%!
这篇论文叫做《On the Surprising Effectiveness of Masking Updates in Adaptive Optimizers 》(掩盖更新在自适应优化器中的惊人有效性),提出了一个叫 MAGMA 的方法------全称 Momentum-Aligned Gradient MAsking(动量对齐梯度掩盖)。
今天这篇文章,我们来聊聊:
- 这个反常识的发现是怎么被发现的
- 为什么"偷懒"反而变强了(背后的数学直觉)
- MAGMA 具体是怎么做的
- 实验数据有多惊人
全文用大量生活类比,不需要深厚的数学基础,只要有梯度下降的基本概念就能读懂。
2、先看个有趣的问题
在进入技术内容之前,我想先给你讲两个生活场景,这能帮助你更自然地理解后面的内容。
场景一:健身的"超量恢复"原理
健身达人都知道一个铁律:肌肉不是在举铁的时候增长的,而是在休息的时候 。肌肉纤维被锻炼撕裂后,需要恢复期才能变得更强壮。如果你每天不停地练同一块肌肉,不给它喘息的机会,最终会过度训练,反而表现下滑。
合理安排休息日的人,往往比"每天都练"的人进步更快。
场景二:间隔记忆法(Spaced Repetition)
背单词时,你是选择每天背 1000 个全新单词,还是今天背 300 个、后天复习一遍、一周后再强化?
认知科学研究表明,后者的记忆效果远胜前者。这就是著名的"间隔重复"学习法------适当的遗忘和间隔,反而能加强记忆的牢固程度。强行每次都不间断地塞进去,大脑反而容易形成"肌肉记忆式的过拟合",不够稳健。
这两个场景,其实暗示了神经网络训练中一个被长期忽视的规律:
适当的"跳过",有时比"全量执行"更有益。
3、背景知识:优化器是什么
要理解 MAGMA,我们先得搞清楚两个基础概念:梯度下降 和 Adam 优化器。
3.1 梯度下降的直觉
想象你被蒙上了眼睛,站在一座崎岖的山上,任务是走到山脚(找到损失最小的参数组合)。
你看不见周围的地形,但可以用脚感觉脚下地面的倾斜方向。每一步,你都朝着"脚下最陡峭的下坡方向"迈出一步。走了很多步之后,你大概率会到达某个谷底。
这就是**梯度下降(Gradient Descent)**的核心逻辑:
| 生活类比 | 神经网络训练 |
|---|---|
| 山的海拔高度 | 损失值(Loss),越高说明模型预测越不准 |
| 你的位置 | 模型的参数值 |
| 脚感到的坡度 | 梯度(告诉你往哪走损失下降最快) |
| 每步的步幅 | 学习率(Learning Rate) |
| 走到谷底 | 找到最优参数 |
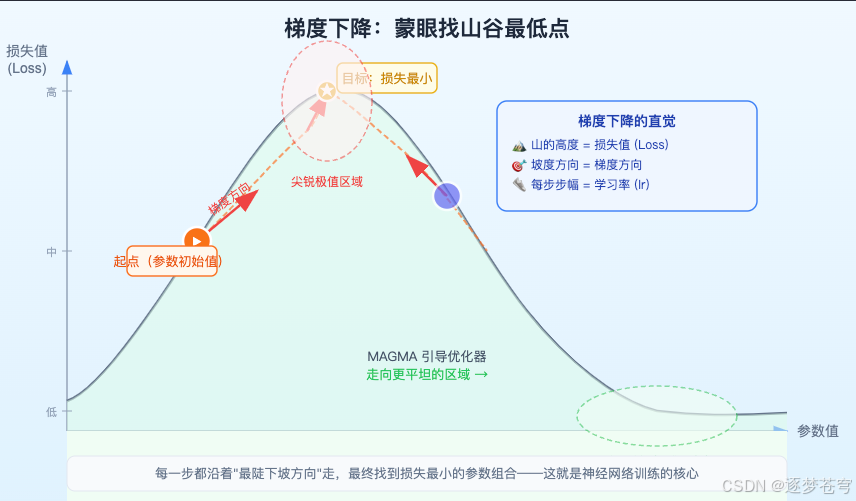
神经网络训练就是这样一个过程:不断计算梯度(坡度),然后把参数向梯度的反方向移动(下坡),直到走到某个谷底。
3.2 Adam 为什么这么流行
普通的梯度下降有个实际问题:对所有参数用同一个步长更新。这会导致有些参数更新太猛(像在悬崖边跑步),有些又更新太慢(像在平地上爬行)。
Adam 优化器 就是为了解决这个问题诞生的。你可以把 Adam 想象成一个有记忆的聪明学习者,他会记录两件事:
第一件事:最近走的方向(一阶矩/动量)
如果最近几步都在往同一个方向走,说明这个方向是"靠谱的",可以加速;如果方向来回变(震荡),说明可能在绕弯路,要保守一点。
第二件事:每个方向走了多猛(二阶矩)
如果某个参数方向历史上变化很大,就小心翼翼地小步走;如果变化一直很稳定,就可以大胆迈步。
这种自动调节让 Adam 成为了训练大型语言模型(LLM)的"标配"------它聪明地处理了参数之间的差异性,训练更稳、更快。
在过去几年里,几乎整个行业都有一个共识:
每次训练迭代,所有参数必须全部更新(密集更新)。
毕竟,反向传播已经计算出了所有参数的梯度,为什么不全用上呢?浪费了岂不是可惜?
然而,MAGMA 这篇论文正是打破了这个"铁律"。
4、论文核心发现:跳过更新反而更好?
4.1 "跳过更新"这个反常识的做法
Google 的研究人员先设计了一个极其简单的实验,叫做 SkipUpdate(跳过更新):
训练时,对每一个"参数块"(比如某一层的权重矩阵)随机抛一枚硬币:正面就正常更新,反面就跳过,让这个参数块这次保持不变。
每个参数块独立地、以 50% 的概率决定是否被更新。
听起来很简单对吧?就像学生随机决定今天某道题"做不做"。
有一个细节非常关键,也是这个方法为什么有效的核心:
动量(历史信息)仍然正常积累!
虽然某个参数块这次没有被实际修改,但 Adam 内部记录"最近走了哪个方向"的动量,还是会照常更新------就像你今天没去健身,但昨天运动后身体的恢复和适应过程还在继续。
同时,为了保证平均意义下的更新量不变,被选中更新的参数块更新量会乘以 2(因为平均只有 50% 的概率被选中,所以选中时放大一倍来维持期望值不变)。
实验结果让所有人大跌眼镜:
在 10 亿参数(1B)规模的 Llama 2 模型预训练上,SkipUpdate 比全量 Adam 表现更好。而且进一步优化的 MAGMA 方法,更是把困惑度从 Adam 的 16.35 一路压到了 13.19!
4.2 为什么跳过反而更好?
这需要引入一个关键概念:损失地形(Loss Landscape)。
地形的两种谷底
把神经网络的参数空间想象成一片复杂的山地,训练目标是找到"最低洼的地方"。但谷底有两种截然不同的类型:
尖锐谷底(Sharp Minima):
就像深山里一条狭窄的峡谷裂缝。训练集上的损失确实很低(你恰好卡在最低点),但这个位置极不稳定------稍微换一批数据(测试集),或者参数偏移一点点,损失就会急剧飙升。
平坦谷底(Flat Minima):
就像一片宽阔的盆地或草原。损失值可能不是绝对最低,但这个区域范围很大------换测试数据、参数微小扰动,都不会让损失大幅上升,模型具有很强的鲁棒性。
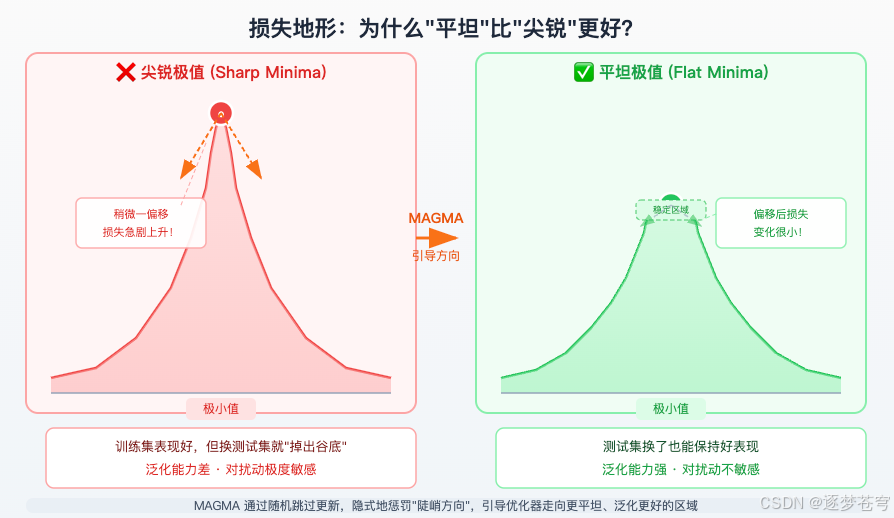
大量研究表明:模型最终落在越平坦的谷底,在新数据上的表现越好(即泛化能力越强)。
随机跳过是如何引导走向平坦区的?
这里是论文最核心的理论发现。数学上可以严格证明(过程很复杂,我们只讲结论):
对参数块随机跳过更新,等效于给每个更新方向额外施加了一个惩罚,而且这个惩罚的大小与该方向的"陡峭程度"成正比。
用生活类比来说:就像给你戴上了一双"智能鞋"------走在越陡峭的山路上,鞋子越沉,你越不想往那里走。自然而然就把你引导到平缓地带了。
这就是论文中所说的**"隐式几何正则化(Implicit Geometric Regularization)"**:
- 越陡峭的参数方向 → 掩盖带来的惩罚越大 → 优化器越不愿往那里走
- 越平坦的参数方向 → 掩盖带来的惩罚越小 → 优化器可以放心走
- 最终效果:轨迹自动偏向平坦极值区域
最妙的是:这种正则化效果完全是"免费"的------不需要任何额外的计算,只需要随机地"跳过"一些本来要做的更新,这种几何引导效果就自然涌现出来了。
这就好比,偶尔"休息",不是在浪费时间,而是在引导训练走向更稳健的方向。
5、MAGMA 方法详解
SkipUpdate 虽然有效,但它的跳过是完全随机的------对所有参数块一视同仁,不管当前这步梯度质量如何,一律 50% 概率跳过。
研究人员想到一个更进一步的问题:能不能更聪明地决定该跳过哪些?
5.1 从随机跳过到智能跳过
这就是 MAGMA 的核心思想。
还记得我们说 Adam 会"记住最近走的方向"(动量)吗?动量是过去多步梯度的累积平均,代表了模型参数"历史上比较可靠的更新方向"。
MAGMA 的洞察非常优雅:
如果当前这一步的梯度方向,和历史积累的动量方向"高度一致",说明这次更新是可靠的信号;如果方向"相反或随机",很可能是随机噪声在捣乱,这次更新不那么可信。
冲浪类比:
想象你是一个冲浪运动员。动量,就是"这片海域过去一小时的浪的整体方向"(稳定的大势)。当前梯度,就是"这一刻你脚下这波浪的方向"。
- 如果当前这波浪和整体大势方向一致 → 大概率是真实的长浪,全力冲!
- 如果这波浪方向和大势完全相反 → 可能只是一个局部扰动的小浪,保守一点,别用全力
MAGMA 就是这个逻辑:只在"感觉对的时候"全力更新,感觉不对时保守(甚至跳过)。
5.2 动量对齐------智能决策的实现
MAGMA 的计算方式其实并不复杂:
第一步:计算"可信度分数"
对每个参数块,用余弦相似度来量化当前梯度和动量的"方向一致性":
- 分数接近 +1 → 方向高度一致 → 这步更新可信 → 给高权重
- 分数接近 0 → 方向不相关 → 中等置信
- 分数接近 -1 → 方向完全相反 → 可能是噪声 → 大幅压制
然后通过 Sigmoid 函数把这个分数转化成 0~1 之间的权重,并用指数移动平均做一点平滑(防止单步噪声影响决策太大)。
第二步:用这个分数来缩放更新
最终的更新 = 原始更新 × 可信度分数 × 随机掩码
效果就是:
- 可信度高(接近1)→ 更新几乎完整保留
- 可信度低(接近0)→ 更新被大幅压制,相当于"软跳过"
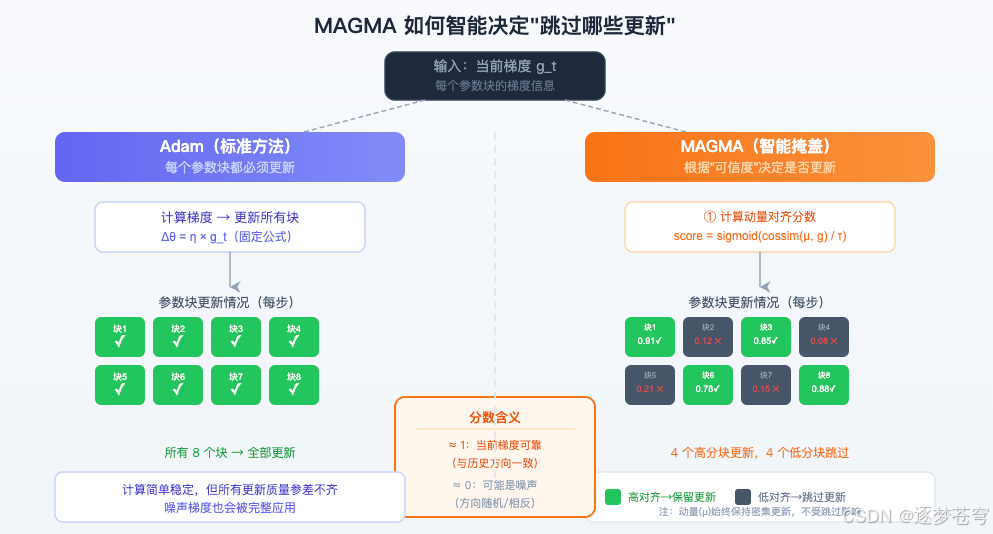
最妙的设计:零额外成本
MAGMA 完全不需要额外计算!
动量(μ)本来就是 Adam/RMSProp 每一步都要维护的量。计算余弦相似度只需要几个向量运算,相比整个反向传播的计算量完全可以忽略不计。
更重要的是,MAGMA 的设计是一个**"插件式包装器(Optimizer Wrapper)"**------你不需要改动任何模型结构或训练代码,只需要在现有优化器(Adam、RMSProp 等)外面套一个 MAGMA,就能立刻获得提升。就像给手机套了个保护壳,不改变手机本身,但却额外提供了保护。
6、实验结果
6.1 大模型预训练效果
研究团队在标准的 C4 数据集上,使用 Llama 2 架构,训练了 4 种不同规模的模型(6000万 到 10 亿参数),并与当前最先进的优化器进行了全面比较。
评估指标是验证集困惑度(Perplexity),困惑度越低,说明模型对语言的理解和预测能力越强(越不"懵逼")。
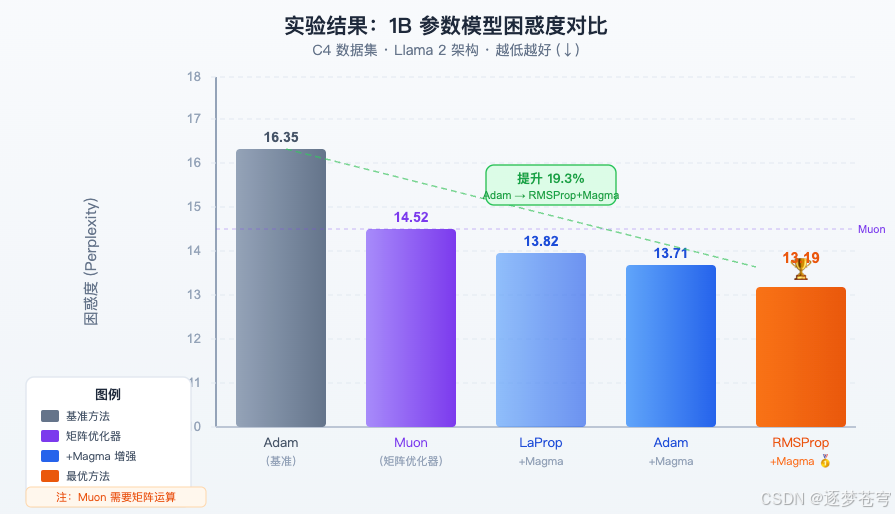
在 1B(10 亿参数)规模的模型上,主要结果如下:
| 方法 | 1B 模型困惑度 | 备注 |
|---|---|---|
| Adam(标准方法) | 16.35 | 行业基准 |
| C-Adam(谨慎 Adam) | 15.92 | 已有改进方法 |
| Muon | 14.52 | 复杂矩阵优化器,额外开销大 |
| APOLLO+SGG | 13.95 | 复杂组合方法 |
| Adam+MAGMA | 13.71 | 零额外计算成本 |
| LaProp+MAGMA | 13.82 | 零额外计算成本 |
| RMSProp+MAGMA | 13.19 | 最优!零额外计算成本 |
6.2 令人惊讶的数字
惊喜一:零成本超越高成本对手
最让人目瞪口呆的是:RMSProp + MAGMA 在所有模型规模上均取得最低困惑度,甚至击败了 Muon 这类需要昂贵矩阵运算的"重量级"优化器。
Muon 需要在每步训练中对梯度矩阵做复杂的数学分解,计算成本很高;而 MAGMA 的额外成本几乎为零,却能超越 Muon。
更夸张的是:RMSProp 本来是个比 Adam 还古老的优化器,在 1B 规模的训练中甚至会"发散"(训练崩溃),但套上 MAGMA 之后,不仅训练稳定了,还拿了最好成绩!
惊喜二:规模越大,提升越显著
| 模型规模 | Adam 基准 | Adam+MAGMA | 相对提升 |
|---|---|---|---|
| 6000万参数 | 30.79 | 29.09 | -5.5% |
| 1.3亿参数 | 24.77 | 22.08 | -10.9% |
| 3.5亿参数 | 18.42 | 16.41 | -10.9% |
| 10亿参数 | 16.35 | 13.71 | -16.1% |
注意这个规律:模型越大,MAGMA 带来的提升越明显! 这是个绝好消息------我们最关心的正是大模型的训练效果,而 MAGMA 恰恰在这里表现最亮眼。
背后的原因也很直观:模型越大,参数之间的交互越复杂,损失地形越"崎岖多变"(陡峭区域更多),MAGMA 的几何正则化效果就越能发挥作用。
惊喜三:调参从此轻松很多
普通 Adam 对学习率非常敏感:学习率稍微大一点,训练就会不稳定;稍微小一点,又收敛太慢。使用 Adam 时,你可能需要做大量的学习率搜索实验。
而 Adam+MAGMA 的有效学习率范围大幅拓宽------即使学习率高达 0.05(正常最优值的几十倍),Adam+MAGMA 依然能稳定收敛,而同等条件下纯 Adam 已经完全失败了。
这意味着用 MAGMA 时,不需要那么精细地调参,省去了大量试错实验的成本。
惊喜四:MoE 架构也有效
混合专家模型(Mixture-of-Experts, MoE)是现代最先进大模型(如 Mixtral、GPT-4 据推测)使用的架构,它的优化难度比普通模型高很多。实验表明,MAGMA 在 MoE 架构上同样有稳定提升,当 MAGMA 与 Muon 组合时,性能大幅超越了所有基线。
7、总结与启示
7.1 用生活类比收尾
这篇文章开头,我们说到"偶尔摸鱼反而变强"的反常识现象。现在我们可以理解背后的逻辑了:
| 生活类比 | MAGMA 对应概念 |
|---|---|
| 蒙眼下山 | 梯度下降找最优参数 |
| 有记忆的学习者 | Adam 优化器(维护动量) |
| 间隔记忆法 | SkipUpdate(随机跳过 50% 更新) |
| 只在"感觉对的时候"全力投入 | MAGMA 的动量对齐机制 |
| 走向平坦草原,而非狭窄峡谷 | 引导优化到平坦极值区域 |
7.2 三大核心价值
技术价值:接近零成本的显著提升
在大模型训练动辄花费数百万美元的今天,MAGMA 带来的困惑度降低直接转化为巨大的经济价值------更少的计算资源,达到同等甚至更好的模型质量。而 MAGMA 的额外成本几乎为零,作为插件可以直接叠加到任何现有的训练流程上。
理论价值:发现了新的优化机制
论文首次从理论上严格证明了"随机跳过更新为什么有效":隐式几何正则化------通过随机跳过,自动地惩罚了"走向陡峭区域"的更新,引导优化轨迹朝着泛化能力更好的平坦极值移动。这是之前从未被认识到的一种优化机制。
认知价值:挑战"多多益善"的偏见
最重要的也许是这个结论对我们认知的颠覆:
"密集更新(每步全量更新所有参数)对神经网络训练未必是最优的。"
近年来,大家都在竞相研究"更复杂的二阶信息"、"更精密的矩阵运算"来提升优化器性能,代价是越来越高的计算开销。而 MAGMA 告诉我们:一个如此简单的"随机跳过"操作,就能超越那些复杂昂贵的方法。
有时候,少即是多 。有时候,选择性地放弃,是更聪明的策略。
这种反直觉的洞察,往往才是推动整个领域向前的最强驱动力。
如果你觉得这篇文章对你有帮助,欢迎点赞收藏!如果想深入了解论文细节,可以在 arxiv 搜索:"On the Surprising Effectiveness of Masking Updates in Adaptive Optimizers"
我们下篇文章见!