写在前面:在人机交互(HRI)中,我们常因为机器人表情的"慢半拍"而感到违和。《Human-robot facial coexpression》的论文作者U航老师提出了一种基于预测的共情表达机制。这不仅是一个技术突破,更像是机器人向人类社交本能的一次致敬。
1. 我们在解决什么问题?
目前的人形机器人,虽然皮肤越来越像人,但在非语言交流上依然显得很笨拙。核心痛点在于:延迟。
传统的机器人表情生成逻辑是"反应式"的:先通过摄像头感知人类笑了→识别表情 →指令驱动电机 → 机器人笑。 这就导致了机器人总是充当"复读机"的角色,笑得比人晚,看着不真诚。

作者的核心观点是: 真正的共情不应该是你笑完了我再笑,而是我预判了你要笑,所以我与你同时笑 。
2. 怎么解决:双模型驱动的"预测大脑"
为了实现这种"同步率",作者设计了一个包含两个核心模型的系统框架:
A. 逆运动学模型 (Inverse Model / Self-Model)
这是一个让机器人"认识自己"的过程。机器人对着镜子进行"随机运动牙牙学语"(Motor Babbling),记录下"电机指令"与"面部关键点"的对应关系 。
-
功能:输入想要达到的面部形状(关键点),输出电机应该怎么动。
-
网络架构细节(你关心的部分):
这是一个相对轻量的全连接网络(MLP),包含三层结构:
-
输入层:113个面部关键点坐标。
-
隐藏层 1 :1024个神经元,使用 ReLU 激活函数 + Batch Normalization。
-
隐藏层 2 :512个神经元,使用 ReLU 激活函数。
-
输出层 :11个神经元(对应11个控制参数),使用 Sigmoid 激活函数将输出限制在 0, 1 范围内,直接对应电机的归一化行程。
-
B. 预测模型 (Predictive Model)
这是一个让机器人"读懂人类"的过程。作者使用了 MMI Facial Expression Database,并进行了严格的数据筛选(排除了机器人硬件做不到的动作,如嘟嘴)。
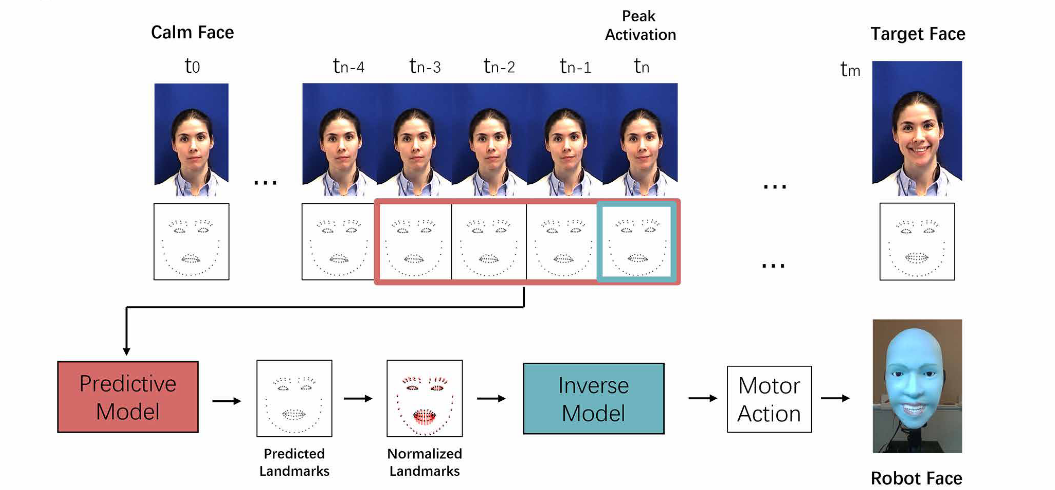
-
数据构建技巧:
为了训练机器人捕捉"微表情",作者引入了激活峰值 (Peak Activation) 的概念:
-
计算每一帧面部关键点相对于"平静脸"的距离(MSE)。
-
使用 Savitzky-Golay 滤波器平滑曲线。
-
对距离曲线求二阶导数得到加速度。
-
激活峰值 = 加速度最大的时刻(即表情爆发的瞬间)。
-
输入/输出构造:输入是峰值前后9帧里随机采样的4帧(捕捉其实趋势);输出是目标脸及其后3帧(预测最终形态)。
-
-
网络架构细节:
这是一个类似 ResNet 结构的深度神经网络:
-
输入:4帧关键点数据打平。
-
主干网络:8个全连接层(FC)。
-
激活函数 :前6层使用 Tanh 激活函数(而非ReLU)。
-
残差连接 (Skip Connection):在第4层和第6层之间有一个跳跃连接,用于保留原始信息,防止梯度消失 。
-
输出:预测的目标面部关键点。
-
3. 实验测评:它真的"同步"了吗?
直观对比:赛跑模式
作者设计了一个非常直观的实验:让机器人看一段人类笑的视频。

-
Mimicry(模仿组):等到人类笑到最大幅度时,机器人检测到了,才开始执行动作。结果明显滞后。
-
Ours(预测组):在人类嘴角刚刚开始微动的瞬间(微表情),机器人就已经计算出了目标表情并开始执行。
-
结果 :机器人的生成指令耗时仅 0.002秒 。最终,机器人和人类在同一时刻达到了笑容的最高点,实现了完美的 Zero-lag。
量化分析:混淆矩阵与距离
-
面部还原度(形状误差): 这里确实是计算关键点的欧氏距离(Euclidean distance)。如图 4B 所示,预测模型的关键点误差显著低于随机猜测,略优于模仿基线 。
-
触发准确率(混淆矩阵):
基于电机指令的 L1 距离
-
定义:将电机指令归一化到 0, 1。平静脸为原点。
-
阈值:如果预测出的指令与平静脸的 L1 距离 > 0.25,则认为机器人决定"做一个表情";否则为"保持冷静"。
-
表现 :在这种标准下,机器人判断"该不该动"的准确率(Accuracy)为 72.2% ,阳性预测值(PPV,即机器人觉得该笑时,真的该笑的概率)为 80.5% 。这证明它不是瞎猜,而是真的看懂了意图。
-
4. 启发与思考
这篇文章虽然聚焦于具体的工程实现,但给我带来了两个层面的思考:
- 关于"成长的轨迹": 论文最后提到,这种"预测并同步"的能力,很像人类婴儿的学习过程。婴儿最初也是通过模仿父母的表情来学习社交线索的 。对于机器人而言,模仿不是终点,而是通向自主情感表达的必经之路。
- 关于"交互的本质" : 从应用角度看,用户体验往往决胜于毫秒之间。我们在设计 AI Agent 或机器人时,往往沉迷于模型参数的大小,却忽略了交互的实时性(Real-time)。如果你讲了一个笑话,机器人过了2秒才通过云端大模型生成了一个完美的笑声,那个尴尬的瞬间已经破坏了所有的交流氛围。
总结:未来的机器人,不应该只是听懂你的话,更应该在你说完之前,就已经懂得了你的情绪。