提示工程(Prompt Engineering),也称为 In-Context Prompting,是指在不更新模型权重的情况下如何与大模型交互以引导其行为以获得所需结果的方法。
在人工智能领域,Prompt指的是用户给大型语言模型发出的指令。
- 例如,"「讲个笑话」"、"「用Python编个贪吃蛇游戏」"、"「写封情书」"等。
- 虽然看似简单,但实际上,Prompt的设计对于模型的结果影响很大。
- 因此如何设计prompt,进而与模型更好的交互,是研究人员必备的必不可少的技能(提示工程)。
提示词技巧
技巧一:详细的描述
任何Prompt技巧,都不如清晰的表达你的需求。这就类似人与人沟通,如果话说不明白,不可能让别人理解你的思想。因此,写出清晰的指令,是核心。
- 错误示例:
latex
写一封情书- 正确示例:
latex
用一些温柔的话语写一封情书,来表达我对你的仰慕和思念。最后,我要求书写字体数要不低于500个字技巧二:让模型充当某个角色
示例:
latex
我需要你充当一个AI算法面试官的角色,
要求你自主的对我进行AI面试过程中常考的面试题,你可以一次说一个问题,
然后我回答完,你再出第二道题技巧三:使用分隔符标明输入的不同部分
中括号、XML标签、三引号等分隔符可以帮助划分要区别对待的文本,也可以帮助模型更好的理解文本内容。常用''''''把内容框起来
示例:
latex
用20个字符总结由三引号分割的文本。"""在此插入文本"""技巧四:对任务指定步骤
对于可以拆分的任务可以尽量拆开,最好能为其指定一系列步骤,明确步骤可以让模型更容易实现它们。
示例:
步骤1:
latex
""""用户输入文本"""",用一句话总结这段文本,并加上前缀"Summary".步骤2:
latex
将步骤1中的摘要翻译成英语,并添加前缀"翻译:"技巧五:提供例子
本质类似于few-shot leaning。先扔给大模型举例,然后让模型按照例子来输出
示例:
latex
按照这句评论文本的格式:'""用户输入文本""',帮我创造新的样本于文本文档,辅助大模型问答,降低模型"幻觉"(一本正经的胡说八道)问题。即使用参考文本作答 经典的知识库用法,让大模型使用我们提供的信息来组成答案。
示例:
latex
根据下文中三重引号引起来的文章来回答问题。如果在文章中找不到答案,请写"我找不到答案",不要自己造答案。
"""<在此插入文档>""""""<在此插入文档>""" 问题:<在此插入问题>Zero-shot思想
Zero-shot学习(Zero-shot Learning)是指在训练阶段不存在与测试阶段完全相同的类别,但是模型可以使用训练过的知识来推广到测试集中的新类别上。
这种能力被称为"零样本"学习,因为模型在训练时从未见过测试集中的新类别,在模型训练和提示词优化中均有体现。
在模型训练中
- 已知马(四脚兽)、虎(有条纹)、熊猫(黑白色)的特征,但未训练过斑马的数据(不认识)
- 告知模型:斑马是四脚兽、有黑白色的条纹
- 模型可以在已知数据中进行推理,从而识别斑马。
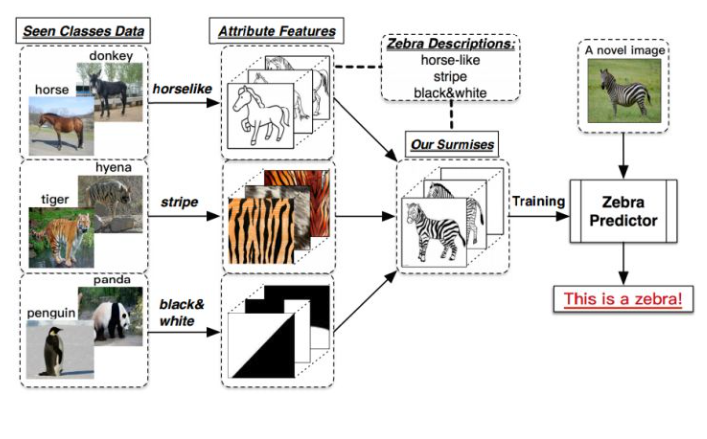
在提示词优化中
Zero-shot思想用于基于已训练的能力,不提供任何示例,仅通过语言去描述任务的要求、目标和约束,让模型直接生成结果。简单来说就是"用语言定义任务,解放(信任)模型的预训练知识"比如:请判断""包围的用户评论中的情感倾向,输出 正面 或 负面。"这款代餐鸡胸肉饱腹感很强,吃起来也不柴,很推荐!"
Few-shot
Few-shot学习(Few-shot Learning)是指少样本学习,当模型在学习了一定类别的大量数据后,对于新的类别,只需要少量的样本就能快速学习,对应的有one-shot learning,单样本学习,也算样本少到为一的情况下的一种few-shot learning。
在模型训练中(相似度判断方法)
基于少量企鹅样本并结合相识度判断,推论未知图片内含"企鹅"
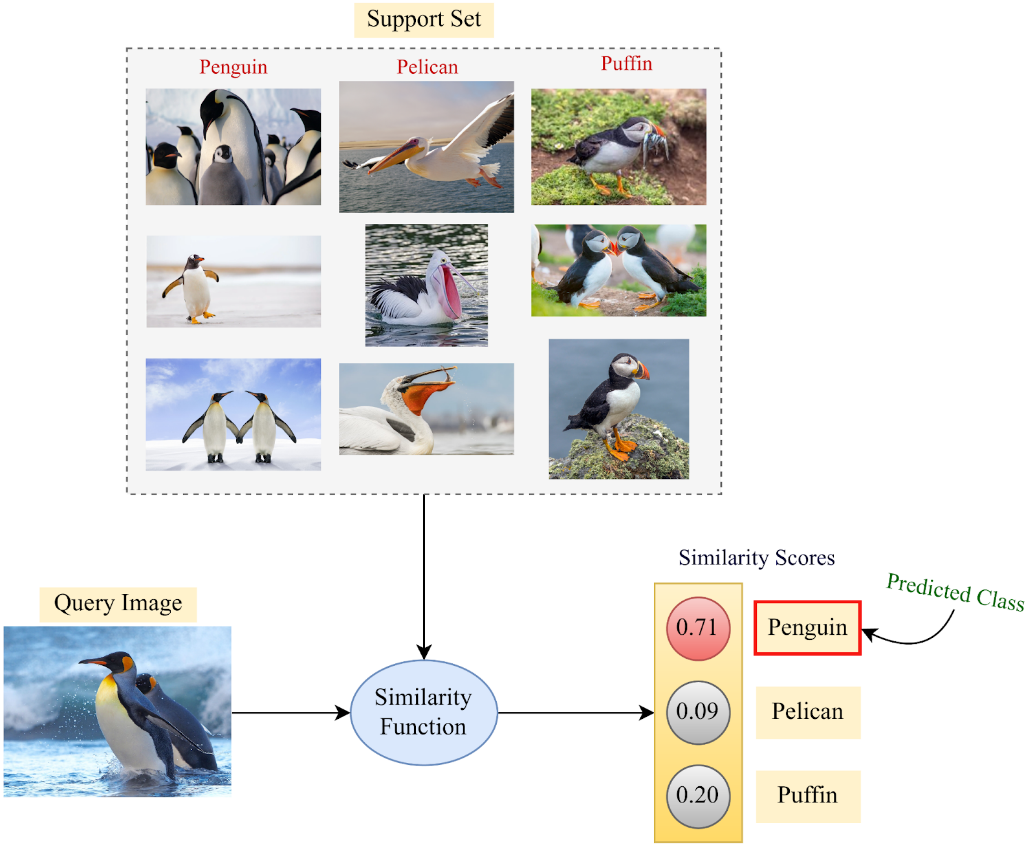
在提示词优化中:
Few-shot主要用于基于少量示例,让模型参考示例回答。简单来说就是"用示例定义任务,在模型的预训练知识的基础上,提升模型回答的对齐精度(比如参考示例的格式)"
比如:请抽取产品名称和核心卖点2个字段,格式为Json,我提供2个示例。
latex
示例1:MacBookPro高效节能,性能强大,适合牛马工作使用
输出:{"产品名称": "MacBookPro", "产品卖点": "高效节能,性能强大"}
示例2:联想笔记本拥有RTX4060独立显卡,畅玩游戏,丝滑流畅
输出:{"产品名称": "联想笔记本", "产品卖点": "畅玩游戏,丝滑流畅"}请处理:华为MatepadPro,高清大屏,长效续航,你的好帮手。
latex
{"产品名称": "华为MatepadPro", "产品卖点": "高清大屏,长效续航"}参考: