目录
[2、Chrome Driver版本问题](#2、Chrome Driver版本问题)
前言
在当今数字化时代,自动化测试和数据采集的需求日益增长。Java作为一种广泛使用的编程语言,以其强大的功能和跨平台特性,成为许多开发者的首选工具。而Selenium,作为一款功能强大的自动化测试框架,能够模拟真实用户的浏览器操作,为自动化测试和网页数据采集提供了极大的便利。将Java与Selenium相结合,不仅可以实现高效的网页自动化操作,还能通过自动截图功能,为测试和数据采集过程提供直观的可视化支持。
Java搭配Selenium实现网页访问与自动截图,具有多方面的重要意义。对于软件测试人员来说,自动化截图可以快速定位问题,提高测试效率和准确性;对于数据采集人员而言,截图可以作为数据采集过程中的辅助手段,帮助验证数据的完整性和准确性。此外,这种技术组合在实际应用中也面临着一些挑战,如环境配置、代码调试、截图质量等问题。这些问题如果得不到妥善解决,可能会严重影响项目的进度和质量。因此,深入探讨Java搭配Selenium实现网页访问与自动截图的实战技巧,并对常见问题进行详细解析,对于提升开发效率和项目质量具有至关重要的作用。
本文将详细介绍Java搭配Selenium实现网页访问与自动截图的全过程。首先,我们会从环境搭建开始,逐步讲解如何安装和配置Java开发环境以及Selenium框架,确保读者能够在本地环境中顺利运行相关代码。接着,通过具体的代码示例,展示如何使用Java编写代码来控制Selenium驱动浏览器访问网页,并实现自动截图功能。最后,针对在实战过程中可能遇到的常见问题,如截图不完整、元素定位失败、多浏览器兼容性等,进行深入分析并提供有效的解决方案。通过本文的介绍,读者将能够掌握Java搭配Selenium实现网页访问与自动截图的核心技术,并能够灵活应对实际开发中遇到的各种问题,从而在自动化测试和数据采集领域更加得心应手。
一、需求描述
在测试领域,负责测试的同学通常需要对待测试的页面进行集中回归,也会进行相应的功能整理。有时候,我们的程序是自动在跑的。因此我们希望在发生异常的时候,能够将一些页面的参数记录下来,从而为开发的同学去排查问题提供一些现场的数据环境。在这种情况下就需要用到网页自动截图的功能。本节我们将从使用场景和以CSDN的首页为例给大家进行说明。
1、自动截图使用场景
除了给测试的同学使用,在很多的时长或者销售场景中。也经常需要截图处理,我们需要自动的对一些功能进行录屏介绍。当然,如果有对应的市场或者销售队友帮忙,那么无需关心。如果是我们技术的小伙伴打天下,那么是不是可以有一些技术的方式来提升工作效率呢?
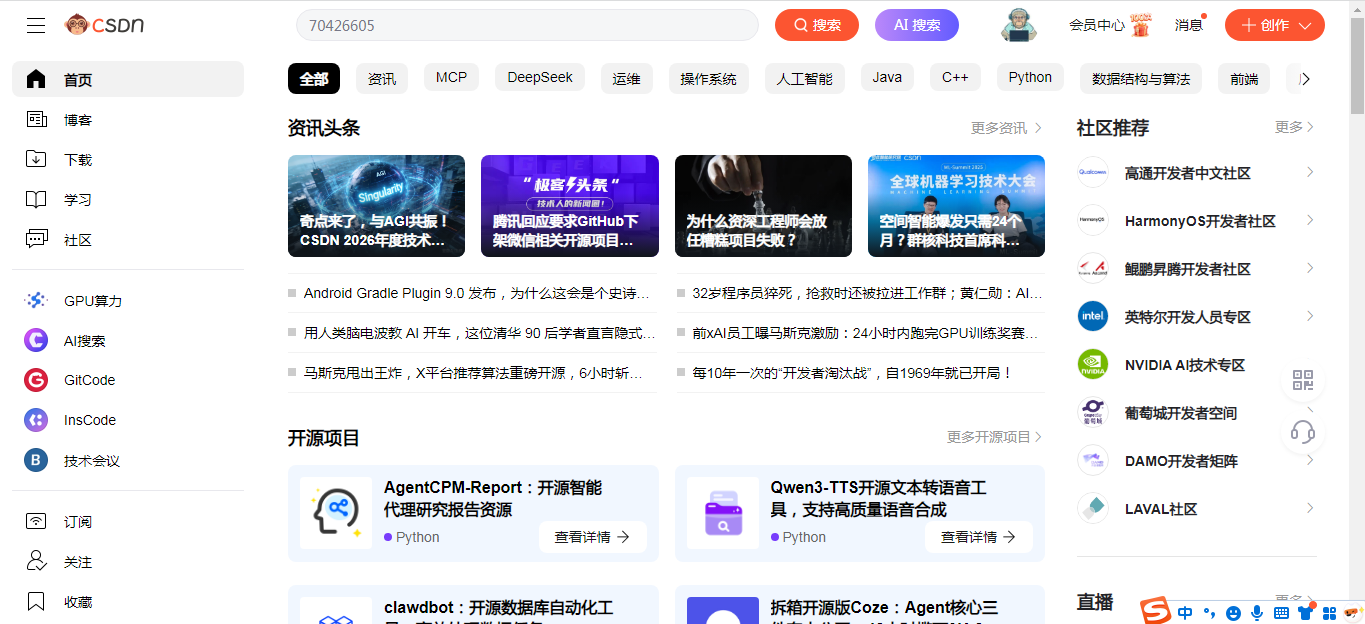
2、以CSDN首页为例
以CSDN首页为例,我们在网站上输入CSDN的首页地址后,点击回车就可以看到其首页。如下图所示:
如果我们不想使用人工截图的方式来获取相关资源,如何直接使用一些脚本来实现以上功能呢?下面就跟随博主的介绍来一步一步的进行实现。要想实现网页的自动截图,有很多种的解决方案。这里我们使用Selenium这种成熟的方案。下文将详细的介绍如何搭建Selenium环境以及给出一个具体的例子,让大家快速入门。
二、Selenium环境搭建
本节将详细介绍如何在Java中搭建Selenium环境,并且以访问CSDN的首页为入口进行实例测试。让大家不仅掌握环境的搭建,同时也了解如何进行程序的驱动。
1、Maven定义
这里我们使用Maven的方式来管理相应的资源依赖包。在Java中,如果需要使用到Selenium的话,我们需要在Pom.xml中进行如下的定义:
java
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>3.141.59</version>
</dependency>需要说明的是,关于Selenium的版本,请大家结合自己的Jdk来设置。写博客的这台机器只安装了JDK1.8,因此我们就选择可以兼容jdk1.8的3.141.59。大家在实际过程中可以根据自己的实际配置环境来进行调整,如果有更高的jdk版本,大家可以升级到高级版本来引入。
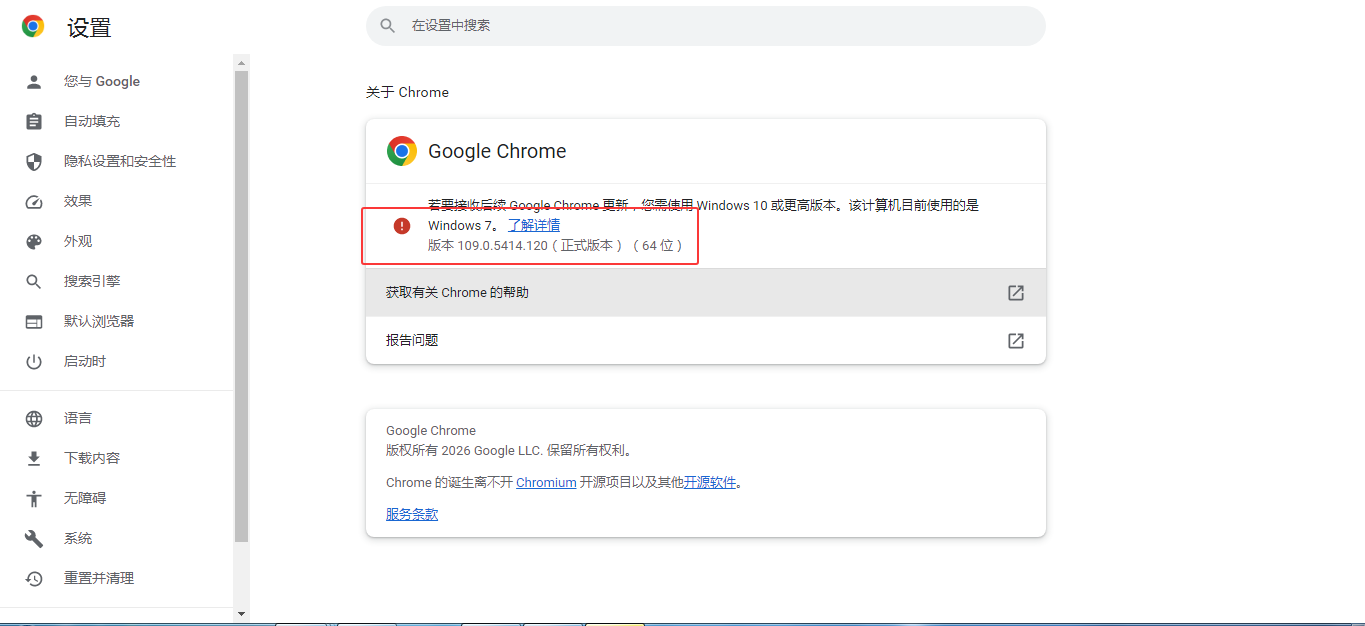
2、Selenium版本定义
Selenium的一个核心原理其实需要一个Driver,而这个驱动至关重要。如何选择自己的驱动版本。首先我们可以来看一下自己的本地浏览器的版本,这里以Chrome浏览器为演示对象。我们可以在浏览器的关于中看到其具体的版本号,如下图所示:
为了保证我们的应用程序能通过驱动来调用具体的浏览器,因此我们也需要下载相应版本的驱动器,这里我们已经提前下载好了,如下图所示:
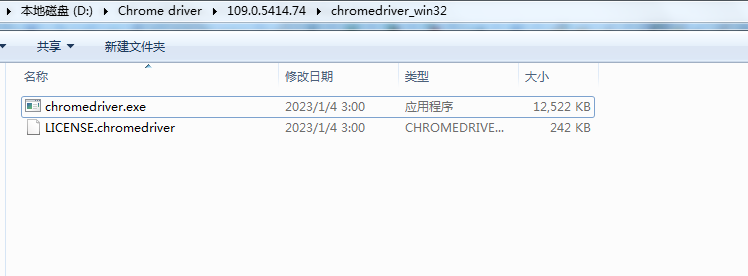
下载好之后,将压缩包解压下来,这个目录请大家记住,在后续的应用程序中还会重点使用的,一定要记下来。
3、实例程序
下面将开发一个示例程序,能够打开网页,并且实现截图,最后还能够将截图的图片保存到本地磁盘中。跟着我的脚步来看看如何实现吧。首先第一步是设置驱动路径,这里的驱动路径是在上一节中详细介绍的。核心方法如下:
java
// 1. 配置驱动路径 (需根据实际存放位置修改)
System.setProperty("webdriver.chrome.driver",
"D:/Chrome driver/109.0.5414.74/chromedriver_win32/chromedriver.exe");第二步是设置访问设置,比如设置无head模式,这样就不会打开浏览器页面,看起来更友好,同时还可以设置浏览器的高度和宽度。核心代码如下:
java
// 2. 开启无头模式 (Headless),这样不会弹出浏览器窗口
ChromeOptions options = new ChromeOptions();
options.addArguments("--headless");
options.addArguments("--window-size=1920,1080");第三步是创建WebDriver,然后访问我们的具体页面,在访问页面的同时还要进行截图,并且保存到本地。核心代码如下:
java
WebDriver driver = new ChromeDriver(options);
try {
// 3. 访问网页
driver.get("https://www.csdn.net/");
// 4. 执行截图
File srcFile = ((TakesScreenshot) driver).getScreenshotAs(OutputType.FILE);
File targetFile = new File("screenshot_chrome_csdn.png");
// 5. 保存到本地
FileUtils.copyFile(srcFile, targetFile);
System.out.println("截图已保存至: " + targetFile.getAbsolutePath());
} catch (IOException e) {
e.printStackTrace();
} finally {
// 6. 关闭并退出
driver.quit();
}接下来我们就可以在Main方法中测试以下是否可以打开界面,并且可以实现对应的截图功能。应用程序运行完成后,看到一下输出即说明成功输出:
bash
Starting ChromeDriver 109.0.5414.74 (e7c5703604daa9cc128ccf5a5d3e993513758913-refs/branch-heads/5414@{#1172}) on port 19531
Only local connections are allowed.
Please see https://chromedriver.chromium.org/security-considerations for suggestions on keeping ChromeDriver safe.
ChromeDriver was started successfully.
一月 25, 2026 8:59:34 下午 org.openqa.selenium.remote.ProtocolHandshake createSession
信息: Detected dialect: W3C
截图已保存至: F:\wzh_workspace_20210320\selenium-demo\screenshot_chrome_csdn.png最后我们在页面看到生成的目标图片:
能看到这个界面,说明你集成成功了。如果遇到了一些问题,可以在评论区留言交流。
三、可能遇到的问题
本节将简单讲解在集成过程中可能遇到的问题,帮助在集成过程中遇到问题时可以进行对照参考等。这里主要讲解两个问题,一个是jdk的版本问题,另一个是Chrome Driver的版本问题。这两个问题都是在集成中经常遇到的。
1、JDK的版本问题
首先,JDK 8与高版本兼容性问题 。Selenium 4.x要求JDK 11或更高版本,如果使用JDK 8运行Selenium 4,会因模块化系统不兼容而报错。建议使用Selenium 3.x(最后版本3.141.59)配合JDK 8。其次,模块路径问题 。从JDK 9开始引入的模块系统会导致传统类路径加载失败,特别是使用--add-exports和--add-opens参数时配置复杂。WebDriver启动时可能因反射权限不足而失败。再者,内部API访问限制 。高版本JDK(特别是JDK 16+)加强了封装限制,Selenium依赖的某些内部API(如sun.misc.Unsafe)被限制访问,需手动添加JVM参数解封。最后,弃用警告与未来兼容性。Selenium 4大量使用的新API在旧JDK中可能不可用,而新JDK中某些Selenium依赖的方法已被标记为弃用,会在日志中产生大量警告。建议始终使用Selenium官方文档推荐的JDK版本组合,并在持续集成环境中统一JDK版本以避免环境差异问题。
2、Chrome Driver版本问题
在上述的实例代码中,我已经设置了Chrome Driver。程序没有任何问题,假如没有设置或者设置错误会遇到什么问题呢?来看看:
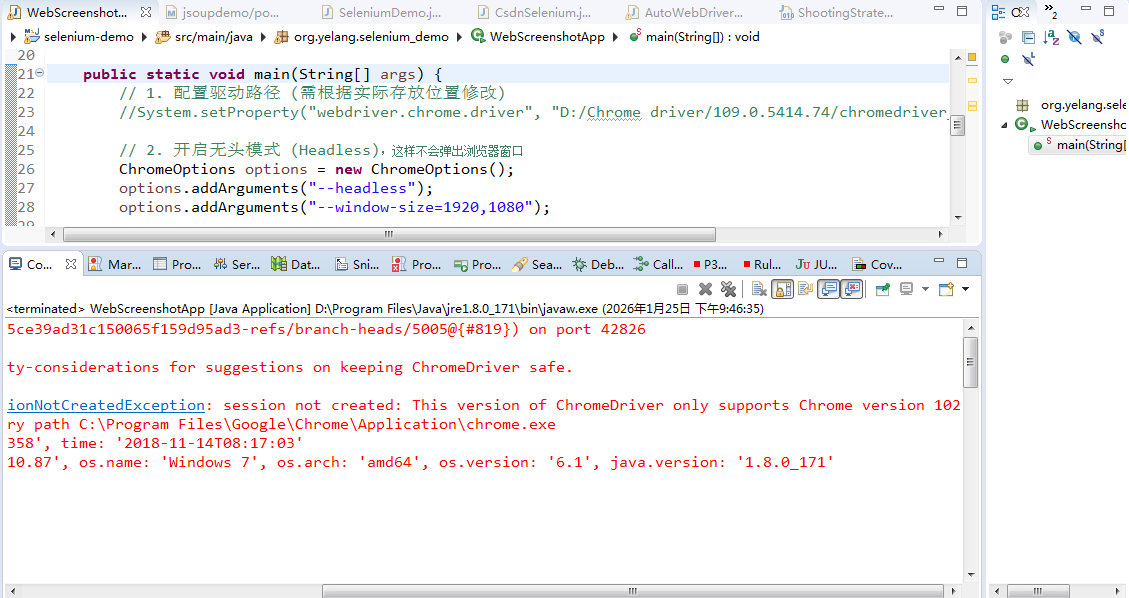
这其实说的就是版本的问题,因此我们在调用时,一定要注意本地访问浏览器的版本问题,然后设置对应的驱动版本才能保证程序正常运行。
四、总结
以上就是本文的主要内容, 本文将详细介绍Java搭配Selenium实现网页访问与自动截图的全过程。首先,我们会从环境搭建开始,逐步讲解如何安装和配置Java开发环境以及Selenium框架,确保读者能够在本地环境中顺利运行相关代码。接着,通过具体的代码示例,展示如何使用Java编写代码来控制Selenium驱动浏览器访问网页,并实现自动截图功能。相信通过本文,您可以掌握Selenium的正确开发姿势。行文仓促,定有不足之处,欢迎各位朋友在评论区批评指正,不胜感激。