概要
本周对强化学习进行了初步的学习和了解,强化学习不同于于监督学习对有标签的训练数据输出期待的结果,而是用于处理决策的问题。
abstract
This week, I embarked on a preliminary study of reinforcement learning. Unlike supervised learning, which relies on labeled training data to produce expected outcomes, reinforcement learning is designed to tackle decision-making problems.
机器学习中的强化学习(RL)和监督学习是两种核心范式。监督学习依赖带有标签的训练数据,通过建立输入与输出之间的映射关系进行预测,适用于模式识别和分类任务,如图像识别、自然语言处理中的文本分类和金融风控模型等。而强化学习则通过智能体与环境交互,以试错方式学习最优策略以最大化累积奖励,无需预先提供标签数据,更擅长序列决策问题,
强化学习的运行逻辑可以概括为 "智能体在与环境的持续交互中,通过试错学习最优决策策略" 。这个过程是一个闭环,其核心逻辑循环如下:
感知状态:在每一个时间步 t,智能体从环境中观察到一个状态 S_t
做出决策:智能体根据当前状态和自身的策略,选择一个动作 A_t
获得反馈:环境接收动作后,发生变化,并给出两个关键反馈:
即时奖励 R_{t+1}:一个标量数值,表示该动作在当下带来的好坏
新的状态 S_{t+1}:动作执行后,环境进入下一个状态。
学习与更新:智能体将这次交互的经验 (S_t, A_t, R_{t+1}, S_{t+1}) 存储起来。其核心目标是学习一个能最大化长期累积奖励(而非眼前即时奖励)的策略。它通过算法(如Q-learning、策略梯度)不断评估动作的价值,并更新其策略,使得在未来遇到类似状态时,能做出更优的选择。

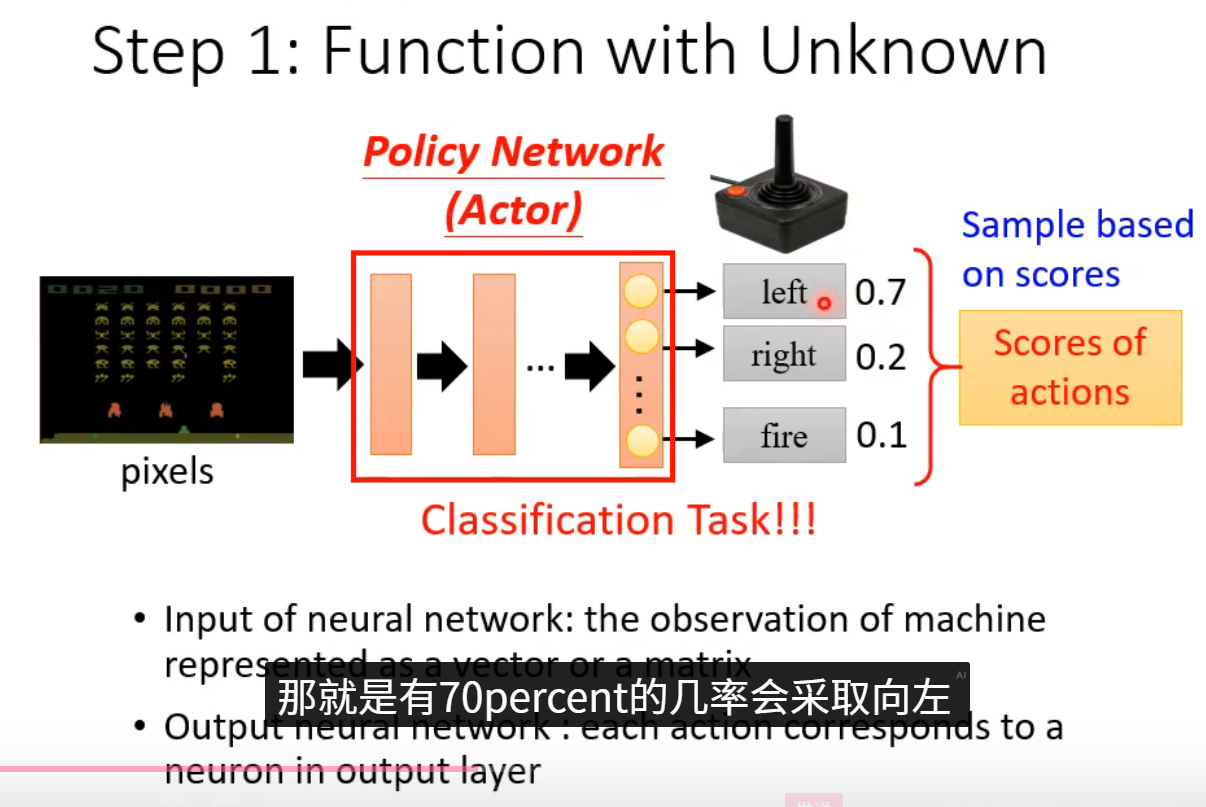
第一步:Function with Unknown(建立待优化函数)
我们直接搭建一个参数化的函数 (例如神经网络),输入状态,输出动作的价值(Q-learning)或动作的概率分布(Policy Gradient)。这个函数初始时参数随机,决策完全随机,它就是我们要训练的核心对象。
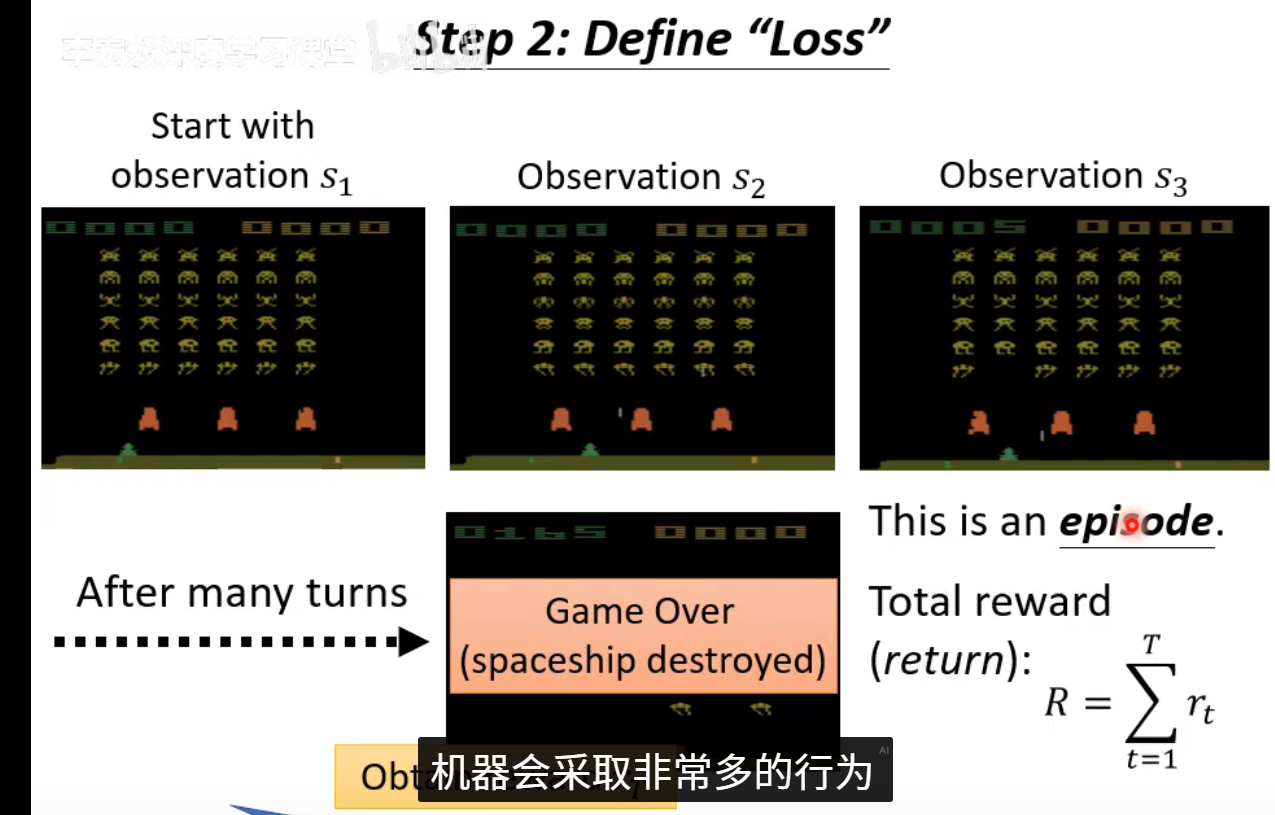
第二步:Define "Loss"(计算损失函数)
智能体与环境交互 ,收集数据(状态、动作、奖励)。然后,我们根据这些数据计算一个损失:
-
在Q-learning中,损失 = (实际获得的奖励 + 对未来收益的预测 - 网络原来的预测值)²。我们希望网络的预测越来越准。
-
在Policy Gradient中,损失 = -(获得的累计奖励 × 采取该动作的概率的对数)。我们希望提高带来高回报动作的概率,降低低回报动作的概率。
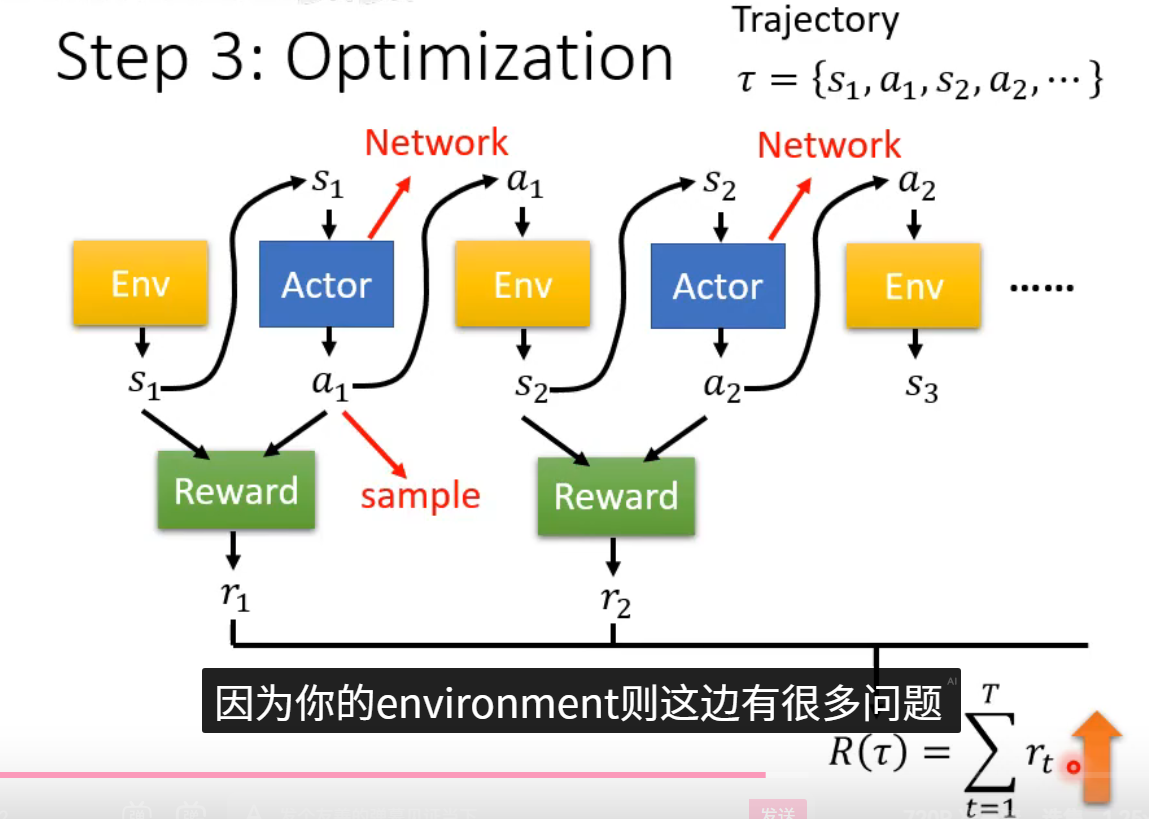
第三步:Optimization(执行优化更新)
我们固定第二步中计算损失用到的数据 ,然后对损失函数执行反向传播,计算梯度 ,最后使用优化器(如SGD或Adam)更新第一步中函数的参数 。参数更新后,智能体的决策策略就发生了一点点改变。然后回到第二步,用新策略收集新数据,不断循环,直到策略表现令人满意。