郑重声明:本案例只做交流学习,不得商用,不得危害网站运行,如出现问题与本人无关
案例网址:gov公安
找加密参数
接口:
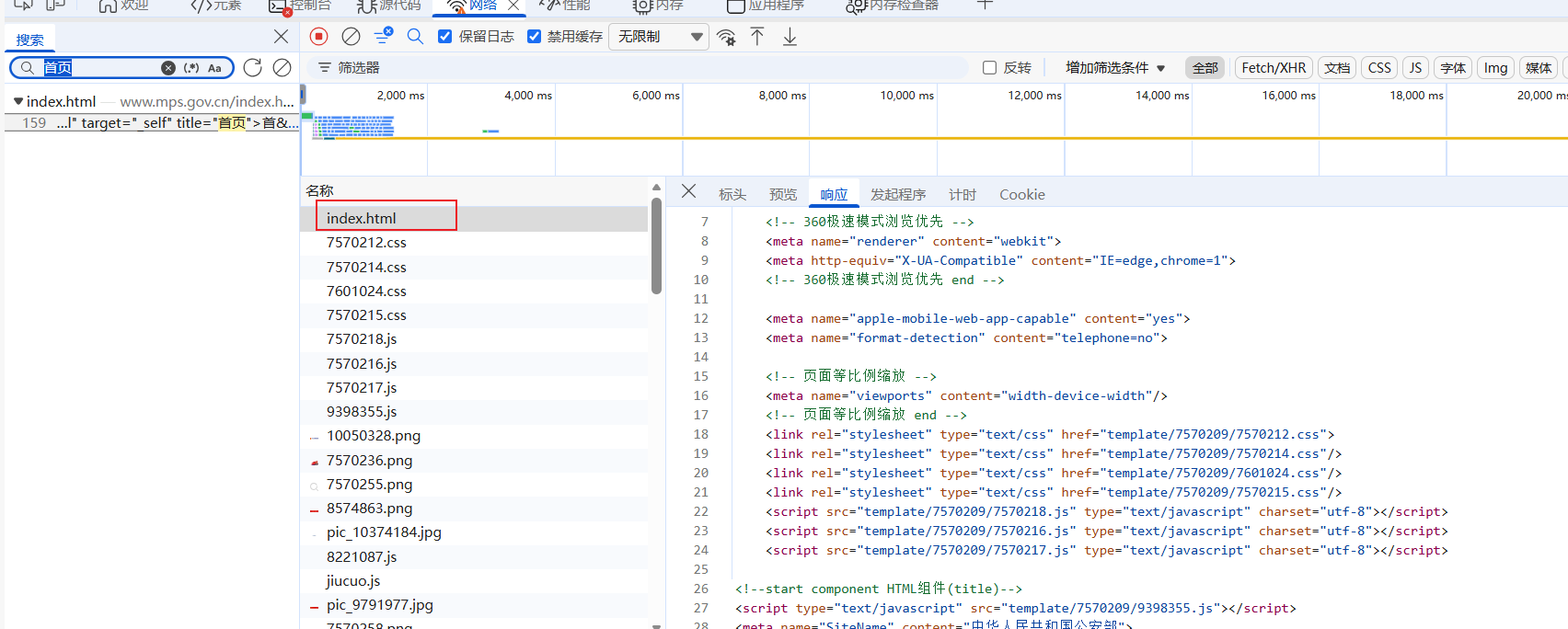
加密参数:
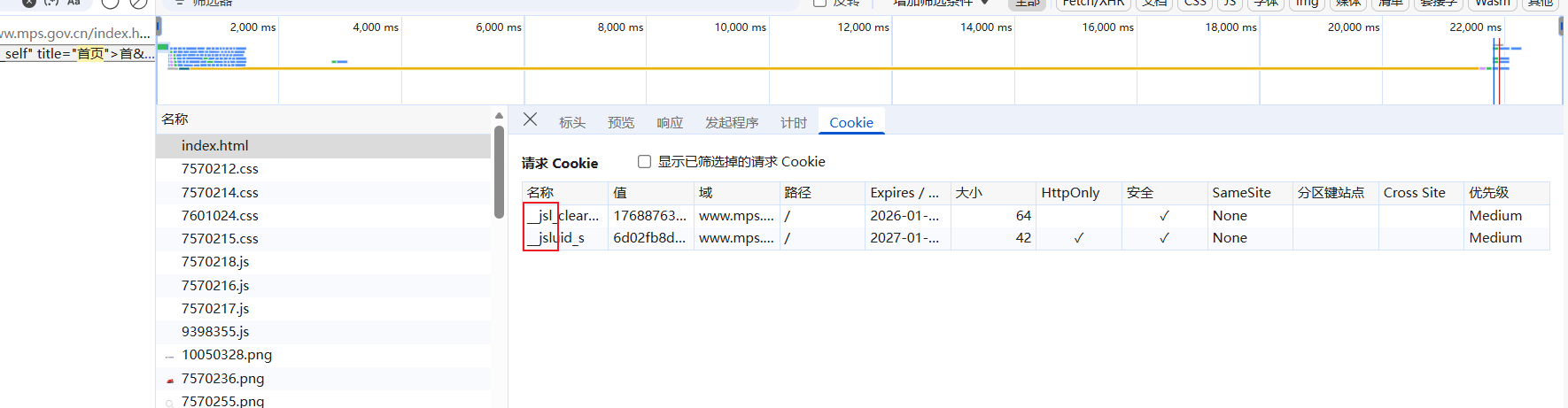
cookie一眼加速乐,其他地方(请求头)没有加密参数
处理加速乐
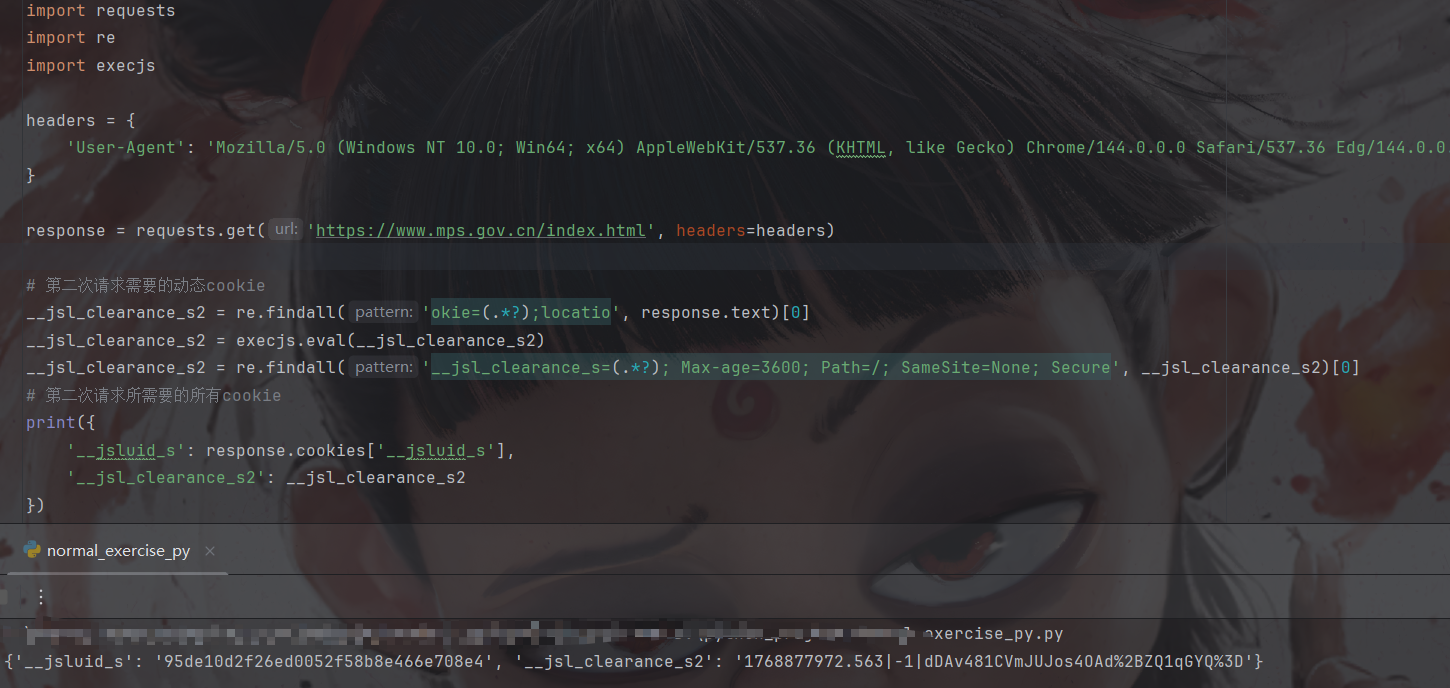
构建第一次请求并拿到cookie
不带任何cookie拿到第二次请求所有cookie和第三次请求的一个cookie:
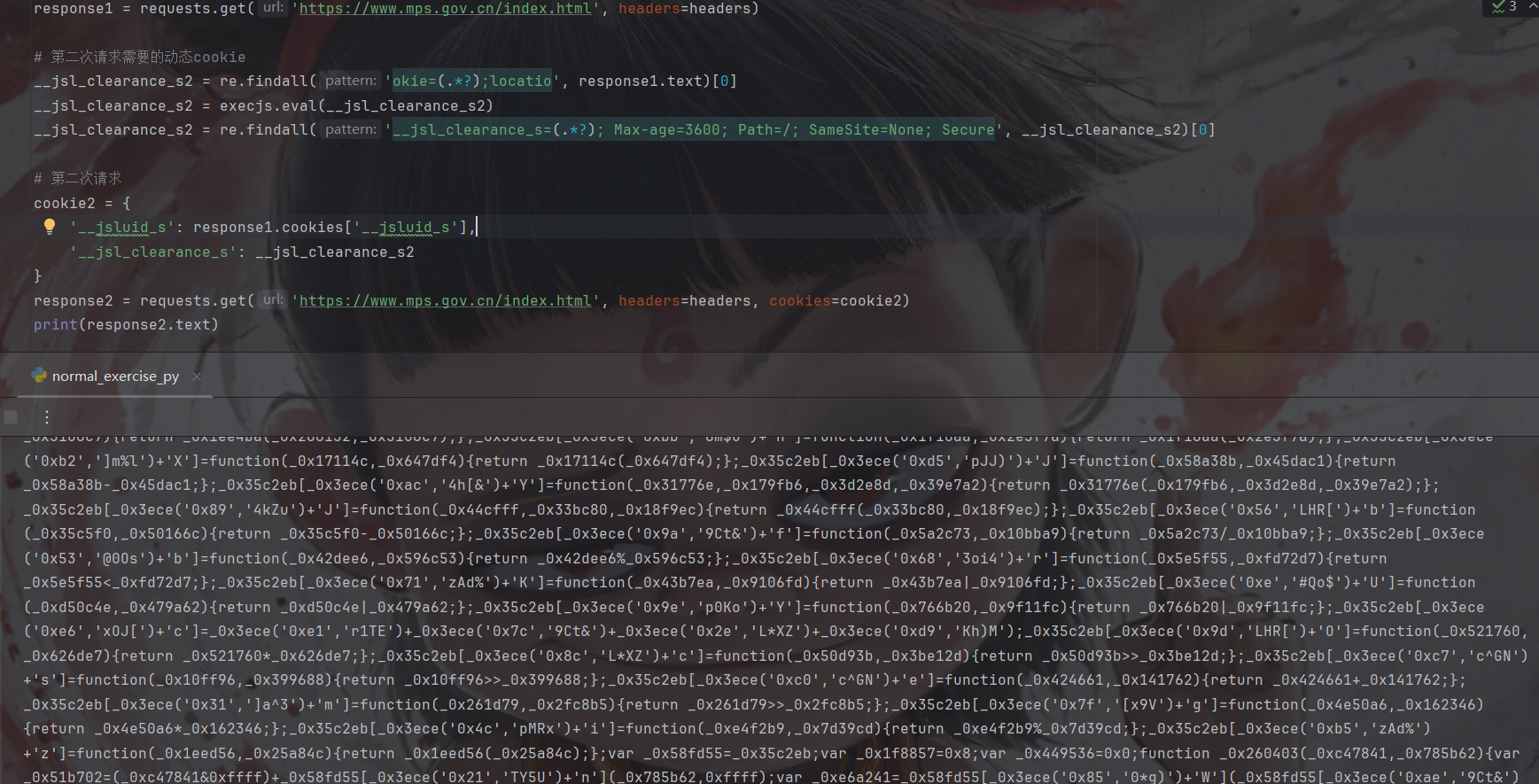
构建第二次请求
带上第一次请求拿到的cookie发起第二次请求:
补环境拿cookie
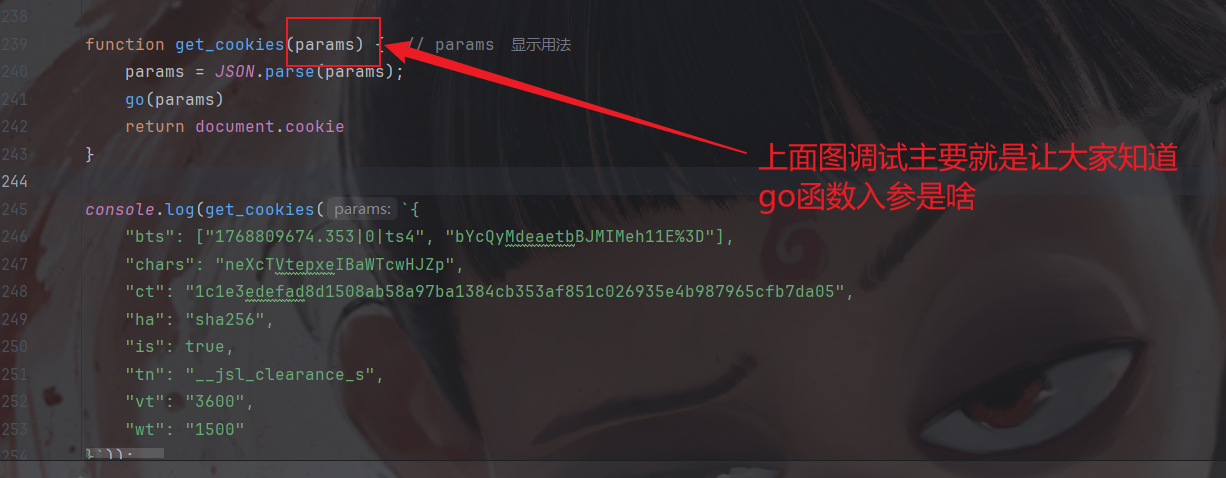
通过第二次请求拿到加密第三次cookie的js代码,我们去浏览器下断点(脚本断点)拿到代码,记得清空cookie再刷新网页:
拿到之后看到是VM文件那就别乱动了,因为VM固定不了,我们直接全扣然后补环境:
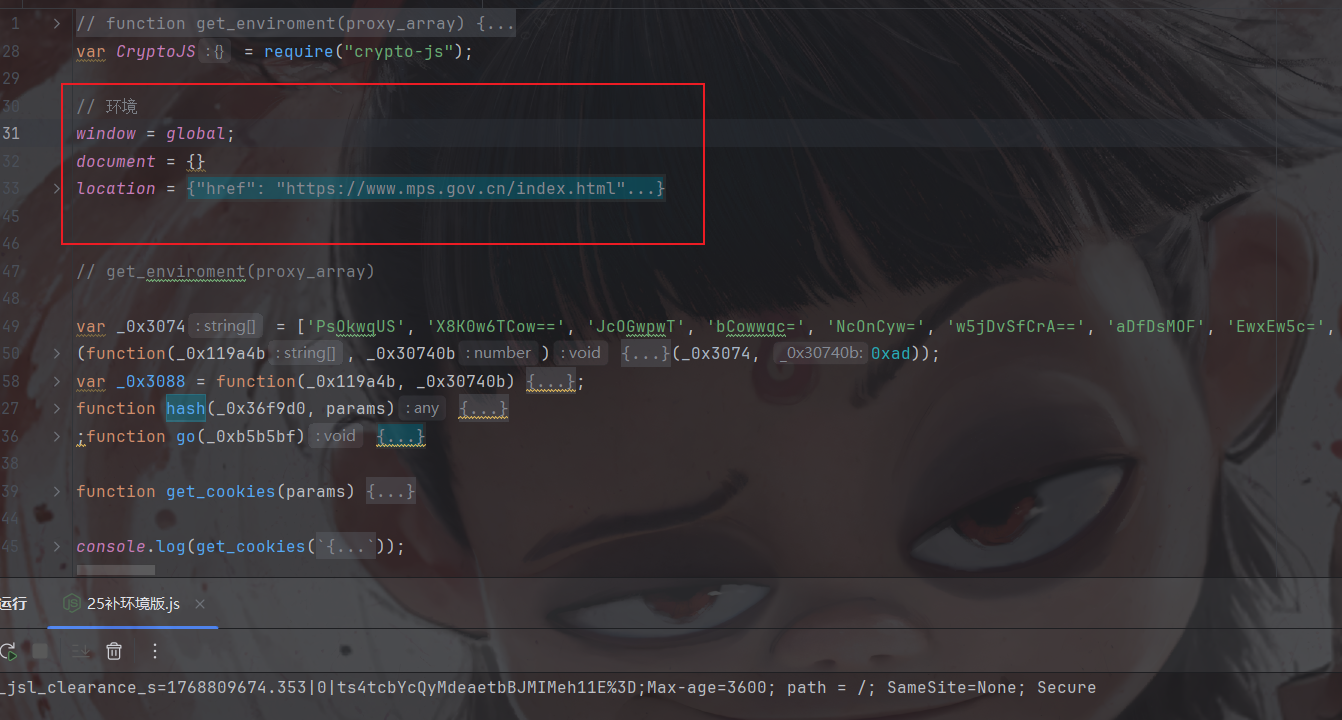
环境就这些然后我们需要封装一下,并改一下hash算法那块,众所周知jsl加密有md5,sha1和sha256这三个算法,我们找到hash这个函数改一下:
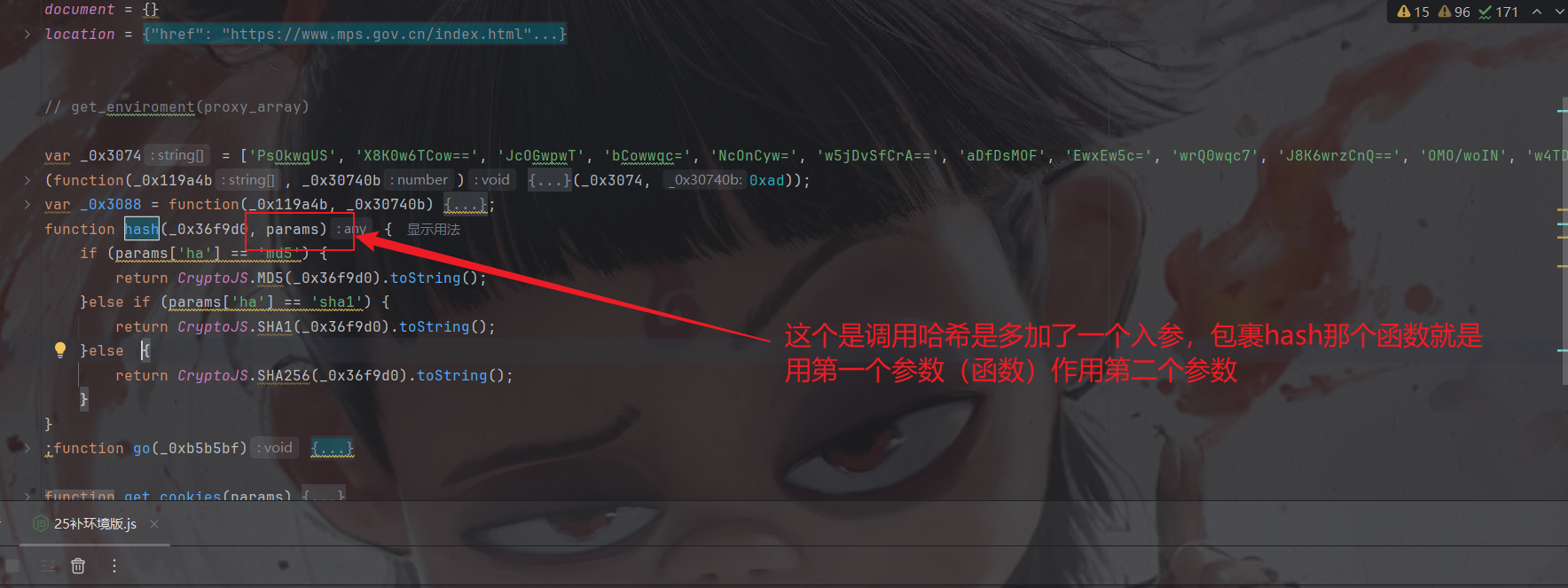
还有就是调用的地方(上图中其实已经说明了):
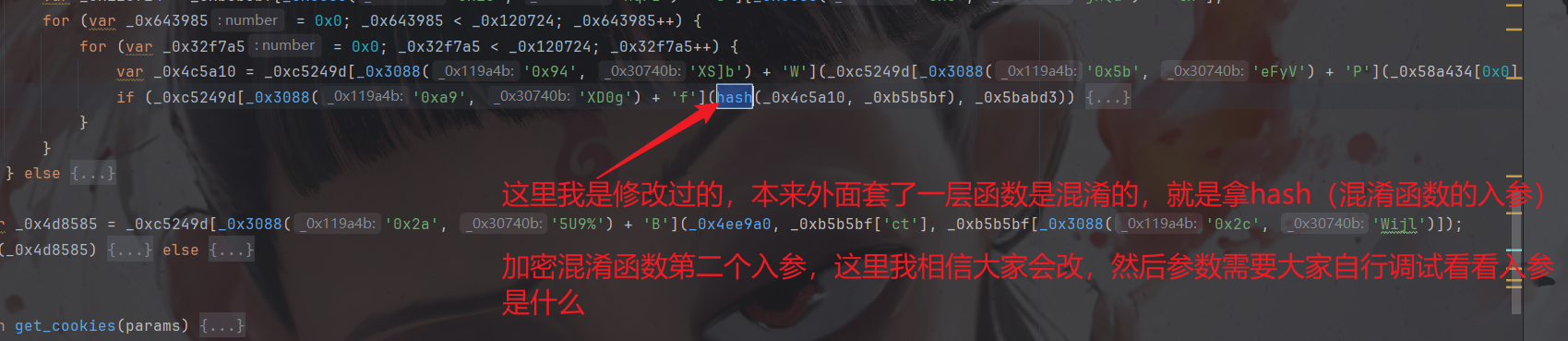
封装:
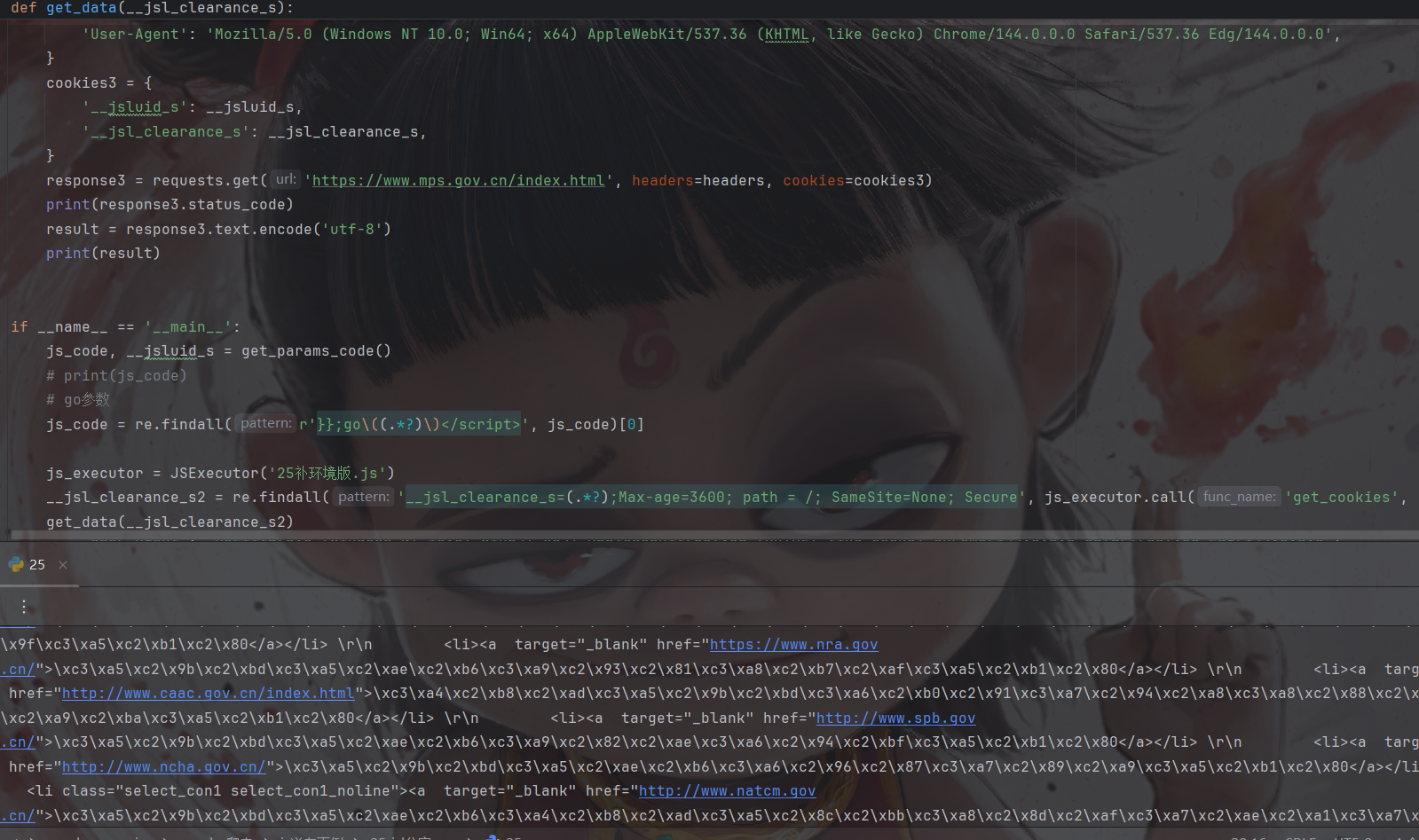
构建第三次请求
其实就是py调用js拿到动态cookie然后再带上第一次请求得到的cookie(服务器返回那个)请求:
小结
本文很简单,jsl纯防小白用的,后面我会出一下此案例的js扣关键代码和纯算,敬请期待,如本文有什么问题请及时提出,加油加油