拆解机器学习的三大支柱:监督学习、无监督学习与强化学习
1. 前言:机器是如何"学会"的?
在人工智能的浪潮中,我们经常听到"模型训练"这个词。但机器毕竟不是人类,没有大脑神经元,它是如何从一堆冰冷的数据中学会识别猫狗、预测股价甚至在《王者荣耀》里大杀四方的?
机器学习(Machine Learning)的核心本质,就是通过算法解析数据,从中学习规律,并对真实世界中的事件做出决策或预测。
根据**"数据是否带有标签"以及"学习的反馈机制"**,我们将机器学习主要分为三大流派:
-
监督学习 (Supervised Learning):有老师带着学。
-
无监督学习 (Unsupervised Learning):自己找规律学。
-
强化学习 (Reinforcement Learning):在实战中试错学。
本文将深入解析这三种范式的底层原理及其核心应用场景。
2. 监督学习 (Supervised Learning):全知全能的老师
监督学习是目前工业界应用最广泛、商业价值变现最成熟的范式。
2.1 核心原理
想象你在教一个小孩识字。你拿出一张卡片(输入数据 Input ),上面写着"山",然后告诉他:"这个字念 Shan"(标签 Label)。你不断地重复这个过程,直到下次你拿出一张新卡片,小孩能自己说出读音。
在数学上,这就是在寻找一个函数 f(x) = y。我们拥有大量的 (x, y) 数据对,目的是训练出一个模型,当输入新的 x 时,能准确预测出 y。
2.2 两大核心任务
根据**输出结果(标签 y)**的数据类型不同,监督学习分为两类:
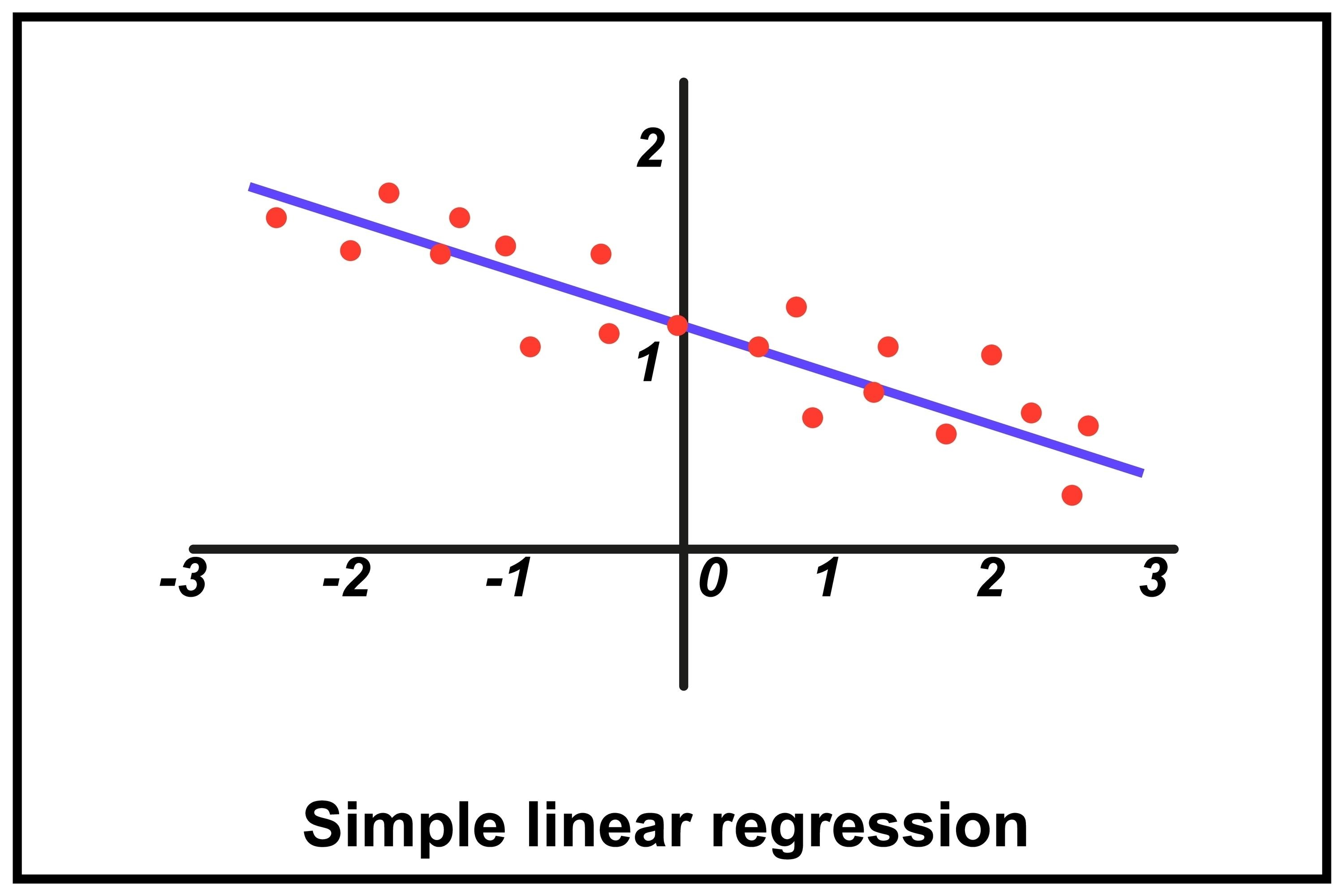
A. 回归 (Regression) ------ 预测"多少"
Shutterstock
Explore
-
定义 :目标变量是连续的数值。
-
场景:
-
房价预测:输入房屋面积、地段、房龄,输出具体的房价(如 500万、500.1万)。
-
销量预测:输入历史销售额、季节、促销力度,输出下个月的销量。
-
-
经典算法:线性回归 (Linear Regression)。
B. 分类 (Classification) ------ 预测"是谁"
-
定义 :目标变量是离散的类别。
-
场景:
-
垃圾邮件识别:输入邮件内容,输出"是垃圾邮件"或"不是垃圾邮件"(二分类)。
-
图像识别:输入一张图片,输出"猫"、"狗"或"兔子"(多分类)。
-
-
经典算法:逻辑回归 (Logistic Regression)、支持向量机 (SVM)、决策树。
💡 产品经理笔记:
做监督学习项目,最痛的点通常不是算法,而是数据标注。如果你的业务无法获取大量带标签的高质量数据,监督学习可能无法启动。
3. 无监督学习 (Unsupervised Learning):数据的自我发现
如果我们只有题目,没有答案,机器还能学吗?可以,这就是无监督学习。
3.1 核心原理
数据中只有输入 x,没有标签 y。算法的任务不是"预测",而是**"发现"**------发现数据内部隐藏的结构、模式或规律。
就像给外星人一堆地球的硬币,虽然他不知道面值(没有标签),但他可以通过大小、材质、花纹,把硬币分成几堆。
3.2 核心任务:聚类 (Clustering)
聚类是无监督学习中最典型的应用。它的目标是将相似的样本自动归为一类(Cluster)。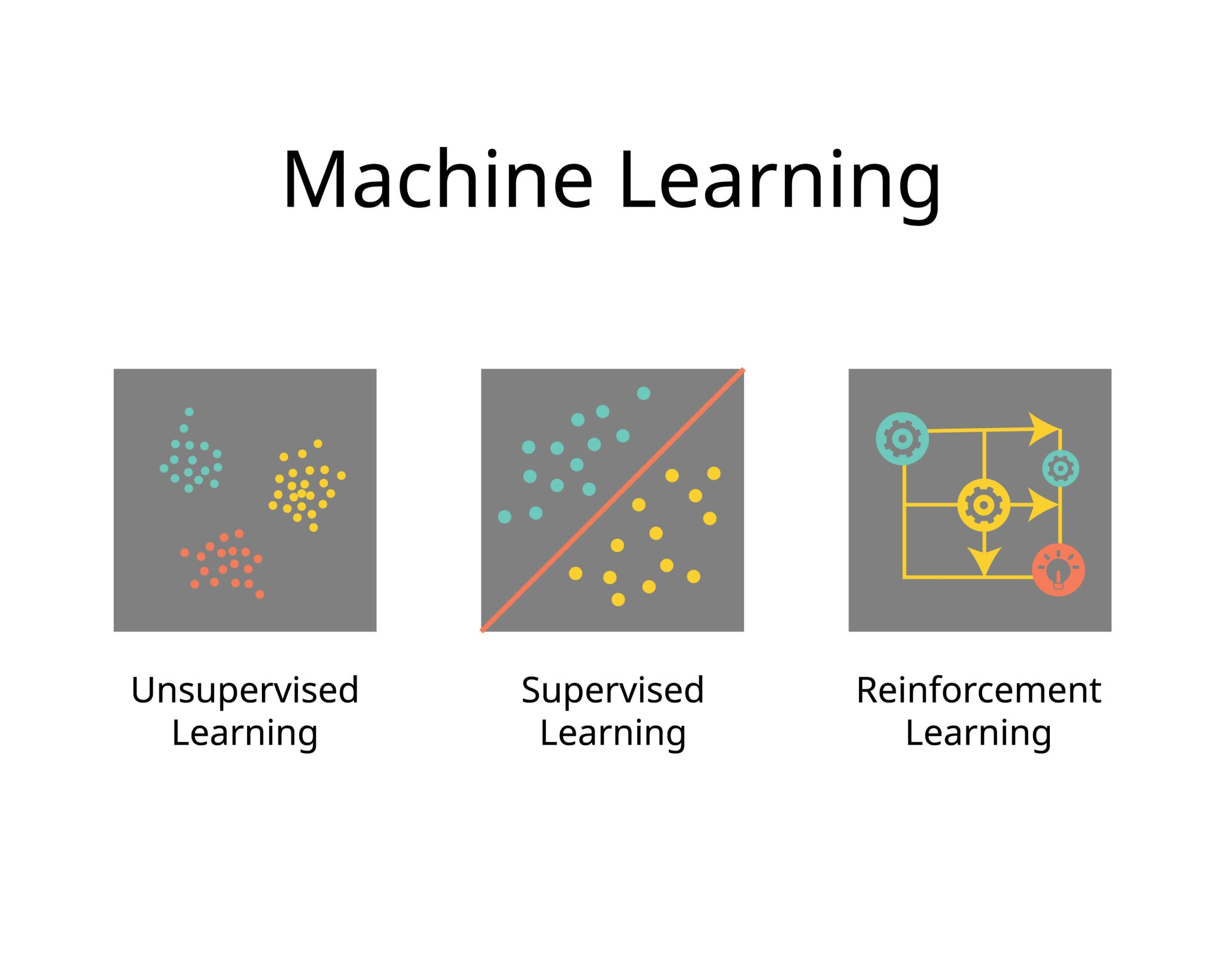
Getty Images
Explore
-
原理 :计算样本之间的距离(如欧氏距离)。距离近的样本,被认为相似度高。
-
场景:
-
用户分群 (User Segmentation):电商平台根据用户的点击历史、购买力,自动将用户划分为"价格敏感型"、"高净值型"、"闲逛型",以便进行精细化运营。
-
异常检测:在大量正常的服务器日志中,自动聚类出那些"长得不一样"的数据,通常意味着系统故障或黑客攻击。
-
-
经典算法:K-Means, DBSCAN。
💡 产品经理笔记:
无监督学习非常适合冷启动阶段,或者用于探索性数据分析(EDA),帮我们理解手里到底有什么样的数据。
4. 强化学习 (Reinforcement Learning):在试错中进化
强化学习与前两者完全不同,它不依赖静态的数据集,而是依赖交互。
4.1 核心原理
强化学习由 智能体 (Agent) 和 环境 (Environment) 组成。
智能体在环境中做一个动作(Action),环境会给它一个反馈------奖励 (Reward) 或 惩罚 (Penalty)。智能体的目标是:通过不断的试错,找到一套策略(Policy),使得获得的累积奖励最大化。
这就像训练小狗:
-
动作:小狗坐下。
-
奖励:给它吃肉干。
-
策略:小狗学会了"只要听到口令坐下,就有肉吃"。
4.2 核心应用
-
游戏 AI:AlphaGo 下围棋、OpenAI Five 打 Dota 2。赢了就是+1分,输了就是-1分,AI 自己琢磨怎么赢。
-
推荐系统:现在的抖音/TikTok 推荐算法。你"滑走"是惩罚,你"完播/点赞"是奖励。算法通过强化学习不断调整推给你的视频,目的是最大化你的停留时间(累积奖励)。
-
机器人控制:波士顿动力的机器人学走路,摔倒了扣分,走稳了得分。
5. 总结与对比图谱
为了方便记忆,我们可以通过下表快速区分这三种学习方式:
| 维度 | 监督学习 (Supervised) | 无监督学习 (Unsupervised) | 强化学习 (Reinforcement) |
|---|---|---|---|
| 数据特征 | 输入 + 标签 (Input + Label) | 只有输入 (Input Only) | 动作 + 奖励 (Action + Reward) |
| 核心任务 | 回归、分类 | 聚类、降维 | 决策控制、策略优化 |
| 人类类比 | 老师教学生刷题 | 孩子自己玩积木找规律 | 训练小狗 / 玩游戏 |
| 典型算法 | 线性回归、决策树、随机森林 | K-Means、PCA | Q-Learning、PPO |
| 商业应用 | 房价预测、人脸识别、垃圾邮件过滤 | 用户分群、推荐系统召回 | 自动驾驶、游戏AI、动态定价 |