PyTorch实战(25)------使用PyTorch构建DQN模型
0. 前言
我们已经探讨了深度Q网络 (Deep Q-learning Network, DQN)的理论基础,在本节中,我们将使用 PyTorch 构建一个基于卷积神经网络 (Convolutional Neural Network, CNN)的 DQN 模型,训练一个智能体进行视频游戏 Pong。本节的目标是完整展示如何运用 PyTorch 开发深度强化学习应用。
1. 模型构建
初始化主卷积神经网络 (Convolutional Neural Network, CNN)和目标 CNN 模型。
(1) 首先,导入所需库:
python
# general imports
import cv2
import math
import numpy as np
import random
# reinforcement learning related imports
import re
from ale_py import ALEInterface
from collections import deque
import gymnasium as gym
from gymnasium import ObservationWrapper, Wrapper
from gymnasium.spaces import Box
# pytorch imports
import torch
import torch.nn as nn
from torch import save
from torch.optim import Adam导入所需库之后,为 DQN 模型定义 CNN 架构。这个 CNN 模型的核心功能是接收当前状态输入,并输出所有可能动作的概率分布。智能体会选择概率最高的动作作为下一步行为。我们没有使用回归模型来预测每个状态-动作对的Q值,而是将其转化为分类问题。
(2) 若采用Q值回归模型,就需要为所有可能的动作单独运行计算,然后选择预测Q值最高的动作。而使用分类模型,则能同时完成Q值计算和最佳下一步动作预测两个任务:
python
class ConvDQN(nn.Module):
def __init__(self, ip_sz, tot_num_acts):
super(ConvDQN, self).__init__()
self._ip_sz = ip_sz
self._tot_num_acts = tot_num_acts
self.cnv1 = nn.Conv2d(ip_sz[0], 32, kernel_size=8, stride=4)
self.activation = nn.ReLU()
self.cnv2 = nn.Conv2d(32, 64, kernel_size=4, stride=2)
self.cnv3 = nn.Conv2d(64, 64, kernel_size=3, stride=1)
self.fc1 = nn.Linear(self.feat_sz, 512)
self.fc2 = nn.Linear(512, tot_num_acts)模型包含三个卷积层 (cnv1、cnv2 和 cnv3),各层之间采用 ReLU 激活函数,最后连接两个全连接层。接下来,实现前向传播过程:
python
def forward(self, x):
op = self.cnv1(x)
op = self.activation(op)
op = self.cnv2(op)
op = self.activation(op)
op = self.cnv3(op)
op = self.activation(op).view(x.size()[0], -1)
op = self.fc1(op)
op = self.activation(op)
op = self.fc2(op)
return opforward 方法定义了模型的前向传播流程:输入数据依次通过卷积层,经展平处理后最终输入全连接层。接下来,实现其他模型方法:
python
@property
def feat_sz(self):
x = torch.zeros(1, *self._ip_sz)
x = self.cnv1(x)
x = self.activation(x)
x = self.cnv2(x)
x = self.activation(x)
x = self.cnv3(x)
x = self.activation(x)
return x.view(1, -1).size(1)
def perf_action(self, stt, eps, dvc):
if random.random() > eps:
stt = torch.from_numpy(np.float32(stt)).unsqueeze(0).to(dvc)
q_val = self.forward(stt)
act = q_val.max(1)[1].item()
else:
act = random.randrange(self._tot_num_acts)
return actfeat_size 方法用于计算最后一个卷积层输出经展平后的特征向量尺寸。而 perf_action 方法的功能与《Q学习原理>一节介绍的的 take_action 方法完全一致。
(3) 定义一个用于实例化主神经网络和目标神经网络的函数:
python
def models_init(env, dvc):
mdl = ConvDQN(env.observation_space.shape, env.action_space.n).to(dvc)
tgt_mdl = ConvDQN(env.observation_space.shape, env.action_space.n).to(dvc)
return mdl, tgt_mdl这两个模型属于同一类别实例,因此具有相同的网络架构。但由于是独立的实例对象,它们会随着不同的权重参数更新而各自演化。
2. 定义经验回放缓冲区
经验回放缓冲区是 DQN 的核心组件,通过这个缓冲区,我们可以存储游戏过程中的数千个状态转移(帧画面),然后随机采样这些视频帧来训练 CNN 模型:
python
class RepBfr:
def __init__(self, cap_max):
self._bfr = deque(maxlen=cap_max)
def push(self, st, act, rwd, nxt_st, fin):
self._bfr.append((st, act, rwd, nxt_st, fin))
def smpl(self, bch_sz):
idxs = np.random.choice(len(self._bfr), bch_sz, False)
bch = zip(*[self._bfr[i] for i in idxs])
st, act, rwd, nxt_st, fin = bch
return (np.array(st), np.array(act), np.array(rwd, dtype=np.float32),
np.array(nxt_st), np.array(fin, dtype=np.uint8))
def __len__(self):
return len(self._bfr)其中,cap_max 表示预定义的缓冲区容量,即需要存储在缓冲区内的游戏状态转移帧数。smp1 方法将在 CNN 训练循环中被调用,用于对存储的状态转移进行采样并生成批量训练数据。
3. 环境构建
接下来,将重点构建强化学习问题的核心基础组件------环境模块。通过使用 gymnasium 库,我们可以直接调用预构建的《Pong》游戏环境。并通过以下步骤对该环境进行功能增强,包括对游戏画面帧进行降采样处理、将图像帧推入经验回放缓冲区、将图像转换为 PyTorch 张量等。
(1) 实现各环境控制步骤的类定义,用于初始化并增强视频游戏环境:
python
class ClassicControl(Wrapper):
def __init__(self, env, is_atari):
super().__init__(env)
self._is_atari = is_atari
def reset(self, **kwargs):
if self._is_atari:
return self.env.reset(**kwargs)
else:
obs, info = self.env.reset(**kwargs)
return self.env.render(), info
class FrameResetEnv(Wrapper):
def __init__(self, env):
super().__init__(env)
if env.action_space.n < 3:
raise ValueError("min required action space of 3!")
def reset(self, **kwargs):
obs, info = self.env.reset(**kwargs)
obs, _, term, trunc, _ = self.env.step(1)
if term or trunc:
obs, info = self.env.reset(**kwargs)
obs, _, term, trunc, _ = self.env.step(2)
if term or trunc:
obs, info = self.env.reset(**kwargs)
return obs, info
def step(self, action):
return self.env.step(action)
class FrameDownSample(ObservationWrapper):
def __init__(self, env):
super().__init__(env)
self.observation_space = Box(low=0, high=255, shape=(84, 84, 1), dtype=np.uint8)
self._width = 84
self._height = 84
def observation(self, observation):
frame = cv2.cvtColor(observation, cv2.COLOR_RGB2GRAY)
frame = cv2.resize(frame, (self._width, self._height), interpolation=cv2.INTER_AREA)
return frame[:, :, None]
class MaxAndSkipEnv(Wrapper):
def __init__(self, env, skip=4):
super().__init__(env)
self._obs_buffer = deque(maxlen=2)
self._skip = skip
def step(self, action):
total_reward = 0.0
terminated = False
truncated = False
info = {}
for _ in range(self._skip):
obs, reward, terminated, truncated, info = self.env.step(action)
self._obs_buffer.append(obs)
total_reward += reward
if terminated or truncated:
break
max_frame = np.max(np.stack(self._obs_buffer), axis=0)
return max_frame, total_reward, terminated, truncated, info
def reset(self, **kwargs):
self._obs_buffer.clear()
obs, info = self.env.reset(**kwargs)
self._obs_buffer.append(obs)
return obs, info
class FrameBuffer(ObservationWrapper):
def __init__(self, env, num_steps, dtype=np.float32):
super().__init__(env)
obs_space = env.observation_space
self._dtype = dtype
self.observation_space = Box(
obs_space.low.repeat(num_steps, axis=0),
obs_space.high.repeat(num_steps, axis=0),
dtype=self._dtype
)
def reset(self, **kwargs):
self.buffer = np.zeros_like(self.observation_space.low, dtype=self._dtype)
obs, info = self.env.reset(**kwargs)
return self.observation(obs), info
def observation(self, observation):
self.buffer[:-1] = self.buffer[1:]
self.buffer[-1] = observation
return self.buffer
class Image2PyTorch(ObservationWrapper):
def __init__(self, env):
super().__init__(env)
obs_shape = self.observation_space.shape
self.observation_space = Box(
low=0.0,
high=1.0,
shape=(obs_shape[-1], obs_shape[0], obs_shape[1]),
dtype=np.float32
)
def observation(self, observation):
return np.moveaxis(observation, -1, 0)
class NormalizeFloats(ObservationWrapper):
def observation(self, obs):
return np.array(obs).astype(np.float32) / 255.0(2) 完成环境相关类的定义后,我们还需要定义方法 wrap_env(),该方法以原始《Pong》游戏环境为输入,增强环境功能:
python
def wrap_env(env_name):
env = gym.make(env_name, render_mode='rgb_array', frameskip=1)
env = gym.wrappers.AtariPreprocessing(
env,
frame_skip=4,
screen_size=84,
terminal_on_life_loss=False,
grayscale_obs=True,
scale_obs=False
)
env = gym.wrappers.FrameStackObservation(env, 4)
env = NormalizeFloats(env)
return env4. 定义 CNN 优化函数
接下来,我们将定义训练 DRL 模型的损失函数,并定义每次模型训练迭代结束时需要执行的操作。
(1) 我们已经定义了模型架构,接下来将定义损失函数,模型将根据该损失函数进行训练,目标是最小化该损失:
python
def calc_temp_diff_loss(mdl, tgt_mdl, bch, gm, dvc):
st, act, rwd, nxt_st, fin = bch
st = torch.from_numpy(np.float32(st)).to(dvc)
nxt_st = torch.from_numpy(np.float32(nxt_st)).to(dvc)
act = torch.from_numpy(act).to(dvc)
rwd = torch.from_numpy(rwd).to(dvc)
fin = torch.from_numpy(fin).to(dvc)
q_vals = mdl(st)
nxt_q_vals = tgt_mdl(nxt_st)
q_val = q_vals.gather(1, act.unsqueeze(-1)).squeeze(-1)
nxt_q_val = nxt_q_vals.max(1)[0]
exp_q_val = rwd + gm * nxt_q_val * (1 - fin)
loss = (q_val - exp_q_val.data.to(dvc)).pow(2).mean()
loss.backward()(2) 神经网络架构和损失函数定义完成后,定义模型更新函数,在每次神经网络训练迭代时调用:
python
def upd_grph(mdl, tgt_mdl, opt, rpl_bfr, dvc, log):
if len(rpl_bfr) > INIT_LEARN:
if not log.idx % TGT_UPD_FRQ:
tgt_mdl.load_state_dict(mdl.state_dict())
opt.zero_grad()
bch = rpl_bfr.smpl(B_S)
calc_temp_diff_loss(mdl, tgt_mdl, bch, G, dvc)
opt.step()该函数会从经验回放缓冲区中随机采样一个数据批次,计算该批次数据的时序差分损失,并且每经过 TGT_UPD_FRQ 次迭代后,将主神经网络权重同步至目标网络。
5. 模型训练
(1) 接下来,定义 ε ε ε-贪婪策略中的 ε ε ε 值。定义回合结束后的 ε ε ε 更新函数,其核心目标是在每个训练回合后线性衰减 ε ε ε 值:
python
def upd_eps(epd):
last_eps = EPS_FINL
first_eps = EPS_STRT
eps_decay = EPS_DECAY
eps = last_eps + (first_eps - last_eps) * math.exp(-1 * ((epd + 1) / eps_decay))
return eps(2) 接下来,定义回合终止时的处理函数。如果当前回合的总奖励是迄今为止获得的最佳奖励,则保存 CNN 模型的权重并打印奖励:
python
def fin_epsd(mdl, env, log, epd_rwd, epd, eps):
bst_so_fat = log.upd_rwds(epd_rwd)
if bst_so_fat:
print(f"checkpointing current model weights. highest running_average_reward of\
{round(log.bst_avg, 3)} achieved!")
save(mdl.state_dict(), f"{env}.dat")
print(f"episode_num {epd}, curr_reward: {epd_rwd}, best_reward: {log.bst_rwd},\
running_avg_reward: {round(log.avg, 3)}, curr_epsilon: {round(eps, 4)}")在每个回合结束时,记录回合编号、当前回合的奖励、最近多轮奖励的移动平均值,以及当前的 ε ε ε 值。
(3) 定义 DQN 循环,即在每个回合中执行的操作步骤步骤:
python
def run_epsd(env, mdl, tgt_mdl, opt, rpl_bfr, dvc, log, epd):
epd_rwd = 0.0
st, _ = env.reset()
while True:
eps = upd_eps(log.idx)
act = mdl.perf_action(st, eps, dvc)
nxt_st, rwd, term, trunc, _ = env.step(act)
fin = term or trunc
rpl_bfr.push(st, act, rwd, nxt_st, fin)
st = nxt_st
epd_rwd += rwd
log.upd_idx()
upd_grph(mdl, tgt_mdl, opt, rpl_bfr, dvc, log)
if fin:
fin_epsd(mdl, ENV, log, epd_rwd, epd, eps)
break每回合开始时,奖励和状态会被重置。随后程序会进入一个无限循环,该循环仅在智能体到达终止状态时才会中断。在这个循环中,每次迭代都会执行以下步骤:
- 首先,按照线性衰减方案调整 ε ε ε 值
- 通过主
CNN模型预测下一动作。执行该动作后将获得新状态及对应奖励,此次状态转移会被记录至经验回放缓冲区 - 将下一状态更新为当前状态,计算时序差分损失用于更新主
CNN模型(目标CNN模型保持冻结) - 如果新的当前状态是终止状态, 则中断循环(即结束本回合),并记录本回合的结果
(4) 为存储与奖励及模型性能相关的各项指标,我们需要定义训练元数据类,该类将包含以下属性指标:
python
class TrMetadata:
def __init__(self):
self._avg = 0.0
self._bst_rwd = -float("inf")
self._bst_avg = -float("inf")
self._rwds = []
self._avg_rng = 100
self._idx = 0在完成模型训练后,我们将利用这些指标对模型性能进行可视化分析。
(5) 将上一步定义的模型评估指标存储为私有成员变量,并通过公开的 Getter 方法提供对外访问接口:
python
@property
def bst_rwd(self):
return self._bst_rwd
@property
def bst_avg(self):
return self._bst_avg
@property
def avg(self):
avg_rng = self._avg_rng * -1
return sum(self._rwds[avg_rng:]) / len(self._rwds[avg_rng:])
@property
def idx(self):
return self._idx
def _upd_bst_rwd(self, epd_rwd):
if epd_rwd > self.bst_rwd:
self._bst_rwd = epd_rwd
def _upd_bst_avg(self):
if self.avg > self.bst_avg:
self._bst_avg = self.avg
return True
return False
def upd_rwds(self, epd_rwd):
self._rwds.append(epd_rwd)
self._upd_bst_rwd(epd_rwd)
return self._upd_bst_avg()
def upd_idx(self):
self._idx += 1idx 属性对于决定何时将权重从主 CNN 复制到目标 CNN 至关重要,而 avg 属性则用于计算过去几回合训练中获得的奖励的移动平均值。
我们已经具备了开始训练 DQN 模型所需的所有要素,接下来开始训练模型。
(6) 定义训练封装函数:
python
def train(env, mdl, tgt_mdl, opt, rpl_bfr, dvc):
log = TrMetadata()
for epd in range(N_EPDS):
run_epsd(env, mdl, tgt_mdl, opt, rpl_bfr, dvc, log, epd)具体实现上,我们首先初始化日志记录器,然后运行 DQN 训练系统完成预设训练回合数。
(7) 在正式启动训练循环前,需设定以下超参数值:
- 每次梯度下降迭代的批大小(用于调优
CNN模型) - 训练环境(本节为
Pong电子游戏) - 第一个回合的 ε ε ε 值
- 最后一个回合的 ε ε ε 值
- ε ε ε 值的衰减率
- 折扣因子 γ γ γ
- 最初预留的迭代次数,用于将数据推送到经验回放缓冲区
- 学习率
- 经验回放缓冲区的容量大小
- 训练智能体的总回合数
- 从主
CNN复制权重到目标CNN的间隔迭代次数
实例化以上超参数:
python
B_S = 64
ENV = "ALE/Pong-v5"
EPS_STRT = 1.0
EPS_FINL = 0.005
EPS_DECAY = 100000
G = 0.99
INIT_LEARN = 10000
LR = 1e-4
MEM_CAP = 20000
N_EPDS = 5000
TGT_UPD_FRQ = 1000我们可以修改超参数值,并观察它们对结果的影响。
(8) 执行 DQN 训练流程:
- 首先初始化游戏环境实例
- 根据硬件条件(
CPU/GPU可用性)设定训练设备 - 实例化主
CNN模型与目标CNN模型,并定义Adam作为优化器 - 实例化经验回放缓冲区
- 最后,训练主
CNN模型,一旦训练过程完成,关闭已实例化的环境
python
env = wrap_env(ENV)
dvc = torch.device("cuda") if torch.cuda.is_available() else torch.device("cpu")
mdl, tgt_mdl = models_init(env, dvc)
opt = Adam(mdl.parameters(), lr=LR)
rpl_bfr = RepBfr(MEM_CAP)
train(env, mdl, tgt_mdl, opt, rpl_bfr, dvc)
env.close()输出结果如下所示:
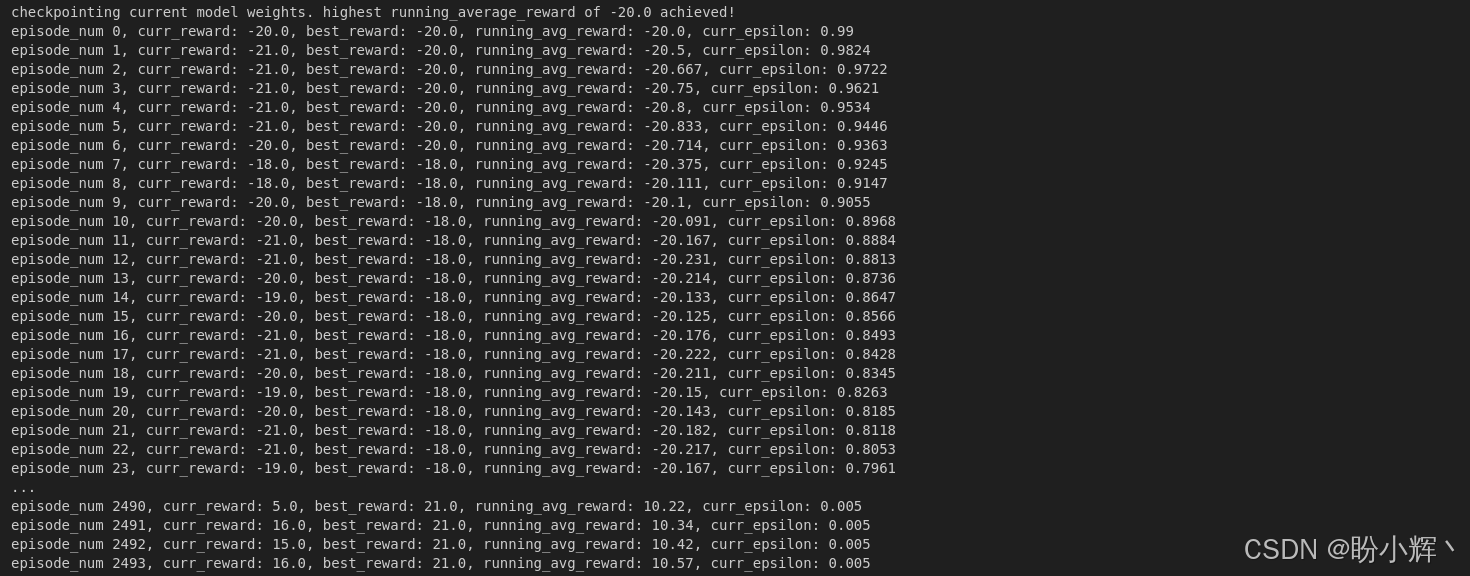
下图显示了当前奖励、最佳奖励和平均奖励在回合进程中的变化:
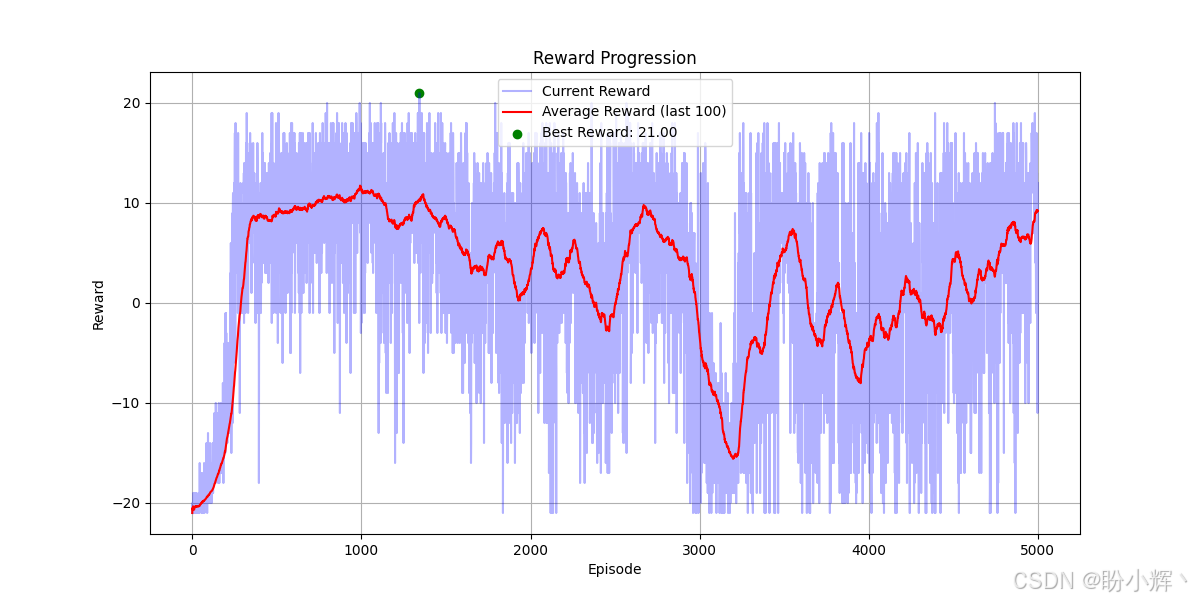
下图显示了在训练过程中 epsilon 值随回合的减少情况:
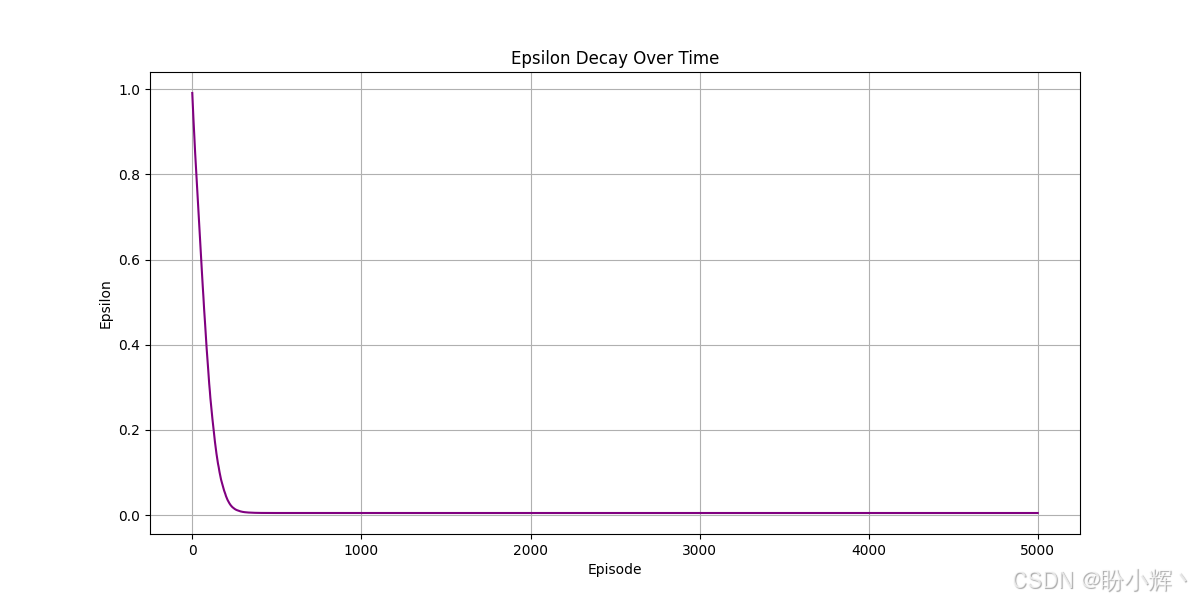
训练过程中,回合中的奖励的运行平均值(红色曲线)从 -20 开始,这意味着智能体在一局游戏中得分为 0,而对手得了 20 分。随着回合的进行,平均奖励不断增加,到第 200 回合时,平均奖励越过了零值。这意味着在经过 200 回合的训练后,智能体已达到与对手势均力敌的水平。此后平均奖励转为正值,表明智能体开始占据上风。训练到第 1000 回合时,智能体平均每局已能领先对手 7 分以上。我们可以训练更长时间,观察智能体是否能实现完全压制。我们已经完成了对 DQN 模型的深入探讨。在本节中,我们实现了 DQN 模型,但本节介绍的思想方法同样适用于其他Q学习变体及深度强化学习算法。
小结
深度Q网络 (Deep Q-learning Network, DQN)在强化学习领域取得了巨大的成功和广泛的应用,PyTorch 结合 gymnasium 库为我们提供了强大的工具,支持在各种强化学习环境中测试不同类型的深度强化学习模型。在本节中,我们使用 PyTorch 框架构建使用卷积神经网络架构的 DQN 模型,模型通过自主学习掌握 Atari 经典游戏《Pong》的操作策略,最终实现击败电脑对手的竞技目标。
系列链接
PyTorch实战(1)------深度学习(Deep Learning)
PyTorch实战(2)------使用PyTorch构建神经网络
PyTorch实战(3)------PyTorch vs. TensorFlow详解
PyTorch实战(4)------卷积神经网络(Convolutional Neural Network,CNN)
PyTorch实战(5)------深度卷积神经网络
PyTorch实战(6)------模型微调详解
PyTorch实战(7)------循环神经网络
PyTorch实战(8)------图像描述生成
PyTorch实战(9)------从零开始实现Transformer
PyTorch实战(10)------从零开始实现GPT模型
PyTorch实战(11)------随机连接神经网络(RandWireNN)
PyTorch实战(12)------图神经网络(Graph Neural Network,GNN)
PyTorch实战(13)------图卷积网络(Graph Convolutional Network,GCN)
PyTorch实战(14)------图注意力网络(Graph Attention Network,GAT)
PyTorch实战(15)------基于Transformer的文本生成技术
PyTorch实战(16)------基于LSTM实现音乐生成
PyTorch实战(17)------神经风格迁移
PyTorch实战(18)------自编码器(Autoencoder,AE)
PyTorch实战(19)------变分自编码器(Variational Autoencoder,VAE)
PyTorch实战(20)------生成对抗网络(Generative Adversarial Network,GAN)
PyTorch实战(21)------扩散模型(Diffusion Model)
PyTorch实战(22)------MuseGAN详解与实现
PyTorch实战(23)------基于Transformer生成音乐
PyTorch实战(24)------深度强化学习