哇 第一次接触带CDN的网站部署,好好玩。
Github Actions
在项目的主目录中新建一个.github/workflows/deploy.yml文件
大概长这样:
yml
name: Deploy to Volcengine TOS
on: # 触发条件
push:
branches:
- main # 或者是你的主分支名称
jobs: # 在什么机器上跑+环境变量
build-and-deploy:
runs-on: ubuntu-latest
env:
# Build-time env for Vite (optional)
VITE_API_BASE_URL: ${{ secrets.VITE_API_BASE_URL }}
# Volcengine TOS (S3-compatible) deploy config
TOS_BUCKET: ${{ secrets.TOS_BUCKET }}
TOS_REGION: ${{ secrets.TOS_REGION }}
TOS_ENDPOINT: ${{ secrets.TOS_ENDPOINT }}
# Credentials
AWS_ACCESS_KEY_ID: ${{ secrets.VOLC_AK }}
AWS_SECRET_ACCESS_KEY: ${{ secrets.VOLC_SK }}
AWS_EC2_METADATA_DISABLED: "true"
steps:
- name: Checkout code
uses: actions/checkout@v4
- name: Set up Node.js
uses: actions/setup-node@v4
with:
node-version: "20"
cache: "npm"
- name: Install dependencies
run: npm ci
- name: Build project
run: npm run build
env:
VITE_API_BASE_URL: ${{ secrets.VITE_API_BASE_URL }} # 如果有生产环境 API 地址
- name: Sanity check build output contains API base # 防止把 localhost 打进生产
run: |
echo "Check if build still contains localhost:"
grep -R "127.0.0.1:8080" -n dist/ && exit 1 || echo "OK: localhost not found"
- name: Upload Vite build output (dist/) to TOS
run: |
aws s3 sync dist/ "s3://${TOS_BUCKET}/" \
--endpoint-url "$TOS_ENDPOINT" \
--region "$TOS_REGION" \
--delete
# --delete 会删除远程桶中本地不存在的文件,确保完全同步
- name: Configure Static Website Hosting
run: |
aws s3 website "s3://${TOS_BUCKET}/" \
--index-document index.html \
--error-document index.html \
--endpoint-url "$TOS_ENDPOINT" \
--region "$TOS_REGION" \
# 说明:
# 配置 TOS 桶为静态网站托管模式
# index-document: index.html (默认首页)
# error-document: index.html (SPA 应用路由所需的 fallback)SPA(Single Page Application)
浏览器只加载一次 index.html,之后所有页面切换都在前端完成。同一个 index.html + 不同 JS 渲染结果得到不同的页面。
文件里的环境变量在github secrets里配。VOLC_AK是火山引擎的api access key,VOLC_SK是secret access key。
这里写的触发条件是push到main分支就自动执行steps里的那些步骤。
桶
创建一个桶(bucket)做对象存储。
对象存储(object storage)有点像网盘。传统数据库有records、table结构,对象存储存的对象由key(名字)、data(内容)和metadata构成。这些对象被放在桶里,可以通过http访问。上述配置文件中的endpoint是S3 兼容 Endpoint,是给 AWS S3 CLI / SDK 用的(啊啊啊这里我没有很懂,先写着);还有一个Bucket 域名,是给浏览器、CDN回源访问用的。Endpoint 只知道"你要用 TOS",Bucket 域名 才知道"你要的是哪个桶"。
CDN
老天鹅啊终于讲到了内容分发网络(Content Deliverty Network, CDN)。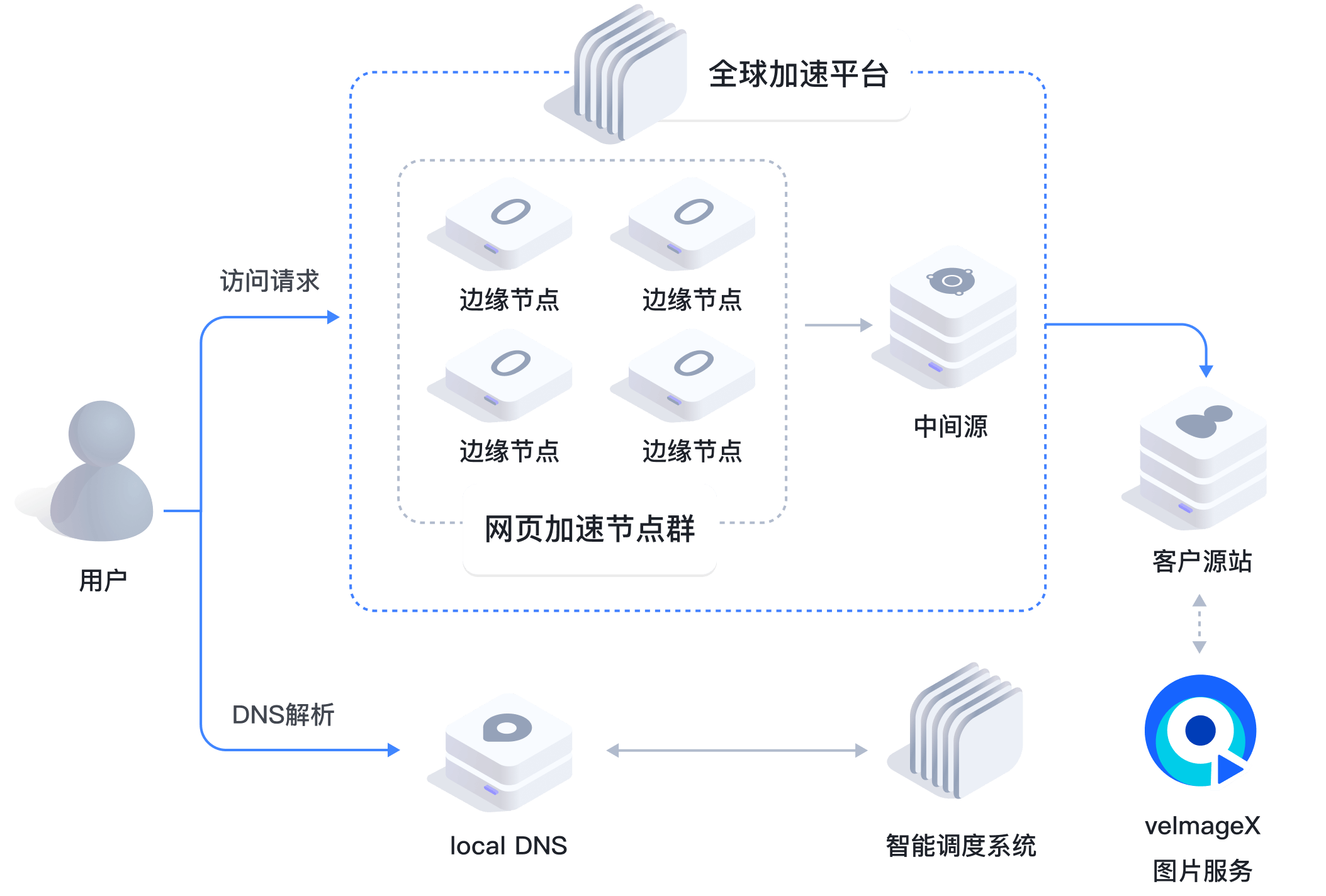
(图片来自火山引擎)
原来CDN的作用是把对源站的HTTP请求的响应提前缓存到离用户比较近的边缘节点,如果请求找不到缓存再打到源站。所以需要一个回源host,就是缓存没有资源从源站请求资源时要去哪里。
这里有一个很好玩的bug。我最开始在github secrets里面把后端的base api写成本地的了,改过来之后还不能直接rerun job,因为直接rerun还是会读旧的环境变量。然后我提交了一个空commit (加上--allow-empty)来触发workflow。(也有可能不是这个问题,因为后面还有bug orz)。
结果还是没有更新,这个时候curl是通的,但是浏览器console还是现实之前的本地api。
这个时候对比curl的包和浏览器拿到的包
bash
% curl -s http://admin.muyulab.com/index.html | grep -Eo '/assets/index-[^"]+\.js'
/assets/index-CaFYC_R-.js我才知道原来浏览器console可以直接执行命令,而不是只能在代码里console.log orz
> [...document.scripts].map(s => s.src).filter(Boolean)
> [
"http://admin.muyulab.com/assets/index-C0Ov5svQ.js"
]发现他俩抓的包不是一个。清浏览器storage也没用。
原来是要清CDN的缓存...火山引擎的内容分发网络页面下有一个刷新预热,可以在那里操作。
在yaml里面配置 --cache-control "no-cache, max-age=0"是规定源站的表现,即不管谁来取(CDN/直连/curl)都没有缓存。
而在CDN控制台配置缓存配置的是CDN的缓存。
老天鹅呀第一次搞带对象存储和CDN的部署,好多概念都不懂,没想到写这篇这么艰难orz 边写边查,涉及到的小点我全没见过orz 呜呜呜呜呜累了。