0. 前言
既然想做这个,用什么模型呢?Yolo 模型在图像识别领域使用起来还是挺方便的,之前工作中就接触过 yolo 5 模型,去官网一看,现在都已经到 yolo 26 了,本着学新不学旧的原则,而且看起来 yolo 26 相比较于之前的模型,在识别准确率方便有着明显的优势,而且在边缘计算方便做了很大的优化,很适合在手机端部署。
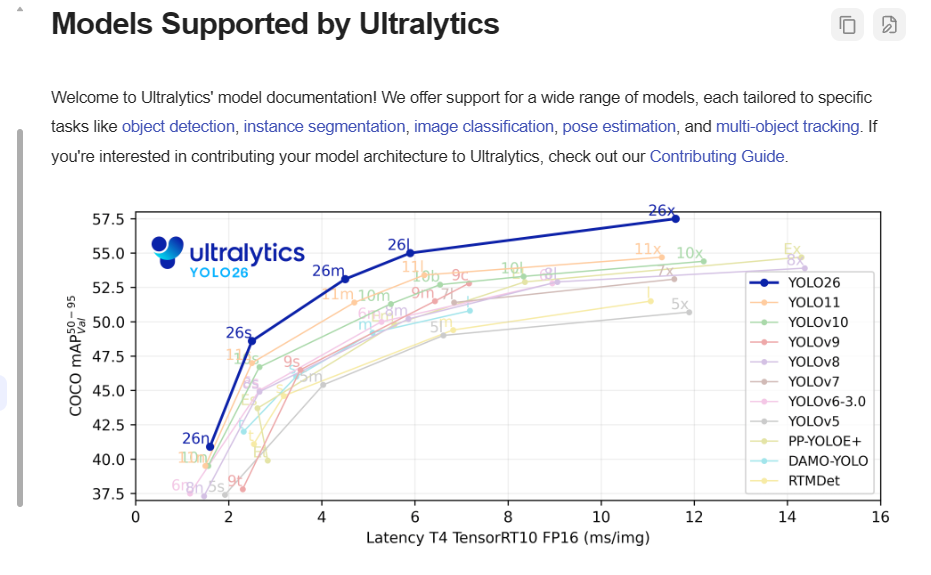
模型的分类
yolo 提供了多种不同类型的模型,适用于不同的场景。具体的模型类别 yolo 管网都有详细的描述。这里只简单概述。

- YOLO 26 ,图像识别,用于探测图像中存在有那些类别的物体,包括物体的边界框坐标
- YOLO 26-seg,图像分割,识别图像中不同物体的边缘,进行图像分割
- YOLO 26-pose, 人姿态识别,识别图像中的人体姿态,进行人体姿态识别
- YOLO 26-obb, 定向边界框对象监测,允许边框旋转以更紧密地匹配物体的形状
- YOLO 26-cls, 用于识别图像中存在有那些类别的物体,但是不包括物体的边界框坐标
每种类型的模型,都提供了不同参数的模型,从n、s、m、b,分别对应不同的模型大小和准确率。
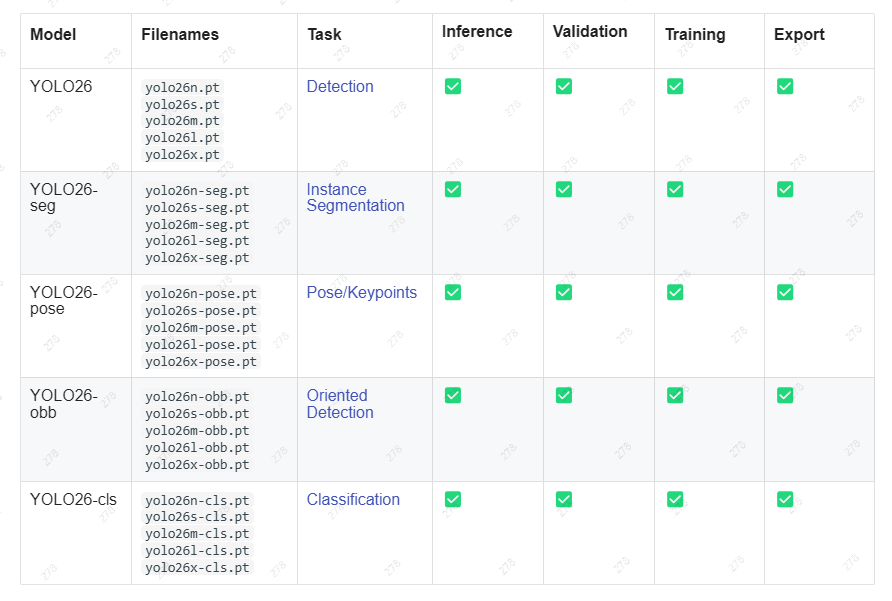
我这里想做的是物体检测,受限于手机端的性能,从官方图中来看,选择 yolo26s 模型比较合适,相比较于yolo26n模型,参数没有增加多少,但是准确率上升了很多。
1. 生成 Android 可调用的 TFLite 文件
首先,手机端是没办法直接使用 yolo 模型的,需要将 yolo 模型转换为 tflite 模型,通过 TensorFlow Lite 框架进行调用。所以我们需要你将 yolo 的 pt 模型文件转换为 tflite 模型文件。
好在,yolo 提供了非常方便的模型转换工具,直接几行代码就可以搞定,之前尝试用各种工具转换,耗时两天未成功,遗憾没有早发现这个方法。
注意事项
- 一定要使用一个新的 python 环境,因为编译过程中会出现各种莫名其妙的版本匹配不上的问题
- 一定要在 Linux 下面编译,某些 python 库只在 linux 下可用,比如 ai-edge-litert,别问我怎么知道的,说多了都是泪啊。
- 安装使用 python 3.10,低于 python 3.10 有些库没法使用
安装 Yolo 与 tensorflow
sh
pip install ultralytics -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tensorflow==2.19.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
python
from ultralytics import YOLO
model = YOLO("yolo26s.pt")
model.export(format="tflite")2. Android 整合 tflite 模型
添加 TensorFlow 依赖
在 build.gradle.kts 中添加 TFLite 依赖
libs.versions.toml
toml
[versions]
tensorflowLite = "2.17.0"
tensorflowLiteSupport = "0.5.0"
tensorflowLiteGpu = "2.17.0"
litertGpuApi = "1.4.1"
[libraries]
tensorflow-lite-gpu = { module = "org.tensorflow:tensorflow-lite-gpu", version.ref = "tensorflowLiteGpu" }
tensorflow-lite-support = { module = "org.tensorflow:tensorflow-lite-support", version.ref = "tensorflowLiteSupport" }
tensorflow-lite = { module = "org.tensorflow:tensorflow-lite", version.ref = "tensorflowLite" }
litert-gpu-api = { group = "com.google.ai.edge.litert", name = "litert-gpu-api", version.ref = "litertGpuApi" }build.gradle.kts
kts
dependencies {
// TFLite核心库
implementation(libs.tensorflow.lite)
// TFLite支持库(包含图像处理)
implementation(libs.tensorflow.lite.support)
// 可选:GPU加速(需要对应设备支持)
implementation(libs.tensorflow.lite.gpu)
implementation(libs.litert.gpu.api)
}配置模型
将生成好的 tflite 模型放在 assets 目录下,如下图所示:
yolo 会生成两种类型的文件,float32 和 float16, float32 要比 float16 模型大一倍,问了 ai 这两个就是数值精度不同,准确率几乎差别不大,除非是用于很精细识别的情形下才需要考虑使用 float32 的模型,所以这里我选择了 float16 的模型。
创建推测模型类
tensorflow 通过 Interpreter 加载 tflite 模型,通过 Interpreter 的 run 方法运行模型。
TfLiteDetectModel.kt
kotlin
object TfLiteDetectModel {
private const val TAG = "TfLiteModelHelper"
private const val MODEL_PATH = "yolo26s_float16.tflite"
private const val INPUT_SIZE = 640
private const val CONF_THRESHOLD = 0.5f // 置信度阈值(过滤低置信度结果)
// 模型
private lateinit var mTfLite: Interpreter
// yolo26 使用 COCO 数据集80个类别上进行训练
private lateinit var COCO_CLASSES: List<Classes>
// 加载类别数据,英文,中文
private fun loadClasses(context: Context) : List<Classes> {
context.assets.open("classes.csv").use {
val csvReader = it.bufferedReader()
val lines = csvReader.readLines()
return lines.map { line ->
val split = line.split(",")
Classes(
us = split[0],
cn = split[1]
)
}
}
}
fun init(context: Context) {
COCO_CLASSES = loadClasses(context)
try {
// 加载模型
val mappedFile = FileUtil.loadMappedFile(context, MODEL_PATH)
val options = Interpreter.Options()
val compatibilityList = CompatibilityList()
// 如果GPU可用的话,使用GPU
if (compatibilityList.isDelegateSupportedOnThisDevice) {
val gpuDelegate = GpuDelegate(compatibilityList.bestOptionsForThisDevice())
options.addDelegate(gpuDelegate)
} else {
options.setNumThreads(4)
}
mTfLite = Interpreter(mappedFile, options)
Log.d(TAG, "init: model $MODEL_PATH init success")
} catch (e: Exception) {
Log.e(TAG, "init: model $MODEL_PATH init failed : ${e.message}")
e.printStackTrace()
}
}
/**
* 预处理图像
*/
suspend fun preProcessImage(bitmap: Bitmap): TensorImage {
val processor = ImageProcessor.Builder()
// 调整到yolo26需要的尺寸
.add(ResizeOp(INPUT_SIZE, INPUT_SIZE, ResizeOp.ResizeMethod.BILINEAR))
// 归一化
.add(NormalizeOp(0f, 255f))
.build();
// 协程处理图片
return withContext(Dispatchers.IO) {
val tensorImage = TensorImage(DataType.FLOAT32)
tensorImage.load(bitmap)
return@withContext processor.process(tensorImage)
}
}
/**
* 监测图片
*/
suspend fun detect(bitmap: Bitmap): List<DetectionResult> {
if (!::mTfLite.isInitialized) {
return emptyList()
}
// 预处理图片
val tensorImage = preProcessImage(convertToArgb8888IfNeeded(bitmap))
// 构建输出
val outputShape = mTfLite.getOutputTensor(0).shape()
val output = Array(outputShape[0]) {
Array(outputShape[1]) {
FloatArray(outputShape[2])
}
}
// 执行推理
mTfLite.run(tensorImage.buffer, output)
return postProcess(output)
}
/**
* 处理结果
*/
private suspend fun postProcess(output: Array<Array<FloatArray>>): List<DetectionResult> {
val results = mutableListOf<DetectionResult>()
withContext(Dispatchers.Default) {
val detections = output[0]
// 结果 [left, top, right, bottom, objConf, classId]
for (det in detections) {
val objConf = det[4] // 目标存在置信度
if (objConf < CONF_THRESHOLD) continue
val classId = det[5]
// 解析检测框
val cx = det[0]
val cy = det[1]
val cx2 = det[2]
val cy2 = det[3]
results.add(
DetectionResult(
classType = COCO_CLASSES[classId.toInt()],
confidence = objConf,
boundingBox = RectF(cx, cy, cx2, cy2)
)
)
}
}
return results
}
private fun convertToArgb8888IfNeeded(bitmap: Bitmap): Bitmap {
// 图片处理必须是ARGB_8888类型
if (bitmap.config == Bitmap.Config.ARGB_8888) {
return bitmap
}
// 使用copy方法,自动处理硬件位图问题
return bitmap.copy(Bitmap.Config.ARGB_8888, true)
}
}3. 调用手机摄像头拍摄图像
如何调用手机摄像头获取图像的内容可以参考 \[Compose调用系统相机] 这篇文章,里面有清晰的步骤,这里直接使用获取到的图像。
4. 调用模型并绘制结果
我们自定义一个组件,使用 Canvas 来绘制图片,绘制监测到的图片框以及类别名称。
该自定义组件具备一下几个特点:
- 根据图片尺寸和组件尺寸自动缩放图片
- 图片传入后,自动调用模型进行图像识别
- 识别过程中显示加载中
- 识别完成后,绘制识别框与文字
定义组件
组件传入图片、为了方便扩展,将模型也放到组件参数中,识别到结果后的回调函数,方便把识别结果提供给父组件。
DetectImageView.kt
kotlin
@Composable
fun DetectImageView(
bitmap: Bitmap,
modifier: Modifier = Modifier,
model: TfLiteDetectModel = TfLiteDetectModel,
onResult: (List<DetectionResult>) -> Unit = {}
) {
Canvas(
modifier = modifier
.padding(10.dp)
// 圆角背景
.background(Color.White, RoundedCornerShape(10.dp)),
) {
// 绘制内容
}
}绘制图片
绘制图片调用 drawImage,为了让图片自适应组件大小,需要根据组件的大小和图片的大小进行缩放。
kotlin
@Composable
fun DetectImageView(...) {
Canvas(..) {
val canvasWidth = size.width
val canvasHeight = size.height
val bitmapWidth = bitmap.width.toFloat()
val bitmapHeight = bitmap.height.toFloat()
// 计算缩放比例,确保图片完全显示在Canvas内
val scale = minOf(
canvasWidth / bitmapWidth,
canvasHeight / bitmapHeight
)
// 计算缩放后的图片尺寸
val scaledWidth = (bitmapWidth * scale).toInt()
val scaledHeight = (bitmapHeight * scale).toInt()
// 计算居中偏移量
val offsetX = ((canvasWidth - scaledWidth) / 2f).toInt()
val offsetY = ((canvasHeight - scaledHeight) / 2f).toInt()
// 绘制图片
drawImage(
image = bitmap.asImageBitmap(),
dstSize = IntSize(scaledWidth, scaledHeight),
dstOffset = IntOffset(offsetX, offsetY)
)
}
}绘制模型结果
绘制模型结果需要调用模型,调用模型是一个耗时方法,我们需要将它放到协程中执行。
kotlin
@Composable
fun DetectImageView(...,onResult: (List<DetectionResult>) -> Unit = {}) {
// 存放模型结果
var res: List<DetectionResult> by remember { mutableStateOf(emptyList()) }
// 是否正在加载模型结果
var isLoading by remember { mutableStateOf(false) }
// 测量文字
val textMeasurer = rememberTextMeasurer()
// 模型成功后的回调
val resultCallback by rememberUpdatedState(onResult)
// 调用模型,这里使用bitmap为键,只要图片该表,就重新调用模型
LaunchedEffect(bitmap) {
isLoading = true
res = model.detect(bitmap)
isLoading = false
// 调用回调向组件外传输模型调用后的结果
resultCallback(res)
}
Canvas(..) {
// ... 绘制图片逻辑
// 绘制结果
drawBounds(textMeasurer, res, offsetX, offsetY, scaledWidth, scaledHeight)
}
}
/**
* 绘制检测结果
* @param res 检测结果
* @param offsetX 图片在Canvas中的X轴偏移量
* @param offsetY 图片在Canvas中的Y轴偏移量
* @param scaledWidth 图片缩放后的宽度
* @param scaledHeight 图片缩放后的高度
*/
private fun DrawScope.drawBounds(
textMeasurer: TextMeasurer,
res: List<DetectionResult>,
offsetX: Int, offsetY: Int,
scaledWidth: Int, scaledHeight: Int
) {
// 绘制检测结果
res.forEach { detectionResult ->
// 计算边框位置
val left = offsetX + detectionResult.boundingBox.left * scaledWidth
val top = offsetY + detectionResult.boundingBox.top * scaledHeight
val right = offsetX + detectionResult.boundingBox.right * scaledWidth
val bottom = offsetY + detectionResult.boundingBox.bottom * scaledHeight
drawRect(
style = Stroke(width = 5f),
color = Color.Red, topLeft = Offset(
left,
top
), size = Size(
right - left,
bottom - top
)
)
val layoutResult = textMeasurer.measure(detectionResult.classType.cn)
drawText(
layoutResult,
color = Color.Red,
topLeft = Offset(left, top - layoutResult.size.height)
)
}
}这里的返回结果回调使用了 rememberUpdatedState,这是因为模型是在协程中调用,为了防止回调方法被修改后导致的问题,使用 rememberUpdatedState 保持回调的最新引用。具体详情可以参考\[用rememberUpdatedState解决Compose协程中的"旧回调"问题] 这篇文章。
绘制加载中
加载中比较难绘制,Compose 是状态决定组件,状态不改变,组件显示行为就不会改变,所以我们得需要让加载内容动起来就需要不停地修改加载内容的状态。
kotlin
@Composable
fun DetectImageView(...) {
// 记录加载中的圆环角度
var loadingRotation by remember { mutableFloatStateOf(0f) }
// 监听isLoading状态,只要isLoading改变,就启动协程,不断修改圆环角度
LaunchedEffect(isLoading) {
while (isLoading) {
loadingRotation += 5f
if (loadingRotation >= 360f) {
loadingRotation = 0f
}
delay(10)
}
}
Canvas(..) {
// 如果正在加载,显示加载内容
if(isLoading) run {
// 绘制loading圆环
drawLoading(canvasWidth, canvasHeight, loadingRotation)
// 绘制遮罩
drawRect(
color = Color.Gray.copy(alpha = 0.5f),
size = size
)
}
}
}
/**
* 绘制加载中
*/
private fun DrawScope.drawLoading(canvasWidth: Float, canvasHeight: Float, rotation: Float = 0f) {
// 绘制不停转圈的图标
val centerX = canvasWidth / 2f
val centerY = canvasHeight / 2f
val radius = 30f
val strokeWidth = 8f
// 绘制背景圆
drawCircle(
color = Color.Gray.copy(alpha = 0.3f),
radius = radius,
center = Offset(centerX, centerY),
style = Stroke(width = strokeWidth)
)
// 绘制旋转的弧形
drawArc(
color = Color.Blue,
startAngle = rotation,
sweepAngle = 90f,
useCenter = false,
topLeft = Offset(centerX - radius, centerY - radius),
size = Size(radius * 2, radius * 2),
style = Stroke(width = strokeWidth, cap = Stroke.DefaultCap)
)
}5. 页面中整合组件
MainActivity.kt
在页面中使用就比较简单了,直接引用就可以了
kotlin
@Composable
fun MainContentView() {
var capturedImageBitmap by remember { mutableStateOf<Bitmap?>(null) }
var res by remember { mutableStateOf(listOf<DetectionResult>()) }
// 调用相机获取图片, 此内容参考 Compose中调用相机文章
if (capturedImageBitmap != null) {
Column(modifier = Modifier.padding(innerPadding)) {
Card(
modifier = Modifier
.weight(1.0f)
.padding(16.dp)
.fillMaxSize(),
) {
DetectImageView(
capturedImageBitmap!!,
modifier = Modifier.fillMaxSize()
) {
res = it
}
}
Column(
modifier = Modifier
.verticalScroll(rememberScrollState())
.heightIn(0.dp, 200.dp)
) {
Text(
"识别结果",
modifier = Modifier.padding(horizontal = 16.dp),
style = MaterialTheme.typography.titleLarge
)
FlowRow(
modifier = Modifier.padding(16.dp),
horizontalArrangement = Arrangement.spacedBy(8.dp)
) {
for (detectionResult in res) {
ElevatedAssistChip(onClick = {}, label = {
Text(text = detectionResult.classType.cn)
})
}
}
}
}
}
}最终结果如下:

6.后续计划
仅仅整合进来 yolo 的模型是远远不够的,目前 yolo 仅可以识别 80 种类别的物品,如何让 yolo 识别其他没见过的物品才是模型可以使用的关键。所以后续计划有两个:
- 研究如何在手机端对模型进行训练,针对没见过的图片进行专项训练
- yolo 还有一个 yoloe 模型,意为分割一切模型,不过转 tffile 没转成功,研究一下如何转换,利用 yoloe 在手机端分割图像,分割后形成样本,进行训练。