一. 主从复制架构简要回顾
MySQL 主从复制基于二进制日志(binlog)实现。主库将事务写入 binlog,从库通过 I/O 线程拉取 binlog 并写入中继日志(relay log),再由 SQL 线程重放事务。
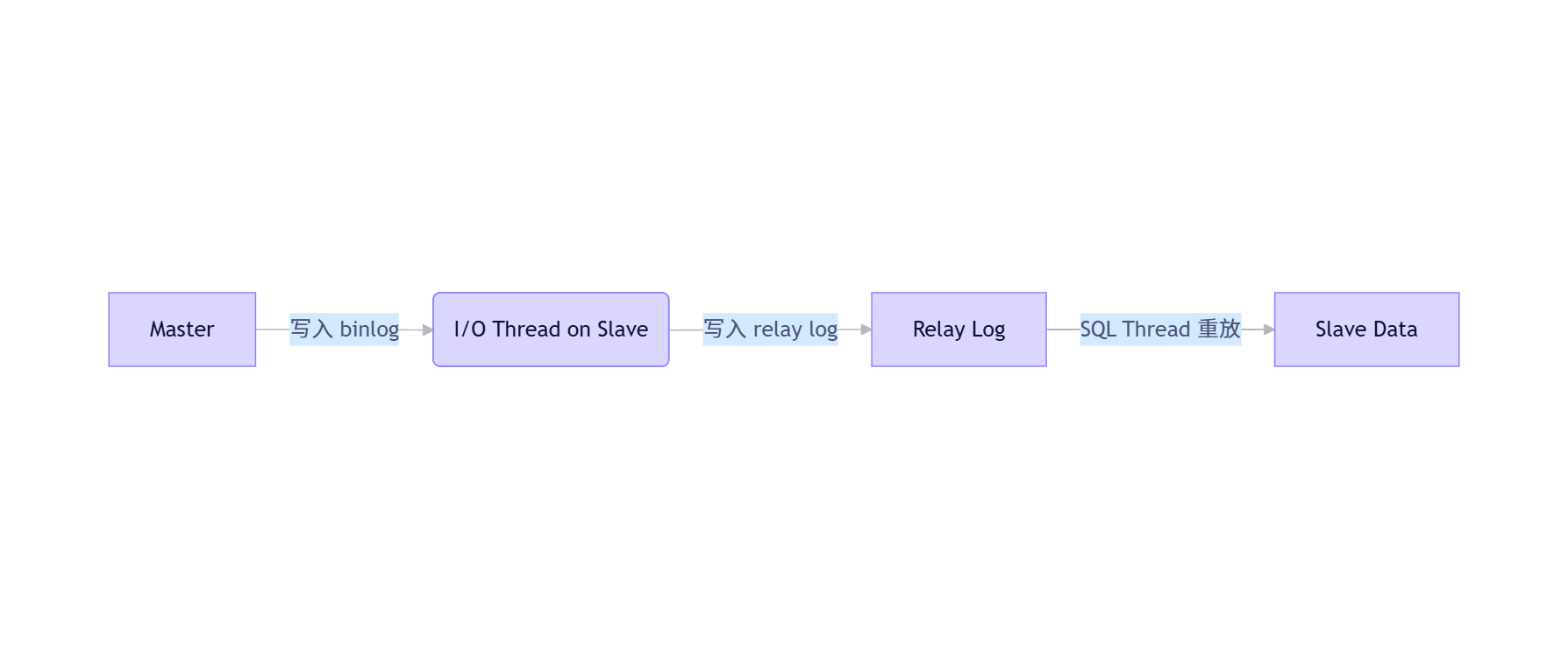
在 MySQL 8.0 中,默认启用 GTID(Global Transaction Identifier),使得复制更加健壮,支持自动定位事务位置,简化故障切换。
二. 主从复制常见问题详解
1. 复制延迟(Replication Lag)------通用场景
- 现象 :
Seconds_Behind_Master持续增大。 - 常见原因 :
- 从库硬件性能不足(CPU/IO 瓶颈)
- 未启用并行复制(
slave_parallel_workers = 0) - 主库并发写入过高
但延迟的具体诱因远不止于此。
主库执行 DELETE 导致从库严重延迟
当主库执行大范围 DELETE(如清理历史日志表),从库可能出现数小时甚至数天的延迟。原因如下:
| 原因 | 说明 |
|---|---|
| 单事务过大 | 删除百万行生成超大 binlog event,从库 SQL 线程串行回放,无法并行 |
| ROW 格式开销高 | binlog_format=ROW 下,每行删除记录完整前镜像,binlog 体积暴增 |
| 从库 IO/CPU 瓶颈 | 回放时触发大量索引更新、undo purge,消耗资源 |
| 并行复制失效 | 即使开启并行,单事务仍强制串行执行 |
| 锁竞争 | 从库有慢查询持有表锁,阻塞 SQL 线程 |
优化建议:
sql
-- 拆分大 DELETE 为小批次
DELETE FROM logs WHERE create_time < '2020-01-01' LIMIT 10000;
-- 循环执行 + sleep(0.1s),避免主库压力激增同时确保:
binlog_format = ROWslave_parallel_type = LOGICAL_CLOCKslave_parallel_workers = CPU 核数
其他 5 种易被忽视的复制延迟场景
(1) 主库频繁执行 DDL(如 ALTER TABLE)
- DDL 在从库单线程执行,可能重建整表。
- 对策 :使用在线 DDL(
ALGORITHM=INPLACE, LOCK=NONE),避开业务高峰。
(2) 使用 MyISAM 表
- MyISAM 无事务,每条语句单独写 binlog,且从库回放需加表锁。
- 对策:全面迁移到 InnoDB。
(3) 从库开启审计插件或慢日志
- 额外日志写入拖慢 SQL 线程。
- 对策:从库关闭非必要插件,或降低日志级别。
(4) 主从服务器时间不同步
- 导致
Seconds_Behind_Master计算失真,掩盖真实延迟。 - 对策 :主从均配置 NTP 同步,设置相同
time_zone。
(5) relay log 过度同步(sync_relay_log=1)
- 默认每次写 relay log 都刷盘,I/O 成瓶颈。
- 对策 :设
sync_relay_log = 1000(权衡 RPO 与性能)。
2. I/O 或 SQL 线程停止
- 现象 :
Slave_IO_Running或Slave_SQL_Running为No - 原因:binlog 被 purge、网络中断、权限错误、GTID 冲突
- 诊断 :查看
Last_IO_Error/Last_SQL_Error - 解决:重建从库、修复权限、GTID 模式下注入空事务
3. 主从数据不一致
- 原因 :从库被写入、非确定性函数、
STATEMENT格式 - 对策 :
read_only=ON+binlog_format=ROW
4. GTID 冲突或不连续
- 原因:手动在从库写入、切换流程错误
- 对策 :禁止从库写入,切换前校验
gtid_executed
5. Binlog 格式不兼容
- 对策 :主从统一设为
ROW
6. 主库 Binlog 被提前清理
- 对策 :延长
expire_logs_days,监控 binlog 使用量
7. 半同步复制退化为异步
- 监控 :
SHOW STATUS LIKE 'Rpl_semi_sync%'
8. 多源复制通道冲突
- 对策 :每个主库使用独立 channel,确保
server_uuid唯一
9. Relay Log 损坏
- 解决 :
RESET SLAVE+ 重新CHANGE MASTER TO
10. 字符集/时区不一致
- 影响:隐性数据错乱(如中文乱码、时间偏移)
- 对策:主从全局配置对齐
三. 问题对比
| 问题类型 | 典型症状 | 根本原因 | 解决复杂度 |
|---|---|---|---|
| 大 DELETE 延迟 | Seconds_Behind_Master 暴涨 |
单事务过大、ROW 格式开销 | 中 |
| DDL 延迟 | SQL 线程长时间不动 | ALTER TABLE 重建表 | 中 |
| MyISAM 延迟 | 从库表锁等待高 | 表级锁阻塞 | 高(需迁移引擎) |
| 审计插件延迟 | CPU 高、IO 正常 | 日志写入开销 | 低 |
| 时间不同步 | 延迟值异常波动 | 系统时钟偏差 | 低 |
| I/O 线程停止 | 无法拉取 binlog | 网络/binlog purge | 高 |
| SQL 线程停止 | 事务应用中断 | 数据冲突/GTID 缺失 | 高 |
| GTID 冲突 | 复制报 GTID 错误 | 手动写入/切换错误 | 中 |
解决复杂度:低(配置调整)、中(需代码/流程变更)、高(需重建或数据修复)
四. 最佳实践建议
- 强制从库只读 :
SET GLOBAL read_only = ON; - 统一使用 ROW 格式 :
binlog_format = ROW - 启用 GTID :
gtid_mode = ON,enforce_gtid_consistency = ON - 配置并行复制 :
slave_parallel_workers = 8,slave_parallel_type = LOGICAL_CLOCK - 大操作拆分:DELETE/UPDATE 分批执行
- 监控关键指标 :
Seconds_Behind_MasterRpl_semi_sync_master_statusRelay_Log_Spacereplication_applier_status_by_worker
| 参数/指标 | 作用 | 获取方式 |
|---|---|---|
slave_parallel_type = LOGICAL_CLOCK |
启用基于主库 Group Commit 的并行复制,大幅提升从库回放速度 | SHOW VARIABLES LIKE 'slave_parallel_type'; |
Seconds_Behind_Master |
复制延迟秒数 | SHOW SLAVE STATUS |
Rpl_semi_sync_master_status |
半同步是否生效 | SHOW STATUS LIKE 'Rpl_semi_sync_master_status' |
Relay_Log_Space |
relay log 磁盘占用 | SHOW SLAVE STATUS |
replication_applier_status_by_worker |
并行 worker 详细状态 | performance_schema 表 |
- 定期一致性校验 :
pt-table-checksum
五. 面试题
问题一:
主库执行一个删除 1000 万行的 DELETE,从库延迟飙升,如何优化?
答:
- 将大 DELETE 拆分为小批次(如每次 1 万行 + sleep)
- 确保
binlog_format=ROW+slave_parallel_type=LOGICAL_CLOCK - 从库使用 SSD、增大 buffer pool
- 避免在业务高峰期执行
问题二:
Seconds_Behind_Master = 0 是否代表主从完全同步?
答:不一定。该值仅反映 SQL 线程当前执行事件的时间差。若 I/O 线程尚未拉取最新 binlog,或主库刚提交事务但未写入 binlog,仍可能存在微小延迟。更可靠的方式是比对 GTID 集合是否一致。