二、公共模块
1)将资料目录下的dataset目录整个复制到common包的根目录下
本章节涉及的所有资料均放置在网盘,没有加密没有过期时间
https://pan.quark.cn/s/8483cdcc5e7d
2)将fashion-labels.csv复制到common包的根目录下
3)创建utils.py,写入以下内容
python
# 导入必要的库
import numpy as np # 数值计算库
import os # 操作系统接口库
import torch # PyTorch深度学习框架
import random # 随机数生成库
def seed_everything(seed):
"""
为了保证训练过程可复现,使用确定的随机数种子。对 torch,numpy 和 random 都使用相同的种子。
参数:
- seed: 随机数种子(整数)
"""
random.seed(seed) # 设置Python内置随机数种子
os.environ["PYTHONHASHSEED"] = str(seed) # 设置Python哈希种子
np.random.seed(seed) # 设置NumPy随机数种子
torch.manual_seed(seed) # 设置PyTorch CPU随机数种子
torch.cuda.manual_seed(seed) # 设置PyTorch GPU随机数种子
torch.backends.cudnn.deterministic = True # 确保CuDNN操作确定性
torch.backends.cudnn.benchmark = False # 禁用CuDNN性能优化
三、去噪模块
3.1知识储备
3.1.1自编码器
1)定义
自编码器(Autoencoder) 是一种无监督学习的神经网络模型,主要用于数据的特征提取、降维和重建。其核心思想是通过学习一个高效的编码表示(潜在空间表示),并能够从该表示中重建原始数据。
2)核心结构
自编码器由两个主要部分组成:
(1)编码器(Encoder):
将输入数据压缩为低维的潜在表示(编码)。
目标是捕获输入数据的关键特征。
(2)解码器(Decoder)
从潜在表示重建原始数据。
目标是尽可能准确地还原输入。
3)工作原理
(1)输入数据: 输入数据 x(如图像、文本等)。
(2)编码过程: 编码器将 x 映射为潜在表示 z: z=f(x)
(3)解码过程: 解码器从 z 重建数据 x: x = g(z)
(4)损失函数: 通过最小化重建误差(如均方误差)来优化模型
3.1.2自编码器案例
3.1.2.1架构设计
1)编码器
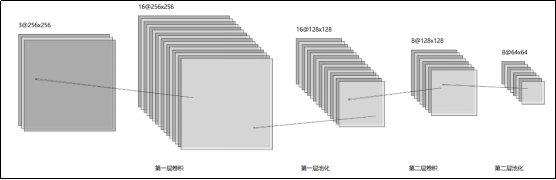
2)解码器

转置卷积:一种用于"上采样"(upsample)的卷积操作,在深度学习中表示为卷积的一个逆向过程,可以根据卷积核大小和输出的大小,恢复卷积前的图像尺寸;有时也称为"反卷积",但需要注意不是恢复原始值,所以并不是数学上的逆运算。
在PyTorch中,提供了"转置卷积层"类ConvTranspose2d,输出的形状可以简单表示为:
OH=H−1·S−2P+KH+OP
OW=W−1·S−2P+KW+OP
其中,OH×OW表示输出的形状,H×W表示输入的形状,KH×KW表示卷积核的形状(kernel_size);S表示步幅,P表示填充;OP表示为了得到卷积前的尺寸而对输出进行的"额外填充"。
3)完整的自编码器架构
3.1.2.2环境准备
1)在项目根目录下创建apple.ipynb
2)将资料目录下的Apple.jpg置于项目根目录下
3.1.2.3编码实现
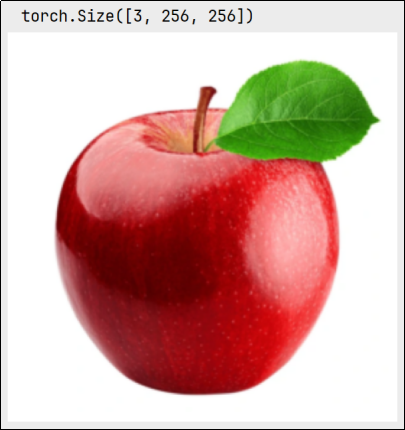
1)Cell1
用于加载原图并展示
(1)代码清单
python
import matplotlib.pyplot as plt # 导入 matplotlib 库,用于图像显示
from PIL import Image # 导入 PIL 库,用于图像加载和处理
import torchvision.transforms as transforms # 导入 torchvision.transforms 模块,用于图像预处理
# 定义图像转换操作
transform = transforms.Compose([
transforms.Resize((256, 256)), # 调整图像大小为 256x256
transforms.ToTensor(), # 将图像转换为 PyTorch 张量
])
# 加载 JPG 图像
img_path = 'Apple.jpg' # 图像文件路径,替换为你的图像路径
image = Image.open(img_path) # 使用 PIL 打开图像
# 应用定义的转换操作
img_tensor = transform(image) # 将图像转换为张量并调整大小
print(img_tensor.shape) # 打印张量的形状,格式为 (C, H, W)
# 将张量转换为 NumPy 数组
img_numpy = img_tensor.numpy() # 将 PyTorch 张量转换为 NumPy 数组,形状为 (C, H, W)
# PoTorch 的图像张量使用 (C, H, W) 格式,而 Matplotlib 的图像显示函数需要 (H, W, C) 格式的数组,需要转换维度
# 调整 NumPy 数组的维度顺序
img_numpy = img_numpy.transpose((1, 2, 0)) # 将形状从 (C, H, W) 转换为 (H, W, C)
# 显示图像
plt.imshow(img_numpy) # 显示调整后的 NumPy 数组
plt.axis('off') # 不显示坐标轴
plt.show() # 显示图像(2)输出
2)Cell2
用于定义模型
(1)代码清单
python
import torch # 导入 PyTorch 库
import torch.nn as nn # 导入 PyTorch 的神经网络模块
import torch.optim as optim # 导入 PyTorch 的优化器模块
# 定义自编码器(Autoencoder)的架构
class Autoencoder(nn.Module):
def __init__(self):
super(Autoencoder, self).__init__() # 调用父类的构造函数,初始化模型
# 编码器部分:将输入图像压缩为低维特征表示
self.encoder = nn.Sequential(
# 第一层卷积:输入通道数为 3(RGB 图像),输出通道数为 16,卷积核大小为 3x3,步长为 1,填充为 1
# 输出尺寸:(16, 256, 256)
nn.Conv2d(3, 16, kernel_size=3, stride=1, padding=1),
nn.ReLU(), # ReLU 激活函数,引入非线性
# 最大池化层:池化核大小为 2x2,步长为 2,将图像尺寸减半
nn.MaxPool2d(kernel_size=2, stride=2),
# 第二层卷积:输入通道数为 16,输出通道数为 8,卷积核大小为 3x3,步长为 1,填充为 1
nn.Conv2d(16, 8, kernel_size=3, stride=1, padding=1),
nn.ReLU(), # ReLU 激活函数
# 最大池化层:池化核大小为 2x2,步长为 2,将图像尺寸再次减半
nn.MaxPool2d(kernel_size=2, stride=2)
)
# 解码器部分:将低维特征表示重构为原始图像
self.decoder = nn.Sequential(
# 第一层转置卷积:输入通道数为 8,输出通道数为 16,卷积核大小为 3x3,步长为 2,填充为 1,输出填充为 1
nn.ConvTranspose2d(8, 16, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.ReLU(), # ReLU 激活函数
# 第二层转置卷积:输入通道数为 16,输出通道数为 3,卷积核大小为 3x3,步长为 2,填充为 1,输出填充为 1
nn.ConvTranspose2d(16, 3, kernel_size=3, stride=2, padding=1, output_padding=1),
nn.Sigmoid() # Sigmoid 激活函数,将输出值限制在 [0, 1] 范围内,表示像素值
)
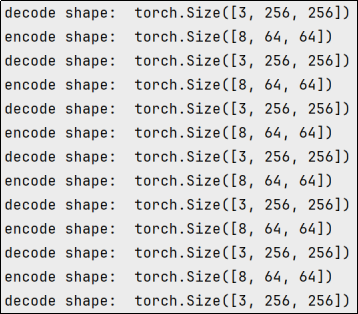
def forward(self, x):
x = self.encoder(x) # 对输入图像进行编码
print("encode shape: ", x.shape)
x = self.decoder(x) # 对编码后的特征进行解码,重构图像
print("decode shape: ", x.shape)
return x
# 初始化自编码器模型
model = Autoencoder()
# 测试模型前向传播
x = model.forward(torch.randn(1, 3, 256, 256))(2)测试

3)Cell3
训练并保存模型
(1)代码清单
python
# 将模型移动到 GPU(如果可用),否则使用 CPU
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
print(device) # 打印当前使用的设备(GPU 或 CPU)
model.to(device) # 将模型参数和缓冲区移动到指定设备
# 定义损失函数和优化器
criterion = nn.MSELoss() # 使用均方误差损失(MSE),衡量重构图像与原始图像的差异
optimizer = optim.Adam(model.parameters(), lr=0.001) # 使用 Adam 优化器,学习率为 0.001
# 训练自编码器
num_epochs = 400 # 训练的总轮数
for epoch in range(num_epochs):
img = img_tensor.to(device) # 将输入图像移动到指定设备
optimizer.zero_grad() # 清空梯度缓存,避免梯度累积
output = model(img) # 前向传播,获取重构图像
loss = criterion(output, img) # 计算损失(重构图像与原始图像的差异)
loss.backward() # 反向传播,计算梯度
optimizer.step() # 更新模型参数
if epoch % 50 == 0: # 每 50 轮打印一次损失值
print('Epoch [{}/{}], Loss: {:.4f}'.format(epoch + 1, num_epochs, loss.item()))
# 保存训练好的模型
torch.save(model.state_dict(), 'conv_autoencoder.pth')(2)测试
4)Cell4
(1)代码清单
python
# 推理阶段不需要梯度计算
# 禁用梯度计算,减少内存消耗并加速推理过程
with torch.no_grad():
# 将图像张量移动到指定设备(GPU 或 CPU)
data = img_tensor.to(device)
# 使用训练好的模型对输入数据进行重构,得到输出张量
recon = model(data)
# 导入 Matplotlib 库,用于图像显示
import matplotlib.pyplot as plt
# 显示重构后的图像
# 1. 将张量从 GPU 移到 CPU(如果张量在 GPU 上)
# 2. 转换为 NumPy 数组
# 3. 调整维度顺序从 (C, H, W) 到 (H, W, C),以适配 Matplotlib 的 imshow 函数
plt.imshow(recon.cpu().numpy().transpose((1, 2, 0)))
# 关闭坐标轴显示,使图像更干净
plt.axis('OFF')
# 渲染并显示图像窗口
plt.show()(2)测试

3.2模型架构
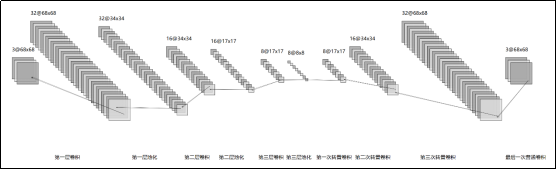
3.3测试
3.3.1环境准备
1)在项目根目录下创建denoising_test.ipynb
3.3.2编码实现
1)Cell1
定义数据处理类
(1)代码清单
python
import torch # 导入PyTorch库,用于深度学习任务
from PIL import Image # 导入PIL库中的Image模块,用于图像处理
import os # 导入os库,用于处理文件和目录路径
from torch.utils.data import Dataset # 从PyTorch的工具库中导入Dataset类,用于自定义数据集
class FolderDataset(Dataset): # 定义一个名为FolderDataset的类,继承自PyTorch的Dataset类
def __init__(self, main_dir, transform=None): # 定义类的构造函数,接受两个参数:main_dir(主目录路径)和transform(图像预处理操作,默认为None)
self.main_dir = main_dir # 将主目录路径保存为类的属性
self.transform = transform # 将图像预处理操作保存为类的属性
self.all_imgs = os.listdir(main_dir) # 获取主目录下的所有文件名,并保存为列表
def __len__(self): # 定义__len__方法,返回数据集中图像的数量
return len(self.all_imgs) # 返回主目录下图像文件的数量
def __getitem__(self, idx): # 定义__getitem__方法,根据索引idx获取图像
img_loc = os.path.join(self.main_dir, self.all_imgs[idx]) # 根据索引idx构建图像的完整路径
image = Image.open(img_loc).convert("RGB") # 使用PIL库打开图像并将其转换为RGB格式
if self.transform is not None: # 如果定义了图像预处理操作
tensor_image = self.transform(image) # 对图像进行预处理,并将其转换为张量
else:
# 若无变换,抛出异常提示必须提供预处理
raise ValueError("transform参数不能为None,需指定预处理方法")
noise_factor = 0.5
## 向输入图像添加随机噪声
# 生成与 tensor_image 形状相同的随机噪声,乘以噪声因子 noise_factor
noisy_imgs = tensor_image + noise_factor * torch.randn(*tensor_image.shape)
# 将图像像素值裁剪到 [0, 1] 范围内,避免超出有效范围
noisy_imgs = np.clip(noisy_imgs, 0., 1.)
return noisy_imgs, tensor_image # 返回预处理后的图像张量(将噪声图片作为输入,将原图作为目标)(2)测试
无输出
2)Cell2
用于定义模型
(1)代码清单
python
import torch.nn as nn
import torch.nn.functional as F
# 定义神经网络架构
class ConvDenoiser(nn.Module):
def __init__(self):
super(ConvDenoiser, self).__init__()
## 编码器层 ##
# 卷积层 (输入通道数从1变为32), 3x3卷积核
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
# 卷积层 (输入通道数从32变为16), 3x3卷积核
self.conv2 = nn.Conv2d(32, 16, 3, padding=1)
# 卷积层 (输入通道数从16变为8), 3x3卷积核
self.conv3 = nn.Conv2d(16, 8, 3, padding=1)
# 池化层,用于将x-y维度减少一半;卷积核和步幅均为2
self.pool = nn.MaxPool2d(2, 2)
## 解码器层 ##
# 转置卷积层,卷积核为2,步幅为2,将空间维度增加2倍
self.t_conv1 = nn.ConvTranspose2d(8, 8, 3, stride=2) # 卷积核大小为3,以得到7x7的图像输出
# 另外两个转置卷积层,卷积核为2
self.t_conv2 = nn.ConvTranspose2d(8, 16, 2, stride=2)
self.t_conv3 = nn.ConvTranspose2d(16, 32, 2, stride=2)
# 最后一个普通的卷积层,用于减少通道数
self.conv_out = nn.Conv2d(32, 3, 3, padding=1)
# forward函数用于向前传播,该函数接受一个输入张量x,并返回一个输出张量,该函数的实现真正决定了神经网络的架构
def forward(self, x):
## 编码 ##
# 添加带有ReLU激活函数的隐藏层
# 并在之后进行最大池化
x = F.relu(self.conv1(x))
print("conv1 shape: ", x.shape)
x = self.pool(x)
print("pool1 shape: ", x.shape)
# 添加第二个隐藏层
x = F.relu(self.conv2(x))
print("conv2 shape: ", x.shape)
x = self.pool(x)
print("pool2 shape: ", x.shape)
# 添加第三个隐藏层
x = F.relu(self.conv3(x))
print("conv3 shape: ", x.shape)
x = self.pool(x) # 压缩表示
print("pool3 shape: ", x.shape)
## 解码 ##
# 添加转置卷积层,带有ReLU激活函数
x = F.relu(self.t_conv1(x))
print("t_conv1 shape: ", x.shape)
x = F.relu(self.t_conv2(x))
print("t_conv2 shape: ", x.shape)
x = F.relu(self.t_conv3(x))
print("t_conv3 shape: ", x.shape)
# 再次转置卷积,输出应应用sigmoid函数
x = F.sigmoid(self.conv_out(x))
print("conv_out shape: ", x.shape)
return x
# 初始化神经网络
model = ConvDenoiser()
print(model)
x = model.forward(torch.rand(1, 3, 68, 68))(2)测试
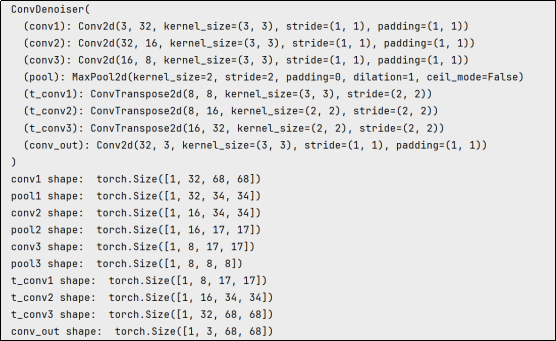
需要注意,此处的print是为了了解各层处理完成后的数据维度,训练时过多的print会严重拖慢训练效率,因此测试完成后注释forward函数中的print,然后重新运行Cell。
3)Cell3
定义损失函数和优化器
(1)代码清单
python
# 指定损失函数
criterion = nn.MSELoss()
# 指定优化器
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)(2)测试
无输出
4)Cell4
创建数据集
(1)代码清单
python
import numpy as np # 导入 NumPy 库,用于数值计算
import torchvision.transforms as T # 导入torchvision.transforms模块,用于图像预处理
# 检查是否有可用的 GPU,如果有则使用 GPU,否则使用 CPU
if torch.cuda.is_available():
device = "cuda"
else:
device = "cpu"
# 定义数据预处理流程
transforms = T.Compose([T.Resize((68, 68)), T.ToTensor()])
# 打印日志,提示用户正在创建数据集
print("------------ 正在创建数据集 ------------")
# 创建自定义数据集
full_dataset = FolderDataset('common/dataset/', transforms)
# 计算训练集和验证集的大小
train_size = int(0.75 * len(full_dataset)) # 训练集占 75%
val_size = len(full_dataset) - train_size # 验证集占剩余的 25%
# 按照计算的数据集大小,随机划分训练集和验证集
train_dataset, val_dataset = torch.utils.data.random_split(
full_dataset, [train_size, val_size]
)
# 数据是分批训练的
# 设置训练数据的批次大小
batch_size = 32
# 打印数据集创建完成的信息
print("------------ 数据集创建完成 ------------")
# 打印创建 DataLoader 的信息
print("------------ 创建数据加载器 ------------")
# 创建训练集的 DataLoader
train_loader = torch.utils.data.DataLoader(
train_dataset, # 训练数据集,通常是 torch.utils.data.Dataset 的子类
batch_size=batch_size, # 每个批次的样本数量,这里设置为 batch_size 变量的值
shuffle=True, # 是否在每个 epoch 开始时打乱数据顺序
drop_last=True # 如果最后一个批次的样本数不足 batch_size,是否丢弃该批次
)
# 创建验证集的 DataLoader
val_loader = torch.utils.data.DataLoader(
val_dataset, # 验证数据集,通常是 torch.utils.data.Dataset 的子类
batch_size=batch_size # 每个批次的样本数量,这里设置为 batch_size 变量的值
)
for noisy_imgs, noisy_images in train_dataset:
print(f"Noisy images device: {noisy_imgs.device}")
print(f"Images device: {noisy_images.device}")
break(2)测试

5)Cell5
训练
(1)代码清单
python
# 设置训练的 epoch 数量
n_epochs = 20
# 设置噪声因子,用于向图像添加噪声
noise_factor = 0.5
# 将模型移动到指定的设备(GPU 或 CPU)
model.to(device)
criterion.to(device)
# optimizer.to(device)
# 开始训练循环,遍历每个 epoch
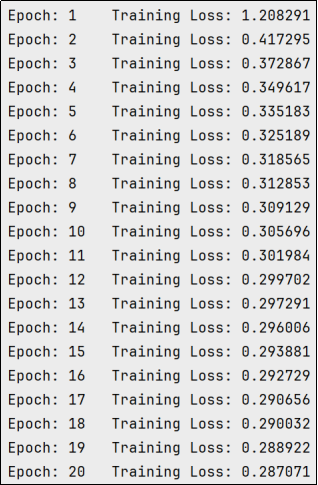
for epoch in range(1, n_epochs + 1):
# 初始化训练损失
train_loss = 0.0
###################
# 训练模型 #
###################
# 遍历训练数据加载器中的每个批次
for noisy_imgs, noisy_images in train_loader:
# 在训练循环中添加调试语句
# print(f"Model device: {next(model.parameters()).device}")
# print(f"Noisy images device: {noisy_imgs.device}")
# print(f"Images device: {images.device}")
# 从 DataLoader 中加载数据
# noisy_imgs 是带噪声的输入图像,
# images 是原图,作为训练目标
# 将噪声图像和原始图像移动到指定设备(GPU 或 CPU)
noisy_imgs = noisy_imgs.to(device)
noisy_images = noisy_images.to(device)
# 清除优化器中所有参数的梯度
optimizer.zero_grad()
## 前向传播:将噪声图像输入模型,得到输出
outputs = model(noisy_imgs)
# 计算损失
# 目标值是原始图像(无噪声),而不是噪声图像
loss = criterion(outputs, noisy_images)
# 反向传播:计算损失对模型参数的梯度
loss.backward()
# 执行优化步骤:更新模型参数
optimizer.step()
# 更新当前 epoch 的训练损失
# loss.item() 返回损失的标量值,images.size(0) 是当前批次的样本数量
train_loss += loss.item() * noisy_images.size(0)
# 计算并打印平均训练损失
# train_loss 是所有批次损失的总和,除以批次数(len(train_loader))得到平均损失
train_loss = train_loss / len(train_loader)
# 打印当前 epoch 的编号和平均训练损失
print('Epoch: {} \tTraining Loss: {:.6f}'.format(
epoch, # 当前 epoch 编号
train_loss # 当前 epoch 的平均训练损失
))(2)测试
6)Cell6
测试模型效果
(1)代码清单
python
import matplotlib.pyplot as plt # 导入 matplotlib 库,用于绘图
%matplotlib inline
# 在 Jupyter Notebook 中内嵌显示图像
# 从验证数据加载器中获取一个批次的测试图像
dataiter = iter(val_loader) # 创建验证数据加载器的迭代器
noisy_images, original_images = next(dataiter) # 获取下一个批次的数据(图像和标签)
print("测试集 images 形状: ", noisy_images.shape) # 打印图像的形状,通常是 (batch_size, channels, height, width)
model = model.to(device) # 将模型移动到指定的设备
noisy_images = noisy_images.to(device) # 将噪声图像移动到指定的设备
print("测试集 noisy_images 形状: ", noisy_images.shape) # 打印图像的形状,通常是 (batch_size, channels, height, width)
# 获取模型的输出(去噪后的图像)
output = model(noisy_images) # 将噪声图像输入模型,得到去噪后的输出
print("测试集输出结果 output 形状: ", output.shape) # 打印输出的形状,通常是 (batch_size, channels, height, width)
# 准备噪声图像用于显示
noisy_images = noisy_images.cpu().numpy() # 将噪声图像从 PyTorch 张量转换为 NumPy 数组
print('noisy_imgs 转换为 numpy 数组后的形状: ', noisy_images.shape) # 打印噪声图像的形状
noisy_images = np.moveaxis(noisy_images, 1, -1) # 调整维度顺序,将通道维度移到最后一维,适配 matplotlib 的显示格式
# 将输出调整为批次图像的形状
output = output.view(batch_size, 3, 68, 68) # 将输出张量调整为 (batch_size, channels, height, width) 的形状
# 使用 detach() 分离梯度信息,并将其转换为 NumPy 数组
output = output.detach().cpu().numpy() # 将输出从 PyTorch 张量转换为 NumPy 数组
print('output 转换为 numpy 数组后的形状: ', output.shape) # 打印输出的形状
output = np.moveaxis(output, 1, -1) # 调整维度顺序,将通道维度移到最后一维,适配 matplotlib 的显示格式
print('output 的通道维度移到最后一维后的形状: ', output.shape) # 打印调整后的输出形状
original_images = original_images.cpu().numpy().transpose((0, 2, 3, 1))
print("original_image shape: ", original_images.shape)
# 绘制前 10 张输入图像和重建图像
fig, axes = plt.subplots(nrows=3, ncols=10, sharex=True, sharey=True, figsize=(25,4)) # 创建 2 行 10 列的子图
# 第一行显示噪声图像,第二行显示重建图像
for imgs, row in zip([noisy_images, original_images, output], axes): # 遍历噪声图像和重建图像
for img, ax in zip(imgs, row): # 遍历每张图像和对应的子图
ax.imshow(np.squeeze(img)) # 显示图像,并去除多余的维度
ax.get_xaxis().set_visible(False) # 隐藏 x 轴
ax.get_yaxis().set_visible(False) # 隐藏 y 轴
plt.show() # 显示图像(2)测试

3.4实现
3.4.1环境准备
在image_denoising包下创建以下文件
denoising_config.py:项目配置信息
denoising_data.py:数据处理
denoising_engine.py:训练和向前传递的实现
denoising_model.py:模型定义
denoising_train.py:包括数据加载、预处理直至训练的完整流程
3.4.2代码清单
1)denoising_config.py
python
# ------------ 数据路径与预处理配置 ------------
IMG_PATH = "../common/dataset/" # 原始图像存储根目录(需确保存在子目录)
IMG_HEIGHT = 512 # 原始图像高度(注意:实际训练时会被Resize为68x68)
IMG_WIDTH = 512 # 原始图像宽度(需检查与数据预处理的一致性)
# ------------ 随机性与数据划分配置 ------------
SEED = 42 # 全局随机种子(确保实验可复现性)
TRAIN_RATIO = 0.75 # 训练集划分比例(75%训练,25%验证)
VAL_RATIO = 1 - TRAIN_RATIO # 验证集比例(自动计算,无需修改)
SHUFFLE_BUFFER_SIZE = 100 # 数据混洗缓冲区大小(影响数据加载顺序随机性)
NOISE_FACTOR = 0.5 # 设置噪声因子,用于向图像添加噪声
# ------------ 训练超参数配置 ------------
LEARNING_RATE = 1e-3 # 初始学习率(AdamW优化器使用)
EPOCHS = 30 # 总训练轮次(需平衡过拟合与欠拟合)
TRAIN_BATCH_SIZE = 32 # 训练批次大小(GPU显存不足时可调小)
TEST_BATCH_SIZE = 32 # 验证/测试批次大小(建议与训练批次一致)
# ------------ 模型配置 ------------
PACKAGE_NAME = "image_denoising"
DENOISER_MODEL_NAME = "denoiser.pt" # 编码器权重保存路径(需写权限)2)denoising_data.py
python
# 定义模块的公开接口,仅暴露FolderDataset类
__all__ = ["FolderDataset"]
from PIL import Image # 导入PIL库中的Image模块,用于图像处理
import os # 导入os库,用于处理文件和目录路径
from torch.utils.data import Dataset # 从PyTorch的工具库中导入Dataset类,用于自定义数据集
import denoising_config
import torch
import numpy as np
# 正则表达式相关库
import re
def sorted_alphanumeric(data):
"""按字母数字混合顺序对文件名进行排序(例如:img1, img2, ..., img10)"""
# 定义转换函数:将数字部分转换为整数,非数字部分转换为小写
convert = lambda text: int(text) if text.isdigit() else text.lower()
# 生成排序键:用正则分割字符串,分别处理数字和非数字部分
alphanum_key = lambda key: [convert(c) for c in re.split('([0-9]+)', key)]
# 按生成的键排序
return sorted(data, key=alphanum_key)
class FolderDataset(Dataset): # 定义一个名为FolderDataset的类,继承自PyTorch的Dataset类
def __init__(self, main_dir, transform=None): # 定义类的构造函数,接受两个参数:main_dir(主目录路径)和transform(图像预处理操作,默认为None)
self.main_dir = main_dir # 将主目录路径保存为类的属性
self.transform = transform # 将图像预处理操作保存为类的属性
self.all_imgs = sorted_alphanumeric(os.listdir(main_dir)) # 获取所有图像文件名并按字母数字顺序排序
def __len__(self): # 定义__len__方法,返回数据集中图像的数量
return len(self.all_imgs) # 返回主目录下图像文件的数量
def __getitem__(self, idx): # 定义__getitem__方法,根据索引idx获取图像
img_loc = os.path.join(self.main_dir, self.all_imgs[idx]) # 根据索引idx构建图像的完整路径
image = Image.open(img_loc).convert("RGB") # 使用PIL库打开图像并将其转换为RGB格式
if self.transform is not None: # 如果定义了图像预处理操作
tensor_image = self.transform(image) # 对图像进行预处理,并将其转换为张量
else:
# 若无变换,抛出异常提示必须提供预处理
raise ValueError("transform参数不能为None,需指定预处理方法")
## 向输入图像添加随机噪声
# 生成与 tensor_image 形状相同的随机噪声,乘以噪声因子 noise_factor
noisy_imgs = tensor_image + denoising_config.NOISE_FACTOR * torch.randn(*tensor_image.shape)
# 将图像像素值裁剪到 [0, 1] 范围内,避免超出有效范围
noisy_imgs = torch.clip(noisy_imgs, 0., 1.)
return noisy_imgs, tensor_image # 返回预处理后的图像张量(将噪声图片作为输入,将原图作为目标)3)denoising_engine.py
python
# 定义模块的公开接口
__all__ = ["train_step", "val_step", "create_embedding"]
# 导入PyTorch核心库和神经网络模块
import torch
def train_step(denoiser, train_loader, loss_fn, optimizer, device):
"""
执行一个完整的训练迭代
参数:
- encoder: 卷积编码器(如ConvEncoder)
- decoder: 卷积解码器(如ConvDecoder)
- train_loader: 训练数据加载器,提供批次化的(输入图像, 目标图像)
- loss_fn: 损失函数(如MSE)
- optimizer: 优化器(如Adam)
- device: 计算设备("cuda" 或 "cpu")
返回值:
- 当前epoch的平均训练损失(标量值)
"""
# 设置为训练模式(启用Dropout/BatchNorm等训练专用层),当前场景下无用
# encoder.train()
# decoder.train()
total_loss = 0 # 累计损失
num_batches = 0 # 批次计数器
# 遍历训练数据加载器中的所有批次
for train_img, target_img in train_loader:
# 将数据移动到指定设备(GPU/CPU)
train_img = train_img.to(device)
target_img = target_img.to(device)
# 清空优化器中之前的梯度
optimizer.zero_grad()
# 前向传播:编码器生成潜在表示
output = denoiser(train_img)
# 计算重建损失(预测图像与目标图像的差异)
loss = loss_fn(output, target_img)
# 反向传播:计算梯度
loss.backward()
# 优化器更新模型参数
optimizer.step()
total_loss += loss.item() # 累加损失值
num_batches += 1
return total_loss / num_batches # 返回平均损失
def val_step(denoiser, val_loader, loss_fn, device):
"""
执行验证步骤(不更新参数)
参数与train_step类似,但不含优化器参数
返回值:
- 验证集的平均损失(标量值)
"""
# 设置为评估模式(禁用Dropout/BatchNorm等训练专用层)
# encoder.eval()
# decoder.eval()
total_loss = 0
num_batches = 0
# 禁用梯度计算以节省内存和计算资源
with torch.no_grad():
for train_img, target_img in val_loader:
train_img = train_img.to(device)
target_img = target_img.to(device)
# 前向传播
output = denoiser(train_img)
# 计算损失
loss = loss_fn(output, target_img)
total_loss += loss.item()
num_batches += 1
return total_loss / num_batches4)denoising_model.py
python
# 定义模块的公开接口,仅暴露ConvEncoder和ConvDecoder类
__all__ = ["ConvDenoiser"]
import torch.nn as nn
import torch.nn.functional as F
# 定义神经网络架构
class ConvDenoiser(nn.Module):
def __init__(self):
super(ConvDenoiser, self).__init__()
## 编码器层 ##
# 卷积层 (输入通道数从1变为32), 3x3卷积核
self.conv1 = nn.Conv2d(3, 32, 3, padding=1)
# 卷积层 (输入通道数从32变为16), 3x3卷积核
self.conv2 = nn.Conv2d(32, 16, 3, padding=1)
# 卷积层 (输入通道数从16变为8), 3x3卷积核
self.conv3 = nn.Conv2d(16, 8, 3, padding=1)
# 池化层,用于将x-y维度减少一半;卷积核和步幅均为2
self.pool = nn.MaxPool2d(2, 2)
## 解码器层 ##
# 转置卷积层,卷积核为2,步幅为2,将空间维度增加2倍
self.t_conv1 = nn.ConvTranspose2d(8, 8, 3, stride=2) # 卷积核大小为3,以得到7x7的图像输出
# 另外两个转置卷积层,卷积核为2
self.t_conv2 = nn.ConvTranspose2d(8, 16, 2, stride=2)
self.t_conv3 = nn.ConvTranspose2d(16, 32, 2, stride=2)
# 最后一个普通的卷积层,用于减少通道数
self.conv_out = nn.Conv2d(32, 3, 3, padding=1)
# forward函数用于向前传播,该函数接受一个输入张量x,并返回一个输出张量,该函数的实现真正决定了神经网络的架构
def forward(self, x):
## 编码 ##
# 添加带有ReLU激活函数的隐藏层
# 并在之后进行最大池化
x = F.relu(self.conv1(x))
x = self.pool(x)
# 添加第二个隐藏层
x = F.relu(self.conv2(x))
x = self.pool(x)
# 添加第三个隐藏层
x = F.relu(self.conv3(x))
x = self.pool(x) # 压缩表示
## 解码 ##
# 添加转置卷积层,带有ReLU激活函数
x = F.relu(self.t_conv1(x))
x = F.relu(self.t_conv2(x))
x = F.relu(self.t_conv3(x))
# 再次转置卷积,输出应应用sigmoid函数
x = F.sigmoid(self.conv_out(x))
return x
import torch
if __name__ == "__main__":
# 创建一个随机输入张量
input_tensor = torch.randn(1, 3, 64, 64)
# 创建一个卷积编码器模型
denoiser = ConvDenoiser()
# 编码输入张量
encoded_tensor = denoiser(input_tensor)5)denoising_train.py
python
# 导入PyTorch核心库
import torch
# 导入自定义模型模块(包含ConvEncoder和ConvDecoder)
import denoising_model
# 导入训练引擎模块(包含train_step和val_step)
import denoising_engine
# 导入torchvision的图像变换模块
import torchvision.transforms as T
# 导入自定义数据加载模块
import denoising_data
# 导入配置文件参数
import denoising_config
# 导入numpy用于数据处理
import numpy as np
# 导入进度条工具
from tqdm import tqdm
# 导入PyTorch神经网络模块
import torch.nn as nn
# 导入优化器模块
import torch.optim as optim
# 导入自定义工具函数(如seed_everything)
from common import utils
def test(denoiser, val_loader, device):
import matplotlib.pyplot as plt
# 从验证数据加载器中获取一个批次的测试图像
dataiter = iter(val_loader) # 创建验证数据加载器的迭代器
noisy_images, original_images = next(dataiter) # 获取下一个批次的数据(图像和标签)
print("测试集 images 形状: ", noisy_images.shape) # 打印图像的形状,通常是 (batch_size, channels, height, width)
denoiser = denoiser.to(device) # 将模型移动到指定的设备
noisy_images = noisy_images.to(device) # 将噪声图像移动到指定的设备
print("测试集 noisy_images 形状: ", noisy_images.shape) # 打印图像的形状,通常是 (batch_size, channels, height, width)
# 获取模型的输出(去噪后的图像)
output = denoiser(noisy_images) # 将噪声图像输入模型,得到去噪后的输出
print("测试集输出结果 output 形状: ", output.shape) # 打印输出的形状,通常是 (batch_size, channels, height, width)
# 准备噪声图像用于显示
noisy_images = noisy_images.cpu().numpy() # 将噪声图像从 PyTorch 张量转换为 NumPy 数组
print('noisy_imgs 转换为 numpy 数组后的形状: ', noisy_images.shape) # 打印噪声图像的形状
noisy_images = np.moveaxis(noisy_images, 1, -1) # 调整维度顺序,将通道维度移到最后一维,适配 matplotlib 的显示格式
# 将输出调整为批次图像的形状
output = output.view(denoising_config.TEST_BATCH_SIZE, 3, 68,
68) # 将输出张量调整为 (batch_size, channels, height, width) 的形状
# 使用 detach() 分离梯度信息,并将其转换为 NumPy 数组
output = output.detach().cpu().numpy() # 将输出从 PyTorch 张量转换为 NumPy 数组
print('output 转换为 numpy 数组后的形状: ', output.shape) # 打印输出的形状
output = np.moveaxis(output, 1, -1) # 调整维度顺序,将通道维度移到最后一维,适配 matplotlib 的显示格式
print('output 的通道维度移到最后一维后的形状: ', output.shape) # 打印调整后的输出形状
original_images = original_images.cpu().numpy().transpose((0, 2, 3, 1))
print("original_image shape: ", original_images.shape)
# 绘制前 10 张输入图像和重建图像
fig, axes = plt.subplots(nrows=3, ncols=10, sharex=True, sharey=True, figsize=(25, 4)) # 创建 2 行 10 列的子图
# 第一行显示噪声图像,第二行显示重建图像
for imgs, row in zip([noisy_images, original_images, output], axes): # 遍历噪声图像和重建图像
for img, ax in zip(imgs, row): # 遍历每张图像和对应的子图
ax.imshow(np.squeeze(img)) # 显示图像,并去除多余的维度
ax.get_xaxis().set_visible(False) # 隐藏 x 轴
ax.get_yaxis().set_visible(False) # 隐藏 y 轴
plt.show() # 显示图像
# 主程序入口
if __name__ == "__main__":
# 检测GPU可用性并设置设备
if torch.cuda.is_available():
device = "cuda" # 优先使用GPU
else:
device = "cpu" # 回退到CPU
# 打印随机种子配置信息
print("设置训练去噪模型的随机数种子, seed = {}".format(denoising_config.SEED))
# 调用工具函数设置全局随机种子(确保可复现性)
utils.seed_everything(denoising_config.SEED)
# 定义图像预处理流程
transforms = T.Compose([T.Resize((68, 68)), T.ToTensor()])
# 打印日志,提示用户正在创建数据集
print("------------ 正在创建数据集 ------------")
# 实例化完整数据集(输入和目标均为同一图像,自监督学习)
full_dataset = denoising_data.FolderDataset(denoising_config.IMG_PATH, transforms)
# 计算训练集和验证集大小
train_size = int(denoising_config.TRAIN_RATIO * len(full_dataset)) # 75%训练
val_size = len(full_dataset) - train_size # 25%验证
# 随机划分数据集
train_dataset, val_dataset = torch.utils.data.random_split(
full_dataset, [train_size, val_size]
)
# 数据加载器配置阶段
print("------------ 数据集创建完成 ------------")
print("------------ 创建数据加载器 ------------")
# 训练数据加载器(打乱顺序,丢弃最后不完整的批次)
train_loader = torch.utils.data.DataLoader(
train_dataset,
batch_size=denoising_config.TRAIN_BATCH_SIZE,
shuffle=True,
drop_last=True
)
# 验证数据加载器(不打乱,完整加载)
val_loader = torch.utils.data.DataLoader(
val_dataset,
batch_size=denoising_config.TEST_BATCH_SIZE
)
print("------------ 数据加载器创建完成 ------------")
# 初始化自编码器用于去噪
denoiser = denoising_model.ConvDenoiser() # 创建自编码器实例
# 指定损失函数
loss_fn = nn.MSELoss()
# 将模型移动到指定设备(GPU/CPU)
denoiser.to(device)
# 指定优化器
optimizer = torch.optim.Adam(denoiser.parameters(), lr=denoising_config.LEARNING_RATE)
# 初始化最佳损失值为极大值
min_loss = 9999
# 开始训练循环
print("------------ 开始训练 ------------")
# 使用tqdm进度条遍历预设的epoch数量
for epoch in tqdm(range(denoising_config.EPOCHS)):
# 执行一个训练epoch
train_loss = denoising_engine.train_step(
denoiser, train_loader, loss_fn, optimizer, device=device
)
# 打印当前epoch的训练损失
print(f"\n----------> Epochs = {epoch + 1}, Training Loss : {train_loss} <----------")
# 执行验证步骤
val_loss = denoising_engine.val_step(
denoiser, val_loader, loss_fn, device=device
)
# 模型保存逻辑:当验证损失创新低时保存模型
if val_loss < min_loss:
print("验证集的损失减小了,保存新的最好的模型。")
min_loss = val_loss
# 保存去噪自编码器状态字典
torch.save(denoiser.state_dict(), denoising_config.DENOISER_MODEL_NAME)
else:
print("验证集的损失没有减小,不保存模型。")
# 打印验证损失
print(f"Epochs = {epoch + 1}, Validation Loss : {val_loss}")
# 训练结束提示
print("\n==========> 训练结束 <==========\n")
print("本次训练的去噪模型测试结果如下")
test(denoiser, val_loader, device)
print("================> 从磁盘加载模型 <================")
load_denoiser = denoising_model.ConvDenoiser()
load_denoiser.load_state_dict(torch.load(denoising_config.DENOISER_MODEL_NAME, map_location=device))
load_denoiser.to(device)
print("从磁盘加载的去噪模型测试结果如下")
test(load_denoiser, val_loader, device)3.4.3测试
运行denoising_train.py即可训练模型
日志如下

在image_denoising目录下会出现denoiser.pt文件,这是训练好的模型文件。