表的增删查改可以概括为CRUD : Create(创建), Retrieve(读取),Update(更新),Delete(删除)
create
语法:
c
INSERT [INTO] table_name
[(column [, column] ...)]
VALUES (value_list) [, (value_list)] ...
value_list: value, [, value] ...例子:
c
mysql> CREATE TABLE students (
-> id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
-> sn INT NOT NULL UNIQUE COMMENT '学号',
-> name VARCHAR(20) NOT NULL,
-> qq VARCHAR(20)
-> );
Query OK, 0 rows affected (0.93 sec)单行数据插入+全列插入
全列插入:不需要输入要插入的列属性,默认按列一个一个插入值。
c
mysql> INSERT INTO students VALUES (100, 10000, '小一', NULL);
Query OK, 1 row affected (0.07 sec)
mysql> INSERT INTO students VALUES (101, 10001, '小二', '11111');
Query OK, 1 row affected (0.01 sec)
mysql> select * from students;
+-----+-------+--------+-------+
| id | sn | name | qq |
+-----+-------+--------+-------+
| 100 | 10000 | 小一 | NULL |
| 101 | 10001 | 小二 | 11111 |
+-----+-------+--------+-------+
2 rows in set (0.01 sec)多行数据 + 指定列插入
多行数据:要填充的数据排列起来,逗号隔开。
指定列:给定(id, sn, name)几个元素,在里面填充数据,对于不填的列,自动为NULL,如果是自增长的列,会自动填充下一个数。
c
mysql> INSERT INTO students (id, sn, name) VALUES(102, 20001, '小三'),(103, 20002, '小四');
Query OK, 2 rows affected (0.01 sec)
mysql> select * from students;
+-----+-------+--------+-------+
| id | sn | name | qq |
+-----+-------+--------+-------+
| 100 | 10000 | 小一 | NULL |
| 101 | 10001 | 小二 | 11111 |
| 102 | 20001 | 小三 | NULL |
| 103 | 20002 | 小四 | NULL |
+-----+-------+--------+-------+
4 rows in set (0.00 sec)替换1------插入否则更新on duplicate key update
可以选择性的进行同步更新操作语法:
c
INSERT ... ON DUPLICATE KEY UPDATE
column = value [, column = value] ...若插入的记录存在主键冲突或唯一键冲突时,加上on duplicate key update,后面接上要修改的属性对应的值,就可以把数据库中冲突的记录进行修改。
c
mysql> insert into students values (101,10001,'小二','22222');--直接想要修改某个记录的某个值
ERROR 1062 (23000): Duplicate entry '101' for key 'students.PRIMARY'
mysql> insert into students values (101,10001,'小二','22222') on duplicate key update sn=10002, name='小二',qq=22222;--加上on duplicate key update
Query OK, 2 rows affected (0.04 sec)
-- 0 row affected: 表中有冲突数据,但冲突数据的值和 update 的值相等
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,并且数据已经被更新
mysql> select * from students;
+-----+-------+--------+-------+
| id | sn | name | qq |
+-----+-------+--------+-------+
| 100 | 10000 | 小一 | NULL |
| 101 | 10002 | 小二 | 22222 |
| 102 | 20001 | 小三 | NULL |
| 103 | 20002 | 小四 | NULL |
+-----+-------+--------+-------+
4 rows in set (0.00 sec)替换2------replace替换
c
-- 主键 或者 唯一键 没有冲突,则直接插入;
-- 主键 或者 唯一键 如果冲突,则删除后再插入
mysql> replace into students (sn, name) values(20001,'三号');
Query OK, 2 rows affected (0.02 sec)
-- 1 row affected: 表中没有冲突数据,数据被插入
-- 2 row affected: 表中有冲突数据,删除后重新插入总结:主键或者唯一键冲突的前提,可以理解为确定了那一条记录的位置,然后进行替换
retrieve
语法:
c
SELECT
[DISTINCT] {* | {column [, column] ...}
[FROM table_name]
[WHERE ...]
[ORDER BY column [ASC | DESC], ...]
LIMIT ...创建测试表:
c
mysql> CREATE TABLE exam_result (
-> id INT UNSIGNED PRIMARY KEY AUTO_INCREMENT,
-> name VARCHAR(20) NOT NULL COMMENT '同学姓名',
-> chinese float DEFAULT 0.0 COMMENT '语文成绩',
-> math float DEFAULT 0.0 COMMENT '数学成绩',
-> english float DEFAULT 0.0 COMMENT '英语成绩'
-> );
Query OK, 0 rows affected (0.17 sec)
mysql> INSERT INTO exam_result (name, chinese, math, english) VALUES
-> ('唐三藏', 67, 98, 56),
-> ('孙悟空', 87, 78, 77),
-> ('猪悟能', 88, 98, 90),
-> ('曹孟德', 82, 84, 67),
-> ('刘玄德', 55, 85, 45),
-> ('孙权', 70, 73, 78),
-> ('宋公明', 75, 65, 30);
Query OK, 7 rows affected (0.03 sec)
Records: 7 Duplicates: 0 Warnings: 0SELECT 列
全列查询
通常情况下不建议使用 * 进行全列查询
- 查询的列越多,意味着需要传输的数据量越大;
- 可能会影响到索引的使用。(索引待后面课程讲解)
c
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘玄德 | 55 | 85 | 45 |
| 6 | 孙权 | 70 | 73 | 78 |
| 7 | 宋公明 | 75 | 65 | 30 |
+----+-----------+---------+------+---------+
7 rows in set (0.00 sec)指定列查询
c
mysql> select name from exam_result;
+-----------+
| name |
+-----------+
| 唐三藏 |
| 孙悟空 |
| 猪悟能 |
| 曹孟德 |
| 刘玄德 |
| 孙权 |
| 宋公明 |
+-----------+
7 rows in set (0.00 sec)查询字段为表达式
cpp
mysql> select name, chinese + math + english from exam_result;
+-----------+----------------------+
| name | chinese+math+english |
+-----------+----------------------+
| 唐三藏 | 221 |
| 孙悟空 | 242 |
| 猪悟能 | 276 |
| 曹孟德 | 233 |
| 刘玄德 | 185 |
| 孙权 | 221 |
| 宋公明 | 170 |
+-----------+----------------------+
7 rows in set (0.01 sec)
mysql> select name, chinese+math+english+10000 from exam_result;
+-----------+----------------------------+
| name | chinese+math+english+10000 |
+-----------+----------------------------+
| 唐三藏 | 10221 |
| 孙悟空 | 10242 |
| 猪悟能 | 10276 |
| 曹孟德 | 10233 |
| 刘玄德 | 10185 |
| 孙权 | 10221 |
| 宋公明 | 10170 |
+-----------+----------------------------+
7 rows in set (0.00 sec)为查询结果指定别名
cpp
mysql> select name, chinese+math+english as total from exam_result;--可以重命名
+-----------+-------+
| name | total |
+-----------+-------+
| 唐三藏 | 221 |
| 孙悟空 | 242 |
| 猪悟能 | 276 |
| 曹孟德 | 233 |
| 刘玄德 | 185 |
| 孙权 | 221 |
| 宋公明 | 170 |
+-----------+-------+
7 rows in set (0.00 sec)
mysql> select name 姓名, chinese+math+english total from exam_result;--可以不带as
+-----------+-------+
| 姓名 | total |
+-----------+-------+
| 唐三藏 | 221 |
| 孙悟空 | 242 |
| 猪悟能 | 276 |
| 曹孟德 | 233 |
| 刘玄德 | 185 |
| 孙权 | 221 |
| 宋公明 | 170 |
+-----------+-------+
7 rows in set (0.00 sec)查询结果去重
select 后面加上 distinct
c
mysql> select math from exam_result;
+------+
| math |
+------+
| 98 |--98重复
| 78 |
| 98 |
| 84 |
| 85 |
| 73 |
| 65 |
+------+
7 rows in set (0.00 sec)
mysql> select distinct math from exam_result;
+------+
| math |
+------+
| 98 |
| 78 |
| 84 |
| 85 |
| 73 |
| 65 |
+------+
6 rows in set (0.03 sec)where条件
| 运算符 | 说明 |
|---|---|
>, >=, <, <= |
大于,大于等于,小于,小于等于 |
= |
等于,NULL 不安全,例如 NULL = NULL 的结果是 NULL |
<=> |
等于,NULL 安全,例如 NULL <=> NULL 的结果是 TRUE(1) |
!=, <> |
不等于 |
BETWEEN a0 AND a1 |
范围匹配,[a0,a1],如果 a0 <= value <= a1,返回 TRUE(1) |
IN (option,...) |
如果是 option 中的任意一个,返回 TRUE(1) |
IS NULL |
是 NULL |
IS NOT NULL |
不是 NULL |
LIKE |
模糊匹配。% 表示任意多个(包括 0 个)任意字符;_ 表示任意一个字符 |
逻辑运算符
| 运算符 | 说明 |
|---|---|
AND |
多个条件必须都为 TRUE(1),结果才是 TRUE(1) |
OR |
任意一个条件为 TRUE(1), 结果为 TRUE(1) |
NOT |
条件为 TRUE(1),结果为 FALSE(0) |
关于NULL
c
mysql> select NULL = NULL,NULL = 1, NULL = 0;
+-------------+----------+----------+
| NULL = NULL | NULL = 1 | NULL = 0 |
+-------------+----------+----------+
| NULL | NULL | NULL |
+-------------+----------+----------+
1 row in set (0.00 sec)
mysql> SELECT NULL <=> NULL, NULL <=> 1, NULL <=> 0;
+---------------+------------+------------+
| NULL <=> NULL | NULL <=> 1 | NULL <=> 0 |
+---------------+------------+------------+
| 1 | 0 | 0 |
+---------------+------------+------------+
1 row in set (0.00 sec)各种例子
英语不及格的同学及英语成绩 ( < 60 )
c
mysql> select name, english from exam_result where english < 60;
+-----------+---------+
| name | english |
+-----------+---------+
| 唐三藏 | 56 |
| 刘玄德 | 45 |
| 宋公明 | 30 |
+-----------+---------+
3 rows in set (0.01 sec)语文成绩在 80, 90 分的同学及语文成绩
c
--使用AND
mysql> select name, chinese from exam_result where chinese >= 80 and chinese <= 90;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 孙悟空 | 87 |
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+---------+
3 rows in set (0.00 sec)
--使用BETWEEN......AND......
mysql> select name, chinese from exam_result where chinese between 80 and 90;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 孙悟空 | 87 |
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+---------+
3 rows in set (0.00 sec)数学成绩是 58 或者 59 或者 98 或者 99 分的同学及数学成绩
c
-- 使用 OR 进行条件连接
mysql> select name, math from exam_result
-> where math = 58
-> or math = 59
-> or math = 98
-> or math = 99;
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+------+
2 rows in set (0.00 sec)
-- 使用 IN 条件
mysql> select name, math from exam_result where math in (58, 59, 98, 99);
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+------+
2 rows in set (0.00 sec)姓孙的同学 及 孙某同学
c
-- % 匹配任意多个(包括 0 个)任意字符
mysql> select name from exam_result where name like '孙%';
+-----------+
| name |
+-----------+
| 孙悟空 |
| 孙权 |
+-----------+
2 rows in set (0.01 sec)
mysql> select name from exam_result where name like '孙_';
+--------+
| name |
+--------+
| 孙权 |
+--------+
1 row in set (0.00 sec)语文成绩 > 80 并且不姓孙的同学
c
mysql> select name, chinese from exam_result where chinese > 80 and name not like '孙%';
+-----------+---------+
| name | chinese |
+-----------+---------+
| 猪悟能 | 88 |
| 曹孟德 | 82 |
+-----------+---------+
2 rows in set (0.00 sec)总分在 200 分以下的同学
c
--别名不能出现在where条件中,为什么?
mysql> select name, chinese+math+english total from exam_result where chinese+math+english < 200;
+-----------+--------+
| name | total |
+-----------+--------+
| 刘玄德 | 185 |
| 宋公明 | 170 |
+-----------+--------+
2 rows in set (0.00 sec)理解执行顺序

结果排序
语法:
c
-- ASC 为升序(从小到大)
-- DESC 为降序(从大到小)
-- 默认为 ASC
SELECT ... FROM table_name [WHERE ...]
ORDER BY column [ASC|DESC], [...];注意:没有 ORDER BY 子句的查询,返回的顺序是未定义的,永远不要依赖这个顺序
各种例子
同学及数学成绩,按数学成绩升序/降序显示
c
mysql> select name, math from exam_result order by math;--默认升序
+-----------+------+
| name | math |
+-----------+------+
| 宋公明 | 65 |
| 孙权 | 73 |
| 孙悟空 | 78 |
| 曹孟德 | 84 |
| 刘玄德 | 85 |
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+------+
7 rows in set (0.00 sec)
mysql> select name, math from exam_result order by math asc;
+-----------+------+
| name | math |
+-----------+------+
| 宋公明 | 65 |
| 孙权 | 73 |
| 孙悟空 | 78 |
| 曹孟德 | 84 |
| 刘玄德 | 85 |
| 唐三藏 | 98 |
| 猪悟能 | 98 |
+-----------+------+
7 rows in set (0.00 sec)
mysql> select name, math from exam_result order by math desc;
+-----------+------+
| name | math |
+-----------+------+
| 唐三藏 | 98 |
| 猪悟能 | 98 |
| 刘玄德 | 85 |
| 曹孟德 | 84 |
| 孙悟空 | 78 |
| 孙权 | 73 |
| 宋公明 | 65 |
+-----------+------+
7 rows in set (0.01 sec)同学及 qq 号,按 qq 号排序显示
c
-- NULL 视为比任何值都小,升序出现在最上面
mysql> select name, qq from students order by qq;
+--------+-------+
| name | qq |
+--------+-------+
| 小一 | NULL |
| 小四 | NULL |
| 三号 | NULL |
| 小二 | 22222 |
+--------+-------+
4 rows in set (0.00 sec)查询同学各门成绩,依次按 数学降序,英语升序,语文升序的方式显示
解释:类似于字典排序,如果有几个同学数学成绩相等,那么这几个同学按照英语升序来排序,如果这几个同学中又有几个同学英语成绩相等,那剩下这几个同学按照语文升序来排序
c
-- 多字段排序,排序优先级随书写顺序
mysql> select name, math, english from exam_result order by math desc, english asc, chinese asc;
+-----------+------+---------+
| name | math | english |
+-----------+------+---------+
| 唐三藏 | 98 | 56 |
| 猪悟能 | 98 | 90 |
| 刘玄德 | 85 | 45 |
| 曹孟德 | 84 | 67 |
| 孙悟空 | 78 | 77 |
| 孙权 | 73 | 78 |
| 宋公明 | 65 | 30 |
+-----------+------+---------+
7 rows in set (0.00 sec)查询同学及总分,由高到低
c
-- ORDER BY 中可以使用表达式
mysql> select name, chinese+english+math from exam_result order by chinese+english+math desc;
+-----------+----------------------+
| name | chinese+english+math |
+-----------+----------------------+
| 猪悟能 | 276 |
| 孙悟空 | 242 |
| 曹孟德 | 233 |
| 唐三藏 | 221 |
| 孙权 | 221 |
| 刘玄德 | 185 |
| 宋公明 | 170 |
+-----------+----------------------+
7 rows in set (0.00 sec)
-- ORDER BY 子句中可以使用列别名,为什么?
mysql> select name, chinese+english+math 总分 from exam_result order by 总分 desc;
+-----------+--------+
| name | 总分 |
+-----------+--------+
| 猪悟能 | 276 |
| 孙悟空 | 242 |
| 曹孟德 | 233 |
| 唐三藏 | 221 |
| 孙权 | 221 |
| 刘玄德 | 185 |
| 宋公明 | 170 |
+-----------+--------+
7 rows in set (0.00 sec)理解执行顺序1
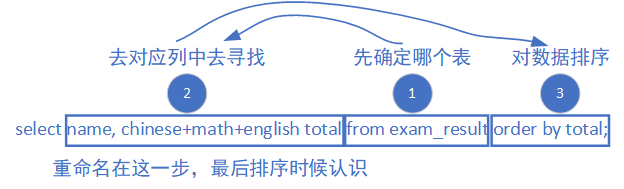
查询姓孙的同学或者姓曹的同学数学成绩(1),结果按数学成绩由高到低显示(2)
c
mysql> SELECT name, math FROM exam_result
-> WHERE name LIKE '孙%' OR name LIKE '曹%'
-> ORDER BY math DESC;
+-----------+------+
| name | math |
+-----------+------+
| 曹孟德 | 84 |
| 孙悟空 | 78 |
| 孙权 | 73 |
+-----------+------+
3 rows in set (0.00 sec)理解执行顺序2

筛选分页结果
语法:
c
-- 起始下标为 0
-- 从 s 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT s, n
-- 从 0 开始,筛选 n 条结果
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n;
;
-- 从 s 开始,筛选 n 条结果,比第二种用法更明确,建议使用
SELECT ... FROM table_name [WHERE ...] [ORDER BY ...] LIMIT n OFFSET s;建议:对未知表进行查询时,最好加一条 LIMIT 1,避免因为表中数据过大,查询全表数据导致数据库卡死
从0开始连续读三行
c
mysql> select * from exam_result limit 3;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 67 | 98 | 56 |
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
+----+-----------+---------+------+---------+
3 rows in set (0.00 sec)从1位置开始,筛选4条信息
c
mysql> select * from exam_result limit 1,4;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘玄德 | 55 | 85 | 45 |
+----+-----------+---------+------+---------+
4 rows in set (0.00 sec)
mysql> select * from exam_result limit 4 offset 1;--与上面比就是顺序反了
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 2 | 孙悟空 | 87 | 78 | 77 |
| 3 | 猪悟能 | 88 | 98 | 90 |
| 4 | 曹孟德 | 82 | 84 | 67 |
| 5 | 刘玄德 | 55 | 85 | 45 |
+----+-----------+---------+------+---------+
4 rows in set (0.00 sec)理解执行顺序
limit的本质功能是显示 ,数据都准备好了,进行显示的时候,再进行分页(limit)。所以limit放在语句最后。

update
语法:
c
UPDATE table_name SET column = expr [, column = expr ...]
[WHERE ...] [ORDER BY ...] [LIMIT ...]对查询到的结果进行列值更新
各种例子
将孙悟空同学的数学成绩变更为 80 分
c
mysql> select name, math from exam_result where name = '孙悟空';
+-----------+------+
| name | math |
+-----------+------+
| 孙悟空 | 78 |
+-----------+------+
1 row in set (0.00 sec)
mysql> update exam_result set math = 80 where name = '孙悟空'; -- 如果不加where条件,所有的人员math均改为80
Query OK, 1 row affected (0.06 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select name, math from exam_result where name = '孙悟空';
+-----------+------+
| name | math |
+-----------+------+
| 孙悟空 | 80 |
+-----------+------+
1 row in set (0.01 sec)将曹孟德同学的数学成绩变更为 60 分,语文成绩变更为 70 分
c
--一次更新多个列
mysql> select name, math, chinese from exam_result where name = '曹孟德';
+-----------+------+---------+
| name | math | chinese |
+-----------+------+---------+
| 曹孟德 | 84 | 82 |
+-----------+------+---------+
1 row in set (0.00 sec)
mysql> update exam_result set math = 60, chinese = 70 where name = '曹孟德';
Query OK, 1 row affected (0.01 sec)
Rows matched: 1 Changed: 1 Warnings: 0
mysql> select name, math, chinese from exam_result where name = '曹孟德';
+-----------+------+---------+
| name | math | chinese |
+-----------+------+---------+
| 曹孟德 | 60 | 70 |
+-----------+------+---------+
1 row in set (0.00 sec)将总成绩倒数前三的 3 位同学的数学成绩加上 30 分
c
mysql> select name, math, chinese + math + english total from exam_result order by total limit 3;
+-----------+------+-------+
| name | math | total |
+-----------+------+-------+
| 宋公明 | 65 | 170 |
| 刘玄德 | 85 | 185 |
| 曹孟德 | 60 | 197 |
+-----------+------+-------+
3 rows in set (0.00 sec)
mysql> update exam_result set math = math + 30 order by chinese + math + english limit 3;
Query OK, 3 rows affected (0.02 sec)
Rows matched: 3 Changed: 3 Warnings: 0
mysql> select name, math, chinese + math + english total from exam_result order by total limit
3;
+-----------+------+-------+
| name | math | total |
+-----------+------+-------+
| 宋公明 | 95 | 200 |
| 刘玄德 | 115 | 215 |
| 唐三藏 | 98 | 221 |
+-----------+------+-------+
3 rows in set (0.00 sec)将所有同学的语文成绩更新为原来的 2 倍
注意:更新全表的语句慎用!
c
--没有where语句,更新全表
mysql> select name, chinese from exam_result;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 唐三藏 | 67 |
| 孙悟空 | 87 |
| 猪悟能 | 88 |
| 曹孟德 | 70 |
| 刘玄德 | 55 |
| 孙权 | 70 |
| 宋公明 | 75 |
+-----------+---------+
7 rows in set (0.00 sec)
mysql> update exam_result set chinese = 2*chinese;
Query OK, 7 rows affected (0.02 sec)
Rows matched: 7 Changed: 7 Warnings: 0
mysql> select name, chinese from exam_result;
+-----------+---------+
| name | chinese |
+-----------+---------+
| 唐三藏 | 134 |
| 孙悟空 | 174 |
| 猪悟能 | 176 |
| 曹孟德 | 140 |
| 刘玄德 | 110 |
| 孙权 | 140 |
| 宋公明 | 150 |
+-----------+---------+
7 rows in set (0.00 sec)delete
删除数据
语法:
c
DELETE FROM table_name [WHERE ...] [ORDER BY ...] [LIMIT ...]删除孙悟空同学的考试成绩
c
mysql> delete from exam_result where name = '孙悟空';
Query OK, 1 row affected (0.01 sec)
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 134 | 98 | 56 |
| 3 | 猪悟能 | 176 | 98 | 90 |
| 4 | 曹孟德 | 140 | 90 | 67 |
| 5 | 刘玄德 | 110 | 115 | 45 |
| 6 | 孙权 | 140 | 73 | 78 |
| 7 | 宋公明 | 150 | 95 | 30 |
+----+-----------+---------+------+---------+
6 rows in set (0.00 sec)删除总分最低法同学的信息
c
mysql> select name, chinese+math+english total from exam_result order by total asc limit 1;
+-----------+-------+
| name | total |
+-----------+-------+
| 刘玄德 | 270 |
+-----------+-------+
1 row in set (0.00 sec)
mysql> delete from exam_result order by english+math+chinese asc limit 1;
Query OK, 1 row affected (0.01 sec)
mysql> select name, chinese+math+english total from exam_result order by total asc limit 1;
+-----------+-------+
| name | total |
+-----------+-------+
| 宋公明 | 275 |
+-----------+-------+
1 row in set (0.00 sec)
mysql> select name, chinese+math+english total from exam_result order by total asc;
+-----------+-------+
| name | total |
+-----------+-------+
| 宋公明 | 275 |
| 唐三藏 | 288 |
| 孙权 | 291 |
| 曹孟德 | 297 |
| 猪悟能 | 364 |
+-----------+-------+
5 rows in set (0.00 sec)删除整张表
c
--建一个用于删除的表
mysql> CREATE TABLE for_delete (
-> id INT PRIMARY KEY AUTO_INCREMENT,
-> name VARCHAR(20)
-> );
Query OK, 0 rows affected (0.34 sec)
mysql> INSERT INTO for_delete (name) VALUES ('A'), ('B'), ('C');
Query OK, 3 rows affected (0.03 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from for_delete;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.00 sec)删除表内容
c
mysql> delete from for_delete;
Query OK, 3 rows affected (0.02 sec)
mysql> select * from for_delete;
Empty set (0.00 sec)在插入一条数据,发现自增是在删除之前的顺序之后再次增加。
删除表内容并不会删除已经记录的 AUTO_INCREMENT 值!
c
mysql> INSERT INTO for_delete (name) VALUES ('D');
Query OK, 1 row affected (0.01 sec)
mysql> select * from for_delete;
+----+------+
| id | name |
+----+------+
| 4 | D |
+----+------+
1 row in set (0.00 sec)
mysql> show create table for_delete \G;
*************************** 1. row ***************************
Table: for_delete
Create Table: CREATE TABLE `for_delete` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(20) COLLATE utf8mb4_unicode_ci DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=5 DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_unicode_ci
1 row in set (0.01 sec)截断表
语法:
c
TRUNCATE [TABLE] table_name- 只能对整表操作,不能像 DELETE 一样针对部分数据操作
- 不会把这个操作记录在日志中,所以比 DELETE 更快,但是TRUNCATE在删除数据的时候,并不经过真正的事物,所以无法回滚
- 会重置 AUTO_INCREMENT 项(delete 不会重置)
创建测试表
c
mysql> CREATE TABLE for_truncate (
-> id INT PRIMARY KEY AUTO_INCREMENT,
-> name VARCHAR(20)
-> );
Query OK, 0 rows affected (0.09 sec)
mysql> INSERT INTO for_truncate (name) VALUES ('A'), ('B'), ('C');
Query OK, 3 rows affected (0.02 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | A |
| 2 | B |
| 3 | C |
+----+------+
3 rows in set (0.22 sec)截断表
c
--截断整表数据,注意影响行数是 0,所以实际上没有对数据真正操作
mysql> truncate for_truncate;
Query OK, 0 rows affected (0.83 sec)
mysql> select * from for_truncate;
Empty set (0.08 sec)
cpp
--再插入一条数据,自增 id 在重新增长
mysql> insert into for_truncate (name) values ('D');
Query OK, 1 row affected (0.01 sec)
mysql> select * from for_truncate;
+----+------+
| id | name |
+----+------+
| 1 | D |
+----+------+
1 row in set (0.00 sec)插入查询结果
语法:insert与select组合
c
INSERT INTO table_name [(column [, column ...])] SELECT ...删除表中的的重复复记录,重复的数据只能有一份。
创建一个表结构,并插入有重复的数据
c
mysql> CREATE TABLE duplicate_table (id int, name varchar(20));
Query OK, 0 rows affected (0.15 sec)
mysql> INSERT INTO duplicate_table VALUES
-> (100, 'aaa'),
-> (100, 'aaa'),
-> (200, 'bbb'),
-> (200, 'bbb'),
-> (200, 'bbb'),
-> (300, 'ccc');
Query OK, 6 rows affected (0.01 sec)
Records: 6 Duplicates: 0 Warnings: 0
mysql> select * from duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 100 | aaa |
| 200 | bbb |
| 200 | bbb |
| 200 | bbb |
| 300 | ccc |
+------+------+
6 rows in set (0.00 sec)操作
c
-- 创建一张空表 no_duplicate_table,结构和 duplicate_table 一样
mysql> CREATE TABLE no_duplicate_table LIKE duplicate_table;
Query OK, 0 rows affected (0.07 sec)
--- 将 duplicate_table 的去重数据插入到 no_duplicate_table
mysql> insert into no_duplicate_table select distinct * from duplicate_table;
Query OK, 3 rows affected (0.03 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from no_duplicate_table;
+------+------+
| id | name |
+------+------+
| 100 | aaa |
| 200 | bbb |
| 300 | ccc |
+------+------+
3 rows in set (0.00 sec)
--重命名表
mysql> rename table duplicate_table to old_duplicate, no_duplicate_table to duplicate_table;
Query OK, 0 rows affected (0.11 sec)聚合函数
| 函数 | 说明 |
|---|---|
COUNT([DISTINCT] expr) |
返回查询到的数据的数量 |
SUM([DISTINCT] expr) |
返回查询到的数据的总和,非数字类型无实际意义 |
AVG([DISTINCT] expr) |
返回查询到的数据的平均值,非数字类型无实际意义 |
MAX([DISTINCT] expr) |
返回查询到的数据的最大值,非数字类型无实际意义 |
MIN([DISTINCT] expr) |
返回查询到的数据的最小值,非数字类型无实际意义 |
对列使用,本质上是一开始对列数据进行处理筛选。
聚合函数使用场景:SELECT子句,GROUP BY + HAVING 子句,ORDER BY 子句。
注意 :WHERE 子句不能直接使用聚合函数:因为 WHERE 是在聚合计算之前筛选行,此时聚合结果还未生成。
各种例子
c
mysql> select * from students;
+-----+-------+--------+-------+
| id | sn | name | qq |
+-----+-------+--------+-------+
| 100 | 10000 | 小一 | NULL |
| 101 | 10002 | 小二 | 22222 |
| 103 | 20002 | 小四 | NULL |
| 104 | 20001 | 三号 | NULL |
+-----+-------+--------+-------+
4 rows in set (0.00 sec)
mysql> select * from exam_result;
+----+-----------+---------+------+---------+
| id | name | chinese | math | english |
+----+-----------+---------+------+---------+
| 1 | 唐三藏 | 134 | 98 | 56 |
| 3 | 猪悟能 | 176 | 98 | 90 |
| 4 | 曹孟德 | 140 | 90 | 67 |
| 6 | 孙权 | 140 | 73 | 78 |
| 7 | 宋公明 | 150 | 95 | 30 |
+----+-----------+---------+------+---------+
5 rows in set (0.01 sec)统计班级共有多少同学
c
mysql> select count(*) from students;
+----------+
| count(*) |
+----------+
| 4 |
+----------+
1 row in set (0.02 sec)
mysql> select count(1) from students;
+----------+
| count(1) |
+----------+
| 4 |
+----------+
1 row in set (0.01 sec)统计班级收集的 qq 号有多少
c
-- NULL不会计入结果
mysql> select count(qq) from students;
+-----------+
| count(qq) |
+-----------+
| 1 |
+-----------+
1 row in set (0.01 sec)统计本次考试的数学成绩分数个数
c
mysql> select count(math) from exam_result;
+-------------+
| count(math) |
+-------------+
| 5 |
+-------------+
1 row in set (0.00 sec)
--可以理解为先对math这列数据去重,然后进行计数
mysql> select count(distinct math) from exam_result;
+----------------------+
| count(distinct math) |
+----------------------+
| 4 |
+----------------------+
1 row in set (0.00 sec)
--这样去重是不对的,计数完math之后,就只有一个math的count数,对这一个数去重等于没去重
mysql> select distinct count(math) from exam_result;
+-------------+
| count(math) |
+-------------+
| 5 |
+-------------+
1 row in set (0.00 sec)统计数学成绩总分
c
mysql> select sum(math) from exam_result;
+-----------+
| sum(math) |
+-----------+
| 454 |
+-----------+
1 row in set (0.00 sec)
--计算不及格 < 60 的总分,没有结果,返回 NULL
mysql> select sum(math) from exam_result where math < 60;
+-----------+
| sum(math) |
+-----------+
| NULL |
+-----------+
1 row in set (0.00 sec)统计平均总分
c
mysql> select avg(chinese + math + english) 平均总分 from exam_result;
+--------------+
| 平均总分 |
+--------------+
| 303 |
+--------------+
1 row in set (0.01 sec)返回英语最高分
c
mysql> select max(english) from exam_result;
+--------------+
| max(english) |
+--------------+
| 90 |
+--------------+
1 row in set (0.00 sec)返回 > 70 分以上的数学最低分
c
mysql> select min(math) from exam_result where math > 70;
+-----------+
| min(math) |
+-----------+
| 73 |
+-----------+
1 row in set (0.01 sec)group by子句的使用
在select中使用group by 子句可以对指定列进行分组查询
c
select column1, column2, .. from table group by column;分组的目的是为了进行分组之后,方便进行聚合统计
例子:
c
mysql> show tables;
+-----------------+
| Tables_in_scott |
+-----------------+
| dept |
| emp |
| salgrade |
+-----------------+
3 rows in set (0.00 sec)
mysql> select * from dept;
+--------+------------+----------+
| deptno | dname | loc |
+--------+------------+----------+
| 10 | ACCOUNTING | NEW YORK |
| 20 | RESEARCH | DALLAS |
| 30 | SALES | CHICAGO |
| 40 | OPERATIONS | BOSTON |
+--------+------------+----------+
4 rows in set (0.00 sec)
mysql> select * from emp;
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| empno | ename | job | mgr | hiredate | sal | comm | deptno |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
| 007369 | SMITH | CLERK | 7902 | 1980-12-17 00:00:00 | 800.00 | NULL | 20 |
| 007499 | ALLEN | SALESMAN | 7698 | 1981-02-20 00:00:00 | 1600.00 | 300.00 | 30 |
| 007521 | WARD | SALESMAN | 7698 | 1981-02-22 00:00:00 | 1250.00 | 500.00 | 30 |
| 007566 | JONES | MANAGER | 7839 | 1981-04-02 00:00:00 | 2975.00 | NULL | 20 |
| 007654 | MARTIN | SALESMAN | 7698 | 1981-09-28 00:00:00 | 1250.00 | 1400.00 | 30 |
| 007698 | BLAKE | MANAGER | 7839 | 1981-05-01 00:00:00 | 2850.00 | NULL | 30 |
| 007782 | CLARK | MANAGER | 7839 | 1981-06-09 00:00:00 | 2450.00 | NULL | 10 |
| 007788 | SCOTT | ANALYST | 7566 | 1987-04-19 00:00:00 | 3000.00 | NULL | 20 |
| 007839 | KING | PRESIDENT | NULL | 1981-11-17 00:00:00 | 5000.00 | NULL | 10 |
| 007844 | TURNER | SALESMAN | 7698 | 1981-09-08 00:00:00 | 1500.00 | 0.00 | 30 |
| 007876 | ADAMS | CLERK | 7788 | 1987-05-23 00:00:00 | 1100.00 | NULL | 20 |
| 007900 | JAMES | CLERK | 7698 | 1981-12-03 00:00:00 | 950.00 | NULL | 30 |
| 007902 | FORD | ANALYST | 7566 | 1981-12-03 00:00:00 | 3000.00 | NULL | 20 |
| 007934 | MILLER | CLERK | 7782 | 1982-01-23 00:00:00 | 1300.00 | NULL | 10 |
+--------+--------+-----------+------+---------------------+---------+---------+--------+
14 rows in set (0.00 sec)
mysql> select * from salgrade;
+-------+-------+-------+
| grade | losal | hisal |
+-------+-------+-------+
| 1 | 700 | 1200 |
| 2 | 1201 | 1400 |
| 3 | 1401 | 2000 |
| 4 | 2001 | 3000 |
| 5 | 3001 | 9999 |
+-------+-------+-------+
5 rows in set (0.00 sec)各种例子
显示平均工资和最高工资
c
mysql> select avg(sal), max(sal) from emp;
+-------------+----------+
| avg(sal) | max(sal) |
+-------------+----------+
| 2073.214286 | 5000.00 |
+-------------+----------+
1 row in set (0.00 sec)显示每个部门 的平均工资和最高工资
group by 列名指定列名,实际分组是用该列的不同的行的数据来进行分组的。
c
mysql> select deptno, avg(sal), max(sal) from emp group by deptno;
+--------+-------------+----------+
| deptno | avg(sal) | max(sal) |
+--------+-------------+----------+
| 20 | 2175.000000 | 3000.00 |
| 30 | 1566.666667 | 2850.00 |
| 10 | 2916.666667 | 5000.00 |
+--------+-------------+----------+
3 rows in set (0.01 sec)分组就是把一组按条件拆分成了多个组,进行各自组内的统计。
理解:分组("分表"),就是把一张表按照条件在逻辑上拆分成了多个子表,然后分别对各自子表进行聚合统计。
显示每个部门 的每种岗位 的平均工资和最低工资
分两组:1.按部门 2.按岗位
c
mysql> select deptno, job, avg(sal), min(sal) from emp group by deptno, job order by deptno;
+--------+-----------+-------------+----------+
| deptno | job | avg(sal) | min(sal) |
+--------+-----------+-------------+----------+
| 10 | CLERK | 1300.000000 | 1300.00 |
| 10 | MANAGER | 2450.000000 | 2450.00 |
| 10 | PRESIDENT | 5000.000000 | 5000.00 |
| 20 | ANALYST | 3000.000000 | 3000.00 |
| 20 | CLERK | 950.000000 | 800.00 |
| 20 | MANAGER | 2975.000000 | 2975.00 |
| 30 | CLERK | 950.000000 | 950.00 |
| 30 | MANAGER | 2850.000000 | 2850.00 |
| 30 | SALESMAN | 1400.000000 | 1250.00 |
+--------+-----------+-------------+----------+
9 rows in set (0.00 sec)显示平均工资低于2000的部门和它的平均工资
- 统计各个部门的平均工资
c
mysql> select avg(sal) from emp group by deptno;
+-------------+
| avg(sal) |
+-------------+
| 2175.000000 |
| 1566.666667 |
| 2916.666667 |
+-------------+
3 rows in set (0.00 sec)- 对聚合出来的结果进行判断
c
--having和group by配合使用,对group by结果进行过滤,作用有些像where。
mysql> select avg(sal) from emp group by deptno having avg(sal)<2000;
+-------------+
| avg(sal) |
+-------------+
| 1566.666667 |
+-------------+
1 row in set (0.01 sec)having & where 区别的理解
筛选条件的阶段是不同的。
例子:SMITH员工不参与统计,显示平均工资低于2000的部门和它的平均工资
c
mysql> select deptno,job,avg(sal) myavg from emp where ename != 'SMITH' group by deptno, job having myavg < 2000;
+--------+----------+-------------+
| deptno | job | myavg |
+--------+----------+-------------+
| 30 | SALESMAN | 1400.000000 |
| 20 | CLERK | 1100.000000 |
| 30 | CLERK | 950.000000 |
| 10 | CLERK | 1300.000000 |
+--------+----------+-------------+
4 rows in set (0.00 sec)执行顺序
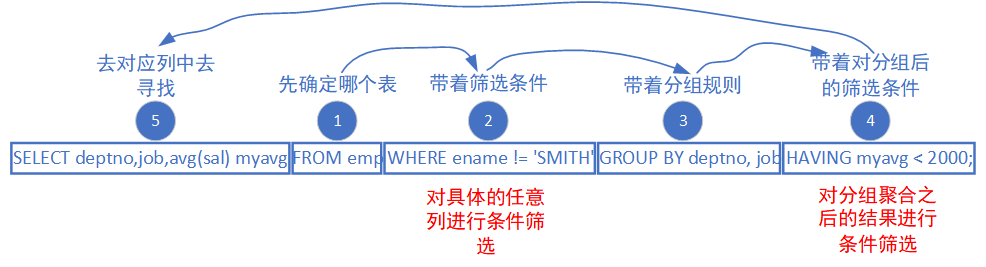
例子:SMITH员工不参与统计,显示平均工资低于2000的部门和它的平均工资,按平均分 myavg 降序排序,只取前 5 条结果
c
mysql> SELECT deptno, job, AVG(sal) myavg
-> FROM emp
-> WHERE ename != 'SMITH'
-> GROUP BY deptno, job
-> HAVING myavg < 2000
-> ORDER BY myavg DESC -- 放在HAVING之后,对筛选后的结果排序
-> LIMIT 5; -- 放在最后,限制返回的行数
+--------+----------+-------------+
| deptno | job | myavg |
+--------+----------+-------------+
| 30 | SALESMAN | 1400.000000 |
| 10 | CLERK | 1300.000000 |
| 20 | CLERK | 1100.000000 |
| 30 | CLERK | 950.000000 |
+--------+----------+-------------+
4 rows in set (0.00 sec)执行顺序
- FROM(找数据源):先找到公司的员工花名册(emp 表)------ 第一步必须先有数据来源;
- WHERE(初筛行):先把花名册里叫 SMITH 的人删掉 ------ 筛行是分组前的基础操作;
- GROUP BY(分组):把剩下的人按 "部门(deptno)+ 岗位(job)" 分成若干小组(比如 "部门 10 + 文员" 一组、"部门 20 + 分析师" 一组);
- 聚合计算:给每个小组算平均工资(AVG (sal))------ 这一步才算出 "myavg" 这个值;
- HAVING(筛分组):把平均工资≥2000 的小组直接剔除 ------ 此时只保留符合条件的小组,还没决定要展示哪些列;
- SELECT(选列):从剩下的小组里,只提取 "部门、岗位、平均工资" 这三列(并把平均工资命名为 myavg)------ 这一步才是 "选择要展示的内容";
- ORDER BY(排序):把选出来的结果按平均工资降序排列;
- LIMIT(限行):只取排序后的前 5 个小组。

总结SQL语句的书写顺序与执行顺序
| 名称 | 顺序 |
|---|---|
| 书写顺序 | SELECT → FROM → WHERE → GROUP BY → HAVING → ORDER BY → LIMIT |
| 执行顺序 | FROM → WHERE → GROUP BY → 聚合 → HAVING → SELECT → ORDER BY → LIMIT |