在大模型应用开发中,单纯依靠模型的训练数据早已无法满足实际业务需求 ------ 我们需要让模型能查天气、调接口、执行自定义代码,甚至对接企业内部系统。OpenAI 推出的函数调用(Function Calling,也叫工具调用 Tool Calling) 正是解决这一问题的核心能力,它让大模型突破训练数据的边界,能与外部系统灵活交互,把 AI 的推理能力和实际业务的工具能力结合起来。
这篇文章将基于 OpenAI 官方指南,用通俗易懂的方式讲清函数调用的工作原理、实操步骤、核心配置和最佳实践,从基础的函数定义到高级的自定义工具、语法约束,再到真实落地的应用案例,一站式掌握这一核心开发技能。
一、函数调用的核心概念:搞懂这几个词就入门
在开始实操前,先明确 OpenAI 函数调用体系中的核心术语,避免概念混淆:
-
工具(Tool):我们赋予模型的可执行功能,既可以是查询天气、获取星座运势的简单函数,也可以是执行代码、调用 API 的复杂能力;
-
工具调用(Tool Calling):模型根据用户需求,向指定工具发出的执行请求;
-
工具调用输出(Tool Calling Output):工具执行后返回的结果,需要回传给模型做后续处理;
-
函数工具(Function Tool):基于 JSON Schema 定义的标准化工具,是最常用的工具类型,模型会按固定格式发起调用;
-
自定义工具(Custom Tool):无需严格 JSON 格式,支持自由文本输入的工具,可通过语法约束实现定制化输入格式。
简单来说,函数调用的本质,就是让应用程序和 OpenAI 模型通过 API 完成多轮交互,让模型决定何时调用、调用哪个工具,应用程序执行工具并返回结果,最终模型基于结果生成用户能理解的答案。
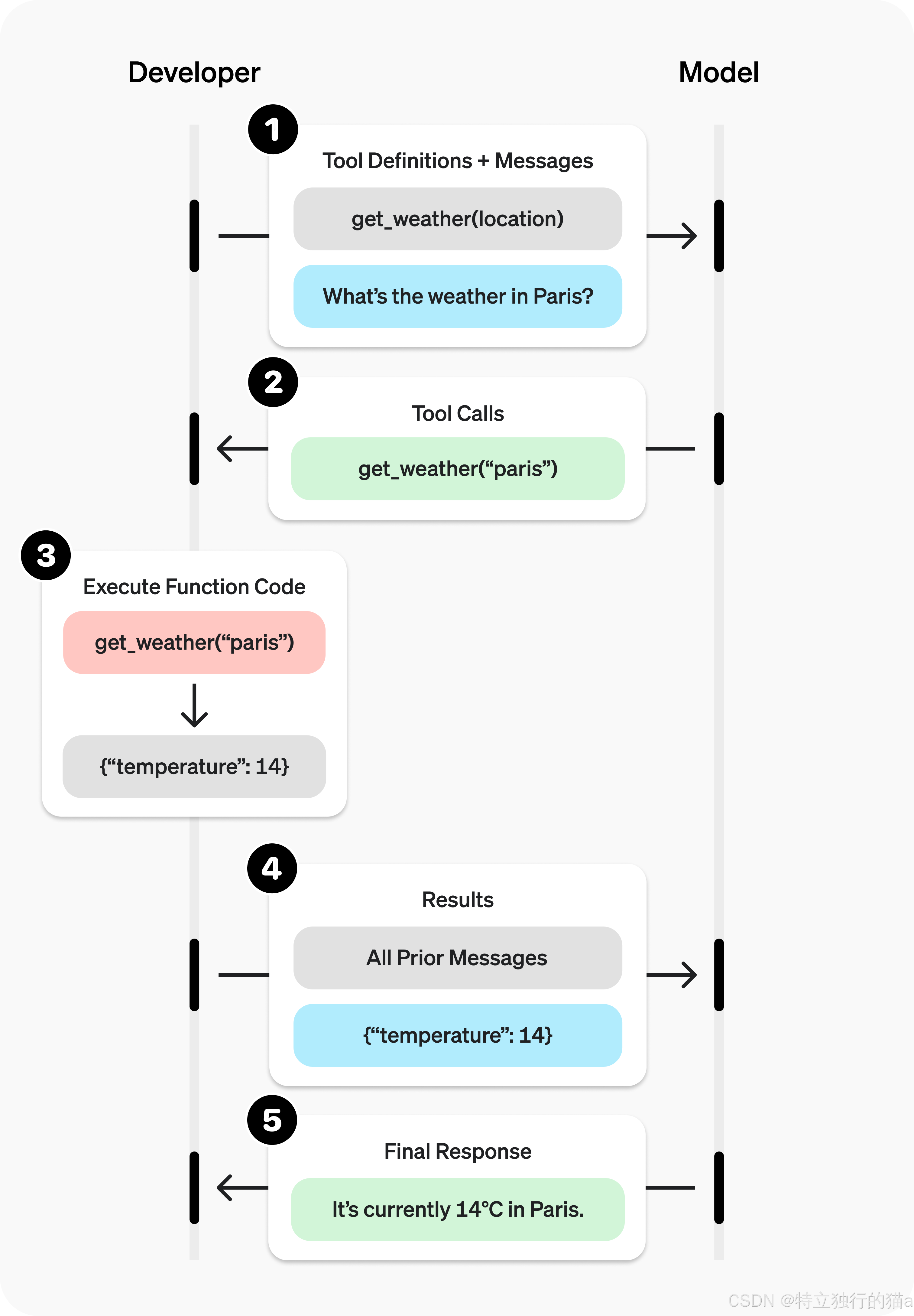
二、函数调用的通用流程:五步走实现模型与工具联动
无论是什么类型的工具,OpenAI 的函数调用都遵循一套标准化的五步流程,这是整个能力的核心框架,所有实操都基于此展开:
-
发起带工具的请求:向 OpenAI 模型发送用户请求时,附带模型可调用的工具列表(定义工具的功能、参数、格式);
-
接收模型的工具调用:模型分析用户需求后,返回工具调用请求(可能是 0 个、1 个或多个,需考虑多调用场景);
-
应用端执行工具:解析模型的调用请求,提取工具名称和参数,在应用程序中执行对应的代码 / 逻辑;
-
回传工具执行结果:将工具执行后的输出结果,以指定格式追加到请求中,再次向模型发起请求;
-
接收模型最终响应:模型基于工具执行结果,生成最终的自然语言响应;若模型判断结果不足,会返回更多工具调用请求,重复 2-4 步。
这套流程的核心是 "模型做决策,应用做执行",模型负责判断是否需要调用工具、调用哪个,而具体的执行逻辑由开发者控制,既保证了灵活性,也让业务逻辑更安全可控。
三、快速上手:函数工具的端到端实操示例
函数工具是 OpenAI 函数调用中最基础、最常用的类型,基于 JSON Schema 定义,适合绝大多数标准化的工具需求。下面以获取星座每日运势为例,通过完整的 Python 代码,演示函数工具的实际使用(基于 OpenAI 官方 SDK)。
3.1 核心准备:定义函数工具和执行逻辑
首先需要定义模型可调用的工具列表(按 JSON Schema 规范),并实现工具对应的本地执行函数:
python
from openai import OpenAI
import json
# 初始化OpenAI客户端
client = OpenAI()
# 1. 定义模型可调用的函数工具列表
tools = [
{
"type": "function", # 工具类型固定为function
"name": "get_horoscope", # 函数名称,需与本地执行函数一致
"description": "Get today's horoscope for an astrological sign.", # 函数描述,越详细模型判断越准确
"parameters": { # 函数参数,基于JSON Schema定义
"type": "object",
"properties": {
"sign": {
"type": "string",
"description": "An astrological sign like Taurus or Aquarius", # 参数描述,明确参数含义
},
},
"required": ["sign"], # 必传参数,模型会强制按此传参
},
},
]
# 定义工具对应的本地执行逻辑
def get_horoscope(sign):
# 模拟星座运势查询,实际场景可替换为API调用、数据库查询等
return f"{sign}: Next Tuesday you will befriend a baby otter."3.2 执行函数调用流程:按五步走实现交互
python
# 初始化输入列表,存储用户请求和后续的工具调用/输出
input_list = [
{"role": "user", "content": "What is my horoscope? I am an Aquarius."}
]
# 2. 向模型发起带工具的请求
response = client.responses.create(
model="gpt-5", # 支持函数调用的模型,如gpt-5、gpt-4.1、o4-mini等
tools=tools,
input=input_list,
)
# 将模型的工具调用结果追加到输入列表
input_list += response.output
# 3. 解析工具调用并执行本地逻辑
for item in response.output:
if item.type == "function_call" and item.name == "get_horoscope":
# 提取函数参数并执行
args = json.loads(item.arguments)
horoscope_result = get_horoscope(**args)
# 4. 将工具执行结果按格式追加到输入列表
input_list.append({
"type": "function_call_output",
"call_id": item.call_id, # 与工具调用的call_id对应,模型用于匹配结果
"output": json.dumps({"horoscope": horoscope_result})
})
# 向模型发起二次请求,传入工具执行结果
final_response = client.responses.create(
model="gpt-5",
instructions="Respond only with a horoscope generated by a tool.", # 系统提示,约束模型输出
tools=tools,
input=input_list,
)
# 5. 输出模型最终响应
print("Final output:")
print(final_response.model_dump_json(indent=2))
print("n" + final_response.output_text)3.3 关键说明
-
函数工具的描述是核心 :模型会根据
description判断何时调用该函数,描述越详细、越贴合用户需求场景,模型的调用准确率越高; -
必传参数需明确
required:模型会按规范传参,避免因参数缺失导致工具执行失败; -
工具执行结果需带
call_id:模型通过call_id匹配工具调用和执行结果,多工具调用时不可缺少。
四、函数定义的核心规范与最佳实践
函数工具的定义质量直接决定模型的调用准确率,OpenAI 官方给出了一套标准化的定义规范和落地最佳实践,开发者需严格遵循,减少模型调用错误。
4.1 函数定义的标准化属性
每个函数工具都需在tools列表中按固定属性定义,核心属性如下:
| 属性 | 类型 | 描述 |
|---|---|---|
| type | 字符串 | 固定为function,标识工具类型 |
| name | 字符串 | 函数名称,唯一标识,需与本地执行函数一致,建议使用英文小写 + 下划线 |
| description | 字符串 | 函数的用途描述,明确 "何时 / 为何使用该函数",是模型判断的关键 |
| parameters | 对象 | 基于 JSON Schema 定义的参数,包含参数类型、属性、必传项等 |
| strict | 布尔值 | 是否开启严格模式,开启后模型会严格遵循参数规范,建议始终设为true |
其中parameters支持 JSON Schema 的丰富功能,如属性类型、枚举、嵌套对象、可选参数(通过type: ["string", "null"]定义)等,例如查询天气的函数可定义枚举参数units: ["celsius", "fahrenheit"],约束模型传参范围。
4.2 函数定义的落地最佳实践
-
描述要清晰具体:明确函数的用途、每个参数的含义和格式、输出结果的类型,避免模糊表述;
-
用好系统提示 :通过
instructions告诉模型 "何时调用、何时不调用" 该函数,比如 "仅当用户询问天气时,调用 get_weather 函数"; -
遵循软件工程原则 :函数功能单一,避免一个函数处理多个逻辑;参数设计遵循 "最小惊讶原则",比如不要设计
toggle_light(on: bool, off: bool)这种可能出现无效调用的参数; -
减轻模型负担:模型已知的参数(如用户 ID、订单 ID)无需作为函数参数,直接在本地代码中传递,避免模型重复处理;
-
合并连续调用的函数 :如果总是先调用
mark_location()再调用query_location(),直接将标记逻辑整合到查询函数中,减少模型调用次数; -
控制函数数量:函数数量越多,模型的判断难度越大,建议按业务场景拆分,单次请求的函数数量不宜过多,可通过测试评估最优数量。
4.3 令牌使用优化
函数定义会被注入到系统消息中,占用模型的上下文令牌,若遇到令牌限制,可通过两种方式优化:
-
精简函数的
description和参数描述,去掉冗余信息; -
若有大量函数需要定义,可通过微调模型,减少函数定义占用的令牌数量。
五、高级配置:严格模式、并行调用、流式调用
掌握基础的函数定义后,还需要了解 OpenAI 函数调用的高级配置,适配复杂的业务场景,提升调用的稳定性和灵活性。
5.1 严格模式:强制模型遵循参数规范
开启strict: true后,模型会严格按照 JSON Schema 定义的参数发起调用,避免 "尽力而为" 的不规范传参,建议所有场景都开启。
严格模式的核心要求
-
parameters中的每个对象都需设置additionalProperties: false,禁止模型传递未定义的参数; -
所有
properties中的字段都需标记为required,可选参数通过type: [参数类型, null]定义; -
若请求的模式不符合要求,API 会直接拒绝请求,并返回缺失的约束信息。
严格模式的示例
json
{
"type": "function",
"name": "get_weather",
"description": "Retrieves current weather for the given location.",
"strict": true,
"parameters": {
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "City and country e.g. Bogotá, Colombia"
},
"units": {
"type": ["string", "null"], // 可选参数,支持null
"enum": ["celsius", "fahrenheit"],
"description": "Units the temperature will be returned in."
}
},
"required": ["location", "units"],
"additionalProperties": false
}
}5.2 工具调用的控制:tool_choice 参数
默认情况下,模型会自动决定是否调用工具、调用多少个(tool_choice: "auto"),开发者可通过tool_choice参数强制控制模型的调用行为,适配不同业务场景:
-
auto(默认):模型自主判断,可调用 0 个、1 个或多个工具; -
required:强制模型调用至少一个工具,适用于 "必须通过工具获取结果" 的场景,如查询实时天气; -
{"type": "function", "name": "xxx"}:强制模型调用指定的单个函数,适用于业务逻辑固定的场景; -
allowed_tools:限制模型只能调用指定的工具子集,无需修改原始tools列表,节省资源; -
none:禁止模型调用任何工具,等同于不传递tools参数的普通请求。
5.3 并行函数调用:控制多工具调用行为
模型支持在一次回合中调用多个函数(并行调用),若需要禁止并行,可设置parallel_tool_calls: false,确保模型每次只调用 0 个或 1 个工具。
注意:gpt-4.1-nano-2025-04-14 等轻量模型开启并行调用时,可能会重复调用同一个工具,建议这类模型禁用并行调用。
5.4 流式函数调用:实时获取模型调用进度
和 OpenAI 的流式响应一样,函数调用也支持流式传输,通过设置stream: true,可以实时获取模型的工具调用过程,包括函数名称、参数的拼接过程,适合需要展示加载进度的前端场景。
流式调用的核心是解析模型返回的事件流,关键事件类型包括:
-
response.output_item.added:模型开始发起工具调用,返回函数名称、初始参数; -
response.function_call_arguments.delta:模型逐步拼接函数参数,返回参数的增量内容; -
response.function_call_arguments.done:函数参数拼接完成,返回完整的调用参数; -
response.output_item.done:工具调用完成,返回完整的工具调用对象。
开发者只需将增量的参数内容拼接,即可得到完整的工具调用请求,实现实时处理。
六、进阶玩法:自定义工具与语法约束
基础的函数工具适合标准化场景,但实际开发中,我们可能需要模型输出自由文本(如执行 Python 代码、生成指定格式的字符串),此时自定义工具(Custom Tool) 就是最佳选择。
6.1 自定义工具的核心特点
-
工具类型为
custom,无需定义严格的 JSON Schema 参数,模型可返回任意自由文本作为工具输入; -
支持通过上下文无关文法(CFG) 约束模型的输入格式,避免模型输出无意义的内容;
-
工具调用类型为
custom_tool_call,解析逻辑与函数工具略有差异,但整体流程仍遵循五步走。
6.2 自定义工具的基础示例:执行 Python 代码
python
from openai import OpenAI
client = OpenAI()
# 发起带自定义工具的请求
response = client.responses.create(
model="gpt-5",
input="Use the code_exec tool to print hello world to the console.",
tools=[
{
"type": "custom", # 工具类型为custom
"name": "code_exec", # 自定义工具名称
"description": "Executes arbitrary Python code.", # 工具描述
}
]
)
# 输出模型的自定义工具调用结果
print(response.output)模型会返回custom_tool_call类型的结果,其中input字段为纯文本的 Python 代码print("hello world"),开发者只需解析该字段并执行即可。
6.3 语法约束:用 CFG 规范自定义工具的输入格式
为了避免模型输出的自由文本不符合业务要求,OpenAI 支持为自定义工具配置上下文无关文法(CFG) ,通过语法规则约束模型的输入格式,目前支持两种 CFG 语法:Lark (适合复杂的结构化语法)和Regex(适合简单的正则匹配)。
示例 1:Lark CFG 约束数学表达式格式
python
from openai import OpenAI
client = OpenAI()
# 定义Lark语法规则:仅允许生成数字+加减乘除的数学表达式
grammar = """
start: expr
expr: term (SP ADD SP term)* -> add
| term
term: factor (SP MUL SP factor)* -> mul
| factor
factor: INT
SP: " "
ADD: "+"
MUL: "*"
%import common.INT
"""
# 带Lark语法约束的自定义工具
response = client.responses.create(
model="gpt-5",
input="Use the math_exp tool to add four plus four.",
tools=[
{
"type": "custom",
"name": "math_exp",
"description": "Creates valid mathematical expressions",
"format": {
"type": "grammar",
"syntax": "lark", # 语法类型为lark
"definition": grammar, # 语法规则
},
}
]
)
print(response.output)模型会严格遵循 Lark 语法,输出4 + 4而非其他格式,确保工具输入的规范性。
示例 2:Regex CFG 约束时间戳格式
python
from openai import OpenAI
client = OpenAI()
# 定义正则规则:匹配「月份 日期 年份 at 时间AM/PM」的格式
grammar = r"^(?P<month>January|February|March)s+(?P<day>d{1,2})(?:st|nd|rd|th)?s+(?P<year>d{4})s+ats+(?P?[1-9]|1[0-2])(?Pm>AM|PM)$"
# 带正则语法约束的自定义工具
response = client.responses.create(
model="gpt-5",
input="Use the timestamp tool to save a timestamp for August 7th 2025 at 10AM.",
tools=[
{
"type": "custom",
"name": "timestamp",
"description": "Saves a timestamp in date + time format.",
"format": {
"type": "grammar",
"syntax": "regex", # 语法类型为regex
"definition": grammar,
},
}
]
)
print(response.output)模型会输出符合正则规则的时间戳字符串,避免格式混乱。
6.4 CFG 语法的最佳实践
-
Lark 语法适合复杂结构,Regex 适合简单匹配:若需要约束多层嵌套的结构化内容,用 Lark;若只是简单的字符串格式匹配,用 Regex 更高效;
-
语法规则尽量简化:过于复杂的语法会导致 API 拒绝请求,且模型的生成准确率会下降;
-
避免无界量词 :正则中尽量用
{0,10}等有界量词代替*,防止模型输出过长内容; -
显式处理空白字符:不要依赖开放式的忽略指令,用显式的规则约束空格、换行,提升语法的稳定性。
七、实际应用案例:函数调用的落地场景
理论学习后,结合真实场景的案例能更深刻理解函数调用的价值。下面选取 3 个高频应用场景,每个案例包含完整代码和核心解析,可直接复用或修改适配自身业务。
7.1 场景 1:实时天气查询(对接第三方 API)
场景说明:用户询问某个城市的实时天气,模型调用第三方天气 API 获取数据,再整理成自然语言回复。这里使用「高德地图天气 API」(需提前申请 key)。
完整代码
python
from openai import OpenAI
import json
import requests
# 初始化OpenAI客户端和天气API配置
client = OpenAI()
AMAP_WEATHER_API = "https://restapi.amap.com/v3/weather/weatherInfo"
AMAP_API_KEY = "你的高德地图APIKey" # 替换为自己的key
# 1. 定义天气查询函数工具
tools = [
{
"type": "function",
"name": "get_real_time_weather",
"description": "查询指定城市的实时天气,返回温度、天气状况、风力等信息",
"strict": True,
"parameters": {
"type": "object",
"properties": {
"city": {
"type": "string",
"description": "城市名称,如北京、上海、广州(仅支持中国城市)"
},
"extensions": {
"type": ["string", "null"],
"enum": ["base", "all"],
"description": "返回信息类型:base(基础天气)、all(详细天气),默认base"
}
},
"required": ["city"],
"additionalProperties": False
}
}
]
# 2. 实现天气API调用逻辑
def get_real_time_weather(city, extensions="base"):
params = {
"key": AMAP_API_KEY,
"city": city,
"extensions": extensions,
"output": "json"
}
response = requests.get(AMAP_WEATHER_API, params=params)
result = response.json()
if result["status"] != "1":
return f"天气查询失败:{result.get('info', '未知错误')}"
# 解析返回结果
lives = result["lives"][0]
return {
"city": lives["city"],
"temperature": lives["temperature"],
"weather": lives["weather"],
"windDirection": lives["winddirection"],
"windPower": lives["windpower"],
"humidity": lives["humidity"],
"reportTime": lives["reporttime"]
}
# 3. 执行函数调用流程
input_list = [{"role": "user", "content": "查询深圳今天的天气,要详细信息"}]
# 第一步:发起带工具的请求
response = client.responses.create(
model="gpt-4.1",
tools=tools,
input=input_list,
instructions="用户询问天气时,必须调用get_real_time_weather函数,extensions参数根据用户需求选择"
)
input_list += response.output
# 第二步:解析工具调用并执行
for item in response.output:
if item.type == "function_call" and item.name == "get_real_time_weather":
args = json.loads(item.arguments)
weather_data = get_real_time_weather(**args)
# 追加执行结果
input_list.append({
"type": "function_call_output",
"call_id": item.call_id,
"output": json.dumps(weather_data, ensure_ascii=False)
})
# 第三步:获取最终响应
final_response = client.responses.create(
model="gpt-4.1",
input=input_list,
tools=tools,
instructions="将天气数据整理成自然语言,清晰展示温度、天气状况、风力、湿度和更新时间"
)
print("最终回复:")
print(final_response.output_text)关键解析
-
对接第三方 API 时,函数工具的
description需明确 "支持的城市范围""返回信息类型",避免模型传入无效参数; -
异常处理:API 调用失败时返回友好提示,模型会将错误信息告知用户;
-
系统提示
instructions强制模型 "必须调用工具",避免模型直接编造天气数据(大模型无法获取实时信息)。
7.2 场景 2:电商订单查询(对接数据库)
场景说明:用户作为电商平台用户,询问自己的订单状态,模型调用数据库查询工具,根据用户 ID 和订单号获取订单信息,再回复用户。这里用 SQLite 模拟数据库。
完整代码
python
from openai import OpenAI
import json
import sqlite3
# 初始化OpenAI客户端和数据库
client = OpenAI()
DB_NAME = "ecommerce.db"
# 1. 初始化数据库(模拟订单数据)
def init_db():
conn = sqlite3.connect(DB_NAME)
cursor = conn.cursor()
# 创建订单表
cursor.execute('''
CREATE TABLE IF NOT EXISTS orders (
order_id TEXT PRIMARY KEY,
user_id TEXT NOT NULL,
product_name TEXT NOT NULL,
create_time TEXT NOT NULL,
status TEXT NOT NULL,
total_amount REAL NOT NULL
)
''')
# 插入测试数据
test_data = [
("ORDER20250101001", "USER123", "iPhone 15 Pro", "2025-01-01 10:30:00", "已发货", 7999.00),
("ORDER20250102002", "USER123", "AirPods Pro 2", "2025-01-02 14:20:00", "已签收", 1999.00),
("ORDER20250103003", "USER456", "MacBook Air", "2025-01-03 09:15:00", "待付款", 8999.00)
]
cursor.executemany('''
INSERT OR IGNORE INTO orders (order_id, user_id, product_name, create_time, status, total_amount)
VALUES (?, ?, ?, ?, ?, ?)
''', test_data)
conn.commit()
conn.close()
# 2. 定义订单查询函数工具
tools = [
{
"type": "function",
"name": "query_order",
"description": "查询电商平台用户的订单状态,需提供用户ID和订单号",
"strict": True,
"parameters": {
"type": "object",
"properties": {
"user_id": {
"type": "string",
"description": "用户唯一标识,如USER123、USER456"
},
"order_id": {
"type": "string",
"description": "订单号,如ORDER20250101001"
}
},
"required": ["user_id", "order_id"],
"additionalProperties": False
}
}
]
# 3. 实现数据库查询逻辑
def query_order(user_id, order_id):
conn = sqlite3.connect(DB_NAME)
cursor = conn.cursor()
cursor.execute('''
SELECT order_id, product_name, create_time, status, total_amount
FROM orders
WHERE user_id = ? AND order_id = ?
''', (user_id, order_id))
result = cursor.fetchone()
conn.close()
if not result:
return f"未查询到订单:用户ID={user_id},订单号={order_id}"
return {
"order_id": result[0],
"product_name": result[1],
"create_time": result[2],
"status": result[3],
"total_amount": result[4]
}
# 4. 执行流程(模拟用户查询)
init_db() # 初始化数据库
input_list = [{"role": "user", "content": "我是USER123,查询订单号ORDER20250101001的状态"}]
# 发起工具请求
response = client.responses.create(
model="gpt-4.1",
tools=tools,
input=input_list,
instructions="用户查询订单时,必须提取user_id和order_id参数,调用query_order函数"
)
input_list += response.output
# 执行工具并回传结果
for item in response.output:
if item.type == "function_call" and item.name == "query_order":
args = json.loads(item.arguments)
order_data = query_order(**args)
input_list.append({
"type": "function_call_output",
"call_id": item.call_id,
"output": json.dumps(order_data, ensure_ascii=False)
})
# 获取最终回复
final_response = client.responses.create(
model="gpt-4.1",
input=input_list,
tools=tools,
instructions="用亲切的语气回复用户订单状态,包含商品名称、创建时间、状态和金额"
)
print("最终回复:")
print(final_response.output_text)关键解析
-
参数提取:模型自动从用户的自然语言中提取
user_id和order_id,无需用户按固定格式输入; -
数据安全:数据库查询逻辑在应用端执行,模型无法直接操作数据库,避免数据泄露;
-
实用性:可扩展为 "订单物流查询""退款申请" 等联动工具,形成电商客服闭环。
7.3 场景 3:PDF 内容提取(自定义工具 + 本地文件处理)
场景说明 :用户需要提取本地 PDF 文件中的指定内容(如 "第三章的核心观点"),模型调用自定义工具,执行 PDF 解析逻辑,返回提取结果。这里使用PyPDF2库处理 PDF。
完整代码
python
from openai import OpenAI
import json
from PyPDF2 import PdfReader
# 安装依赖:pip install PyPDF2
client = OpenAI()
# 1. 定义PDF提取自定义工具(带Lark语法约束)
# 语法规则:仅允许输入「文件名+提取范围」格式
pdf_grammar = """
start: pdf_request
pdf_request: filename SP extract_scope
filename: /[A-Za-z0-9_]+.pdf/ # 匹配PDF文件名
extract_scope: "整本书" | "第" INT "章" | "第" INT "页" | "关键词:" /[A-Za-z0-9u4e00-u9fa5]+/
SP: " "
%import common.INT
"""
tools = [
{
"type": "custom",
"name": "pdf_content_extractor",
"description": "提取本地PDF文件的指定内容,支持整本书、指定章节、指定页码、关键词匹配",
"format": {
"type": "grammar",
"syntax": "lark",
"definition": pdf_grammar
}
}
]
# 2. 实现PDF提取逻辑
def pdf_content_extractor(input_text):
# 解析输入格式:filename 提取范围
parts = input_text.split(" ", 1)
filename = parts[0]
extract_scope = parts[1]
try:
# 打开PDF文件
reader = PdfReader(filename)
total_pages = len(reader.pages)
content = []
# 根据提取范围提取内容
if extract_scope == "整本书":
for page in reader.pages:
content.append(page.extract_text())
elif extract_scope.startswith("第") and "章" in extract_scope:
# 简化处理:假设每章对应连续页码(实际需根据PDF结构调整)
chapter_num = int(extract_scope.replace("第", "").replace("章", ""))
# 模拟章节对应页码:第1章=1-5页,第2章=6-10页...
start_page = (chapter_num - 1) * 5
end_page = min(chapter_num * 5 - 1, total_pages - 1)
for i in range(start_page, end_page + 1):
content.append(reader.pages[i].extract_text())
elif extract_scope.startswith("第") and "页" in extract_scope:
page_num = int(extract_scope.replace("第", "").replace("页", "")) - 1 # 转为0索引
if 0 page_num
content.append(reader.pages[page_num].extract_text())
else:
return f"页码超出范围,PDF共{total_pages}页"
elif extract_scope.startswith("关键词:"):
keyword = extract_scope.replace("关键词:", "")
for page in reader.pages:
page_text = page.extract_text()
if keyword in page_text:
content.append(f"第{reader.pages.index(page)+1}页:{page_text[:200]}...") # 截取前200字
return {
"filename": filename,
"extract_scope": extract_scope,
"total_pages": total_pages,
"content": "nn".join(content) if content else "未提取到内容"
}
except FileNotFoundError:
return f"文件不存在:{filename}"
except Exception as e:
return f"PDF提取失败:{str(e)}"
# 3. 执行流程
input_list = [{"role": "user", "content": "帮我提取test.pdf中第3章的核心观点,用自定义工具处理"}]
# 发起工具请求
response = client.responses.create(
model="gpt-5",
tools=tools,
input=input_list,
instructions="必须使用pdf_content_extractor工具,输入格式严格遵循语法规则,如test.pdf 第3章"
)
input_list += response.output
# 解析自定义工具调用并执行
for item in response.output:
if item.type == "custom_tool_call" and item.name == "pdf_content_extractor":
extract_input = item.input
extract_result = pdf_content_extractor(extract_input)
# 追加执行结果
input_list.append({
"type": "custom_tool_call_output",
"call_id": item.call_id,
"output": json.dumps(extract_result, ensure_ascii=False)
})
# 获取最终回复
final_response = client.responses.create(
model="gpt-5",
input=input_list,
tools=tools,
instructions="将PDF提取的内容整理成清晰的结构,突出核心观点,去除冗余信息"
)
print("最终回复:")
print(final_response.output_text)关键解析
-
自定义工具 + 语法约束:通过 Lark 语法限制输入格式,避免模型输出无效的文件路径或提取范围;
-
本地文件处理:工具执行逻辑在本地,无需上传文件到 OpenAI,保护文件隐私;
-
扩展性:可扩展为 "PDF 转文字""PDF 表格提取" 等子工具,通过
allowed_tools控制模型调用范围。
八、常见疑问解答:函数调用与 MCP 的关系
在函数调用学习过程中,很多开发者会混淆「函数调用」与「MCP(Model Control Plane)」,核心原因是二者都涉及 "模型与外部系统交互",但本质是完全不同的概念 ------函数调用是 OpenAI 提供的 "模型能力",MCP 是第三方 / 自建的 "中间件服务",二者是 "能力" 与 "载体" 的关系,而非同一事物。
8.1 核心概念定义
1. 函数调用(Function Calling)
-
本质:OpenAI 模型(如 gpt-4.1、gpt-5)内置的「决策与交互能力」------ 模型能理解用户需求,判断是否需要调用外部工具(如查天气、查订单),并按 JSON Schema 规范输出调用指令(如函数名、参数)。
-
核心作用:解决 "模型如何与外部工具对话" 的问题,是模型侧的 "接口协议" 和 "推理逻辑"。
-
提供方 :OpenAI 官方直接提供,是大模型 API 的核心功能之一(需在请求中传入
tools参数启用)。
2. MCP(Model Control Plane)与 MCP Server
-
本质 :MCP 是一套工程化的中间件框架,MCP Server 是该框架的具体实现(服务器端),核心定位是「大模型与外部工具的 "调度中枢"」,相当于 "工具调用的中转站"。
-
核心作用:解决 "多工具整合""跨平台调用""权限控制""日志监控" 等工程化问题,是应用侧的 "工具管理系统"。
-
提供方 :不是 OpenAI 官方提供!常见于企业级应用或第三方开发框架(如 LangChain、LlamaIndex 的工具调度模块,或自研的中间件)。
8.2 核心区别(一张表看懂)
| 对比维度 | 函数调用(Function Calling) | MCP Server |
|---|---|---|
| 本质定位 | 模型的 "交互能力 / 协议规范" | 应用的 "工具调度中间件" |
| 提供方 | OpenAI 官方 | 第三方框架 / 企业自研 |
| 核心功能 | 1. 模型判断是否调用工具;2. 按规范输出调用指令(函数名 + 参数) | 1. 接收模型的调用指令;2. 路由到对应的工具 / API;3. 执行工具并返回结果;4. 管理工具权限、日志、重试 |
| 作用范围 | 仅在 OpenAI 模型侧生效(模型输出调用指令) | 在应用侧生效(承接调用、执行工具) |
| 依赖关系 | 不依赖 MCP Server,可直接对接工具 | 依赖模型的函数调用能力(需接收模型输出的规范调用指令) |
| 典型场景 | 简单工具调用(如单 API、本地函数) | 复杂工具集群(如同时对接 10 + 工具、跨团队工具共享、权限管控) |
8.3 二者的联系:如何配合工作?
实际开发中,二者常一起使用,形成 "模型→MCP→工具" 的完整链路,以电商客服场景为例:
-
用户需求:"查询我的订单 ORDER20250101001 的物流状态";
-
函数调用(模型侧):OpenAI 模型通过函数调用能力,分析需求后输出规范的调用指令(如
{"name":"query_logistics","parameters":{"order_id":"ORDER20250101001"}}); -
MCP Server(应用侧):接收模型的调用指令,做三件事:
-
权限校验:确认当前用户有权查询该订单;
-
工具路由:将请求转发到 "物流查询 API"(而非订单查询 API);
-
执行监控:记录调用日志,若 API 超时则自动重试;
-
工具执行:物流 API 返回结果,经 MCP Server 整理后回传给模型;
-
模型生成回复:OpenAI 模型基于结果,生成自然语言回复用户。
简单说:函数调用负责 "让模型会说话(输出规范指令)",MCP Server 负责 "让工具能听懂(执行规范指令)"。
8.4 实操建议:什么时候需要 MCP Server?
-
若你只需要调用 1-2 个简单工具(如本地函数、单 API):无需 MCP Server,直接用 OpenAI 的函数调用对接工具即可(如文章中天气查询、PDF 提取的案例);
-
若你需要:① 管理多个工具(如 10+API、跨团队工具);② 控制权限(如部分用户只能调用查询工具,不能调用修改工具);③ 监控日志、重试失败、负载均衡:需要 MCP Server,统一调度工具调用。
九、总结:函数调用是大模型应用开发的核心基石
OpenAI 的函数调用能力,让大模型从 "纯文本生成器" 变成了 "智能决策器",它的核心价值在于将大模型的推理能力与开发者的工程能力结合:模型负责理解用户需求、做出调用决策,开发者负责实现具体的业务逻辑、控制工具执行,最终让大模型能对接真实的业务系统,解决实际问题。
掌握函数调用的关键,在于理解五步通用流程,做好函数定义的描述和规范,处理好多工具调用和异常场景,而高级的自定义工具和 CFG 语法,则能让你适配更复杂的业务需求。无论是做智能客服、数据分析、API 对接,还是开发企业级的大模型应用,函数调用都是必备的核心技能,也是打通大模型和外部世界的关键桥梁。
未来,大模型的竞争不再是模型本身的能力,而是模型与外部工具的融合能力,而 OpenAI 的函数调用,正是这套融合能力的最佳实践之一。