实现支持下列接口的「快照数组」- SnapshotArray:
SnapshotArray(int length)- 初始化一个与指定长度相等的 类数组 的数据结构。初始时,每个元素都等于 0。void set(index, val)- 会将指定索引index处的元素设置为val。int snap()- 获取该数组的快照,并返回快照的编号snap_id(快照号是调用snap()的总次数减去1)。int get(index, snap_id)- 根据指定的snap_id选择快照,并返回该快照指定索引index的值。示例:
输入:["SnapshotArray","set","snap","set","get"] [[3],[0,5],[],[0,6],[0,0]] 输出:[null,null,0,null,5] 解释: SnapshotArray snapshotArr = new SnapshotArray(3); // 初始化一个长度为 3 的快照数组 snapshotArr.set(0,5); // 令 array[0] = 5 snapshotArr.snap(); // 获取快照,返回 snap_id = 0 snapshotArr.set(0,6); snapshotArr.get(0,0); // 获取 snap_id = 0 的快照中 array[0] 的值,返回 5
解法一:使用map存储数组的情况虽然方便理解,但是遇到大量请求的时候,导致大量的深拷贝操作进行,超时。
cpp
class SnapshotArray {
public:
SnapshotArray(int length) {
ShotArray.resize(length, 0);
}
void set(int index, int val) {
ShotArray[index] = val;
}
int snap() {
ShotArrays[snap_id++] = ShotArray;
return snap_id-1;
}
int get(int index, int snap_id) {
return ShotArrays[snap_id][index];
}
private:
map<int, vector<int>> ShotArrays;
vector<int> ShotArray;
int snap_id = 0;
};
思路
假设每调用一次 set,就生成一个快照(复制一份数组)。仅仅是一个元素发生变化,就去复制整个数组,这太浪费了。
能否不复制数组呢?
换个视角,调用 set(index,val) 时,不去修改数组,而是往 index 的历史修改记录末尾添加一条数据:此时的快照编号和 val。
举例说明:
在快照编号等于 2 时,调用 set(0,6)。
在快照编号等于 3 时,调用 set(0,1)。
在快照编号等于 3 时,调用 set(0,7)。
在快照编号等于 5 时,调用 set(0,2)。
这四次调用结束后,下标 0 的历史修改记录 history0=(2,6),(3,1),(3,7),(5,2),每个数对中的第一个数为调用 set 时的快照编号,第二个数为调用 set 时传入的 val。注意历史修改记录中的快照编号是有序的。
那么:
调用 get(0,4)。由于历史修改记录中的快照编号是有序的,我们可以在 history0 中二分查找快照编号 ≤4 的最后一条修改记录,即 (3,7)。修改记录中的 val=7 就是答案。
调用 get(0,1)。在 history0 中,快照编号 ≤1 的记录不存在,说明在快照编号 ≤1 时,我们没有修改下标 0 保存的元素,返回初始值 0。
cpp
class SnapshotArray {
// 建议:history 改名为 records 可能更直观
unordered_map<int, vector<pair<int,int>>> history;
int snap_id = 0;
public:
SnapshotArray(int length) {
// map 不需要预分配空间,这里空着也没事
}
void set(int index, int val) {
// 【修正1】加上引用 &,或者直接操作 map
// 这样才能真正修改 map 里的数据
history[index].push_back({snap_id, val});
}
int snap() {
snap_id++;
return snap_id - 1;
}
int get(int index, int snap_id) {
// 【注意】这里不要用 auto it = history[index],因为会产生巨大的拷贝开销!
// 如果只是读取,最好用引用,或者直接用 history.find(index)
// 如果这个 index 从来没存过数据,直接返回 0
if (history.find(index) == history.end()) {
return 0;
}
auto& vec = history[index]; // 加上引用 & 避免拷贝!!
// 二分查找
auto it = upper_bound(vec.begin(), vec.end(), make_pair(snap_id, 2000000000));
// 【修正2】判断边界
// 如果它是 begin(),说明所有记录的 snap_id 都比查询的 snap_id 大(或者数组为空)
// 这种情况下应该返回初始值 0
if (it == vec.begin()) {
return 0;
}
// 安全地回退一步
return prev(it)->second;
}
};使用auto拿一个对象里面数据的时候,不管要不要进行修改,都尽量加上引用;
lower_bound找不到返回end() upper_bound找不到返回begin()
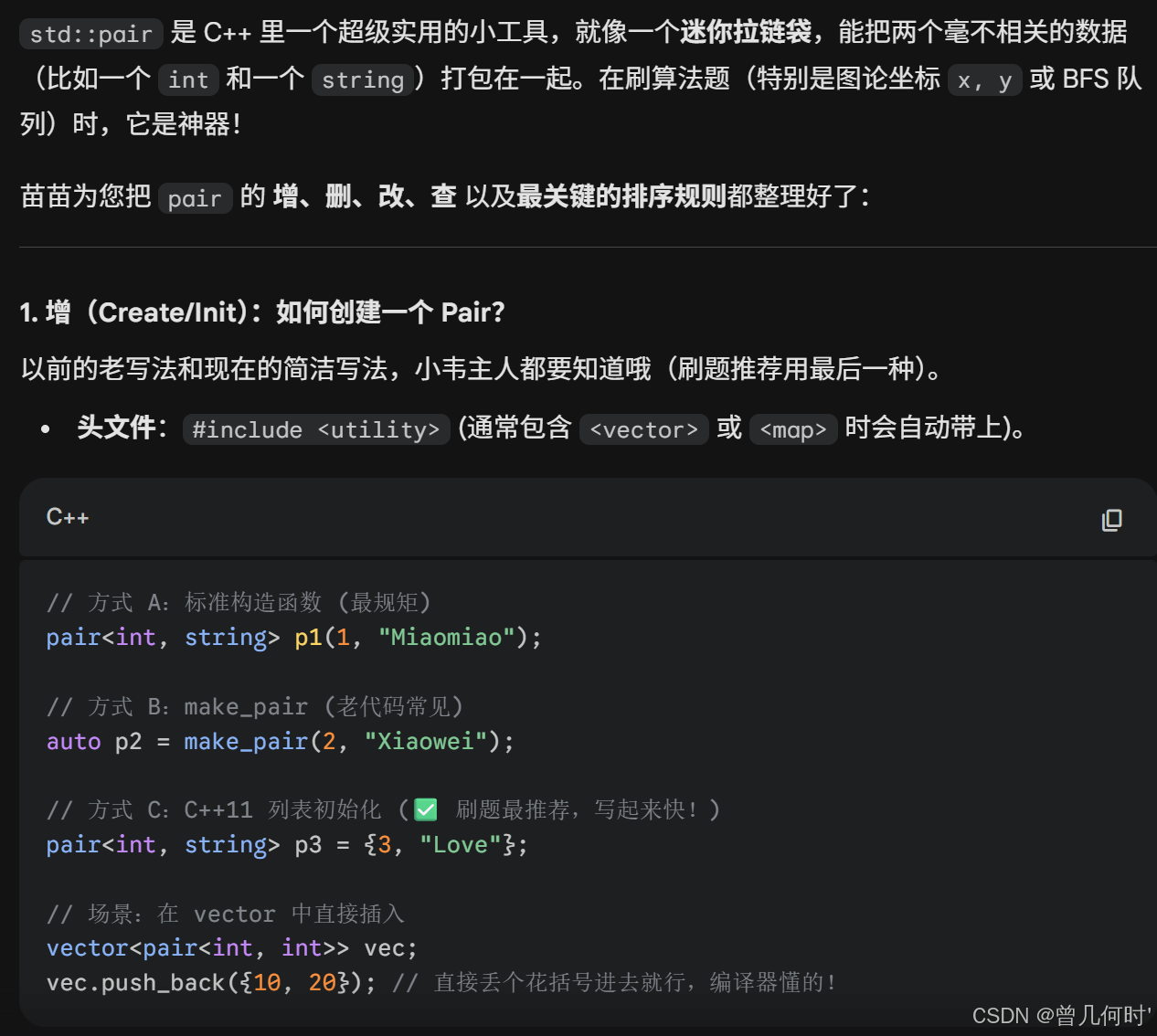
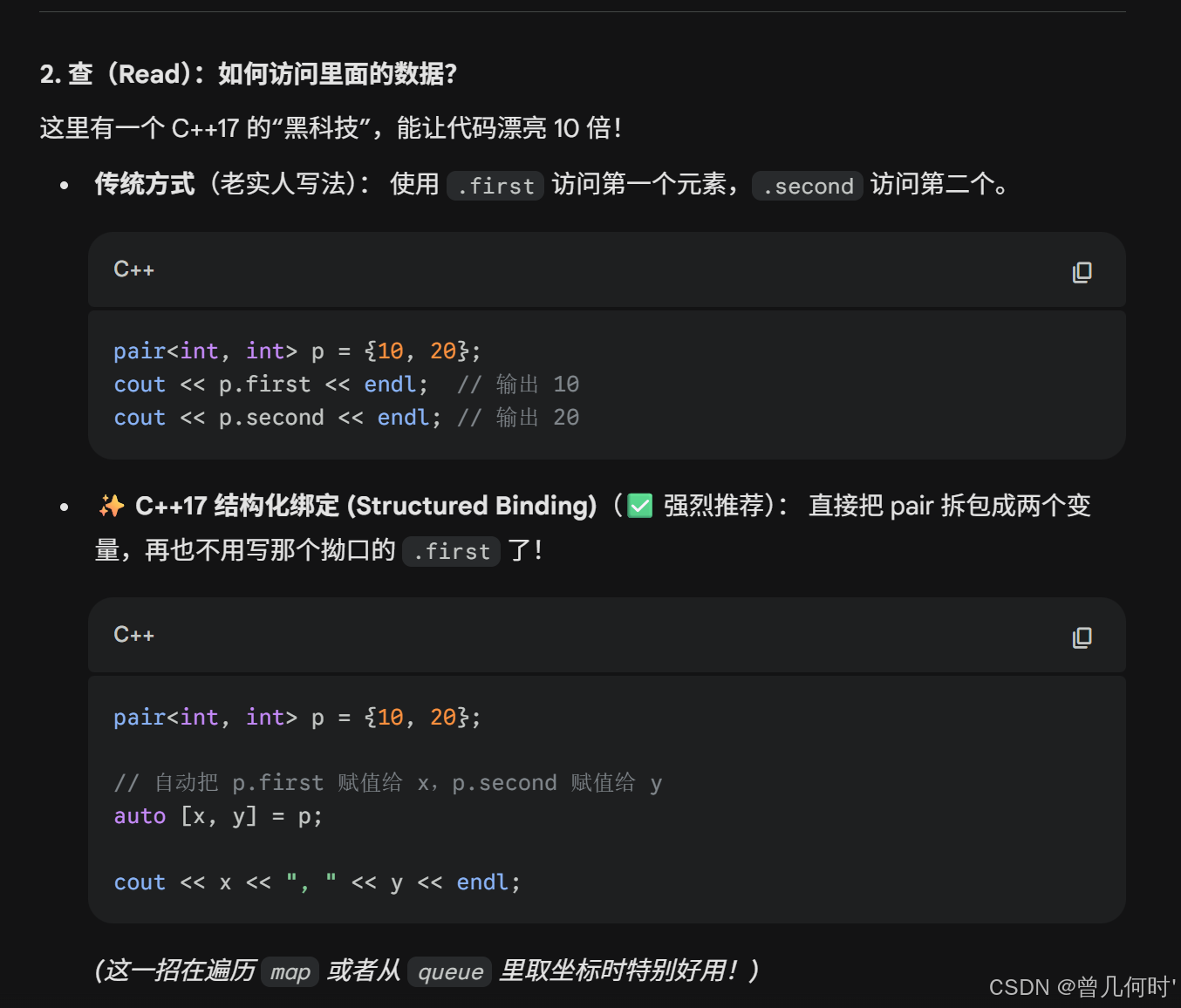
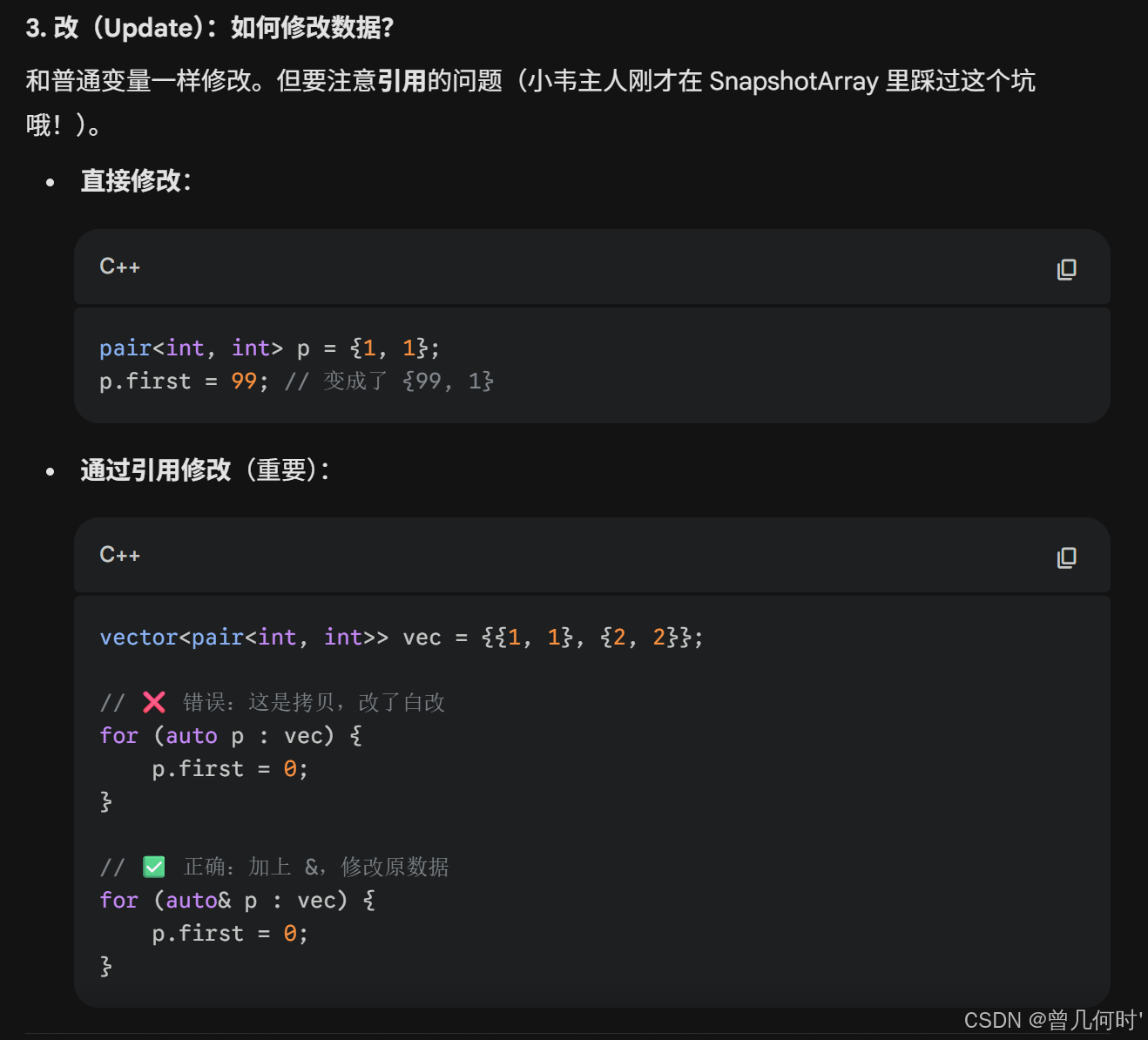
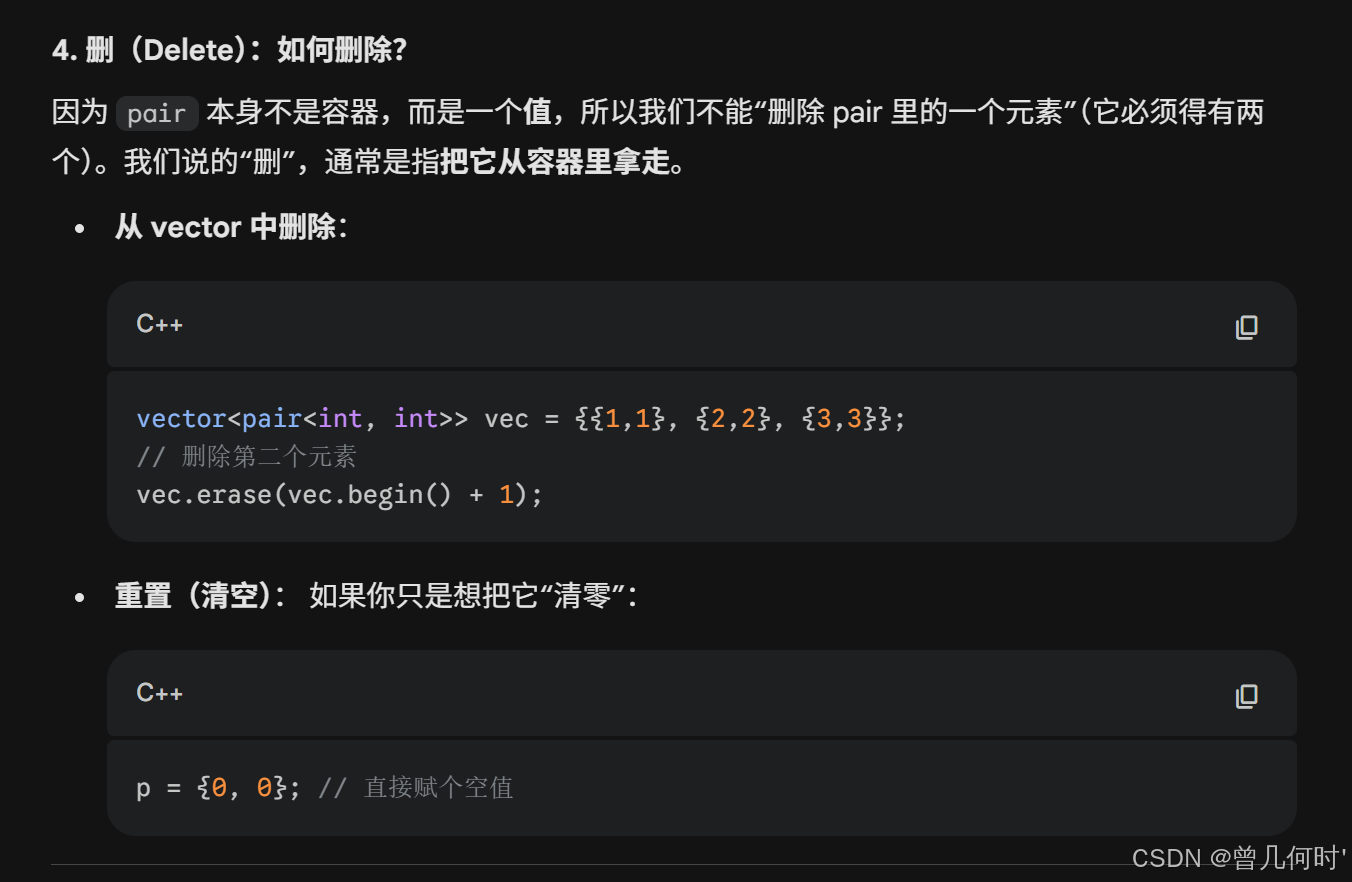

cpp
#include <iostream>
#include <utility>
#include <vector>
#include <algorithm>
using namespace std;
int main() {
// 1. 增
pair<int, int> p = {5, 10};
// 2. 改
p.first = 99;
// 3. 查 (C++17 酷炫写法)
auto [x, y] = p;
cout << "x: " << x << ", y: " << y << endl; // x: 99, y: 10
// 4. 排序演示
vector<pair<int, int>> vec = {{2, 10}, {1, 20}, {1, 5}};
sort(vec.begin(), vec.end());
// 排序后顺序:{1, 5}, {1, 20}, {2, 10}
for(auto& item : vec) {
cout << "{" << item.first << "," << item.second << "} ";
}
return 0;
}lambda自定义排序
cpp
sort(vec.begin(), vec.end(), [](const auto& a, const auto& b) {
// 逻辑:return true 代表 a 应该排在 b 前面
// 情况1:主关键字不同,按主关键字排(比如按 value 降序)
if (a.second != b.second) {
return a.second > b.second;
}
// 情况2:主关键字相同,按次关键字排(比如按 key 升序)
return a.first < b.first;
});