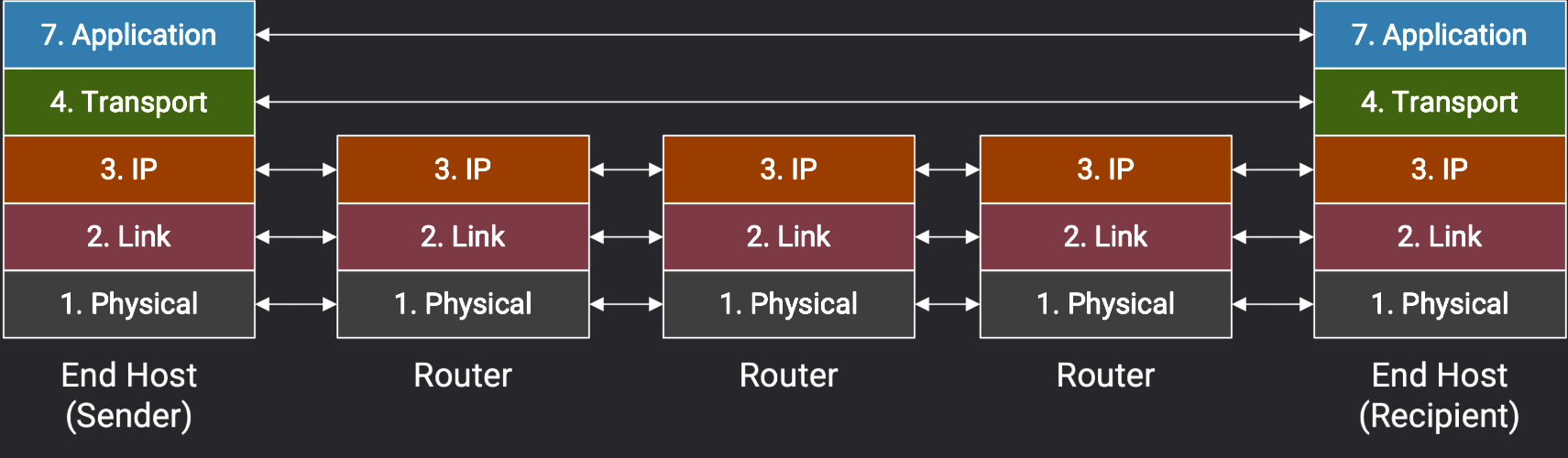
Transport Layer Principles-传输层原理
Reliability Abstraction and Goals - 可靠性抽象与目标
- 应用程序需要可靠性(Reliability) ,而 Layer 3 (IP 层、网际层)只提供了不可靠的、尽力而为的数据包传输服务,致使数据包有以下错误风险:lost(dropped)丢失、corrupted(损坏)、reordered(重排序)、delay(延迟) ,在极少数情况下还可能会 duplicated(重复),Layer 4 传输层就可以弥合这一缺点,提供可靠的抽象。
- 可靠性在终端主机(end host)上实现,而不是在中间路由器实现;可靠性在操作系统中实现,这样应用程序就不用自己重新实现可靠性。
- 可靠性传输并不保证数据包一定被发送,可靠性协议允许放弃并失败发送数据包,但一定要将失败报告给应用程序;协议还应该是高效的,应尽可能快的传输数据,并最小化带宽使用,避免不必要地发送数据包
Transport Layer Goals - 传输层目标
- 传输层目标是向应用程序提供便捷的抽象 ,允许开发者以连接的概念来思考,而不是考虑网络中的各个数据包,开发者无需考虑网络细节,如将长数据分割成数据包、重传丢失的数据包、超时等。可靠性只是传输层希望实现的目标之一。
- 传输层通过引入端口号,在终端主机上的不同进程之间实现解复用,每个数据流(连接)都可以与终端主机上的不同进程相关联。
- 传输层还实现了 flow control(流量控制)和 congestion control(拥塞控制),有助于限制发送数据包的速率,以避免分别过载(overload)接收者(receiver)和网络(network)。
Demultiplexing with Ports - 端口分用
为了区分或多路复用 (demultilexing,或翻译成"分用")哪些数据包是为哪个应用程序准备的,传输层头部包含一个额外的端口号,用于识别终端主机上的特定应用程序
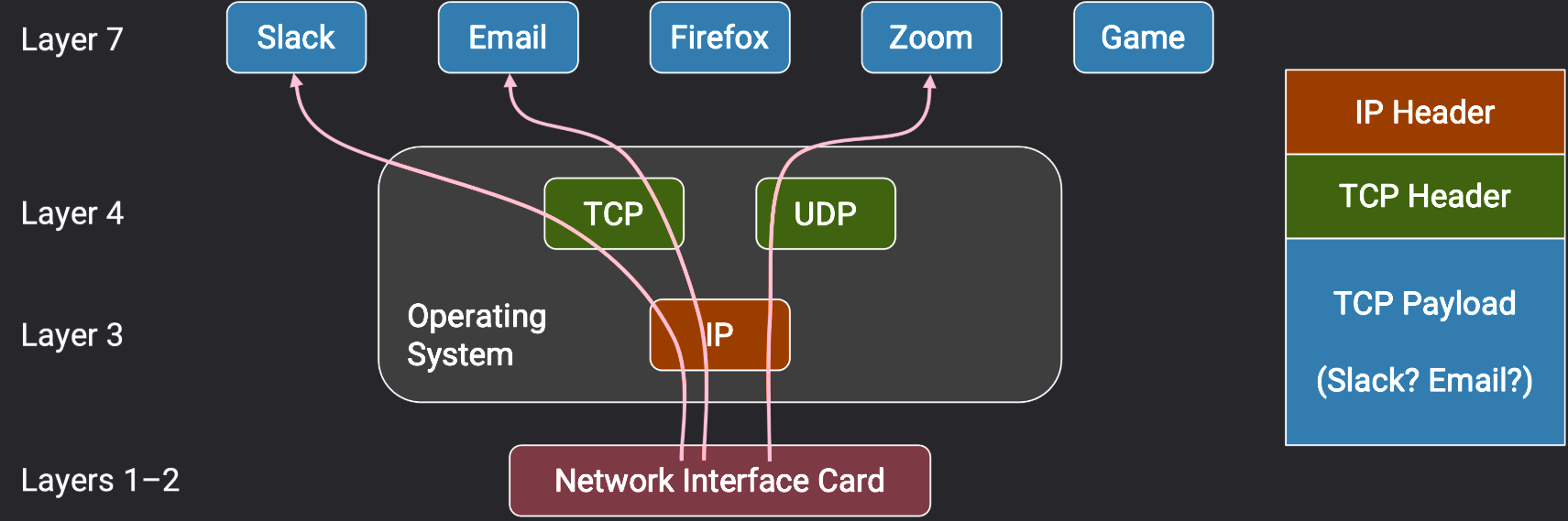
- 由于传输层是在操作系统实现的,这些端口(也称为逻辑端口 )是连接应用程序和操作系统网络栈(network stack)的连接点,应用程序知道自己的端口号,操作系统知道所以应用程序的端口号,数据 就能通过匹配的端口号 在应用程序和操作系统之间明确传输,不会与其他应用程序混淆。
- 端口号是 16 位的。服务器通常在知名端口(0~1023)上监听请求,例如 http(80)和 ssh(22),客户端知道这些端口,并可以通过它们请求服务。
- 相比之下,客户端可以自行选择自己的随机端口号(通常在 1024~65535 之间),这些端口可以随机选择,因为客户端是发起连接的一方,客户端不提供服务,没有人依赖于客户端有固定的端口号。客户端的端口号是短暂的(临时的),连接结束后可以被放弃,无需永久保留。
Bytestream Abstraction - 字节流抽象
- 在传输层实现可靠性意味着应用程序开发者不再需要考虑单个有限大小的数据包在网络中传输。相反,开发者可以思考一个可靠的有序字节流 。发送方有一个无长度限制的字节流,并将其提供传输层。然后,接收方接收到完全相同的字节流,以相同的顺序,没有任何字节丢失 。你可以将字节流想象成一根管道,发送方逐个将字节插入管道,而相同的字节会逐个出现在接收方的管道末端。发送方和接收方不需要考虑重传丢失的数据包或乱序到达的数据包,因为传输层协议会为开发者实现这些功能。

UDP and Datagrams - UDP 和数据报
- 有时,应用程序不需要可靠性,就可以使用 UDP(用户数据报协议) ,此时应用程序需自行处理重发 数据包;UDP 的消息仅限于单个数据包 ,如果想发更大的消息,应用程序负责拆分和重组这些消息。
- UDP 和 TCP 是现代互联网的标准传输层协议。在传输层可以根据需要自行选择 UDP 和 TCP,但不能同时使用两者。
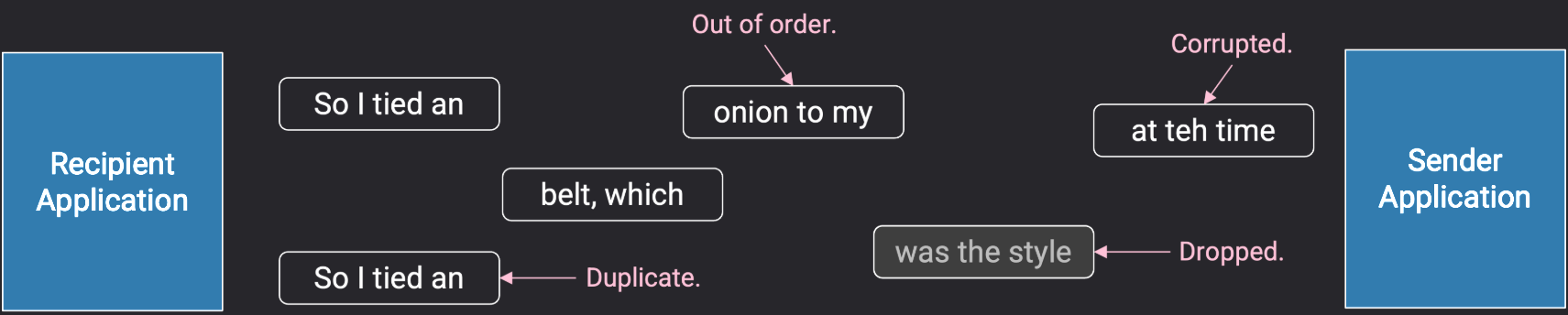
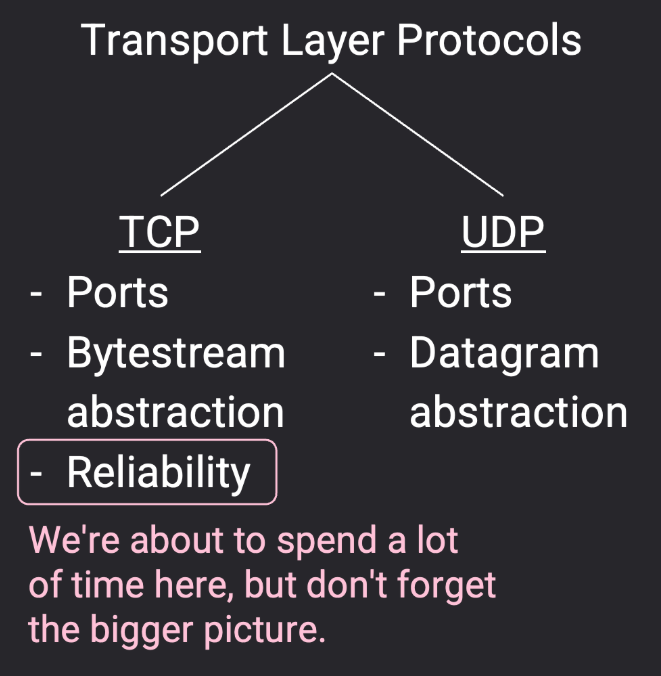
TCP Design-TCP 设计
Reliably Delivering a Single Packet - 可靠地传输单个数据包
数据包从发送方到接收方所需的时间是一跳延迟(one-way delay)。数据包从发送方到接收方所需的时间,加上回复数据包从接收方到发送方所需的时间,是往返时间(RTT,round-trip time)。
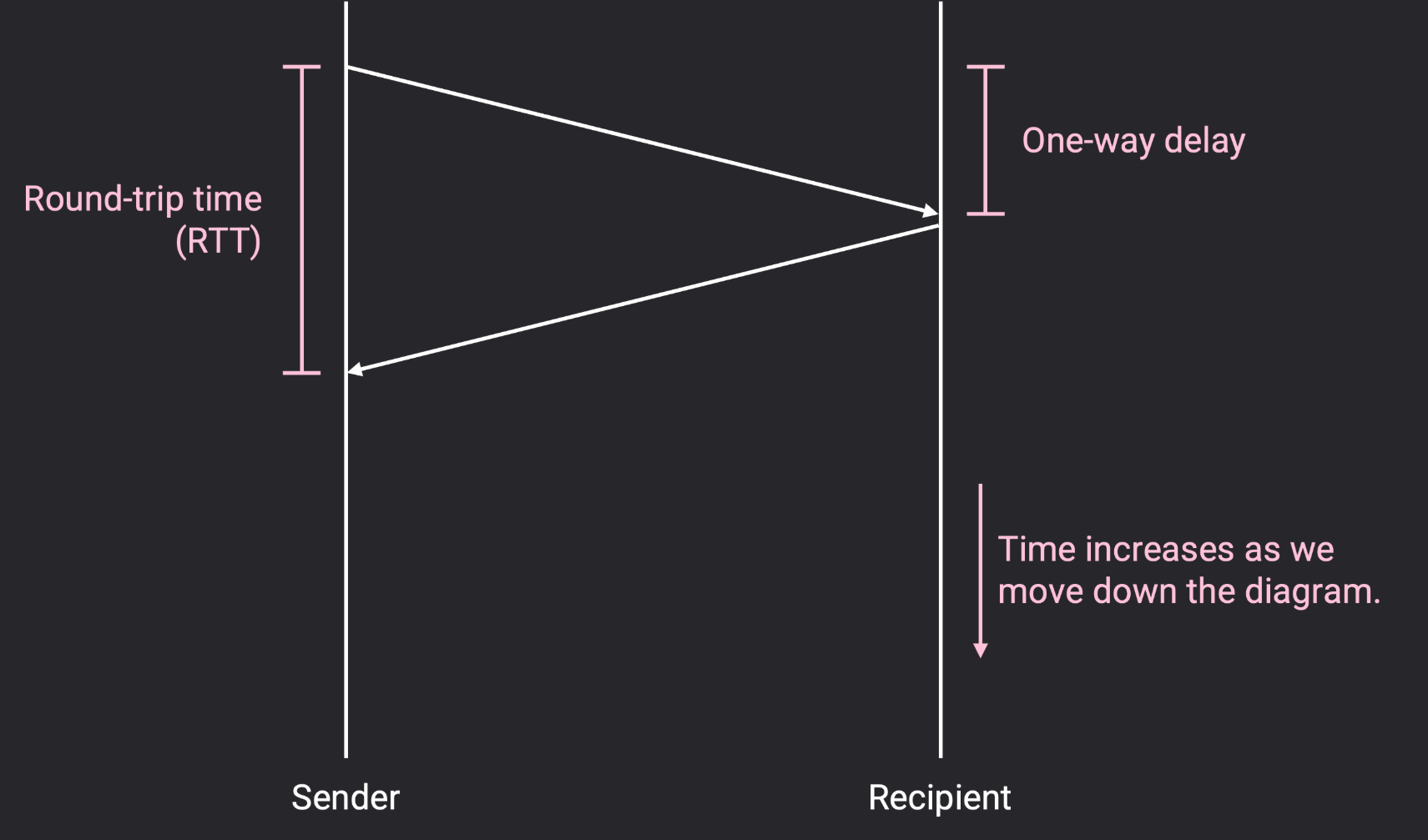
以下关于可靠性设计提出几个问题,当发送方尝试发送一个数据包(send a packet):
发送方如何知道数据包是否成功被接收?
接收方可以发送一个确认(ack,acknowledgement)信息,确认数据包已被接收。
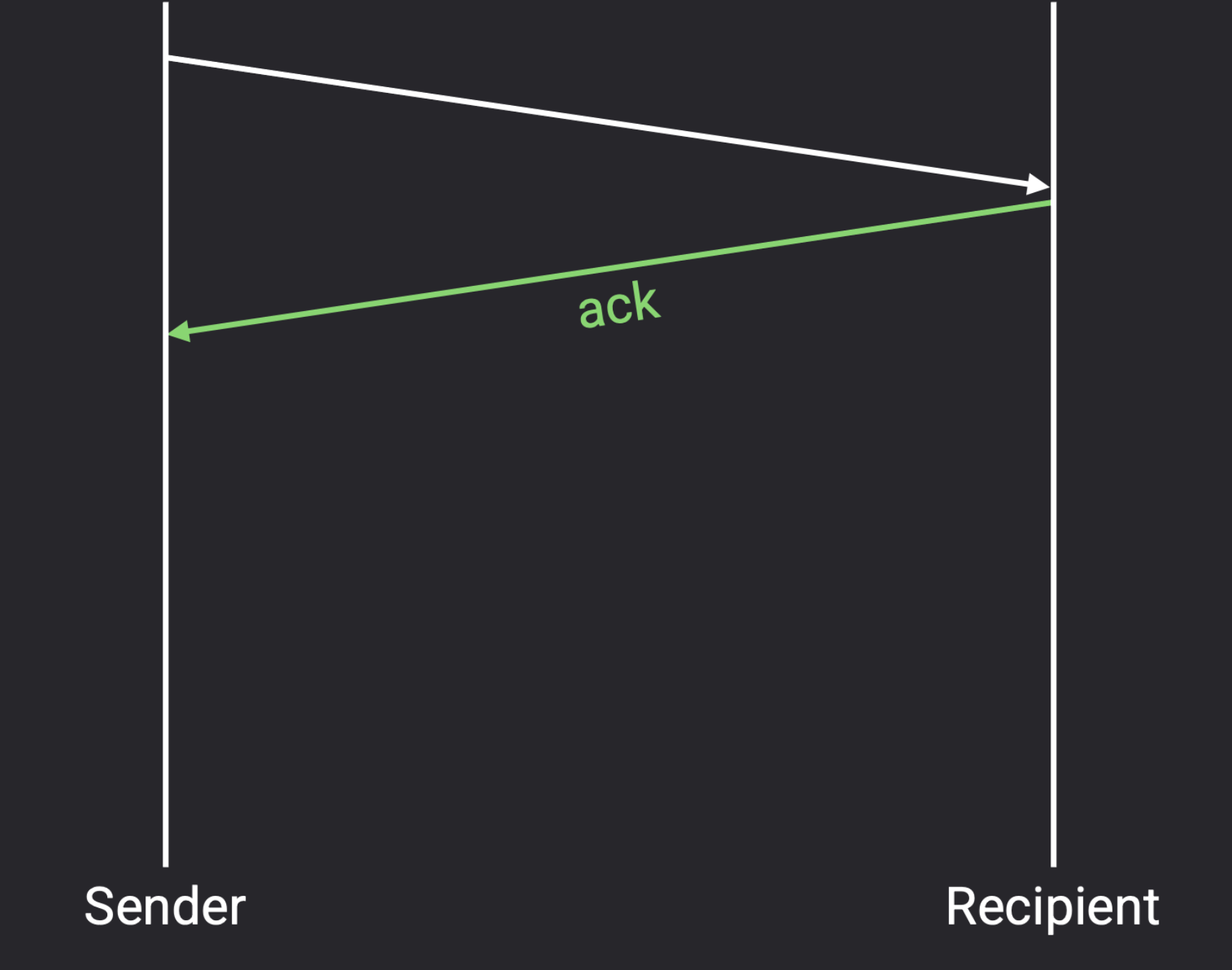
如果数据包丢失了(dropped)?
可以重新发送数据包。
如何知道何时重发(re-send)数据包?
发送方维持一个计时器:当计时器超时,重发数据包;当发送方收到 ack 时,可以取消计时器,无需重发。
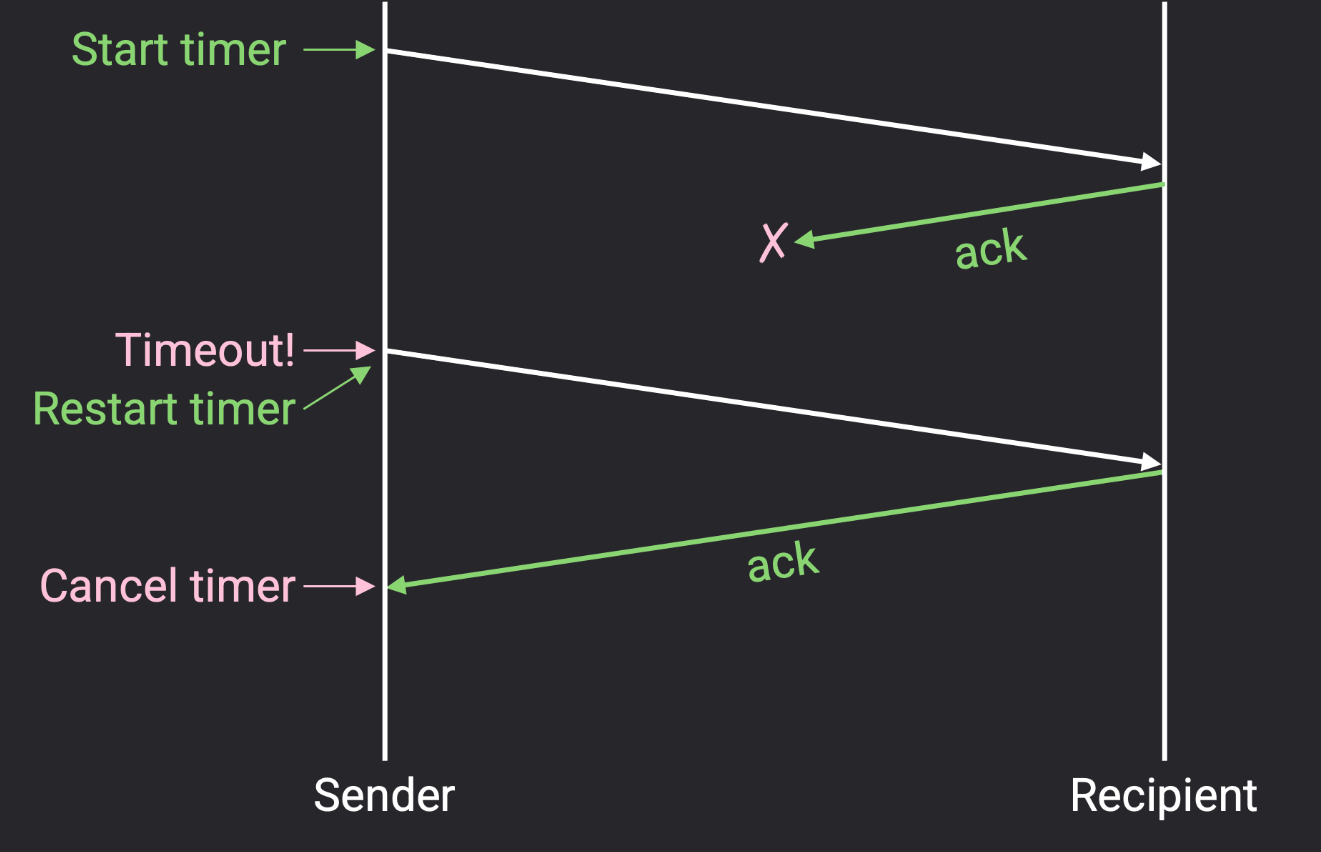
如果确认应答 (ack) 丢失了?
此时以上设计的协议依然有效,这时发送方会超时(即未收到 ack)并重发数据包,直到确认成功发送 。注意到此时接收方收到了同一数据包的两个副本,但这样其实没事,接收方可以检测到重复数据包并将其丢弃。
计时器(timer)如何设置?
一个合适的计时器长度应该是往返时间 RTT。
实际上,估计 RTT 很困难,RTT 会根据数据包在网络中的路径的不同 而变化;即使在特定的路径上,RTT 也受该路径上的拥塞和负载的影响。
通常倾向于把计时器设置的更长,如果计时器太短并经常超时,那么连接会表现得不佳(不断重发数据包)。
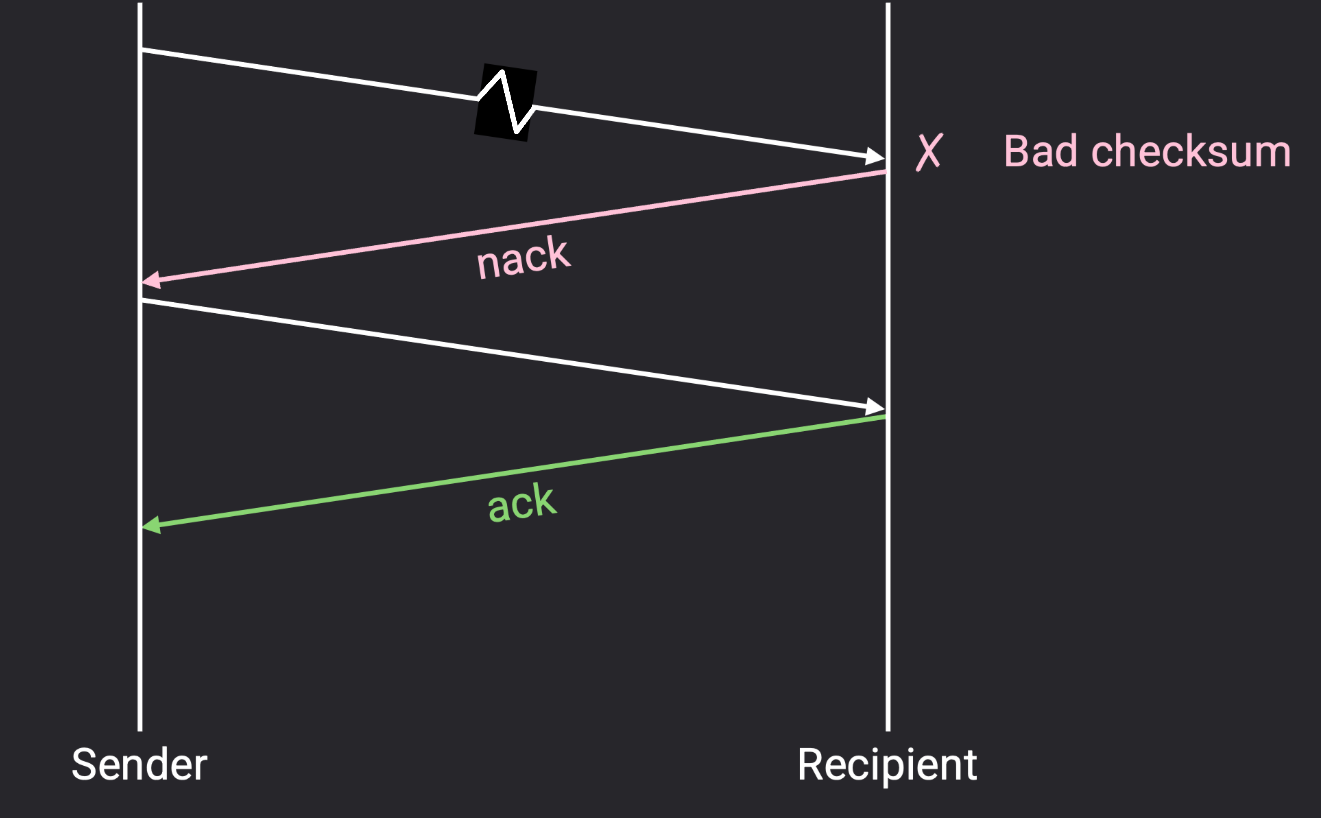
如果比特位损坏(corrupted)?
可以在传输层头部加一个校验和(checksum) ,当接收者发现损坏的数据包时,它可以有两种做法:一是显式地重新发送一个否定确认(nack,negative acknowledgement)并告诉发送者重新发送;或者,它也可以丢弃损坏的数据包并什么也不做 (不发送 ack 也不发 nack),然后,发送者就会超时并重发数据包。
这两种方法都有效,其中 TCP 使用的是后者(等待超时),并且 TCP 没有实现否定确认 nack。
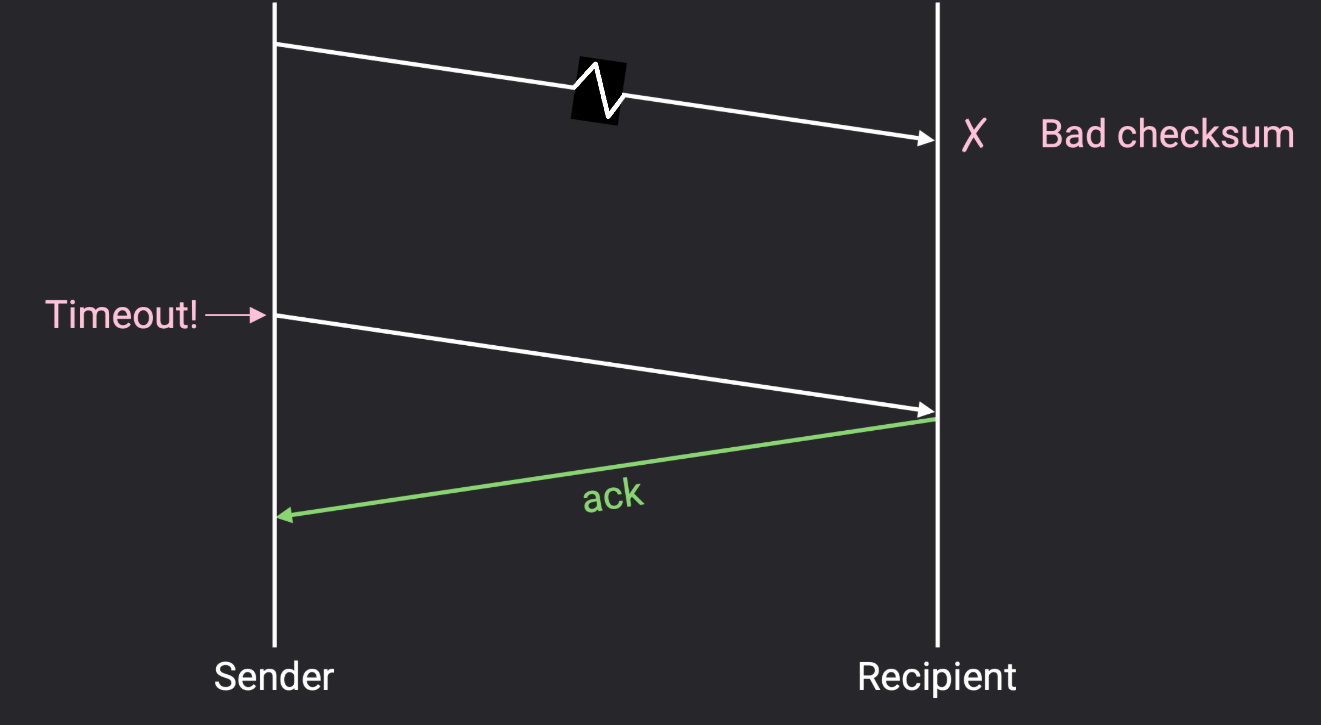
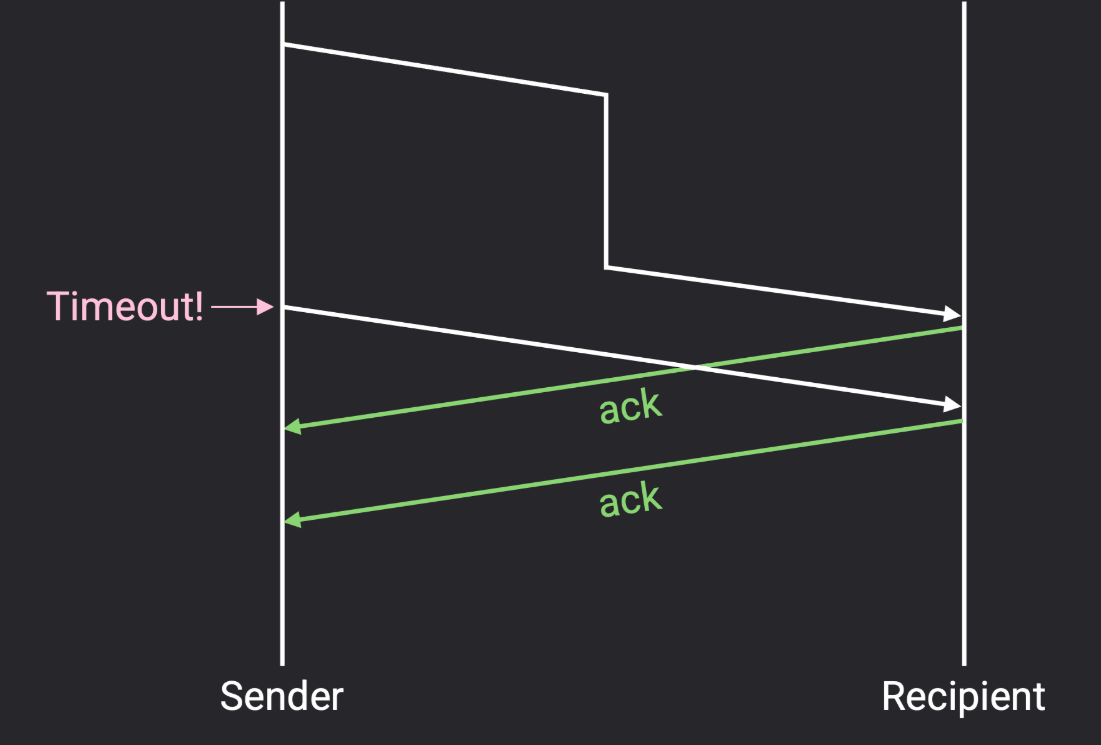
如果数据包延迟了(delay)?
无需修改。如果延迟较长,发送者可能会在接收者的 ack 到达之前重发数据包(因此接收者会接收到两个副本),这样发送者可能会收到两个 ack 信号,但这没关系。
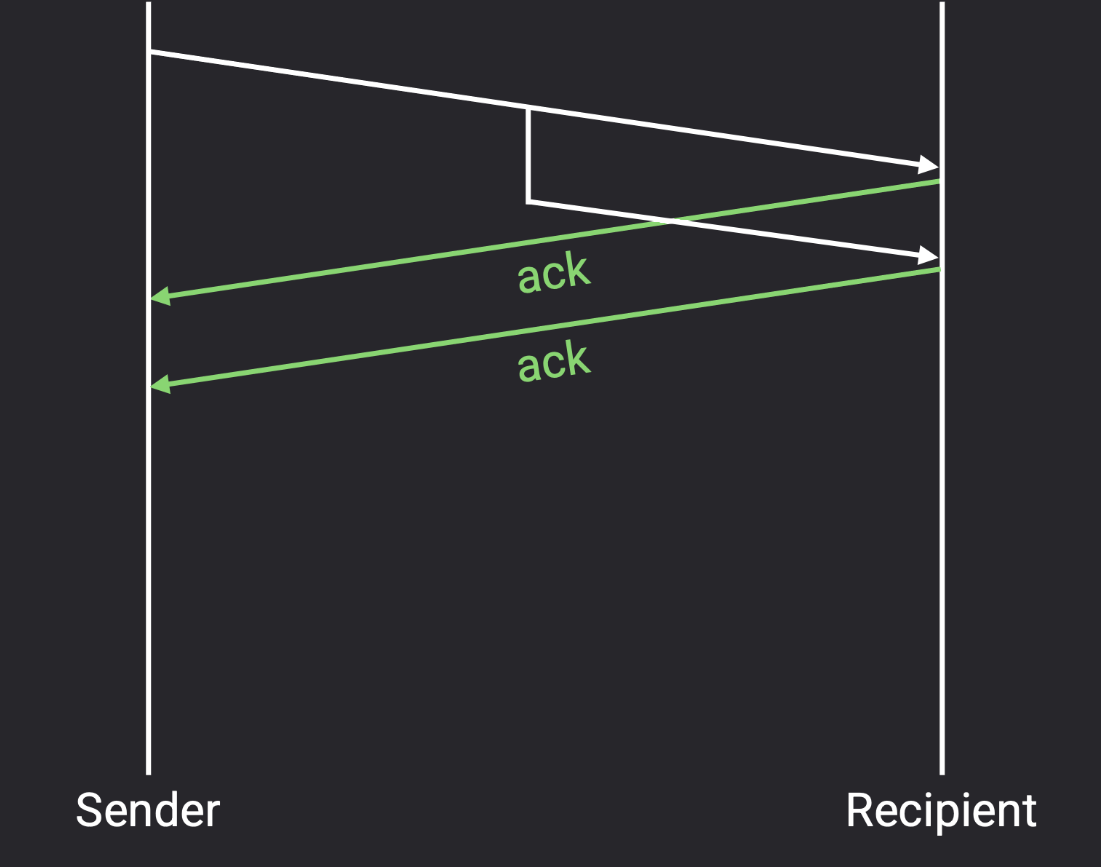
数据包重复了(duplicated),接收方收到两个副本?
无需修改。接收方会发送两个 ack,发送方和接收方都可以安全处理重复数据包。
总之,在这个单数据包可靠性协议中:
- 如果你是发送方,发送数据包,并设置一个计时器。如果在计时器超时之前没有收到确认,则重新发送数据包并重置计时器。当收到确认时停止并取消计时器。
- 如果你是接收方,如果你收到未损坏的数据包,则发送一个确认。 (如果你多次收到数据包,可能会发送多个确认。)
核心思想:校验和 checksum(用于检测损坏)、确认 ack、重发数据包 re-send 和超时 time-out。
Reliably Delivering Multiple Packets - 可靠地传输多个数据包
- 与上面的单数据包遵循相同的规则。同时,为了区分数据包,可以给每个数据包附加一个唯一的序列号(sequence number) ,每个确认包 ack 都与特定的数据包相关联;如果数据包乱序到达,序列号还可以帮助我们重新排序数据包。
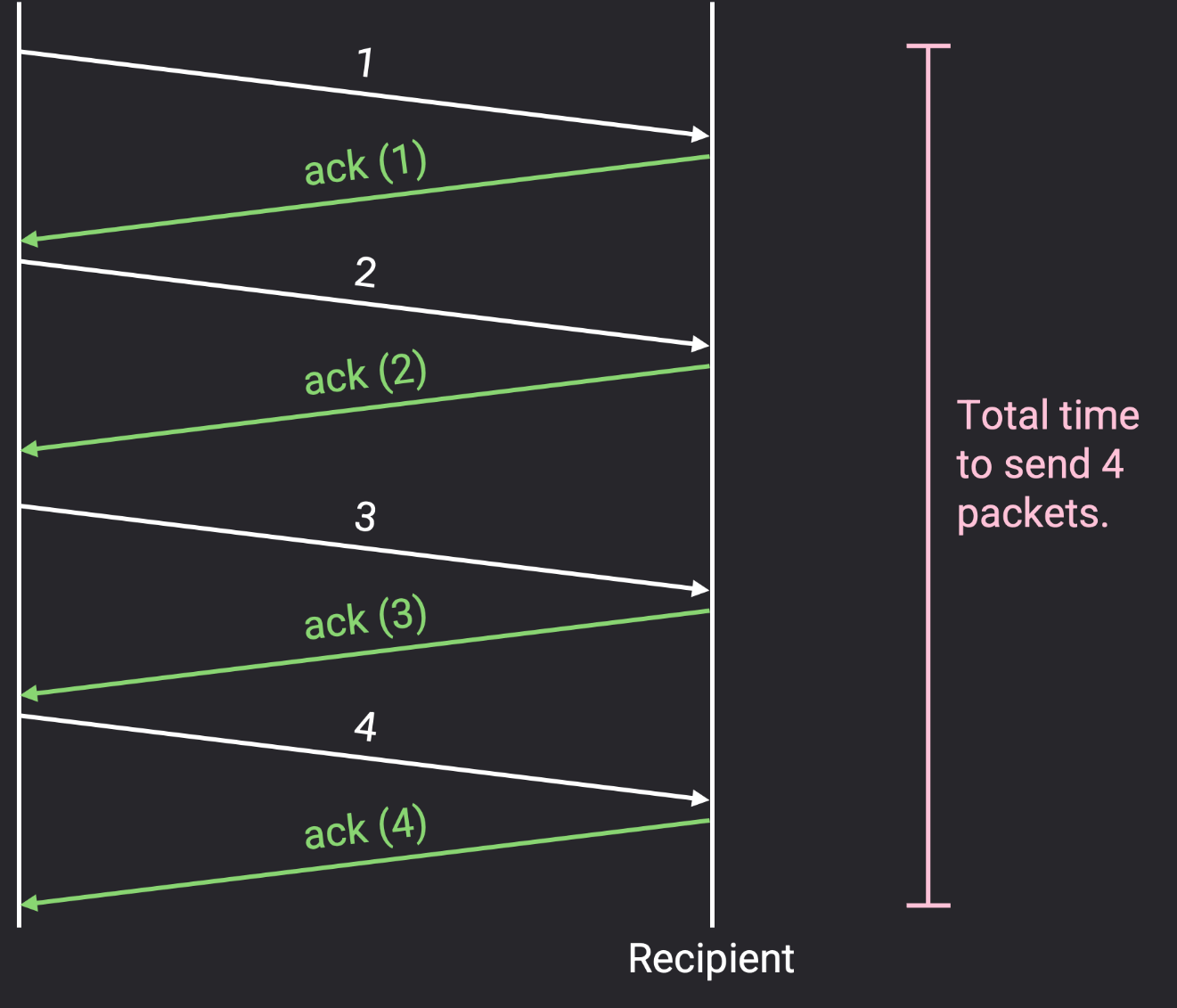
- 发送方何时发送每个数据包?
- 最简单的是停止等待协议(stop and wait),即发送方在收到数据包 i 的确认后再发送数据包 i+1。这将正确地提供可靠性,但它非常慢。每个数据包至少需要一个往返时间(RTT)才能发送(如果数据包丢失或损坏,则需要更多时间)。
- 还可以是立即发送所有数据包,但这可能会使网络不堪重负(例如,连接到计算机的链路可能有有限的带宽)。
- 其次,还可以并行发送数据包。我们可以在等待确认应答到达时发送更多数据包。当一个数据包被发送出去,但相应的确认应答还未收到时,我们就称这个数据包正在传输中。
Window-Based Algorithms - 基于窗口的算法
- 逐个发送数据包太慢,但一次性发送所有数据包会使网络不堪重负。为了解决这个问题,设置一个限制 W,并规定在任何给定时间内最多只能有 W 个数据包正在传输,这就是基于窗口协议的核心思想,其中 W 是窗口的大小。如果 W 是飞行中的最大数据包数,那么发送者可以开始发送 W 个数据包。当收到确认时,我们发送下一个队列中的数据包。
- W如何选择?我们希望充分利用可用的网络容量("fill the pipe")。如果 W 太小,我们就不能使用所有可用的带宽。
然而,我们不想过载链路 ,因为其他人可能正在使用该链路(拥塞控制 congestion control);我们也不想过载接收者,接收者需要接收并处理来自发送者的所有数据包(流量控制 flow control)。
Window Size: Filling the Pipe - 填充管道
-
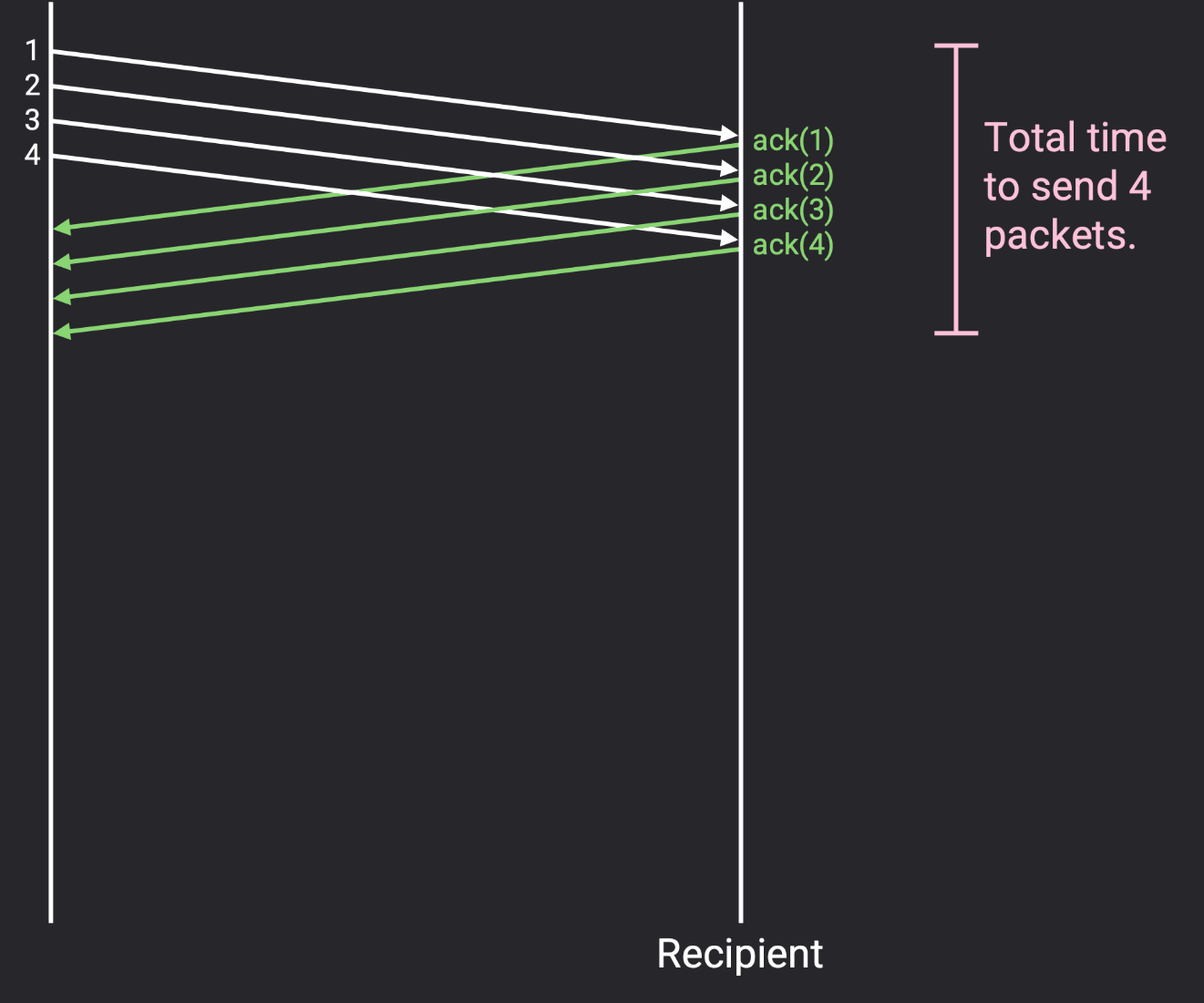
只关注第一个 RTT,即从第一个数据包发送到第一个 ack 到达的时间。假设这个时间是 5 秒,此外,假设发送链路允许发送方每秒发送 10 个数据包。在第一个 RTT 时间内,发送方应该能够总共发送 50 个数据包。因此,50 是一个合理的窗口大小,这样发送方总是发送数据包而不会闲置。
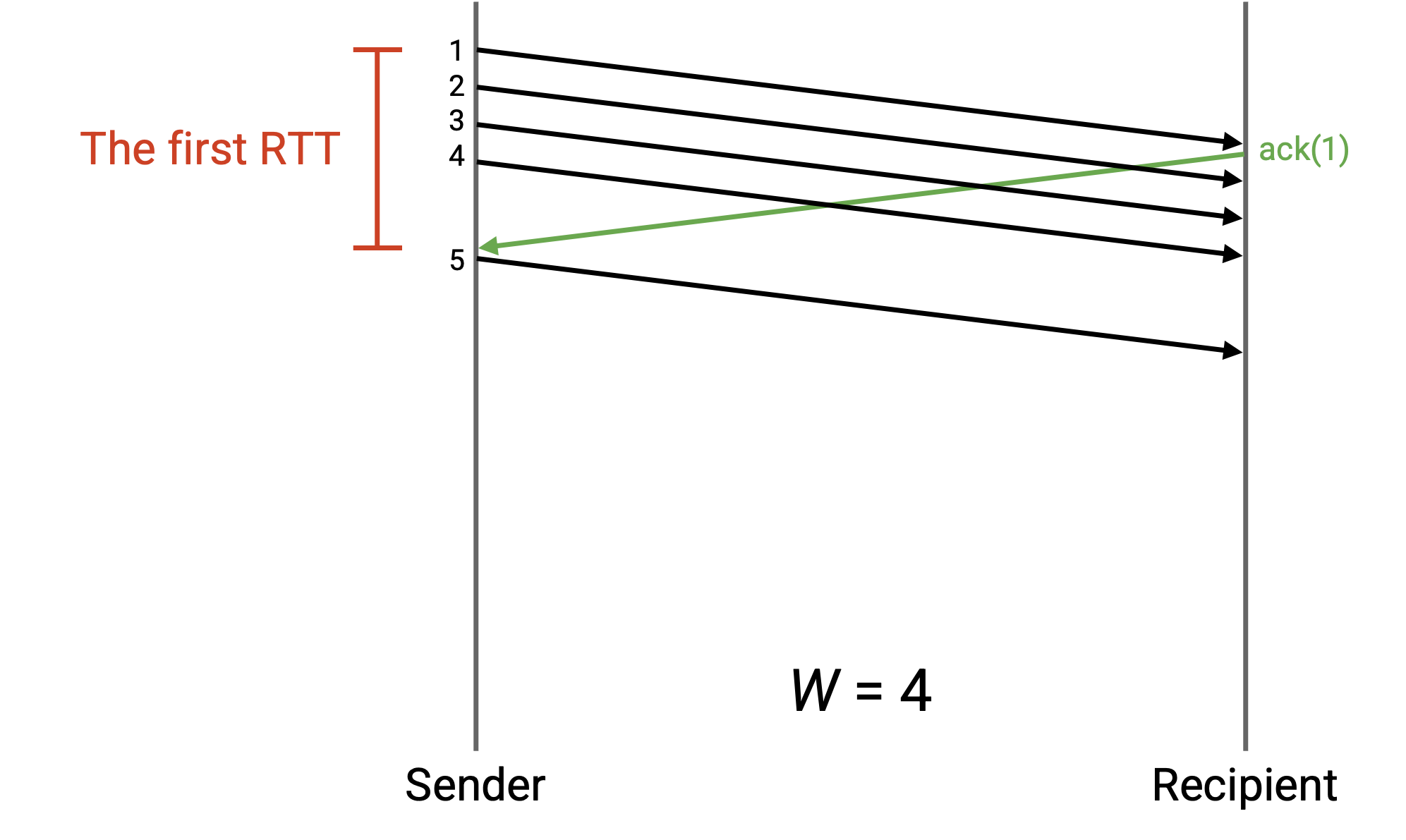
如果我们设置 W(窗口大小) 小于 50,那么发送方在第一个 ack 到达之前就会完成所有初始数据包的发送。然后,发送方将被迫在等待 ack 到达时闲置,从而浪费一些网络带宽 。更一般地说,我们希望发送方在整个 RTT 期间都在发送数据包 。
-
通往目的地的路径可能有多个链路,每个链路具有不同的容量。设 B 为路径上最小(瓶颈)链路的带宽 。我们不应发送比 B 更快的包,以避免链路过载。我们也希望发送包的速度不低于 B(即我们希望在所有时间都使用 B 的速率 )。
此外,假设 R 是发送方和接收方之间的往返时间。我们可以将 R 乘以 B 来得到在往返时间内可以发送的总数据包数。(我们每秒可以发送 B 个包,持续 R 秒。)这告诉我们窗口大小,以数据包为单位。
实际上,B 是以每秒比特数来测量的 ,而不是每秒数据包数。当我们将 R 乘以 B 时,我们得到在往返时间内可以发送的比特数。(每秒 B 比特,持续 R 秒。)这告诉我们窗口大小,以字节为单位。
总而言之,我们可以写成:W × packet size = R × B,等式左边表示在窗口期内发送的字节数(W 个数据包乘以每个数据包的字节数),而等式右边表示在 RTT 时间内可以发送的字节数。
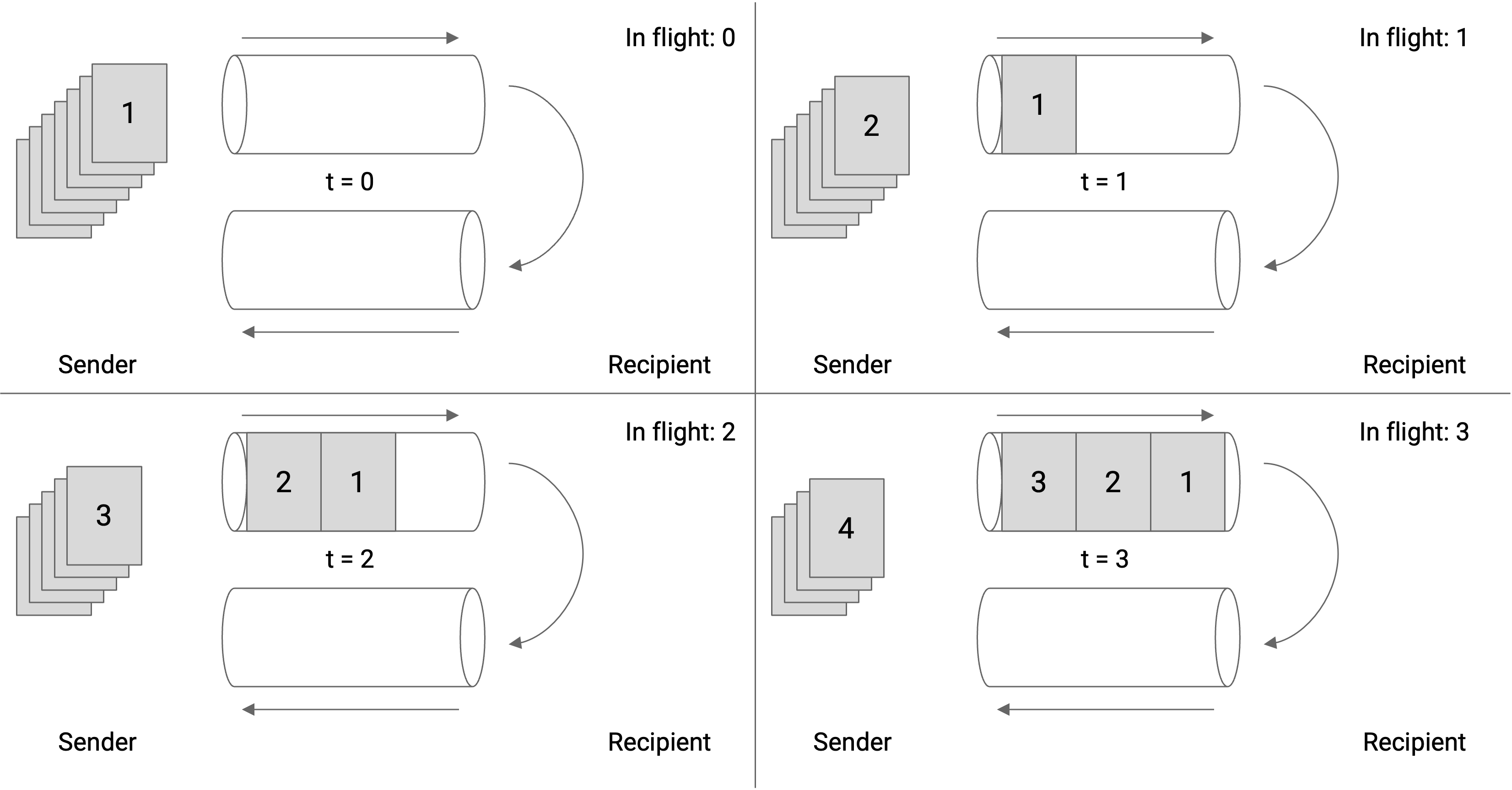
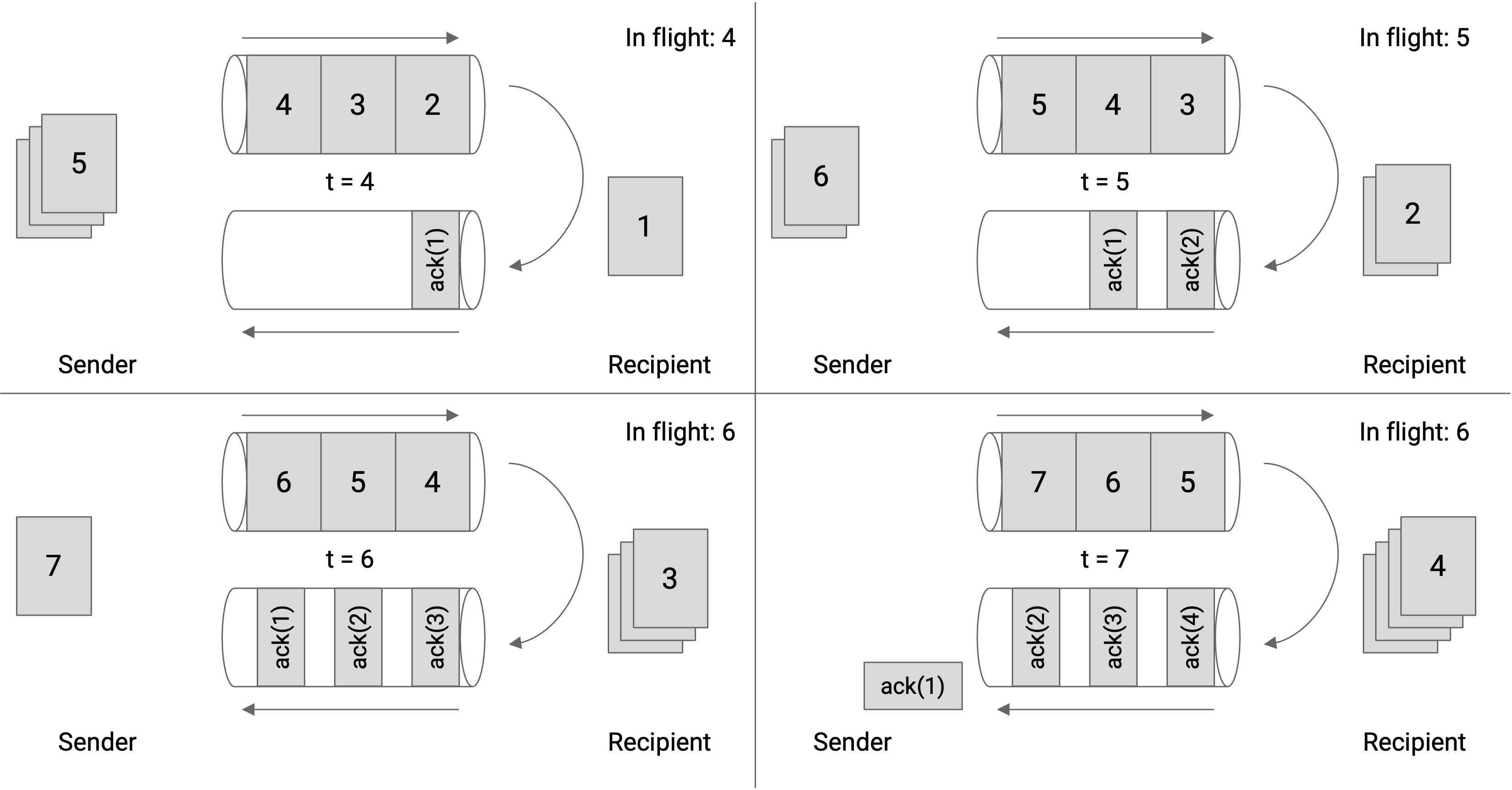
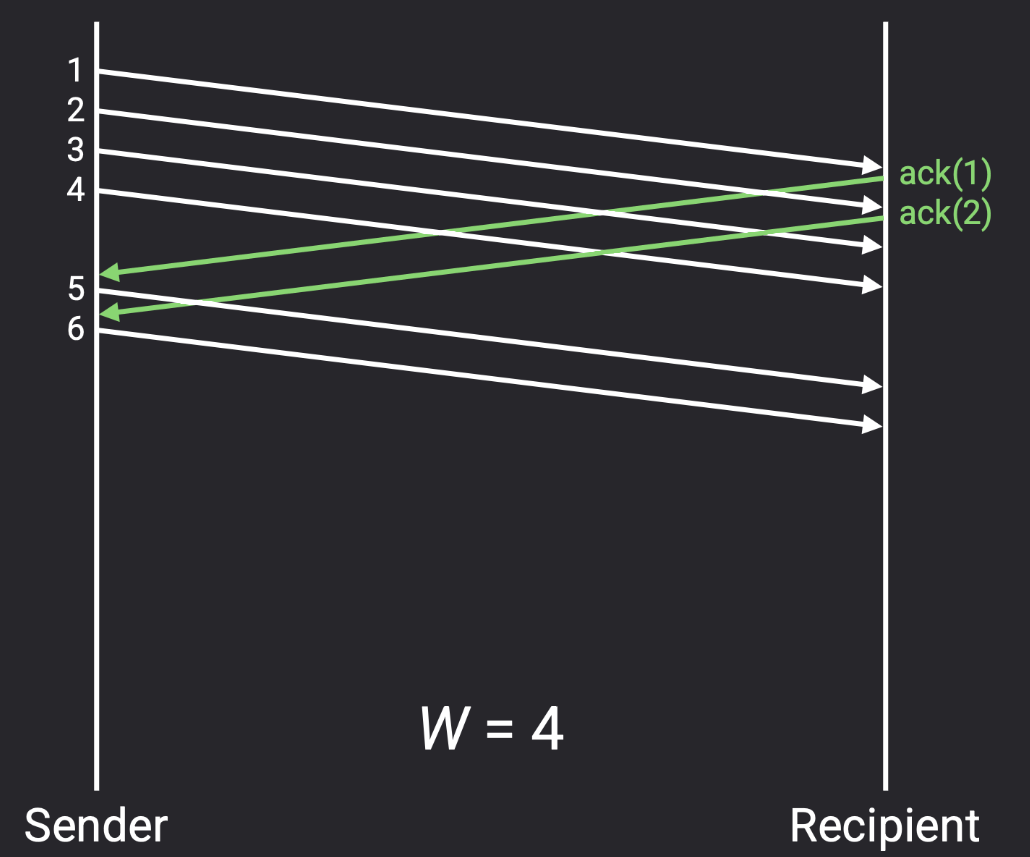
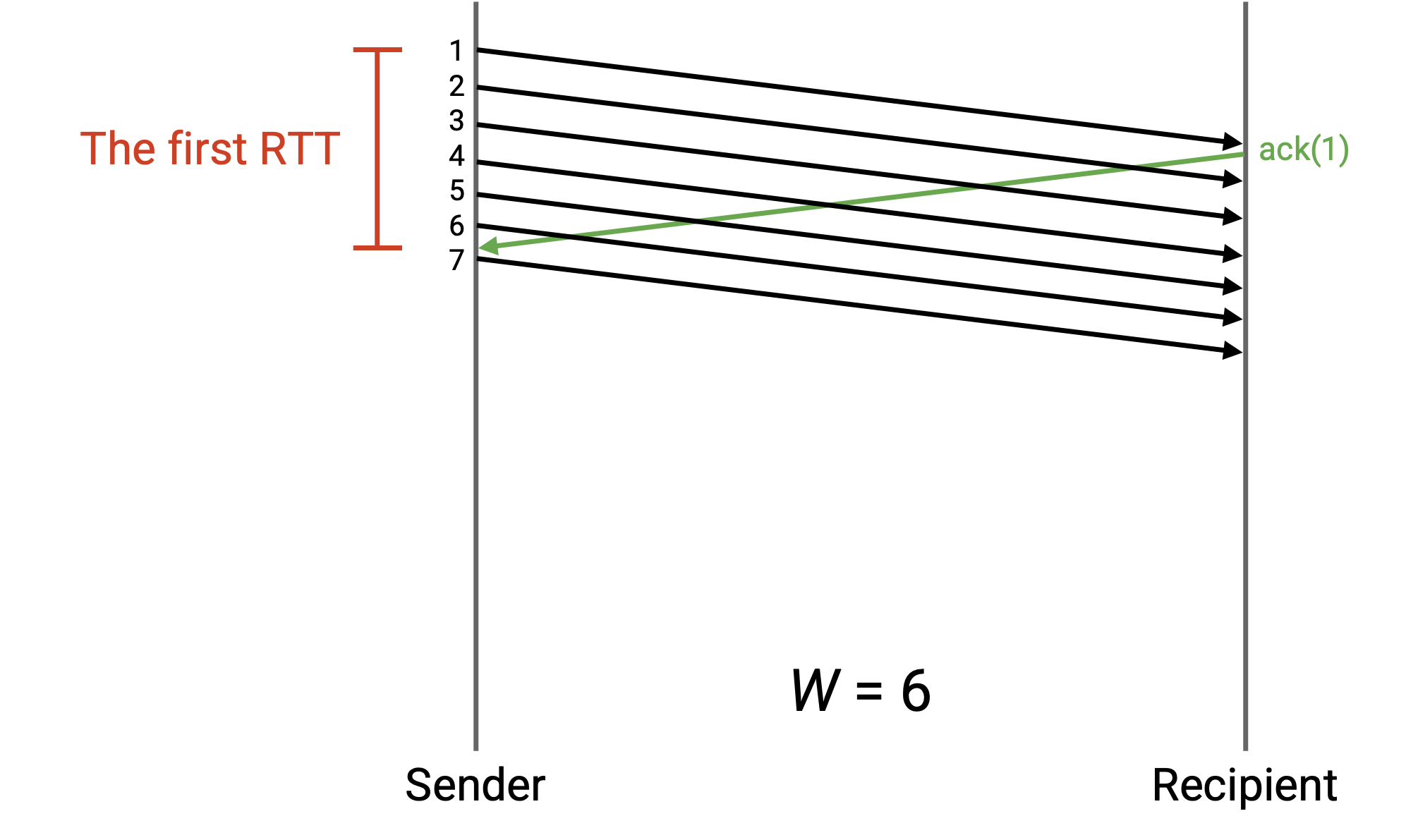
- 请注意上图所示,窗口大小不是 3,是 6。当发送第 6 个数据包时,有 3 个数据包正在发送,但有 3 个更多数据包的确认包尚未到达,所以总共有 6 个数据包正在传输。如果我们将窗口大小设置为 3,那么在确认包 1、2、3 正在传输期间,出站管道将未被使用。
请注意,确认包不会填满整个入站管道(所以图中 ack 宝之间有间隙,而 sender 发给 recipient 的 packet 没有间隙),因为数据包除了确认收到数据包外不包含任何实际数据。
Window Size: Flow Control - 流量控制
-
考虑接收方操作系统中的传输层协议,接收方可能会收到乱序的数据包,但字节流抽象要求数据包必须按序交付 。这意味着传输层实现必须通过缓存(buffering, 将它们保存在内存中)来暂存乱序数据包,直到它们轮到被交付 。
例如,假设接收方已经接收并处理了数据包 1 和数据包 2。然后,接收方看到了数据包 4 和数据包 5。传输层实现还不能将 4 和 5 交付给应用程序。相反,我们必须等待数据包 3 到达,同时必须将数据包 4 和数据包 5 保存在传输层实现的内存中。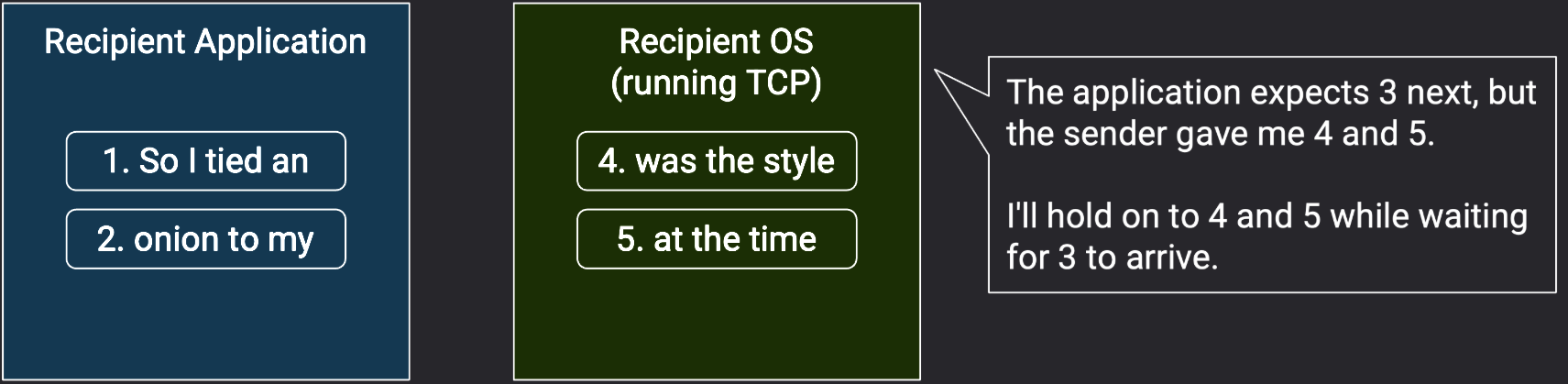
-
然而,内存不是无限的,接收方用于存储乱序数据包的缓冲区大小是有限的 。接收方必须在内存中存储每个乱序数据包,直到中间缺失的数据包到达 。如果连接中有大量数据包丢失和重排序,接收方可能会耗尽内存 。
流量控制(flow control)确保接收方的缓冲区不会耗尽内存 。为此,接收方需要告诉发送方缓冲区中剩余的空间量。接收方缓冲区中剩余的空间量称为通告窗口(advertised window) 。在确认信息中,接收方会说"我已经收到这些数据包,并且我还有 X 字节的缓冲区空间来存储数据包。"
当发送方了解到通告窗口后,会相应地调整其窗口大小。具体来说,正在传输的数据包数量不能超过接收方通告的窗口大小。如果接收方说"我的缓冲区有足够的空间来存储 5 个数据包",发送方必须将窗口大小设置为最多 5 个数据包(即使带宽可能允许传输更多数据包)。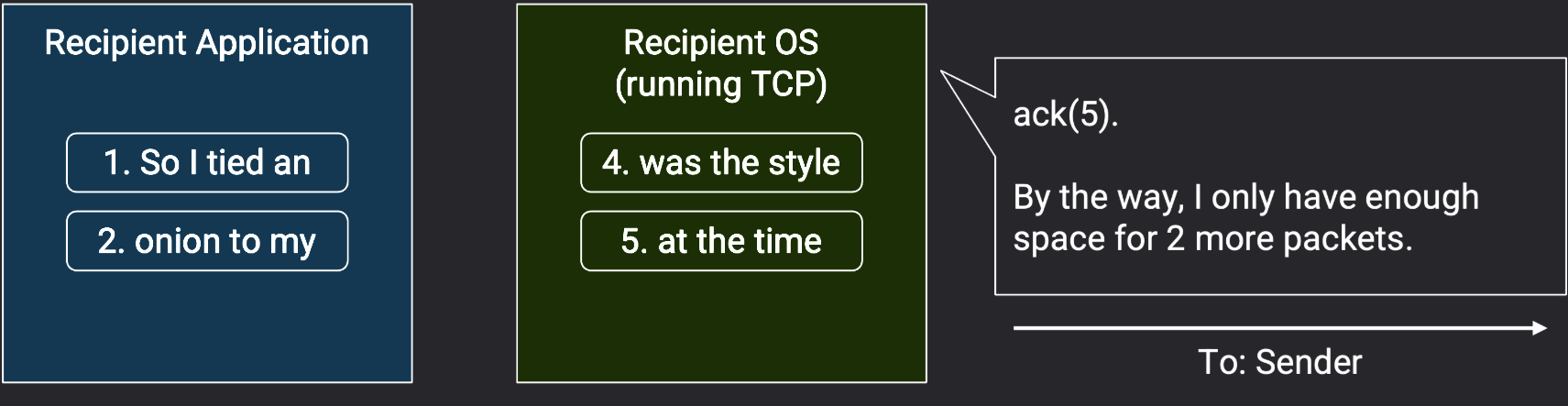
Window Size: Congestion Control - 拥塞控制
-
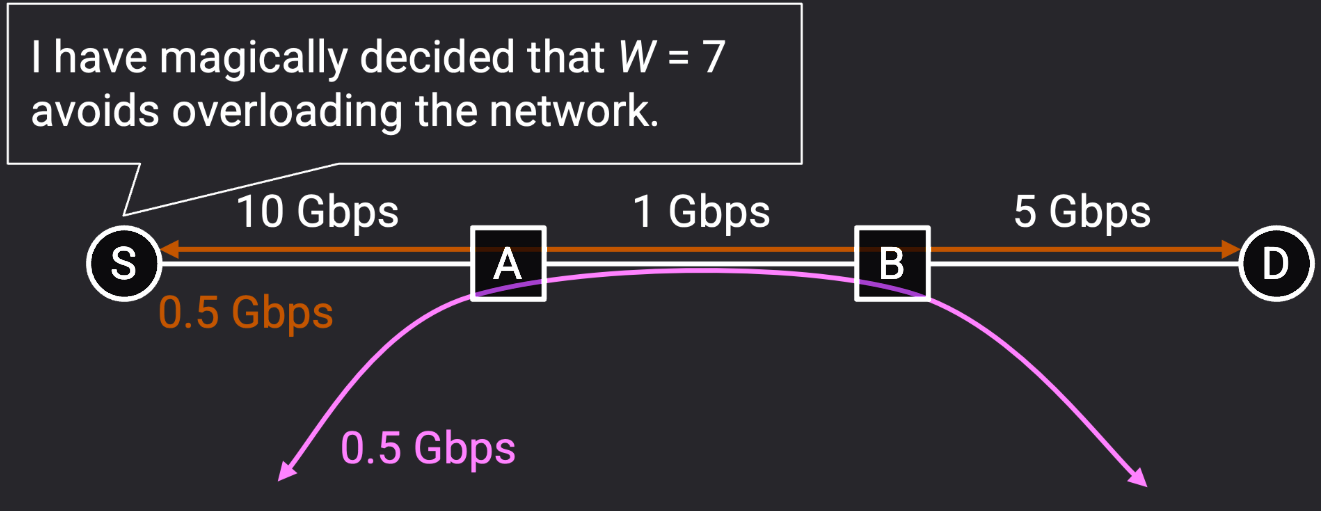
通过上面的学习我们知道,为了充分利用带宽,发送方会将窗口大小设置为完全消耗瓶颈链路的带宽。例如,如果瓶颈链路的带宽为 1Gbps,我们会设置窗口大小,使得发送方在整个 RTT 时间内持续以 1Gbps 的速度发送数据(不空闲)。然而,在实际中,1Gbps 链路不太可能只被单个连接使用。其他连接也可能使用该链路上的容量。发送者不应该消耗该链路上的全部带宽,而应该只消耗自己应占的带宽份额。
-
那么,带宽的份额应该如何分配给每个连接呢?假设有两个连接分别使用 400MBps 和 250MBps。如果另一个连接尝试使用同一链路,那么发送者的份额可能是剩余的 350MBps。但也有人认为带宽分配不公平,所以或许每个人都应该调整为使用 333MBps。
-
确定并计算每个连接能够使用的确切带宽量 是拥塞控制(congestion control) 的目标。拥塞控制算法 本身是一个完整的话题(将在后面的学习中介绍)。目前,我们将抽象掉拥塞控制,并假设作为传输层的一部分,发送者正在实现一个拥塞控制算法,其任务是动态计算连接上瓶颈链路的发送者份额。
-
运行算法的结果是发送方的拥塞窗口(cwnd,congestion window) 。目前,您只需要知道该算法会输出这个数值,它代表一个最大化性能且不会过载链路的带宽,同时与其他连接公平共享带宽。
-
现在我们知道如何设置窗口以实现我们之前提到的三个目标 。为了充分利用网络容量 ,我们将根据往返时间(RTT)和瓶颈链路的带宽来设置窗口大小;为了避免过载接收方 ,我们将根据接收方通告的窗口大小(advertised window)来限制窗口大小;为了避免过载链路 ,我们将根据发送方的拥塞窗口(发送方运行拥塞控制算法输出的某个数值)来限制窗口大小。
为了满足所有三个目标,我们将窗口大小设置为这三个值中的最小值。 -
在实践中,请注意拥塞窗口(第三个目标)总是小于或等于充分利用带宽的窗口大小(第一个目标)。如果没有拥塞,我们将充分利用所有瓶颈带宽,因此这两个数值将相等。在大多数情况下,拥塞将迫使我们使用少于所有瓶颈带宽,因此第三个数值将小于第一个数值。没有拥塞窗口带宽大于瓶颈带宽的情况。
-
此外,在实践中,发现瓶颈带宽(即上面所提的第一个目标带宽数值)很困难。发送者必须以某种方式穿越网络拓扑并了解每条链路的带宽。由于第一个数值难以获取,且始终大于或等于第三个数值,我们可以将窗口大小设置为后两个数值中的最小值(忽略第一个数值) 。窗口大小是发送者的拥塞窗口和接收者通告窗口的最小值。
Smarter Acknowledgments - 更智能的确认
-
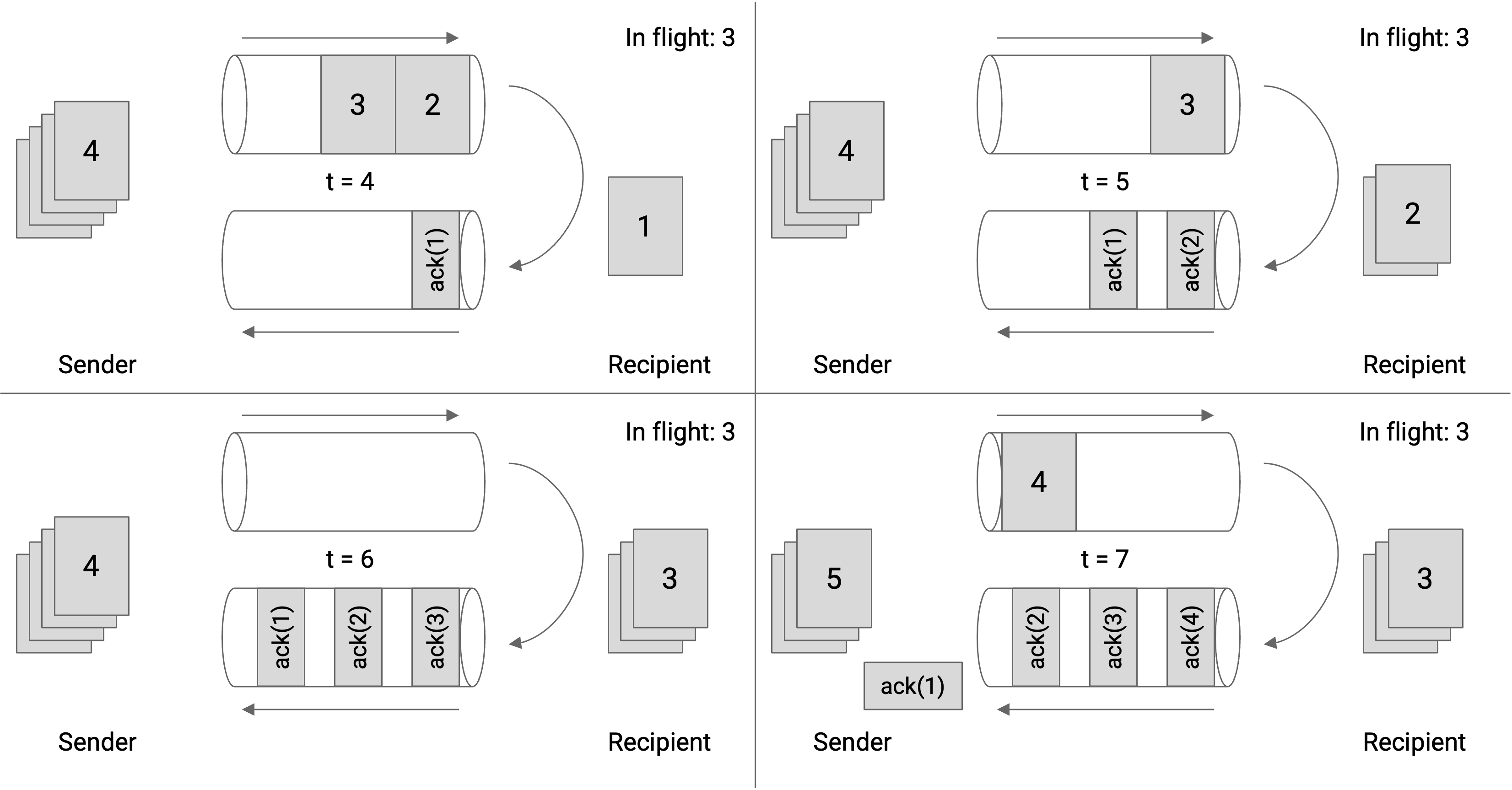
到目前为止,每个确认包都对应一个数据包。我们能否继续优化呢,一次确认多个数据包?一次确认一个数据包存在哪些问题?
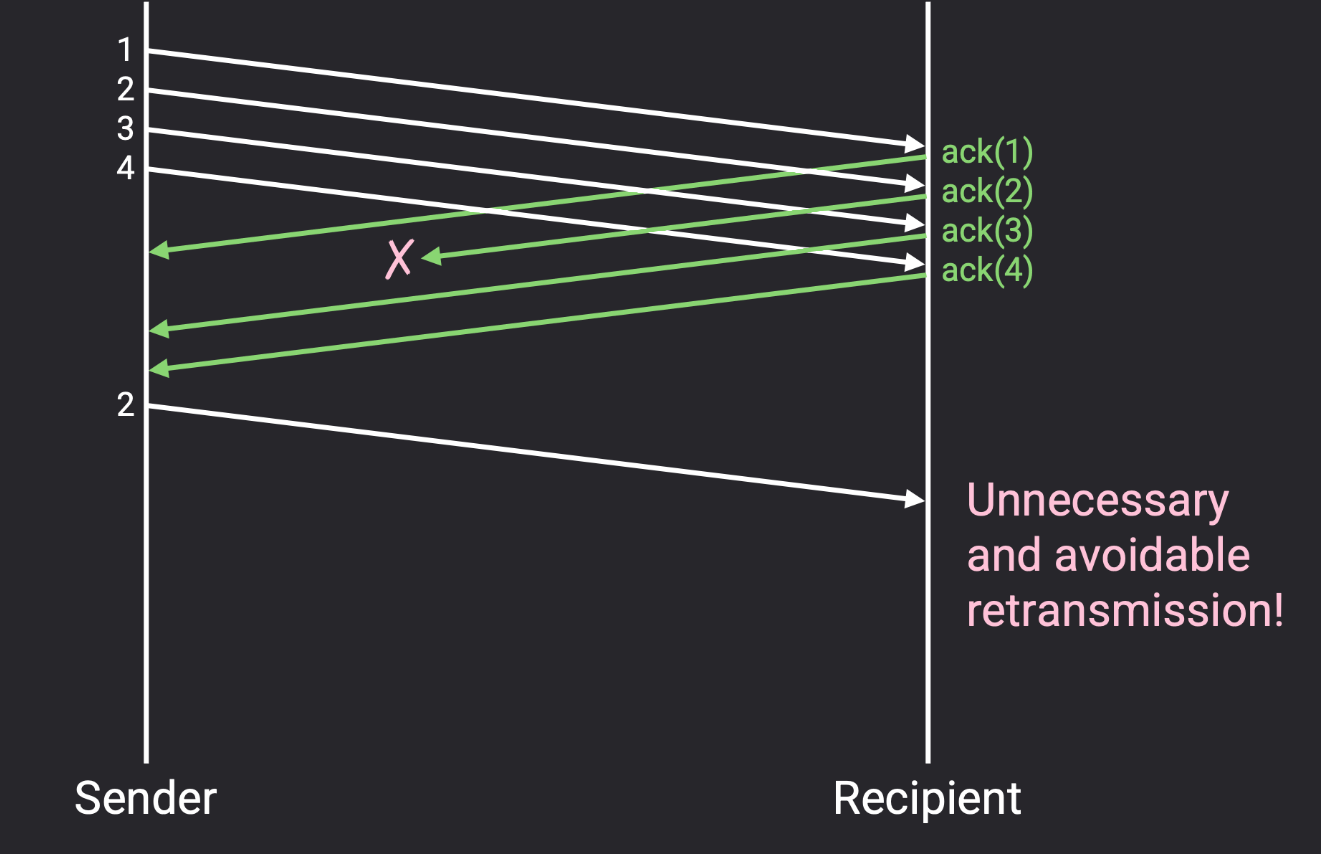
在这个例子中,即使接收者成功接收了所有 4 个数据包,其中一个确认包仍然丢失了。这将迫使发送者重新发送数据包 2,尽管这次重传是不必要的。
与其为特定的数据包发送确认,每次发送确认时,我们实际上可以列出我们已接收的所有数据包。这被称为全信息确认(full information ack) 。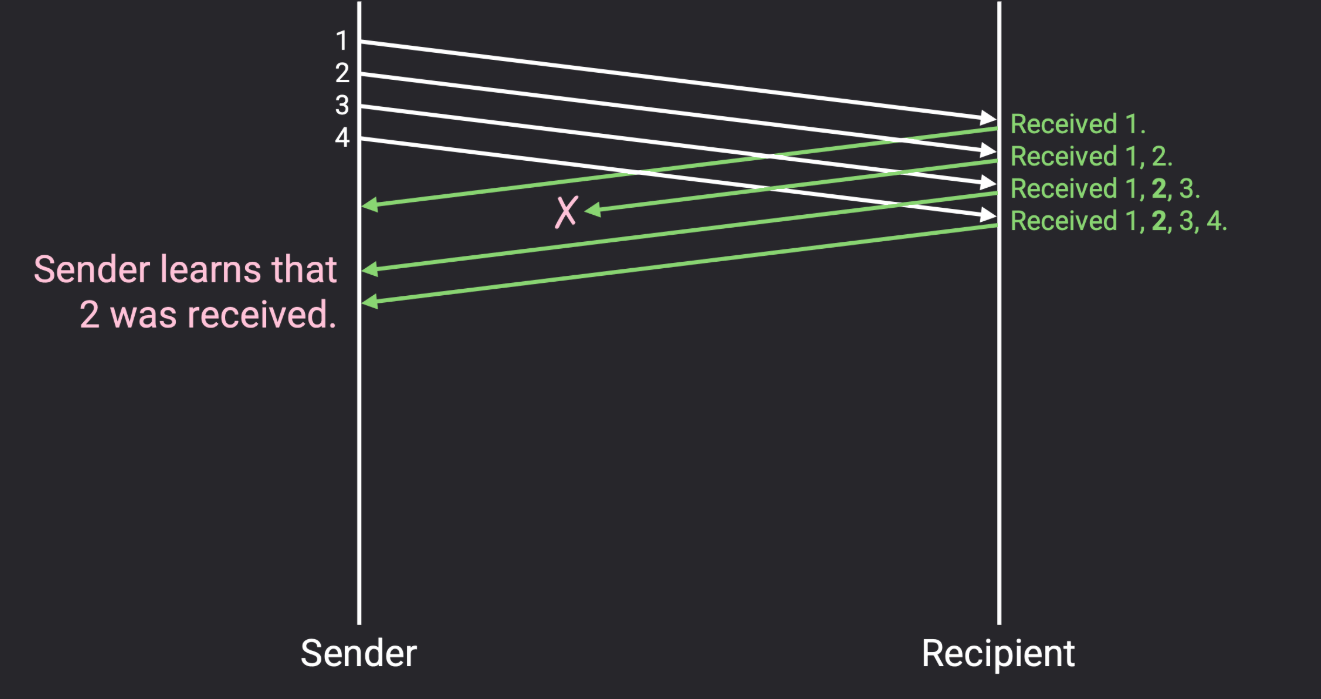
在这个例子中,确认包现在表示:"我收到了 1 个","我收到了 1 和 2 个","我收到了 1、2、3 个",以及"我收到了 1、2、3、4 个"。这样,尽管第二个确认包丢失了,但第三和第四个确认包帮助发送者确认包 2 已被接收,包 2 不再需要重传。
-
随着更多数据包的发送,所有已接收数据包的列表将会变得非常长。完整信息确认包可以通过以下方式简化信息:"我已经接收了编号到 12 的所有数据包。此外,我还接收了编号 14 和 15 的数据包。"形式上,我们给出最高的累积确认号(编号小于或等于这个数字的所有数据包都已接收),再加上一个已接收的任何额外数据包的列表。
即使有这种简写,完整信息确认包也可能变得很长。例如(极端情况下),如果所有偶数编号的数据包都丢失了,那么最高的累积确认号将始终是 1(因为我们只能说编号到 1 的所有数据包已被接收,因为 2 丢失了)。其余接收到的数据包将不得不列在1, 3, 5, 7, 9, ...这样的列表中,这可能会变得非常长。
-
在单独确认(individual acks ,每个确认丢失都强制重新发送)和完整信息确认(full information acks, 确认可能变长)之间的一种折衷方案是累积确认(cumalative acks) ,在这种方案中,我们只提供最高的累积确认,并丢弃附加列表。形式上,确认编码了所有先前数据包均已接收的最高序列号。

累积确认不再存在规模问题(我们总是发送一个数字,而不是一个数字列表)。然而,它们可能更模糊,如上述情况所示。发送者看到三个确认都说"我收到了编号至 1 的所有数据包",并可以推断出收到了三个数据包(编号为 1 的数据包和另外两个数据包),但无法推断出那两个数据包是什么。
Detecting Loss Early - 早期丢包检测
- 关于丢包检测,能否继续优化?不仅仅等待超时,而是利用我们接收到的其他信息来更早地检测丢包并更快地重传数据包?例如,在单独确认模型中,如果收到数据包 1、3、4、5、6 的确认,我们可能会推断数据包 2 丢失了,并在数据包 2 计时器到期之前重新发送它。
基于此想法,我们可以设置一个值 K(与窗口无关),并规定如果缺失数据包之后有 K 个连续的数据包被确认,我们就认为该数据包丢失(即使计时器尚未到期)。例如,如果 K=3,我们正在等待数据包 5 的确认,而我们收到了数据包 6、7 和 8 的确认,那么我们可以认为数据包 5 丢失了。

- 如果我们使用累积确认,这种策略可能会更加模糊。如果数据包 5 丢失,确认信息可能会显示"最多 4 个"(确认 4 个),然后是"最多 4 个"(确认 6 个),接着是"最多 4 个"(确认 7 个),然后是"最多 4 个"(确认 8 个)。发送方由于连续数据包之间的间隙而看到重复的确认信息。如果 K=3,那么在接收到 3 个重复的确认信息后(对应于间隙后确认的 3 个更多数据包),我们可以宣布数据包 5 丢失,总共 4 个重复的确认信息。
相反的,当我们有单独的确认和完整信息的确认时,我们可以清楚地看到哪个数据包需要重发。有一个数据包缺少确认(并且 K 个后续确认到达)。然而,使用累积确认时,决定重发哪个数据包变得更加模糊,尤其是在多个数据包丢失的情况下。