目录
[一、 为什么需要RabbitMQ集群](#一、 为什么需要RabbitMQ集群)
[二、 RabbitMQ普通集群的致命缺陷](#二、 RabbitMQ普通集群的致命缺陷)
[三、 解决方案:仲裁队列(Quorum Queue)](#三、 解决方案:仲裁队列(Quorum Queue))
一、 为什么需要RabbitMQ集群
1.1、单点故障风险:
如果 RabbitMQ 服务器断电、内存崩溃或硬件故障,整个消息服务直接瘫痪,依赖它的业务(比如订单推送、通知发送)全停;
1.2、吞吐量不够:
单机通常只能扛每秒几千条消息,要是业务需要每秒 10 万条消息(比如电商大促),靠升级单机硬件成本太高,不如加节点扩展。
而RabbitMQ集群可以解决这两个问题:
高可用:单个节点崩溃,客户端能连其他节点继续生产 / 消费;
扩吞吐:加节点就能线性提升消息处理能力。
二、 RabbitMQ普通集群的致命缺陷
普通集群只同步元数据,不同步消息本身。
元数据同步:所有节点都知道队列、交换机的名字和属性。
消息不备份 :队列中的消息只存在于创建该队列的那个节点上。
严重后果 :如果某个节点宕机,该节点上队列的所有消息都会永久丢失,即使队列和消息都设置了持久化。
本质 :普通集群主要提高了并发处理能力 ,但未实现数据的"高可用"。
三、 解决方案:仲裁队列(Quorum Queue)
RabbitMQ的仲裁队列是基于Raft一致性算法实现的持久化、复制的FIFO队列;提供队列复制的能力,保障数据的高可用和安全性;使用仲裁队列可以在RabbitMQ节点间进行队列数据的复制,从而达到在一个节点宕机时,队列仍然可以提供服务的效果。
3.1、Raft共识算法
1、核心概念
三种角色:
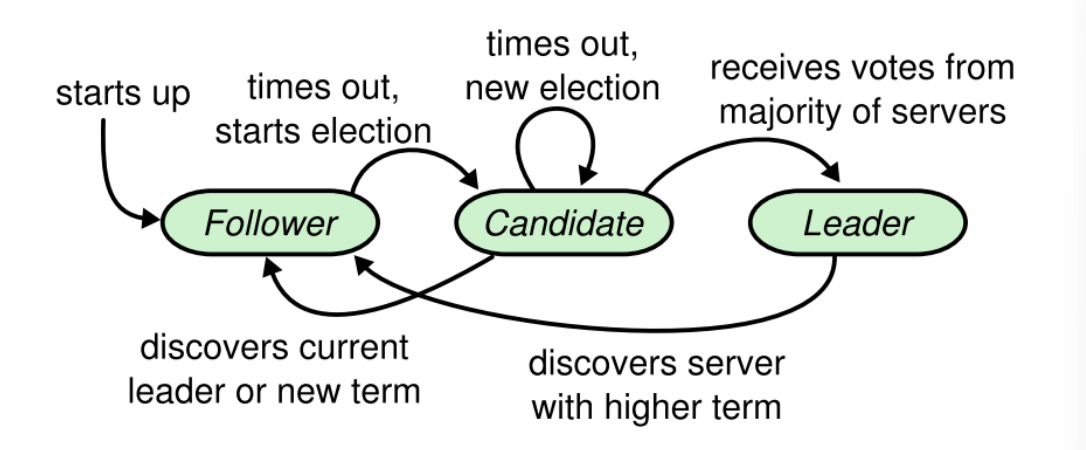
Leader(主节点):处理客户端所有请求(发消息、收消息),同步日志到从节点;Follower(从节点):接收 Leader 的日志同步,不直接处理客户端请求;
Candidate(候选节点):Follower 没收到 Leader 心跳时,会变成 Candidate 发起选举。
三种角色状态转换图:
任期:
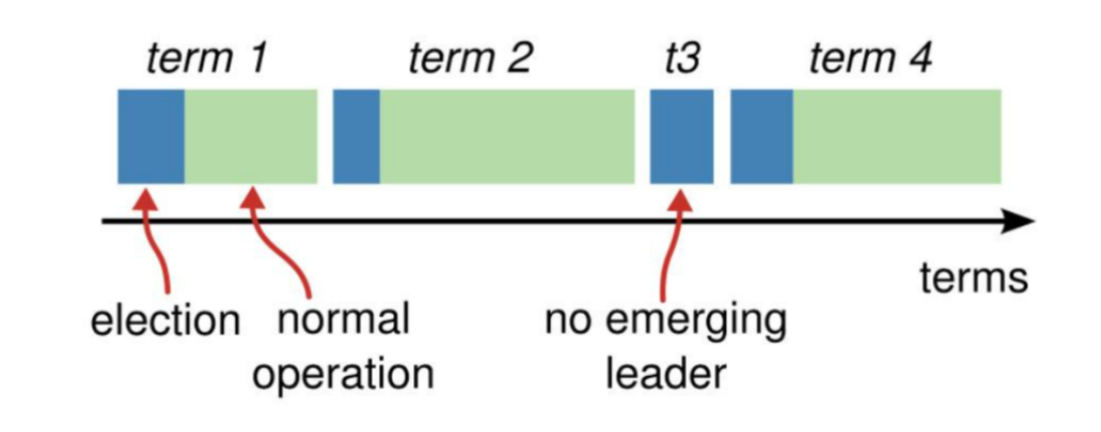
Raft 把时间分成 "任期(Term)",每个任期从选举开始,有且只有一个 Leader(没选出来就进入下一个任期),任期像 "逻辑时钟",避免节点状态混乱。
节点之间通信的时候会交换当前任期号:
如果一个节点的当前任期号比其他节点小,那么它就将自己的任期号更新为较大的那个值.
如果一个candidate或者leader发现自己的任期号过期了,它就会立刻回到follower状态.
如果一个节点接收了一个带着过期的任期号的请求,那么它会拒绝这次请求.
2、两大核心RPC(远程过程调用)
Raft算法中服务器之间采用RPC进行通信,主要有两类RPC请求:
RequestVote RPC(请求投票):
由Candidate发起,竞选Leader时,向其他节点拉票,每个节点在一个任期内只能投一票(先到先得)
AppendEntries RPC(追加条目):
由Leader发起,将客户端的消息(操作日志)同步给所有的Follower,定期发送心跳,宣告自己存活,组织其他节点发起选举
3.2、Leader选举流程
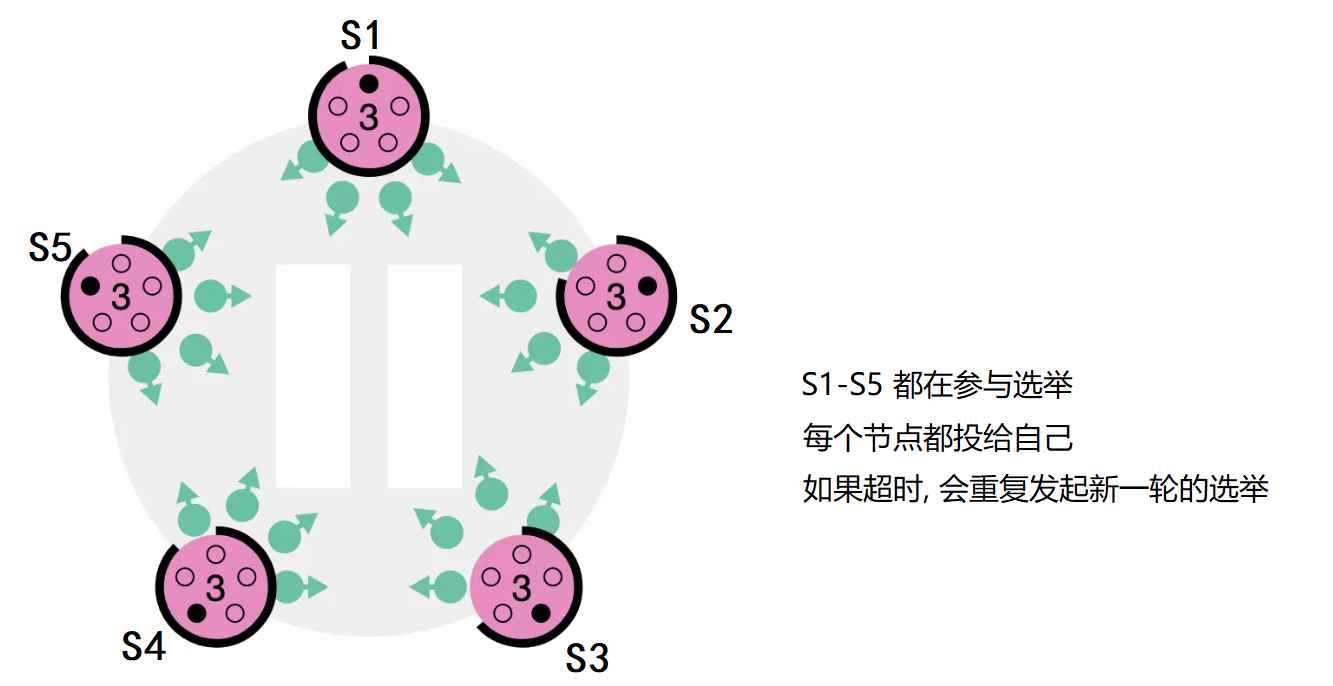
1、所有节点启动时均为Follower
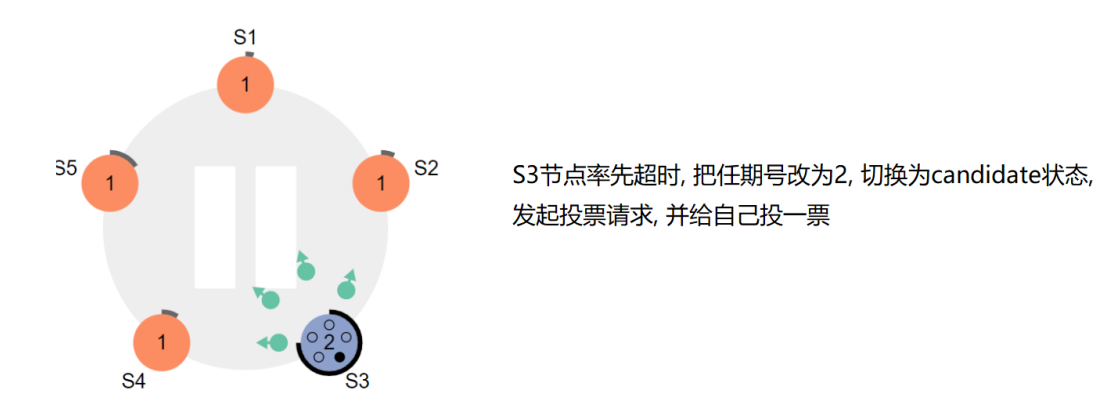
2、Follower在设定的时间内未收到Leader心跳,则变为Candidate
3、Candidate递增任期号,先投自己一票,然后并行向其他节点发送RequestVote RPC
4、等待投票结果,出现三种情况:
情况A(获胜) :收到超过半数投票,成为Leader,并立即广播心跳确立地位。
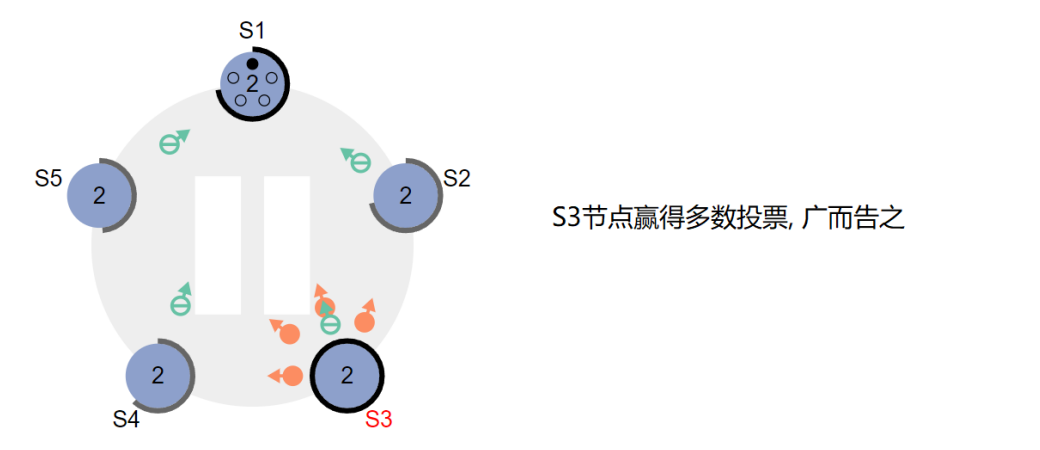
情况B(失败) :收到其他合法Leader的心跳,且其任期号不低于自己,则主动降级为Follower。

情况C(平局) :未收到半数投票,也未收到新Leader心跳。等待随机超时后,发起新一轮选举 (随机超时设计是为了减少再次冲突)。
3.3、数据复制流程
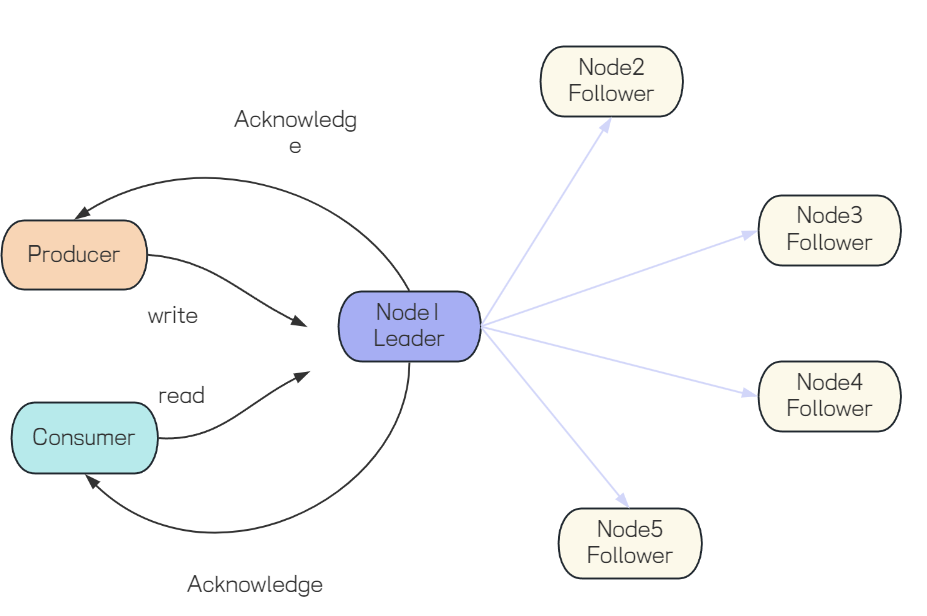
1、客户端向Leader发送一条消息。
2、Leader将其作为日志条目追加到本地,然后通过
AppendEntries RPC给所有Follower发送复制请求。3、当超过半数的Follower回复确认后,Leader即认为该日志条目已提交,可以安全地应用到状态机(如存储消息),并回复客户端成功。
4、Leader在后续心跳中通知Follower哪些日志已提交,Follower随后应用这些日志。
四、引入负载均衡:HAProxy
4.1、HAProxy必要性
节点故障客户端断连:如果客户端连的节点挂了,程序得改配置重新连其他节点,太麻烦;
流量不均衡:所有客户端都连同一个节点,这个节点网络负载爆满,其他节点闲得慌,浪费资源。
4.2、HAProxy核心作用
统一入口:客户端只连 HAProxy 的 IP 和端口,不用管背后有多少 RabbitMQ 节点;
流量分摊:把客户端请求均匀分给集群节点,避免单节点过载;
故障转移:某个 RabbitMQ 节点挂了,HAProxy 会自动把流量切到其他正常节点,客户端完全没感觉。
4.3、自身高可用
HAProxy 也可能单点故障(比如 HAProxy 服务器宕机),所以生产环境会配Keepalived做 "主备 HAProxy":
主 HAProxy 正常时,流量走主节点;
主 HAProxy 故障,备节点自动接管 IP 和流量,保证负载均衡服务不中断。